LiteLLM深度解析:功能亮点、完整使用指南及与CC Switch的终极对比
前言
2026年,大语言模型已全面进入工程化落地阶段。OpenAI、Anthropic、Google、DeepSeek、智谱AI等数十家厂商的模型百花齐放,开发者在享受模型红利的同时,也面临三个核心痛点:多模型API格式碎片化(换模型就要重写业务代码)、调用成本失控(单月账单动辄数万)、单模型宕机直接导致线上应用瘫痪(可用性难以保障)。
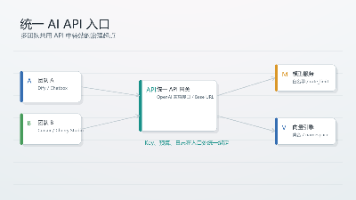
在这种背景下,AI网关 应运而生——它充当应用与上游模型厂商之间的统一入口层,是实现AI工程化不可或缺的基础设施。而 LiteLLM 和 CC Switch 正是这一赛道中最受关注的两个开源项目。
本文将全面解析LiteLLM的核心功能亮点,提供从安装到部署的完整使用指南,并深度对比LiteLLM与CC Switch的差异,帮助你根据实际场景做出正确选择。
一、LiteLLM是什么?
LiteLLM本身不是模型,而是一个统一的AI网关与中间件层。 它最初只是一个薄薄的抽象层,用于屏蔽不同LLM服务商的API差异,如今已演进为一个成熟的、生产级的AI网关。
通俗理解:如果把各种大模型API比作不同规格的电源插座(美标、欧标、国标),LiteLLM就是那个 “万能转接头” ——对外暴露统一的接口(OpenAI格式),对内适配所有主流模型提供商。
核心技术特性:
-
统一接口:100+ LLM提供商,全部通过OpenAI兼容格式调用(文本生成、嵌入、图像生成、视频生成)
-
零代码改造:业务代码无需任何修改即可接入,一行配置切换模型
-
生产级特性:内置重试与故障转移、负载均衡、成本追踪、预算控制、限流、缓存、日志记录等全套运维能力
-
极致性能:当前可在4 CPU、8 GB RAM单实例上承受5000 QPS压力测试零失败,并正在向亚毫秒级代理延迟的目标迈进
二、LiteLLM 核心功能亮点
2.1 统一API:一套代码调用100+模型
这是LiteLLM最核心的能力。无论底层是OpenAI GPT-5、Anthropic Claude 4.5、Google Gemini 2.5还是本地vLLM/Ollama部署的开源模型,开发者只需使用同一套OpenAI风格的代码即可完成调用。
传统方式的痛点:每个厂商的API格式、参数定义、错误码都不相同,业务代码里写死厂商SDK,换模型就要重写调用逻辑、适配参数、处理错误——一个Agent应用兼容3家模型就得多写上千行适配代码。
LiteLLM的解决方案:统一OpenAI兼容格式,所有模型调用都用同一套代码,一行配置切换模型,业务层完全不用关心底层厂商差异。
from litellm import completion
# 调用 OpenAI
response = completion(model="openai/gpt-5", messages=[{"role": "user", "content": "你好"}])
# 切换到 Claude,只需修改 model 参数
response = completion(model="anthropic/claude-4-sonnet", messages=[{"role": "user", "content": "你好"}])
# 切换到本地 Ollama 模型
response = completion(model="ollama/llama3", messages=[{"role": "user", "content": "你好"}])2.2 智能路由:成本优化与故障自动转移
LiteLLM不只是简单转发请求,更像一个“智能调度员”,能在不同模型之间进行灵活调度。
(1)负载均衡
当某个模型的请求量过大时,LiteLLM自动将请求分发到多个部署实例或API密钥上,避免单点过载。
(2)故障转移(Fallback)
当首选模型出现超时、限流或宕机时,LiteLLM自动切换到备用模型,确保业务不中断。结合多模型路由,实测可将大模型调用可用性从99.5%提升至99.99%。
(3)成本优化路由
设定预算上限后,LiteLLM可以根据价格自动将部分请求路由到更便宜的模型(如将非核心场景的请求从高价模型降级为性价比更高的模型),实测可将大模型调用成本降低高达70%。
2.3 企业级治理与安全
对于团队和企业用户,LiteLLM提供强大的中央管控能力。
统一鉴权:通过虚拟密钥(Virtual Key)管理所有后端模型的访问权限,团队成员无需接触真实的API Key。
预算与限流:可为不同项目、不同团队设置费用上限和调用频率限制,有效防止滥用和账单爆炸。
全链路可观测性:提供详细的日志记录、成本追踪和监控面板,清晰掌握每个团队的花费和模型调用表现。
安全护栏:支持边缘级防护,包括内容过滤、数据脱敏和PII遮蔽等。
2.4 高级功能支持
LiteLLM通过统一接口实现了跨提供商的高级AI工作流能力。
工具调用:统一OpenAI兼容的 tools 参数,支持跨OpenAI、Anthropic、Bedrock、Vertex AI的函数调用,自动将请求转换为各提供商的格式。
Prompt缓存:支持Anthropic、Gemini、OpenAI、Bedrock的原生提示缓存,通过缓存重复使用的前缀大幅降低延迟和成本。
推理/思考模式:支持Claude 3.7+、OpenAI o1/o3、Gemini的深度推理能力,通过 reasoning_effort 或 thinking 参数控制。
结构化输出:统一的 response_format 参数,支持跨提供商的JSON模式输出。
MCP服务器集成:通过代理服务支持Model Context Protocol(MCP)服务器的集成,实现分布式工具执行。
2.5 极致性能优化
LiteLLM团队2026年Q1的性能目标是实现亚毫秒级代理延迟。目前已在4 CPU、8 GB RAM的单实例上做到5000 QPS零失败压力测试,并采用可选的Sidecar架构将性能关键型执行从Python进程中分离处理,确保生产环境的高吞吐和低延迟。
三、LiteLLM 完整使用指南
3.1 环境要求与安装
环境要求:
-
Python 3.8 或更高版本
-
建议在虚拟环境中操作
安装方式一:pip快速安装(推荐入门)
pip install litellm如果需要在生产环境部署代理服务,安装带代理功能的版本:
bash
pip install 'litellm[proxy]'安装方式二:Docker部署(推荐生产环境)
bash
docker pull ghcr.io/berriai/litellm:main-latest验证安装是否成功:
import litellm
print(f"✅ LiteLLM 版本:{litellm.__version__}")3.2 SDK模式:快速开始
SDK模式适合个人开发者或简单脚本,直接在Python代码中调用。
from litellm import completion
# 1. 设置API密钥(或通过环境变量设置)
import os
os.environ["OPENAI_API_KEY"] = "your-openai-key"
os.environ["ANTHROPIC_API_KEY"] = "your-anthropic-key"
# 2. 基础调用
response = completion(
model="openai/gpt-4o",
messages=[{"role": "user", "content": "用一句话介绍LiteLLM"}]
)
print(response.choices[0].message.content)
# 3. 流式响应
response = completion(
model="anthropic/claude-4-sonnet",
messages=[{"role": "user", "content": "写一首关于AI的诗"}],
stream=True
)
for chunk in response:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="")
# 4. 带工具调用
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "获取指定城市的天气",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}},
"required": ["city"]
}
}
}]
response = completion(
model="openai/gpt-5",
messages=[{"role": "user", "content": "北京今天天气怎么样?"}],
tools=tools,
tool_choice="auto"
)3.3 代理模式(Proxy):企业级部署
当需要为团队提供统一的AI接口访问时,推荐使用代理模式。
Step 1:创建配置文件 litellm_config.yaml
model_list:
- model_name: gpt-5
litellm_params:
model: openai/gpt-5
api_key: ${OPENAI_API_KEY}
- model_name: claude-4-sonnet
litellm_params:
model: anthropic/claude-4-sonnet
api_key: ${ANTHROPIC_API_KEY}
- model_name: deepseek-v3
litellm_params:
model: deepseek/deepseek-chat
api_key: ${DEEPSEEK_API_KEY}
general_settings:
master_key: ${LITELLM_MASTER_KEY}
litellm_settings:
drop_params: true
set_verbose: true
router_settings:
routing_strategy: "latency-based-routing"
enable_load_balancing: true
allowed_fails: 3
num_retries: 2
fallbacks:
- gpt-5: ["claude-4-sonnet"]
- claude-4-sonnet: ["gpt-5"]Step 2:启动代理服务
# 使用 pip 安装的代理模式启动
litellm --config litellm_config.yaml --port 4000
# 或使用 Docker
docker run -p 4000:4000 \
-v $(pwd)/litellm_config.yaml:/app/config.yaml \
-e OPENAI_API_KEY=$OPENAI_API_KEY \
-e ANTHROPIC_API_KEY=$ANTHROPIC_API_KEY \
ghcr.io/berriai/litellm:main-latest \
--config /app/config.yamlStep 3:客户端调用代理
启动代理后,其他应用只需将API地址指向 http://localhost:4000 即可:
import openai
client = openai.OpenAI(
base_url="http://localhost:4000/v1",
api_key="your-virtual-key" # 使用虚拟密钥而非真实API Key
)
response = client.chat.completions.create(
model="gpt-5",
messages=[{"role": "user", "content": "你好"}]
)Step 4:访问管理界面
代理启动后,可以访问 http://localhost:4000/ui 进入内置的Web管理面板,实现可视化模型管理、密钥创建、用量监控等操作。
3.4 Docker Compose 生产环境部署
对于长期使用或团队协作,推荐使用Docker Compose方式部署。
目录结构:
text
litellm/ ├── docker-compose.yml ├── litellm_config.yaml └── .env
docker-compose.yml:
services:
litellm:
image: docker.litellm.ai/berriai/litellm:main-stable
ports:
- "4000:4000"
volumes:
- ./litellm_config.yaml:/app/config.yaml
command: ["--config=/app/config.yaml"]
environment:
DATABASE_URL: "postgresql://llmproxy:dbpassword@db:5432/litellm"
STORE_MODEL_IN_DB: "True"
env_file:
- .env
depends_on:
- db
db:
image: postgres:16
restart: always
environment:
POSTGRES_DB: litellm
POSTGRES_USER: llmproxy
POSTGRES_PASSWORD: dbpassword
ports:
- "5432:5432"
volumes:
- ./postgres_data:/var/lib/postgresql/data启动:
docker compose up -d
3.5 成本追踪与预算管控
LiteLLM可以详细追踪每一次调用的成本,便于团队预算管理。在代理模式下配置预算:
litellm_settings: success_callback: ["prometheus"] # 接入Prometheus监控
还可以通过管理UI为不同虚拟密钥设置不同的预算上限,实现精细化的成本控制。
四、LiteLLM 的局限与注意事项
尽管LiteLLM功能强大,但在实际使用中也需要注意以下几点:
-
部分厂商高级功能可能受限:为统一API体验,LiteLLM在某些情况下可能舍弃特定厂商的独家功能(如Bedrock的特定函数调用能力),需要团队在使用时评估是否会影响业务场景。
-
drop_params模式可能静默丢弃参数:当路由决策导致调用不支持的参数时,这些功能可能悄无声息地丢失。 -
最佳实践提示:如果你重度依赖某个特定提供商的独有功能,可能需要同时维护网关依赖和特定提供商的耦合代码。
五、LiteLLM vs CC Switch:全面对比
5.1 CC Switch是什么?
CC Switch 是一款面向终端开发者的 跨平台桌面应用(支持 Windows / macOS / Linux),其核心定位是 AI编程工具的配置中心与切换管家。
它主要服务于个人开发者,用于统一管理 Claude Code、Codex、Gemini CLI、OpenCode、OpenClaw 五大AI编程CLI工具的供应商配置、MCP配置和Skills配置。内置50+供应商预设,选择后填入API Key即可一键切换,解决手动编辑JSON/TOML/.env配置文件的繁琐问题。
5.2 核心差异对比表
| 对比维度 | LiteLLM | CC Switch |
|---|---|---|
| 定位 | 企业级AI网关/中间件 | 终端开发者配置管理工具 |
| 目标用户 | 平台团队、后端开发者、企业 | AI编程工具的个人用户、前端开发者 |
| 架构形态 | Python库 + 独立Proxy服务 | 跨平台桌面应用(Tauri/Rust构建) |
| 部署方式 | pip/Docker/自托管服务 | 桌面安装(brew/MSI/AppImage) |
| 支持的模型/供应商 | 100+ LLM提供商(通过API) | 50+内置预设(含国内中转服务) |
| 核心使用场景 | Web应用/API服务的模型调用 | Claude Code/Codex/Gemini CLI等本地AI编程工具的模型切换 |
| 接口标准 | OpenAI兼容API | Anthropic API兼容格式(适配各类CLI工具) |
| 多模型切换 | 通过修改 model 参数或路由策略动态切换 |
图形界面一键切换,系统托盘热切换 |
| 负载均衡 | ✅ 支持(多实例、多Key) | ❌(个人用途,无需) |
| 故障转移 | ✅ 自动Fallback,多级备用链 | ✅ 本地故障转移+熔断器 |
| 成本控制 | ✅ 预算上限、成本追踪、用量报表 | ✅ Token消耗统计、趋势图表 |
| 权限管理 | ✅ 虚拟Key、团队管理、角色权限 | ❌(个人工具,仅本地加密存储) |
| 可观测性 | ✅ 日志、追踪、Prometheus监控 | ✅ API节点延迟可视化、请求日志 |
| MCP支持 | ✅ 代理层MCP服务器集成 | ✅ 跨4个应用统一管理MCP配置 |
| SDK/API集成 | ✅ Python SDK + REST API | ❌(桌面应用,无对外API) |
| 缓存支持 | ✅ 提供商原生Prompt缓存 | ❌ |
| 工具调用 | ✅ 统一 tools 参数跨提供商 |
❌ |
| 云同步 | ❌ | ✅ WebDAV/iCloud/坚果云多端同步 |
| 开源协议 | MIT License | 开源(GitHub) |
| 企业级部署 | ✅ 支持Kubernetes、Docker Compose | ❌ |
| 性能 | 5000 QPS零失败,目标亚毫秒延迟 | 不适用(非API服务) |
5.3 关键差异深度解读
差异一:平台 vs 工具
LiteLLM 是一个可独立部署的 平台级基础设施,设计初衷是成为团队所有AI应用访问大模型的统一入口。当你有Web服务、移动端App、定时任务等多个应用需要调用AI模型时,LiteLLM作为中央网关统一管理所有流量、权限和预算。
CC Switch 是一个运行在本地的 终端工具,它的设计目标是“让Claude Code等AI CLI工具的用户不再需要手动编辑JSON配置文件”。它不提供对外API,只服务于使用者本机上的AI编程工具。
类比: LiteLLM就像公司里统一的WiFi路由器,所有员工通过它上网;CC Switch就像你手机里的WiFi管理App,帮你快速切换不同的热点。
差异二:服务端 vs 客户端
LiteLLM 部署在 服务端(服务器/Docker),所有流量经过它转发到上游模型提供商。当调用量激增时,它承担着负载均衡、失败重试、限流等关键职责。
CC Switch 运行在 客户端(你的笔记本电脑/台式机),它干预的是Claude Code等本地CLI工具的启动环境和配置文件,而不是请求的实际网络路径。它通过本地代理服务实现透明切换,但不承载高并发流量。
关键区分: 当你使用CC Switch切换到DeepSeek后,Claude Code的请求 直接 发往DeepSeek的API服务器,CC Switch本身不参与请求的转发和处理。而LiteLLM则是请求的 必经中转站。
差异三:团队管控 vs 个人效率
LiteLLM 天然服务于团队场景:谁用了多少Token、花了多少钱、有没有超预算——这些信息都可以通过统一的管理面板一目了然。
CC Switch 服务于个人开发者的效率提升:快速切换模型对比效果、统一管理多个CLI工具的配置、在多台设备间同步设置——这些能力属于“个人生产力”范畴。它也支持团队统一配置模板,但不提供运行时管控(无法阻止某个开发者超量调用)。
差异四:API集成 vs 工具适配
LiteLLM 提供标准的 REST API 和 Python SDK,可以集成到任何类型的应用中——不仅限于AI编程工具,也适用于聊天机器人、内容生成、数据分析等各类AI应用场景。
CC Switch 的功能边界则限定在 特定的AI CLI工具(Claude Code、Codex、Gemini CLI、OpenCode、OpenClaw),它解决的是“这些工具的配置文件格式不统一”这一具体问题。如果你需要给公司的生产服务接入AI模型,CC Switch完全无法满足需求。
5.4 使用建议:什么时候选哪个?
选择 LiteLLM 的场景:
-
✅ 构建需要调用大模型的Web应用或API服务
-
✅ 团队有多个项目/多个人需要共用AI模型
-
✅ 需要精细化的预算管控和成本追踪
-
✅ 需要高可用保障(故障转移、负载均衡)
-
✅ 需要统一的API入口来纳管多个模型提供商
-
✅ 生产环境需要日志、监控、告警等运维能力
选择 CC Switch 的场景:
-
✅ 个人开发者使用Claude Code/Codex/Gemini CLI进行AI编程
-
✅ 需要在多个AI模型间频繁切换对比效果
-
✅ 不想手动编辑JSON/TOML配置文件
-
✅ 需要在多台设备间同步AI编程工具的配置
-
✅ 需要统一管理MCP服务器和Skills配置
两者也可以配合使用: 团队部署LiteLLM作为统一的模型接入网关,个人开发者在自己的机器上用CC Switch管理Claude Code等工具,将这些工具指向LiteLLM的代理地址——实现“团队管控 + 个人高效”的最佳实践。
六、总结
LiteLLM 是一个 生产级的AI网关基础设施,通过统一的OpenAI兼容接口纳管100+大模型提供商,提供智能路由、故障转移、成本管控、企业级安全等完整能力,已成为2026年Thoughtworks技术雷达的采纳项,被称为“AI驱动应用的明智默认选择”。
CC Switch 则是一个 面向终端开发者的效率工具,专注于解决AI CLI工具配置碎片化的痛点,让开发者可以通过图形界面一键切换模型,无需手动编辑配置文件。
一句话总结: LiteLLM管理的是“API流量”,CC Switch管理的是“配置文件”。两者定位不同、场景互补——了解它们的差异,才能在实际工作中做出正确选择。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)