RAG基础知识
RAG 是什么?为什么需要 RAG?
RAG(Retrieval-Augmented Generation,检索增强生成)的本质就一句话:在 LLM 生成回答之前,先从外部知识库检索相关信息,把检索结果塞进 Prompt,让 LLM 基于事实回答。
为什么需要 RAG?
引入 RAG 主要为了解决大模型在落地应用时的几个核心痛点:
缓解幻觉问题:纯大模型容易编造不存在的规则或事实,RAG 强制模型基于检索到的真实文档回答,大幅提升准确性。
解决知识时效性:大模型的训练数据有截止日期,RAG 可以随时接入最新的业务文档或数据库,无需重新训练模型即可获取最新知识。
接入私有数据:企业内部的私有数据无法用于训练公开的大模型,RAG 能让通用模型安全地处理私有领域知识。
回答可溯源:RAG 的每条结论都能找到对应的文档来源,满足企业合规审计与风控解释的需求。
降低推理成本:相比将海量文档全部塞入长上下文窗口,RAG 只检索最相关的信息,大幅减少了 Token 消耗和计算资源浪费。
RAG 的完整链路是怎样的?
Query → 文档处理 → Chunking → Embedding → 检索 → Rerank → 生成
| 步骤 | 做什么 | 关键决策 |
|---|---|---|
| 文档处理 | 解析 PDF/Word/Markdown,提取文本 | PDF 表格怎么处理?OCR 要不要? |
| Chunking | 把长文档切成小块 | 切多大?overlap 多少?按语义切还是固定长度? |
| Embedding | 把文本块转成向量 | 用什么模型?维度多少?中文还是英文? |
| 检索 | 根据用户问题检索最相关的文本块 | 纯向量还是混合检索?Top-K 设多少? |
| Rerank | 对检索结果重排序 | 用什么 Rerank 模型?重排后再取 Top-N |
| 生成 | 把检索结果 + 问题喂给 LLM 生成回答 | Prompt 怎么写?幻觉怎么约束? |
向量检索的原理是什么?
向量检索的核心是将“语义相似性”转化为“向量空间中的距离相似性”。
向量化:通过 Embedding 模型将文本映射为高维稠密向量。语义相近的文本(如“苹果手机”与“iPhone”),其向量在空间中的夹角很小(余弦相似度趋近于 1)。
相似度计算:在检索时,计算用户查询向量与库中文档向量的距离(通常使用余弦相似度或欧氏距离)。
近似最近邻(ANN):为了在海量数据中快速找到最相似的向量,通常采用 ANN 算法(如 HNSW 多层图结构、IVF 聚簇等),在极短时间内召回 Top-K 个最相关的文档片段。
| 算法 | 原理 | 特点 |
|---|---|---|
| HNSW | 多层跳表图,从上层粗搜到下层精搜 | 查询快,内存占用大,Milvus 默认 |
| IVF | 先聚类,只搜最近的几个簇 | 可控精度,适合超大规模 |
| PQ(乘积量化) | 压缩向量维度,降低内存 | 内存省,精度有损 |
向量数据库怎么选?Milvus、FAISS、Qdrant 各自适合什么场景?
| FAISS | Milvus | Qdrant | |
|---|---|---|---|
| 类型 | 库(Library) | 数据库(Database) | 数据库(Database) |
| 部署方式 | 嵌入应用进程 | 独立服务,支持分布式 | 独立服务,轻量级 |
| 持久化 | 需自己实现 | 原生支持 | 原生支持 |
| 适合规模 | 百万级以下 | 亿级 | 千万级 |
| 运维成本 | 低(无额外服务) | 中(需部署集群) | 低(单节点起步) |
| 生产环境 | 适合原型验证 | 适合大规模生产 | 适合中小规模生产 |
Milvus:适合企业级大规模生产环境,数据量达到千万甚至十亿级别,需要分布式扩展和多租户隔离的场景。
FAISS:适合对检索速度要求极高、数据不需要频繁更新、且不需要复杂过滤条件的离线或内存检索场景。
Qdrant:适合追求极致单机性能、需要复杂的 Payload(元数据)过滤、以及希望快速落地生产级 RAG 的中小型到大规模场景。
纯向量检索有什么问题?为什么需要混合检索?
纯向量检索的三个致命问题
① 精确匹配不行——用户搜"RFC 7231",向量检索可能返回"HTTP 协议规范"这种语义相关但没提到 RFC 7231 的文档。因为它靠语义相似度,不是精确匹配。
② 专业术语召回差——“K8s 的 HPA 怎么配置”,向量检索可能找的是"Kubernetes 自动扩缩容",而真正包含 HPA 配置细节的文档反而排不上。专业术语的向量表示和口语描述的向量表示距离可能很远。
③ 专有名词遗漏——产品名、人名、缩写这些,向量检索容易丢失。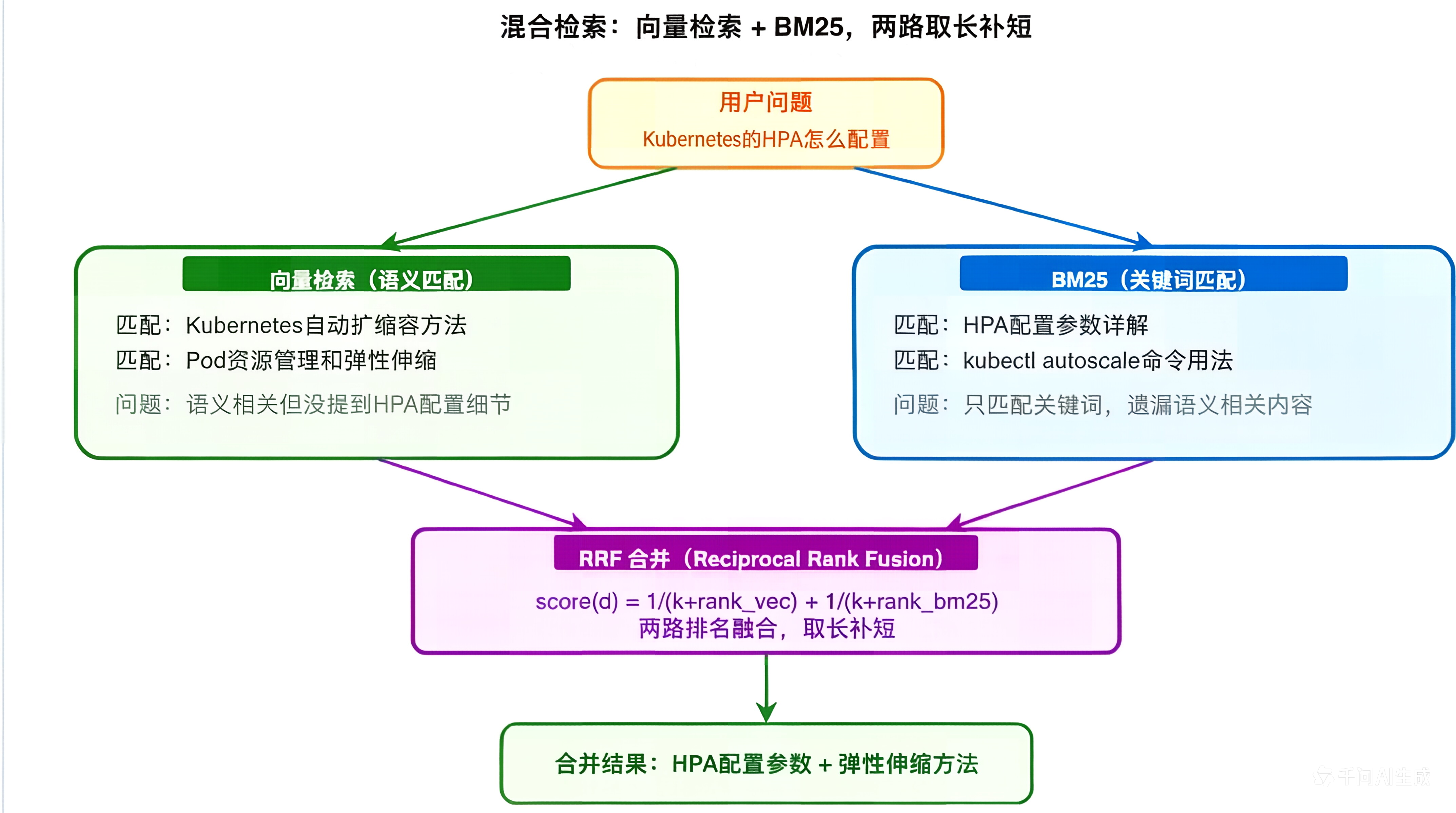
Rerank 是什么?为什么检索之后还要重排序?
检索是粗筛快捞,Rerank 是精排提准。检索用 Bi-Encoder 快但粗,Rerank 用 Cross-Encoder 慢但准。先用检索从百万级捞 Top-20,再用 Rerank 精排取 Top-5,这是生产环境的标配流程。
常用 Rerank 模型
| 模型 | 特点 |
|---|---|
| BGE-Reranker (bge-reranker-v2-m3) | 中文效果好,开源免费 |
| Cohere Rerank | API 调用,效果好,英文为主 |
| bce-reranker-base_v1 | 中文场景,轻量级 |
Chunk 怎么切?切大了切小了各有什么问题?
切分策略:常见的有递归切分(按段落、句子优先级)、结构化切分(按 Markdown 标题或 HTML 标签)、语义切分(在语义断裂点切分)以及固定大小+重叠(Overlap)。
切分大小影响:
切太大:包含的噪声信息多,容易稀释核心语义,导致向量表征不精准,且会占用大模型宝贵的上下文窗口。
切太小:语义可能不完整,导致检索时无法匹配到用户的宏观问题,丢失必要的上下文背景。
建议:通常 Chunk 大小在 256-1024 tokens 之间,并保留 10%-20% 的重叠(Overlap)以保持上下文连贯。
Embedding 模型怎么选?中文场景选什么?
| 模型 | 维度 | 特点 |
|---|---|---|
| bge-large-zh-v1.5 | 1024 | 中文效果最好,开源,本地部署 |
| bge-m3 | 1024 | 多语言,支持稠密+稀疏+多向量三种检索 |
| text-embedding-3-large (OpenAI) | 3072 | 效果好,但 API 调用有成本,中文不如 bge |
| text-embedding-3-small (OpenAI) | 1536 | 便宜,效果够用,英文场景首选 |
选型原则:必须使用同一个模型生成查询和文档的向量;模型升级时需全量重新向量化。通常选择在该语言评测榜单(如 MTEB)上排名靠前的模型。
中文场景:强烈推荐 BGE-M3 系列。它原生支持中文,最大支持 8192 tokens 的长文本,并且能同时产出 Dense(稠密)、Sparse(稀疏)、ColBERT 三种向量,天然非常适合混合检索。
RAG 的幻觉怎么处理?
六种幻觉处理策略
1、Prompt 约束——在 Prompt 里明确要求"只能基于检索结果回答,检索结果没有的信息不要编造"。
2、输出自校验——LLM 生成回答后,再用一次 LLM 检查:回答的每一条是否都能在检索结果中找到依据?找不到的标注为"未验证"。
3、引用标注——要求 LLM 在回答时标注每条信息的来源 chunk,方便人工核查。
4、温度调低——temperature 设 0.1-0.3,降低 LLM 的随机性,减少"编造"的倾向。
5、检索结果和生成结果的对齐——生成回答后,把回答和检索结果做相似度对比,如果回答中有大段内容和所有检索结果都不相关,大概率是幻觉。
6、兜底回答——当检索结果的相似度都低于阈值时,直接回答"未找到相关信息",而不是让 LLM 硬编。
RAG 检索效果不好怎么优化?
优化思路:从链路的每一步找问题
文档处理阶段——PDF 表格提取准确率够不够?图片里的文字有没有 OCR?不同格式(PDF/Word/Markdown)分别做了什么适配?
Chunk 阶段——chunk_size 合不合理?有没有针对不同文档类型调参?
overlap 设的多少?
检索阶段——纯向量还是混合检索?Top-K 设多少?有没有加 Rerank?
生成阶段——Prompt 怎么写的?幻觉怎么处理的?
四种高级优化策略
① Query 改写——用户的问题可能表述不清或太短,先用 LLM 改写成更适合检索的 query。
② 多路召回——同一问题用多种方式检索:原问题检索、改写问题检索、提取关键词检索、拆分子问题检索,最后合并结果。
③ Parent-Child 检索——检索时用小 chunk(精确匹配),返回时用大 chunk(保留上下文)。具体做法:小 chunk 存向量索引用于检索,每个小 chunk 关联一个父 chunk,检索命中后返回父 chunk 的完整内容。
④ 上下文窗口扩展——检索到一个 chunk 后,把它前后的 chunk 也带上,保证上下文完整。
Agentic RAG 是什么?和普通 RAG 有什么区别?
普通 RAG 是固定流程:用户问 → 检索一次 → 生成回答。如果第一次检索结果不好,它不会自己纠正,直接硬生成。就像一个不会反思的人,说错就错到底。
Agentic RAG:让 RAG 自己决定怎么检索Agentic RAG 把 Agent 的规划能力引入 RAG——LLM 自己判断:需要检索哪些数据源?检索结果够不够?不够就换个角度再检索。
设计一个面向 10 万用户的 RAG 知识库系统,你会怎么设计?
从五个维度展开:
数据层(文档解析→Chunk→Embedding→向量库 + ES 双写)、
检索层(混合检索 + Rerank,Top-20 检索 + Top-5 精排)、
生成层(vLLM 部署 + Prompt 模板 + 幻觉约束)、
工程层(Redis 缓存热点查询、异步处理文档更新、监控检索准确率和幻觉率)、
安全层(文档权限隔离、Prompt Injection 防御、敏感信息过滤)。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 6
6 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)