(B站TinyML 教程学习笔记)C30 - 实施策略+C31 - 传感器融合+C32 - 课程总结
嵌入式机器学习部署与系统设计 学习笔记
(0:06) 嵌入式机器学习的实施策略
-
训练好模型后,还需要考虑:
-
阈值(Threshold)怎么设置
-
如何减少误判
-
如何在 MCU 上稳定运行
-
如何优化 CPU 占用
-
如何处理传感器数据
-
一、阈值(Threshold)与分类效果
(0:20) 什么是阈值?
-
神经网络输出的是“概率分数”
-
例如:
hello = 0.82
noise = 0.12
unknown = 0.06
-
通常需要设定一个阈值:
如果 hello > 0.6
则认为检测成功
(0:27) 使用直方图分析模型效果
真正力是“抓对了小偷”,真负力是“放对了路人”,这俩都是模型做对的事;
假负力是“放跑了小偷”,假正力是“抓错了路人”,这俩是模型犯的两种错。
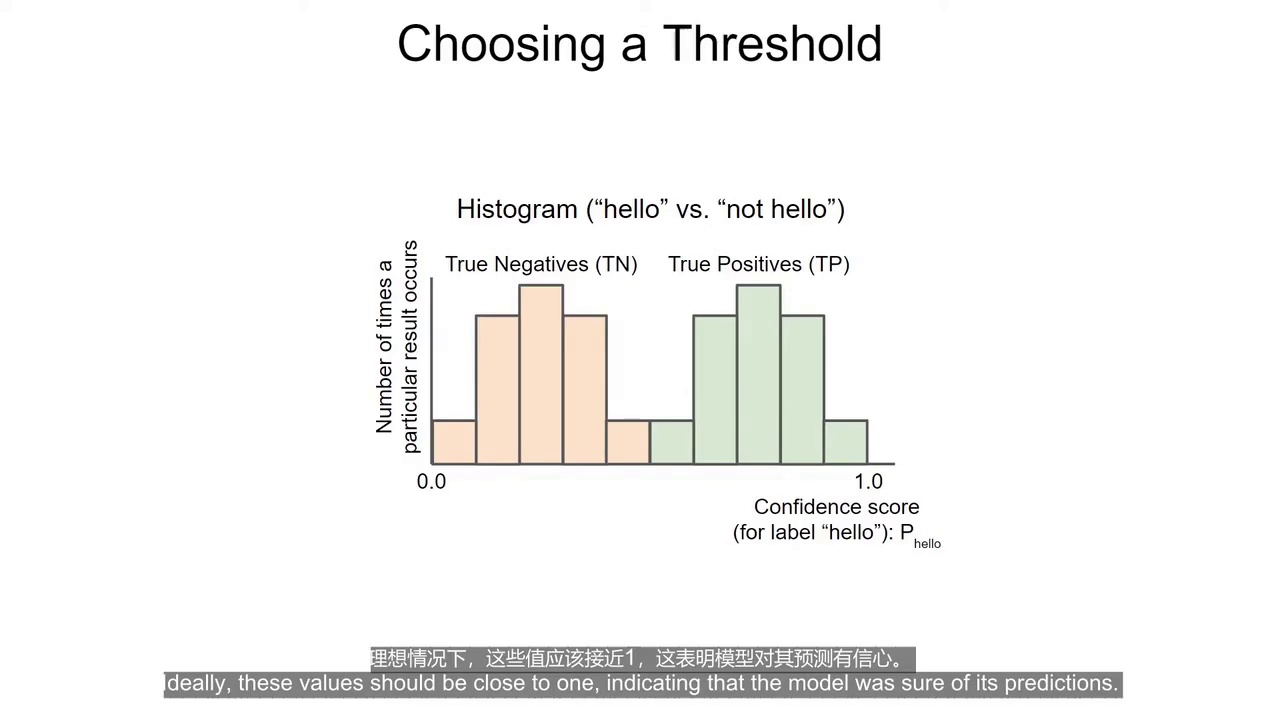
方法:
-
用测试集数据跑模型
-
记录模型输出概率
-
绘制直方图
(1:14) 观察两种分布是否分离
重点:
-
真正例分布
-
非目标分布
如果明显分开:
选择阈值会非常简单
(1:33) 理想情况
例如:
真正例集中在 0.5~1
非目标集中在 0~0.5
此时:
阈值选 0.5 即可
系统会非常稳定。
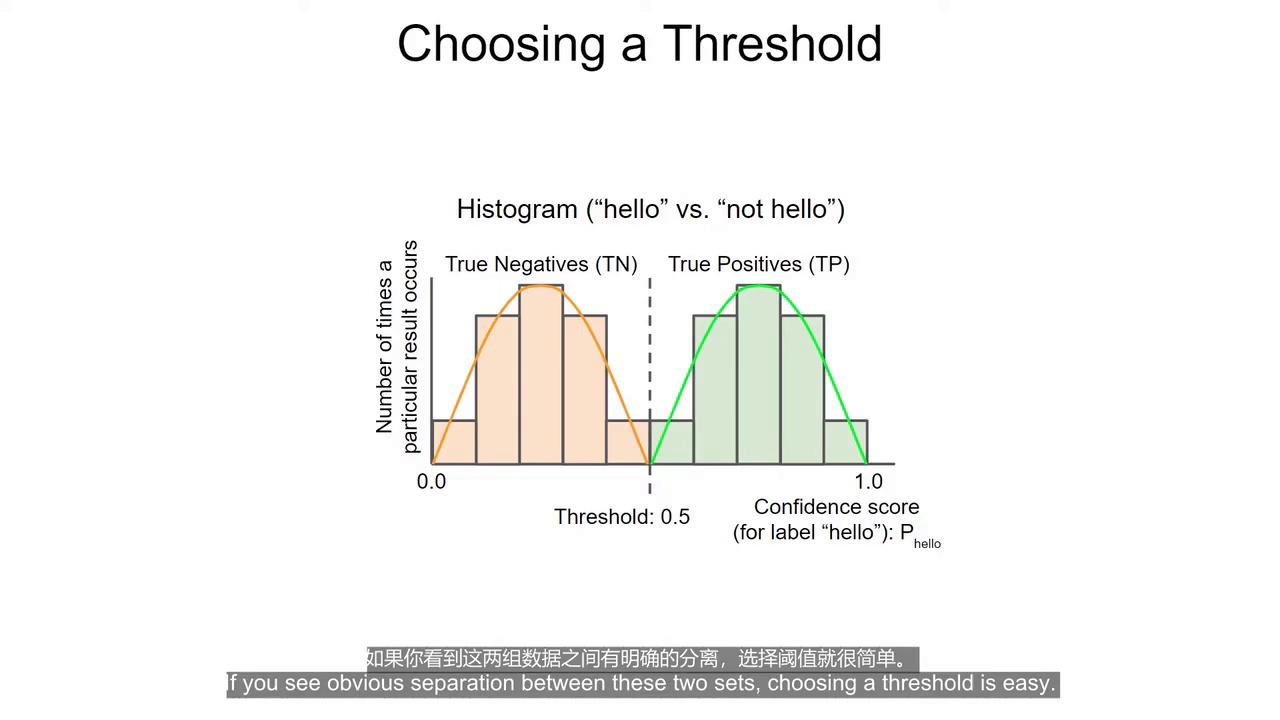
(1:41) 实际情况:分布重叠
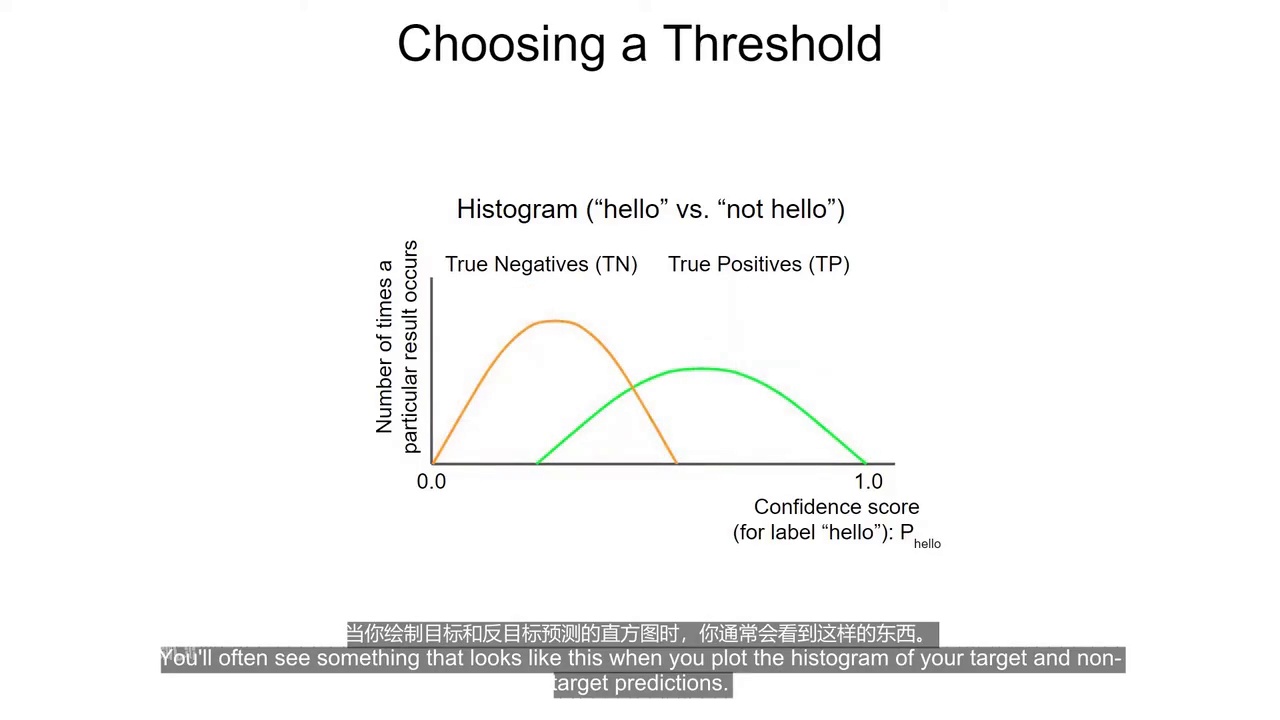
图中曲线分布解读:首先明确曲线不是先定置信度再去测试,而是喊出hello和not hello模型检测后给出的把握(确定是hello)分数
所以可以看见当喊出hello时,模型认为是hello的把握较高,
当喊出not hello时,模型认为是hello的把握低。
现实中:
-
两种数据通常会重叠
因此:
阈值不好选
(2:15) 阈值的取舍
阈值高
优点:
-
假正例减少
缺点:
-
假反例增加
阈值低
优点:
-
更容易检测到目标
缺点:
-
更容易误触发
(2:29) 不同应用的取舍
医疗 / 安全系统
宁愿:
多一点假正例
也不能:
漏检(假反例)
因为漏检代价太大。
(2:50) 关键词检测系统
例如:
Alexa
语音助手
更重要的是:
不要乱触发
因此:
-
通常会提高阈值
-
减少假正例
三、ROC 曲线 与 AUC
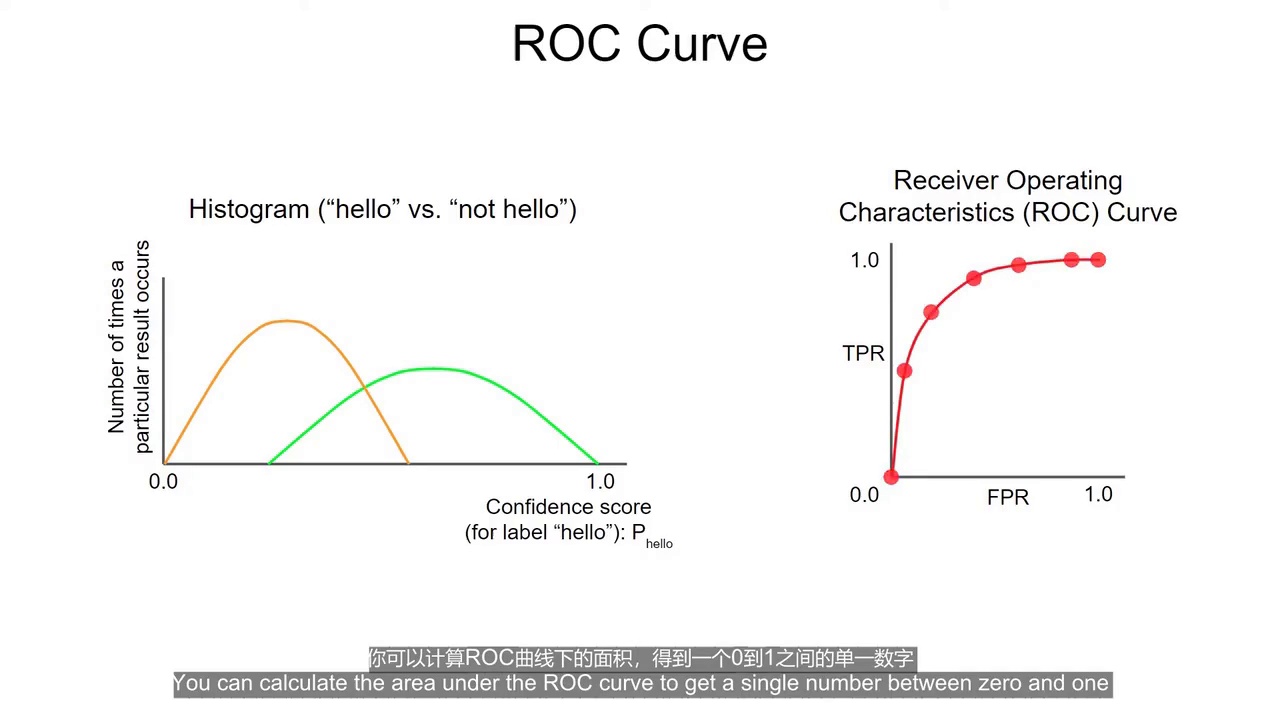
(3:04) ROC 曲线(根据不同的可信度绘制的)
ROC:
Receiver Operating Characteristic
接收者操作特征曲线
(3:04) ROC 坐标轴
X轴:
假正例率(FPR)
Y轴:
真正例率(TPR)
(3:17) ROC 原理
不断改变阈值:
0 → 1
然后:
-
计算 FPR
-
计算 TPR
最终形成曲线。
(3:48) 理想分类器
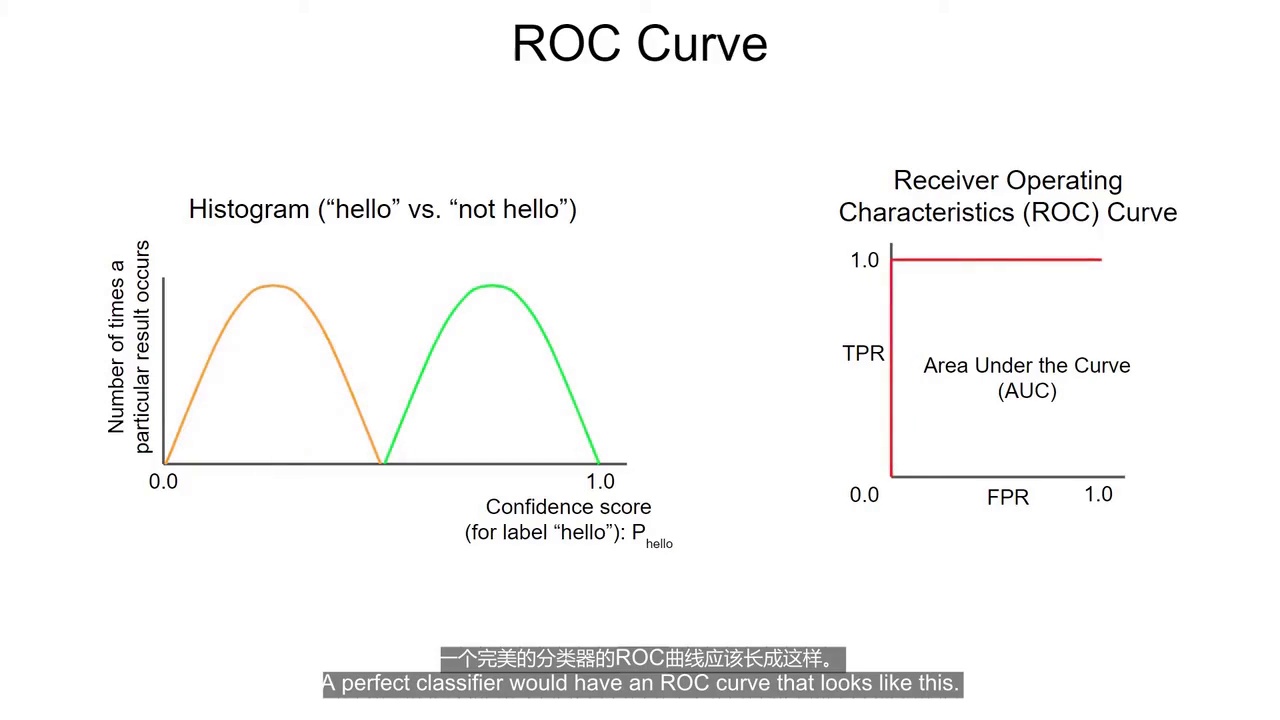
特点:
-
ROC 曲线贴近左上角
-
AUC 接近 1(面积)
说明:
分类效果非常优秀
(4:02) 最差分类器
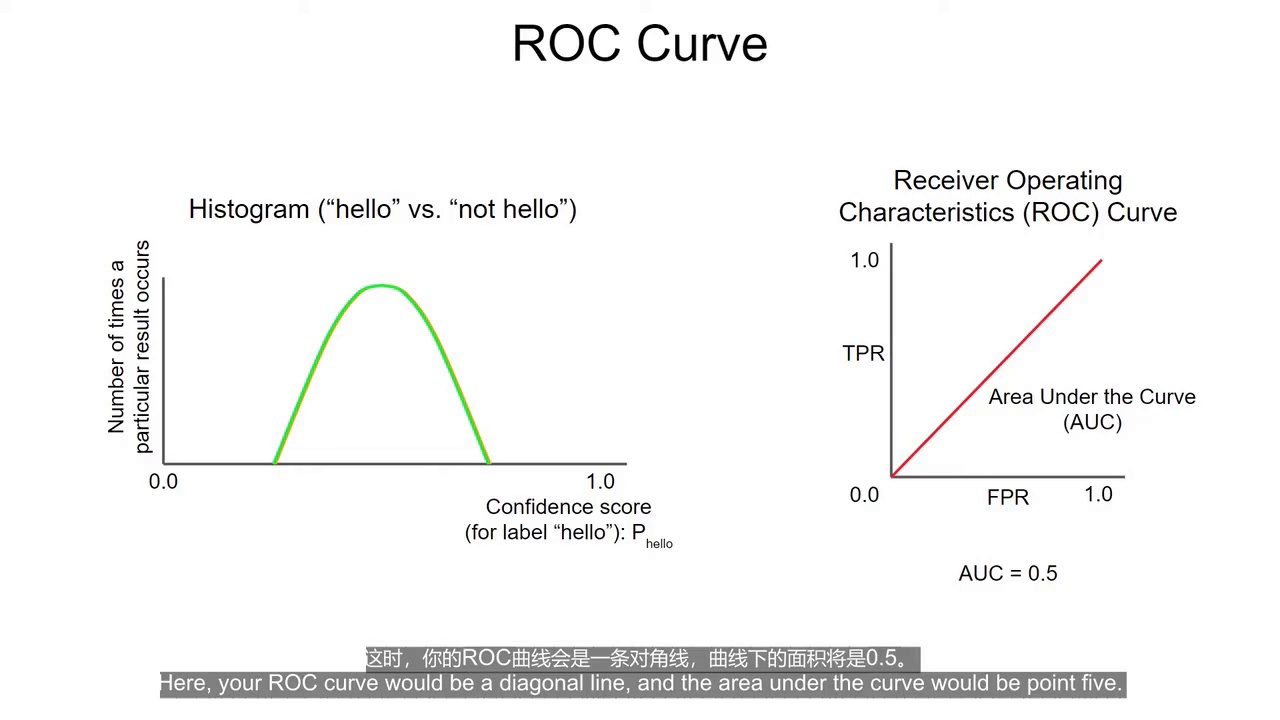
如果:
像随机猜测
ROC 会接近对角线。
(4:16) AUC
AUC:
ROC 曲线下面积
范围:
0.5 ~ 1
含义:
-
越接近 1 越好
-
0.5 基本等于乱猜
四、确定性(Deterministic)与概率性
(4:30) 确定性系统
定义:
同样输入
永远得到同样输出
例如:
-
FIR滤波器
-
FFT
-
普通数学运算
(5:13) 概率性 / 随机系统
特点:
相同输入
结果可能不同
内部存在随机性。
(5:35) 神经网络是随机的吗?
结论:
训练完成后的神经网络
是确定性的
(6:05) 为什么?
因为推理阶段本质是:
-
乘法
-
加法
-
激活函数
内部没有随机行为。
(6:25) 确定性的好处
可以验证模型是否正确部署。
方法:
PC 上运行一次
记录输出。
MCU 上运行同样输入
如果输出一致:
说明部署成功
(6:57) Edge Impulse 的作用
Edge Impulse:
-
自动完成模型转换
-
降低部署出错概率
Edge Impulse
(7:09) 为什么还要统计分析?
因为:
未知输入不可预测
虽然模型本身是确定性的:
但现实世界数据是变化的
因此仍需:
-
ROC
-
阈值分析
-
统计方法
五、移动平均滤波(Moving Average)
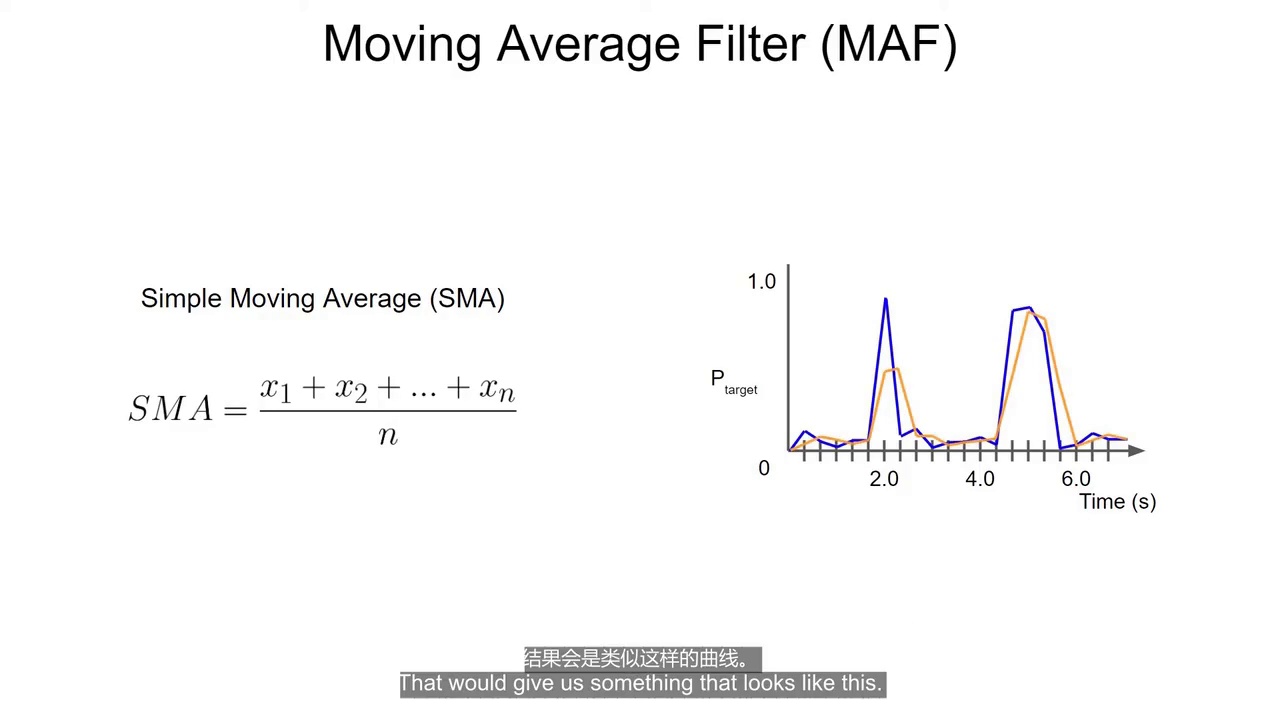
(7:35) 用输出分数做平滑处理
目的:
减少输出抖动
(7:51) 简单移动平均
方法:
当前值 + 前几个值
取平均
(8:02) 关键词检测示例
例如检测:
stop
系统每秒输出多个概率值。
(8:13) 两点移动平均
计算:
当前分数 + 上一个分数
再平均
(8:22) 平滑后的好处
系统不直接看瞬时值:
而看平均值
这样可以:
-
减少误触发
-
提高稳定性
(8:30) stopping 问题
例如:
stopping
前半段像:
stop
会短暂提高分数。
但后面:
ing
又会降低分数。
移动平均可以避免误触发。
(8:54) 缺点:延迟
因为:
需要等待多个采样点
所以:
响应速度会变慢
六、Hold-off 技术
(9:07) 什么是 Hold-off?
当事件触发后:
暂停继续推理
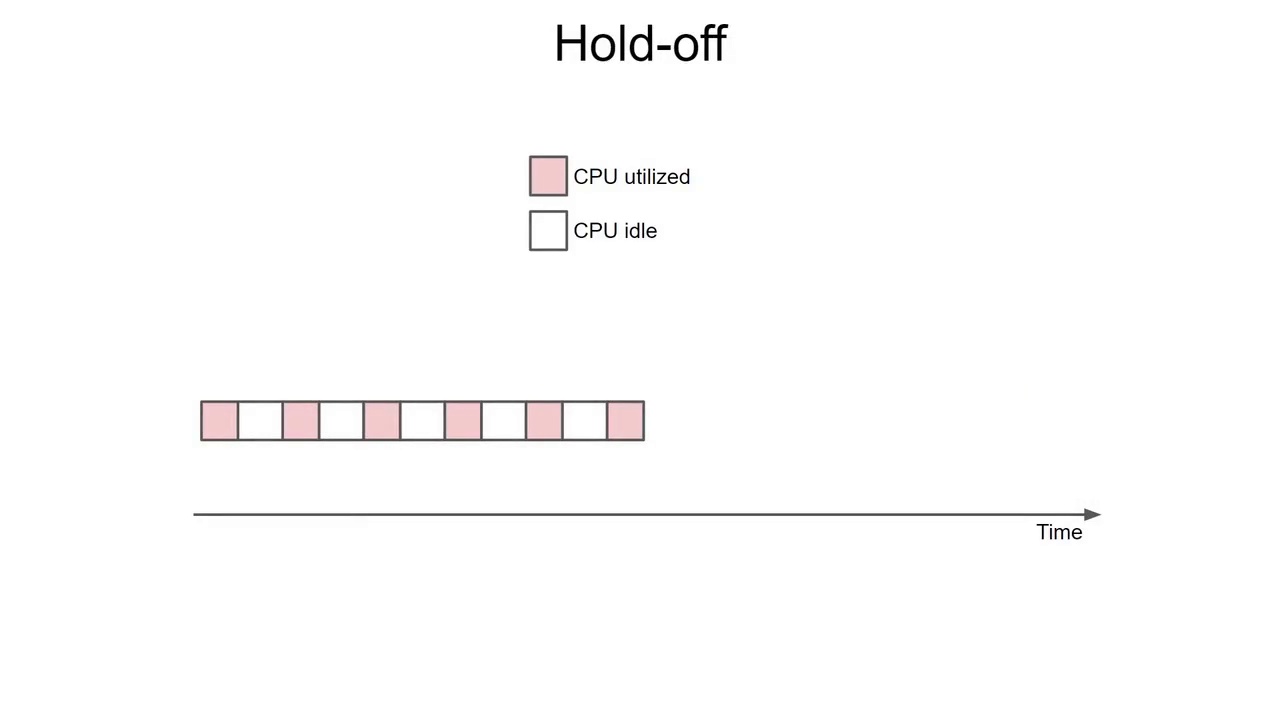
(9:15) CPU 占用问题
例如:
333ms 周期
其中:
135ms 用于推理
剩余时间:
只有 198ms
用于其他任务。
(9:34) Hold-off 的作用
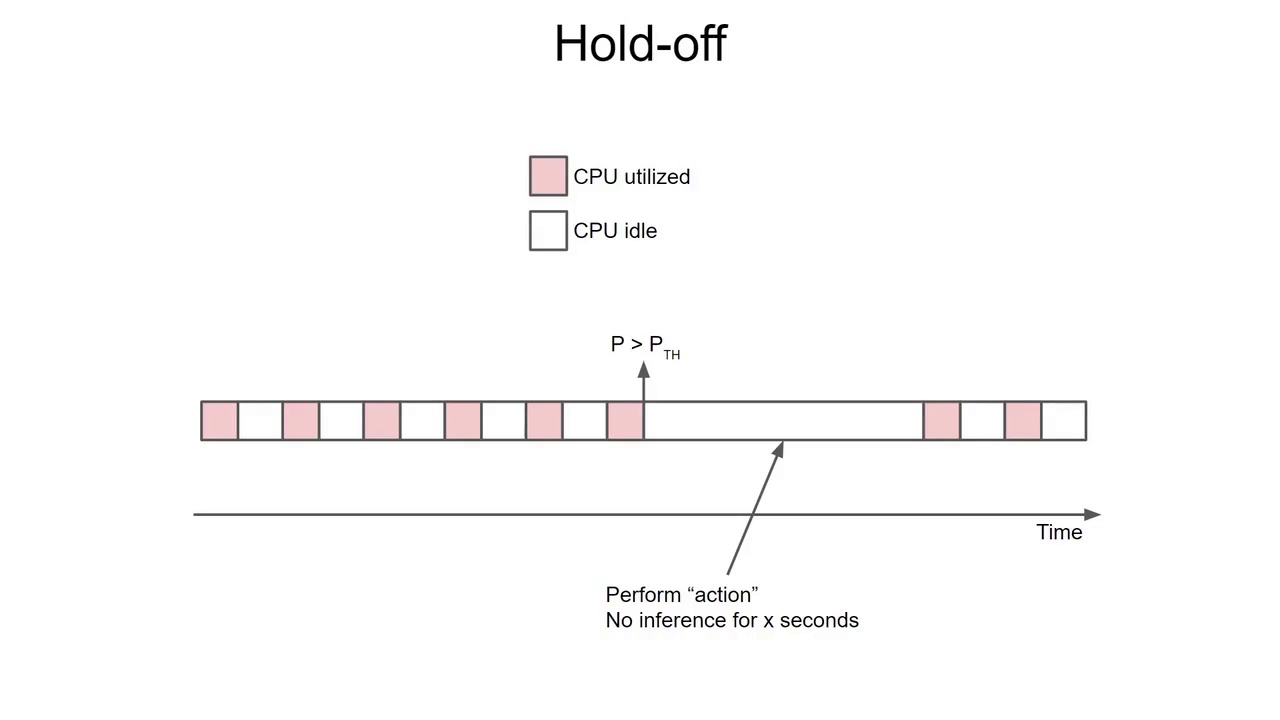
检测到事件后:
-
暂停推理(继续检测唤醒词)
-
执行动作
例如:
-
播放语音
-
网络通信
-
控制设备
(9:48) 缺点
暂停期间:
可能错过其他事件
(9:53) Alexa 示例
Amazon Alexa
检测到:
Alexa
后:
-
上传语音到云端
-
暂停再次唤醒检测
七、AI 协处理器思想
(10:10) 独立 MCU 负责 AI
方案:
小 MCU
负责:
-
读取传感器
-
AI 推理
主 MCU
负责:
-
主业务逻辑
-
UI
-
通信
(10:29) 通信方式
AI MCU 可以通过:
-
GPIO
-
UART
-
I2C
通知主控:
检测到了事件
(10:41) AI 协处理器趋势
未来趋势:
AI 加速器 + 主CPU
集成在同一芯片
(11:03) 苹果 M1
例如:
Apple M1
内部就包含:
-
AI 神经网络引擎
-
专门 AI 加速单元
十、后续学习路线
(15:15) Andrew Ng 机器学习课程
推荐:
Andrew Ng
课程平台:
(15:42) Keras
推荐学习:
Keras
特点:
-
高级深度学习框架
-
使用简单
-
Edge Impulse 底层使用 Keras
(16:03) Edge Impulse 社区
官方论坛:
(16:09) TinyML 社区
TinyML:
TinyML Foundation
官网:
内容:
-
线上讲座
-
研究分享
-
嵌入式AI社区
十一、AutoML(自动机器学习)
(16:45) 什么是 AutoML?
AutoML:
自动化机器学习
(16:51) Edge Impulse API
可自动完成:
-
数据收集
-
特征提取
-
模型训练
-
模型部署
(17:00) 自动化工作流
适用于:
大量设备自动更新模型
例如:
-
数百个传感器节点
-
自动重新训练
-
自动部署
十二、本节核心总结
嵌入式 AI 不只是“训练模型”
真正工程重点包括:
-
阈值设计
-
ROC/AUC分析
-
误判控制
-
输出平滑
-
CPU资源管理
-
Hold-off机制
-
AI协处理器
-
传感器融合
-
MCU部署验证
关键概念总表
| 概念 | 作用 |
|---|---|
| Threshold | 判断是否触发 |
| False Positive | 误触发 |
| False Negative | 漏检 |
| ROC | 分类器性能曲线 |
| AUC | ROC面积 |
| Moving Average | 输出平滑 |
| Hold-off | 暂停推理 |
| IMU | 惯性测量单元 |
| Sensor Fusion | 多传感器融合 |
| Kalman Filter | 经典融合算法 |
| AI Coprocessor | AI协处理器 |
| AutoML | 自动化机器学习 |

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)