计算机毕业设计:Python农业粮食产量与气候预测平台 Django框架 数据分析 可视化 机器学习 深度学习 大数据 大模型(建议收藏)✅
文章摘要: 本文介绍了一个基于Python Django框架开发的农业数据分析预测系统。系统采用SQLite3数据库存储数据,前端使用Semantic UI和Echarts实现可视化展示。核心功能包括夏收粮食产量分析、播种面积分析、受灾面积分析、降水量分析等模块,支持多维数据筛选与图表展示。系统通过机器学习模型实现农业指标预测,后台提供气候数据管理功能。技术栈涵盖Django 4.2.1、Pand
·
博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
2、大数据毕业设计:2026年选题大全 深度学习 python语言 JAVA语言 hadoop和spark(建议收藏)✅
1、项目介绍
技术栈
采用 Python 3.x 语言开发,基于 Django 4.2.1 框架搭建后端服务,使用 SQLite3 数据库进行数据存储,前端采用 Semantic UI 框架构建界面,利用 Echarts 实现数据可视化,通过 Pandas 和 NumPy 进行数据处理,运用 scikit-learn 机器学习库构建预测模型,使用 requests 和 BeautifulSoup4 进行网络请求与 HTML 解析。
功能模块
· 夏收粮食产量分析页
· 平均降水量分析页
· 农业数据中心页
· 夏收粮食播种面积分析页
· 秋收粮食播种面积分析页
· 受灾面积分析页
· 预测分析页
· 登录页
· 气候数据管理页
项目介绍
本系统基于 Django 框架构建农业数据分析预测平台,通过爬虫技术采集农业与气候数据,存入 SQLite3 数据库。系统提供夏收粮食产量与播种面积、秋收粮食播种面积、受灾面积、平均降水量等多维度数据分析功能,通过柱状图、饼图、折线图等 Echarts 图表直观展示数据。农业数据中心支持按地区、指标、年份筛选查看数据详情。预测分析模块基于 scikit-learn 机器学习模型,对农业指标进行历史数据与预测结果的对比展示。后台支持气候数据的管理与导出操作。
2、项目界面
夏收粮食产量分析页
该页面为农业数据分析预测系统的夏收粮食产量分析界面,通过柱状图展示各省份近五年夏收粮食产量数据,支持切换近5年、近10年、近20年数据查看,下方配有表格同步呈现数据详情。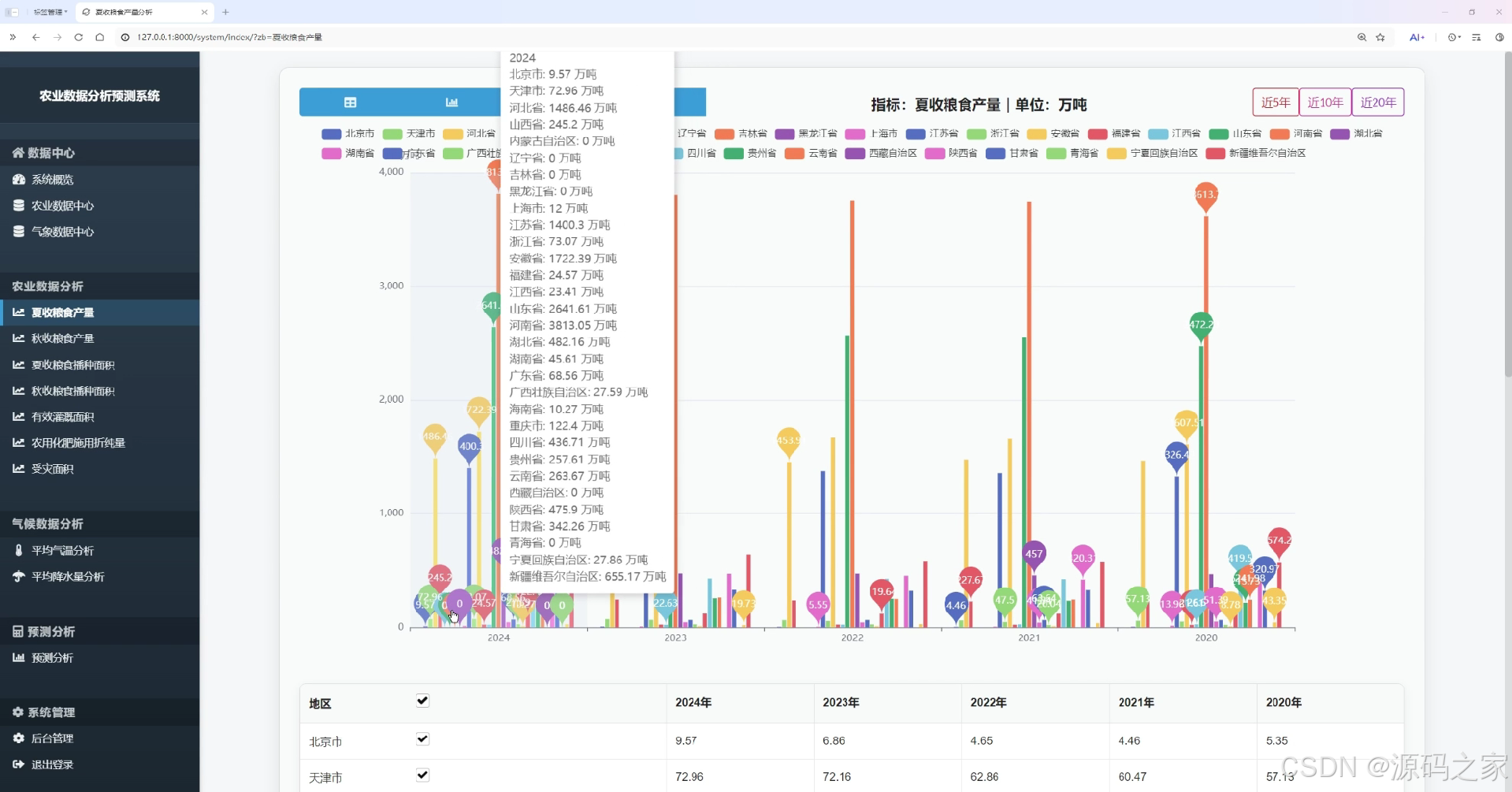
平均降水量分析页
该页面为农业数据分析预测系统的平均降水量分析界面,可选择月份,通过饼图和柱状图展示全国各省份的降水量分布与统计数据,直观呈现不同地区的降水情况。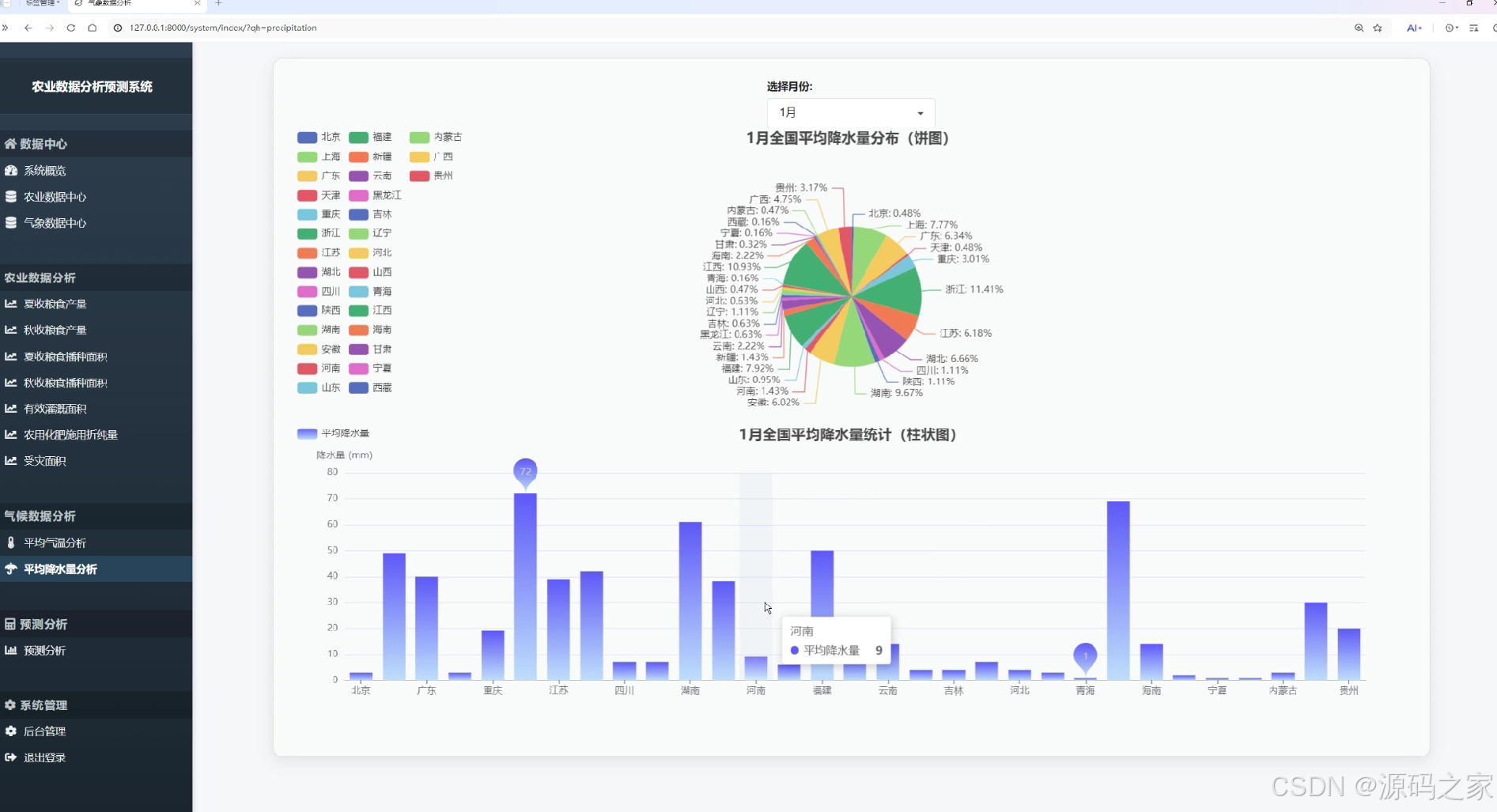
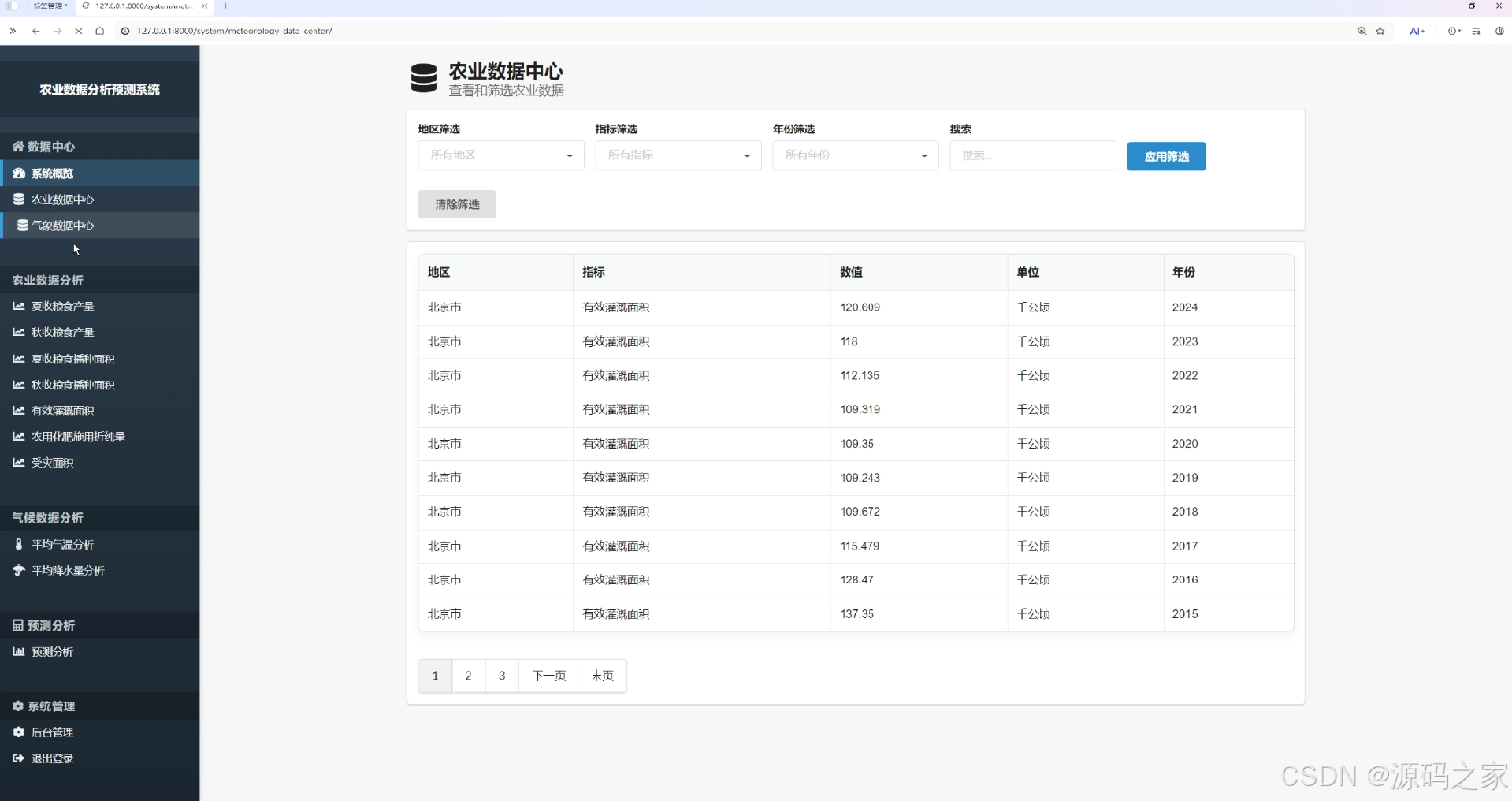
农业数据中心页
该页面为农业数据分析预测系统的农业数据中心界面,提供地区、指标、年份筛选与搜索功能,可查看不同地区、年份的农业指标数据,下方表格展示数据详情并支持分页浏览。
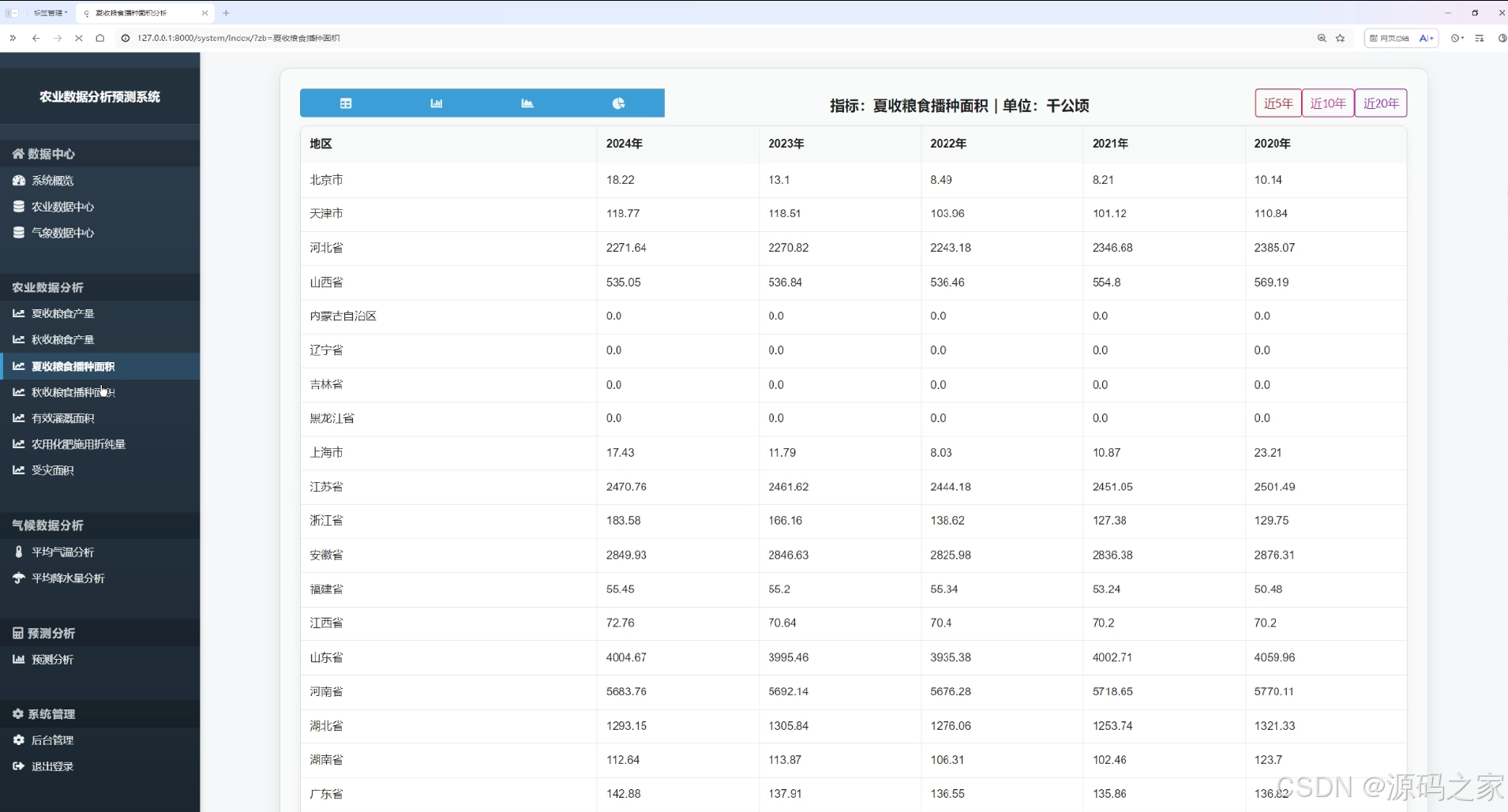
夏收粮食播种面积分析页
该页面为农业数据分析预测系统的夏收粮食播种面积分析界面,通过表格展示各省份近五年夏收粮食播种面积数据,支持切换近5年、近10年、近20年数据查看,呈现不同地区历年播种面积的变化情况。
秋收粮食播种面积分析页
该页面为农业数据分析预测系统的秋收粮食播种面积分析界面,通过表格展示各省份近五年秋收粮食播种面积数据,支持切换近5年、近10年、近20年数据查看,呈现不同地区历年播种面积的变化情况。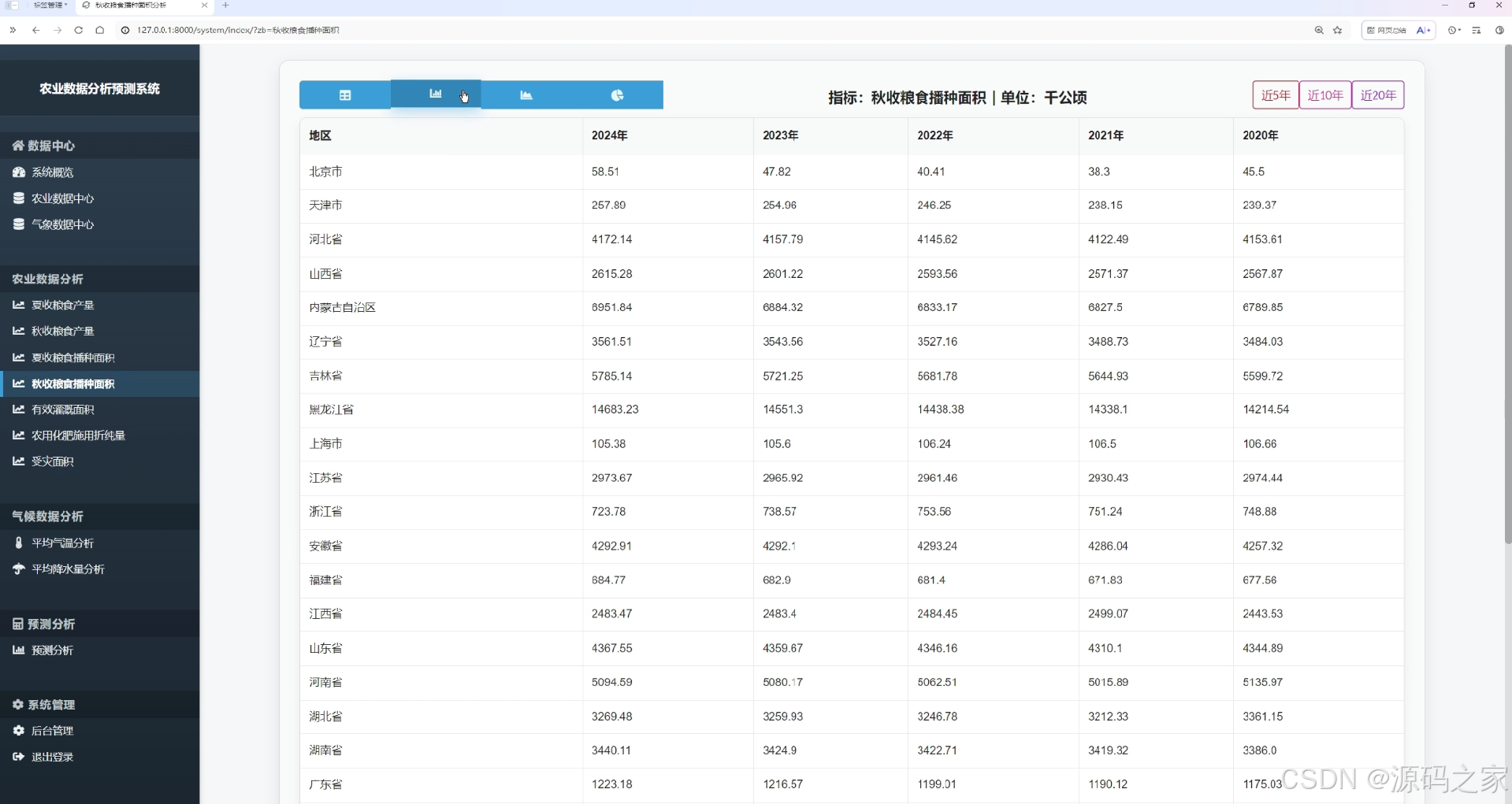
受灾面积分析页
该页面为农业数据分析预测系统的受灾面积分析界面,通过折线图展示各省份近五年受灾面积数据,支持切换近5年、近10年、近20年数据查看,下方配有表格同步呈现数据详情。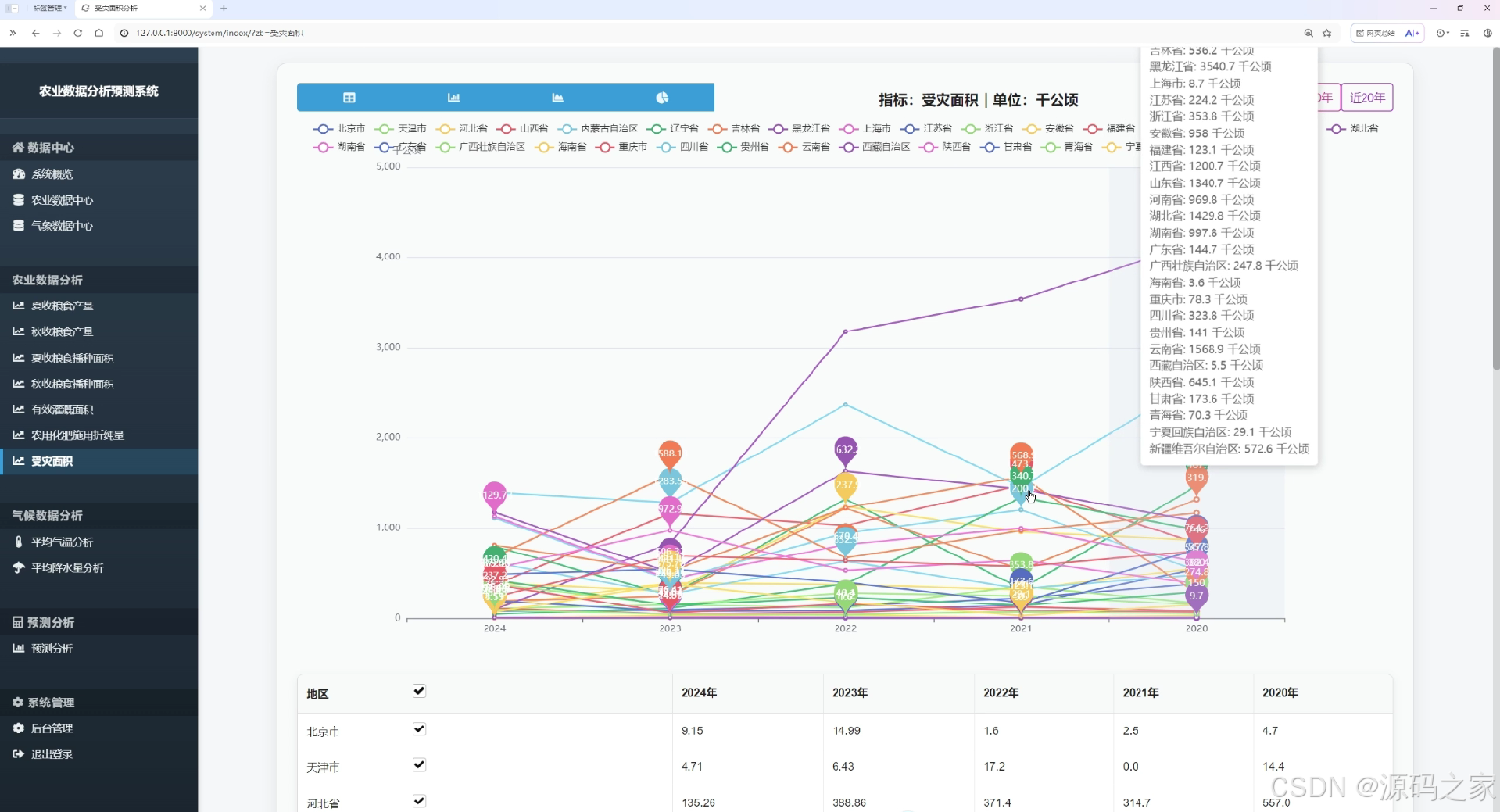
平均降水量分析页
该页面为农业数据分析预测系统的平均降水量分析界面,可选择月份,通过饼图和柱状图展示全国各省份的降水量分布与统计数据,直观呈现不同地区的降水情况。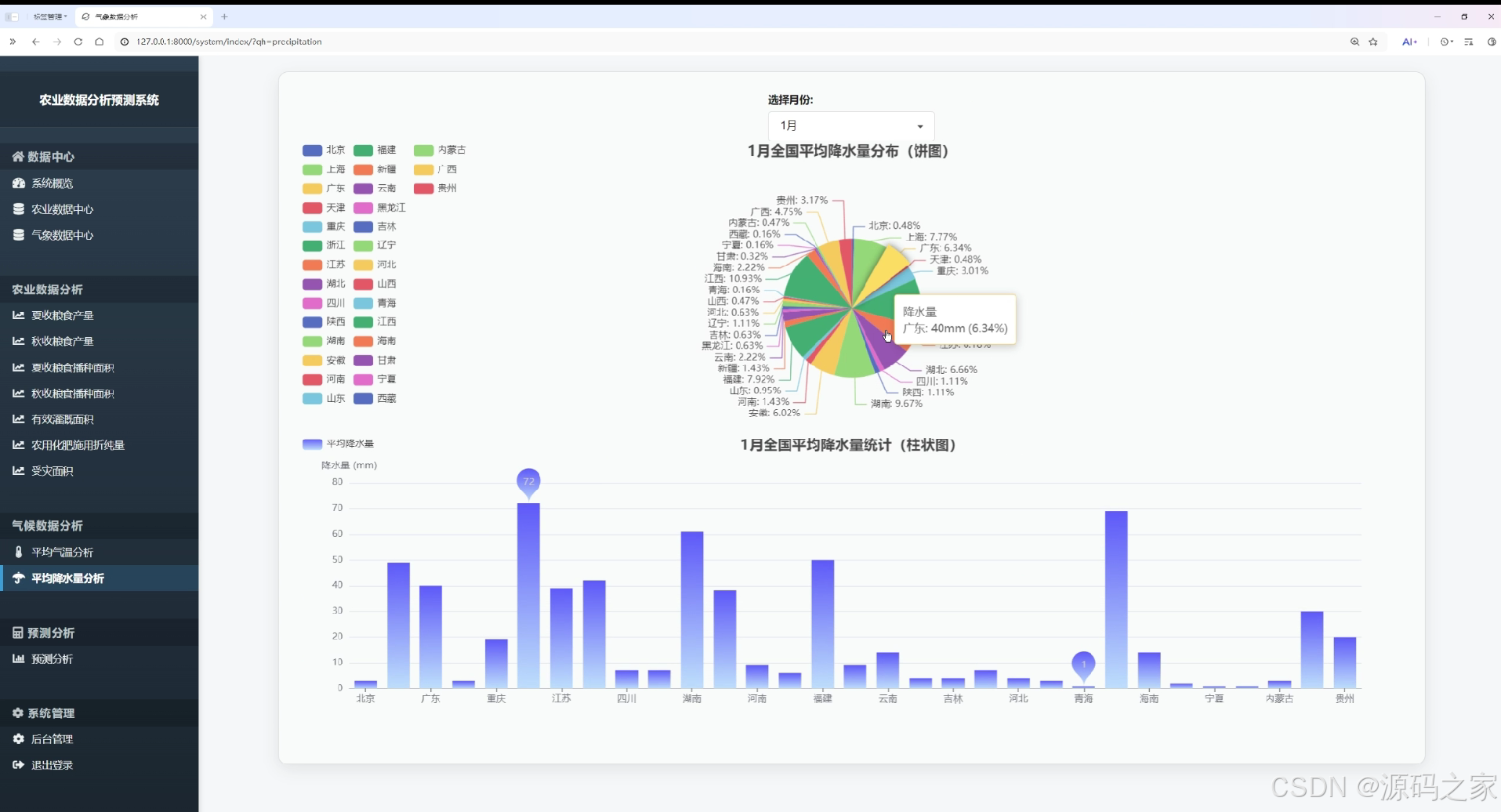
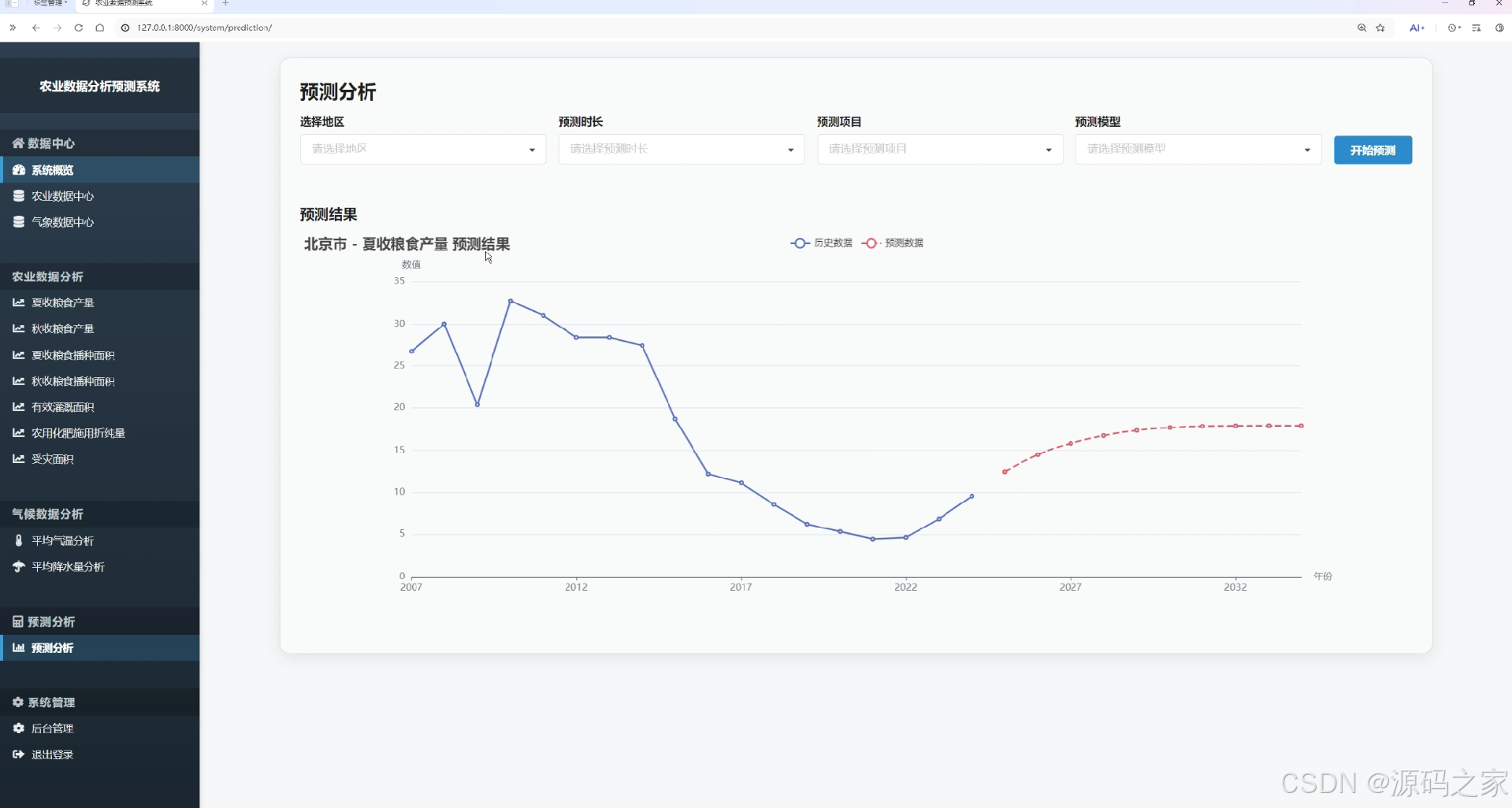
预测分析页
该页面为农业数据分析预测系统的预测分析界面,提供地区、预测时长、预测项目、预测模型选择功能,点击开始预测后,通过折线图展示对应地区农业指标的历史数据与预测结果对比。
登录页
该页面为农业数据分析预测系统的登录界面,提供用户名、密码输入框与登录按钮,支持用户输入账号密码登录系统,同时设有注册入口,方便新用户创建账号。
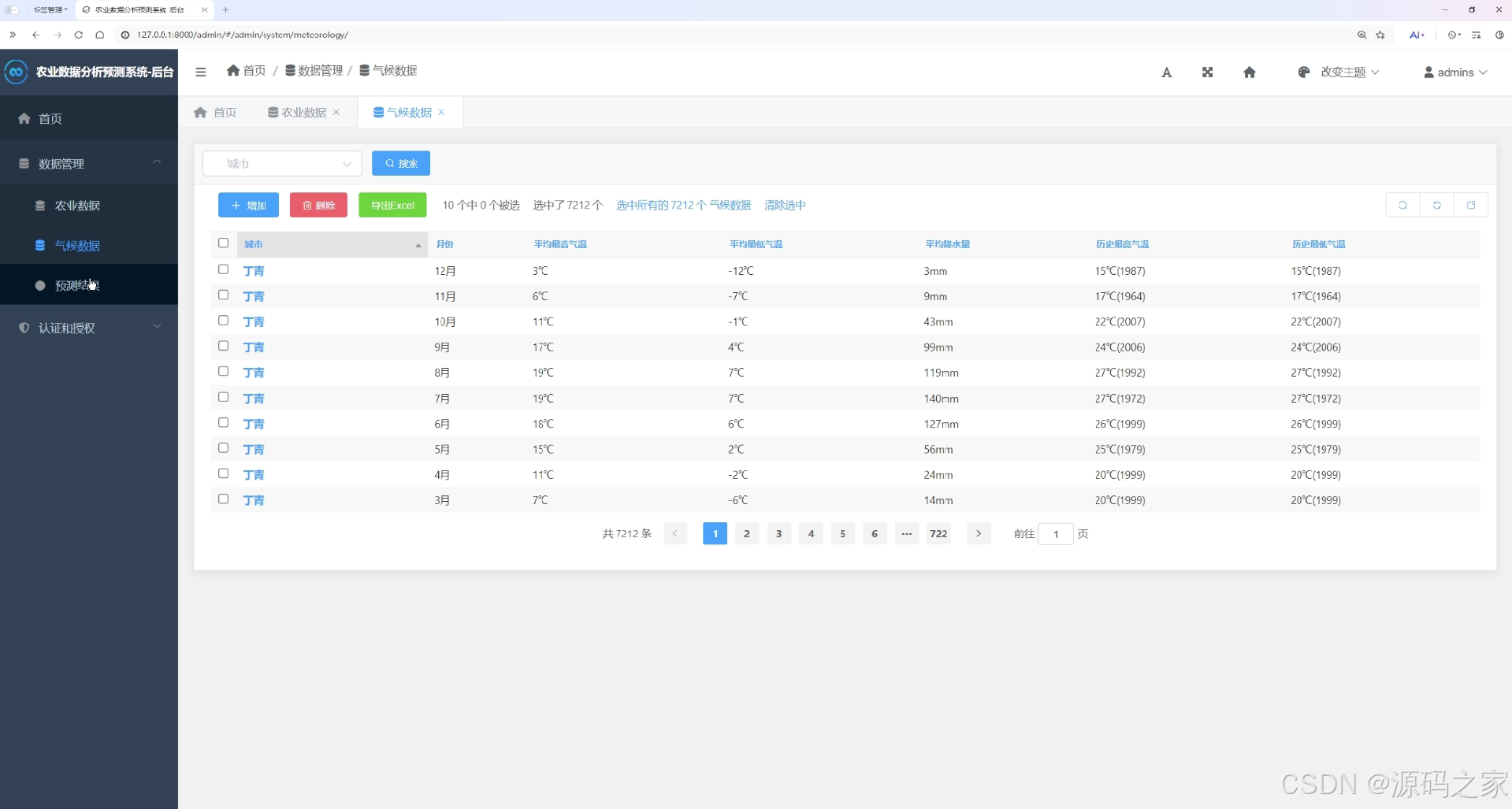
气候数据管理页
该页面为农业数据分析预测系统后台的气候数据管理界面,提供城市筛选、搜索功能,支持数据的增加、删除、导出Excel操作,可查看并分页浏览各城市不同月份的气温、降水量等气候数据。
3、项目说明
一、技术栈简要说明
本系统采用 Python 3.x 语言开发,基于 Django 4.2.1 框架搭建后端服务,使用 SQLite3 数据库进行数据存储,前端采用 Semantic UI 框架构建界面,利用 Echarts 实现数据可视化,通过 Pandas 和 NumPy 进行数据处理,运用 scikit-learn 机器学习库构建预测模型,使用 requests 和 BeautifulSoup4 进行网络请求与 HTML 解析。
二、功能模块详细介绍
· 夏收粮食产量分析页
该页面通过柱状图展示各省份近五年夏收粮食产量数据,支持切换近5年、近10年、近20年数据查看,下方配有表格同步呈现数据详情,帮助用户直观了解不同地区夏收粮食产量的长期变化趋势。
· 夏收粮食播种面积分析页
该页面通过表格展示各省份近五年夏收粮食播种面积数据,支持切换近5年、近10年、近20年数据查看,清晰呈现不同地区历年播种面积的变化情况,为种植结构调整提供数据参考。
· 秋收粮食播种面积分析页
该页面通过表格展示各省份近五年秋收粮食播种面积数据,支持切换近5年、近10年、近20年数据查看,直观反映各地区秋收粮食播种面积的年度波动与区域差异。
· 受灾面积分析页
该页面通过折线图展示各省份近五年受灾面积数据,支持切换近5年、近10年、近20年数据查看,下方配有表格同步呈现数据详情,帮助用户了解自然灾害对农业生产的影响程度与变化趋势。
· 平均降水量分析页
该页面可选择月份,通过饼图和柱状图展示全国各省份的降水量分布与统计数据,直观呈现不同地区的降水情况,为农业灌溉与防灾减灾提供气象依据。
· 农业数据中心页
该页面提供地区、指标、年份筛选与搜索功能,可查看不同地区、年份的农业指标数据,下方表格展示数据详情并支持分页浏览,实现农业数据的集中查询与统一管理。
· 预测分析页
该页面提供地区、预测时长、预测项目、预测模型选择功能,点击开始预测后,通过折线图展示对应地区农业指标的历史数据与预测结果对比。系统基于 scikit-learn 机器学习库构建预测模型,为用户提供科学的产量与趋势预估。
· 登录页
该页面提供用户名、密码输入框与登录按钮,支持用户输入账号密码登录系统,同时设有注册入口,方便新用户创建账号,保障系统访问安全与用户权限管理。
· 气候数据管理页
该后台管理页面提供城市筛选、搜索功能,支持气候数据的增加、删除、导出 Excel 操作,可查看并分页浏览各城市不同月份的气温、降水量等气候数据,方便管理员对气象信息进行系统化维护。
三、项目总结
本系统基于 Django 框架构建农业数据分析预测平台,通过爬虫技术采集农业与气候数据,存入 SQLite3 数据库。系统提供夏收粮食产量与播种面积、秋收粮食播种面积、受灾面积、平均降水量等多维度数据分析功能,通过柱状图、饼图、折线图等 Echarts 图表直观展示数据变化趋势与区域分布。农业数据中心支持按地区、指标、年份筛选查看数据详情,实现农业指标的集中查询。预测分析模块基于 scikit-learn 机器学习模型,对农业指标进行历史数据与预测结果的对比展示,为农业生产规划提供科学参考。后台支持气候数据的管理与导出操作,方便数据维护。系统为农业决策者、研究人员及从业者提供了全面的数据支持与智能化分析工具。
4、核心代码
# 导入必要的库
import requests # 用于发送HTTP请求
import time # 用于处理时间相关操作
import urllib3
import os
# 禁用SSL证书验证警告
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
# 农业统计数据爬虫脚本,采集到 data/data_agriculture.csv文件,主要功能是从国家统计局网站抓取多种农业相关的统计数据。
# 它通过模拟HTTP请求访问国家统计局的数据接口,获取包括夏收和秋收粮食产量及播种面积、受灾面积、有效灌溉面积、农用化肥施用量等多个关键农业指标的数据。
# 程序会自动处理数据格式,提取地区名称、数值、单位和更新时间等信息,最终将这些数据保存到本地的CSV文件中,便于后续分析使用。
def getData(zb, zb_code, csv_file):
"""
获取指定统计指标的数据并直接写入CSV文件
:param zb: 指标名称(如'夏收粮食产量')
:param zb_code: 指标代码(如'A0D0Q02')
:param csv_file: CSV文件对象,用于写入数据
"""
# 生成当前时间戳(毫秒),用于防止缓存
millis = int(round(time.time() * 1000))
# 构建API请求URL,包含指标代码和时间戳
url = 'https://data.stats.gov.cn/easyquery.htm?m=QueryData&dbcode=fsnd&rowcode=reg&colcode=sj&wds=%5B%7B%22wdcode%22%3A%22zb%22%2C%22valuecode%22%3A%22{}%22%7D%5D&dfwds=%5B%7B%22wdcode%22%3A%22sj%22%2C%22valuecode%22%3A%22LAST20%22%7D%5D&k1={}'.format(zb_code,millis)
# 打印正在采集的URL
# print('正在采集URL:{}'.format(url))
# 设置请求头,包括Cookie、User-Agent等信息,模拟浏览器访问
headers = {
'Connection': 'keep-alive', # 保持连接
'Cookie':'wzws_sessionid=oGQ6m6aAMTE5LjM5LjEzMy43N4JmYzVlZTGBMzVkYWQ3; JSESSIONID=CwqE7x_DL8afP48RRS0lnYUSPHymBClZKx0UKJjeYPtWpDSVZW0E!1171792879; u=6',
'Host':'data.stats.gov.cn', # 目标主机
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36', # 浏览器标识
'X-Requested-With': 'XMLHttpRequest' # 标识为Ajax请求
}
# 发送GET请求获取数据,禁用SSL验证
response = requests.get(url=url,headers=headers, verify=False)
# 将响应解析为JSON格式
results = response.json()
# 提取数据单位
unit = results['returndata']['wdnodes'][0]['nodes'][0]['unit']
# 创建地区代码与名称的映射字典
area_code = {}
for item in results['returndata']['wdnodes'][1]['nodes']:
name = item['cname'] # 地区名称
code = item['code'] # 地区代码
area_code[code] = name
# 遍历数据节点,提取具体数值并直接写入CSV文件
for item in results['returndata']['datanodes']:
value = item['data']['data'] # 具体的统计数据值
area = area_code[item['wds'][1]['valuecode']] # 通过地区代码获取地区名称
updateTime = item['wds'][2]['valuecode'] # 数据更新时间
# 将提取的数据以[地区, 数值, 单位, 指标, 更新时间]的格式写入CSV文件
data_item = [area, value, unit, zb, updateTime]
# 写入数据到CSV文件
csv_file.write('\t'.join([str(_) for _ in data_item]) + '\n')
csv_file.flush() # 立即刷新到磁盘
# 打印采集到的单条数据及提示信息
print(f'已采集数据 - 地区: {area}, 数值: {value}, 单位: {unit}, 指标: {zb}, 更新时间: {updateTime}')
def writeHeader(csv_file):
"""
写入CSV文件的表头
:param csv_file: CSV文件对象
"""
# 写入表头:地区、数值、单位、指标、更新时间
csv_file.write('\t'.join(['area','value','unit','zb','updateTime'])+'\n')
if __name__ == '__main__':
# 定义需要抓取的统计指标列表,包括指标名称和对应的代码
zb_code_list = [
{'zb':'夏收粮食产量','zb_code':'A0D0Q02'},
{'zb':'秋收粮食产量','zb_code':'A0D0Q02'},
{'zb':'夏收粮食播种面积','zb_code':'A0D0P03'},
{'zb':'秋收粮食播种面积','zb_code':'A0D0P04'},
{'zb':'受灾面积','zb_code':'A0D1801'},
{'zb':'有效灌溉面积','zb_code':'A0D0H01'},
{'zb':'农用化肥施用折纯量','zb_code':'A0D0H02'}
]
# 创建数据目录(如果不存在)
os.makedirs('./data', exist_ok=True)
# 打开CSV文件用于写入数据
with open('./data/data_agriculture.csv', 'w+', encoding='utf-8') as csv_file:
# 写入表头
writeHeader(csv_file)
# 遍历指标列表,逐个获取数据
for item in zb_code_list:
zb = item['zb'] # 当前指标名称
zb_code = item['zb_code'] # 当前指标代码
print(f'开始采集指标: {zb} (代码: {zb_code}) 的数据...')
# 调用getData函数获取该指标的数据并直接写入文件
getData(zb, zb_code, csv_file)
# 输出进度提示信息
print('指标:{}数据采集完成!'.format(zb))
# 添加延时,避免请求过于频繁被服务器限制
time.sleep(3)
print('所有指标数据采集完成,数据已成功写入 ./data/data_agriculture.csv 文件中')
5、项目列表



6、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献45条内容
已为社区贡献45条内容

所有评论(0)