企业级RAG系统构建指南
Introduction
Retrieval-Augmented Generation (RAG) has rapidly become the backbone of enterprise-grade LLM solutions, with nearly 90% of companies now relying on it to ground large language models with trusted, domain-specific knowledge. However, moving from a simple demo script to a production-ready enterprise system remains a significant challenge.
Many teams struggle with:
-
Hallucinations that break user trust
-
Poor retrieval accuracy that leads to irrelevant answers
-
Scalability issues under enterprise load
-
Compliance and data privacy requirements
-
High latency and operational costs
In this comprehensive guide, we'll walk through how to build a fully productionized enterprise RAG system using LangChain in 2025. We'll cover everything from architecture design to deployment strategies, optimization techniques, and operational best practices that will save your team months of trial and error.
Why RAG? RAG vs. Fine-Tuning vs. Long Context
Before we dive into implementation, let's clarify why RAG is the right choice for most enterprise use cases:
|
Factor |
RAG |
Fine-Tuning |
Long Context |
|
Data freshness |
Dynamic, frequent updates |
Static, stable |
Static |
|
Cost |
$70-1000/month |
6x inference cost |
High token costs |
|
Setup time |
Days |
Weeks-Months |
Hours |
|
Hallucinations |
Reduced (grounded) |
Can increase |
Depends on model |
|
Domain adaptation |
Multiple domains |
Single domain |
None |
|
Traceability |
Full source citations |
Black box |
Limited |
Use RAG when: You need citations, frequent data updates, multiple domains, and cost-sensitive scaling. This is exactly the scenario most enterprises face.
Why LangChain as Your Orchestrator?
LangChain has matured significantly into the de facto orchestration layer for production RAG systems in 2025. It provides:
-
Rich Ecosystem: 1000+ integrations with models, vector stores, and tools
-
First-class Observability: Built-in tracing and evaluation via LangSmith
-
Flexible Abstractions: Swap components without rewriting your entire pipeline
-
Production Patterns: Native support for batching, streaming, and parallelism
-
Multi-modal Support: Handle text, images, and other modalities seamlessly
Enterprise RAG Architecture Overview
A robust enterprise RAG system follows a modular, layered architecture that separates concerns and allows independent scaling of each component.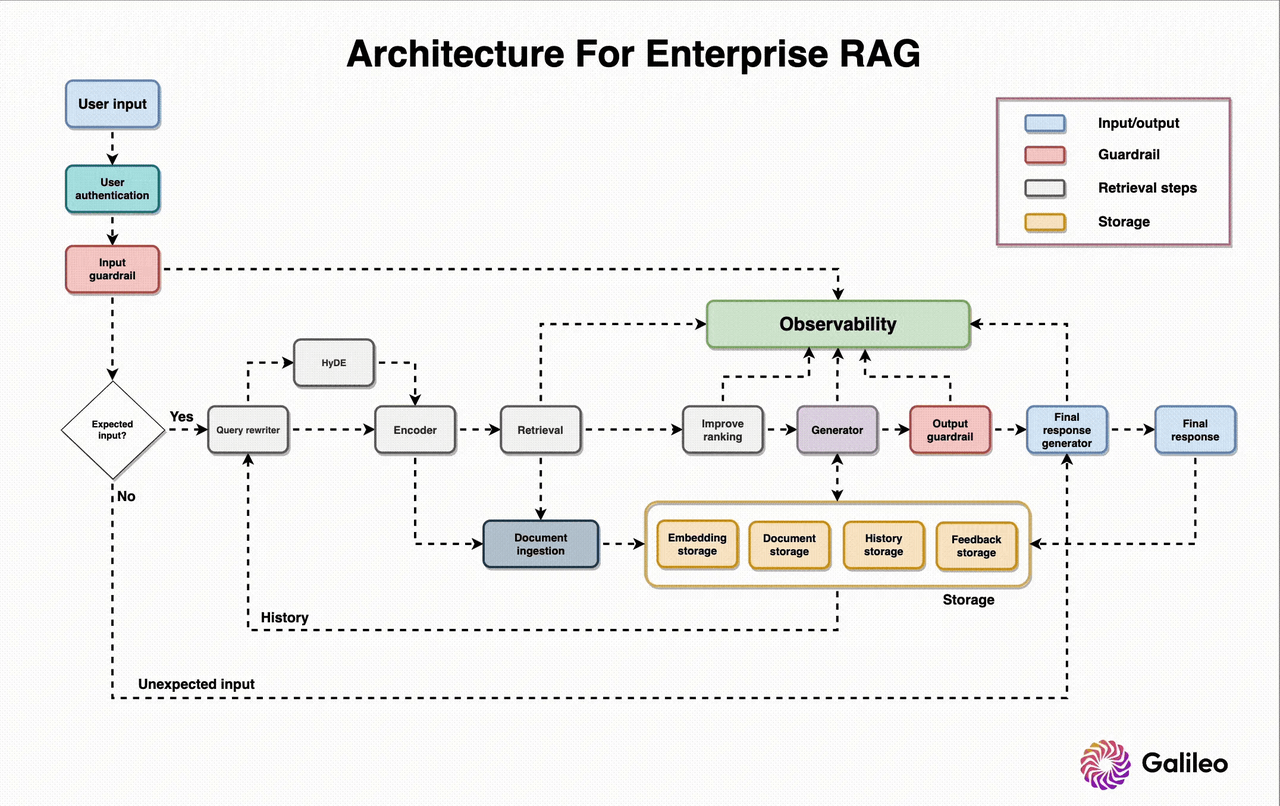
Figure 1: Reference architecture for enterprise-grade RAG systems
Our architecture follows the proven MVC (Model-View-Controller) pattern with five core engines:
-
Query Processing Engine: Transforms user questions into optimized search queries
-
Vector Retrieval Engine: Finds relevant content using semantic search
-
Reranking Module: Prioritizes results using relevance and business rules
-
Generation Engine: Synthesizes context into accurate responses
-
Event-Driven Backbone: Keeps everything loosely coupled for scalability
Step-by-Step Implementation Guide
Now let's get hands-on with building the system. We'll use a stack of AWS Bedrock for models, Zilliz Cloud for vector storage, and LangChain for orchestration.
1. Document Processing & Intelligent Chunking
The foundation of good retrieval is good chunking. Bad chunking is the #1 reason RAG systems fail in production.
from langchain.text_splitter import RecursiveCharacterTextSplitter
class DocumentProcessor:
def __init__(self, chunk_size=1000, chunk_overlap=100):
self.splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
separators=["\n\n", "\n", ". ", " ", ""]
)
def process(self, document):
parsed_content = self._parse_document(document)
cleaned_text = self._clean_content(parsed_content)
chunks = self.splitter.split_text(cleaned_text)
metadata = self._extract_metadata(document)
contextualized_chunks = [
self._format_chunk(chunk, metadata)
for chunk in chunks
]
return contextualized_chunks, metadata
def _parse_document(self, document):
# 实现文档解析逻辑
pass
def _clean_content(self, text):
# 实现文本清洗逻辑
pass
def _extract_metadata(self, document):
# 实现元数据提取逻辑
pass
def _format_chunk(self, chunk, metadata):
return f"文档: {metadata.get('title','')}\n章节: {metadata.get('section','')}\n内容: {chunk}"
Best Practices for Chunking:
-
Start with 512-1024 tokens with 10-20% overlap
-
Use semantic chunking for complex documents
-
Always add contextual information to each chunk
-
Test retrieval quality with a golden dataset before finalizing
2. Embedding Model Selection
Choosing the right embedding model is critical for retrieval accuracy. Here's our 2025 recommendation:
|
Tier |
Model |
Best For |
Cost |
|
Top Quality |
Voyage-3-large |
Precision-critical applications |
$0.20/1M tokens |
|
Enterprise |
text-embedding-3-large |
General purpose, good support |
$0.13/1M tokens |
|
Budget |
text-embedding-3-small |
Cost-sensitive scaling |
$0.02/1M tokens |
|
Open Source |
Nomic Embed v1 |
Private deployments |
Free |
from langchain_openai import OpenAIEmbeddings # Initialize embedding model embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
3. Hybrid Retrieval: The Game Changer
Single-stage vector search is no longer enough for production. Hybrid search combines semantic vector search with keyword-based BM25 search to get the best of both worlds.
from langchain.retrievers import EnsembleRetriever
from langchain_community.retrievers import BM25Retriever
# 向量检索器(假设已存在 vectorstore)
vector_retriever = vectorstore.as_retriever(search_kwargs={"k": 20})
# BM25 检索器(需传入分块后的文档 chunks)
bm25_retriever = BM25Retriever.from_documents(chunks)
bm25_retriever.k = 20 # 设置返回结果数量
# 创建混合检索器,加权合并结果
ensemble_retriever = EnsembleRetriever(
retrievers=[bm25_retriever, vector_retriever],
weights=[0.3, 0.7] # 权重可调整
)
# 使用混合检索器查询
results = ensemble_retriever.get_relevant_documents("你的查询问题")
4. Reranking: Boost Precision by 48%
After initial hybrid retrieval, we use cross-encoder reranking to reorder the results based on true query-document relevance. This step alone can improve your NDCG@10 score by up to 48%.
from langchain.retrievers import ContextualCompressionRetriever from langchain_cohere import CohereRerank # Add reranking reranker = CohereRerank(top_n=5) compression_retriever = ContextualCompressionRetriever( base_compressor=reranker, base_retriever=ensemble_retriever ) # Get the final, ranked results relevant_docs = compression_retriever.invoke(user_query)
5. LangChain Integration & Prompt Engineering
Finally, we tie everything together with LangChain's orchestration, using source-aware prompts that enforce citations and prevent hallucinations.
from langchain.chains import RetrievalQA from langchain_aws import BedrockLLM # Initialize LLM llm = BedrockLLM(model_id="amazon.nova-pro-v1:0") # Build the RAG chain qa_chain = RetrievalQA.from_chain_type( llm=llm, chain_type="stuff", retriever=compression_retriever, return_source_documents=True, chain_type_kwargs={ "prompt": PromptTemplate.from_template(""" You are a helpful assistant that answers questions based on the provided context. **Rules:** 1. Only answer using the information provided in the context. 2. If you don't have enough information, say "I don't have enough information to answer this question." 3. Cite your sources using [document_title] format. 4. Be concise and professional. Context: {context} Question: {question} Answer: """) } ) # Execute the query result = qa_chain.invoke({"query": user_query})
Production Optimization Strategies
Building the pipeline is only half the battle. To make it enterprise-ready, you need to optimize for performance, cost, and reliability.
Multi-Tier Caching Architecture
Caching is the single most effective way to reduce latency and cost. We implement a three-tier caching system:
from langchain.cache import RedisSemanticCache # Semantic cache for similar queries set_llm_cache(RedisSemanticCache( redis_url="redis://localhost:6379", embedding=embeddings, score_threshold=0.95 ))
-
L1 Cache: Lambda function memory (5-minute TTL)
-
L2 Cache: Redis cluster (1-hour TTL)
-
L3 Cache: S3 storage (1-day TTL)
This optimization cuts p95 response time from 2.1 seconds to 450 milliseconds while reducing inference costs by 60%.
Cold Start Mitigation
For serverless deployments, cold starts can be a major issue. We solve this with:
-
Provisioned Concurrency: For critical query functions
-
Warm-up Mechanisms: CloudWatch Events to keep functions warm
-
Dependency Optimization: Minimize package sizes
Multi-Tenant Architecture
If you're building a SaaS application, you need strict data isolation:
-
Tenant Filtering: Enforce
tenant_idfilters at the retriever level -
Namespace Isolation: Separate collections or indexes per tenant
-
Per-Tenant Quotas: Prevent noisy neighbor problems
-
Separate Encryption Keys: For maximum security
Deployment & Operations
Safe Deployment Strategies
Updating your RAG pipeline doesn't have to cause downtime. Use these proven patterns:
-
Shadow Deploy: Run new pipeline in parallel, compare outputs silently
-
Canary Release: Start with 1-5% of traffic, ramp up gradually
-
Feature Flags: Switch strategies per user or tenant
-
Rollback Contracts: Always be able to revert to last-known-good version
Observability & Monitoring
You can't improve what you don't measure. Implement comprehensive observability:
# Use RAGAS for evaluation metrics from ragas import evaluate from ragas.metrics import faithfulness, answer_relevancy result = evaluate( dataset, metrics=[faithfulness, answer_relevancy] )
Key metrics to monitor:
-
Precision@k: Retrieval accuracy
-
Faithfulness: Hallucination rate
-
Answer Relevancy: How relevant the response is
-
Latency: End-to-end response time
-
Cost: Token usage and infrastructure costs
Implementation Checklist
Here's a quick checklist to guide you from prototype to production:
MVP (Week 1-2)
-
Choose embedding model (start with text-embedding-3-small)
-
Set up vector database (Chroma for prototyping)
-
Implement basic chunking (recursive, 1000 tokens)
-
Build simple retrieval pipeline
-
Test with sample queries
Production Ready (Week 3-4)
-
Implement hybrid search (BM25 + vector)
-
Add reranking
-
Set up caching layer
-
Implement evaluation metrics
-
Monitor retrieval quality
Optimization (Ongoing)
-
Tune chunk size and overlap
-
Experiment with embedding models
-
Implement advanced patterns (GraphRAG, etc.)
-
A/B test retrieval strategies
-
Monitor cost and latency
Common Pitfalls to Avoid
-
One-shot retrieval: Skipping reranking and hybrid search leads to noisy context
-
Oversized chunks: Hurts recall and increases token costs
-
Prompt sprawl: Unmanaged prompt versions make bugs impossible to trace
-
No eval harness: You'll ship regressions without noticing
-
Ignoring security early: Retrofits cost 10x more and damage trust
-
Over-indexing: Index what users actually query, archive the rest
Conclusion
Building an enterprise-grade RAG system is no longer a research project—it's a well-understood engineering discipline with proven patterns and best practices.
By following the guide above, you can move from a simple demo to a production-ready system in just 4 weeks, with all the scalability, security, and reliability features enterprises demand. The key is to start simple, implement the core hybrid retrieval and reranking patterns first, then layer on optimizations and operational tooling as you scale.
The future of enterprise AI is grounded, traceable, and cost-effective—and with LangChain and the patterns we've covered here, you can build it today.
References:
-
Zilliz. (2025). How to Build an Enterprise-Ready RAG Pipeline on AWS.
-
InnoVirtuoso. (2025). LangChain RAG Handbook: The 2025 Developer's Guide.
-
GitHub Community. (2025). RAG Implementation Guide.

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)