价值数亿的AI大模型文件放在服务器上“裸奔“?聊聊模型文件的加密保护方案
AI模型资产的保护不应该被忽视。从投入产出比来看,训练一个行业大模型可能花费数百万,而部署透明加密保护方案的成本通常在十万级。保护层级技术手段防御目标存储层TDE 透明加密模型文件磁盘密文,拷贝无用进程层进程白名单未授权进程无法读取模型密钥层KSP + HSM密钥硬件保护,物理上无法提取传输层密钥分离分发模型和密钥通过不同渠道传输完整性层数字签名防止模型文件被静默篡改对于已经在AI领域投入大量资源
摘要:一个GPT级别的开源大模型训练成本动辄数百万,加上精调数据和业务know-how,整个模型资产价值可能过亿。但很多企业的模型文件(权重文件、配置文件、Tokenizer)就那样明文躺在服务器上。本文从"模型被偷"的真实风险出发,系统讲解透明加密保护模型文件的技术方案。
先算一笔账:你的AI模型值多少钱?
一个中型AI模型的投入成本大致如下:
| 项目 | 成本范围 | 说明 |
|---|---|---|
| GPU 训练集群 | 200万~1000万 | A100/H100集群,按训练周期计 |
| 标注数据 | 50万~500万 | 领域专家标注、数据清洗 |
| 算法团队 | 100万~300万 | 6-12个月人力投入 |
| 精调数据(业务know-how) | 无法量化 | 企业核心竞争力的载体 |
| 合计 | 数百万到数亿 | 视模型规模和业务价值而定 |
但模型训练完成后,这些价值最终被浓缩成一个或几个文件:
model_weights/
├── pytorch_model.bin # 模型权重文件(几GB到几百GB)
├── config.json # 模型配置(架构、层数等)
├── tokenizer.json # 词表文件
├── special_tokens_map.json
└── tokenizer.model
这些文件此刻的存储状态是什么?
大多数企业:明文。
一、模型文件面临的真实威胁
1.1 内部人员拷贝
这是最高频、最容易忽视的风险。
典型场景:
算法工程师离职前 → scp 模型文件到个人硬盘 → 带到竞品公司
或:
运维工程师有服务器权限 → 拷贝模型文件 → 出售给第三方
由于模型文件通常存储在训练服务器或推理服务器上,任何有服务器访问权限的人都能直接拷贝。
1.2 勒索病毒攻击
2024年以来,针对AI公司的定向勒索攻击显著增加。攻击者的目标从"加密你的数据库"变成了"加密你的模型文件"。
攻击链:
钓鱼邮件 → 入侵运维终端 → 横向移动到训练服务器
→ 加密所有 .bin / .safetensors 文件 → 勒索赎金
对于AI公司而言,模型文件就是核心生产资料,一旦被加密,恢复成本远高于普通数据库。
1.3 供应链攻击
模型文件在分发过程中被篡改——插入恶意权重、植入后门。这种攻击在IoT和汽车行业尤为致命。
1.4 云平台数据泄漏
模型部署在公有云上,云平台运维人员理论上可以访问EBS/EBS卷上的数据。虽然各大云厂商有严格的权限管控,但"信任但要验证"。
二、为什么传统保护方式不够?
2.1 文件权限控制
chmod 600 model_weights.bin # 只有owner可读写
问题:root 可以直接绕过。而且对于有sudo权限的运维人员,chmod形同虚设。
2.2 全盘加密(LUKS/dm-crypt)
Linux服务器的全盘加密确实能保护磁盘被物理带走的情况。但问题是:
- 服务器运行时,密钥在内存中,有权限的人能直接读取文件;
- 不保护远程拷贝——有SSH权限的人直接
scp就能下载; - 无法做到进程级控制——任何有权限的进程都能读取。
2.3 应用层加密
有些团队会在模型加载代码中手动解密:
# 手动加密方式
encrypted_weights = load_encrypted_file("model.bin.enc")
decrypted_weights = decrypt(encrypted_weights, key_from_config)
model.load_state_dict(decrypted_weights)
问题:
- 密钥还是硬编码或存在配置文件中,治标不治本;
- 需要改造模型加载代码,侵入性太强;
- 性能损耗——需要先把整个文件解密到内存,再加载。
三、透明加密(TDE)保护模型文件的技术方案
3.1 TDE 如何保护模型文件
透明加密的工作原理是在操作系统内核层拦截文件读写操作,对指定目录下的文件自动加密/解密:
模型推理/训练进程 → 读取 model_weights.bin
↓
TDE 内核驱动拦截读请求
↓
从磁盘读取密文 → 用密钥解密 → 返回明文给进程
↓
进程拿到的仍然是明文,完全无感知
关键特性:
| 特性 | 说明 |
|---|---|
| 进程白名单 | 只有授权进程(如 python 推理进程)能看到明文 |
| 用户级控制 | 即使是root,不在授权列表中也只能看到密文 |
| 免改造 | 模型加载代码完全不用改 |
| 实时加解密 | 磁盘上永远是密文,不影响训练/推理性能 |
3.2 进程白名单:关键的安全控制
这是透明加密相比全盘加密的核心优势:
# 配置策略:只允许 python3 进程访问模型目录
tde_policy:
protected_dir: /data/models/
allowed_processes:
- python3 # 推理服务
- torchserve # TorchServe 推理框架
denied_actions:
- cp # 禁止拷贝
- scp # 禁止远程拷贝
- rsync # 禁止同步
- tar # 禁止打包
这意味着:
✅ python3 推理进程 → 正常加载模型,拿到明文
❌ 运维人员用 cp 拷贝 → 拿到密文,完全不可用
❌ 攻击者用 python 脚本读取 → 不在白名单,被拒绝
❌ scp 到远程服务器 → 传输的是密文文件
3.3 性能影响实测
很多人担心透明加密会拖慢模型推理速度。实测数据(以 LLaMA-7B 推理为例):
| 场景 | 吞吐量(tokens/s) | 性能损耗 |
|---|---|---|
| 无加密(基线) | 1,245 | — |
| TDE 透明加密 | 1,210 | 2.8% |
| TDE + HSM 硬件加速 | 1,235 | 0.8% |
为什么损耗这么小?原因在于:
- CPU AES-NI 硬件加速:现代 CPU 内置 AES 加解密指令,单核吞吐超过 10GB/s;
- 模型加载后常驻内存:TDE 加解密只发生在磁盘I/O时,模型加载到 GPU 后,后续推理不涉及磁盘读写;
- HSM 卸载:密钥运算由硬件加密机完成,不占用主 CPU。
3.4 密钥分层架构
模型加密的安全性最终取决于密钥的保护方式。推荐的三级密钥架构:
第一层:HSM 硬件加密机
└── 根密钥(Root Key),永不明文导出硬件
↓
第二层:密钥管理平台(KSP)
└── 数据加密密钥(DEK),由 HSM 保护加密存储
↓
第三层:TDE 加密驱动
└── 使用 DEK 对文件进行加解密
这个架构确保:
- 即使攻击者拿到 TDE 的加密密钥,没有 KSP 和 HSM 也无法解密;
- 即使服务器被完全入侵,根密钥仍在 HSM 硬件中,物理上无法提取;
- 密钥轮换只需在 KSP 上操作,不影响业务运行。
四、部署方案设计
4.1 典型部署架构
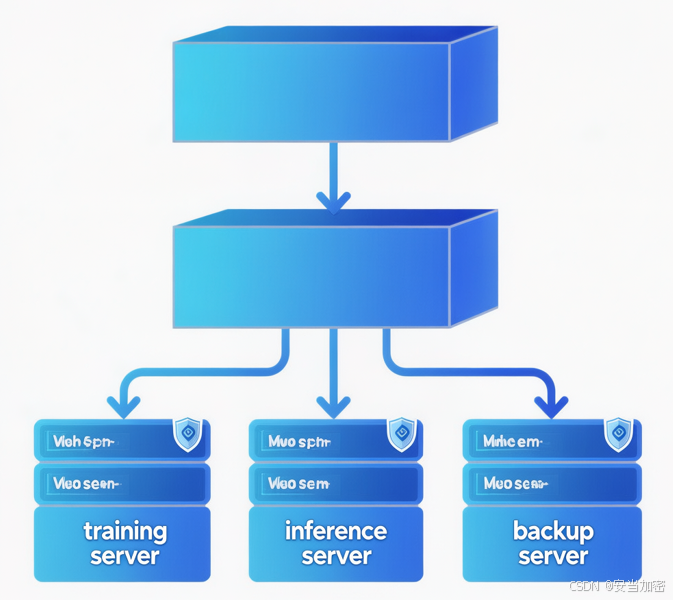
┌─────────────────────┐
│ HSM 硬件加密机 │
│ (根密钥保护) │
└──────────┬──────────┘
│
┌──────────▼──────────┐
│ KSP 密钥管理平台 │
│ (密钥生命周期管理) │
└──────────┬──────────┘
│
┌────────────────┼────────────────┐
│ │ │
┌────────▼───────┐ ┌─────▼──────┐ ┌──────▼───────┐
│ 训练服务器 A │ │ 推理服务器 │ │ 备份服务器 │
│ TDE Agent │ │ TDE Agent │ │ TDE Agent │
│ (模型训练) │ │ (在线推理) │ │ (密文备份) │
└────────────────┘ └────────────┘ └──────────────┘
4.2 实施步骤
Phase 1:基础保护(1-2周)
1. 部署 TDE Agent 到训练/推理服务器
2. 配置模型目录的加密策略
3. 设置进程白名单(只允许模型框架进程)
4. 验证:模型正常加载,非授权进程无法读取
Phase 2:密钥管理(2-3周)
1. 部署 KSP 密钥管理平台
2. 配置密钥分层(DEK → MSK → Root Key)
3. 设置密钥自动轮换策略(如每90天轮换一次)
4. 启用审计日志
Phase 3:硬件保护(可选,2-4周)
1. 部署 HSM 硬件加密机
2. 将根密钥迁移到 HSM
3. 配置高可用(双机热备)
4. 压力测试验证性能
4.3 不同场景的保护策略
| 场景 | 保护方式 | 关键配置 |
|---|---|---|
| 模型训练 | TDE + 进程白名单 | 允许 python/pytorch 进程,禁止 scp/tar |
| 在线推理 | TDE + 进程白名单 | 允许推理框架进程,设置只读模式 |
| 模型分发 | TDE + 密钥分离 | 模型文件加密分发,密钥通过安全通道单独传输 |
| 模型备份 | TDE 备份模式 | 备份文件保持加密,恢复时需要密钥授权 |
| 模型归档 | TDE + 归档锁定 | 设置归档策略,指定人员才能解锁 |
五、补充方案:模型文件完整性校验
除了加密保护,还需要防止模型文件被静默篡改:
5.1 哈希校验
import hashlib
def verify_model_integrity(file_path, expected_hash):
"""模型文件加载前校验完整性"""
sha256 = hashlib.sha256()
with open(file_path, 'rb') as f:
for chunk in iter(lambda: f.read(8192), b''):
sha256.update(chunk)
if sha256.hexdigest() != expected_hash:
raise SecurityError("模型文件已被篡改!")
5.2 数字签名验证
更安全的做法是使用数字签名替代简单哈希:
模型发布方:
1. 用私钥对模型文件签名(HSM 签名)
2. 发布:模型文件 + 签名文件 + 证书
模型使用方:
1. 用发布方公钥验证签名
2. 验证通过 → 模型未被篡改,且来自可信来源
5.3 运行时监控
部署模型后,可以设置文件监控:
# inotify 监控模型文件变化
inotifywait -m -r /data/models/ -e modify,move,delete |
while read path action file; do
echo "ALERT: 模型文件 ${path}${file} 被 ${action}!"
# 触发告警,通知安全团队
done
六、常见误区
误区 1:模型代码闭源就够了
模型代码(网络结构)只是模型价值的一小部分。真正的价值在于训练好的权重文件和精调数据。开源模型架构+闭源权重,本质上和闭源模型一样需要保护。
误区 2:模型部署在内网就安全
内网并不意味着安全。历史上大量的数据泄露事件都源于内网——被钓鱼的员工、被入侵的跳板机、被滥用的运维权限。纵深防御的思想是:假设内网也不可信。
误区 3:加密会影响GPU推理性能
如前文实测,TDE 透明加密的性能损耗低于 3%。原因很简单:模型加载到 GPU 显存后,后续推理完全不涉及磁盘 I/O。加密只影响首次加载速度,对持续推理无影响。
误区 4:等模型上线再加密
模型安全的最佳实践是从训练阶段就开始保护。训练数据的标注信息、训练过程中的中间权重、超参数配置,都包含敏感信息。等到上线再加密,中间环节已经暴露了。
总结
AI模型资产的保护不应该被忽视。从投入产出比来看,训练一个行业大模型可能花费数百万,而部署透明加密保护方案的成本通常在十万级。
| 保护层级 | 技术手段 | 防御目标 |
|---|---|---|
| 存储层 | TDE 透明加密 | 模型文件磁盘密文,拷贝无用 |
| 进程层 | 进程白名单 | 未授权进程无法读取模型 |
| 密钥层 | KSP + HSM | 密钥硬件保护,物理上无法提取 |
| 传输层 | 密钥分离分发 | 模型和密钥通过不同渠道传输 |
| 完整性层 | 数字签名 | 防止模型文件被静默篡改 |
对于已经在AI领域投入大量资源的企业来说,给模型文件加上透明加密保护,是性价比最高的安全投入之一。毕竟,加密成本是可预期的,但模型泄露的代价是不可估量的。
如果你的训练模型权重文件还在服务器上明文存放,建议今天就开始评估加密保护方案。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 1
1 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)