AI编码OpenCode入门到入神
OpenCode 是一款开源的 AI 编程助手,原生集成于终端环境,支持智能编码、调试和项目重构。它提供双模式工作流(分析/执行)、模型无关性(可连接多种AI模型)和多端运行能力。安装方式包括 npm、Chocolatey 和 WSL 三种方案,支持配置本地私有模型。实际使用中,开发者可在项目目录通过opencode命令启动,连接公司大模型服务后即可开始AI辅助编程。该工具将传统编码升级为AI协作
OpenCode使用分享
将开发方式从 传统 IntelliJ IDEA 转向 OpenCode 终端编程(AI 原生终端开发环境),并非简单“换工具”,而是一次 开发范式的升级。
在 2026 年,不会用 OpenCode 的 Java 开发者,就像 2010 年不用 IDEA 的程序员——不是不能工作,而是效率被降维打击。
拥抱 OpenCode||ClaudeCode|Codex,不是放弃编码,而是把编码交给 AI,把创造力留给自己。
OpenCode 是一款开源的 AI 编程助手,其核心特点是原生集成于终端。它就像是你的专属高级开发伙伴,能直接在命令行里与你对话,高效地完成编码、调试、项目重构等一系列任务。
✨ 核心功能一览
- 🤖 智能编码:理解、调试、重构代码,并能自动扫描项目以提供准确的上下文。
- ⚙️ 双模式工作流:拥有
plan(仅分析)和build(实际修改)两种模式,让你在审查和执行之间找到平衡。 - 🔌 模型无关性:不绑定任何AI厂商,你可以自由选择 OpenAI、Claude、DeepSeek等数十种模型,甚至使用本地部署的模型。
- 🖥️ 多端运行:不仅限于命令行,还能作为桌面应用(Beta版)或 VS Code 等IDE的扩展来使用,随时随地进行AI辅助编程。
(一)部署步骤准备好OpenCode
⚙️ 准备工作:安装Node.js并配置npm加速
这一步是所有方案的基础。
-
下载与安装:访问Node.js官网,下载并安装最新的LTS(长期支持)版本。安装时使用默认选项即可,它会自动将Node.js和npm添加到系统环境变量中。
-
配置npm镜像加速:安装完成后,打开终端(PowerShell),执行以下命令,将npm的默认镜像源切换为国内更快的阿里云镜像(原淘宝镜像)。
npm config set registry https://registry.npmmirror.com -
验证配置:执行以下命令,如果返回你设置的镜像地址,就说明配置成功了。
npm config get registry
💎 方案一:使用npm直接安装(最简单,最稳妥,强力推荐)
这个方法最直接,但由于OpenCode的安装包较大,国内镜像同步可能存在延迟,有几率安装失败。
-
临时切换官方源:为避免镜像同步延迟导致的问题,建议直接使用官方源来安装OpenCode。
npm install -g opencode-ai --registry=https://registry.npmjs.org -
验证安装:安装完成后,运行以下命令,如果显示版本号,说明安装成功了。
opencode --version -
可能遇到的问题:如果安装过程中卡住不动,可以尝试更新你的PowerShell到最新版本,或使用下文提到的
Chocolatey方式安装。
🔧 方案二:使用Chocolatey安装
Chocolatey是Windows平台的包管理工具,可以避免npm安装可能出现的网络兼容性问题,是官方推荐的稳妥方案。
-
安装Chocolatey:以管理员身份打开PowerShell,然后运行以下命令:
Set-ExecutionPolicy Bypass -Scope Process -Force; [System.Net.ServicePointManager]::SecurityProtocol = [System.Net.ServicePointManager]::SecurityProtocol -bor 3072; iex ((New-Object System.Net.WebClient).DownloadString('https://community.chocolatey.org/install.ps1')) -
安装OpenCode:Chocolatey安装成功后,在同一终端中运行以下命令,即可完成OpenCode的安装。
choco install opencode -
验证安装:同样,运行
opencode --version来检查。
🐧 方案三:通过WSL安装
WSL(Windows Subsystem for Linux,适用于Linux的Windows子系统)能提供最完整的原生Linux体验,完全避开Windows平台的各种兼容性问题,OpenCode官方也推荐此方式。
-
安装WSL:以管理员身份打开PowerShell,直接运行以下命令即可完成WSL及默认Ubuntu发行版的安装。
wsl --install安装完成后,根据提示重启电脑。
-
在WSL中安装OpenCode:重启后,在开始菜单中找到并打开你安装的Linux发行版(如Ubuntu),在其中运行官方的一键安装脚本。
curl -fsSL https://opencode.ai/install | bash -
验证安装:在WSL终端中输入
opencode --version来检查。
⚠️ 常见问题与解决方案
-
pnpm、yarn或其他镜像源:如果你使用pnpm或yarn,也可以用pnpm config set registry https://registry.npmmirror.com类似的命令为其配置镜像加速。阿里云、腾讯云等镜像源都是很好的选择。 -
PowerShell脚本执行受限:如果在运行脚本时遇到权限错误,可以以管理员身份运行PowerShell,并执行以下命令,将执行策略改为
RemoteSigned:Set-ExecutionPolicy -ExecutionPolicy RemoteSigned -Scope CurrentUser -
opencode命令找不到:如果安装成功后,在终端输入opencode提示找不到命令,通常是因为npm的全局安装路径没有添加到系统的PATH环境变量中。- 解决方法:执行
npm config get prefix查看全局安装路径,然后将[该路径]添加到系统环境变量中。
- 解决方法:执行
-
opencode用着用着就ENAMETOOLONG: name too long, uv_spawn;npx 缓存膨胀导致的
- 解决方法:npm cache clean --force
🐧 本地模型私有模型配置
-
定位配置文件:OpenCode 的配置文件可以放在全局或项目级别,以决定配置的作用范围。
- 全局配置:
~/.config/opencode/opencode.json - 项目配置:
<你的项目根目录>/opencode.json
- 全局配置:
-
**公司环境配置:**推荐全局配置好:不存在就新建opencode.json
-
{ "$schema": "https://opencode.ai/config.json", "disabled_providers": [], "model": "Local_provider/glm-5", "provider": { "Local_provider": { "name": "Local provider", "npm": "@ai-sdk/openai-compatible", "models": { "glm-5": { "name": "glm-5", "limit": { "context": 931072, "output": 60536 }, "modalities": { "input": ["text", "image", "audio"], "output": ["text"] }, "attachment": true }, "qwen3-980b": { "name": "qwen3-980b", "limit": { "context": 931072, "output": 60536 } } }, "options": { "baseURL": "http://127.0.0.01:14000/v1" } } } } -
配置中文回答:~/.config/opencode/AGENTS.md
-
## 交互要求 1. 你在处理所有问题时,**全程思考过程必须使用中文**(包括需求分析、逻辑拆解、方案选择、步骤推导等所有内部推理环节); 2. 最终输出的所有回答内容(包括文字解释、代码注释、步骤说明等)**必须全部使用中文**,仅代码语法本身的英文关键词除外。
(二)OpenCode在项目中的实践
1.opencode使用初体验
1.1 在项目目录中右键打开终端,执行命令:opencode
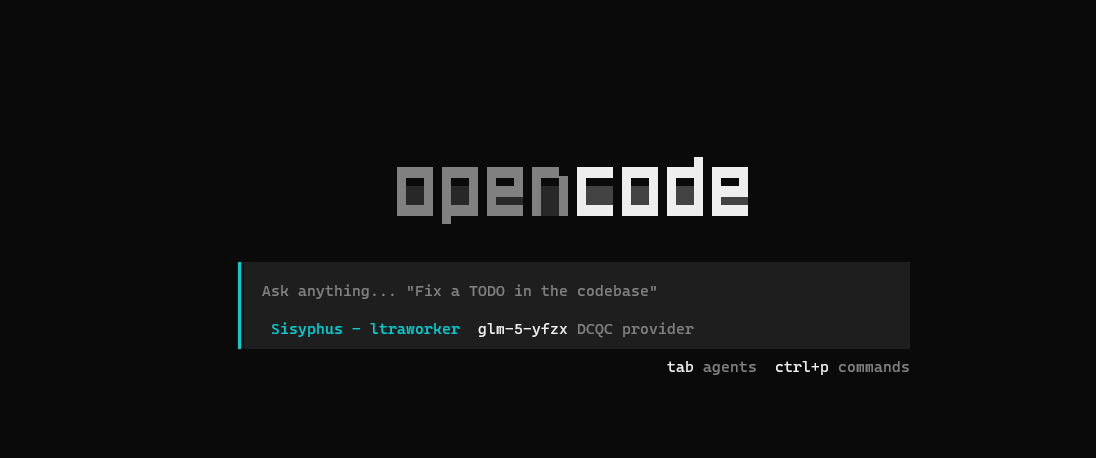
1.2 连接公司大模型组进入 OpenCode 交互界面后,输入 /connect,在选项中选择公司统一配置的 AI 提供商(例如 Local_provider)。
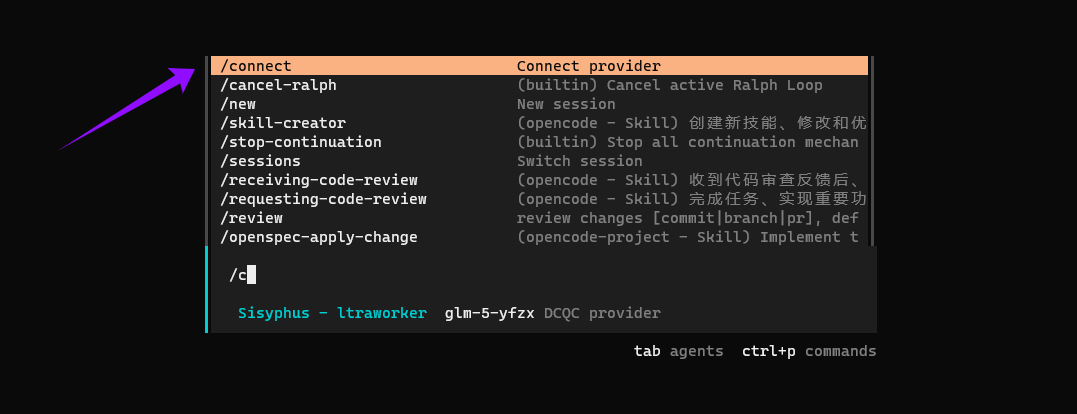
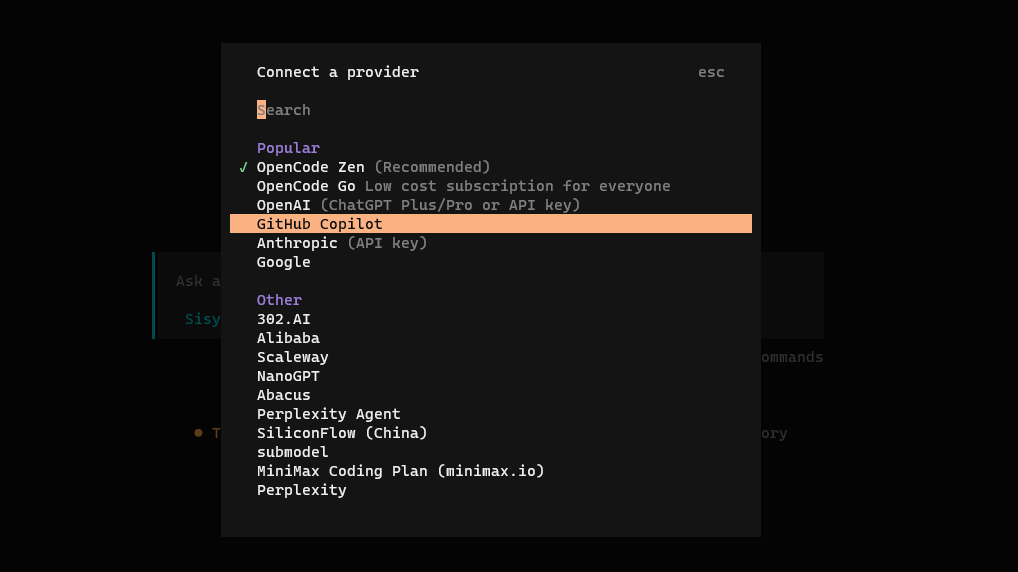
1.3 确认模型提供商在搜索结果中找到 Local_provider公司的大模型 AI 提供商,按 Enter 确认。
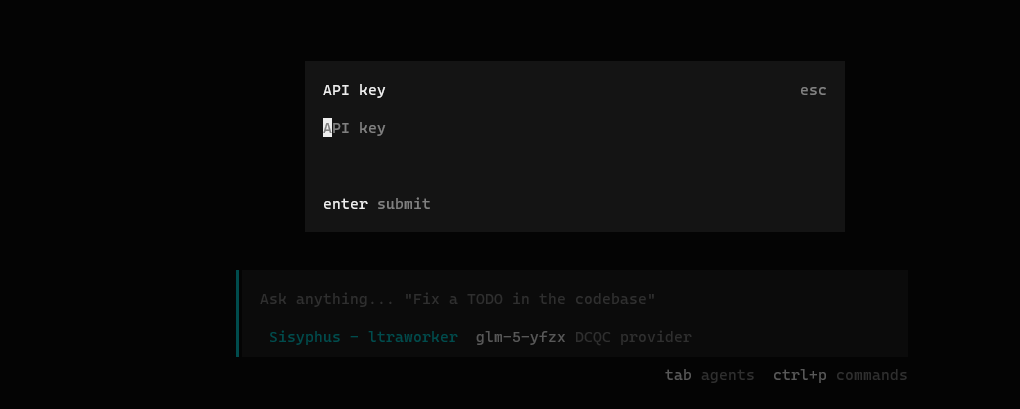
1.4输入 API Key根据提示,输入公司为你颁发的 API Key 秘钥。
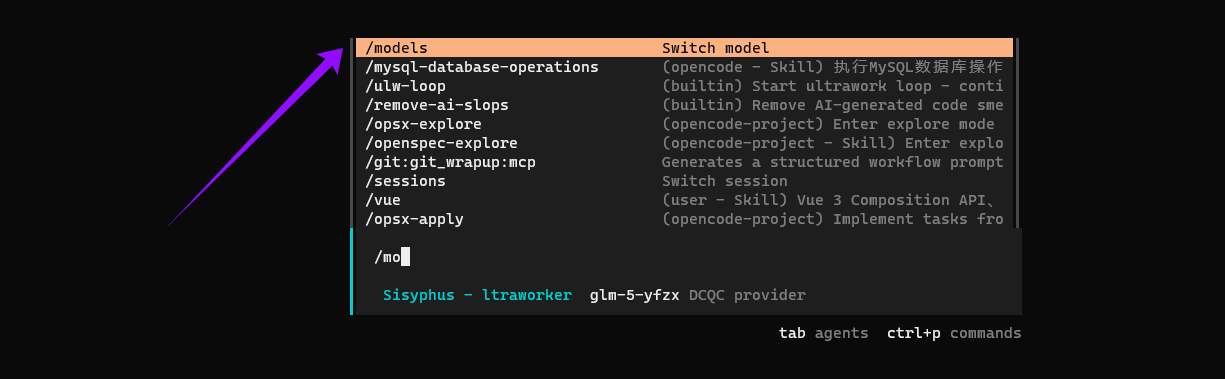
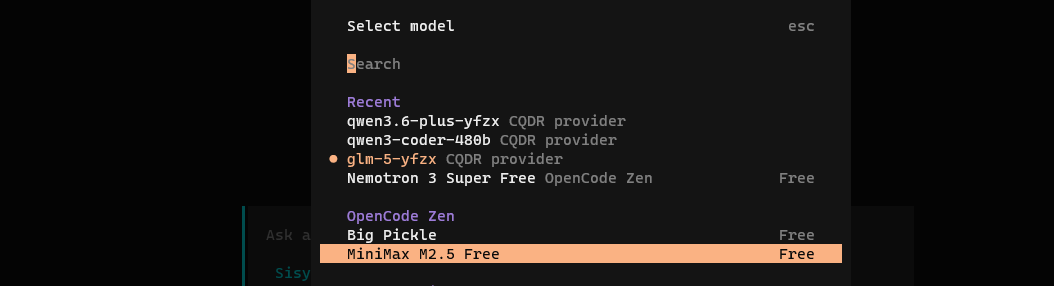
1.5**切换模型(可选)**连接成功后,你可以通过 /models 命令切换公司提供的其他模型。默认模型已在配置中预设,无需额外设置。
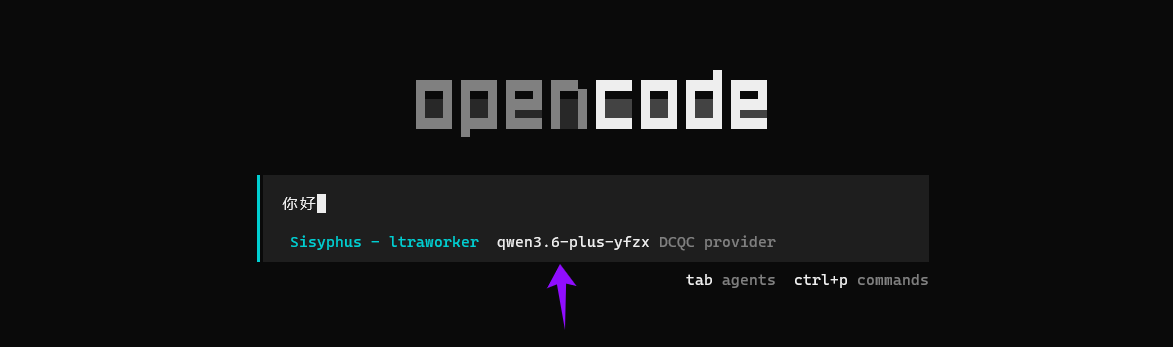
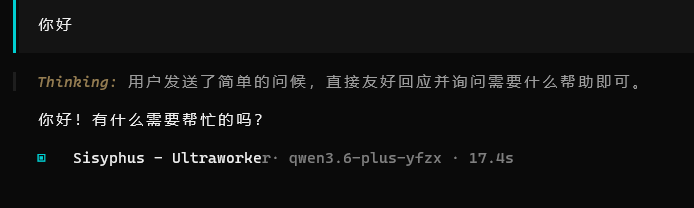
1.6 测试模型连接输入一个简单问题,例如:“你好”,如果能正常收到回复,说明配置成功。
2. OpenCode 项目实战(初阶形态)
-
进入项目根目录,打开 OpenCode 终端。
-
选择一个性能较好的模型,确认连接正常。
-
初始化项目上下文:输入
/init命令,OpenCode 会自动扫描项目结构并生成AGENTS.md文件,为 AI 提供理解项目所需的基础信息。 -
理解两种核心交互模式:OpenCode 围绕
/plan和/build两个命令切换工作模式。/plan模式:仅分析,不修改代码。/build模式:分析并执行修改操作。
-
根据任务选择合适的模式,并熟悉常用命令:
/undo— 一键撤销 AI 的错误修改,安全可靠。/redo— 重做上一次撤销的操作。/models— 在不同 AI 模型之间切换。/new— 开始新会话(别名:/clear)。/sessions— 列出并切换历史会话(别名:/resume、/continue)。/compact— 压缩当前对话上下文,释放 Token。/exit— 退出 OpenCode(别名:/quit、/q)。
-
高效提出需求,释放 AI 潜能
OpenCode 的能力上限很大程度上取决于你输入的提示词质量。以下是一些实用建议:- 具体化:不要只说“优化代码”,而要说“优化
src/utils/format.js中的dateFormatter函数,使其支持 ISO 8601 格式,并添加错误处理”。 - 分步骤:复杂任务可拆解为多个小步骤,每完成一步验证一次。例如:“1. 创建一个
api文件夹;2. 在文件夹中生成user.js,包含获取用户信息的 axios 请求;3. 在main.js中引入并挂载到 Vue 原型上。” - 提供示例:给出输入/输出的例子,或引用项目中已有的类似代码,让 AI 模仿风格。
- 指定约束:明确要求如“不要修改其他文件”“使用 ES6 语法”“添加 JSDoc 注释”等。
- 迭代反馈:如果 AI 第一次输出不够理想,可以补充说明:“你生成的代码没有处理空字符串的情况,请补充一个
if判断。”
只要提示词足够精准、任务边界清晰,OpenCode 在代码生成、重构、文档编写、单元测试等方面都能展现出非常强大的能力。
跳转到之前的对话:进入opencode输入/session,选中你想进入的会话直接进去即可。
- 具体化:不要只说“优化代码”,而要说“优化
3.OpenCode (进阶形态):标准化与自动化 使用工具、创建Skills、Agents,接入MCP服务器
初阶形态中,你已掌握通过
/plan和/build与 AI 协同完成单次任务。但面对复杂项目或团队协作时,重复性指令、风格不一致、上下文碎片化等问题会显著降低效率。为此,OpenCode 提供 进阶能力:通过 Skills(技能模块) 与 Agents(智能体) 实现任务标准化,并通过 MCP 服务器 实现跨项目、跨模型的统一调度与状态管理。
3.1 permission 工具,
OpenCode 的所有“能力”都由底层工具(tools)驱动,而这些工具的行为受 permission 控制。
原生内置工具:
- read - 原生文件读取
- write - 原生文件写入
- edit - 原生文件编辑
- glob - 原生文件模式匹配
- grep - 原生内容搜索
你可以在项目根目录的 .opencode/config.json 中精细控制 AI 能做什么、不能做什么。
{
"$schema": "https://opencode.ai/config.json",
"permission": {
"read": "allow", // 允许读取任意文件内容
"edit": "deny", // 禁止直接编辑文件(安全模式)
"bash": "ask", // 执行 shell 命令前需用户确认
"websearch": "allow", // 允许联网搜索(如查 API 文档)
"webfetch": "allow", // 允许抓取网页内容
"question": "allow", // 允许 AI 主动向你提问澄清需求
"todowrite": "allow", // 自动维护任务清单(用于多步操作)
"skill": "allow", // 允许加载和使用 Skills
"lsp": "allow", // 启用语言服务器协议(跳转定义、智能提示等)
"glob": "allow", // 支持通配符搜索文件(如 src/**/*.ts)
"grep": "allow" // 支持正则全文搜索
}
}
- 在生产项目中,建议将
"edit": "ask"或"deny",避免意外覆盖。 - 开发初期可设为
"allow",提升效率,但务必配合/undo使用。
3.2 Skills 技能
Skill 是一个封装了特定意图、输入/输出规范、执行逻辑和约束条件的可复用代码模板。它本质上是“提示词 + 执行策略”的标准化产物。
如何使用现有 Skill
-
从社区下载热门 Skill 包(注意安全,有投毒的恶意Skill),访问
https://skills.sh,选择你需要的功能,例如:frontend-designagent-browserskill-creator
-
社区扩展安装Skill方式:npx skills add
https://github.com/numpy/numpy.git--skill frontend-design- 国内快速稳定使用清华镜像代理:npx skills add https://mirrors.tuna.tsinghua.edu.cn/git/源地址
-
使用方式:例如 /use xxx技能名称 skill,需要做什么事情。
-
Skill使用示例:
-
例如使用自定义的SKill,执行数据库操作:/use mysql-database-operations skill ,查询用户表的建表语句是什么;
-
模型输出:找到了!用户表 sys_user 的建表语句如下: -- ---------------------------- -- 2、用户信息表 -- ---------------------------- create table sys_user ( user_id bigint(20) not null comment '用户ID', tenant_id varchar(20) default '000000' comment '租户编号', dept_id bigint(20) default null comment '部门ID', user_name varchar(30) not null comment '用户账号', nick_name varchar(30) not null comment '用户昵称', primary key (user_id) ) engine=innodb comment = '用户信息表'; -
例如使用查询市面上的技能:/use find-skills 查询spirngboot项目最佳实践的技能有哪些,列举2条;
-
根据搜索结果,我为你整理了 SpringBoot 项目最佳实践相关的2条推荐技能: --- SpringBoot 项目最佳实践技能推荐 1. 🥇 java-springboot (12.4K 安装量) 来源: github/awesome-copilot GitHub 官方维护的 SpringBoot Java 开发最佳实践技能,是最热门的 SpringBoot 技能。 npx skills add github/awesome-copilot@java-springboot -g -y 🔗 https://skills.sh/github/awesome-copilot/java-springboot --- 2. 🥈 java-spring-boot (10.4K 安装量) 来源: pluginagentmarketplace/custom-plugin-java 专注于 Spring Boot 框架的开发指南和最佳实践。 npx skills add pluginagentmarketplace/custom-plugin-java@java-spring-boot -g -y 🔗 https://skills.sh/pluginagentmarketplace/custom-plugin-java/java-spring-boot --- 推荐安装顺序 如果你需要 SpringBoot 项目最佳实践,建议优先安装前2个: # 最推荐的组合 npx skills add github/awesome-copilot@java-springboot -g -y npx skills add jeffallan/claude-skills@spring-boot-engineer -g -y 需要我帮你安装这些技能吗?
-
Agents:具备上下文记忆的智能体
Agent 是一个拥有持久身份、专属技能集、记忆缓存和目标导向的 AI 实体。它能长期跟踪项目演进,主动提出优化建议。
OpenCode 内置多个官方 Agent,无需编码即可使用:
| Agent 名称 | 功能说明 |
|---|---|
code-reviewer |
自动审查 PR,指出潜在 bug、性能问题、风格违规 |
doc-writer |
根据代码自动生成 README、API 文档、CHANGELOG |
test-gen |
为新函数自动生成测试用例 |
security-audit |
扫描依赖漏洞、硬编码密钥、不安全 API |
使用方法
# 启动一个代码审查 Agent
/agent start code-reviewer
# 让它分析最近一次提交
/agent run code-reviewer --since=HEAD~1
🔔 Agent 会自动读取
AGENTS.md中的项目规范,并结合历史上下文做出判断。
---
📋 变更内容分析
变更类型: SQL 数据修复 - 菜单表 INSERT 语句字段值修正
修改内容:
将 sys_menu 表 INSERT 语句中的两个字段值从字符串改为整数:
字段
is_frame
is_cache
涉及菜单: 16 个工作流菜单按钮(流程定义管理 9 个 + 流程实例管理 7 个)
接入 MCP(Model Control Protocol)服务器
MCP 工具的设计初衷是扩展能力,而非替代原生工具。原生工具处理本地文件更高效,MCP 用于连接外部服务(文档库、浏览器、Git 平台等)。
常用的MCP:
filesystem:允许 AI 读写本地文件系统(通过@modelcontextprotocol/server-filesystem)context7:Upstash 提供的向量记忆/上下文工具
测试 filesystem MCP : filesystem MCP 工具会自动接管 read / edit / glob 等文件操作,前提是权限允许。
npx -y @modelcontextprotocol/server-filesystem “D:\zhawu\self\jianzhixiangmu”
测试 context7 MCP
npx -y @upstash/context7-mcp@latest
在 opencode.json配置MCP:信息
{
"$schema": "https://opencode.ai/config.json",
"mcp": {
"filesystem": {
"type": "local",
"command": ["npx", "-y", "@modelcontextprotocol/server-filesystem", "D:\\zhawu\\self\\jianzhixiangmu"],
"enabled": true
},
"context7": {
"type": "local",
"command": ["npx", "-y", "@upstash/context7-mcp@latest"],
"enabled": true
}
}
}
提问的时候注意触发MCP调用的关键场景

(三)OpenCode (终极形态):OpenSpec + Superpowers + OmO

OpenSpec 是“大脑”(思考做什么)。
Superpowers 是“肌肉”(规范怎么做)。
OmO 是“神经系统”(协调谁来做)。
OpenSpec(规范驱动)、Superpowers(技能框架) 和 oh-my-openagent(多模型编排),代表了 AI 编程从“辅助模式”向“自主模式”进化的三个流派。
2026 年是一个“分水岭”。我们不再满足于 Copilot 那样的“自动补全”,而是追求能独立完成复杂任务的“超级个体”。
完整协作流程为:OpenSpec 创建变更提案 → Superpowers 动态调整任务计划 → OmO 提供底层工具支持 → Superpowers 并行执行任务 → OmO + Superpowers 测试验证 → OpenSpec 归档闭环。
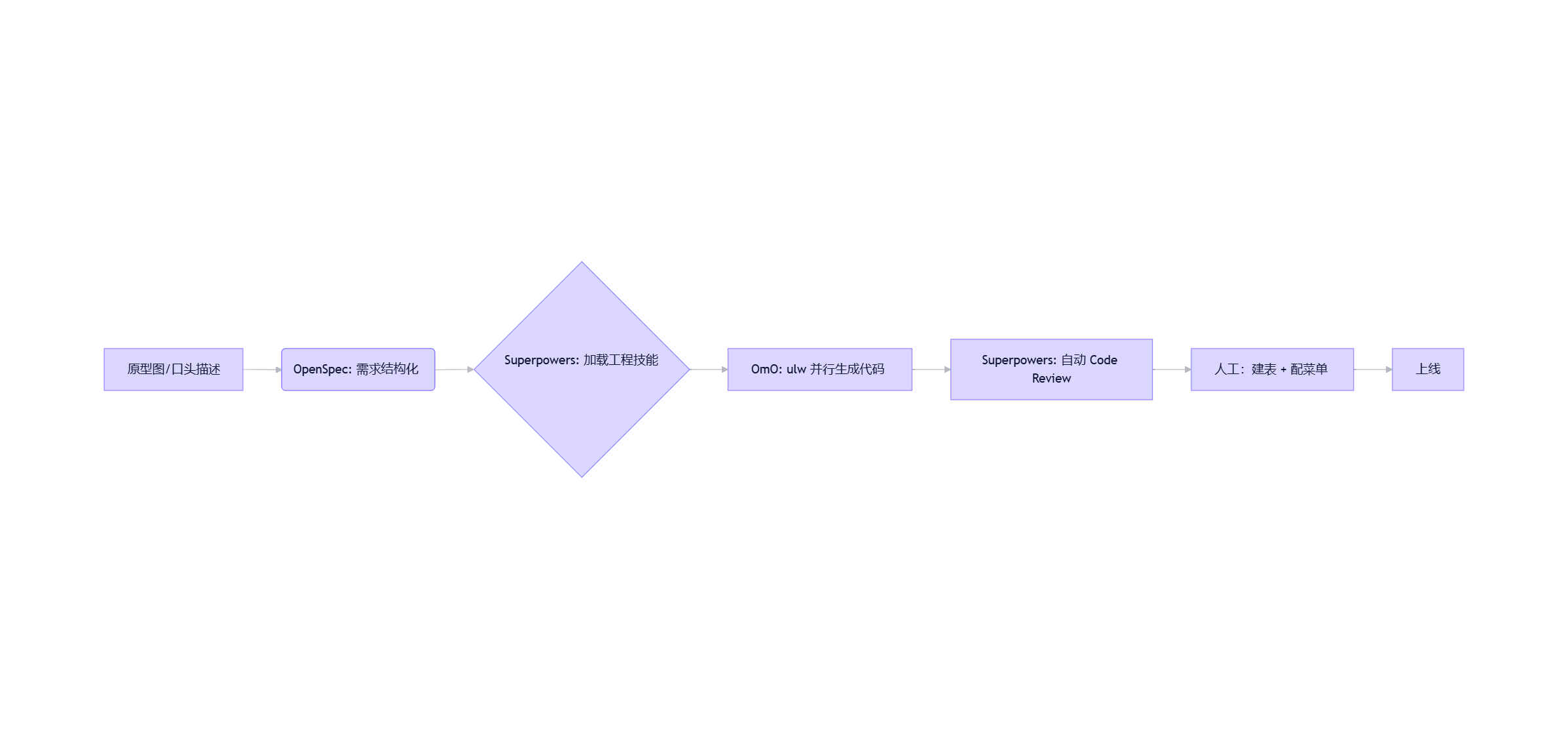
三大框架:定位与分工
🧭 整体思路:三阶段工作流
| 阶段 | 核心目标 | 使用框架 | 关键动作 |
|---|---|---|---|
| 1. 规划与设计 | 明确需求、技术方案、任务拆解 | OpenSpec | 生成提案 → 技术规格 → 架构设计 |
| 2. 开发与测试 | 高质量、可维护地实现功能 | Superpowers + OmO | 并行编码 + TDD + Git Flow |
| 3. 审查与交付 | 确保代码合规、可合并、可部署 | Superpowers | 自动 Code Review + PR 生成 |
第一步:部署 OpenSpec
OpenSpec 不依赖 OpenCode 插件系统,而是在项目级别进行初始化。
部署方式:
-
互联网安装全局安装 CLI 工具(在系统终端执行):
npm install -g @fission-ai/openspec@latest -
在目标项目目录执行初始化:
openspec init .
📁
openspec init会创建openspec/文件夹,包含:
proposal.md(提案)specs.md(规格)design.md(设计)
💡 若想在 OpenCode 中直接使用
/opsx开头的命令,可能还需安装 OpenSpec 对应的 OpenCode 集成插件。
第二步:部署 Superpowers
Superpowers 通过 OpenCode 的插件系统注入“工程技能”,是提升 AI 代码质量的基础。
部署方式:
/plugin install superpowers-zh
验证安装:
-
重启 OpenCode
-
执行以下命令验证:
/plugin list -
或直接询问 AI:“列出你当前加载的所有 Superpowers 技能”
✅ 若安装成功,AI 将列出已加载的技能,如
brainstorming、test-driven-development等。
第三步:安装部署 oh-my-openagent (OmO)
OmO 是一个强大的 OpenCode 插件,提供多智能体协作能力。
部署方式:
-
安装插件:
/plugin install oh-my-openagent -
初始化配置:
omo init
⚠️ 注意:
ulw(ultrawork)是 OmO 安装并初始化完成后才能使用的核心指令,不是安装命令。
注意配置~/.config/opencode/oh-my-openagent.json配置model信息:
{
"$schema": "https://raw.githubusercontent.com/code-yeongyu/oh-my-openagent/dev/assets/oh-my-opencode.schema.json",
"agents": {
"hephaestus": {
"model": "Local_provider/qwen3.6-plus-yfzx"
}
},
"categories": {
"visual-engineering": {
"model": "Local_provider/qwen3.6-plus-yfzx"
}
}
}
略过很多。。。。。
具体的配置信息如下opencode.json:注意plugin有插件,但不包含 OpenSpec
{
"$schema": "https://opencode.ai/config.json",
"disabled_providers": [],
"model": "Local_provider/MiniMax-M2.5-yfzx",
"provider": {
"Local_provider": {
"name": "Local provider",
"npm": "@ai-sdk/openai-compatible",
"models": {
"MiniMax-M2.5-yfzx": {
"name": "MiniMax-M2.5-yfzx",
"limit": {
"context": 931072,
"output": 60536
}
}
},
"options": {
"baseURL": "http://127.0.0.1:14000/v1"
}
}
},
"plugin": [
"oh-my-openagent@latest",
"superpowers-zh@latest"
],
"mcp": {
"filesystem": {
"type": "local",
"command": ["npx", "-y", "@modelcontextprotocol/server-filesystem", "D:\\zhawu\\self\\jianzhixiangmu", "C:\\Users\\Admin\\workspace"],
"enabled": true
},
"context7": {
"type": "local",
"command": ["npx", "-y", "@upstash/context7-mcp@latest"],
"enabled": true
},
"playwright": {
"type": "local",
"command": ["npx", "-y", "@playwright/mcp@latest"],
"enabled": true
},
"git": {
"type": "local",
"command": ["npx", "@cyanheads/git-mcp-server@latest"],
"enabled": true
}
}
}
终极形态:协同工作流实战
当三者部署完毕后,你将获得一个拥有“思维、纪律和协作能力”的数字工程师团队。
OpenSpec 的核心是一条 Artifact 依赖链,每个 artifact 都是前一个的细化:
| Artifact | 职责 | 核心内容 |
|---|---|---|
| proposal.md | 变更提案 | 为什么做、目标/非目标、影响范围 |
| design.md | 设计决策 | 技术方案选择、替代方案对比、风险评估 |
| specs/*.md | 需求规格 | Requirements + Scenarios(WHEN/THEN) |
| tasks.md | 任务清单 | 可执行的 checkbox 任务列表 |
1. 需求分析与方案设计(OpenSpec)
1、在项目的根目录执行: openspec init
2、它会提示你选择当前系统所用的agent:这里我们选择opencode就好了。
3、结束后会在项目根路径下创建openspec 文件夹。
-
当前项目根路径终端-用户输入(终端):(传统)
-
openspec proposal 帮我添加API管理功能,包含API的增删改查,API支持GET/PUT/POST/DELETE等类型,支持Header设置参数,支持普通的Restfull和Event事件流式接口这个功能
-
-
或在 OpenCode 中说,让opencode使用大模型完成提案(推荐)
-
“请根据 OpenSpec 规范,帮我添加API管理功能,包含API的增删改查,API支持GET/PUT/POST/DELETE等类型,支持Header设置参数,支持普通的Restfull和Event事件流式接口;这个功能生成提案。”
-
-
OpenSpec 生成详细技术提案,并存入
openspec/目录。- 自己写也行。。。。
运行过程
具体的OpenSpec 的流程在opencode创建过程如下:(规范驱动由AI大模型完成,如果不满意可以手动找到对应的几个md文件修改即可)
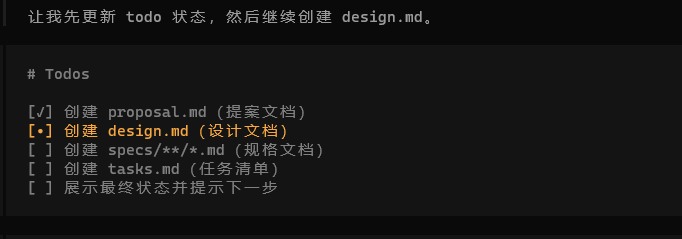
等待生成完成之后,opencode会将任务规划打印出来:

检查项目OpenSpec 的规范文件是否落地成功:
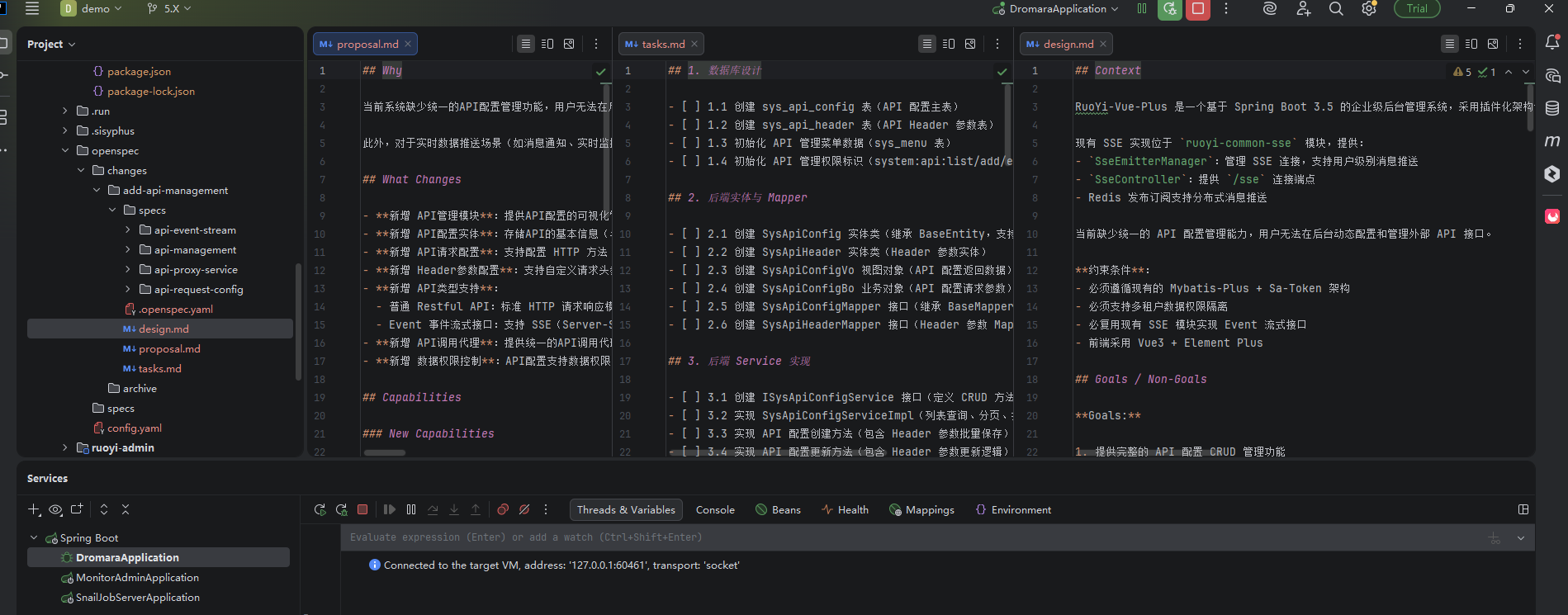
2. 任务拆解与并行开发(OmO + Superpowers)
| 场景 | 命令 |
|---|---|
| 探索需求 | /opsx:explore |
| 创建变更 | /opsx:propose <name> |
| 生成计划 | /superpowers:writing-plans |
| 执行任务 | /superpowers:subagent-driven |
| 验证结果 | /opsx:verify |
| 归档变更 | /opsx:archive |
| 切换 Agent | 在 OpenCode Tab 中点击(需设 mode: primary) |
具体项目的实战流程:
OMO 最强大的特性。你不需要详细描述如何分工,只需在 Prompt 中包含魔法词:
ultrawork/ulw: 激活“全火力”模式。Sisyphus 会自动启动后台搜索、调用专家、进行深度重构,直到任务彻底完成。ultrathink: 强制开启深度思考模式,适用于解决极其复杂的逻辑 Bug 或架构选型。search/find: 自动并行启动多个 Explore 智能体进行全量代码库扫描。
**💡 **实战技巧:
在 OpenCode 中直接说:“请基于 openspec/design.md 开始开发”,AI 就会严格遵循你定义的架构,而不是自由发挥。
-
或者用户输入:
-
ulw 根据 design.md,实现API管理这个功能
-
-
OmO 自动拆解任务,调度多个智能体并行工作。
-
/superpowers:subagent-driven-development
-
-
编码智能体自动加载 Superpowers 的
test-driven-development技能,先写测试,再写实现。
3. 代码审查与合并(Superpowers)
- 开发完成后,Superpowers 的
requesting-code-review技能自动触发,进行自我审查,确保代码符合规范后再合并。
执行过程:它执行到不愿意执行的时候,可以通过提示词加方案让opencode继续完成任务。
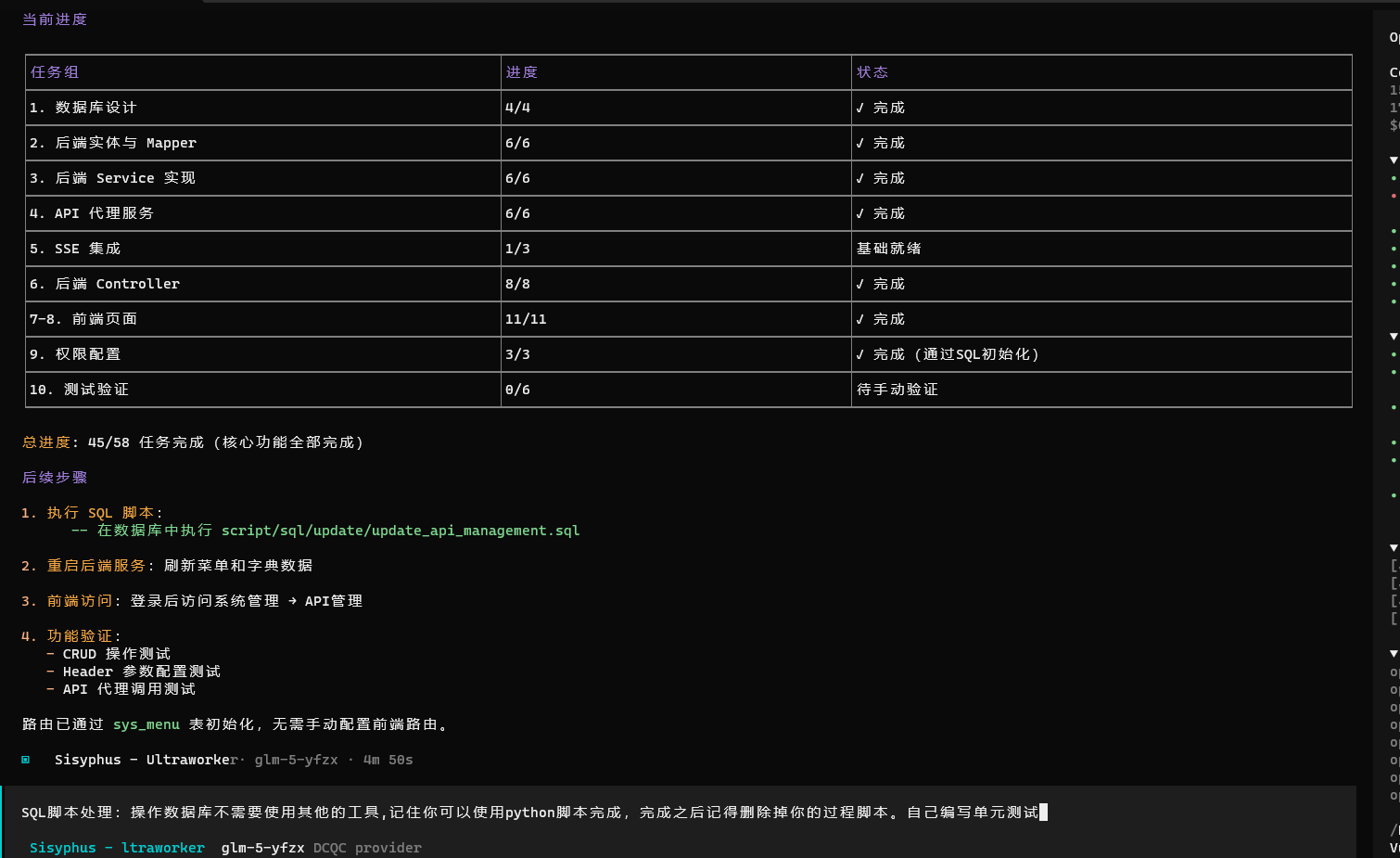

常用件套命令;
# OMO
ulw <需求> # 懒人模式,自动完成
/ralph-loop "<任务>" # 不完成不停止
/ulw-loop "<任务>" # 最大火力模式
/init-deep # 生成代码知识图谱
/refactor <模块> --scope=file # 安全重构
/start-work # 执行计划
# Superpowers
帮我计划<需求> # 激活 brainstorming
帮我debug # 激活 systematic-debugging
# OpenSpec
openspec propose "<功能>" # 创建提案
openspec verify # 验证实现
openspec update # 更新
结合Opencode大部分的指令可以直接用自然语言对话式的输入到对话框里完成:例如【根据openspec规范的/opsx:verify指令,你需要自动化完成验证,验证通过后根据指令/opsx:archive自动化归档提交git】
部署总结表
| 插件/框架名称 | GitHub 地址 | 核心部署命令 | 执行位置 | 说明 |
|---|---|---|---|---|
| Superpowers | github.com/obra/superpowers | /plugin install superpowers |
OpenCode TUI | OpenCode 插件,安装后自动加载工程技能 |
| oh-my-openagent (OmO) | github.com/code-yeongyu/oh-my-openagent | /plugin install oh-my-openagent + omo init |
OpenCode TUI | 安装后需执行 omo init 完成配置 |
| OpenSpec | github.com/fission-ai/openspec | npm install -g @fission-ai/openspec + openspec init |
系统终端 / 项目目录 | 项目级框架,不依赖 OpenCode 插件系统 |
优化技巧:任务步骤过多的时候,会超上下文、使用/compact,第一波处理,实在是压缩也不行了开启新的任务,指定未完成的task继续执行。

成果展示全程不懂一行代码:相当丝滑。
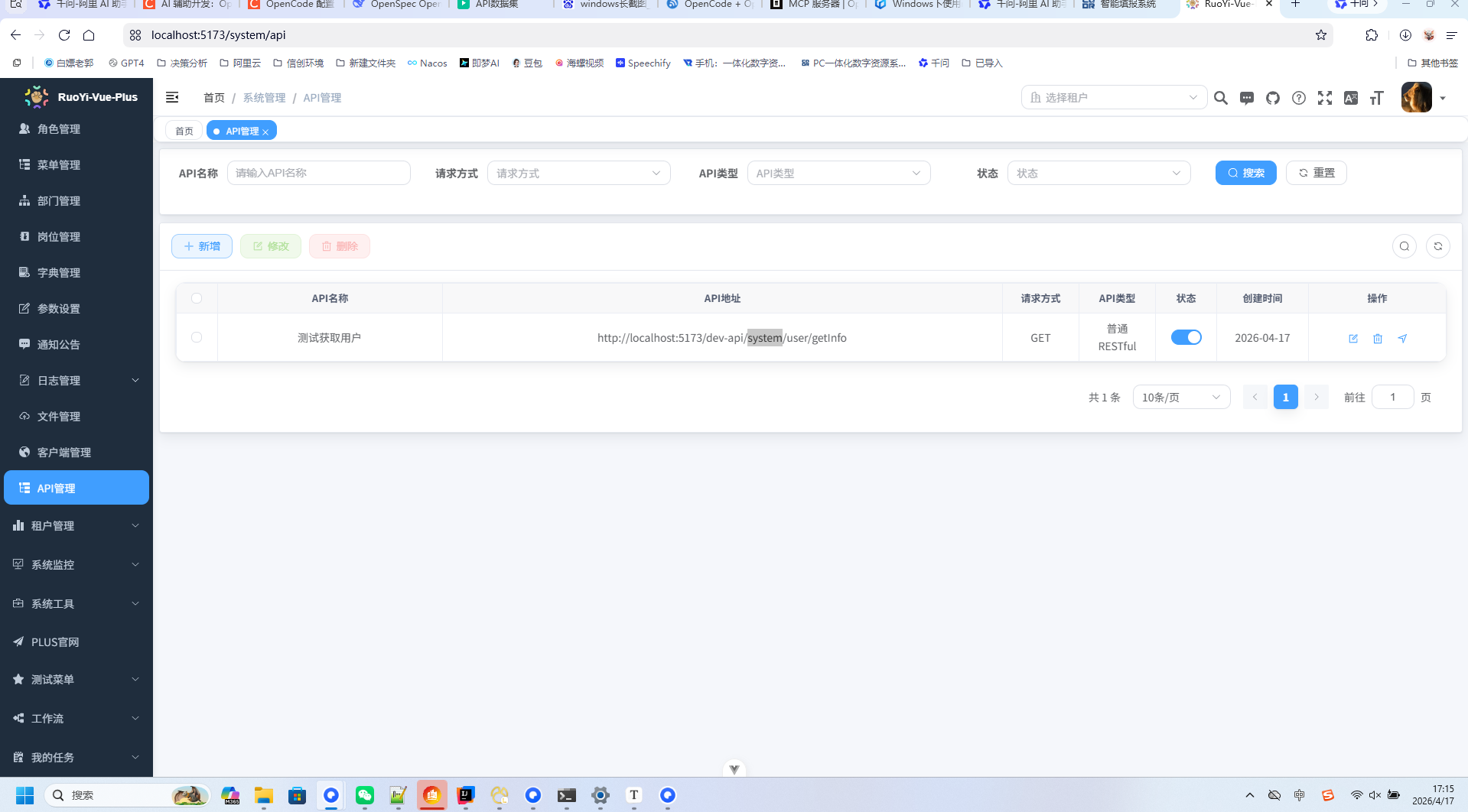
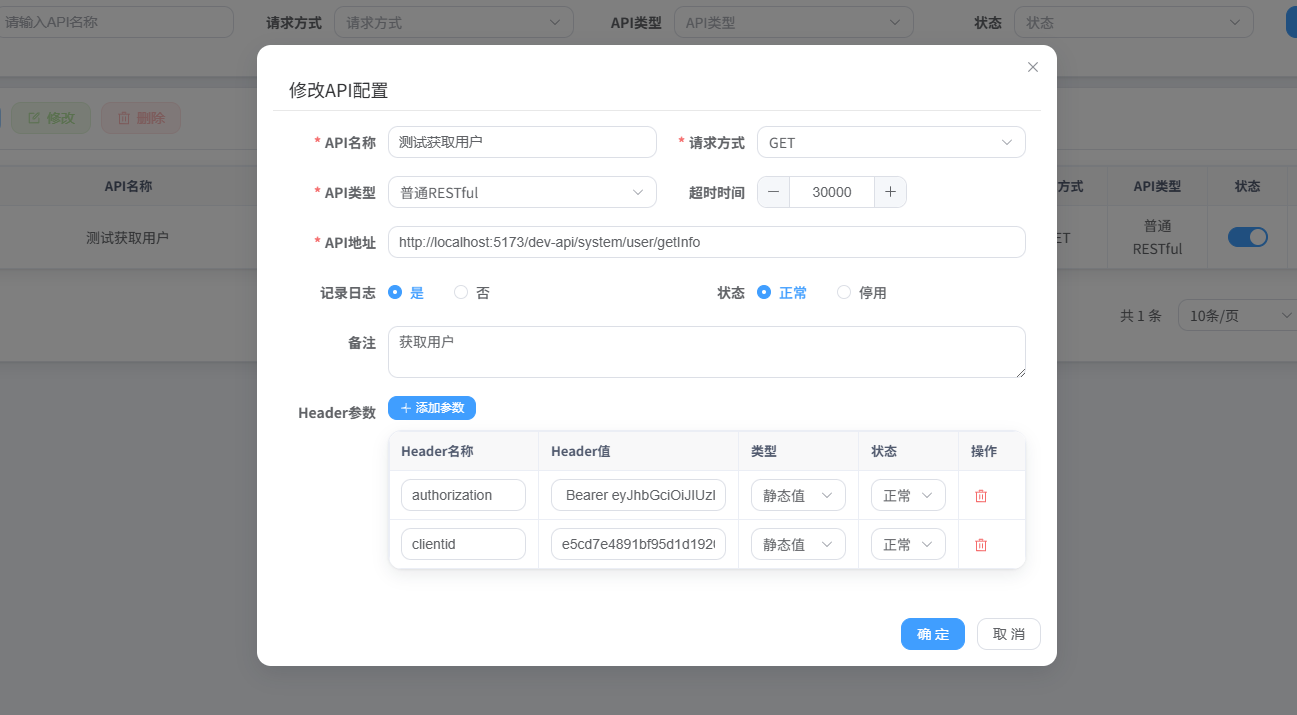
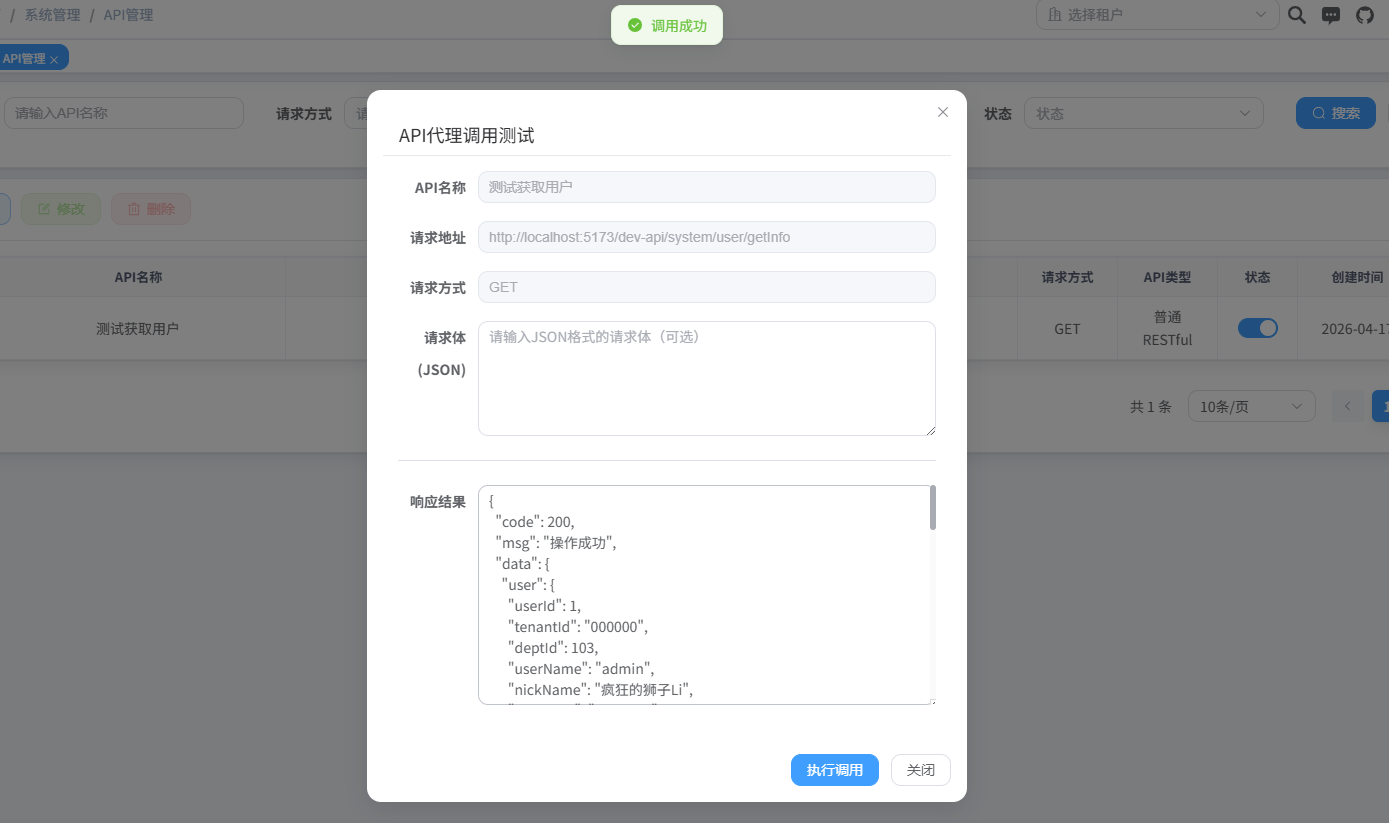
提示词优化:以设计者视角预判 AI Agent 的不确定性,确保结果导向的一步到位
在设计 AI Agent 的执行链路时,应站在设计者层次,以结果导向反向推导:Agent 在执行过程中因哪些信息不明确会导致无法一步到位?以下是最常见的不确定性场景及其系统性解决方案,可沉淀为项目上下文中的“指导思想文件”。
1. 环境与操作系统不明确
- 问题:Agent 不知道当前运行环境(Windows / Linux / macOS),可能混用
cmd、powershell、bash、zsh命令,或调用不存在的系统 API。 - 后果:反复试错,浪费大量时间和 token,甚至误修改系统配置。
- 解决方案:
- 在项目根目录提供
.env或AGENT_CONTEXT.md,明确声明OS_TYPE=windows(或linux)、SHELL=powershell。 - 所有脚本命令前显式标注执行环境,如
[win-cmd]、[linux-bash]。
- 在项目根目录提供
2. 编译构建环境及工具链版本缺失
- 问题:Agent 不知道项目依赖的具体工具版本(JDK、Maven、Node、Python、Gradle 等),可能使用系统默认版本或错误版本。
- 后果:编译/运行阶段反复报错(如
UnsupportedClassVersionError、missing dependency),多次重试后仍失败。 - 解决方案:
- 在
AGENT_GUIDE.md中写明:JDK_PATH=C:\jdk-17、MAVEN_HOME=D:\apache-maven-3.9.0。 - 提供一键环境检测脚本,Agent 执行前自动校验并输出当前版本,不匹配则中止并提示人工介入。
- 在
3. 脚本执行意图不明确(SQL、迁移、数据初始化)
- 问题:AI 完成功能后生成了 SQL 脚本或数据迁移脚本,但不会主动执行,也不知道执行顺序、连接参数、失败回滚策略。
- 后果:任务停留在“代码完成”,数据库状态未同步,导致集成测试失败或功能不完整。
- 解决方案:
- 形成 脚本执行指导文件(如
SCRIPT_RUNBOOK.md),包含:- 脚本清单及执行顺序
- 数据库连接串(占位符由 Agent 替换)
- 执行命令(如
psql -f script.sql或python migrate.py) - 成功/失败判断标准(如影响行数、错误码)
- 要求 Agent 在生成脚本后立即读取该指导文件,按步骤执行并验证。
- 形成 脚本执行指导文件(如
4. 历史错误未系统化沉淀
- 问题:Agent 在不同任务中反复犯同类错误(如忘记处理文件编码、忽略超时设置、使用已废弃的 API)。
- 后果:每次遇到相同场景都要重新试错,效率低下且不可靠。
- 解决方案:
- 建立 错误经验库(如
LESSONS_LEARNED.md),按错误类型分类,记录触发条件、正确做法、检查点。 - 要求 Agent 在执行关键任务前先扫描该文件,并在执行日志中引用相关条目。
- 每次人工纠正 Agent 后,自动追加新条目到错误经验库,形成闭环。
- 建立 错误经验库(如
5. 流程执行缺乏强制性规范(OpenSpec 思想)
- 问题:Agent 可能跳过某些必要步骤(如单元测试、代码格式化、变更日志更新),直接输出“完成”。
- 后果:交付物质量差,遗漏非功能性要求,后期返工成本高。
- 解决方案:
- 基于 OpenSpec 思想,将任务拆解为强制顺序的阶段(规划 → 编码 → 测试 → 文档 → 提交),每个阶段定义明确的输入、输出和验收标准。
- 在提示词中嵌入检查清单,Agent 每完成一个阶段必须自检并输出
[PASS]标记,未通过则不允许进入下一阶段。
6. 上下文过载导致轻重知识混淆
- 问题:对话历史过长(超过模型有效窗口),Agent 开始遗忘早期约束条件,或对次要细节过度关注,忽略核心目标。
- 后果:生成内容发散、重复、自相矛盾,或突然出现不相关建议。
- 解决方案:
- 使用 上下文压缩指令:定期要求 Agent 将当前状态总结为结构化快照(包括已完成任务、未完成任务、关键决策、待解决问题),然后替换原始历史。
- 示例提示:“请将以上对话压缩为 500 字以内的任务快照,保留环境配置、当前文件列表、下一步目标。”
7. 长时间任务中断与恢复机制缺失
- 问题:任务执行到一半(如编译大型项目、批量数据处理),因 token 超限或会话超时中断,Agent 无法从中断点继续。
- 后果:需要重新开始,浪费大量前期计算成果。
- 解决方案:
- 在每个阶段任务完成后,Agent 必须输出一个 档案快照(
checkpoint.json),记录:- 已完成步骤清单
- 生成/修改的文件列表及校验和
- 未完成任务的下一个动作
- 所有重要环境变量和临时决策
- 当需要开启新会话时,将最新的快照作为输入,并指示:“继续执行快照中的未完成任务,不要重复已完成步骤。”
- 在每个阶段任务完成后,Agent 必须输出一个 档案快照(
8. 依赖关系和执行顺序未显式声明
- 问题:任务中存在隐性依赖(例如:必须先启动数据库服务,再运行后端;必须先下载数据集,再执行分析脚本),Agent 可能并行执行或逆序执行。
- 后果:执行失败,且错误信息不直观(如“端口被占用”“文件不存在”),难以定位。
- 解决方案:
- 使用有向无环图(DAG)形式在
WORKFLOW.md中定义依赖关系,例如:A: 启动数据库 → B: 执行迁移 → C: 启动后端服务 A → B → C - 要求 Agent 执行前解析 DAG,严格按拓扑顺序执行,并在完成每个节点后标记
[DONE]。
- 使用有向无环图(DAG)形式在
9. 成功标准模糊或缺失
-
问题:Agent 被要求“完成一个功能”,但不知道什么是“完成”——是没有编译错误?通过全部测试?还是用户手动验收?
-
后果:Agent 提前终止任务,或者无限细化、超出范围。
-
解决方案:
- 在每个任务描述中嵌入 验收条件(AC, Acceptance Criteria),格式如:
AC1: 所有单元测试通过(`npm test` 返回 exit code 0) AC2: 无 linter 警告 AC3: 生成的 API 文档包含新增接口 - Agent 在最终输出前必须逐条验证 AC,并附上证据(如测试日志截图、命令输出)。
- 在每个任务描述中嵌入 验收条件(AC, Acceptance Criteria),格式如:
10. 外部资源与权限未提前说明
- 问题:Agent 需要访问外部 API、私有仓库、挂载磁盘、管理员权限等,但未被告知可用凭证或限制策略。
- 后果:执行时遇到
403、sudo required、network unreachable,卡住并尝试无意义的修复。 - 解决方案:
- 创建
ACCESS_MANIFEST.md,列出:- 允许访问的 URL 白名单
- 无需认证的路径 / 需使用的 API Key(占位符)
- 哪些命令需要提权(并说明如何提权,如
runas/sudo -u) - 禁止执行的操作(如删除系统文件、修改注册表)
- Agent 执行任何外部访问前应先查阅该清单,若所需权限不在清单中,则主动询问设计者。
- 创建
总结:系统性落地方法
以上所有“不明确点”均可通过 预先加载到项目上下文的指导文件 来消除。建议创建以下标准文件集:
AGENT_CONTEXT.md– 环境、工具链、路径、OS 信息SCRIPT_RUNBOOK.md– 所有需要执行的脚本及其运行方式LESSONS_LEARNED.md– 历史错误与正确做法WORKFLOW.md– 依赖关系与强制顺序(OpenSpec 风格)ACCESS_MANIFEST.md– 外部资源与权限清单CHECKPOINT.json– 任务快照,用于断点续传
并要求 Agent 在执行任何实质性动作之前,先扫描这些文件,并在每阶段完成后更新相关文件。通过这种“设计者先定义确定性,Agent 仅填充执行细节”的范式,可将一步到位成功率提升至 90% 以上。
(可选)进阶Base基础全局提示词系统级优化
外面有两个版本自定义修改全局或者项目级
基础提示词邪修项目全局规范与上下文(AGENTS.md|CLAUDE.md)
交互要求
- 你在处理所有问题时,全程思考过程必须使用中文(包括需求分析、逻辑拆解、方案选择、步骤推导等所有内部推理环节);
- 最终输出的所有回答内容(包括文字解释、代码注释、步骤说明等)必须全部使用中文,仅代码语法本身的英文关键词除外。
1. 项目核心定位与业务边界
- 项目名称:企业级微服务后台管理系统
- 核心业务:用户认证、信息管理、RBAC权限管控、操作审计
- 业务边界:仅处理用户域相关逻辑,不涉及订单、商品等其他业务域
- 合规要求:符合等保2.0三级规范,用户敏感数据必须加密存储,所有操作留痕
2. 技术栈与版本约束
- 后端:Java 21 + Spring Boot 3.5.x + Spring AI Alibaba 1.1.2.2
- 数据库:MySQL 8.0 + Redis 7.2 + MyBatis-Plus 3.5.16
- 运维:Docker 26.x + Kubernetes 1.30.x + GitHub Actions
- 强制约束:所有依赖版本必须与pom.xml中保持一致,禁止引入未声明的第三方依赖,禁止使用已废弃的API
3. 编码规范与代码风格
- 命名规范:类名使用大驼峰,方法名/变量名使用小驼峰,常量全大写下划线分隔,禁止拼音缩写
- 注释规范:所有类、公共方法必须带JavaDoc注释,核心业务逻辑必须带行内注释,注释需说明“为什么这么做”而非“做了什么”
- 异常处理:所有异常必须捕获并分类处理,禁止空catch块,业务异常需定义统一错误码,系统异常需记录完整堆栈日志
- 接口规范:所有RESTful接口必须遵循统一返回格式,路径统一放在/api/v1/业务域/下,GET请求禁止传Body,POST请求必须做参数校验
4. 架构与分层约束
- 严格遵循Controller→Service→Mapper三层架构,禁止跨层调用
- Controller层仅做参数校验和结果返回,禁止包含业务逻辑
- Service层分为接口层和实现层,核心业务逻辑必须在Service层实现,禁止在Mapper层写业务逻辑
- 数据库操作必须使用MyBatis-Plus,禁止裸写SQL,查询必须使用LambdaQueryWrapper,禁止拼接SQL字符串,复杂的查询可以在Mapper的接口层使用注解@Select(“xxsqlxx”)完成,禁止使用xml。
5. 安全与合规红线
- 禁止硬编码密钥、AK/SK、数据库密码等敏感信息,所有配置必须通过环境变量或者配置文件或者配置中心注入
- 所有用户输入必须做校验和过滤,防止SQL注入、XSS攻击、路径遍历等安全漏洞
- 用户密码必须使用BCrypt加密存储,禁止明文存储,禁止可逆加密
- 所有接口必须做权限校验,除登录接口外,禁止未授权访问,越权操作必须拦截并记录审计日志
6. 权限与操作约束
- 修改核心业务逻辑、数据库表结构前,必须先输出实现方案,经人工确认后再执行
- 禁止执行rm -rf、drop table、alter table等高危命令,执行前必须人工二次确认
- 代码修改完成后,必须自动执行单元测试,确保原有功能不受影响
- 所有Git提交必须遵循约定式提交规范,commit message必须清晰说明修改内容
7. 交付与测试标准
- 所有功能开发必须附带对应的单元测试用例,单元测试覆盖率不得低于80%
- 核心接口必须附带压力测试用例,确保单接口QPS不低于1000,响应时间不超过100ms
- 所有功能必须附带详细的使用文档,包含接口说明、入参出参、异常场景、使用示例
- 本地系统环境为Windows11;JDK指定位置:D:\anzbao\jdk21\jdk-21.0.7;Maven指定配置文件位置:D:\anzbao\Maven\apache-maven-3.9.13\conf\settings.xml;
- 操作数据库不需要使用其他的工具,记住你可以使用python脚本完成,完成之后记得删除掉你的过程脚本。
- 分析后端接口日志,在项目的根路径下的log文件里面找log日志文件
8. AI 协作指令
- 上下文最小化:仅引用当前任务相关文件(使用 @filename);
- 需求复述校验:在生成代码前,先复述需求、约束、交付标准;
- 自我批评迭代:对核心逻辑,执行 “生成 → 自我评审(指出≥5个缺陷)→ 优化” 流程;
- 调试闭环:遇错时自动添加日志 → 复现 → 定位 → 修复 → 验证。
9. 多智能体研发协作框架指导
可根据具体的项目场景自动化创建多个智能体角色写作完成对应的任务,按需增减设定的六个智能体。
| 智能体角色 | 核心职责 | 专业能力要求 | 交付物 |
|---|---|---|---|
| 主架构师代理 | 项目总负责人,负责需求拆解、任务分配、方案审核、进度管控、跨角色协调 | 全栈架构设计能力,微服务架构经验,项目管理能力 | 项目架构方案、任务拆解清单、里程碑计划、方案审核报告 |
| 前端专家代理 | 负责前端项目搭建、UI组件开发、交互逻辑实现、响应式适配、前端性能优化 | React/Vue/TS专家,UI/UX设计能力,前端工程化经验 | 前端项目代码、交互组件、单元测试用例、部署配置 |
| 后端专家代理 | 负责后端接口开发、数据库设计、业务逻辑实现、缓存策略设计、接口性能优化 | 对应语言/框架专家,微服务开发经验,数据库优化能力 | 后端项目代码、SQL脚本、接口文档、单元测试用例 |
| 测试专家代理 | 负责测试用例设计、单元测试、集成测试、E2E测试、压力测试、bug定位与回归验证 | 测试开发专家,自动化测试经验,性能压测能力 | 测试用例、自动化测试脚本、测试报告、bug修复建议 |
| 安全审计专家代理 | 负责代码安全审计、漏洞扫描、合规校验、渗透测试、安全方案优化 | 网络安全专家,等保合规经验,渗透测试能力 | 安全审计报告、漏洞修复方案、合规校验报告 |

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)