【灵炼】让大模型数据集维护更简单、更高效
支持手动录入与一键导入,内置校验与标准化能力,降低维护成本,提升数据质量与管理效率,助力企业高效构建大模型数据集

汉得企业级大模型训练与管理平台(中文名灵炼,英文名H-AI TrainHub,以下简称灵炼),旨在提供企业级一站式模型训练与管理平台,覆盖数据集管理、精调、推理部署与评测等端到端能力,专注性能与安全保障,全面支撑企业 AI 模型开发与落地。
本文将系统性介绍数据集维护的核心能力,帮助用户从 0 到 1 构建符合企业级标准的数据集,实现数据质量、结构规范与管理效率的全面提升。
一、功能亮点
通过简洁直观的界面与标准化操作流程,用户可以高效完成数据集的创建与维护,在降低使用门槛的同时,显著提升数据治理能力:
- 多格式兼容
支持 Alpaca、ShareGPT、OpenAI 等主流对话数据格式 - 结构化数据定义
支持多轮对话、系统提示词、工具调用等复杂结构 - 自动校验与标准化处理
内置数据格式校验机制,保障数据质量 - 多维度统计分析
提供样本数量、数据规模、平均样本大小等关键指标
二、快速入门
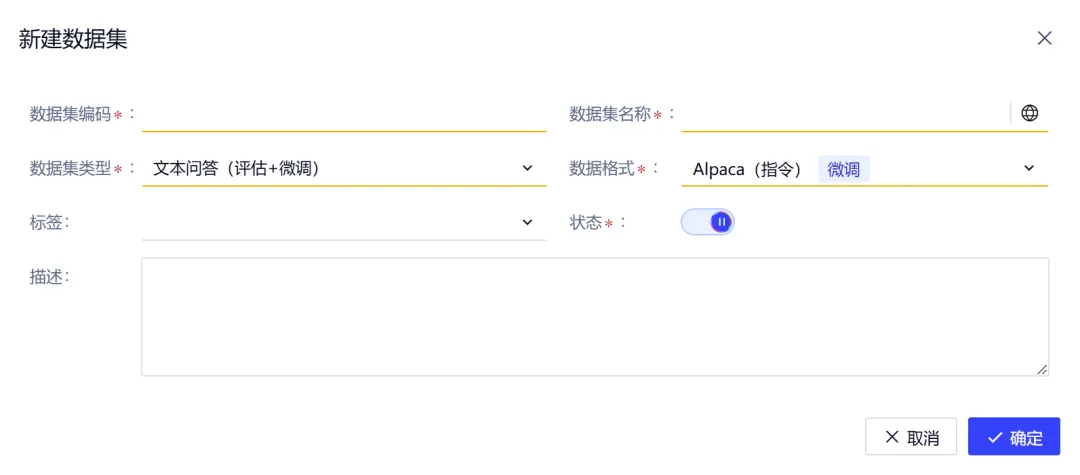
1. 新建数据集
模型管理中心/数据集管理:新建数据集
支持 Alpaca、ShareGPT、Role 等主流微调格式,高效复用开源数据集或企业内部数据资产,兼容开源与企业数据资产,一键导入、统一管理。平台将多格式抽象为标准「多轮指令-响应」结构,便于处理与训练;并扩展支持工具调用数据集,包含工具定义、函数调用与结果,助力构建具备工具能力的模型。
核心字段说明:
-
数据集类型:支持文本问答(评估+微调)及工具调用(评估+微调)
-
数据集格式:支持如下几种数据格式
- 纯文本:用于继续预训练(Pretraining)
- Alpaca:用于 SFT 微调,支持多轮对话与工具调用
- ShareGPT:用于 SFT 微调,支持复杂对话结构
- Role:用于 SFT 微调,强化角色语义表达与多轮交互
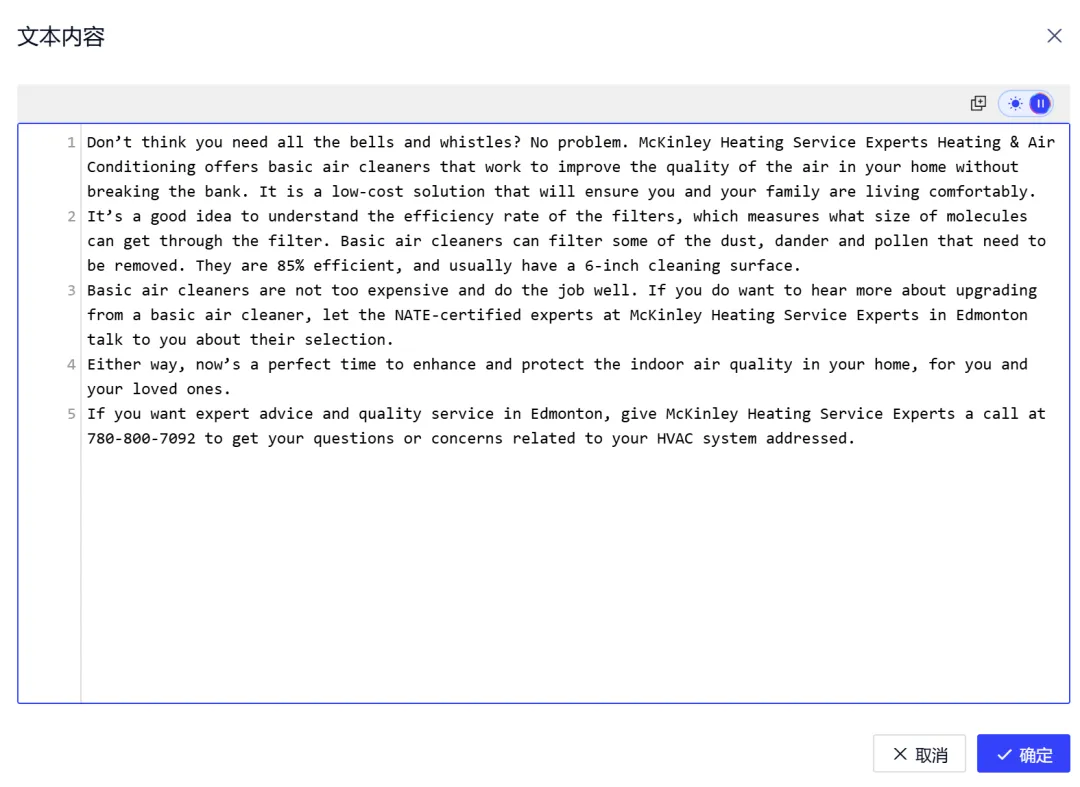
2. 手工维护数据
不同数据集类型与格式,对应的数据结构存在差异。
整体可归纳为以下三类
- 文本问答+纯文本:适用于基础语言建模与继续预训练场景,结构简单,强调语料规模与覆盖度
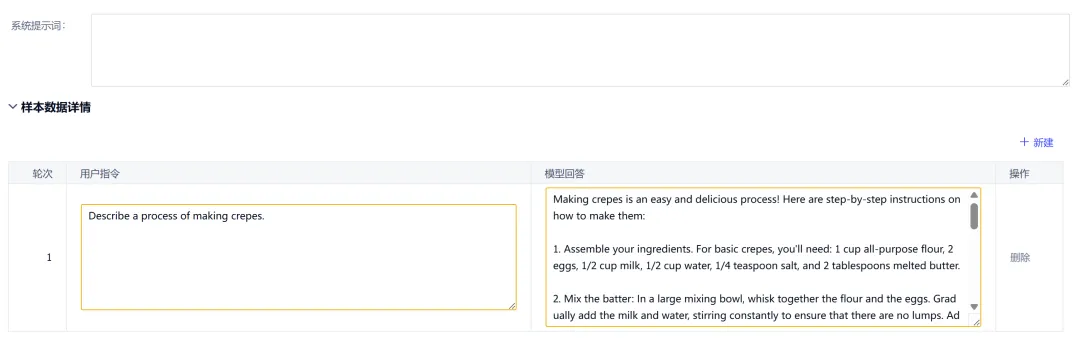
- 文本问答+ Alpaca(指令数据):面向指令微调(Instruction Tuning),采用标准的「指令-输入-输出」结构,支持多轮对话扩展
- 工具调用(评估+微调):用于训练具备工具调用能力的模型,该类数据集适用于 Agent、Function Calling 等复杂应用场景:
- 工具定义(Tools):支持定义多工具
- 函数调用(Function Call):调用与返回结果必须成对出现
3. 批量导入数据
支持通过导入功能快速构建或更新数据集,同时兼容JSON及JSONL格式,用户可通过批量导入方式高效接入已有数据资产,降低人工维护成本。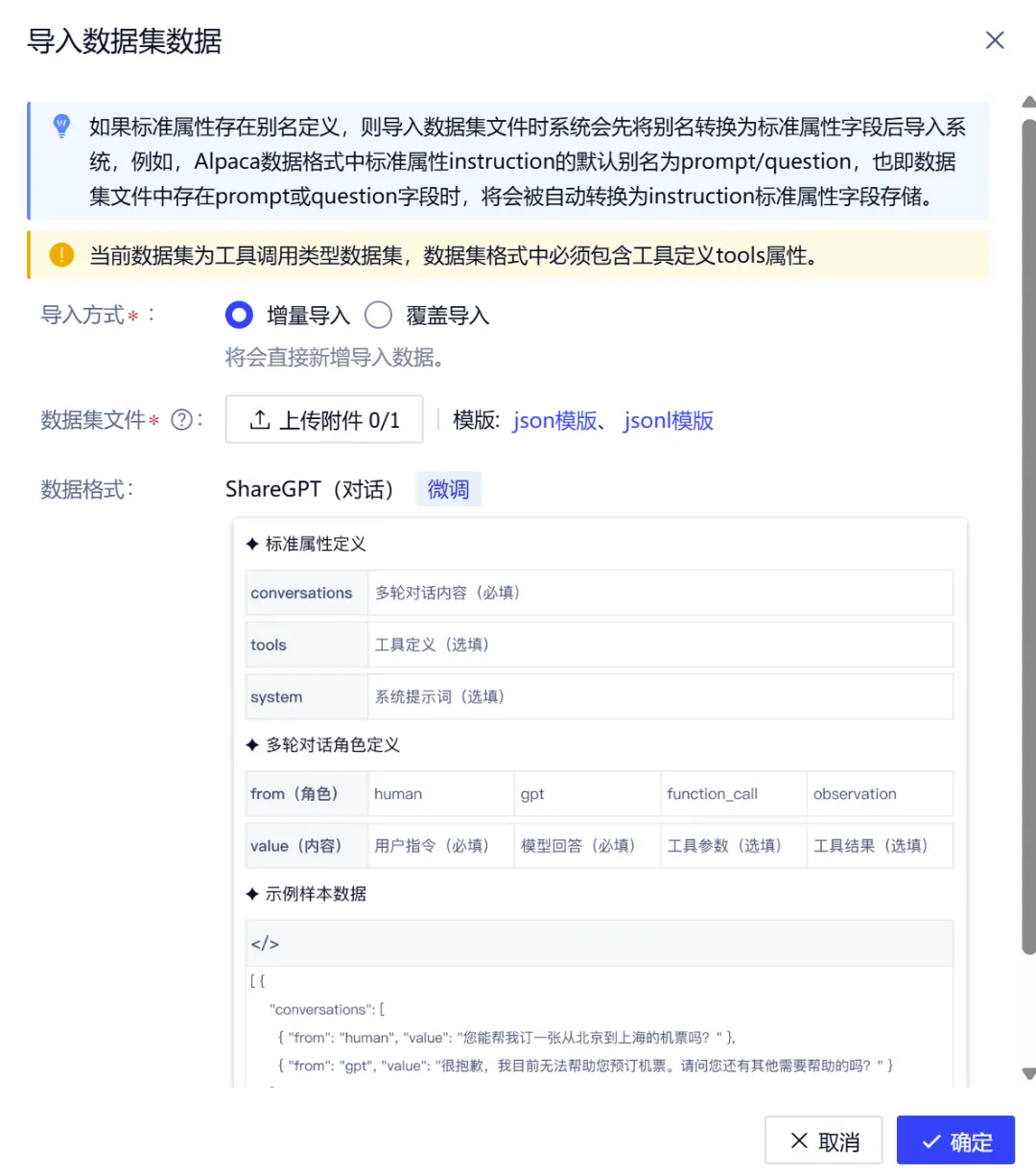
导入过程管理:系统提供完整的导入历史记录与状态跟踪能力,包括:导入状态(成功 / 失败 / 进行中)、处理进度 、错误详情定位等;对于异常数据,支持快速重试及清理后重新导入。从而实现数据问题的快速修复与闭环管理。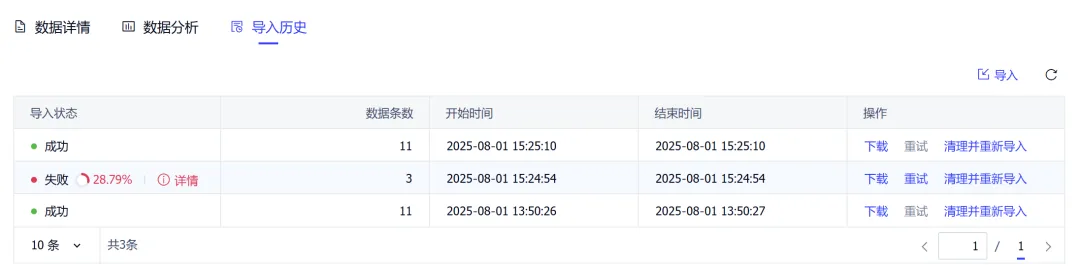
4. 数据集质量
系统基于数据集类型与格式,内置完整的校验规则体系,对数据进行自动检测与规范化处理,确保数据的一致性与可用性,从源头提升模型训练效果。 
5. 数据样本统计
平台提供多维度数据集统计信息,帮助用户快速掌握数据整体情况:包括样本总数、数据集大小、平均样本大小、创建人信息等
通过数据指标可直观评估数据集质量,为后续训练与优化提供依据。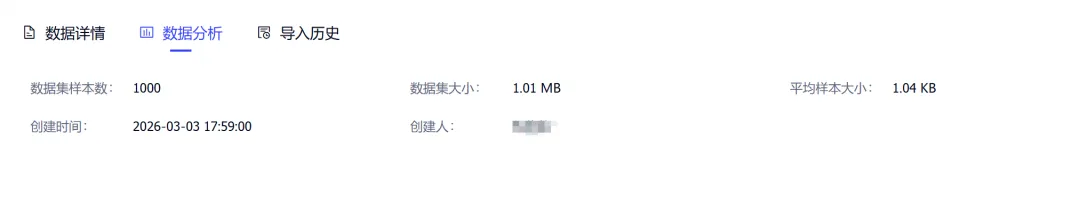
结语
以上内容主要讲解了如何通过灵炼进行数据集管理的相关能力,打造完整的数据集闭环管理。
更多功能细节可参阅开放平台文档,或随时联系研发团队。未来我们将持续迭代,为您带来更多AI模型开发与落地体验,期待与您交流!
💬 欢迎在评论区留言,一起探讨AI模型开发在您业务中的应用潜力~
联系我们
- 如果您想了解灵炼更详细的功能介绍和产品信息,可以查阅我们的产品文档
请在PC端打开 ➡️汉得焱牛开放平台
【文档>技术产品>汉得灵炼大模型训练与管理平台】 - 相关产品咨询或更多信息了解,欢迎联系我们
邮箱 ➡️ openhand@vip.hand-china.com - 试用灵炼期间,若您有任何问题需要咨询,都可前往焱牛开放平台(open.hand-china.com)提反馈,或将疑问发往联系邮箱。我们有专业人员针对您的问题进行解决回复,技术精良的研发团队根据您的反馈进行应用优化。期待您的反馈,我们将用心对待每一份回应~

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)