多模态AI工程师:2026年最抢手的复合型人才
多模态AI工程师成为稀缺人才,供需比1:1.3远优于纯NLP工程师的1:6。核心差距在于跨模态融合能力,而非单一领域技能。文章从技术架构角度解析多模态工程师的核心能力:1)CLIP对比学习实现图文对齐;2)BLIP-2的Q-Former桥接视觉与语言模型;3)LLaVA的轻量化线性投影方案。重点指出多模态RAG系统在企业落地中的关键作用,以及视觉编码器优化等工程挑战。建议4个月转型路径:先补足CV
纯NLP工程师供需比1:6,多模态AI工程师供需比1:1.3。
差距不在"会的多",而在"能把不同模态融在一起"。
前言:为什么多模态突然这么值钱?
2026年的AI产品,几乎全在走多模态方向。
GPT-4o能同时处理文本、图像、语音。Gemini原生多模态。Claude 3.5支持图像理解。
企业要落地这些能力,就需要能够设计和实现多模态系统的工程师。
但问题是:会NLP的人和会CV的人都很多,能把两者融合起来的人极少。
这就是多模态工程师薪资溢价的根源——不是因为技术更难,而是因为跨领域融合的能力稀缺。
本文从技术栈的角度,拆解多模态AI工程师需要掌握的核心能力。
一、多模态AI的核心架构
1.1 多模态系统的基本结构
任何多模态系统都可以拆解为三个模块:
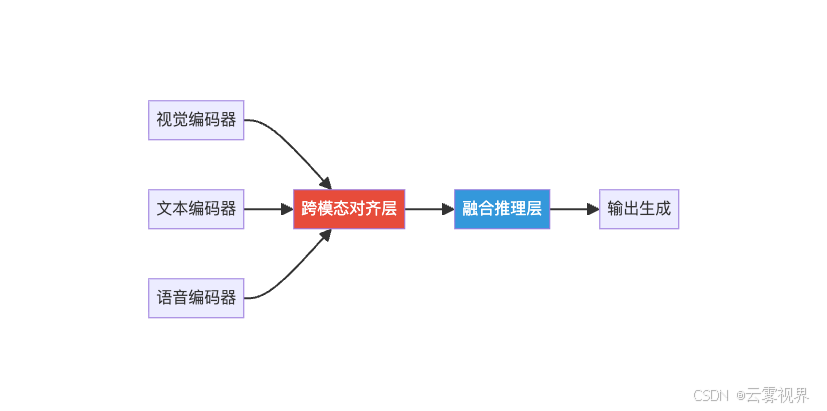
视觉编码器: 把图像转换为特征向量。主流选择是ViT(Vision Transformer)系列。
文本编码器: 把文本转换为特征向量。通常是预训练的LLM(如LLaMA、Qwen)。
跨模态对齐层: 这是多模态系统最核心的模块——把不同模态的特征映射到同一个语义空间。
为什么对齐层这么重要?因为图像特征和文本特征"说的不是同一种语言"。ViT输出的特征向量维度、分布、语义粒度都跟LLM的文本特征不同。如果不做对齐,模型根本无法理解"这张图片对应这段文字"。
1.2 三大主流架构对比
| 架构 | 代表模型 | 对齐策略 | 优势 | 劣势 |
|---|---|---|---|---|
| 对比学习 | CLIP | 图文对比损失 | 训练简单,零样本能力强 | 不能生成文本 |
| Q-Former桥接 | BLIP-2 | 可学习查询向量 | 效率高,参数少 | 架构复杂 |
| 线性投影 | LLaVA | 线性层映射 | 简单直接,效果好 | 依赖强视觉编码器 |
二、CLIP:跨模态对齐的基石
CLIP(Contrastive Language-Image Pre-training)是多模态AI的基石。即使你不直接用CLIP,理解它的原理也是必须的。
2.1 核心思想
CLIP的训练目标很简单:让匹配的图文对在特征空间中距离近,不匹配的图文对距离远。
import torch
import torch.nn.functional as F
class CLIPModel(torch.nn.Module):
"""简化版CLIP模型"""
def __init__(self, image_encoder, text_encoder, embed_dim=512):
super().__init__()
self.image_encoder = image_encoder # ViT-B/16
self.text_encoder = text_encoder # Transformer
# 投影层:将不同维度的特征映射到统一空间
self.image_proj = torch.nn.Linear(image_encoder.output_dim, embed_dim)
self.text_proj = torch.nn.Linear(text_encoder.output_dim, embed_dim)
# 可学习的温度参数
self.temperature = torch.nn.Parameter(torch.tensor(0.07))
def forward(self, images, texts):
# 提取特征
image_features = self.image_proj(self.image_encoder(images))
text_features = self.text_proj(self.text_encoder(texts))
# L2归一化
image_features = F.normalize(image_features, dim=-1)
text_features = F.normalize(text_features, dim=-1)
# 计算相似度矩阵
logits = torch.matmul(image_features, text_features.T) / self.temperature
return logits
def compute_loss(self, logits):
"""对比学习损失:对称的交叉熵"""
batch_size = logits.shape[0]
labels = torch.arange(batch_size, device=logits.device)
# 图→文方向的损失
loss_i2t = F.cross_entropy(logits, labels)
# 文→图方向的损失
loss_t2i = F.cross_entropy(logits.T, labels)
return (loss_i2t + loss_t2i) / 2
这段代码的核心逻辑:把图像和文本分别编码,投影到同一维度空间,然后用对比损失训练。对角线上的元素(匹配的图文对)相似度要高,非对角线(不匹配的)要低。
2.2 温度参数的作用
注意self.temperature = 0.07这个参数。它控制了相似度分布的"尖锐程度":
- 温度低(0.01):分布极其尖锐,模型非常确定哪些是匹配的。但容易过拟合。
- 温度高(1.0):分布平坦,模型对所有对都"不确定"。欠拟合。
- 0.07是经验值,在大多数场景下效果最好。
CLIP的创新在于它让温度成为可学习参数,模型自己找到最优温度。
三、BLIP-2:高效的多模态桥接
BLIP-2的核心创新是Q-Former——一个轻量级的桥接模块,用可学习的查询向量从视觉特征中提取与语言相关的信息。
3.1 为什么需要Q-Former?
直接把ViT的输出(比如257个patch token)全部送入LLM,会有两个问题:
- Token太多: 257个视觉token + 文本token,LLM的计算量爆炸
- 信息冗余: 不是所有patch都与当前问题相关。你问"图中有几个人",背景的天空patch是噪声
Q-Former用32个可学习的查询向量(query),通过交叉注意力从257个视觉token中"提问",提取出最相关的32个特征向量送入LLM。
信息压缩比:257 → 32,减少了87.5%的视觉token。
class QFormer(torch.nn.Module):
"""简化版Q-Former"""
def __init__(self, num_queries=32, hidden_dim=768, num_layers=6):
super().__init__()
# 可学习的查询向量
self.queries = torch.nn.Parameter(
torch.randn(num_queries, hidden_dim)
)
# 交叉注意力层
self.cross_attention_layers = torch.nn.ModuleList([
torch.nn.MultiheadAttention(hidden_dim, num_heads=12, batch_first=True)
for _ in range(num_layers)
])
# 自注意力层
self.self_attention_layers = torch.nn.ModuleList([
torch.nn.MultiheadAttention(hidden_dim, num_heads=12, batch_first=True)
for _ in range(num_layers)
])
self.layer_norms = torch.nn.ModuleList([
torch.nn.LayerNorm(hidden_dim) for _ in range(num_layers * 2)
])
def forward(self, visual_features):
"""
visual_features: [batch, 257, 768] — ViT输出
返回: [batch, 32, 768] — 压缩后的视觉特征
"""
batch_size = visual_features.shape[0]
queries = self.queries.unsqueeze(0).expand(batch_size, -1, -1)
for i in range(len(self.cross_attention_layers)):
# 查询向量之间的自注意力
q_sa, _ = self.self_attention_layers[i](queries, queries, queries)
queries = self.layer_norms[i*2](queries + q_sa)
# 查询向量对视觉特征的交叉注意力
q_ca, _ = self.cross_attention_layers[i](queries, visual_features, visual_features)
queries = self.layer_norms[i*2+1](queries + q_ca)
return queries # [batch, 32, 768]
Q-Former的设计非常优雅:它不改动视觉编码器,也不改动LLM,只在中间加了一个轻量级桥接模块。这意味着你可以冻结ViT和LLM的参数,只训练Q-Former(参数量约100M),大幅降低训练成本。
四、LLaVA:极简但有效的方案
LLaVA(Large Language and Vision Assistant)走了另一条路:不用复杂的Q-Former,直接用一个线性层把视觉特征映射到LLM的输入空间。
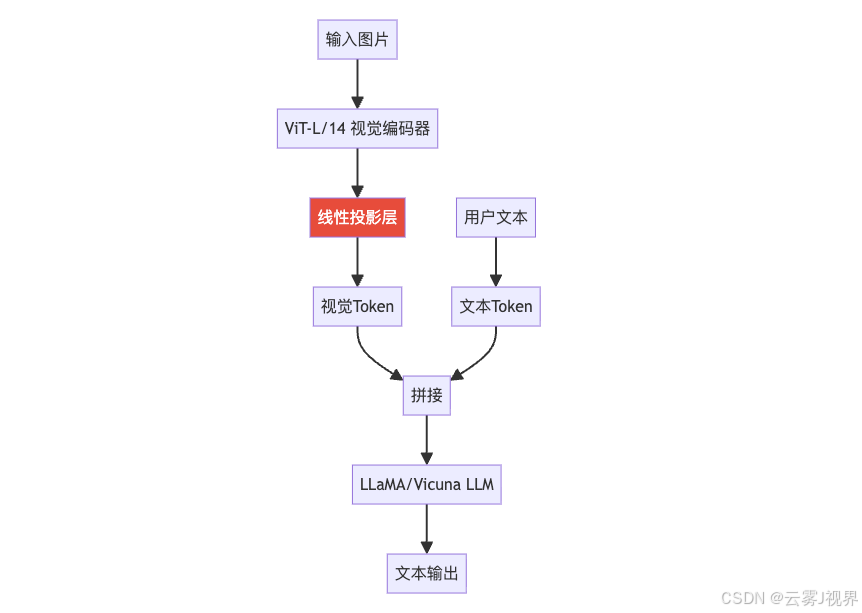
class LLaVA(torch.nn.Module):
"""简化版LLaVA架构"""
def __init__(self, vision_encoder, llm, vision_dim=1024, llm_dim=4096):
super().__init__()
self.vision_encoder = vision_encoder # 冻结
self.llm = llm # 可微调
# 核心:就是一个线性层(或MLP)
self.visual_projection = torch.nn.Sequential(
torch.nn.Linear(vision_dim, llm_dim),
torch.nn.GELU(),
torch.nn.Linear(llm_dim, llm_dim),
)
def forward(self, image, text_input_ids):
# 1. 提取视觉特征
with torch.no_grad():
visual_features = self.vision_encoder(image) # [batch, 576, 1024]
# 2. 投影到LLM空间
visual_tokens = self.visual_projection(visual_features) # [batch, 576, 4096]
# 3. 获取文本embedding
text_embeddings = self.llm.get_input_embeddings()(text_input_ids)
# 4. 拼接:视觉token + 文本token
combined = torch.cat([visual_tokens, text_embeddings], dim=1)
# 5. 送入LLM
output = self.llm(inputs_embeds=combined)
return output
LLaVA的哲学是:视觉编码器足够强(ViT-L/14在CLIP上预训练过),那对齐层就不需要太复杂。 一个两层MLP就够了。
实测结果也证明了这一点——LLaVA在多个多模态benchmark上的表现跟BLIP-2相当,甚至在某些任务上更好。
三种架构选型建议
| 场景 | 推荐架构 | 理由 |
|---|---|---|
| 图文检索/匹配 | CLIP | 对比学习天然适合检索 |
| 图像问答/对话 | LLaVA | 简单高效,效果好 |
| 多任务(检索+问答+生成) | BLIP-2 | Q-Former灵活性最高 |
| 端侧部署 | LLaVA-Lite | 架构简单,易压缩 |
五、多模态RAG:企业落地的关键
多模态RAG(Retrieval-Augmented Generation)是多模态技术在企业中落地的核心场景。
传统RAG只检索文本。多模态RAG可以同时检索文本、图片、表格、PDF扫描件。
class MultimodalRAG:
"""多模态RAG系统"""
def __init__(self, clip_model, llm, vector_db):
self.clip = clip_model
self.llm = llm
self.vector_db = vector_db
def index_document(self, doc):
"""索引多模态文档"""
chunks = []
# 文本块
for text_chunk in doc.text_chunks:
embedding = self.clip.encode_text(text_chunk)
chunks.append({"type": "text", "content": text_chunk, "embedding": embedding})
# 图片
for image in doc.images:
embedding = self.clip.encode_image(image)
caption = self.generate_caption(image)
chunks.append({
"type": "image",
"content": image,
"caption": caption,
"embedding": embedding
})
# 表格(转为文本描述后编码)
for table in doc.tables:
table_text = self.table_to_text(table)
embedding = self.clip.encode_text(table_text)
chunks.append({"type": "table", "content": table, "embedding": embedding})
self.vector_db.insert(chunks)
def query(self, question: str, top_k=5):
"""多模态检索+生成"""
# 1. 编码查询
query_embedding = self.clip.encode_text(question)
# 2. 检索(同时搜索文本、图片、表格)
results = self.vector_db.search(query_embedding, top_k=top_k)
# 3. 构建多模态上下文
context = self._build_context(results)
# 4. LLM生成答案
prompt = f"""基于以下多模态信息回答问题。
{context}
问题:{question}
答案:"""
return self.llm.generate(prompt)
多模态RAG的关键难点不在代码,而在跨模态检索的准确性——用文本query去检索图片时,CLIP的对齐质量直接决定了检索效果。这也是为什么理解CLIP对比学习原理如此重要。
六、推理优化:多模态系统的工程挑战
多模态系统的推理比纯文本LLM更复杂,因为需要同时运行视觉编码器和语言模型。
6.1 视觉编码器优化
视觉编码器(ViT-L/14)的推理占总时间的30-40%。优化策略:
# 策略1:视觉特征缓存
# 如果同一张图片被多次提问,不需要重复编码
from functools import lru_cache
class CachedVisionEncoder:
def __init__(self, encoder):
self.encoder = encoder
self.cache = {}
def encode(self, image_hash, image):
if image_hash not in self.cache:
self.cache[image_hash] = self.encoder(image)
return self.cache[image_hash]
# 策略2:图片分辨率自适应
# 简单问题用低分辨率,复杂问题用高分辨率
def adaptive_resolution(image, question_complexity):
if question_complexity < 0.3:
return resize(image, 224) # 快速推理
elif question_complexity < 0.7:
return resize(image, 336) # 平衡
else:
return resize(image, 448) # 高精度
6.2 性能基准
| 配置 | 首Token延迟 | 吞吐量 | 显存 |
|---|---|---|---|
| LLaVA-7B (FP16) | 280ms | 45 tokens/s | 15GB |
| LLaVA-7B (INT8) | 190ms | 62 tokens/s | 8GB |
| LLaVA-7B (INT4) | 150ms | 78 tokens/s | 5GB |
| BLIP-2 (FP16) | 350ms | 38 tokens/s | 18GB |
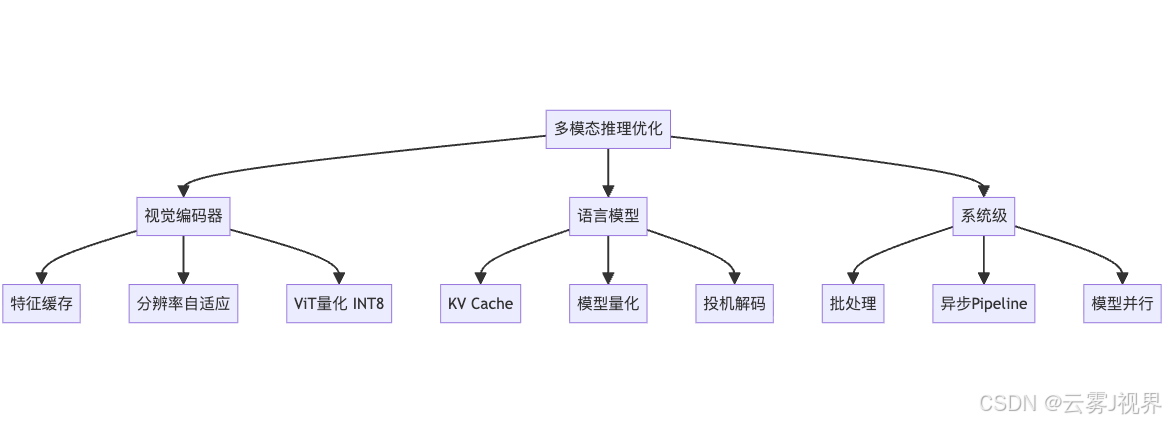
七、多模态工程师的技能图谱
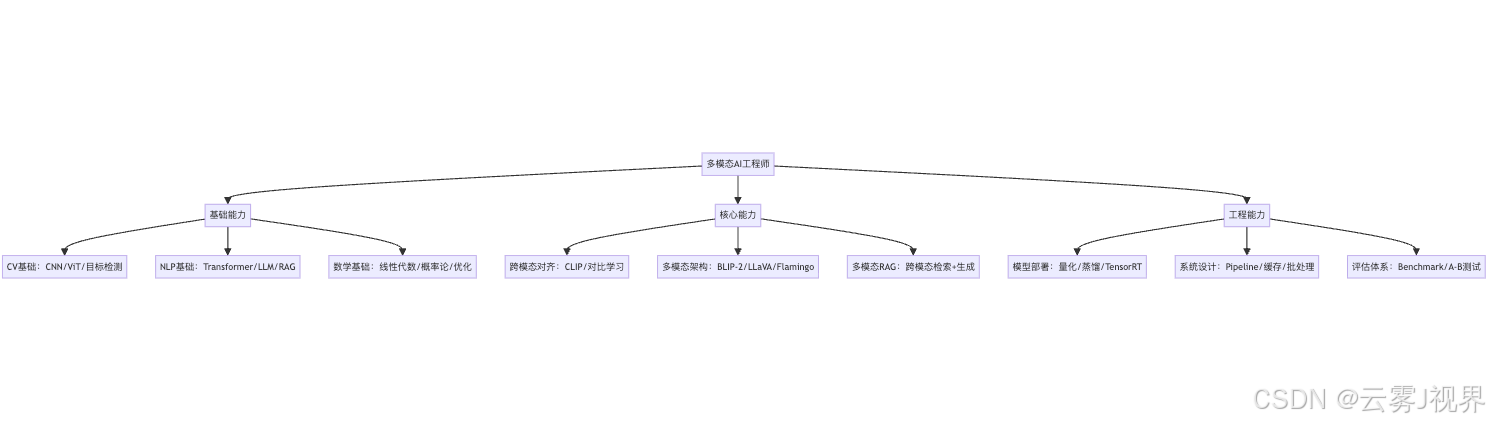
学习路径建议
Phase 1(1个月): 基础补齐
- NLP背景 → 学ViT、ResNet、CLIP
- CV背景 → 学Transformer、Attention、LLM推理
Phase 2(2个月): 核心技术
- 精读CLIP、BLIP-2、LLaVA论文
- 用Hugging Face复现一个简单的多模态问答系统
Phase 3(1个月): 工程化
- 搭建多模态RAG系统
- 学习模型量化和部署优化
4个月时间,足以从单模态工程师转型为多模态工程师。 投入产出比极高——薪资涨幅50%以上。
总结
多模态AI不是"什么都会一点"的通才路线,而是一种跨领域融合的专业能力。
它的稀缺性来自三个方面:
- 需要同时理解CV和NLP两个领域
- 跨模态对齐是一个独立的技术方向,不是简单拼接
- 工程化落地比单模态系统复杂得多
2026年,几乎所有AI产品都在走多模态方向。现在学多模态,就是在为未来3-5年的职业做最好的投资。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献140条内容
已为社区贡献140条内容

所有评论(0)