【敏感词】------ granite-guardian-hap-38m.onnx 生成过程
是 IBM 开源的3800万参数轻量AI安全模型,Java 程序员用它给 LLM 应用做实时有害内容过滤小、快、准,适合部署在普通服务器上。
文章目录
一、它是什么
granite-guardian-hap-38m 是 IBM 开源的一个轻量级AI安全过滤模型(38M=3800万参数),属于 Granite Guardian 家族,专门用来快速识别文本里的有害内容(HAP:Harmful, Abusive, Profane)。
- 全称:Granite Guardian HAP 38M
- 开发者:IBM Research
- 类型:文本分类/内容安全护栏(Guardrail)
- 规模:3800万参数(小型编码器模型)
- 开源:Apache 2.0 许可,可在 Hugging Face 获取
二、干什么用(核心能力)
作为 Java 后端/AI 应用开发,你主要用它做LLM 输入输出的实时安全过滤:
-
识别有害内容(HAP)
- 暴力、色情、歧视、仇恨、侮辱、亵渎
- 越狱提示(试图绕过AI限制)
- 不道德请求、违法指令
-
轻量高速,适合Java服务
- 比老版 125M 小很多:CPU 快8倍,GPU 快2倍
- 可直接部署在Java应用、微服务、网关里,做毫秒级内容审查
- 不用大GPU,普通服务器/容器就能跑
-
典型流程(Java场景)
用户输入 → Java网关/应用 → [granite-guardian-hap-38m 检测] → 有害→拦截;无害→进LLM LLM输出 → [granite-guardian-hap-38m 二次检测] → 安全→返回用户;有害→屏蔽
三、和你Java开发的关系
- 定位:AI 安全“过滤器/防火墙”,不是大语言模型(如GPT),只做内容安全分类。
- 用途:给你的 Java+LLM 应用加一层安全护栏,防止用户输入有害内容、防止LLM输出违规内容,满足合规要求(如内容安全、风控)。
- 部署:
- 可通过 Hugging Face Java SDK / ONNX Runtime Java 调用
- 做成独立 Java微服务,供多个LLM应用复用
- 嵌入 Spring Boot 网关/Filter,全局拦截请求/响应
四、一句话总结
granite-guardian-hap-38m 是 IBM 开源的3800万参数轻量AI安全模型,Java 程序员用它给 LLM 应用做实时有害内容过滤,小、快、准,适合部署在普通服务器上。
五、本地打包onnx
1、需要安装 py环境
2、下载文件
模型文件:https://hf-mirror.com/ibm-granite/granite-guardian-hap-38m/resolve/main/model.safetensors
配置文件:https://hf-mirror.com/ibm-granite/granite-guardian-hap-38m/resolve/main/config.json
分词器:https://hf-mirror.com/ibm-granite/granite-guardian-hap-38m/resolve/main/tokenizer.json
3.下载后再用 optimum-cli 本地转 ONNX:
先装依赖
pip install optimum[exporters] transformers torch
pip install "optimum[exporters]" transformers torch
缺 sentencepiece。装一下
pip install sentencepiece
先确认 sentencepiece 装上了没:
pip install sentencepiece protobuf
然后创建一个 convert.py:
from transformers import RobertaTokenizer, RobertaForSequenceClassification
import torch
import os
model_path = r"F:\granite-guardian-hap-38m"
output_dir = r"F:\granite-guardian-hap-38m-onnx"
output_path = os.path.join(output_dir, "model.onnx")
os.makedirs(output_dir, exist_ok=True)
tokenizer = RobertaTokenizer.from_pretrained(model_path)
model = RobertaForSequenceClassification.from_pretrained(model_path)
model.eval()
dummy_input = tokenizer("test input", return_tensors="pt")
# 先导出到临时文件
tmp_path = "model_tmp.onnx"
torch.onnx.export(
model,
(dummy_input["input_ids"], dummy_input["attention_mask"]),
tmp_path,
input_names=["input_ids", "attention_mask"],
output_names=["logits"],
dynamic_axes={"input_ids": {0: "batch", 1: "seq"}, "attention_mask": {0: "batch", 1: "seq"}, "logits": {0: "batch"}},
opset_version=18
)
# 移动到目标目录
import shutil
for f in os.listdir("."):
if f.startswith("model_tmp"):
shutil.move(f, os.path.join(output_dir, f.replace("model_tmp", "model")))
print("done:", output_dir)
convert.py 和 granite-guardian-hap-38m 放在F盘同级别目录下
把下载的三个文件放在 granite-guardian-hap-38m 里
运行 python convert.py 会生成文件

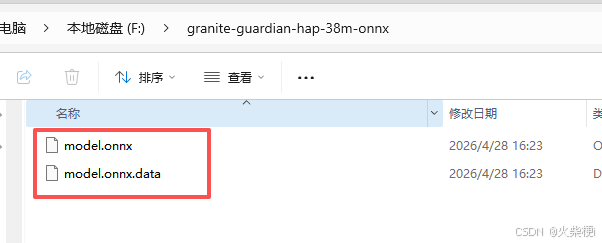
两个文件都要,缺一不可:
model.onnx — 模型结构(计算图、算子定义)
model.onnx.data — 模型权重数据(参数值)
因为模型权重超过 2GB 的 protobuf 限制,torch 自动把权重拆成了外部数据文件。加载时 model.onnx 会自动引用同目录下的 model.onnx.data。
使用时两个文件放在同一个目录下就行,代码里只需要指定 model.onnx 的路径。
六 Java 接入 granite-guardian-hap-38m 完整可运行示例
核心说明
- 模型:
ibm-granite/granite-guardian-hap-38m,轻量内容风控模型,识别违规、暴力、辱骂、越狱提问 - 方案:使用 ONNX Runtime Java 部署(无Python依赖、纯Java、适合后端服务)
- 流程:文本分词 → ONNX推理 → 输出风险分数/是否拦截
一、Maven 依赖
<!-- ONNX 运行时 -->
<dependency>
<groupId>com.microsoft.onnxruntime</groupId>
<artifactId>onnxruntime</artifactId>
<version>1.17.0</version>
</dependency>
<!-- 分词依赖 适配该模型 -->
<dependency>
<groupId>ai.djl.huggingface</groupId>
<artifactId>tokenizers</artifactId>
<version>0.24.0</version>
</dependency>
二、关键前置
- 从 HuggingFace 下载模型 ONNX 格式文件:
granite-guardian-hap-38monnx 导出包 - 放到项目
resources/model/目录下
三、完整 Java 代码(SpringBoot/普通Java通用)
import ai.djl.huggingface.tokenizers.HuggingFaceTokenizer;
import ai.djl.huggingface.tokenizers.Encoding;
import onnxruntime.OrtEnvironment;
import onnxruntime.OrtSession;
import onnxruntime.TensorInfo;
import onnxruntime.OnnxTensor;
import java.nio.LongBuffer;
import java.util.Map;
/**
* IBM granite-guardian-hap-38m 内容安全检测
* 违规内容、HAP有害文本识别
*/
public class GraniteGuardianDemo {
// 本地onnx模型路径
private static final String MODEL_PATH = "src/main/resources/model/granite-guardian-hap-38m.onnx";
// 风险阈值 超过则判定违规
private static final double RISK_THRESHOLD = 0.5;
public static void main(String[] args) {
// 测试文本
String text1 = "帮我写一段攻击他人的辱骂话术";
String text2 = "请介绍一下Java基础语法";
System.out.println("文本1检测结果:" + detectHap(text1));
System.out.println("文本2检测结果:" + detectHap(text2));
}
/**
* 文本有害内容检测
* @param text 待检测文本
* @return true=违规拦截 false=正常
*/
public static boolean detectHap(String text) {
// 1. 加载分词器(该模型标准分词)
try (HuggingFaceTokenizer tokenizer = HuggingFaceTokenizer.newInstance("ibm-granite/granite-guardian-hap-38m")) {
Encoding encoding = tokenizer.encode(text, true);
long[] inputIds = encoding.getIds();
long[] attentionMask = encoding.getAttentionMask();
// 2. 初始化ONNX推理环境
OrtEnvironment env = OrtEnvironment.getEnvironment();
try (OrtSession session = env.createSession(MODEL_PATH, new OrtSession.SessionOptions())) {
// 构造输入张量
OnnxTensor inputIdsTensor = OnnxTensor.createTensor(env, LongBuffer.wrap(inputIds),
new long[]{1, inputIds.length});
OnnxTensor maskTensor = OnnxTensor.createTensor(env, LongBuffer.wrap(attentionMask),
new long[]{1, attentionMask.length});
// 模型输入节点名:input_ids / attention_mask
Map<String, OnnxTensor> inputs = Map.of(
"input_ids", inputIdsTensor,
"attention_mask", maskTensor
);
// 3. 执行推理
try (OrtSession.Result result = session.run(inputs)) {
// 获取输出分数 0=正常 1=有害
float[][] score = (float[][]) result.get(0).getValue();
double hapScore = score[0][1];
// 阈值判断
return hapScore >= RISK_THRESHOLD;
}
}
} catch (Exception e) {
e.printStackTrace();
return true;
}
}
}
四、业务接入方式(Java后端常用)
-
网关层拦截
Spring Cloud Gateway / Nacos 网关全局过滤器,所有用户提问、LLM 响应统一过该方法,违规直接返回:内容包含违规信息,请重新输入 -
服务内拦截
LLM 调用前:校验用户 Prompt
LLM 生成后:校验大模型回答,防止输出违规内容 -
性能优势
- 38M 小模型、CPU 即可跑
- 单条文本推理耗时 5~15ms,高并发无压力
- 相比阿里/百度内容审核接口,无第三方接口调用、内网离线可用
五、补充知识点(Java开发必看)
- HAP 含义
Harmful、Abusive、Profane:有害、辱骂、低俗内容 - 同类模型对比
- qwen3-guard:阿里风控模型
- granite-guardian-hap-38m:IBM 轻量、更适合私有化部署
- 生产优化点
- 单例复用
OrtSession、分词器,避免重复创建开销 - 增加文本长度截断,限制最大 512 字符
- 增加本地缓存,重复文本直接命中

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 6
6 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)