【Qwen2.5本地部署】超简单pytorch-gpu部署教程
本文完成了基于 CUDA 与 Transformers 的 Qwen2.5-VL 本地部署,并结合完整代码详细分析了多模态大模型从图片输入、文本编码到最终生成回答的完整推理流程。
·
前言
- 最近有个项目需要本地部署大模型,故拿上位机先简单验证一下。

1 环境配置
- 这里我们使用
conda来创建虚拟环境
conda create -n qwen_vl python=3.10 -y
conda activate qwen_vl
- 安装
torch的gpu版本,现在pip都很方便,直接连同cuda等环境都一键配好了
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
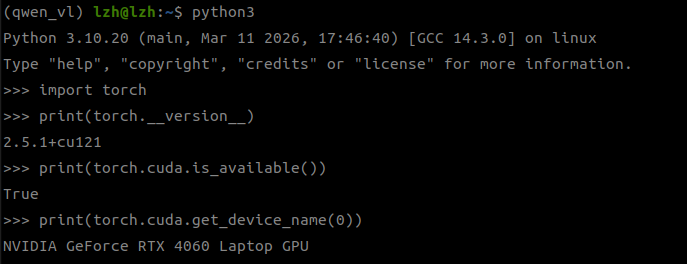
- 然后我们可以验证一下下载的
torch是否可以争取调用gpu
import torch
print(torch.__version__)
print(torch.cuda.is_available())
print(torch.cuda.get_device_name(0))
- 安装运行需要的其他依赖
pip install transformers accelerate pillow qwen-vl-utils
2 代码推理
运行
- 初次运行代码会自动下载模型本体,考虑到可能有些朋友连接不上魔法,这里我们使用国内的镜像站
export HF_ENDPOINT=https://hf-mirror.com

- 完整代码如下:
from transformers import Qwen2_5_VLForConditionalGeneration
from transformers import AutoProcessor
from qwen_vl_utils import process_vision_info
import torch
# 加载模型
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-VL-3B-Instruct",
torch_dtype=torch.float16,
device_map="auto"
)
# 加载processor
processor = AutoProcessor.from_pretrained(
"Qwen/Qwen2.5-VL-3B-Instruct"
)
# 输入
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "cat.png"
},
{
"type": "text",
"text": "请描述这张图片"
}
]
}
]
# 处理输入
text = processor.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt"
)
inputs = inputs.to("cuda")
# 推理
generated_ids = model.generate(
**inputs,
max_new_tokens=128
)
generated_ids_trimmed = [
out_ids[len(in_ids):]
for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed,
skip_special_tokens=True,
clean_up_tokenization_spaces=False
)
print(output_text[0])
-
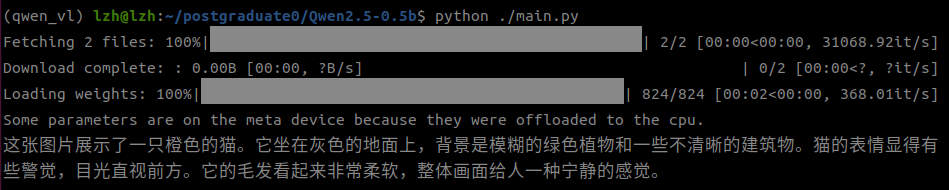
这里我输入的是一张普通的猫猫(可爱捏)

-
运行代码,初次运行需要下载模型,等待即可
3 代码解释
3-0 前置知识
token:大语言模型并不是直接处理文字,而是把文字拆分为一个个token- 例如:
"你好世界"
↓
[108386, 3837]
- 上下文(Context) :模型每次生成内容时,都会参考之前已经输入的全部内容 ,包括:
- system prompt
- 用户问题
- 图片信息
- 历史对话
- 这些内容共同构成上下文窗口(Context Window)
3-1 Qwen2.5系列
- Qwen2.5 是 :阿里云通义千问推出的新一代大语言模型系列。
- 其中主要包括:
| 模型 | 类型 | 是否支持图片 |
|---|---|---|
| Qwen2.5-0.5B | 纯文本LLM | ❌ |
| Qwen2.5-7B | 纯文本LLM | ❌ |
| Qwen2.5-VL-3B | 多模态VLM | ✅ |
| Qwen2.5-VL-7B | 多模态VLM | ✅ |
- 其中:
LLM(Large Language Model)只能处理文本VLM(Vision Language Model)同时支持:- 图片
- 文本
- 视频
3-2 模型加载
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-VL-3B-Instruct",
torch_dtype=torch.float16,
device_map="auto"
)
- 使用
from_pretrained加载预训练模型 - 而
Qwen/Qwen2.5-VL-3B-Instruct代表:
| 部分 | 含义 |
|---|---|
| Qwen2.5 | 模型版本 |
| VL | Vision Language |
| 3B | 30亿参数 |
| Instruct | 指令微调版 |
torch_dtype=torch.float16表示模型使用 FP16 半精度device_map="auto"自动决定模型的哪些层放置的设备(gpu还是cpu)
3-3 加载processor
processor = AutoProcessor.from_pretrained(
"Qwen/Qwen2.5-VL-3B-Instruct"
)
processor是:
Tokenizer + 图像处理器 的组合
- 主要负责:
| 功能 | 作用 |
|---|---|
| tokenizer | 文本转 token |
| image processor | 图片转 tensor |
| chat template | 构建对话格式 |
- 例如:
"你好"
↓
[108386, 3837]
- 图片则会被:
读取
↓
resize
↓
normalize
↓
Tensor化
3-4 构建输入 messages
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "cat.png"
},
{
"type": "text",
"text": "请描述这张图片"
}
]
}
]
- 这里对照Qwen-VL 对话格式设置就行。
"role"表示消息角色:
| role | 含义 |
|---|---|
| user | 用户 |
| assistant | AI |
| system | 系统提示 |
"content"部分支持混合输入:
| type | 含义 |
|---|---|
| image | 图片 |
| text | 文本 |
| video | 视频 |
3-5 Chat Template 处理
text = processor.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
- 该步骤会把
messages转换成模型真正能够理解的输入格式。 tokenize=False- 暂时不进行 token 化
- 先生成完整字符串
add_generation_prompt=True- 自动添加 assistant 回复起始标记
- 告诉模型现在应该开始生成回答
3-6 提取图片/视频数据
image_inputs, video_inputs = process_vision_info(messages)
- 由于 VLM 模型不仅处理文本,还需要处理视觉输入,因此需要额外提取图片信息。
3-7 Tensor输入
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt"
)
- 最核心的一步,把文本+图片统一编码成模型输入
Tensor - 因为模型的最终输入不是图片也不是字符串,是
Tensor
3-8 推理
generated_ids = model.generate(
**inputs,
max_new_tokens=128
)
- 这一步是真正的大模型推理阶段,这里采用了自回归生成(Auto-Regressive Generation)
- 模型会:
输入上下文
↓
预测下一个 token
↓
加入上下文
↓
继续预测
常见参数:
| 参数 | 作用 |
|---|---|
| max_new_tokens | 最大生成 token 数 |
| temperature | 随机性 |
| top_p | nucleus sampling |
| top_k | 候选token数量 |
| do_sample | 是否随机采样 |
- 注意
token数不是汉字数
3-9 去掉输入部分
generated_ids_trimmed = [
out_ids[len(in_ids):]
for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
- 由于
generate返回的是输入 + 输出,因此这里需要进行裁切。
3-10 解析内容
output_text = processor.batch_decode(
generated_ids_trimmed,
skip_special_tokens=True,
clean_up_tokenization_spaces=False
)
- 由于模型的输出是
token id,因此这里需要把token id转换为文字 skip_special_tokens=True表示删除特殊 tokenclean_up_tokenization_spaces=False表示不自动清理空格,保持原始生成结果
3-11 输出
print(output_text[0])
- 最终输出模型生成的文字内容。
3-12 完成流程
总结
- 本文完成了基于 CUDA 与 Transformers 的 Qwen2.5-VL 本地部署,并结合完整代码详细分析了多模态大模型从图片输入、文本编码到最终生成回答的完整推理流程。
- 如有错误,欢迎指出!
- 感谢观看


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)