AI应用开发面试题总结(非八股文)
1.看前端和网络F12开发者模式去查看network,首先判断是前端问题还是后端问题通过查看接口 Waiting 时间进行判断是后端响应时间太长还是说前端渲染问题2.给后端接口添加日志进一步定位后端问题3.如果是数据库问题,则可能是慢查询问题4.看 Redis 问题常见原因:5.看外部接口或第三方服务比如短信、支付、AI 模型、地图接口问题经常是:如果第三方接口卡住,后端线程也会一直阻塞。解决方案
前端请求超过 3 秒,怎么分析原因?
1.看前端和网络
F12开发者模式去查看network,首先判断是前端问题还是后端问题
通过查看接口 Waiting 时间进行判断是后端响应时间太长还是说前端渲染问题
2.给后端接口添加日志进一步定位后端问题

3.如果是数据库问题,则可能是慢查询问题
- 查看慢查询日志,定位是哪个查询语句出问题了
- explain对应的sql语句,看看对应的索引和索引利用情况
- 如果是索引方面是问题,看看是不是索引缺失或者失效的问题
4.看 Redis 问题
常见原因:
大 key、连接池耗尽。
5.看外部接口或第三方服务
比如短信、支付、AI 模型、地图接口
问题经常是:
没有设置超时时间。
如果第三方接口卡住,后端线程也会一直阻塞。
解决方案:
第三方接口超过 1 秒直接失败,返回默认结果,避免拖垮整个接口。
6.看线程池和连接池
如果并发高,请求超过 3 秒可能不是单个逻辑慢,而是排队。
比如:
Tomcat 线程池满了,请求进来后没有线程处理,只能排队。
数据库连接池满了,业务线程拿不到连接,也会等待。
Redis 不加限制会耗尽内存,怎么解决?
Redis 是内存数据库,如果不限制内存,业务一直写 key,最终可能导致内存被打满,轻则 Redis 变慢,重则被操作系统 OOM Kill。所以生产环境一定要做内存限制和淘汰策略。
- 设置最大内存 maxmemory
- 设置淘汰策略 maxmemory-policy
- 给缓存 key 设置过期时间
- 过期时间加随机值,防止缓存雪崩
- 避免大 key
那淘汰策略有哪些呢?
- 不淘汰任何 key,内存满后写入直接报错
- 从所有 key 中淘汰最近最少使用的数据
- 从所有 key 中随机淘汰
- 优先淘汰剩余过期时间最短的 key
MyBatis 为什么 Mapper 接口不用实现?是什么机制?
MyBatis 的 Mapper 接口不用我们手动写实现类,本质原因是 MyBatis 在启动时通过 JDK 动态代理,为 Mapper 接口自动生成了代理对象。
我们调用 Mapper 方法时,实际上调用的是代理对象,而不是接口本身。
如果只是小厂的话,这样你也就够了,但是如果你面试一些大厂可能就会衍生出一些问题:
- 动态代理是什么?底层原理是什么?动态代理还有哪些应用场景
- 调用Mapper方法时候的流程是什么?
我们先回答问题2
调用Mapper方法时候的流程是什么?
- Spring扫描 Mapper 接口
- 为接口创建 MapperProxyFactory(专门生成 Mapper 代理对象)
- 生成代理对象(Spring 容器里放的是 proxy)
- 调用mapper方法的时候拦截方法
- 通过 SQL 唯一标识(com.xxx.mapper.UserMapper.selectById)找到对应的 MappedStatement(MyBatis 启动时会把 XML 或注解 SQL 解析成:MappedStatement)
- 调用 SqlSession 执行 SQL
- SqlSession 调用 Executor
- Executor 调用 JDBC
(1)获取数据库连接
(2)预编译 SQL(select * from user where id = ?)
(3)参数绑定
(4)执行 SQL
9.ResultSet 结果映射
数据库返回:ResultSet
MyBatis 会根据:resultType或者resultMap映射成 Java 对象。
那引出问题:什么是预编译?
数据库会:
1.SQL 语法解析
数据库先检查:
- SQL 是否合法
- 表是否存在
- 字段是否存在
2. SQL 优化
- 走哪个索引
- 如何生成执行计划
- 是否全表扫描
3.生成执行计划
数据库会缓存:执行计划
后面参数不同:可以复用
那我们是不是可以想起之前背八股文的时候,学的#{}和${}的区别是什么
#{} 是预编译参数
例如:
<select>
select * from user where id = #{id}
</select>MyBatis 最终:
select * from user where id = ?然后:
ps.setLong(1,1L)支持:
- 预编译
- 执行计划复用
- 防 SQL 注入
${}是字符串拼接
例如:
<select>
select * from user where id = ${id}
</select>如果:
id=1最终 SQL:
select * from user where id = 1如果:
id=2SQL 会变成:
select * from user where id = 2每次都需要:
- 重新解析
- 重新优化
- 重新生成执行计划
- 更严重的问题:SQL 注入
这里顺带大家回顾一下第一个问题(实则是我也忘记了)
什么是动态代理?
动态代理本质上是在程序运行期间,动态生成一个代理对象,通过代理对象去增强目标对象的方法,而不需要手动编写代理类。
动态代理底层原理是什么?
Java 动态代理主要有两种:
| 类型 | 使用场景 |
|---|---|
| JDK 动态代理 | 代理接口 |
| CGLIB 动态代理 | 代理类 |
JDK 动态代理
目标对象实现接口CGLIB 动态代理
有些类没有接口底层流程
(1)创建代理对象(Proxy.newProxyInstance())
(2)方法被拦截
调用:
proxy.login()实际上进入:
InvocationHandler.invoke()
动态代理有哪些应用场景?
- Spring AOP
- Spring 事务(@Transactional)
- MyBatis Mapper
- 日志监控
那基于此是不是又可以引出问题:
- AOP是什么?AOP的底层原理是什么?AOP的实现方法有哪些
- Spring的事务是什么,有哪些实现方式
AOP 是什么?AOP 底层原理是什么?
AOP 全称是面向切面编程,它的核心思想是在不修改原业务代码的情况下,对方法进行统一增强。比如日志记录、权限校验、性能统计、事务管理这些公共逻辑,如果直接写在业务代码里会产生大量重复代码,而 AOP 可以把这些逻辑抽离成切面,统一织入到目标方法中。
Spring AOP 的底层核心其实是“动态代理 + 反射”。Spring 不会直接把原对象交给我们,而是会在运行期间为目标对象生成一个代理对象。我们调用方法时,实际上先进入的是代理对象,而不是原对象。代理对象会先执行增强逻辑,比如打印日志、开启事务等,然后 JVM 会把当前调用的方法封装成一个 Method 对象传给代理逻辑,例如调用 proxy.login() 时,JVM 会自动把 login 方法对应的 Method 传进来。接着代理对象会通过反射 method.invoke(target,args) 去调用真实业务对象的方法,最后再执行方法后的增强逻辑,比如提交事务、统计耗时等。所以可以理解为:AOP 的核心目的是增强方法;动态代理负责生成代理对象并拦截方法;反射负责真正调用目标对象的方法。
(proxy, method, args) -> {
// AOP增强
System.out.println("before");
// 反射调用真实方法
Object result =
method.invoke(target,args);
// AOP增强
System.out.println("after");
return result;
}反射是什么?底层原理是什么?
反射本质上是 Java 在运行时动态获取类信息,并动态操作类的一种机制。正常情况下,我们是“编译时”就确定调用哪个类、哪个方法,比如 userService.login();而反射可以在程序运行过程中,动态获取类、方法、属性的信息,并动态创建对象、调用方法。比如可以通过 Class 获取类信息,通过 Method 获取方法,再通过 method.invoke() 动态执行方法。
AOP的实现方法有哪些
1.基于 XML 配置实现
2.基于注解实现,也是目前最常用的方式。通常会使用
@Aspect定义切面类,使用@Before、@After、@Around等定义通知,再通过切点表达式指定拦截哪些方法。例如日志、权限、事务等功能通常都是这样实现的。3.基于自定义注解实现
Spring的事务是什么,有哪些实现方式
Spring 事务本质上是 Spring 对数据库事务的一层封装,用来保证一组数据库操作要么全部成功,要么全部失败,从而保证数据一致性。比如转账场景,A 扣钱和 B 加钱必须同时成功,如果其中一步失败,就需要整体回滚,否则数据就会出现问题。Spring 事务底层核心其实是 AOP,Spring 会通过动态代理为目标对象生成事务代理,在方法执行前开启事务,执行成功后提交事务,发生异常时回滚事务。
Spring 事务主要有两种实现方式:编程式事务和声明式事务
编程式事务:TransactionTemplate
声明式事务:@Transactional 注解实现
mysql索引按存储方式划分
MySQL 索引按照存储方式或者底层数据结构来划分,主要可以分为 B+Tree 索引、Hash 索引
其中 InnoDB 最核心、最常用的是 B+Tree 索引。B+Tree 属于多路平衡查找树,特点是树高度低、磁盘 IO 次数少,并且叶子节点之间通过链表连接,因此不仅适合等值查询,还非常适合范围查询、排序和分组
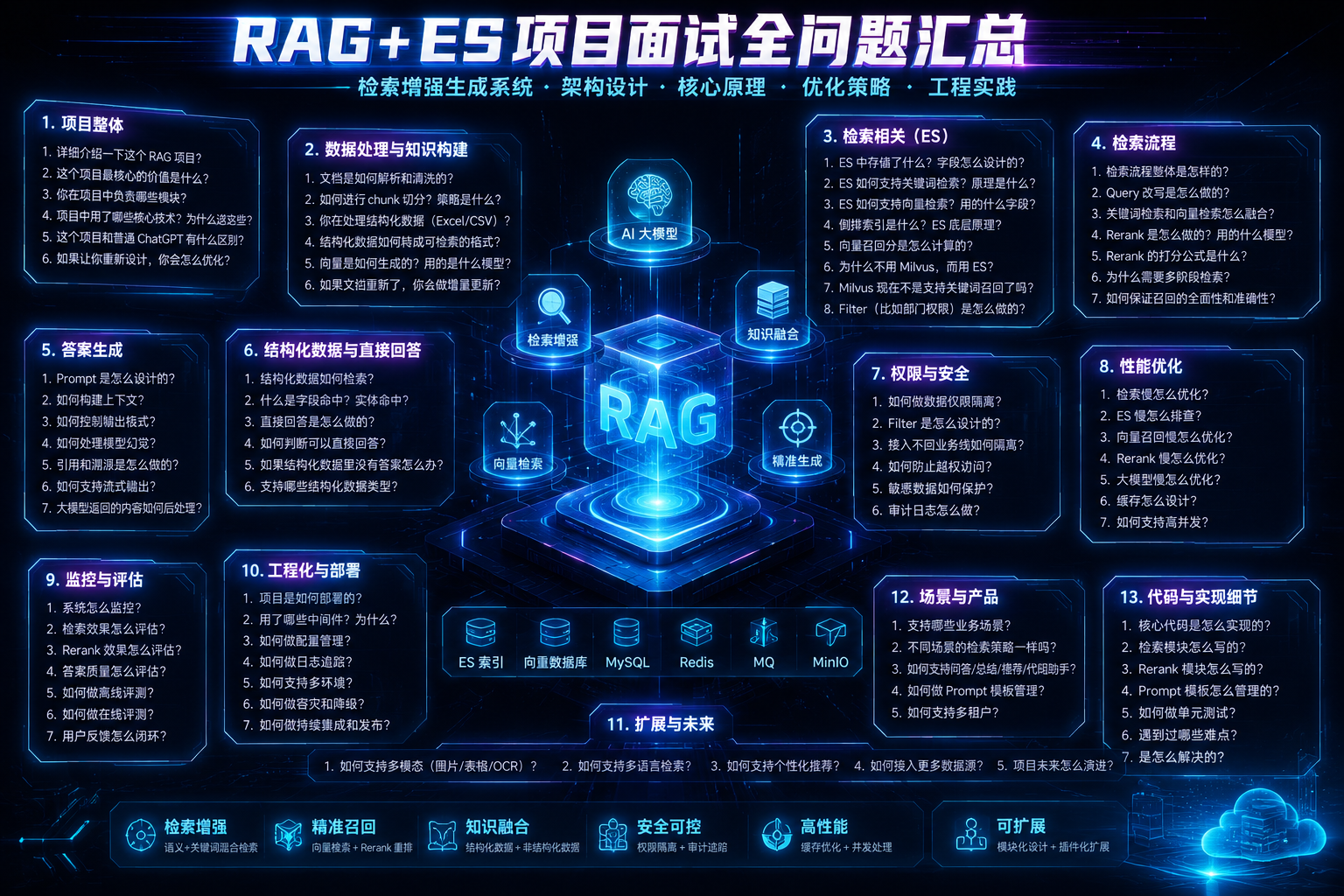
RAG 技术的挑战点是什么?
它最难的地方不在“调用大模型”,而在怎么把正确的知识找出来,并且让模型只基于正确知识回答
1.文档解析难
企业文档不是纯文本,可能是 Word、PDF、Excel、CSV、图片扫描件。不同格式结构不一样。
比如 Word 里有标题、正文、表格;Excel 里是行列结构;PDF 可能有分页、页眉页脚、换行错乱。解析错了,后面检索一定差。
2.chunk 切分难。
chunk 太大,会把很多无关内容塞进上下文;chunk 太小,又会丢上下文
3.召回难
用户问法和文档写法不一样。
如果只靠关键词,“出差花的钱”和“差旅费用报销”不是完全一样,可能召回不到
所以要做 query rewrite、同义词、关键词召回 + 向量召回
4.排序难
召回出来的 topK 不一定最准确,所以要 rerank.
5.拒答难
资料里没有答案时要拒答,资料里有答案时要回答。这件事非常难。
6.权限隔离难
企业文档有权限,A 部门不能看到 B 部门文档。
这个不能只靠 Prompt,必须在检索层做 filter。
那么如何去解决这些挑战
1. 文档解析难
首先按文件类型走不同解析器:
Word → 解析标题、段落、表格
PDF → 解析页码、段落、表格,处理页眉页脚
Excel/CSV → 按 sheet、行、列解析,保留表头和字段关系
图片扫描件 → OCR 识别文字其次,解析结果不要只保存纯文本,还要保留结构信息
例如word文档
标题:3.2 报销审批规则
报销金额小于1000元,由直属主管审批。
报销金额大于等于1000元,由部门负责人审批。
{
"title": "员工报销制度",
"section": "3.2 报销审批规则",
"level": 2,
"content": "报销金额大于等于1000元,由部门负责人审批。",
"page": 5
}2. chunk 切分难
不能只按固定长度切,要做结构化切分。
可以按:
标题
章节
段落
自然语义边界例如制度文档:
3.2 报销审批规则
报销金额小于1000元,由直属主管审批。
报销金额大于等于1000元,由部门负责人审批。切 chunk 时要保留标题:
标题:3.2 报销审批规则
内容:报销金额大于等于1000元,由部门负责人审批。还可以加 overlap,避免上下文断裂
比如 chunk1 末尾和 chunk2 开头重叠一部分:
chunk1: ...小于1000元由主管审批。大于等于1000元...
chunk2: 大于等于1000元由部门负责人审批...这里可以给每个chuck段添加一些额外信息,比如属于哪个文档,文档中的第几个chuck,后面可以进行相邻chuck的merge
3. 召回难
1.做 Query Rewrite
把用户问题改写成更适合检索的形式:
第一层是固定处理规则
去标点
统一大小写
去掉口语填充词
空格归一化
章节编号归一化
中英文数字/符号归一化2.使用混合召回
使用关键词+向量召回
关键词 topK + 向量 topK → 融合去重 → 进入 rerank4. 排序难
做 rerank 重排。重排时不能只看向量分数,要结合多个信号:
关键词命中
标题命中
实体命中
字段命中
结构化命中
chunk 位置
文档权重
内容长度惩罚5. 拒答难
难点是避免两种问题:
没答案却乱答 → 幻觉
有答案却说不知道 → 误拒答Answer Guard,根据多个信号判断:
top1 分数
top1 和 top2 分差
关键词命中率
实体是否命中
字段是否命中
上下文覆盖度
结构化直接命中6. 权限隔离难
第一,文档入库时打权限标签。
每个文档、每个 chunk 都带权限字段:
{
"documentId": 1001,
"departmentId": "B",
"acl": ["dept:B", "role:manager"]
}第二,检索时强制加 filter。
A 部门用户查询时,只能召回:
dept:A
public不能召回 B 部门文档。
ES 查询里加:
{
"terms": {
"acl": ["dept:A", "public"]
}
}第三,rerank/上下文构建阶段 前二次校验
第四,答案必须引用来源。
ES 里存什么?为什么用 ES,而不是 Milvus 做向量数据库?
ES 存的不是“整个文档”,而是“chunk 级别的检索索引”。
ES 底层最核心的数据结构其实是“倒排索引
ES 底层最核心的数据结构是倒排索引(Inverted Index)。传统数据库更像是“文档到内容”的正向存储,而 ES 会建立“词项到文档”的映射关系。
例如文档里有“李四分数88”,ES 在写入时会先经过分词器,把内容拆成“李四、分数、88”等 term,然后建立:
李四 → doc1
分数 → doc1
88 → doc1这样用户搜索“李四”时,就不需要全表扫描,而是直接通过倒排索引快速定位文档,所以检索效率很高。
倒排索引里除了 term 和 docId,还会保存 term frequency、position、offset 等信息,用于 BM25 相关性计算、短语匹配和高亮显示。
在我这个 RAG 项目里,ES 不仅存倒排索引,还存 embedding 向量,所以本质上是:
倒排索引 + 向量索引的混合检索架构。
倒排索引负责关键词、人名、编号、字段等精确检索;向量索引负责语义相似召回;最后再结合 rerank 做融合排序。
Milvus 是专业向量数据库,确实很适合大规模向量检索。
但你的项目不是“纯向量检索系统”,而是“企业 RAG 问答系统”。
企业 RAG 需要的不只是向量,还需要:
关键词检索
权限过滤
结构化字段
文档状态
调试解释
多条件过滤第一,ES 能做混合检索
BM25 关键词召回
dense_vector 向量召回
filter 权限过滤
字段查询第二,ES 过滤能力更方便。
比如 A 部门用户检索时,可以直接加:
{
"term": {
"departmentId": "A"
}
}第三,ES 对调试更友好。
你可以看:
命中了哪些关键词
score 是多少
哪个字段命中
召回了哪个 chunk
为什么排在前面Embedding 模型是什么维度?为什么不用网格划分?
Embedding 维度取决于你用的模型。
比如有的模型输出 768 维,有的 1024 维,有的 1536 维。ES mapping 里的 dense_vector 维度必须和 embedding 模型输出维度一致。比如模型输出 1024 维,ES 里就要建:
{
"contentVector": {
"type": "dense_vector",
"dims": 1024
}
}“网格划分”适合低维空间,比如地图经纬度。
比如二维地图:
x轴:经度
y轴:纬度可以切成很多小格子:
A1 A2 A3
B1 B2 B3
C1 C2 C3查附近的人时,只查附近几个格子。
但 embedding 是高维向量,比如 768 维、1024 维。
如果维度降维可不可以?
可以,但不能随便降。
降维的本质是:
把高维向量压缩成低维向量比如:
1024维 → 256维
1536维 → 384维好处:
存储减少
索引更小
检索更快
内存占用更低坏处:
语义信息损失
召回准确率可能下降
相似度分布改变最近用 AI 做开发的具体需求,如何思考设计并落地?
可以讲你做 Conversation Memory
原问题:
RAG 问答一开始是单轮的。
用户第一轮问:
张三在哪个部门?系统回答:
张三在技术部。第二轮用户问:
那他的负责人是谁?系统不知道“他”是谁,也不知道上一轮的上下文。
所以你要加会话记忆。
设计时你考虑了几个点。
第一,必须有 conversationId。
不然不同用户、不同会话会串。
请求里加:
{
"question": "那他的负责人是谁?",
"conversationId": "conv_123"
}第二,不做复杂长期记忆,只做 Redis 窗口记忆。
比如只存最近 5 轮:
user: 张三在哪个部门?
assistant: 张三在技术部。
user: 那他的负责人是谁?第三,历史只参与生成,不参与检索。
这点很重要。
如果把历史全部拼进检索 query,可能会导致召回偏移。
所以 保守设计:
retrieval 仍然只基于当前 question
history 只放进 prompt 里帮助生成第四,Prompt 里规定优先级:
当前参考知识 > 历史对话因为历史可能过期,当前检索到的知识更可靠。
第五,缓存要改。
如果缓存 key 只看 question,那么:
那他的负责人是谁?这个问题在不同会话里会有不同含义。
所以缓存 key 要包含:
conversationId
question
history signature落地步骤:
QaAskRequest 增加 conversationId
QaAskResponse 增加 conversationId、memoryUsed、historyCount
新增 RedisChatMemoryRepository
新增 ConversationMemorySupport
ask 前读取历史
ask 后写入 user/assistant
PromptBuilder 加入历史对话
缓存 key 加入 conversationId 和历史签名你用 AI 的方式可以这样讲:
你不是让 AI 直接瞎写代码,而是:
先让 AI 帮我拆设计方案
→ 我确定 V1 边界:只做窗口记忆,不做复杂指代消解
→ 让 AI 生成类和接口修改草案
→ 我审查缓存 key、Redis 结构、Prompt 优先级
→ 最后用多轮问题联调验证多表聚合查询:用户表、订单表、支付表
题目:
查询 2026 年注册,且在注册后 30 天内成功支付金额大于 1000 的用户 IDSELECT DISTINCT u.id
FROM user u
JOIN orders o ON o.user_id = u.id
JOIN payment p ON p.order_id = o.id
WHERE u.register_time >= '2026-01-01'
AND u.register_time < '2027-01-01'
AND p.pay_status = 'SUCCESS'
AND p.pay_time >= u.register_time
AND p.pay_time < DATE_ADD(u.register_time, INTERVAL 30 DAY)
AND p.pay_amount > 1000;
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)