从多模态到世界模型:AI3.0的演进之路与未来展望
本文探讨了多模态技术与世界模型的发展现状及未来趋势。文章指出,多模态正处于数字空间LLM与真实空间robotics之间的关键位置,是具身智能的重要瓶颈。世界模型技术呈现多元化发展,包括Dreamer系列、JEPA等不同分支,视频预测与动作预测的结合成为重要趋势。在生成模型方面,扩散模型已成为主流范式,DiT架构展现出长期价值,但仍存在推理效率低、难以扩展等局限。文章还梳理了多模态理解模型的演进历程
一、从多模态到世界模型
我为啥把“多模态”和“世界模型”为啥放一起,看谢赛宁的采访,他把数字空间LLM和真实空间robotics放在智能光谱的两端,那么从LLM推演到robotics,这恰恰是视觉智能和多模态要解决的问题(以不做机器人的方式),这非常make sence,我之前也发了类似的朋友圈观点,VQA、VLA是远不够的,具身智能需要解决多模态理解的瓶颈。数字空间LLM经过推理优化(reasonning)、工具增强(OpenClaw/harness)、自进化机制,已经快接近AGI了;但是真实空间robotics领域,从fundamental research角度尚处早期[这波具身智能仅适合早期投资]。那么,多模态方向就正处于瓶颈同时又中心的位置。
世界模型则是相对综合的,从古早的DreamerV1(2020)模型就能看出来,编解码框架融合了动力学模型,Planet首次提出了循环状态空间模型RSSM,结合CNN和VAE,实现隐空间预测。在此基础上也可以引入更复杂的MPC、Actor-Critic策略方法。Dreamer系列作为一大分支、后面的很多世界模型研究也类似,自动驾驶的朋友应该比较熟悉。另一大分支就是Muzero和JEPA了,2025年JEPA在多模态方向成果密集且显著,比如V-JEPA2(25.06)、LeJEPA(25.11)、VL-JEPA(25.12),以及最新的LeWorldModel(26.03)。由于与生成式模型技术显著不同,年初我花了很多时间来系统学习JEPA的底层数学原理(那些痛苦😣的动力学知识😏)。
有很多人把Sora也作为世界模型的一大分支,我不太认可哈!我个人偏好认为,理解>生成,目前的Sora作为生成模型,其表征能力还远远达不到。太多公司押注视频路线了,数据多、落地更加pragmatic。而且就最近的成果来看,视频预测和动作预测的融合有很多惊艳的表现了(这点以后再讲)。有篇文章《关于世界模型的一切,全在这三万字里了》,相信挺多人看过,算是挺好的世界模型综述,作者(明显的游戏|视频|智驾视角)虽然有点抬高自己的视频生成技术路线和自己的创业公司General Intuition,给自己PR;如他所说,游戏场景是最能扩展|迁移|泛化到真实世界的世界模型场景,有点道理。但是各个“世界模型”和“世界模型”之间无论技术(RSSM/VLAs/JEPA/扩散)还是应用(游戏仿真/自动驾驶/机器人操作)差别很大,可能在较长时间内各走各路。
去2025至今,视频模型中把video prediction和action prediction结合的WM模型成果比较多,当然更早的话从谷歌Genie(24.02)就可以算起。Video模型真正成为backbone了,从预测下一帧到“预测下一个状态+最优动作”,这是个需要高度关注的确定性技术趋势。也许未来还有更好的视频预训练模型(非传统的latent patchify)、自监督视觉基础模型下(如DINO+JEPA)、SSM框架下的潜世界模型、或者视频扩散世界动作模型(WAM)、或者结合仿真物理引擎的RL,或者其他什么新的架构。
以后再写篇关于世界模型的长文。
回到多模态技术。
二、早期理解、早期生成
如果从多模态生成模型来看,这些技术方向都不算新鲜,已经发展好几年了,相对LLM的宏大成果而言显得很“陈旧”。比如突破性的扩散模型论文,去噪扩散概率模型DDPM(U-Net,像素空间),是2020年发表的,已经好几年了。如果从理解模型来看,对比学习的CLIP也是2021年发表的,也已经好几年了。
早期文图生成:在国内创业和投资圈,2021年前后,text2image的 AIGC也比ChatGPT的LLM更早受到关注(从DALL-E到数字人),架构比如GANs到扩散模型。这些古老成果咱就不深入了。更宽泛、更早一点讲,在国内Ai1.0时代,搞Vision的那批人要比搞NLP的那批人更受关注,也更容易获得商业成功。
早期理解模型:多模态理解往前溯的话,在ChatGPT引爆的2023年,多模态大语言模型(MLLM)的成果非常多,那个时候的成果试图利用这些模型的理解能力和强大的LLM结合,以理解图片内容。典型的这些“表征编码器”:Flamingo(22.04,交叉注意力)、BLIP-2(23.01,Q-Former)和InstructBLIP(23.05,Q-Former)、MiniGPT-4(23.04,Q-Former)、learnable query(典型如SEED、MetaQueries)、LLaVA(23.04,线性投影、指令微调)、DINO系列等。
我还梳理了不少,但发现早期效果表现都很一般。表现一般体现在:原因还是在于架构比较简单,使用交叉注意力、query、adapter或MLP来转换图像嵌入LLM,典型如Q-Former的桥梁对齐机制,视觉模型和LLM通常是冻结的。比如开源的MiniGPT-4(2023.04,注意虽然也叫“GPT”,但跟OpenAI没关系)通过Q-Former将视觉编码器(EVA-CLIP)与一个冻结的 LLM(Vicuna)对齐。再比如InstructBLIP,都已经指令调优了,幻觉依然很严重,复杂任务不忠实描述高达30%。
原理上讲,一定有人好奇模态之间究竟是如何对齐的,我们都知道是在大规模文本图像对上训练“强制”对齐的,但内部机制其实难被理解。有一研究(参考原文,《LLM为什么能看懂图?秘密不在Projector,残差结构才是跨模态理解的关键》)发现,即便模态特征空间对齐之后,仍然存在模态gap,图像embedding后语义信息薄弱。既然如此,LLM对图像的理解能力从何而来?研究表明三点:LLM随着层数加深而对齐,LLM中的残差结构起到refine作用,LLM天然存在大量“模型无关”神经元。
提一下2023年H2闭源成果。2023年9月OpenAI GPT-4V和2023年12月Google Gemini 1.0发布,在视觉推理、OCR和少样本学习任务上很强。闭源模型远比之前基于Meta LLaMA构建的模型(比如LLaVA 1.0、MiniGPT-4)强太多了。两者比较也差不多,但有人评测Gemini对多图像和时间的感知能力相比GPT-4V差一点。
三、DiT范式与扩散模型
生成模型从GANs快速转向到扩散模型(从DDPM和DDIM算起)。扩散原本结合主干UNet,将主干换成transformer,就是著名的DiT生成模型(22.12,论文曾被CVPR2023拒收),也是Sora(24.02)的技术基础,目前看依然是生成模型的事实标准,我觉得以后也将长期作为生成“组件”继续存在。
DiT技术:DiT大范围也归属于潜Latent 扩散模型、作为其网络主干,用SD的VAE将像素空间压缩到潜在空间,backbone用到transformer架构替代UNet,从而把“理解侧”和“生成侧”组合在一起。另外通过改进的adaLN-Zero实现更好的条件注入(除了γ、β,引入回归缩放α,初始化为0),以实现稳定训练。这里面没有涉及自回归损失,损失依然是噪声预测损失MSE,所以还是生成模型。更详细解释,transformer的输出与输入形状相同、都是带噪潜变量,输出是噪声预测张量并与真实噪声计算MSE损失,然后反向传播更新参数、并迭代数十到上千步。后面Sora推出的时空patches设计也是关键创新(用到了Google NaViT的Patch n’ Pack),实现了视频分辨率和高宽比的统一表征。
在2022-2023的那个时间点,DiT和Sora的确是最好的成果。受DiT影响,SD3.0(24.06)也从U-Net转移到了transformer,并且用了三个文本编码器(CLIP-vit-L、CLIP-G、T5)。横向对比同期国内成果,理解侧和生成侧的组合就要差点意思了:
1)我注意到国内某司的U-ViT(22.09)宣称是类似DiT的,PR往上面去靠拢。我翻了一下原论文,U-ViT是网络架构,可以对应到DiT论文中的一部分(但是比DiT先发出来,还是很厉害的)。U-ViT更多还是与CNN-based U-Net进行比较,引入ViT骨干,输入包括时间、类别/文本条件和噪声图像块,token空间是拼接的,但有长跳跃连接设计。
跟DiT比较的话,需要加上团队后续的工作Unidiffuser(23.03),采用的骨干网络是U-ViT,并且可通过Stable Diffusion将图像(拼接CLIP图像和文本特征)编码到latent space。Unidiffuser可以处理无条件生成、条件生成、联合生成、模态转换等不同任务,从应用多样性上有价值。
2)还有另一个某司,理解和生成模型更加松耦合,在图文对和视频文本对上训练,生成模型侧重视频(但没有类似spacetime patch设计),可能也更加垂直应用吧。应该也是成本太高了,现在已经没有声音了。
对扩散模型的评价
仅从生成角度来看,近几年都收敛到了扩散/流匹配模型。它的优点太多:比如稳定(尤其相对GANs)、灵活可控(适应各种条件采样)、计算高效(加速采样),目前来看也没有新的技术东东能真正取代它。
扩散模型的缺点也明显:
1)速度快了好多,但依然应用受限。它毕竟只是条件概率下的噪声预测回归模型,固定序列长度输出、没有好的衡量标准、缓存不复用、推理效率低等。最早的时候扩散模型需要反复去噪,甚至几十上百次,耗时长不足以支撑高质量视频。
当然后来由于LCM-LoRA(23.11)等步数蒸馏技术的发展,已经不需要那么多步数,4-8步就行。尤其是25年,许多几步甚至一步采样的流模型(流匹配和整流流)对于加速扩散生成也有极大的推动作用。
这方面的Infra技术一直在加强,比如生数和清华的视频生成加速框架TurboDiffusion(25.12),生成5秒720视频 on 消费级RTX 5090,用时38秒。用的技术:注意力层用清华的低比特量化SageAttention+稀疏计算方案、线性层W8A8的INT8量化、rCM步数蒸馏。但是38秒我觉得还是慢,应用受限。
2)Scalling是最大问题【这点仍然存在争议,后面会提到】。与LLM的分类模型相比、扩散模型没法scale(纯粹的扩散模型没法scale之前已经被证明,参考《Bigger is not Always Better: Scaling Properties of LDMs》,https://arxiv.org/abs/2404.01367),由于扩散模型一直没法自己真正成为主干模型,所以后面大部分的研究都嫁接了自回归主干架构(Diffusion Transformers可以scale,但是仅Diffusion不行)。虽有争议,我个人倾向认为如果仅扩散模型的确没法scale,但作为生成组件是合适的。
3)本质解构。何恺明和谢赛宁两位大神共同有篇文章I-DAE(24.01,https://arxiv.org/pdf/2401.14404.pdf)认真剖析解构了扩散模型,发现去噪过程远比扩散过程更加重要,拆解之后发现扩散模型的本质依然是经典DAE(2008年),即噪声调度策略(如线性或余弦或Sigmoid)本身并不重要,扩散模型越来越复杂结果没什么卵用啊。
4)数学本质分析。从数学原理有人也分析过,扩散模型是数据流形和隐空间拓扑映射(微分同胚),但是只反应概率相关性、无因果关系,比如造成稳恒态和临界态混淆——Sora的“幻觉”问题(如物体穿透、违反物理规律、六根手指头)即来源于此。我早之前就从数学上系统学习过从VAE-扩散-流匹配的知识,从数学上理解是很直观的。下图是扩散模型和流匹配的预测目标和MSE损失函数。【P.S.我喜欢从数学上去理解原理,这是个学了又忘、忘了又学的过程】

这里我觉得还可以加上何恺明团队的MeanFlow的损失函数,建模平均速度,可以一步生成(见下图):

综上,我不看好Sora的DiT路线,[早说过不要尬吹Sora,DiT技术也是原因之一]。大公司是两头押注的,LLM路线和扩散路线都有产品,比如谷歌曾有VideoPoet(23.12,自回归),也有W.A.L.T(23.12,扩散transformer),现在大一统的Gemini是自回归(实为混合);OpenAI除了后面的Sora(24.02,diffusion),之前DALL·E(21.01)也是自回归、更早有基于GPT2的iGPT(20.06,自回归),现在也算是公开放弃Sora路线了。目前来看,这些大厂都在聚焦自回归(或者自回归+扩散混合)路线了。
一些离散扩散研究:需观察
上述的DDPM、Stable Diffusion、Sora都是连续扩散模型,也有一些有意义的离散扩散研究。
比如完全离散的的文本图像双向掩码扩散生成,Muddit(25.05)与MMaDA(25.05),追求并行效率。
【题外话,在语言模型领域,也有很多掩码扩散的研究成果(如LLaDA),在受限数据场景下甚至性能更优,因为随机掩码具备数据增强的作用。最新LLaDA2.0-flash已经达到100B了。】
其实我觉得这类早期的掩码离散扩散确实没啥意思,左右都比不上。离散扩散的视觉质量比连续扩散要差;另外掩码的优势就是比“下一token生成”快很多嘛,但既然都离散了,应该彻底拥抱自回归框架才是,cache推理的效率和scale的能力都要强很多。
连续扩散模型:线性注意力
比如SANA-Video(25.09)是典型代表,线性扩散transformer模型(Linear DiT),可以兼顾生成速度和生成质量。
早期的Minimax在线性注意力方面也是典型企业,但公开信息好像没有桥接到扩散模型。海螺产品采取的是典型的DiT架构。为了提升模型表达能力,MiniMax M2(25.10)转变采用了全注意力机制(Full Attention),当然这是另一个话题了。
扩散模型应用到世界动作模型(WAM):从内容生成到世界模拟与决策
扩散模型,利用大规模视频数据(如网络视频、机器人操作视频等)训练扩散模型,学习视频的时空动态特征,显著优于VLAs。如DreamZero(26.02)基于WAN 2.1扩散模型,通过流匹配Flow Matching目标,联合预测未来视频帧和机器人动作,使模型学习到物理世界的先验知识。(重要成果,以后“世界模型”篇再讲)
四、自回归生成(离散、连续)
上述基于扩散的模型,由于缺乏键值缓存支持、扩展性差,还是适合生成重建任务,现在的统一多模态大都基于自回归统一模型(无论离散token还是连续latent)。
下面分几类典型的:
因果注意力自回归生成:离散token+因果AR
这就是GPT系列。但是由于多模态是连续的,所以不能直接套用GPT范式,一开始都是先将多模态信息(像素)进行离散化处理,用以结合transformer架构。
VQ家族/离散Codebook自回归生成:VQ量化+因果AR
为了适应transformer模型,需对连续图像进行离散化,同时压缩长序列。因此很容易想到的就是先AE压缩、然后在离散生成。这里面离散化过程(即VQ化,比如VQ-VAE、VQ-GAN)需要学习码本codebook。
我认为可以分为大码本和小码本。大码本的优势是重建保真度高,但是开销大速度慢;小码本反之。
1)MAGVIT-v2(23.10)就属于超大码本,达到2^18。增加词汇表大小同时减少编码嵌入维度,它直接把维度降低为 0,并假设码本维度独立、且 latent 变量为二进制,那么潜在空间就被分解为单维变量的笛卡尔积(相当于映射到一个超球体空间)。输出为二进制token索引。MAGVIT-v2最大优势是lookup-free Quantization,到索引、0维度不需要查表,避免了码本坍缩的问题。
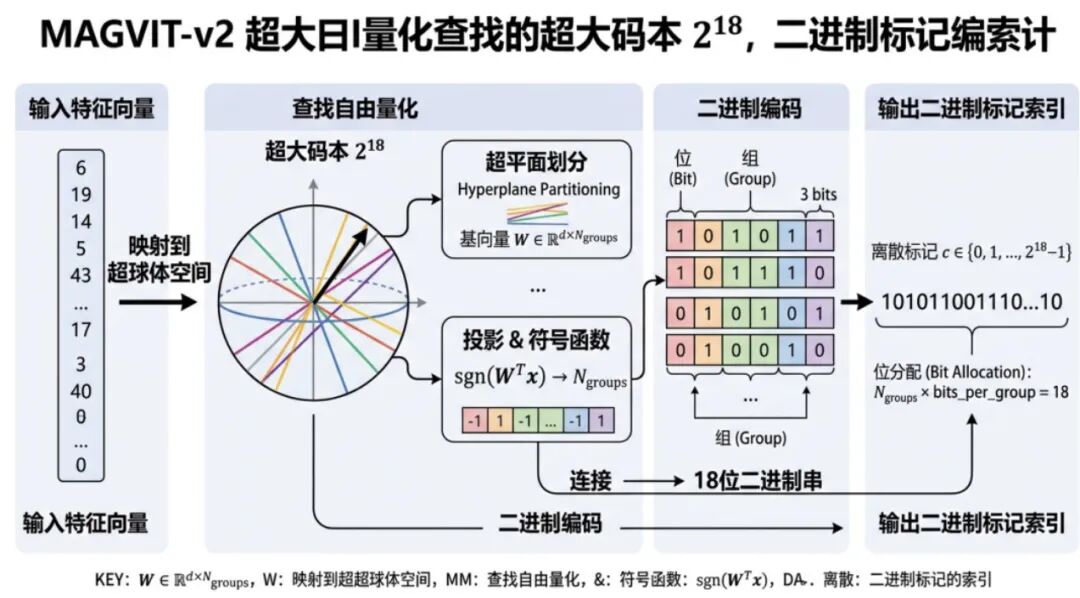
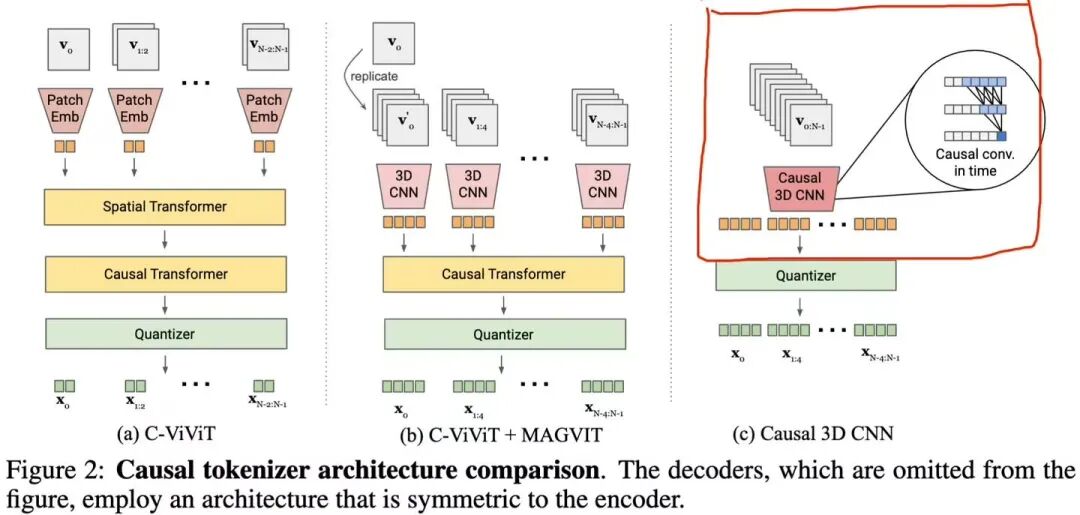
Google的VideoPoet(23.12),就用到了MAGVIT-v2,使用3D因果卷积(casual 3D CNN)实现图片和视频的视觉编码,MAGVIT-v2 的LFQ会将其转化为离散token。然后自回归预测token序列。最后经过MAGVIT-v2解码器转回连续的图片或视频。所以,这是一个完全跟扩散模型无关的自回归模型。
李飞飞团队W.A.L.T也借鉴了基于MAGVIT-v2的因果3D CNN编码器,不过没有VQ操作,而是编码为连续latent(后面还会提到)。
2)另一个超大码本的代表就是字节的Infinity(24.12),字节也同样采用了采用了LFQ这种量化方式,与MAGVIT-v2类似的二进制编码,达到2^32大小。
【题外话:字节InfinityStar(25.11)还用了Wan 2.1 VAE(25.05,这是阿里通义的扩散模型编码器)作为编码器,编码器+量化器(及正则化),再加上在主干transformer的稀疏注意力改进,使得字节的生成模型的质量和速度都大幅提升,5秒720P视频仅需58秒,并在26年让字节的多模态大模型SEES2.0大放异彩。】
3)字节提出的TiTok(24.06)就是极致压缩的小码本,将图像表示为仅需32个离散token,这是很高的压缩比。论文里说这些压缩竟然提高了生成质量,[doge]俺也不晓得。
VQ是发展比较早的压缩技术,但是是有损压缩的,当然可以技术改善。第一,VQ 自编码器训练难度比较大,codebook只有一部分参与计算,就像字节的量化器为了提升利用率有做熵正则化处理;第二,在利用decoder进行重构的时候,离散token的重构效果不是特别好,这可以通过层次化残差量化RQV改善(后面还会提到该技术)。
掩码双向注意力自回归生成:离散/连续token+双向AR
比如典型的MaskGIT(22.04),用VQ-GAN学习tokenizer,然后双向掩码注意力自回归,损失函数为负对数似然。优势可以并行decoding,不足是这类方法更关注图片邻近空间,长距离依赖的语义一致性较差。由于MaskGIT在解码时采用余弦掩码调度、而非Bert一样的固定掩码率,所以准确来讲我觉得应该算是离散扩散模型。——算是比较特殊的情况
典型成果还有何恺明的MAR(24.06)模型,直接省去了VQ(VQ需要STE梯度估计),将输入视为连续分布,用以结合掩码双向注意力自回归建模,其核心创新是用BERT式双向注意力替代传统GPT式的因果单向注意力,支持随机顺序的并行解码生成。MAR引入扩散机制,但主体仍是自回归框架,这是可改用扩散损失MSE来取代交叉熵损失。
既然可对应两种不同损失,那我们就可以进行比较。何恺明推出的Fluid(24.10)就是这样的实验。连续token or离散token、random-order(即随机掩码自回归,可以生成多token)生成 or raster-order(即逐一自回归)生成,两两组合,一共四种情况。参数扩展并评估性能,实验发现连续 token 的 Random-Order 模型表现最佳,这可以看成是何恺明MAR的文生图版本。
MAR和Fluid,都是开创性的成果,在业界影响大,“连续token + 掩码自回归”的架构这也对我们下面的连续token的混合架构提供了实质意义上的参考。
MAR比逐一自回归生成肯定快了,但是相对扩散模型还是慢的。何恺明团队后来推出了分形生成模型Fractal Generative Models(25.02),引入了递归策略,将高分辨率图像分解为多个小块进行逐像素建模,显著降低了计算成本(效率提升4000倍)。原理比较简单,读者自行去查看。
业界还有类似的方案,ARINAR(25.03)双层自回归逐特征生成,区别在于前者是像素空间,后者应用到潜在特征空间,都是利用多层递归提升效率。
混合架构:用以处理连续latent,用“非自回归+扩散”连续建模生成
很明显连续latent的好处是没有离散化处理、没有牺牲连续性,利用扩散/流匹配生成的质量高、效果好。混合架构里面比较复杂,先讲非自回归的(包括编码器和主干都没有自回归),比如:
比如利用CNN架构,比如李飞飞团队的W.A.L.T(23.12),W.A.L.T是一种基于因果3D CNN编码器和窗口注意力的扩散模型,它在共享的潜在空间中训练图像和视频生成。W.A.L.T借鉴了MAGVIT-v2的因果3D CNN编码器(与MAGVIT-v2不同的是,无VQ,编码为连续latent,图中我红色标出来的部分),latent送入DiT,并在窗口注意力内双向并行去噪生成。虽然用到DiT得transformer,但是窗口注意力,所以不算典型的自回归。
混合架构:用以处理连续latent,用“自回归+扩散”连续建模生成
对于“自回归+扩散连续”的混合架构而言,自回归预测在什么level上、以及该level的采样效率,以及总体架构的生成质量,需要模型开发者自己去平衡设计。我找了几个典型的:
1)自回归是token层面的,
-
自回归预测每个token的向量,再用扩散建模向量分布,每个token内部用扩散模型连续采样。比如前述的Masked AR(何恺明,24.06)、Fluid(何恺明,24.10)。
-
上述的MaskGIT(22.04)+连续diffusion生成可以认为也是这类(因为是在token层面,且结合双向的attention掩码自回归,所以我前面单独拎了出来)。
-
还有智源Emu3.5(25.10)在token层面的DiDA离散扩散自适应机制,它将扩散模型的并行去噪思想引入到了离散token空间,并且巧妙地适配到自回归架构上,速度可以大幅提升。噪声token以因果自回归关注之前的干净图像token,同时噪声token之前双向关注并行去噪,去噪过程多步扩散迭代(20倍图像生成加速)。
2)自回归是在scale层面的,
- 通过预测scale条件,即引入Next-Scale Prediction(NSP)进行视觉图像生成,然后在sacle层面用扩散(flow)连续生成。sacle层面一次预测一批,就比逐token预测快多了,不是么。
- 比如VAR(24.05),这篇是字节的成果,也是字节后面的Infinity、InfinityStar模型的理论基础。多尺度VQ-VAE(11*11到256*256的5个尺度),用下一scale预测替代下一token预测,InfinityStar每步可以并行预测数千个token。再比如FlowAR(24.12)。
3)自回归是在block 层面的,
- 还有一个类似的成果Block Diffusion(25.03), 这个块是“token块”(每块16个token),它缝合为块之间AR自回归,block 内部使用 discrete并行去噪建模条件分布。也是相似的混合架构思路。
4)自回归是在图像(patch)层面的,
-
阶跃星辰也出过一个NextStep-1(25.08),它的image tokenizer是基于Flux VAE微调的CNN架构,直接在连续的视觉潜在空间中(16通道float值),以自回归transformer方式逐一预测图像patches。patch内会搭配一个流匹配头作为轻量级采样器,以流匹配生成(损失函数用到速度场MSE)。
-
还有个学术成果我不得不提,就是何恺明团队的JiT(25.11),自回归预测在像素的不同patch层面,意味着就是像素预测(跟古早的DDPM一样,不需要到编码至潜空间),用大的patch处理高维像素。这种“原始”好处是很多的:不需要VAE、不需要latent tokenizer、不需要自监督的特征对齐、不需要预训练,用ViT+adaLN-zero条件注入。
回顾前面扩散模型数学本质的图,像素x、噪声ε、速度场v三种不同的扩散损失函数相互可以公式跳转(熟悉扩散到流匹配原理的会更理解这点)。x、ε、v三个预测空间可以分别对应x、ε、v三种损失空间,共9种情形。JiT对9种都做了实验,实验证明预测x的FID最低,而且自回归直接预测x对后面的x、ε、v损失都是有效的,预测ε、v对于后面的损失则崩溃。并且证明了“预测x + v损失”就是最优选择。这也太神奇了,如果在技术上跑通那太好了!但是技术落地有待探究哈,比如如何效率上自回归预测像素patch这类高维信息。
还记得前面何恺明团队的MeanFlow吗?建模平均速度、可以一步生成的单步采样。这与JiT可以相结合,pMF(26.01)就是这样的探讨——单步、无潜空间生成,FID=2.22,验证了可行性。
5)自回归是在帧级(frame)层面的,
- 自回归预测每帧,然后每帧内的token双向掩码连续扩散生成。比如VideoMAR(25.06)。
(上面这些是我归纳总结[累死doge]的,当然肯定不止这些,,,读者还可以继续列举下去)
但正如上面讲的,无非就是在什么level预测token、在质量和效率之间如何平衡取舍,想必读者也明白了,就是用什么样的tokenizer压缩的嘛、backbone怎么有效率的预测和生成、以及如何维持视觉的保真度。其实生成模型就是这么点东西,也不复杂。
对自回归路线的评价
在生成模型中,把自回归路线与扩散模型进行比较,这个在业界已经吵了好几年了。目前来看,“自回归+扩散”的混合结构是要总体占优的。比如用A100生成5秒720视频,扩散模型Wan 2.1需要用时30分钟,而字节InfinityStar仅用时58秒(只比上文的清华&生数的TurboDiffusion慢一点)。
但这些先进模型本身呢,其实也都是混合模型,大部分都需要加上扩散步骤作为生成组件。所以不需要再分为自回归路线与扩散路线,意义也不大了。所以多模态一直还在演变,也意味着还有投资机会。前面我分别讲到了理解模型、讲到了生成模型,下面我们希望实现真正的“统一理解与生成”,看能否抓住各自的优势。
五、统一理解与生成,很难
在2024年的一大努力工作是统一理解与生成,但貌似并不如人意。貌似理解任务是简单一点的,比如从一张猫的图片中识别出猫;生成模型则复杂,比如从简单的噪声分布映射到复杂多变的真实数据分布。统一理解与生成的目的是从两类截然不同的任务,实现1+1>2的统一。
类似GPT-4o的“统一理解与生成”并不完美,且归因于LLM推理能力
大厂一直都在努力。比如GPT-4o(2024.05),实时视觉语音技术直接引爆了行业。GPT-4o第二天,Google就发布了Gemini Project Astra和Gemini 1.5 Flash,Google数月前还有原生多模态Gemini 1系列。在此前后,开源模型也出现类似的成果:比如Meta Chameleon(2024.06)紧随其后,但貌似大家的认可度很低哦(甚至没有融合音频);Qwen2-VL(2024.08)也表现出较强的视觉理解能力;DeepSeek的Janus(24.10)的理解与生成解耦的双路径的编码器也算是成果之一。
这个阶段,普通C端玩家都明显感觉到多模态理解能力的提升,相比23年H2的GPT-4V和Gemini而言,效果提升了很多,GPT-4o已经出圈了;“统一”二字体现的是扩展能力的提升,GPT-4o用“o”替代“V”也是这个含义。
这些闭源成果,我的个人感觉是LLM推理在其中的作用很大,侧重“理解”,但貌似也仅限于此!因为从demo来看,依然在“文本引导下的图片识别与理解”,只是表现出来模态交互效果。我个人认为这波多模态模型的能力90%归功于LLM推理模型,而本身的架构范式级创新很有限——虽然GPT-4o在行业内,第一次集成了众多模态(文本、视觉、音频)。之前有团队“反向破解”,基本识别为“扩散风格”。后面我会提到“统一理解与生成”应有的落地效果。
【歪题提一下GPT-4o音频的处理,因为闭源,技术不知道。可以参考开源的Moshi,它对音频的处理通过4个步幅为(4/5/6/8)的卷积块和步幅为2的1D卷积将音频投影到latent,8级残差矢量量化RVQ离散化——第一级将WavLM高级语义信息蒸馏进离散化token中,后面7级量化声音细节。另外美团的龙猫LongCat-Next对音频的离散化也是采取了残差矢量量化RVQ离散化方案。另外有某国内音频AI新创团队也是用到了RVQ。RVQ有助于缓解VQ离散化的信息损失,算是业界共识吧。】
统一理解与生成,重新从表征出发
统一理解与生成的多模态模型研究历来已久,成果较多了。早期强行的多模态对齐或融合是很简单的,比如早期的NExT-GPT(23.09)用ImageBind(23.05)统一多模态编码器、生成用不同的图像/声音/视频扩散模型,编码-LLM和LLM-解码之间仅用投影层(projection layers),支持any2any,但自然效果就很差啦。早期成果还有Uni-Perceiver(21.12)、OFA(One For All,22.03),不逐一而论。
统一理解与生成的多模态有很多分类,比如如上的基于扩散(如上“三、DiT范式与扩散模型”部分所述)、自回归transformer(如上“四、自回归生成(离散、连续)”所述)、还是还是自回归和扩散两者融合的(如上第四节中的“混合架构”所述)。
但是上面那些还是从“生成”的角度出发,这次我的分类要换个思路,我侧重embedding端的不同。我觉得表征学习才是重点!如何将特征融合是建模这个世界的本真问题,如何表征比主干网络(LLMs/MAR/DiT/JEPA等)更加重要。
从表示学习来看多模态。【这里表征与表示视为同义词、不做区分。表示学习是指自动从数据(如图像、文本等)中提取特征或表示的方法,转化为向量;表征学习更强调对特征空间的构造,关注结构性信息,并支持下游任务】。因果自回归(LLMs范式)、掩码自回归(如MAR)、DiT扩散模型、Yann LeCun的JEPA等都是模型主干,可以看成是在表示学习之后。那么对应到多模态的视觉token,比如像素空间,latent空间,三维渲染的网格、体素,自驾中的BEV,都是表示/表征学习。这些表征可以通过自监督学习(Clip、Blip、Dino等)、或自监督预训练获得,可以作为表征学习的一大类方法,服务于下游理解与生成任务。
在现在以transformer自回归为主干的当下,是侧重VAE或VQ-VAE处理图像,还是侧重语义编码器(自监督学习),还有图像是离散还是连续处理。
第一,在潜空间融合的,VAE或VQ-VAE、或连续latent空间。又可以分几个方向:
1)下游是扩散损失的,即扩散模型。这个方向依然还是以DiT框架为最佳实践,其他的新成果也有很多进步,但也没那么重要,可以关注与之相关的效率提升方面技术,比如稀疏化、高效采样、流匹配、多token生成等。
2)下游是自回归+扩散,上述token/scale/patch/frame之类的,同时又在潜空间融合的(部分并不在潜空间,比如何恺明团队的JiT,是像素空间)。
3)下游是自回归与扩散双向,两个损失都有的。比如Transfusion(2024.08)。
Transfusion在 50% 文本和 50% 图像数据上预训练 Transformer 模型。最终序列的样子是:包含了离散元素 (表示文本 token 的整数) 和连续元素 (表示图像 patch 的向量),序列都进入transformer,预测序列中token并扩散图像。注意力上,将causal attention应用于序列中的每个元素、以及每个单独图像元素之间bi-directional attention,结合这两种注意力模式。所以每个图像元素可以关注同一图像patch中的其他元素,但只能关注序列中先前出现的文本或其他图像patch。在训练的每一步,Transfusion都使用两种模态的LM损失和Diffusion损失,通过λ平衡相加就行。
Transfusion是将两模态比较粗暴的“拼接”在一起的,对于实验性项目比较友好。Transfusion编码器用的CNN 编码器和解码器,也可以换为VQ-VAE,添加量化层,并且将KL损失替换为码本损失。腾讯UniCom就是在Transfusion之上的应用,完全抛弃了VAE编码器。
第二,潜空间和视觉编码器都有的,解耦架构
比如之前提到的DeepSeek的Janus,根据理解和生成任务的不同将视觉编码内部解耦了。
第三,自监督预训练的文本对齐视觉编码器。这是重点方向,咱们又回到了“统一理解与生成”的理解端,并且已经出现了RAE这样优秀的学术成果。
由于VAE相关技术的语义理解能力跟不上,用自监督学习的encoder去取代VAE是相对比较自然的想法,老的自监督学习的encoder有的CLIP、FLIP、MAE等,新的有用SigLip系列、Dino系列等等。很多都是“语义编码器+MLLM+扩散解码器”的结构,非常典型的成果有Emu系列(语义编码器EVA-CLIP)、BEiT、BEVT。这里面的编码器能力不一,自回归损失和扩散损失组合监督。
据说GPT-4o大概率就是使用的这种方法,用到了SigLip,表现出语义识别与理解的能力。迄今为止,GPT-4o仍然是很厉害的前沿多模态生成模型,GPT5出来后试图拿掉GPT-4o,结果被“粉丝”讨伐,引发一波闹剧。
再比如RAE(25.10),我之前就挺关注的,就是因为谢赛宁。RAE使用预训练冻结Encoder (比如 DINOv2),加上可训练Decoder。用这样得到的Encoder + Decoder组合替代了VAE,配合Diffusion Model完成图像生成任务。
但是替代了VAE,那么高维度空间怎么训练呢?谢赛宁做了三点改进:宽扩散头、噪声调度平移、噪声增强解码,但206年的新论文中(《Scaling Text-to-Image Diffusion Transformers with Representation Autoencoders》(26.01))又承认是随着规模扩展,“宽扩散头”和“噪声增强解码”成了冗余设计。
去掉冗余设计后,论文中RAE的效果明显改善,在从 5 亿到近百亿参数的多个尺度上,RAE 不仅在预训练阶段全面优于当前最强的 VAE 方案,还在高质量数据微调时展现出惊人的稳定性,而 VAE 模型却在短短 64 个 epoch 后出现灾难性过拟合。第一次在“理解侧”的自监督模型应用到生成模型,并超过了原来的VAE生成范式!目前看来类似RAE这样的成果,落地也还是有希望的。
回到基础技术上。之前表征编码器应用到生成任务有什么技术困难吗?之前有些用生成模型的文生图任务来测试,发现直接使用表征编码器的效果并不佳。表征编码器是从高维空间到“理解语义”内在信息的低维度,有极大冗余,传统思路认为扩散模型(解码器)无法有效探索高维空间,易造成生成结构错误和伪影(产生流形外的样本)、或者重建中错误丢弃信息(比如对生成重要、但对理解不重要的几何纹理)。
有些简单的工程方法可以改善,分别对“语义保持”和“视觉重建”提升性能。比如:
- 语义上比如用语义蒸馏的方法。
- 纹理色彩之类的通过通道拼接残差分支。
- 再比如引入细化模型,类似SDXL中的refiner model,在解码至像素空间之前添加细节,实现更好的视觉重建。
- 也有一种比较前沿的语义保持的技术方向,比如利用归一化流NFs理论构建语义和像素的可逆神经网络,比如何恺明团队的双向归一化流BiFlow(25.12),这个细分方向可以关注,但主要是采样速度方面,而非语义-像素问题。
- 还有Uniflow(25.10),层级自适应语义蒸馏、分块像素流解码器,通过流匹配直接将高层语义转为像素空间、无需预训练VAE。
但这些工程方法都指标不治本,需要更“本真”的方法。
RAE怎么解决的呢?谢赛宁的论文显示这个“扩散模型(解码器)无法有效探索高维空间”的传统看法是错的,只是因为数据不够丰富、规模不够大而已。目前来看之前的维度感知噪声调度依然是重要的,另外关键还是数据质量与规模。这也是bitter lesson的体现,我觉得未来视频、物理simulator也会类似scaling up。
“统一理解与生成”应有的落地效果
RAE取消了VAE传统生成路径,我觉得这第一次有了统一理解与生成模型成功的先兆。统一理解与生成模型在落地效果上,将会是:
1)理解多模态指令与意图并即时生成,并有编辑、改动、操纵等改变生成效果的能力(后文会看到),这远非GPT-4o所能比较的。
2)模型前后架构进一步改进。比如前端更好的自监督表征和tokenizer,后端更好的并行预测、快速解码,更健壮的主干模型。
3)如果模型处理多模态的上下文能力进一步提升、下游任务的推理速度也提上来,就能支持与用户交互的速度,就有了跨模态交互的能力(这正是GPT5当时落空的地方)。
4)融入更多能力,比如考虑时空分布和动态信息,还得融合其他技术方法,比如内置的微分物理引擎、显式/隐式的3D结构表征。比如MIT的新成果PhysiOpt,首次实现了在不破坏生成模型原生表示的情况下,直接在潜空间中进行可微分物理优化。
5)那么这类多模态能力落地后,Twelve Labs这样视频搜索与生成的初创公司将失去价值。
这也算得上是新的技术范式。RAE模型目前看对数据和规模比较考究,落地效果和实际任务中,后续还需要再观察。毕竟从论文到生产环境是有一段路要走的,而且业界也可能出现替代的技术方案。考虑到谢赛宁加入了杨立昆的新公司AMI,长远来看,他们也许真能跑通从多模态到世界模型;从自监督视觉(如同更早的DINO-WM(24.11)、DINO-world(25.07))到世界模型,当然只是迈向世界模型的其中一条技术路线而已。
六、前沿模型已经开始体现“统一理解与生成”的前瞻能力
步入2026年,上述我们期待的“统一多模态理解与生成”在前沿模型中开始展现出来。我看到有几个好的迹象:A. RAE表明自监督学习框架也许可以落地,高维视觉表示在生成任务上并不比VAE差;B. 随着Agent的发展,模态从交互到操控变得可控、可落地;C. 统一多模态可以预训练,并且可以扩展到世界模型。
前沿闭源模型成果
GPT-4o什么时候被谁超越呢?谷歌的系列产品开始大幅发力,Gemini2.5 Pro(25.03)、Gemini2 .0 Flash Exp(25.03)、Veo3(25.05)、Nano Banana(25.08,官方为gemini-2.5-flash-image-preview)、Genie3(25.08)。
Gemini2.0 Flash Exp实现了“用嘴改图”的能力;
****Nano Banana实现了更强的“物体替换”,可编辑能力进一步提升;
Veo3更强,用grounded帧链数据集(视频、问答、关键帧引用与理由)进行训练,感知->建模->操纵->推理,实现音视频环境同步,不仅可编辑、还有物体操纵(如开罐子)和帧链(CoF)推理的涌现能力,视频模型第一次具备了进入生产流程的能力(之前Sora并没有),官方强调了提示工程的重要性。从******Veo3开始,已经有些世界模型的感觉了,我们可以从《Video models are zero-shot learners and reasoners》窥见这一点。**
Genie3明确为世界模型,突出交互性、可操控性,它使用时空tokenizer、自回归动力学模型、潜在动作模型,可以实现约1分钟视觉记忆和数分钟连续交互。
说起“交互”,随后两月还有李飞飞的成果RTFM(25.10)、Marble(25.11)。
以谷歌系列为例的上述模型,比较GPT-4o和同期的Gemini的提升在于,已经不限于“理解”了。已经有了统一多模态理解与生成、甚至世界模型的感觉了。(世界模型我暂不说明,以后再说它们的模型架构,比如状态模型之类的)
智能体与视觉推理
Runway推出的GWM-1(25.12),定位为它首款通用世界模型,能够理解物理规律、几何结构及环境动态的模拟系统,用户可以实时改变镜头视角、环境条件或物体状态,其核心突破在于“连贯性”与“交互性”。
****Google ****DeepMind在Gemini 3 Flash基础上提出了一项技术叫“Agentic Vision”(26.01),引入了“Think-Act-Observe”的循环:Think制定多步计划,Act生成代码分析图像(如计数/计算)或操纵图像(如裁剪/旋转/标注),Observe将变化后的图像追加上下文记忆。
Google DeepMind的SIMA2(26.01)在Genie3中表现出类似的能力,可以响应用户指令采取行动、实时生成新的事物,并且表现出前所未有的适应能力。
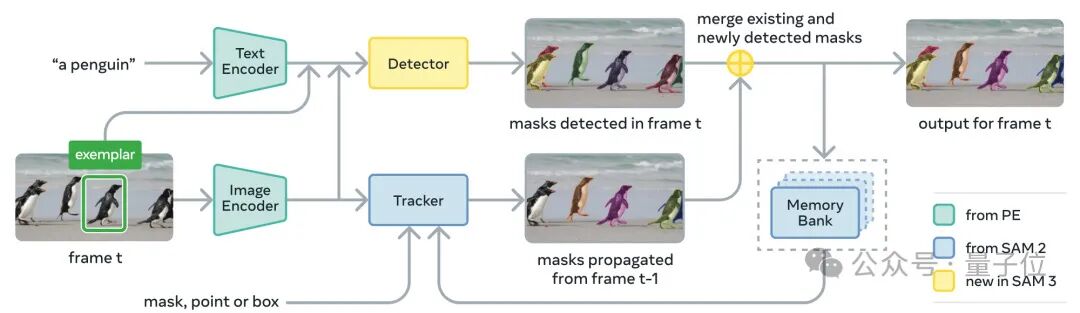
虽然闭源,我们不知道内部的架构和原理。但我们可以从同期的分割模型SAM3(2025.11)中看出一点也许类似的技术。SAM3采用双编码器架构,编码器和解码器之间,还有负责文本和图像的检测器、视频跟踪器,含提示下的检测器发现新目标(第t帧)会融合跟踪器的上一帧信息(t-1),存进记忆模块。这可以瞥见编辑能力的技术展示。
基准与评估
这些视频模型是不是很优秀?那在我们希望的世界模型、空间推理能力如何呢?
谢赛宁在Cambrian-S(25.11)论文中,来对surprise[惊讶度]进行评估,建立了一个关于Visual-Spatial Intelligence的基准VSI-Super:包括:VSI-Super Recall长时程空间观察与回忆,比如通过编辑模型插入视频帧内令人惊讶的物体(比如一只泰迪熊);VSI-Super Count变化视角和场景下的累计计数(一段视频中给不同场景的椅子数数)。G**emini-2.5-flash在这些基准测试中表现就一般般了。**
我们希望的多模态模型是类似人的认知能力的提升,比如如何预测“惊讶”信息、如何驱动注意力、如何记忆编码,等等。我们不希望得到的是一个侧重LLM能力的MLLM,我们希望得到的是一个世界模型。****Cambrian-S的方案是训练了一个潜变量帧预测头LFP来评估“惊讶度”,这是一个自监督模块(读者自己去研究吧)。
强化学习也可以用于构建类似的数据集进行评估,比如智源的Reason-RFT(25.3),用于评估类似物体计数、空间关系判断、操作序列规划等场景任务。
还有比如Physion-Eval(26.03),评测视频生成看起来视觉真实的物理真实程度。
从多模态到世界模型
那么在好的表征能力之下,多模态生成模型未来一定会支持用户编辑&指令遵循、实时交互类动作反馈、并体现因果关系和规则的能力。当然还有很多挑战需要解决:比如相机位姿第一视角的动作可以生成,但是真实世界却有很多非第一视角的动作。这后面大概率还会涉及到智能体行动、强化学习以及reward设计等许多其他技术。等这些能力一一满足了,也就从多模态到了世界模型的范畴了。
最后
对于正在迷茫择业、想转行提升,或是刚入门的程序员、编程小白来说,有一个问题几乎人人都在问:未来10年,什么领域的职业发展潜力最大?
答案只有一个:人工智能(尤其是大模型方向)
当下,人工智能行业正处于爆发式增长期,其中大模型相关岗位更是供不应求,薪资待遇直接拉满——字节跳动作为AI领域的头部玩家,给硕士毕业的优质AI人才(含大模型相关方向)开出的月基础工资高达5万—6万元;即便是非“人才计划”的普通应聘者,月基础工资也能稳定在4万元左右。
再看阿里、腾讯两大互联网大厂,非“人才计划”的AI相关岗位应聘者,月基础工资也约有3万元,远超其他行业同资历岗位的薪资水平,对于程序员、小白来说,无疑是绝佳的转型和提升赛道。
如果你还不知道从何开始,我自己整理一套全网最全最细的大模型零基础教程,我也是一路自学走过来的,很清楚小白前期学习的痛楚,你要是没有方向还没有好的资源,根本学不到东西!
下面是我整理的大模型学习资源,希望能帮到你。
👇👇扫码免费领取全部内容👇👇

最后
1、大模型学习路线
2、从0到进阶大模型学习视频教程
从入门到进阶这里都有,跟着老师学习事半功倍。
3、 入门必看大模型学习书籍&文档.pdf(书面上的技术书籍确实太多了,这些是我精选出来的,还有很多不在图里)

4、 AI大模型最新行业报告
2026最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。
5、面试试题/经验
【大厂 AI 岗位面经分享(107 道)】

【AI 大模型面试真题(102 道)】

【LLMs 面试真题(97 道)】

6、大模型项目实战&配套源码
适用人群

四阶段学习规划(共90天,可落地执行)
第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
-
硬件选型
-
带你了解全球大模型
-
使用国产大模型服务
-
搭建 OpenAI 代理
-
热身:基于阿里云 PAI 部署 Stable Diffusion
-
在本地计算机运行大模型
-
大模型的私有化部署
-
基于 vLLM 部署大模型
-
案例:如何优雅地在阿里云私有部署开源大模型
-
部署一套开源 LLM 项目
-
内容安全
-
互联网信息服务算法备案
-
…
👇👇扫码免费领取全部内容👇👇

3、这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 2
2 0
0- 0



 已为社区贡献798条内容
已为社区贡献798条内容

所有评论(0)