大模型网络服务部署
本文为零基础用户提供详细教程,指导如何将本地LangChain大模型应用部署为可访问的网络服务。教程分为两套方案:LangServer构建后端API接口和Gradio创建前端网页界面。内容涵盖必备知识(Python、依赖库、LangChain框架等概念)、环境配置(Python安装、API密钥获取)、代码编写(逐行注释的翻译工具实现)以及服务部署步骤。通过实战演示,用户可学会创建翻译服务API和可
核心说明:本文全程以“零基础”为前提,不跳过任何一个细节、不省略任何一句关键说明,所有知识点在原文基础上补充扩展,代码逐行注释、运行过程分步拆解、中间结果明确展示,同时详细讲解所有必备前置知识,确保完全不懂编程、不懂大模型的人,跟着步骤也能学会如何部署大模型网络服务。
本文核心目标:把本地的大模型应用(基于LangChain框架),变成“能通过网页访问、能给别人用”的网络服务/可视化界面,全程分2套极简方案讲解——LangServer(做后端接口,供程序调用)和Gradio(做前端页面,供人直接操作),从基础概念到代码运行,一步不落。
一、必备前置知识(必看,详细到每一个概念)
在开始学习部署之前,必须先搞懂这些基础概念,否则后面的代码和步骤会完全看不懂。我会用“生活化例子”讲解,不搞专业术语堆砌,确保能理解。
1. 什么是Python?(核心工具)
简单说:Python是一种“编程语言”,就像我们和电脑沟通的“普通话”。我们写的代码,就是用Python告诉电脑“要做什么”,电脑能看懂Python指令,然后执行相应操作。
必备要求:需要先安装Python(版本≥3.10,后面会说安装方法),因为本文所有代码都需要用Python运行。
补充:我们写的Python代码,会保存成“.py”后缀的文件(比如myserver.py),运行这个文件,电脑就会按照代码里的指令做事。
2. 什么是“依赖/库”?(代码的“工具包”)
简单说:依赖(也叫“库”“包”)就是别人已经写好的、现成的Python代码,我们不需要自己从零写,直接“拿来用”就行,能节省大量时间。
比如:我们要做“翻译功能”,不需要自己写“识别英文、转换成中文”的代码,直接用别人写好的“LangChain”“LangServer”这些依赖,就能快速实现。
如何安装依赖?用Python自带的“pip”工具(安装Python时会自动安装),在“命令提示符”(Windows)或“终端”(Mac)里输入指定命令,就能自动下载、安装依赖。比如后面会用到的“pip install langserve[all]”,就是告诉电脑“下载并安装LangServer相关的所有工具包”。
注意:“命令提示符”怎么打开?Windows系统按“Win+R”,输入“cmd”,回车就能打开;Mac系统按“Command+空格”,输入“终端”,回车打开。
3. 什么是LangChain?(核心框架)
简单说:LangChain是一个“大模型工具框架”,它就像一个“积木盒”,里面有各种现成的“积木”(比如提示词模板、模型调用工具、结果解析工具),我们只要把这些“积木”拼起来,就能快速做出一个“大模型应用”(比如翻译工具、对话机器人)。
举例子:我们要做一个“英文转中文”的翻译工具,不需要自己写“连接大模型、处理输入输出”的代码,用LangChain的“提示词模板”(告诉大模型要做翻译)、“大模型调用”(连接阿里云百炼大模型)、“输出解析器”(把大模型的输出变成干净的文本),拼起来就能实现翻译功能——这就是后面会写的“Chain(链)”。
4. 什么是API?(程序之间的“沟通桥梁”)
简单说:API就是两个程序之间“沟通的接口”,就像你去餐厅吃饭,你不用直接进厨房找厨师,而是通过“服务员”下单、拿菜——服务员就是你和厨师之间的“接口”。
本文中:我们用LangServer把大模型应用(翻译工具)做成“API服务”,这个服务就相当于“服务员”,其他程序(比如前端页面、手机APP)可以通过这个“服务员”,调用我们的翻译功能,而不用直接接触我们写的核心代码。
5. 什么是Web服务?(能通过网页访问的服务)
简单说:Web服务就是“能通过浏览器访问的服务”,比如我们平时用的百度、微信公众号,都是Web服务——你打开浏览器,输入一个网址,就能访问到对应的功能。
本文中:LangServer部署的是“后端Web服务”(主要供程序调用,也有简单的调试网页),Gradio部署的是“前端Web服务”(供人直接通过网页操作,比如输入文本、点击按钮,就能看到翻译结果)。
6. 什么是IP地址和端口?(Web服务的“地址和门牌号”)
必懂:我们部署的Web服务,就像你家的房子,需要一个“地址”(IP地址)和“门牌号”(端口),别人才能找到它。
-
IP地址:本文中常用的“127.0.0.1”,是“本地IP地址”,意思是“只有你自己的电脑能访问这个服务”;如果改成“0.0.0.0”,同一个局域网里的其他电脑(比如你家的笔记本、手机)也能访问。
-
端口:就像你家的门牌号(比如8000、7860),一个电脑上可以部署多个Web服务,每个服务需要一个唯一的端口,避免“混淆”。比如LangServer用8000端口,Gradio用7860端口,这样电脑就能区分开两个不同的服务。
举例子:“http://127.0.0.1:8000/docs”这个网址,拆解一下:
-
http:访问Web服务的“协议”(相当于沟通的规则);
-
127.0.0.1:本地IP地址(只有自己能访问);
-
8000:端口号(门牌号);
-
docs:具体的访问路径(相当于你家的某个房间)。
7. 前置准备操作(必须先做这一步)
在开始写代码、部署服务之前,必须先完成以下准备,否则后面会报错:
(1)安装Python(版本≥3.10)
-
打开Python官方网站:https://www.python.org/downloads/,下载对应系统的Python安装包(Windows选“Windows Installer (64-bit)”,Mac选“macOS 64-bit universal2 installer”);
-
安装时,一定要勾选“Add Python to PATH”(这一步非常重要,否则后面无法在命令提示符里运行Python);
-
安装完成后,打开命令提示符(Windows)/终端(Mac),输入“python --version”,如果显示“Python 3.10.x”或更高版本,说明安装成功。
注意:如果输入“python --version”报错,大概率是没勾选“Add Python to PATH”,可以重新安装,勾选该选项即可。
(2)创建一个“工作文件夹”
在电脑上新建一个文件夹(比如命名为“llm_service”),后面所有的代码文件、配置文件,都放在这个文件夹里,避免文件混乱。
(3)准备API密钥(阿里云百炼)
本文中我们用“阿里云百炼大模型”(免费可试用),需要先获取API密钥,步骤如下:
-
打开阿里云百炼官网:https://bailian.aliyun.com/,注册并登录账号;
-
登录后,进入“控制台”,找到“API密钥”,创建一个密钥(会得到“Access Key ID”和“Access Key Secret”,也就是后面要用的“BAILIAN_API_KEY”);
-
把获取到的API密钥保存好,后面写代码时会用到(相当于“登录大模型的密码”)。
注意:如果不想用阿里云百炼,也可以用其他支持OpenAI兼容模式的大模型,替换代码里的“model”和“base_url”即可。
(4)安装代码编辑器(可选,但推荐)
可以用“记事本”写代码,但推荐安装“VS Code”(免费、简单、好用),步骤:
-
打开VS Code官网:https://code.visualstudio.com/,下载并安装;
-
安装后,打开VS Code,安装“Python”插件(左侧菜单栏点击“扩展”,搜索“Python”,安装第一个即可);
-
打开我们新建的“llm_service”文件夹,后续所有代码都在VS Code里编写、保存。
二、核心总览
我们全程要做的事情,用一句话总结:用LangChain拼一个“翻译工具”(大模型应用),然后用LangServer把它做成“后端API服务”(供程序调用),再用Gradio把它做成“前端网页”(供人操作),最终实现“打开网页就能用翻译功能”。
-
技术栈:Python(工具)+ LangChain(拼大模型应用)+ LangServer(做后端API)+ Gradio(做前端网页);
-
核心流程:安装依赖 → 用LangChain做翻译应用 → 用LangServer部署API服务 → 用Gradio部署前端网页;
-
最终效果:
-
打开浏览器,输入“http://127.0.0.1:8000/docs”,能调试翻译API;
-
打开浏览器,输入“http://127.0.0.1:7860”,能通过网页输入文本,点击按钮得到翻译结果。
-
三、LangServer 构建大模型API服务(后端服务,供程序调用)
LangServer的作用:把我们用LangChain做的“翻译工具”,变成一个“API服务”,这样其他程序(比如前端网页、手机APP)就能通过这个服务调用翻译功能。全程能跟着操作,每一步都有详细说明。
1. LangServer 核心理解(版)
LangServer是一个“现成的工具包”,我们不需要自己写“如何把翻译工具变成API服务”的代码,只要按照它的规则,把我们做的“翻译工具”(Chain)绑定到它上面,它就能自动生成API接口、调试网页,非常简单。
核心优势:不用懂“如何写Web服务”,10行左右代码就能完成部署,还能自动生成调试工具。
2. 第一步:安装LangServer相关依赖
我们需要安装LangServer的依赖(工具包),才能使用它。步骤如下:
-
打开命令提示符(Windows)/终端(Mac);
-
输入以下命令(复制粘贴即可),安装依赖:
# 1. 仅安装服务端(如果只需要部署API服务,用这个)
pip install "langserve[server]"
# 2. 仅安装客户端(如果只需要远程调用别人的API服务,用这个)
pip install "langserve[client]"
# 3. 全量安装(服务端+客户端,推荐用这个,后续调试、调用都方便)
pip install "langserve[all]"
# 补充:还要安装LangChain、阿里云百炼相关依赖(避免后续报错)
pip install langchain langchain-openai python-dotenv注意:
-
输入命令后,按回车,电脑会自动下载、安装依赖,过程可能需要1-5分钟(取决于网络速度);
-
如果出现“pip不是内部或外部命令”,说明Python安装时没勾选“Add Python to PATH”,重新安装Python并勾选该选项即可;
-
安装完成后,没有报错,就说明依赖安装成功。
中间过程示例(可以参考,确认自己安装成功):
输入命令后,终端会显示“Collecting langserve[all]”“Downloading xxx.whl”等信息,最后显示“Successfully installed langserve-xxx ...”,就说明安装成功。
3. 第二步:用LangChain构建“翻译工具”(核心Chain)
这一步我们用LangChain的“积木”,拼一个“英文转中文”的翻译工具,这是后面部署API服务的核心。我们会把代码写在一个“.py”文件里,逐行注释,详细讲解每一行代码的含义、作用,以及运行后的结果。
(1)新建代码文件
打开VS Code,进入我们新建的“llm_service”文件夹,新建一个文件,命名为“translation_chain.py”(后缀必须是.py,代表Python文件)。
(2)编写代码(逐行注释+含义讲解)
# 1. 导入需要的工具包(积木)
# 从LangChain的核心模块中,导入“字符串输出解析器”——作用是把大模型的输出,变成干净的纯文本
from langchain_core.output_parsers import StrOutputParser
# 导入“聊天提示词模板”——作用是告诉大模型“要做什么”(比如“帮我翻译”)
from langchain_core.prompts import ChatPromptTemplate
# 导入“环境变量加载工具”——作用是安全管理API密钥(避免直接写在代码里,泄露密码)
from dotenv import load_dotenv
# 导入“操作系统工具”——作用是读取环境变量里的API密钥
import os
# 导入“ChatOpenAI”——作用是连接大模型(支持阿里云百炼、OpenAI等兼容OpenAI协议的模型)
from langchain_openai import ChatOpenAI
# 2. 加载环境变量(安全管理API密钥)
# 加载当前文件夹下的“.env”文件(后面会创建这个文件,存放API密钥)
load_dotenv()
# 从环境变量中读取阿里云百炼的API密钥(相当于“登录大模型的密码”)
bailian_api_key = os.getenv("BAILIAN_API_KEY")
# 3. 创建提示词模板(告诉大模型“要做什么”)
# from_messages:用“列表”的形式,定义提示词(system是系统提示,user是用户输入)
prompt_template = ChatPromptTemplate.from_messages([
# system提示:告诉大模型“你的角色是翻译员,要把英文翻译成指定语言”
("system", "Translate the following from English into {language}"),
# user提示:告诉大模型“用户输入的文本是要翻译的内容”({text}是占位符,后面会替换成用户输入的文本)
("user", "{text}")
])
# 提示词模板的作用:让大模型知道“自己要做翻译”,并且能接收“目标语言”和“待翻译文本”两个输入
# 4. 连接阿里云百炼大模型(核心步骤)
llm = ChatOpenAI(
model="qwen-plus", # 要使用的大模型名称(阿里云百炼的“通义千问Plus”模型)
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", # 阿里云百炼的兼容接口地址(固定写法)
openai_api_key=bailian_api_key, # 刚才读取的API密钥(登录大模型的凭证)
)
# 这一步的作用:建立和大模型的连接,后面我们就能通过这个“llm”对象,调用大模型的翻译功能
# 5. 创建输出解析器(处理大模型的输出)
parser = StrOutputParser()
# 大模型的原始输出可能有多余的格式、元数据,parser的作用是“过滤掉多余内容,只保留纯文本翻译结果”
# 6. 拼接Chain(把“提示词模板+大模型+输出解析器”拼起来,形成完整的翻译工具)
# 用“|”(管道符)拼接,意思是“数据从左到右流转”:
# 用户输入 → 提示词模板(生成完整提示) → 大模型(处理翻译) → 输出解析器(处理结果) → 最终输出
chain = prompt_template | llm | parser
# 7. 测试Chain(验证翻译工具是否能正常工作,必做这一步)
# 调用chain的invoke方法,传入“目标语言”和“待翻译文本”两个参数
test_result = chain.invoke({"text": "nice to meet you", "language": "Chinese"})
# 打印测试结果(看看翻译是否成功)
print("测试翻译结果:", test_result)
# 补充:如果测试成功,终端会输出“测试翻译结果: 很高兴认识你”;
# 如果测试失败,大概率是API密钥错误、base_url错误,或者网络问题,检查这几点即可。(3)创建“.env”文件(安全存放API密钥)
为什么要创建这个文件?因为如果把API密钥直接写在代码里,不小心分享代码时,密钥会泄露,别人就能用你的密钥调用大模型(可能产生费用)。用“.env”文件存放密钥,更安全。
-
在“llm_service”文件夹里,新建一个文件,命名为“.env”(注意前面有个小数点,没有后缀);
-
打开“.env”文件,输入以下内容(替换成你自己的阿里云百炼API密钥):
BAILIAN_API_KEY=你的阿里云百炼API密钥(比如:LTAI5txxxxxxxxxxxxxxx)
注意:不要在密钥前后加空格、引号,直接写密钥内容即可。
(4)运行代码,查看测试结果
步骤:
-
打开命令提示符/终端,进入“llm_service”文件夹(输入“cd 你的文件夹路径”,比如“cd C:\llm_service”);
-
输入命令:“python translation_chain.py”,按回车运行代码;
-
查看运行结果:
正常结果(成功):终端会输出“测试翻译结果: 很高兴认识你”(不同大模型的翻译结果可能略有差异,只要符合语义就没问题)。
常见错误及解决:
-
报错“API key not provided”:说明.env文件里的密钥没写对,或者文件名称不对(必须是“.env”);
-
报错“Connection error”:说明网络有问题,或者base_url写错了(阿里云百炼的base_url是固定的,不要改);
-
报错“Model not found”:说明model参数写错了,阿里云百炼的模型名称是“qwen-plus”,不要改。
注意:只有这一步测试成功,才能进行下一步部署服务,否则后面会报错。
4. 第三步:构建LangServer服务端(把翻译工具变成API服务)
这一步我们会新建一个代码文件,编写服务端代码,把刚才测试成功的“翻译Chain”,绑定到LangServer上,启动服务后,就能通过浏览器访问API接口了。
(1)新建服务端代码文件
在“llm_service”文件夹里,新建一个文件,命名为“langserver_server.py”。
(2)编写服务端代码
# 1. 导入需要的工具包
# 导入FastAPI——LangServer的底层Web框架,用来构建Web服务
from fastapi import FastAPI
# 导入add_routes——LangServer的核心函数,用来把Chain绑定到Web服务上
from langserve import add_routes
# 导入uvicorn——用来启动Web服务的工具(相当于“启动服务的开关”)
import uvicorn
# 导入我们刚才写的“翻译Chain”(从translation_chain.py文件中导入)
from translation_chain import chain
# 导入环境变量加载工具(避免重复写加载密钥的代码)
from dotenv import load_dotenv
# 2. 加载环境变量(确保能正常调用大模型)
load_dotenv()
# 3. 创建FastAPI应用实例(相当于“创建一个Web服务的容器”)
app = FastAPI(
title="大模型语言翻译助手", # 服务的名称(会显示在API文档页面上)
version="v1.0", # 服务的版本号
description="基于LangChain+LangServer构建的翻译API服务,也能部署" # 服务的描述
)
# 4. 核心步骤:把翻译Chain绑定到Web服务上,生成API接口
add_routes(
app, # 刚才创建的FastAPI应用(容器)
chain, # 我们要暴露的翻译Chain(翻译工具)
path="/langchainDemo" # API接口的访问路径(后面访问API时会用到,比如http://127.0.0.1:8000/langchainDemo)
)
# 这一步的作用:LangServer会自动根据Chain的输入输出,生成API接口,还会自动生成API文档和调试页面
# 5. 启动Web服务(关键步骤)
if __name__ == "__main__":
uvicorn.run(
app, # 要启动的FastAPI应用
host="0.0.0.0", # 访问地址:0.0.0.0表示同一局域网内的设备都能访问;如果改成127.0.0.1,只有自己的电脑能访问
port=8000 # 服务的端口号(门牌号),可以改成8080、8001等,只要不被其他服务占用即可
)
# 代码运行说明:
# 1. 运行这个文件后,Web服务会启动,终端会显示服务的访问地址;
# 2. 服务启动后,不能关闭终端(关闭终端,服务就停了);
# 3. 如果提示“端口已被占用”,把port改成其他数字(比如8001),再重新运行。(3)运行服务端代码,启动Web服务
步骤:
-
确保命令提示符/终端,还是在“llm_service”文件夹下;
-
输入命令:“python langserver_server.py”,按回车运行;
-
查看运行结果(启动成功的标志):
langserver_server.py:
from fastapi import FastAPI
from langserve import add_routes
import uvicorn
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from config.load_key import load_key
from langchain_openai import ChatOpenAI
# --------------------- 构建大模型链 ---------------------
prompt_template = ChatPromptTemplate.from_messages([
("system", "Translate the following from English into {language}"),
("user", "{text}")
])
llm = ChatOpenAI(
model="qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
openai_api_key=load_key("BAILIAN_API_KEY"),
)
parser = StrOutputParser()
chain = prompt_template | llm | parser
# --------------------- 创建 FastAPI 应用并挂载路由 ---------------------
app = FastAPI(
title="大模型语言翻译助手",
version="v1.0",
description="基于LangChain框架构建的大模型语言翻译助手"
)
add_routes(app, chain, path="/langchainDemo")
# --------------------- 启动服务 ---------------------
if __name__ == "__main__":
# 可选:启动前本地测试一下
print(chain.invoke({"text": "nice to meet you", "language": "Chinese"}))
uvicorn.run(app, host="0.0.0.0", port=8000)终端会显示类似以下内容:
INFO: Started server process [12345] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
注意:
-
启动成功后,终端会一直显示上面的内容,不要关闭终端(关闭终端,服务就停止了);
-
如果报错“ImportError: cannot import name 'chain' from 'translation_chain'”,说明“translation_chain.py”文件和“langserver_server.py”文件不在同一个文件夹里,检查文件夹路径;
-
如果报错“Address already in use”,说明8000端口被其他服务占用,修改代码里的“port=8001”,再重新运行。
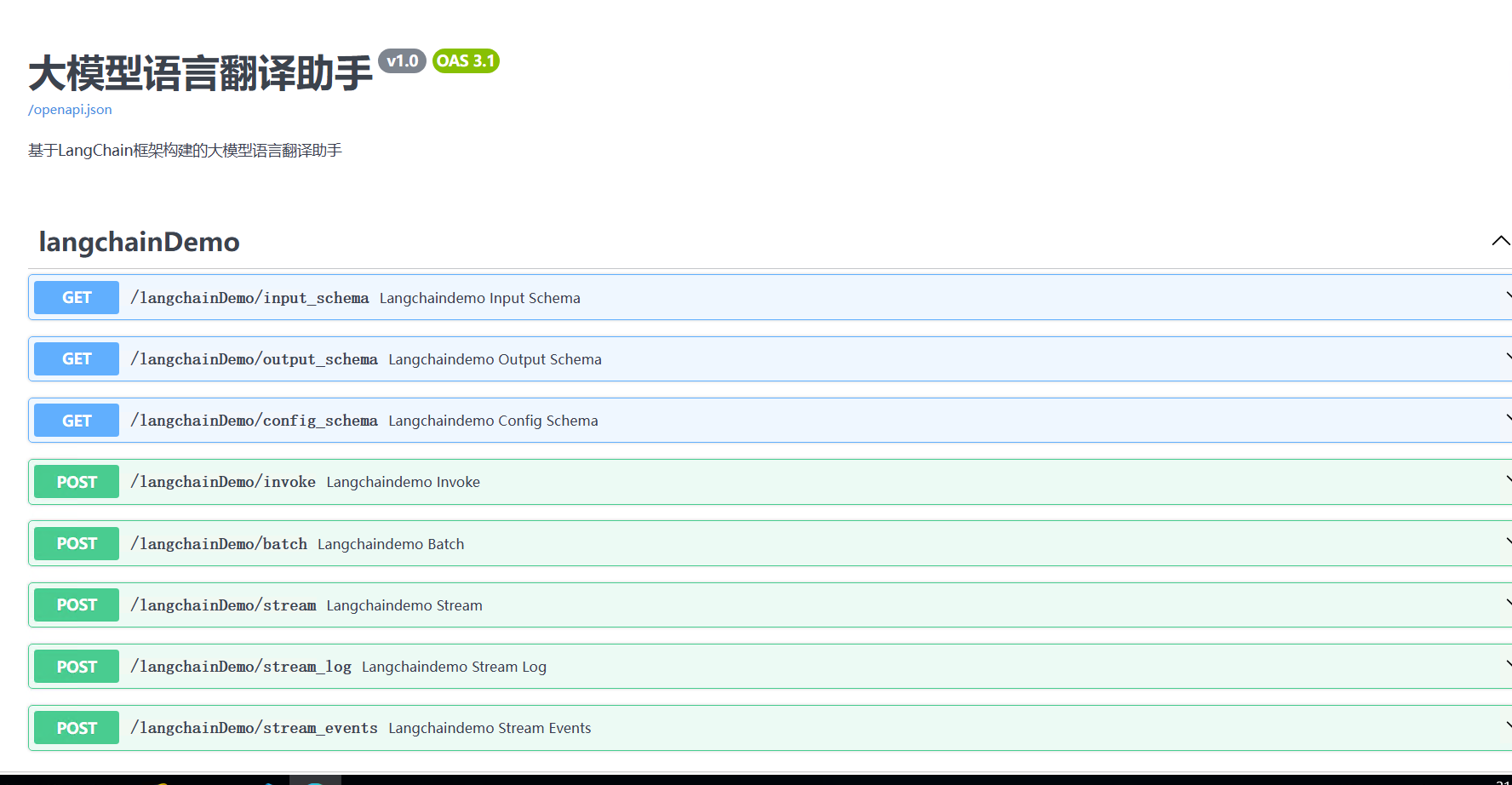
5. 第四步:访问LangServer服务(3种方式,都能操作)
服务启动后,我们可以通过3种方式访问它,验证服务是否正常工作,每一种方式都详细讲解操作步骤和结果。
方式1:访问API文档页面(调试API,首选)
-
打开浏览器(比如Chrome、Edge);
-
在地址栏输入:“http://127.0.0.1:8000/docs”(如果端口改了,就把8000改成你改的端口);
-
进入页面后,找到“/langchainDemo”相关的接口(我们刚才绑定的路径),点击“Try it out”(尝试调试);
-
在“Request body”里,输入以下内容(替换成你想翻译的文本):
{ `` "text": "how are you", `` "language": "Chinese" ``} -
点击“Execute”(执行),等待1-2秒,就能看到“Response body”里的翻译结果(比如“你好吗”);
-
结果说明:这就是API接口的调试过程,后面如果其他程序要调用我们的翻译服务,就是通过这个接口传递参数、获取结果。
方式2:访问交互式Playground(可视化调试,不用写代码)
-
打开浏览器,输入地址:“http://127.0.0.1:8000/langchainDemo/playground/”;
-
进入页面后,会看到两个输入框,分别输入“目标语言”(比如Chinese)和“待翻译文本”(比如I love you);
-
点击“Run”按钮,就能看到下面的输出结果(比如“我爱你”);
-
优势:不用写代码,直接在网页上就能测试翻译功能,非常方便。
方式3:用客户端代码调用(远程调用,模拟其他程序调用)
我们可以新建一个客户端代码文件,模拟“其他程序”调用我们部署的API服务,步骤如下:
-
在“llm_service”文件夹里,新建一个文件,命名为“langserver_client.py”;
-
编写客户端代码(逐行注释):
# 导入LangServer的客户端工具(RemoteRunnable),用来远程调用API服务
from langserve import RemoteRunnable
# 1. 绑定我们部署的API服务地址(注意:服务必须处于启动状态,否则调用失败)
# 地址格式:http://IP地址:端口号/接口路径
client = RemoteRunnable("http://127.0.0.1:8000/langchainDemo")
# 2. 调用API服务,传入参数(和我们测试Chain时的参数一样)
result = client.invoke({
"text": "I am a student", # 待翻译文本
"language": "Chinese" # 目标语言
})
# 3. 打印调用结果
print("客户端调用API结果:", result)
# 运行说明:
# 1. 必须确保“langserver_server.py”正在运行(终端没有关闭);
# 2. 运行这个客户端文件,就能看到翻译结果;
# 3. 中间过程:客户端发送请求到API服务 → 服务调用翻译Chain → 服务返回结果 → 客户端打印结果。-
运行客户端代码:在命令提示符/终端输入“python langserver_client.py”,按回车;
-
正常结果:终端输出“客户端调用API结果: 我是一名学生”。
注意:如果调用失败,先检查服务是否启动,再检查服务地址、端口号是否正确。
6. LangServer 关键注意事项(必看,避免踩坑)
-
❌ 不能在Jupyter Notebook里启动服务:Jupyter本身就是一个Web服务,你不能在一个Web服务里再启动另一个Web服务,必须把代码保存成独立的.py文件,在命令提示符/终端里运行;
-
✅ 服务启动后,终端不能关闭:关闭终端,服务就会停止,别人就无法访问你的API服务了;
-
✅ 端口占用解决:如果提示“端口已被占用”,修改代码里的“port”参数(比如8001、8080),再重新启动服务;
-
✅ 局域网访问:如果想让同一个局域网里的其他设备(比如手机、笔记本)访问你的服务,把代码里的“host=0.0.0.0”,然后让其他设备输入“你的电脑IP:端口号/docs”(比如192.168.1.100:8000/docs);
-
❌ 外网访问:本文部署的服务只能在本地/局域网访问,如果想让外网(比如别人的电脑)访问,需要进行额外的配置(比如端口映射),暂时不用考虑。
四、Gradio 快速构建大模型前端页面(前端服务,供人直接操作)
Gradio的作用:把我们的“翻译工具”,做成一个“可视化网页”,不用写代码、不用调试API,只要打开网页,输入文本、点击按钮,就能得到翻译结果。全程零前端基础,纯Python代码实现。
1. Gradio 核心理解(版)
Gradio是一个“前端页面生成工具包”,它就像一个“现成的网页模板”,我们不需要懂HTML、CSS、JS(前端编程语言),只要用Python代码“告诉它”:页面有什么输入框、什么按钮、什么输出框,它就能自动生成一个完整的网页,非常简单。
核心优势:分钟级就能构建一个可视化网页,不用写一行前端代码,直接对接我们的翻译Chain。
2. 第一步:安装Gradio依赖
和安装LangServer依赖一样,打开命令提示符/终端,输入以下命令,安装Gradio:
# 安装Gradio,要求Python版本≥3.10(我们之前已经安装好了)
# -q:静默安装(不显示太多无关信息),-U:升级到最新版本
pip install -qU gradio注意:安装完成后,没有报错,就说明依赖安装成功。如果报错,检查Python版本是否≥3.10。
3. 第二步:基础用法
先从最简单的例子入手,让熟悉Gradio的用法,了解“输入→处理→输出”的流程,代码逐行注释,运行过程详细讲解。
(1)新建基础示例文件
在“llm_service”文件夹里,新建一个文件,命名为“gradio_basic.py”。
(2)编写代码(逐行注释+运行过程)
# 1. 导入Gradio工具包,并重命名为gr(方便后续调用)
import gradio as gr
# 2. 定义“业务处理函数”——网页上的输入,会传到这个函数里,经过处理后,输出到网页上
# 这里的函数功能:接收“姓名”和“强度”两个输入,返回“Hello, 姓名!!!”(强度决定感叹号的数量)
def greet(name, intensity):
# 拼接返回结果:"Hello, " + 姓名 + "!" * 强度(intensity是数字,比如3,就会有3个感叹号)
return "Hello, " + name + "!" * int(intensity)
# 3. 创建Gradio界面(核心步骤)
# gr.Interface:Gradio的“快速界面模板”,适合简单的“输入→输出”场景
demo = gr.Interface(
fn=greet, # 指定“业务处理函数”(刚才定义的greet函数)
inputs=[ # 定义网页上的输入组件(两个输入:文本框、滑块)
gr.Text(label="姓名"), # 第一个输入:文本框,标签是“姓名”(显示在网页上)
gr.Slider(label="强度", minimum=0, maximum=10, step=1) # 第二个输入:滑块,范围0-10,步长1
],
outputs=[gr.Text(label="输出结果")], # 定义网页上的输出组件(一个文本框,显示处理结果)
live=True # 可选:实时更新,只要输入有变化,就自动触发函数,显示结果
)
# 4. 启动Gradio网页服务
demo.launch(
server_name="0.0.0.0", # 局域网可访问
server_port=7860 # 端口号,和LangServer的8000区分开,避免占用
)
# 代码运行说明:
# 1. 运行这个文件后,会自动生成一个网页地址,复制地址到浏览器就能打开;
# 2. 网页上有“姓名”输入框和“强度”滑块,输入姓名、拖动滑块,就能看到输出结果;
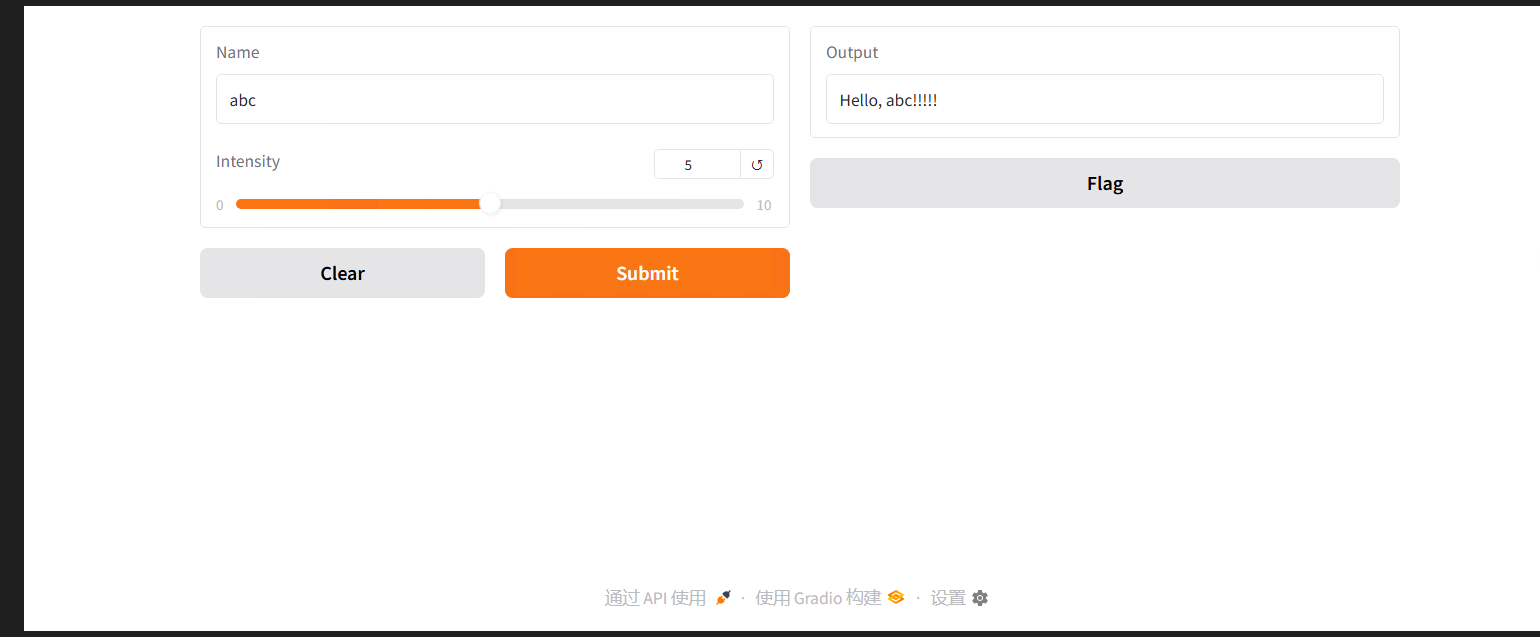
# 3. 服务启动后,终端会显示网页地址,不要关闭终端。(3)运行代码,查看网页效果
-
在命令提示符/终端输入“python gradio_basic.py”,按回车;
-
运行成功后,终端会显示类似以下内容:
Running on local URL: http://0.0.0.0:7860 ``Running on public URL: https://xxxx-xxxx-xxxx-xxxx.gradio.live # 国内一般无法访问,忽略 `` ``To create a public link, setshare=Trueinlaunch(). -
复制“http://0.0.0.0:7860”,打开浏览器,粘贴到地址栏,回车;
-
网页效果:
-
左侧有两个输入框:“姓名”(文本框)、“强度”(滑块);
-
右侧有一个输出框:“输出结果”;
-
操作测试:在“姓名”输入框输入“小明”,把“强度”滑块拖到3,输出框会自动显示“Hello, 小明!!!”(3个感叹号);
-
如果想停止服务,回到终端,按“Ctrl+C”即可。
-
4. 第三步:进阶用法(自定义布局,更灵活)
基础用法适合简单场景,如果想做更复杂的网页(比如多按钮、动态输入框),可以用Gradio的“gr.Blocks”,它支持自定义布局、动态组件,也能轻松上手。
(1)新建进阶示例文件
在“llm_service”文件夹里,新建一个文件,命名为“gradio_advanced.py”。
(2)编写代码
import gradio as gr
# 用gr.Blocks创建自定义布局(比gr.Interface更灵活,支持行列布局、多按钮)
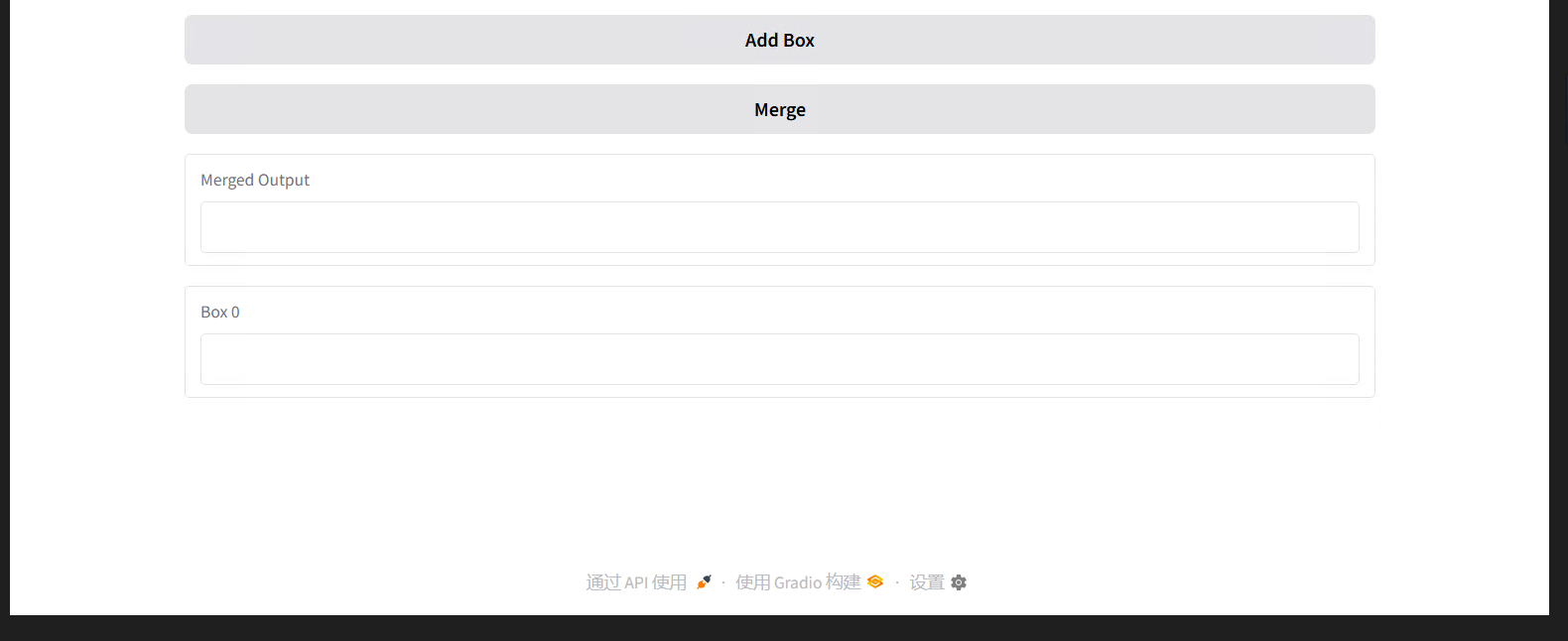
with gr.Blocks(title="动态输入框合并工具") as demo:
# 1. 定义“状态组件”——用来存储临时数据(这里存储输入框的数量)
# 初始值是1,意思是一开始只有1个输入框
text_count = gr.State(1)
# 2. 定义按钮组件(两个按钮:添加输入框、合并文本)
add_btn = gr.Button("添加输入框") # 点击后,增加一个输入框
merge_btn = gr.Button("合并文本") # 点击后,合并所有输入框的内容
# 3. 定义输出组件(显示合并后的文本)
output = gr.Textbox(label="合并结果")
# 4. 给“添加输入框”按钮绑定点击事件
# 点击按钮后,调用lambda函数(匿名函数),把text_count的值+1(输入框数量增加1)
# 格式:按钮.click(处理函数, 输入数据, 输出数据)
add_btn.click(lambda x: x + 1, text_count, text_count)
# 5. 动态渲染输入框(根据text_count的值,生成对应数量的输入框)
# @gr.render(inputs=text_count):监听text_count的变化,一旦变化,就重新渲染输入框
@gr.render(inputs=text_count)
def render_count(count):
# 定义一个列表,用来存储所有输入框
boxes = []
# 循环count次,生成count个输入框
for i in range(count):
# 每个输入框的标签是“输入框 1”“输入框 2”...,key是唯一标识
box = gr.Textbox(key=i, label=f"输入框 {i+1}")
boxes.append(box)
# 定义“合并文本”的函数:接收所有输入框的内容,拼接成一个字符串
def merge(*args):
# args是所有输入框的内容,用空格连接起来
return " ".join(args)
# 给“合并文本”按钮绑定点击事件:调用merge函数,传入所有输入框的内容,输出到output
merge_btn.click(merge, boxes, output)
# 启动服务
demo.launch(server_name="0.0.0.0", server_port=7861) # 用7861端口,和基础示例的7860区分开
# 功能说明:
# 1. 打开网页后,一开始只有1个输入框;
# 2. 点击“添加输入框”,会新增一个输入框(最多可以添加无数个);
# 3. 在每个输入框里输入文本,点击“合并文本”,输出框会显示所有输入框的内容拼接后的结果;
# 4. 这个例子可以让理解“动态组件”的用法,后面我们做翻译网页时会用到类似逻辑。3)运行代码,测试效果
-
输入命令:“python gradio_advanced.py”,按回车;
-
复制终端显示的“http://0.0.0.0:7861”,打开浏览器;
-
测试操作:
-
点击“添加输入框”,会新增一个输入框;
-
在第一个输入框输入“我是”,第二个输入框输入“”,点击“合并文本”;
-
输出框会显示“我是 ”,说明功能正常。
-
5. 第四步:实战(Gradio + LangChain 翻译网页)
这一步我们将Gradio和我们之前写的“翻译Chain”结合起来,做一个“智能翻译网页”,打开网页就能输入英文、选择目标语言,点击按钮得到翻译结果,全程复刻LangServer的Playground,纯Python实现。
(1)新建实战代码文件
在“llm_service”文件夹里,新建一个文件,命名为“gradio_translation.py”。
(2)编写代码(逐行注释+运行过程+结果说明)
# 1. 导入需要的工具包
import gradio as gr
# 导入我们之前写的翻译Chain(核心,不用重新写翻译逻辑)
from translation_chain import chain
# 导入环境变量加载工具(确保能正常调用大模型)
from dotenv import load_dotenv
# 2. 加载环境变量
load_dotenv()
# 3. 定义“翻译处理函数”——对接Gradio的输入和翻译Chain
# 这个函数的作用:接收Gradio网页上的“目标语言”和“待翻译文本”,调用翻译Chain,返回翻译结果
def translate(language, text):
# 先判断输入是否为空(避免报错)
if not language or not text:
return "请输入完整的目标语言和待翻译文本哦!"
# 调用翻译Chain,传入参数,获取翻译结果
# 这里的参数格式,和我们之前测试Chain时完全一样
result = chain.invoke({"language": language, "text": text})
# 返回翻译结果,会显示在Gradio的输出框里
return result
# 4. 创建翻译网页(自定义布局,和我们平时用的翻译工具一样)
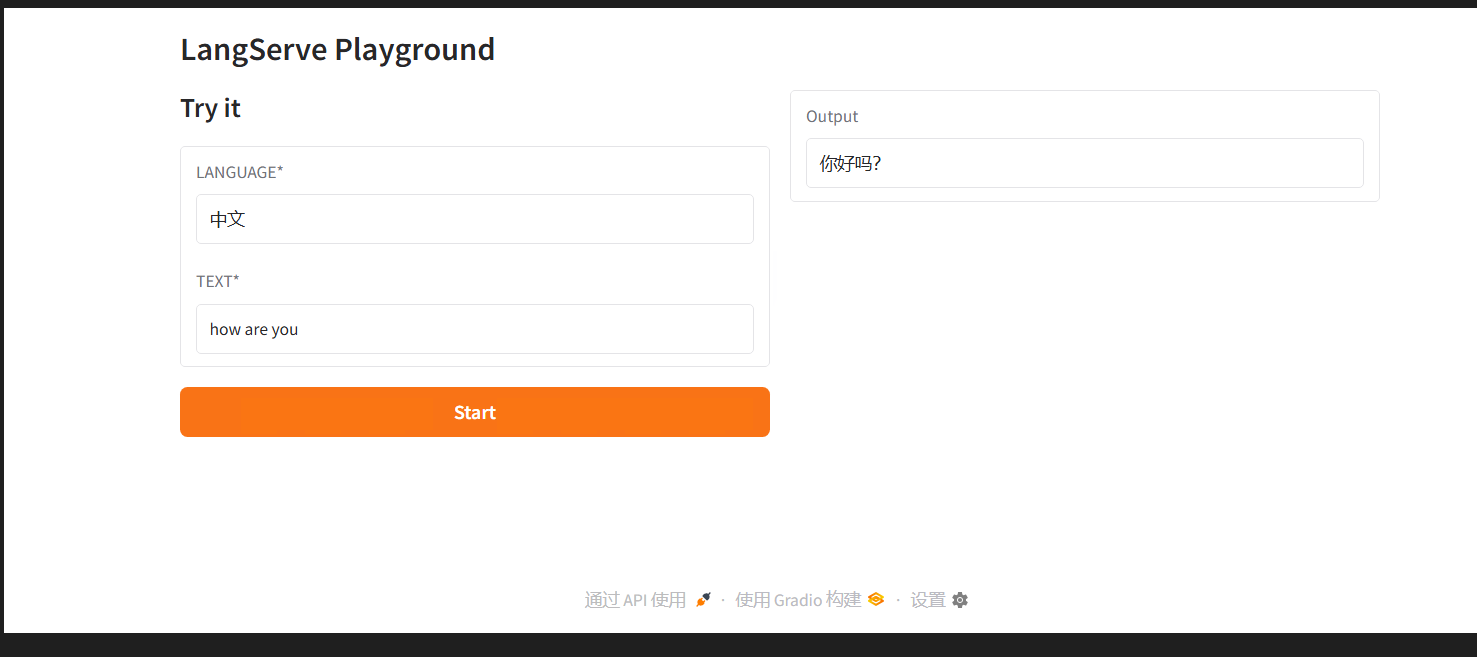
with gr.Blocks(title="大模型智能翻译助手") as demo:
# 网页标题(用Markdown格式,更美观)
gr.Markdown("# 🌐 智能翻译助手(也能操作)")
# 用gr.Row()创建“行布局”——把网页分成左右两列
with gr.Row():
# 左列:输入区域
with gr.Column():
gr.Markdown("## 输入参数") # 左列标题
# 目标语言输入框(默认值设为“中文”,可以直接修改)
lang_input = gr.Textbox(
label="目标语言*", # 标签(*表示必填)
placeholder="请输入目标语言,例:Chinese(中文)、English(英文)、Japanese(日语)",
value="Chinese" # 默认值
)
# 待翻译文本输入(3)运行代码,测试翻译网页效果
步骤和之前Gradio示例一致,全程可操作,每一步都有明确说明,结合常见报错给出解决方法:
-
打开命令提示符/终端,确保当前路径是“llm_service”文件夹(输入“cd 你的文件夹路径”,比如“cd C:\llm_service”);
-
输入命令:“python gradio_translation.py”,按回车运行代码;
-
查看终端输出(启动成功标志):
Running on local URL: http://0.0.0.0:7862 ``Running on public URL: https://xxxx-xxxx-xxxx-xxxx.gradio.live # 国内一般无法访问,直接忽略 ``To create a public link, setshare=Trueinlaunch(). -
访问网页: 复制终端显示的“http://0.0.0.0:7862”,粘贴到浏览器地址栏,按回车;
-
若访问时出现“URL拼写可能存在错误,请检查”(参考文档报错),请检查:① 端口号是否正确(确保是7862);② 终端是否处于运行状态(未关闭);③ 网页地址是否复制完整(无多余空格、符号)。
-
测试翻译功能(必做,验证是否正常工作): 在“目标语言”输入框输入“Chinese”(默认已填,可修改为其他语言,比如“English”);
-
在“待翻译文本”输入框输入英文,比如“I love programming, it's very interesting.”;
-
点击“点击翻译”按钮,等待1-2秒(取决于网络速度),右侧输出框会显示翻译结果(比如“我爱编程,它非常有趣。”);
-
测试清空功能:点击“清空输入和结果”,输入框和输出框会恢复默认状态,可重新输入翻译。
-
停止服务:回到终端,按“Ctrl+C”,即可停止网页服务(关闭终端也会停止服务)。
(4)常见报错及解决方法
结合前文文档中出现的“URL拼写错误”“网页解析失败”等问题,针对性给出解决方法,避免踩坑:
-
报错1:访问“http://0.0.0.0:7862”时,提示“URL拼写可能存在错误,请检查”(参考文档id=5、id=11报错) 解决:① 确认终端中服务已启动(终端显示“Running on local URL: http://0.0.0.0:7862”);② 检查网页地址是否正确,无多余空格、引号(比如不要写成“http://0.0.0.0:7862 ”);③ 若端口被占用,修改代码中“server_port=7863”(或其他未被占用的端口),重新运行代码。
-
报错2:访问网页时,提示“网页解析失败,可能是不支持的网页类型”(参考文档id=8、id=13、id=14报错) 解决:① 确认服务已正常启动(终端无报错);② 关闭浏览器缓存,重新打开网页;③ 检查Python版本是否≥3.10(低于该版本会导致Gradio服务异常)。
-
报错3:运行代码时,提示“ImportError: cannot import name 'chain' from 'translation_chain'” 解决:确保“gradio_translation.py”和“translation_chain.py”在同一个“llm_service”文件夹下,若不在同一文件夹,将两个文件放在一起即可。
-
报错4:点击“点击翻译”无反应,或输出“请输入完整的目标语言和待翻译文本哦!” 解决:检查两个输入框是否都有内容,目标语言不要输入空值,待翻译文本不要只输入空格。
-
报错5:运行代码时,提示“Connection error”(连接失败) 解决:检查“translation_chain.py”中的API密钥、阿里云百炼接口地址(base_url)是否正确,网络是否正常,重新运行“translation_chain.py”测试大模型连接是否正常。
6. Gradio 关键注意事项
-
✅ 端口区分:Gradio的端口号(7860、7861、7862)要和LangServer的端口号(8000)区分开,避免端口占用,若提示“Address already in use”,修改port参数即可;
-
✅ 服务启动:运行Gradio代码后,终端不能关闭,关闭终端则网页服务停止,无法访问;
-
✅ 局域网访问:若想让同局域网的其他设备(手机、笔记本)访问,确保代码中“server_name=0.0.0.0”,其他设备输入“你的电脑IP:7862”(比如192.168.1.100:7862)即可访问;
-
❌ 外网访问:本文部署的Gradio网页仅支持本地/局域网访问,若想让外网访问,需额外配置端口映射,暂时无需考虑;
-
✅ 代码复用:若想修改翻译功能(比如支持中文转英文),无需修改Gradio代码,只需修改“translation_chain.py”中的提示词模板即可,降低修改难度。
五、整体总结
本文全程围绕“零代码基础”,讲解了如何用LangChain+LangServer+Gradio部署大模型网络服务,核心流程可总结为3步,记住这3步,就能轻松复现所有操作:
-
准备工作:安装Python(≥3.10)、创建工作文件夹、获取阿里云百炼API密钥、安装相关依赖(LangChain、LangServer、Gradio);
-
核心操作:用LangChain构建翻译工具(Chain),测试成功后,用LangServer部署后端API服务,用Gradio部署前端可视化网页;
-
验证效果:启动服务,通过浏览器访问API调试页面(127.0.0.1:8000/docs)和Gradio翻译网页(127.0.0.1:7862),测试功能是否正常。
关键提醒:所有报错都可归为3类——端口占用(修改port)、API密钥/接口错误(检查.env文件和base_url)、文件路径错误(确保所有代码文件在同一文件夹),遇到报错先排查这3点,基本都能解决。
后续扩展:若想实现其他功能(比如对话机器人、文本总结),只需修改LangChain的Chain逻辑,复用本文的LangServer和Gradio部署步骤,无需重新学习部署流程,也能快速扩展功能。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)