“记忆系统”作为实现“懂你的Agent”的必备工程模块
摘要: 大模型的记忆系统并非简单存储对话,而是按保留时间(短期/长期)和信息形态(语义/情节)两条维度设计。短期记忆维持会话连续性,长期记忆沉淀稳定事实;语义记忆抽象为可复用知识,情节记忆记录具体事件。工程难点在于筛选有价值信息并适时遗忘,而非单纯存储。技术实现上,Redis适合短期记忆,PostgreSQL管理结构化语义记忆,Vector DB处理非结构化语义记忆。成熟系统需分层设计,确保记忆协
大模型为什么需要“记忆系统”?从短期、长期到语义、情节,一次讲透 Memory 设计
全文概览: 大模型的“记忆”并不是把所有对话原封不动存起来,而是把信息按两条轴来设计:保留多久,以及以什么形式保留。理解了这件事,你就能看清 短期记忆、长期记忆、语义记忆、情节记忆 并不是四个互斥的盒子,而是一套协同工作的系统;同时也会明白,工程上最难的问题从来不是“存哪”,而是“什么值得记住,什么必须忘掉”。
先说结论:记忆系统的核心,不是存储,而是“选择”
一开始做大模型应用时,最自然的想法是:
把历史对话全存起来,需要时再查出来。
这当然能工作,但很快会撞上几个现实问题:
- 上下文会爆炸:历史太长,提示词(Prompt)塞不下。
- 噪声会累积:很多内容只对当时有用,过后就是干扰。
- 检索会失真:存得越多,不代表找得越准。
- 成本会升高:存储、检索、推理都会变贵。
- 合规风险会上升:隐私、敏感信息、未经确认的推断都可能被错误沉淀。
所以,真正成熟的记忆系统,做的不是“归档聊天记录”,而是完成五件事:
- 捕获:从交互中识别有价值的信息
- 抽象:把原话变成可复用的知识或事件
- 检索:在需要时把对的信息找回来
- 更新:旧记忆可以被修正、覆盖或合并
- 遗忘:不重要、过时或高风险的信息要主动清理
从这个角度看,Memory 更像一个“认知层”,而不是一个简单数据库。
四类记忆怎么理解?关键在于:它们其实是“两条维度”
“短期记忆、长期记忆、语义记忆、情节记忆”经常被并列提起,但更准确的理解是:
- 短期 / 长期:是按时间跨度划分
- 语义 / 情节:是按信息形态划分
也就是说,这不是四个互斥桶,而是一个二维坐标系。
维度一:按“保留多久”分
| 类型 | 它回答的问题 | 典型内容 |
|---|---|---|
| 短期记忆(Short-term Memory) | “这次对话里刚刚发生了什么?” | 最近几轮消息、当前任务状态、临时条件 |
| 长期记忆(Long-term Memory) | “这个用户长期是什么样的人?” | 稳定偏好、长期约束、重要历史摘要 |
维度二:按“信息长什么样”分
| 类型 | 它回答的问题 | 典型内容 |
|---|---|---|
| 语义记忆(Semantic Memory) | “能被抽象成事实的是什么?” | 偏好、规则、标签、画像、已确认倾向 |
| 情节记忆(Episodic Memory) | “具体发生过什么事件?” | 某次投诉、某次购买过程、某次售后经历 |
更直观一点:把它们放进同一张表里
| 组合 | 例子 |
|---|---|
| 短期 + 情节 | “刚才你让我比较 A 套餐和 B 套餐” |
| 短期 + 语义 | “本轮需求是预算控制在 500 元以内” |
| 长期 + 语义 | “用户偏好简洁回复,联系渠道优先邮件,不接受周末电话” |
| 长期 + 情节 | “2024-06-10 用户投诉物流延迟,对时效较敏感” |
这张表非常重要。它解释了一个常见误区:
语义记忆和情节记忆,并不只存在于长期记忆中;短期记忆里也可能同时包含语义片段和情节片段。
为什么大模型不能只靠上下文窗口?
很多人会把“上下文窗口”当作记忆。但严格说,它更接近工作记忆(Working Memory,正在脑中暂时处理的信息)。
比如你在和助手连续对话:
- 先说:“帮我比较 A 套餐和 B 套餐”
- 再问:“那哪个更适合我?”
这里的“那”之所以能被理解,是因为前面的信息还在当前上下文里。
这是一种临时可见性,不是稳定记忆。
一旦会话结束、上下文丢失、或者消息太长被截断,这部分信息就没了。
所以:
- 上下文窗口:像桌面,放当前正在用的东西
- 短期记忆:像工作台抽屉,能在当前任务期间随时拿出来
- 长期记忆:像档案室,跨天、跨周、跨会话还能找回来
一个能连续服务用户的系统,不能只靠“桌面”。
一、短期记忆:保证“这段对话像同一个人在交流”
短期记忆到底保存什么?
短期记忆的任务很单纯:维持当前会话的连续性。
它通常保存:
- 最近几轮对话
- 当前流程状态
- 本轮提到的临时条件
- 当前槽位信息(Slot,任务执行时填入的关键字段)
- 中间推理结果或工具调用状态
例如:
- 用户说“帮我比较 A 套餐和 B 套餐”
- 后面问“那哪个更适合我?”
这里的“那”依赖当前上下文。
如果系统忘了前面在比较什么,回答就会立刻失真。
短期记忆的工程特征
短期记忆通常有四个典型特点:
-
生命周期短
常以分钟、小时或一次会话为单位存在。 -
读写频繁
几乎每轮对话都会读,也可能每轮都更新。 -
按 session(一次会话)维度管理
不同会话互不污染。 -
允许过期
任务结束后,很多内容就没有保存价值了。
为什么 Redis 很适合短期记忆?
Redis(内存型键值数据库) 适合短期记忆,原因很直接:
- 低延迟:读写快,适合每轮都访问
- 天然支持 TTL(到期自动删除)
- 按 key 组织 session 状态很方便
- 适合高并发场景
常见放法包括:
- 最近 N 轮消息
- 当前流程状态
- 临时槽位信息
- 工具执行结果缓存
一句话理解: Redis 不是“更聪明的记忆”,而是“更快的当前状态板”。
短期记忆的一个隐患:越存越乱
如果你把每轮消息全塞进短期记忆,又从不做裁剪,就会出现:
- 冗余信息过多
- 相同意图重复出现
- 模型注意力被无关内容分散
因此,短期记忆也需要“轻量总结”。
例如保留最近 N 轮原文 + 一条会话摘要,通常比单纯堆消息更稳。
二、长期记忆:不是存“所有历史”,而是沉淀“稳定事实”
长期记忆的真正作用
长期记忆负责解决一个问题:
下次再见到这个用户时,我应该知道什么?
它保存的不是每一句说过的话,而是那些跨会话仍然有价值的信息,例如:
- 用户偏好
- 稳定约束
- 长期背景
- 高价值历史事件摘要
比如:
- 喜欢简洁回答
- 周末不要电话联系
- 常买高端商务舱
- 喜欢美式咖啡
这些都不是“一次性状态”,而是会持续影响未来服务的内容。
为什么不能把所有对话都存进长期记忆?
因为长期记忆不是日志系统。
如果它变成“永久聊天仓库”,会出现三个问题:
1. 记忆污染
像“我今天有点烦”“我现在在地铁上”这类信息,过几小时就失效了。
把它们长期保存,只会制造噪声。
2. 事实冲突
用户可能今天喜欢 A,三个月后改喜欢 B。
如果没有更新机制,只会让系统同时记住互相矛盾的偏好。
3. 检索失真
长期记忆越杂,召回的“相关信息”越可能只是表面相似,而非当前真正有用。
所以,长期记忆的关键能力不是“存”,而是筛选、归纳、压缩、更新。
三、语义记忆:把交互抽象成“可复用的知识点”
什么是语义记忆?
语义记忆(Semantic Memory,抽象事实型记忆) 保存的是能脱离具体场景复用的知识。
例如这句话:
“用户偏好:客服回复简洁,联系渠道优先邮件,不接受周末电话。”
这不是一次事件本身,而是从多次交互中抽出来的稳定事实。
它像是一张“用户认知卡片”。
语义记忆有什么特点?
- 更像知识点
- 不一定保留原话
- 强调“抽象后的结论”
- 适合跨场景复用
典型内容包括:
- 用户偏好
- 已确认的产品倾向
- 稳定业务约束
- 常见问题历史中的规律性信息
一个容易被误解的点:语义记忆 ≠ 一定要放向量库
很多人一提“语义”,就立刻想到 向量数据库(Vector DB,把文本转成数学向量后做相似搜索的存储系统)。
但这并不完全对。
更准确的说法是:
结构化语义记忆
适合放在 PostgreSQL(关系型数据库) 里,例如:
- preferred_channel = email
- response_style = concise
- no_call_on_weekends = true
这种信息:
- 字段清晰
- 查询稳定
- 易审计
- 易更新
- 适合作为“主数据(系统内最可信的标准记录)”
非结构化语义记忆
适合放在 Vector DB 或 pgvector(PostgreSQL 的向量扩展) 里,例如:
- “用户对物流时效敏感”
- “更关注售后而非价格”
- “近几次咨询都偏向家庭场景产品”
这种信息难以完全规整成字段,但又值得在相似场景下被召回。
关键结论: 语义记忆的本质是“抽象事实”,不是“向量格式”。
它可以结构化,也可以非结构化;存哪,取决于检索方式和治理需求。
四、情节记忆:保存“曾经具体发生过什么”
什么是情节记忆?
情节记忆(Episodic Memory,事件型记忆) 保存的是一次具体发生过的事情。
它通常包含:
- 时间
- 场景
- 参与对象
- 事件经过
- 结果或影响
例如:
“2024-06-10 用户反馈物流延迟,对时效较敏感。”
这里既有时间,也有事件背景。
它不是抽象偏好,而是一段历史经历。
情节记忆为什么重要?
因为很多服务质量,不靠“画像字段”提升,而靠“理解这个用户经历过什么”。
比如:
- 某次投诉是否已解决
- 某次售后是否失败
- 某次购买中出现过什么摩擦
- 某类问题是否反复发生
这些都会直接影响下一次响应方式。
一个知道“用户曾投诉物流慢”的系统,和一个只知道“该用户标签=高价值客户”的系统,服务表现完全不同。
情节记忆的难点:不能无限积累
情节记忆非常有用,但也最容易膨胀。
因为事件天然比偏好更长、更杂、更带细节。
因此它通常需要:
- 时间戳
- 重要性评分
- 状态字段(已解决 / 未解决)
- 过期策略
- 摘要压缩
例如:
- 原始事件保留 90 天
- 之后压缩成一句长期摘要
- 如果事件已解决,优先降权
- 如果同类事件重复发生,合并为趋势信息
这就是“从情节走向语义”的过程。
五、把四类记忆串起来:它们在系统里到底如何协作?
理解这四类记忆后,可以用一句话概括它们的关系:
短期记忆负责当前连续性,长期记忆负责跨会话稳定性;语义记忆负责抽象复用,情节记忆负责事件追溯。
它们在工程上常常是协同存在的:
- 当前会话中保留“最近几轮对话” → 短期
- 把“本轮预算 500 元”作为临时条件 → 短期语义
- 把“偏好简洁回复”写入画像 → 长期语义
- 把“曾投诉物流慢”写成事件摘要 → 长期情节
这也是为什么成熟系统通常不是一个库解决全部问题,而是分层设计。
六、技术选型:Redis、PostgreSQL、Vector DB 各管什么?
一张表看懂三类存储
| 存储层 | 最适合放什么 | 核心优势 | 不适合放什么 |
|---|---|---|---|
| Redis | 当前会话状态、最近 N 轮消息、临时槽位 | 低延迟、TTL、适合高频读写 | 长期画像、复杂审计 |
| PostgreSQL | 结构化用户画像、稳定偏好、联系限制、标签、等级 | 强一致、结构清晰、易查询、易治理 | 大规模语义相似检索 |
| Vector DB / pgvector | 历史摘要、偏好片段、事件摘要、模糊召回片段 | 语义相似搜索强,不依赖精确关键词 | 需要严格字段约束的主数据 |
1. Redis:会话状态层
Redis 很适合存:
- 最近 N 轮消息
- 当前流程状态
- 临时槽位信息
- 本轮工具调用结果
- 到期自动删除的 session 数据
如果只是快速原型和验证,Redis 足够好用。
它让系统“记得刚刚发生了什么”。
2. PostgreSQL:长期主数据层
PostgreSQL 适合存:
- 用户偏好字段
- 联系限制
- 常用渠道
- 标签、等级、客户状态
- 可审计、可事务更新的画像信息
它的价值不在“智能”,而在“可靠”。
如果你问:
用户到底是否接受周末电话?
这个问题不应该交给向量检索“猜”,而应该由 PostgreSQL 里的结构化字段回答。
3. Vector DB / pgvector:模糊召回层
向量数据库适合存:
- 历史对话摘要
- 偏好片段
- 情节记忆摘要
- 跨表达方式的相关历史
例如用户曾说:
- “别打我手机,邮件就行”
- “电话不方便,发邮箱吧”
- “请尽量用邮件联系”
虽然说法不同,但向量检索能把它们视为语义相近。
这就是它的优势。
如果你处于开发和验证阶段,pgvector 是很实用的选择:
一方面保留 PostgreSQL 的治理能力,另一方面获得基础向量检索能力,架构上更轻。
七、最关键的问题:什么该写入长期记忆?
这是所有 Memory 设计里最核心的一步。
不是“能提取到什么”,而是“什么值得沉淀”。
建议写入长期记忆的 4 类信息
1. 稳定偏好
这类信息会持续影响交互体验。
例如:
- 喜欢简洁回答
- 喜欢邮件联系
- 偏爱某类产品
2. 长期约束
这类信息会持续限制系统行为。
例如:
- 周末不要打电话
- 不接受高风险产品
- 预算区间长期明确
3. 稳定背景
这类信息有明确业务价值,而且相对稳定。
例如:
- 行业 / 职位
- 常用场景
- 家庭结构(前提是明确、必要、合规)
4. 重要事件摘要
不是存整段原文,而是存对未来服务有用的“事件结论”。
例如:
- 曾投诉物流慢
- 上次售后未解决
- 某类问题反复发生
八、什么不该写入长期记忆?
一个好的系统,记得住很重要;
但知道什么不该记,更重要。
1. 瞬时情绪
例如:
- “我今天有点烦”
- “刚下班很累”
除非你的业务场景就是心理支持或情绪照护,否则这类信息通常不值得长期沉淀。
2. 一次性上下文
例如:
- “我现在在地铁上”
- “今晚开会”
这类内容是典型短期记忆,不应长期保存。
3. 未确认猜测
例如:
- 模型自己推断出的用户偏好
- 没有明确表达的标签
- 基于少量样本得出的高风险归类
这是实际生产中非常危险的一类错误。
模型推断 ≠ 用户事实。
4. 过于敏感且无授权的信息
例如:
- 身份证、银行卡
- 医疗隐私
- 非业务必需的敏感信息
这里不仅是工程问题,更是合规问题。
记忆系统必须服从最小必要原则:不是能存就该存,而是必须有业务必要性、用户授权和治理能力。
九、写回策略:逐轮提取,还是会话后总结?
长期记忆最大的挑战不是读取,而是写回(Write-back,把信息沉淀到长期存储)。
常见有两种策略。
策略 A:逐轮轻量提取
每轮对话后,都判断是否有值得沉淀的信息。
优点
- 实时性高
- 新偏好能快速生效
- 适合客服、助理类场景
缺点
- 容易碎片化
- 容易膨胀
- 容易把一时信息误存成长期事实
策略 B:会话结束总结
在会话结束或空闲一段时间后,再做一次统一摘要并写回。
优点
- 更稳定
- 更利于压缩
- 更适合事件级总结
缺点
- 延迟较高
- 会话中途难以及时利用新偏好
生产实践中更稳的方案:A + B 组合
这通常是最实用的做法:
- 逐轮提取:只提取高价值、低歧义的偏好与约束
- 会话总结:对整段历史做情节摘要
- 定期压缩:把老记忆合并成周度或月度摘要
换句话说:
- “喜好邮件联系”这类信息,可以尽快生效
- “本次售后过程很曲折”这类信息,更适合会后总结
十、Memory Judge:真正决定系统“记性好不好”的组件
在完整架构里,最好有一个专门的 Memory Judge(记忆裁决器)。
它的职责是:决定这条信息该不该写、写成什么、写到哪、保留多久。
一个成熟的 Judge 通常会看四个维度:
1. 稳定性
这是长期偏好,还是一次性表达?
2. 明确性
这是用户明确说的,还是模型猜的?
3. 业务价值
这条信息会不会影响未来响应、推荐或服务动作?
4. 敏感性
是否涉及高风险或需授权的信息?
如果想更工程化一点,可以给每条候选记忆打分,例如:
- importance(重要性)
- confidence(置信度)
- stability(稳定性)
- sensitivity(敏感度)
- expiry_at(过期时间)
这样系统就不会“看到一点信息就想永久记住”。
十一、防止记忆无限膨胀的 5 个办法
1. 设置写入门槛
例如:
- importance < 0.65 不写入
- 或者必须满足“明确表达 + 有业务价值”才允许落库
这能挡掉大量噪声。
2. 去重
新记忆写入前,先查相似记忆;如果相似度过高,就不要重复保存。
这一步对向量记忆尤其重要。
否则同一偏好会被存成十几条近义表达。
3. 过期
不同信息要有不同寿命:
- 临时意图:30 天过期
- 投诉事件:90 天后转摘要
- 稳定偏好:不过期,但允许更新
“不过期”不等于“永远不检查”。
真正稳的系统会给长期偏好增加 last_verified_at(最近确认时间)。
4. 压缩
老对话不要一直保留原文。
应该逐步压缩成:
- 会话摘要
- 事件摘要
- 趋势摘要
压缩的本质,是把“文本历史”变成“认知资产”。
5. 分层
让不同类型的信息待在不同层里:
- Redis:只保当前会话
- PostgreSQL:只保结构化画像
- Vector DB:只保高价值摘要
分层能减少混乱,也更方便治理。
十二、一个常被忽视的深层问题:记忆和知识库不是一回事
在大模型系统里,很多人会把 RAG 知识库(检索增强生成) 和 用户记忆系统 混在一起。
但两者关注的问题完全不同:
知识库回答的是:
- 世界上有什么事实?
- 产品规则是什么?
- 文档怎么写?
- 流程规范是什么?
记忆系统回答的是:
- 这个用户是谁?
- 他过去发生过什么?
- 他偏好什么表达方式?
- 我这次服务要避开什么坑?
可以把它们理解为:
- 知识库:关于“世界”的外部知识
- 记忆系统:关于“这个用户与这段关系”的内部知识
一个系统可以知识很丰富,但如果不记得你曾投诉过物流,它依然会显得“没有连续性”。
十三、整体架构:一条完整的 Memory 数据流
下面这条链路,基本概括了记忆系统在实际应用中的典型工作方式:
用户消息
↓
Redis 读取短期会话
↓
PostgreSQL 读取用户画像
↓
Vector DB 检索相关历史语义/情节记忆
↓
LLM 生成回答
↓
Memory Judge 判断是否写回长期记忆
├─ 更新 PostgreSQL 用户画像
└─ 写入 Vector DB 语义/情节摘要
↓
Redis 更新当前会话状态
这条链路背后的逻辑是什么?
第一步:先拿当前上下文
从 Redis 取出最近几轮消息、当前任务状态、临时槽位。
这是回答“这轮正在干什么”的基础。
第二步:再拿用户画像
从 PostgreSQL 取出结构化偏好、约束、等级、联系规则。
这是回答“这个用户长期是什么样的人”的基础。
第三步:补充历史相关片段
从 Vector DB 中检索语义相关的旧摘要或事件。
这是回答“过去有没有类似情况”的基础。
第四步:让 LLM 生成响应
模型在“当前上下文 + 长期画像 + 历史相关记忆”的综合输入上作答。
这样回答才既连贯,又个性化。
第五步:判断是否沉淀新记忆
不是每轮都写,也不是什么都写。
由 Memory Judge 做筛选、去重、脱敏、归类、落库。
这一层,决定了系统会越来越聪明,还是越来越混乱。
十四、实测结果
用户画像
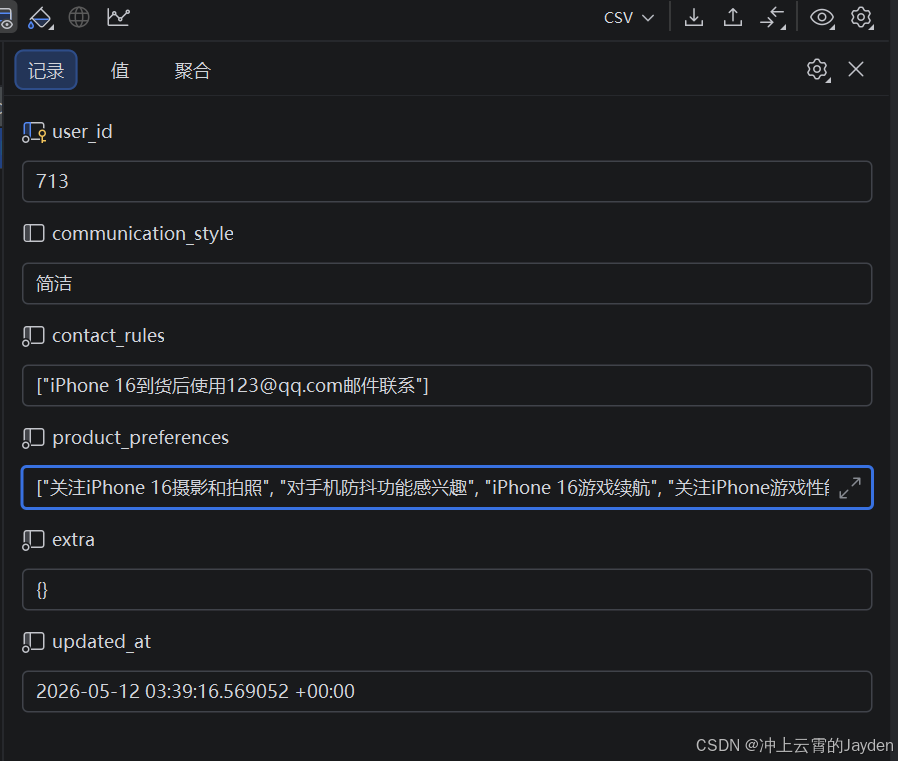
produce_preferences:
[
"关注iPhone 16摄影和拍照",
"对手机防抖功能感兴趣",
"iPhone 16游戏续航",
"关注iPhone游戏性能",
"iPhone 16",
"对三星手机感兴趣",
"关注手机拍照效果",
"关注手机视频录制能力",
"对三星 Galaxy S24 Ultra 感兴趣",
"手机预算7000-12000元",
"感兴趣三星 Galaxy S24 Ultra",
"关注手机游戏性能",
"关注手机拍照和长焦能力",
"关注长焦摄影能力",
"关注游戏性能",
"预算范围7000-12000元"
]
用户语义数据
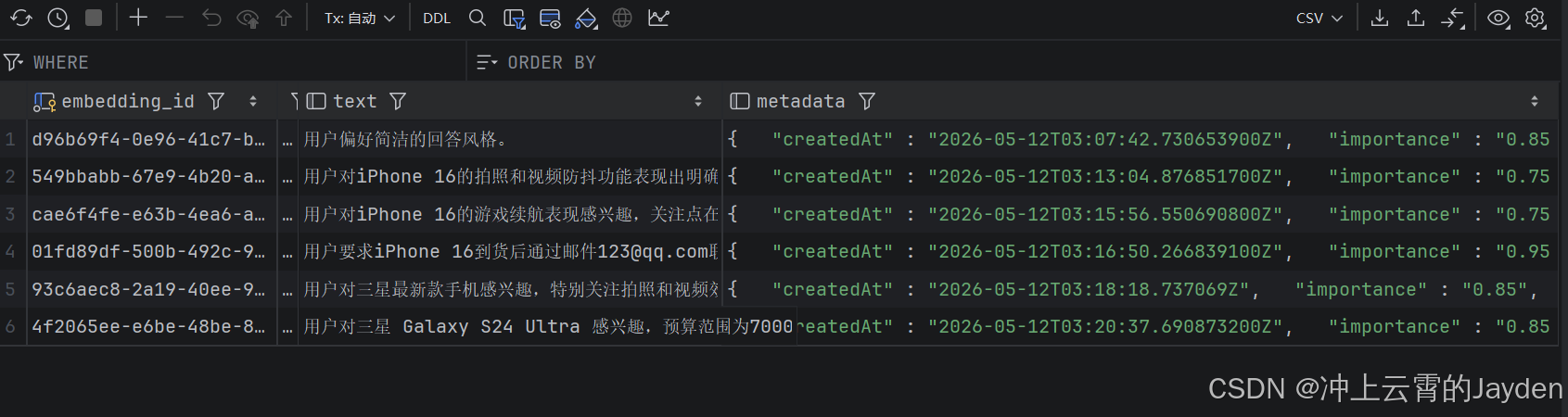
用户问题
问:三星 Galaxy S24 Ultra 有什么优点
答:
三星 Galaxy S24 Ultra 有什么优点
answer:
三星 Galaxy S24 Ultra 的核心优势如下:
* **影像全能(长焦最强)**
* **2亿像素主摄**:细节解析力极高,支持高倍无损裁剪。
* **双长焦系统**:3倍 +5倍潜望长焦组合,远摄画质行业领先,完美契合您对“长焦能力”的关注。
* **视频防抖**:Super Steady 模式提供极致的运动防抖效果。
* **性能与游戏**
* **骁龙 8 Gen 3**:旗舰级性能,大型游戏运行流畅,散热优化出色,满足您对“游戏性能”的需求。
* **抗反射屏幕**:户外可视性极佳,色彩还原准确。
* **独家生产力**
* **内置 S Pen**:手写、绘图、遥控拍照,安卓阵营独有。
* **Galaxy AI**:实时翻译、智能修图、笔记摘要等功能实用。
* **耐用保障**
* **钛金属边框**:坚固且轻量化。
* **7年系统更新**:长期使用无忧。
**总结**:该机型在**长焦摄影、视频防抖及游戏性能**上表现顶尖,完全符合您的预算(7000-12000元)及核心需求。
LLM的答案已经重点放在用户画像produce_preferences记录的摄影、游戏。
十五、几个高频误区,很多系统都踩过
误区 1:把所有历史都塞向量库
向量库擅长“相似召回”,不擅长当权威事实表。
“用户不接受周末电话”这类规则,应该有结构化真值,而不是只存成一段 embedding(向量表示)。
误区 2:把模型推断当用户事实
比如用户说过两次咖啡,系统就永久打上“咖啡爱好者”标签。
这会造成事实幻觉。
更稳的做法是区分:
- 明确表达
- 高概率推断
- 未经确认猜测
这三者的存储策略应完全不同。
误区 3:只会写入,不会更新
偏好会变,约束会变,用户阶段也会变。
长期记忆一定要支持:
- 覆盖
- 合并
- 版本管理
- 最近确认时间
否则旧偏好会像系统里的“认知僵尸”一样长期存在。
误区 4:只有记忆,没有遗忘
遗忘不是缺陷,而是能力。
没有遗忘机制的系统,最终会被旧噪声拖垮。
误区 5:忽略隐私治理
记忆系统天然比一般缓存更敏感,因为它会跨时间保留用户痕迹。
因此必须考虑:
- 用户授权
- 最小必要原则
- 可删除
- 可审计
- 可追溯
结语:好的记忆系统,不是“记得多”,而是“记得准、忘得对”
如果用一句话总结 Memory 设计的本质,那就是:
让系统记住真正会影响未来服务的内容,并有能力忘掉其余内容。
从工程上看,最稳的设计通常是:
- 用 Redis 维护当前会话连续性
- 用 PostgreSQL 管理结构化长期画像
- 用 Vector DB / pgvector 做高价值历史摘要的语义召回
- 用 Memory Judge 控制写回、去重、过期、压缩与合规
而从认知上看,你其实是在给大模型补上一种关键能力:
它不仅能“回答问题”,还能逐渐形成对用户的持续理解。
这也是记忆系统真正的价值——
不是让模型看起来像记住了什么,而是让它在下一次相遇时,真的更懂你。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 4
4 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)