Spring AI RAG 检索增强生成:概念、实战与完整代码
本文介绍了基于SpringAI和Ollama实现检索增强生成(RAG)的技术方案。RAG通过"外部知识检索+大模型生成"的方式,解决了LLM知识滞后和幻觉问题。文章详细讲解了RAG的四步流程:文档加载分块、向量化存储、语义检索和增强生成,并提供了完整的SpringAI实现代码示例。系统采用SimpleVectorStore作为内存向量库,结合TikaDocumentReader
场景
Spring AI ChatMemory 对话记忆配置JDBC方式到Mysql数据库实战示例与原理讲解:
https://blog.csdn.net/BADAO_LIUMANG_QIZHI/article/details/161040572
基于上述基础,学习RAG的使用。
大语言模型(LLM)存在知识滞后、易产生幻觉、领域知识不足等局限性。
检索增强生成(Retrieval Augmented Generation,RAG)技术通过“外部知识检索 + LLM生成”的模式,
在回答问题前先从外部知识源中查找相关信息,再结合自身能力组织语言输出,有效弥补了这些缺陷。
本文将基于之前的 Spring AI 1.1.2 + Ollama 技术栈,系统性地介绍 RAG 的核心概念、Spring AI 中的实现方式,
并提供可直接运行的完整实例代码。
一、RAG 核心概念与工作流程
1.1 什么是 RAG?
RAG 技术的核心在于将检索与生成相结合。传统的生成模型依赖训练数据来生成回答,
当面对新问题或新兴领域知识时,可能产生不准确或不合逻辑的回答。
RAG 引入检索机制,在接收到用户问题后,首先从外部知识库中检索相关信息,
然后将其与原始问题一同输入给生成模型,从而产生更准确、上下文相关的答案。
1.2 RAG 四步流程
| 步骤 | 说明 | 关键技术 |
|---|---|---|
| ① 文档加载与分块(Ingestion) | 将原始文档(PDF、TXT 等)加载进来,切割成适合嵌入的小片段(chunks) | DocumentReader、TokenTextSplitter |
| ② 向量化与存储(Embedding & Store) | 用 Embedding 模型将文本片段转换为高维向量,存入向量数据库 | EmbeddingModel、VectorStore |
| ③ 语义检索(Retrieval) | 用户提问时,将问题同样向量化,在数据库中执行相似度搜索,检索最相关片段 | SearchRequest、相似度计算 |
| ④ 增强生成(Generation) | 将检索到的相关文档片段作为上下文,与用户问题一起提交给 LLM,生成精准回答 | ChatClient + PromptTemplate |
1.3 向量数据库
向量数据库专门用于存储、管理和高效检索高维向量数据。
其核心优势是支持语义级搜索——例如“苹果手机”和“iPhone”虽关键词不同,但语义相近,其向量距离很小,可被精准匹配到。
Spring AI 通过 VectorStore 接口抽象了向量数据库的访问,支持多种实现:
SimpleVectorStore(内存向量库,适合原型开发)
Elasticsearch
PgVector
Milvus / Weaviate / Chroma 等
1.4 关键组件依赖关系
| 组件 | 角色 | Spring AI 接口 |
|---|---|---|
Document |
表示原始文档及其元数据 | org.springframework.ai.document.Document |
DocumentReader |
从文件系统加载文档 | JsonReader、TextReader、PagePdfDocumentReader |
TextSplitter |
将长文本切割成小块 | TokenTextSplitter |
EmbeddingModel |
将文本转换为向量 | EmbeddingModel(Ollama 提供) |
VectorStore |
存储和检索向量 | SimpleVectorStore、ElasticsearchVectorStore 等 |
QuestionAnswerAdvisor |
拦截用户请求,自动检索并注入上下文 | QuestionAnswerAdvisor.builder(vectorStore) |
二、Spring AI RAG 实现方式
Spring AI 通过 Advisor API 为 RAG 提供了开箱即用的支持,核心组件是 QuestionAnswerAdvisor。
使用时需要添加 spring-ai-advisors-vector-store 依赖
2.1 QuestionAnswerAdvisor 工作原理
当用户问题发送到 AI 模型时,QuestionAnswerAdvisor 会查询向量数据库以获取与用户问题相关的文档,
将这些文档附加到用户文本中作为上下文,然后再提交给 AI 模型生成回答。其可配置项为:
| 配置项 | 说明 | 示例 |
|---|---|---|
similarityThreshold |
相似度阈值,低于此值的文档将被过滤 | 0.8 |
topK |
返回最相关的前 K 个文档 | 6 |
FILTER_EXPRESSION |
动态过滤表达式(类似 SQL WHERE) | "type == 'Spring'" |
promptTemplate |
自定义提示词模板,控制上下文与用户问题的拼接方式 | 包含 {query} 和 {question_answer_context} 占位符 |
2.2 检索与生成分离的 ETL 模型
Spring AI RAG 遵循 ETL(Extract-Transform-Load)模型:
Extract(提取):从知识库中读取文档。
Transform(转换):将文档分割为小块,并通过 Embedding 模型转换为向量。
Load(加载):将向量数据写入向量数据库。
这三个步骤通常在应用启动时完成。
运行时,基于 ETL 模型实现真正的 RAG——用户的查询被嵌入,向量数据库被查询,检索到的文档被注入到 LLM 的提示词中。
2.3 RAG Advisor 与其他 Advisor 的组合
RAG 的 QuestionAnswerAdvisor 可以与之前介绍的 Advisor 自由组合:
| 组合方式 | 效果 |
|---|---|
QuestionAnswerAdvisor + MessageChatMemoryAdvisor |
带记忆的 RAG 问答 |
QuestionAnswerAdvisor + SensitiveWordGuardAdvisor |
安全过滤 + RAG |
QuestionAnswerAdvisor + SimpleLoggerAdvisor |
调试日志 |
| 全部组合 | 安全过滤 → 日志记录 → 对话记忆 → 文档检索 → LLM 生成 |
注:
博客:
https://blog.csdn.net/badao_liumang_qizhi
实现
以下示例基于 Spring AI 1.1.2 + Ollama + SimpleVectorStore,演示如何从零构建一个本地 RAG 知识库问答系统。
pom.xml
<properties>
<java.version>17</java.version>
<spring-ai.version>1.1.2</spring-ai.version>
</properties>
<!-- 新增:使用 Spring AI BOM 统一管理所有模块版本 -->
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>${spring-ai.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Spring AI Ollama 核心 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-ollama</artifactId>
</dependency>
<!-- RAG Advisor(核心:提供 QuestionAnswerAdvisor) -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-advisors-vector-store</artifactId>
</dependency>
<!-- Tika 文档读取器(支持 PDF、Word、TXT 等多种格式) -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-tika-document-reader</artifactId>
</dependency>
</dependencies>示例知识库文件
在src/main/resources/knowledge-base/badao-internal.txt 中创建:
Badao科技内部知识库
## 公司政策
- 员工年假:入职满1年享受10天带薪年假,满3年增加到15天。
- 远程办公:每周三、周五为固定远程办公日。
- 报销流程:所有报销需在“易报销”系统提交,金额超过500元需部门经理审批。
## 内部项目
- 项目代号“天枢”:基于Spring AI与Ollama构建的企业智能助手,负责人为张三。
- 项目代号“瑶光”:下一代实时数据湖方案,采用Apache Iceberg + Flink,负责人为李四。
- 内部编码规范:所有Java项目必须使用Lombok,禁止使用var关键字,SQL必须使用参数化查询。
## 技术选型
- 消息中间件:统一使用RocketMQ,禁止引入RabbitMQ。
- 向量数据库:生产环境采用PgVector,开发环境可使用SimpleVectorStore。
- 前端框架:统一使用React 18 + Ant Design 5.x。
## 团队联系人
- 基础架构组:赵六(zhaoliu@badao.com)
- AI组:王五(wangwu@badao.com)
- 数据组:钱七(qianqi@badao.com)application.yml
server:
port: 886
spring: # 替换为实际密码
ai:
ollama:
base-url: http://localhost:11434
chat:
model: qwen2.5:7b-instruct
options:
temperature: 0.3 # RAG 场景建议使用较低温度,减少幻觉
embedding:
model: nomic-embed-text # Embedding 模型(用于文档向量化)
options:
num-batch: 4 # 一次处理的文本数量
logging:
level:
org.springframework.ai.rag: DEBUG
org.springframework.ai.vectorstore: DEBUG
Embedding 模型下载(项目启动前执行)
ollama pull nomic-embed-text模型选型说明:
Chat 模型:
qwen2.5:7b-instruct 支持工具调用且中文能力强,适合生成自然语言回答。也可选择 deepseek-r1:8b、llama3.1:8b 等。
Embedding 模型:
nomic-embed-text 生成 768 维向量,免费且质量好。也可选择 bge-m3(1024 维)、mxbai-embed-large(1024 维)等,
但需修改配置文件中 dimensions 参数。
核心要求:
Chat 模型和 Embedding 模型都必须是 Ollama 本地已下载的模型,
且 Embedding 模型的向量维度必须与向量数据库的 dimensions 配置一致。
VectorStoreConfig — 文档加载与向量存储初始化
Spring AI 在 RAG 流程中默认不负责文档分词,文档的加载与分词需要开发者显式调用 DocumentReader 和 TextSplitter 来完成。
package com.badao.ai.config;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.ai.document.Document;
import org.springframework.ai.document.DocumentReader;
import org.springframework.ai.reader.tika.TikaDocumentReader;
import org.springframework.ai.transformer.splitter.TokenTextSplitter;
import org.springframework.ai.vectorstore.SimpleVectorStore;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.CommandLineRunner;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.Resource;
import java.util.List;
@Configuration
public class VectorStoreConfig {
private static final Logger logger = LoggerFactory.getLogger(VectorStoreConfig.class);
@Value("classpath:knowledge-base/badao-internal.txt")
private Resource knowledgeResource;
@Bean
public VectorStore vectorStore(EmbeddingModel embeddingModel) {
// 创建内存向量库(开发演示用)
return SimpleVectorStore.builder(embeddingModel).build();
}
@Bean
public CommandLineRunner loadDocuments(VectorStore vectorStore) {
return args -> {
// 1. 使用 Tika 读取文档(自动检测文件类型)
DocumentReader reader = new TikaDocumentReader(knowledgeResource);
List<Document> documents = reader.get();
logger.info("共读取到 {} 个文档", documents.size());
// 2. 文本分块(TokenTextSplitter 按语义切分,更适合中文)
TokenTextSplitter splitter = TokenTextSplitter.builder()
.withChunkSize(300) // 每个块最多 300 token
.withMinChunkSizeChars(50) // 最小块字符数,避免出现极短碎片(替代原来 minChunkSize 的功能)
.withMinChunkLengthToEmbed(5) // 保留默认,过滤极短内容
.withKeepSeparator(true) // 保留原文换行等分隔符
.build();
List<Document> chunks = splitter.apply(documents);
logger.info("文本切分为 {} 个片段", chunks.size());
// 3. 写入向量数据库(自动调用 EmbeddingModel 向量化)
vectorStore.add(chunks);
logger.info("向量化完成,向量库初始化成功!");
};
}
}要点说明:
SimpleVectorStore 是 Spring AI 内置的内存向量库实现,适合原型开发和小规模知识库(文档量不超过几千条)。
数据存在内存中,服务重启后需要重新加载,生产环境请替换为 PgVectorStore、ElasticsearchVectorStore 等持久化方案。
TokenTextSplitter 按 Token 数量切分文本,避免切断句子。chunkOverlap 设置重叠区域,保证语义连贯性,防止关键信息被切断。
TikaDocumentReader 基于 Apache Tika,可自动识别 PDF、Word、TXT、HTML 等多种文档格式,无需手动判断文件类型。
RagConfig — 注册 RAG Advisor
package com.badao.ai.config;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.vectorstore.QuestionAnswerAdvisor;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class RagConfig {
@Bean
public ChatClient chatClient(ChatModel chatModel, VectorStore vectorStore) {
return ChatClient.builder(chatModel)
.defaultAdvisors(
QuestionAnswerAdvisor.builder(vectorStore)
.searchRequest(SearchRequest.builder()
.similarityThreshold(0.7) // 相似度阈值
.topK(3) // 返回前 3 个最相关文档
.build())
.build()
)
.build();
}
}RagService
package com.badao.ai.service;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.stereotype.Service;
@Service
public class RagService {
private final ChatClient chatClient;
public RagService(ChatClient chatClient) {
this.chatClient = chatClient;
}
/**
* 基于知识库的 RAG 问答
*/
public String ask(String question) {
return chatClient.prompt()
.user(question)
.call()
.content();
}
}控制器
package com.badao.ai.controller;
import com.badao.ai.service.RagService;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("/api")
public class RagController {
private final RagService ragService;
public RagController(RagService ragService) {
this.ragService = ragService;
}
@PostMapping("/rag")
public ChatResponse rag(@RequestBody ChatRequest request) {
String result = ragService.ask(request.message());
return new ChatResponse(200, "success", result);
}
public record ChatRequest(String message) {}
public record ChatResponse(int code, String msg, String data) {}
}测试验证
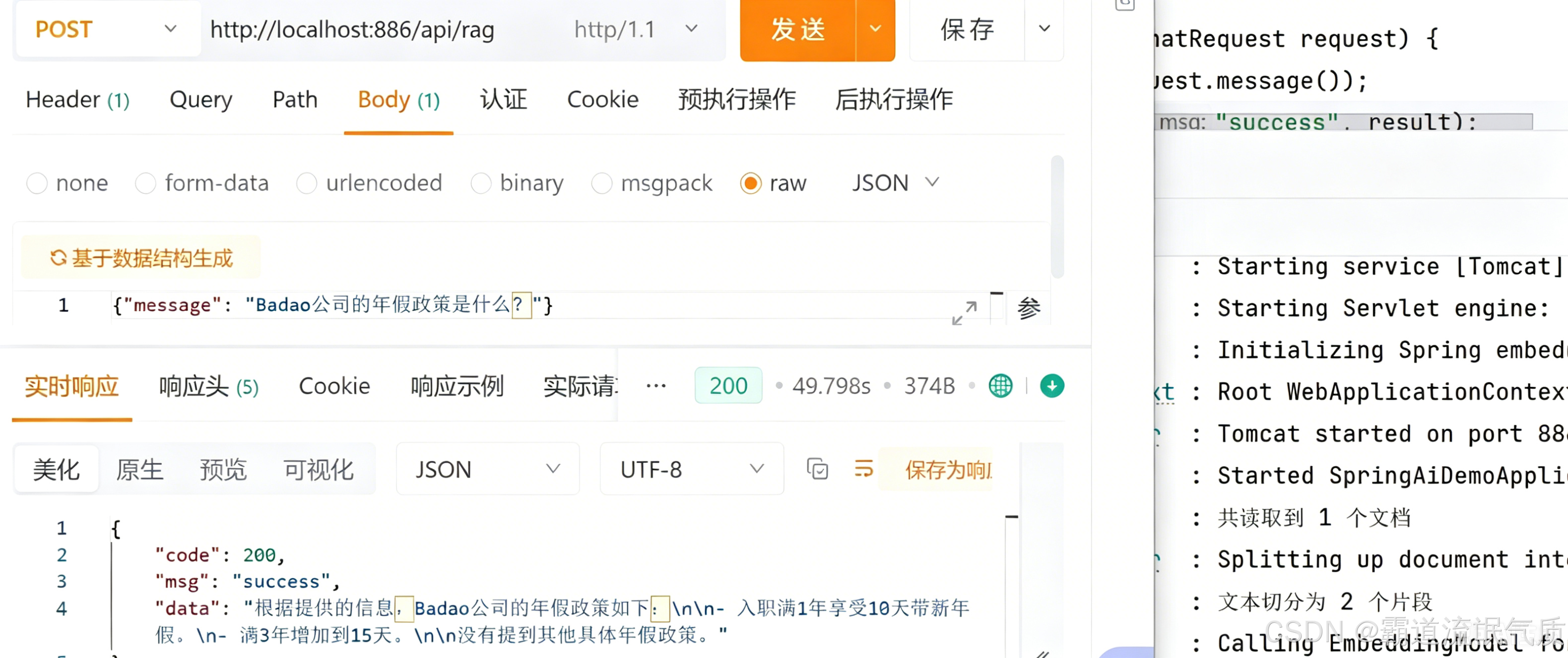
常用优化策略
| 策略 | 说明 | 配置示例 |
|---|---|---|
| 提高相似度阈值 | 相同 topK 下减少候选文档量,剔除不相关文档 |
similarityThreshold(0.8) |
| 降低相似度阈值 | 相同 topK 下增加候选文档量,适合文档量大的场景 |
similarityThreshold(0.5) |
| 控制返回数量 | topK 不宜过大,否则会超出模型上下文窗口 |
topK(3) |
| 文档分块优化 | 调整 chunkSize 和 chunkOverlap 平衡精度和召回率 |
chunkSize(300), chunkOverlap(50) |
| 动态过滤 | 按文档类型、日期等元数据过滤 | .param(QuestionAnswerAdvisor.FILTER_EXPRESSION, "type == 'manual'") |
| 自定义提示词模板 | 控制上下文与用户问题的拼接格式,提升回答质量 | 见 上文 |
总结
| 环节 | 核心组件 | 关键操作 |
|---|---|---|
| 文档加载 | TikaDocumentReader |
自动识别多种文档格式 |
| 文本分块 | TokenTextSplitter |
chunkSize(300), chunkOverlap(30) |
| 向量化 | EmbeddingModel |
Ollama 提供 nomic-embed-text 模型 |
| 向量存储 | VectorStore |
开发用 SimpleVectorStore,生产用 PgVector / Elasticsearch |
| 检索 + 生成 | QuestionAnswerAdvisor |
similarityThreshold + topK 控制检索质量 |
| 增强生成 | ChatClient |
检索结果自动注入上下文 |
RAG 技术让通用大模型能够“读懂”你的私有文档,在面对特定领域问题时给出精准答案。
结合 Spring AI 的模块化设计和 Ollama 的本地模型能力,Java 开发者可以轻松构建安全、高效、低成本的本地知识库问答系统。
本文系统地介绍了 Spring AI RAG 的核心概念与完整实现方式。关键要点回顾:

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 2
2 0
0- 0



 已为社区贡献39条内容
已为社区贡献39条内容

所有评论(0)