大模型Agent算法面试60问
AI应用层技术研究摘要 本文系统探讨了大模型应用开发中的关键技术挑战与解决方案。聚焦RAG、Agent智能体和模型微调三大核心方向,重点分析了ReAct框架中Action失败时的梯度传播机制、Ring Attention的跨节点通信优化,以及多模态Agent的Uncertainty Estimation阈值设计等前沿问题。研究揭示了工具调用、长程记忆检索、分布式协同等场景下的性能瓶颈与优化路径,为
本文深入探讨了ReAct框架中Action执行失败时,Observation Prompt对后续Reasoning步骤的梯度影响路径。通过详细分析梯度反向传播机制,揭示了Prompt构造在维持策略稳定性和避免灾难性遗忘中的关键作用,为优化智能体决策逻辑提供了理论依据。
-
- 推导 ReAct 框架中 Action 执行失败时,Observation Prompt 构造对后续 Reasoning 步骤的梯度影响路径。
-
- 计算 Ring Attention 机制在 KV Cache 分块加载过程中,跨节点通信开销与序列长度 及显存块大小 的函数关系。
-
- 推导 Function Calling 微调中 Syntax Constraint Loss 的数学形式,并分析其对 JSON 参数生成概率分布 的约束效果。
-
- 从 Fisher 信息矩阵角度,量化解释 Tool Learning 场景下 ICL 相比 SFT 更易发生灾难性遗忘的特征子空间重叠度。
-
- 写出 Reflexion 算法中自我反思信号 嵌入价值函数 的具体更新公式,并分析其收敛边界条件。
-
- 设计 ToT 框架中基于 MCTS 的剪枝策略,给出启发式函数 的数学定义以平衡搜索宽度与深度。
-
- 推导 POMDP 模型下 Agent 的 Belief State 更新公式,并分析部分可观测性对规划最优性的误差界。
-
- 推导 DPO 优化 Agent 轨迹的目标函数 ,并证明其在不训练 Value Model 情况下隐含了对 KL 散度的约束。
-
- 分析异步执行架构中,状态机处理并发工具请求时的竞态条件数学模型及死锁检测算法复杂度。
-
- 设计基于 NLI 的 RAG 实时校验算法,给出 Faithfulness 得分 的计算公式及阈值判定逻辑。
-
- 理论推导 Memory Bank 检索 Top-K 值过大导致 Lost in the Middle 现象时,注意力权重 的衰减分布规律。
-
- 推导 Multi-Agent Debate 共识达成过程的马尔可夫链转移矩阵,并给出收敛到唯一稳态的特征值条件。
-
- 分析 DOM Tree 转 Token 序列时,HTML 标签截断策略对元素定位准确率 的信息论下界影响。
-
- 推导 GitRepl 利用 Diff 序列作为 Action Space 时,Token 消耗量 与代码修改行数 的线性关系。
-
- 写出 VLA 模型中 Cross-Attention 层动态调整视觉/文本 Token 权重 的梯度反向传播公式。
-
- 对比 Summary-based Compression 与 Vector-based Retrieval 的信息保留率 与检索延迟 的 Pareto 前沿。
-
- 设计基于对抗生成的 Tool Use 负样本合成方案,给出判别器损失 以最大化无效工具调用的识别梯度。
-
- 推导 GraphRAG 子图提取算法中,随机游走概率 与 LLM 注意力噪声抑制率 的数学关联。
-
- 给出本地 Agent 实现 Differential Privacy 的高斯噪声添加公式 ,并推导其对工具调用准确率的损耗界。
-
- 分析 SWE-agent 中正则解析器提取结构化状态的错误传播模型,给出状态丢失概率 的递推公式。
-
- 推导多模态 Agent 中 Uncertainty Estimation 的置信度分数 计算公式,并确定触发 Human-in-the-loop 的最优阈值 。
-
- 对比 Least-to-Most 与 Plan-and-Solve Prompting 的误差传播累积公式,设计 Backtracking 算法的最小回退步长。
-
- 推导 LLM Agent 强化学习中 Reward Hacking 现象的数学成因,给出奖励函数 被 exploit 的梯度方向条件。
-
- 设计分布式 Agent 系统中基于 Raft 协议的 Consensus Mechanism,分析 Leader 选举耗时与节点数 的对数关系。
-
- 分析 QLoRA 4-bit 量化对工具调用参数预测精度的影响,推导量化噪声 与参数误差 的方差关系。
-
- 设计流式 ASR-LLM-TTS 流水线优化策略,推导 TTFT 延迟 与各模块处理速度 的瓶颈约束公式。
-
- 推导 Self-Rewarding Language Models 中自动反馈循环的不动点存在条件,分析迭代收敛的 Lipschitz 常数。
-
- 设计基于 Event-Driven 的金融交易 Agent 缓存更新策略,给出数据一致性延迟 与市场波动率 的关系。
-
- 推导 HRL 中 High-level Policy 与 Low-level Policy 的信息交互接口互信息 的最大化目标函数。
-
- 分析代码执行 Sandbox 的 CPU/Memory Quota 机制,推导防止死循环的资源消耗上界 与时间片 的关系。
-
- 推导 Speculative Decoding 在 Agent 动作生成中的验证接受率 公式,并分析 Draft Model 误差对加速比的影响。
-
- 设计法律合规 Agent 的 Logit Masking 策略,给出违反 Constraints 的概率 的理论下界及抑制方法。
-
- 对比 VLA 模型中离散化与连续 Action Space 的控制精度误差 ,推导量化粒度 的最优解。
-
- 推导基于 World Model 的 Agent 内部模拟环境演变的预测误差 随步长 指数增长的系数。
-
- 设计基于信息增益的搜索引擎 Early Stopping 准则,给出停止检索的条件公式 。
-
- 推导 Multi-Modal CoT 中视觉与文本推理链的对齐损失 ,分析模态缺失时的梯度消失问题。
-
- 设计基于语义解析的 Defense Layer,推导过滤 Adversarial Prompts 的召回率 与误报率 的权衡曲线。
-
- 推导 Agent 在动态环境中 Online Learning 的更新规则 ,分析学习率 对环境非平稳性的适应性。
-
- 分析基于 Ray 的大规模 Agent 集群仿真通信瓶颈,推导状态同步延迟 与集群规模 的线性缩放关系。
-
- 推导 ReAct 范式下 Reason 与 Act 联合优化时,Stop-Gradient 操作对策略梯度 的偏差修正量。
-
- 分析 Toolformer 中工具调用标记插入策略对 Perplexity 的影响,推导最优插入频率 。
-
- 设计多 Agent 系统中基于 Shapley Value 的任务分配机制,给出全局奖励最大化时的边际贡献计算公式。
-
- 推导 LangChain 中 Chain of Thought 在复杂推理任务中的误差累积公式 ,设计中间步骤校正项。
-
- 分析 AutoGen Group Chat 模式下的消息路由算法,推导防止无限循环聊天的终止条件概率 。
-
- 设计基于向量数据库的长期记忆检索策略,推导千轮对话中上下文相关性得分 随时间衰减的函数。
-
- 推导 Plan-and-Solve 提示工程中子任务分解递归深度 对最终任务成功率 的 sigmoid 影响曲线。
-
- 分析 Reflexion 机制中历史失败轨迹作为 Few-shot 示例的显存占用 与轨迹长度 的线性关系。
-
- 设计基于强化学习的 Agent 探索策略,推导工具调用成本 与任务收益 的期望回报最大化公式。
-
- 推导多模态 Agent 中 Fusion Layer 的交互矩阵维度变换公式,计算计算复杂度 的优化下限。
-
- 对比 End-to-End Neural Agent 与 Modular Agent 的鲁棒性,推导对抗扰动 下的性能下降率 。
-
- 推导 ReWOO 框架中去除 Observation 依赖后,规划阶段潜在变量 的后验分布 的近似误差。
-
- 分析 CodeAct 框架中 Python 代码作为 Action Space 的图灵完备性对任务表达能力的上限及安全风险边界。
-
- 推导 SwiftSage 框架中双模块(Swift 与 Sage)切换机制的决策边界,给出切换阈值 的最优解。
-
- 分析 Agent 在长程任务中的状态漂移问题,推导 Kalman Filter 在隐状态跟踪中的增益矩阵 更新公式。
-
- 推导 Multi-Agent Planning 中基于合同网协议(Contract Net Protocol)的任务投标机制,给出中标概率 。
-
- 分析 RAG 中检索器与生成器的联合训练目标,推导检索质量 对生成困惑度 的梯度贡献。
-
- 推导 Agent 在使用 Search 工具时的 Query 重写机制,给出语义相似度 最大化时的重构公式。
-
- 分析 Visual Agent 中屏幕截图编码的 Token 压缩率,推导图像分辨率 与检测精度 的幂律关系。
-
- 推导 Agent 在多轮对话中意图识别的贝叶斯更新公式 ,分析历史轮次 对置信度的影响。
-
- 分析 Agent 系统评估中的 Pass@k 指标,推导在 次尝试中至少一次成功的概率公式及采样效率优化。
2026年AI行业最大的机会,毫无疑问就在应用层!
字节跳动已有7个团队全速布局Agent
大模型岗位暴增69%,年薪破百万!
腾讯、京东、百度开放招聘技术岗,80%与AI相关……
如今,超过60%的企业都在推进AI产品落地,而真正能交付项目的 大模型应用开发工程师 **,**却极度稀缺!
落地AI应用绝对不是写几个prompt,调几个API就能搞定的,企业真正需要的,是能搞定这三项核心能力的人:
✅RAG:融入外部信息,修正模型输出,给模型装靠谱大脑
✅Agent智能体:让AI自主干活,通过工具调用(Tools)环境交互,多步推理完成复杂任务。比如做智能客服等等……
✅微调:针对特定任务优化,让模型适配业务
目前,脉脉上有超过1000家企业发布大模型相关岗位,人工智能岗平均月薪7.8w!实习生日薪高达4000!远超其他行业收入水平!
技术的稀缺性,才是你「值钱」的关键!
具备AI能力的程序员,比传统开发高出不止一截!有的人早就转行AI方向,拿到百万年薪!👇🏻👇🏻

AI浪潮,正在重构程序员的核心竞争力!现在入场,仍是最佳时机!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

⭐️从大模型微调到AI Agent智能体搭建
剖析AI技术的应用场景,用实战经验落地AI技术。从GPT到最火的开源模型,让你从容面对AI技术革新!
大模型微调
-
掌握主流大模型(如DeepSeek、Qwen等)的微调技术,针对特定场景优化模型性能。
-
学习如何利用领域数据(如制造、医药、金融等)进行模型定制,提升任务准确性和效率。
RAG应用开发
- 深入理解检索增强生成(Retrieval-Augmented Generation, RAG)技术,构建高效的知识检索与生成系统。
- 应用于垂类场景(如法律文档分析、医疗诊断辅助、金融报告生成等),实现精准信息提取与内容生成。
AI Agent智能体搭建
- 学习如何设计和开发AI Agent,实现多任务协同、自主决策和复杂问题解决。
- 构建垂类场景下的智能助手(如制造业中的设备故障诊断Agent、金融领域的投资分析Agent等)。

如果你也有以下诉求:
快速链接产品/业务团队,参与前沿项目
构建技术壁垒,从竞争者中脱颖而出
避开35岁裁员危险期,顺利拿下高薪岗
迭代技术水平,延长未来20年的新职业发展!
……
那这节课你一定要来听!
因为,留给普通程序员的时间真的不多了!
立即扫码,即可免费预约
「AI技术原理 + 实战应用 + 职业发展」
「大模型应用开发实战公开课」
👇👇

👍🏻还有靠谱的内推机会+直聘权益!!
完课后赠送:大模型应用案例集、AI商业落地白皮书

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
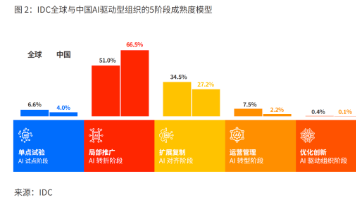

 1
1 0
0- 0



 已为社区贡献702条内容
已为社区贡献702条内容

所有评论(0)