[Python3高阶编程] - Waitress 源码剖析05: HTTP 请求解析器 - parser.py
parser.py通过增量式解析严格的安全验证模块化的协作组件和完整的WSGI兼容性,在纯 Python 环境中实现了一个健壮且高效的 HTTP 请求解析器。它的设计充分体现了 Waitress “生产级、纯Python、跨平台” 的核心哲学,是连接底层 I/O 与上层业务逻辑之间不可或缺的一环。理解parser.py,有助于掌握 HTTP 协议解析的核心原理、WSGI 规范的具体实现,以及 Wa
作者:andylin02
关键词:HTTP Request Parser、WSGI、Waitress、状态机、HTTP/1.0/1.1、Chunked Transfer-Encoding
一、模块总览:网络字节流到 WSGI 环境的“翻译官”
waitress/parser.py 是 Waitress 架构中连接“原始网络 I/O”与“业务逻辑”的关键枢纽。
它的核心职责是将从客户端接收到的、无结构的 TCP 数据流,解析成一个结构化的 HTTP 请求对象,为后续 task.py 执行 WSGI 应用提供标准化的输入数据(即 WSGI 的 environ 字典)。
正如其文档所述:“A structure that collects the HTTP request. Once the stream is completed, the instance is passed to a server task constructor.”——它是一个请求数据的“收集器”,一旦数据收集完成,就会被传递给 server.py 中的任务构造器。
为什么需要它?
在混合架构中,channel.py负责接收原始 TCP 字节流,但 WSGI 应用需要一个包含请求方法、路径、头部和正文等信息的 Python 字典。parser.py就是完成这个“字节流 → 结构化数据”转换的模块,它确保了异步 I/O 层与同步业务层之间的数据格式解耦。
二、核心功能:增量式请求解析
HTTPRequestParser 类是这个模块的“灵魂”。Waitress 采用的是增量式(增量式)解析,而非等所有数据到齐后再处理。
它的解析流程可概括为以下几个步骤:
-
接收数据:
channel.py通过parser.received(data)不断将 TCP 数据块投喂给解析器。 -
解析首行与头部:解析器内部维护一个缓冲区,持续查找
\r\n\r\n标记以确定头部结束位置。 -
解析请求体:头部解析完成后,根据
Transfer-Encoding或Content-Length头部,创建对应的“接收器”。 -
标记完成:当接收器报告请求体接收完毕,
parser.completed标志位被设为True,一个完整的 HTTP 请求就此诞生。
增量式解析 vs. 等待式解析
| 对比维度 | Waitress(增量式解析) | 传统阻塞式解析 |
|---|---|---|
| 内存占用 | 边读边处理,缓冲区可控 | 必须等待完整请求到达,内存占用大 |
| 大文件处理 | 支持流式接收,不会阻塞 | 必须全部加载后处理 |
| 响应延迟 | 头部解析完成即可开始处理 | 必须等所有数据到达 |
| 实现复杂度 | 较高,需维护解析状态 | 较低,逻辑更简单 |
对于大文件上传场景,Waitress 可以一边接收数据一边将超出内存阈值的数据溢出到磁盘,而不是耗尽服务器内存,这正是增量式解析的优势所在。
三、架构设计:模块化的解析流水线
parser.py 的设计遵循单一职责原则,将复杂的 HTTP 解析任务拆解为多个专注且可插拔的协作组件。
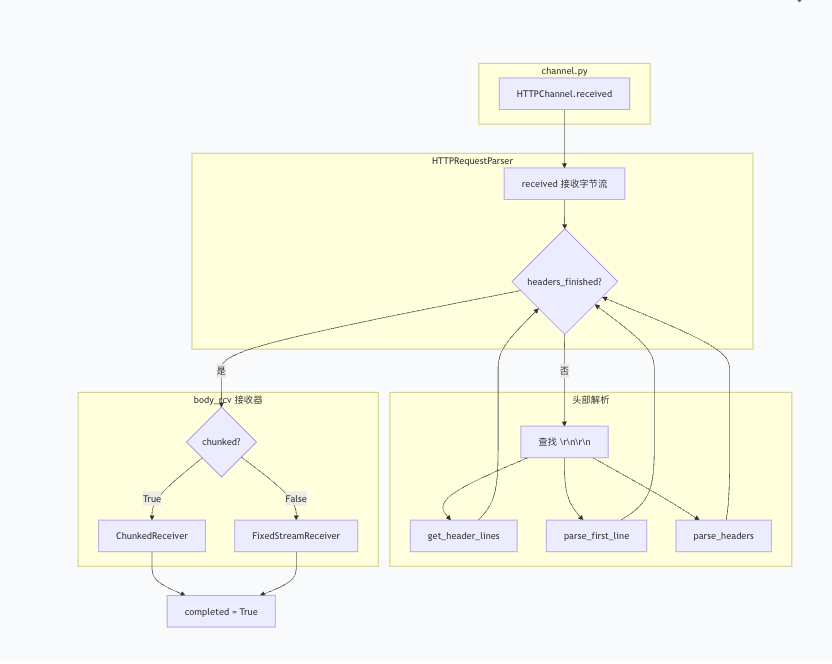
组件分解
| 组件 | 职责 | 关键方法 |
|---|---|---|
HTTPRequestParser |
主控制器,协调各组件完成请求解析 | received() |
crack_first_line() |
用正则表达式解析请求行(方法、URI、版本) | first_line_re 正则匹配 |
get_header_lines() |
处理多行 HTTP 头部,合并折叠行 | 按 \r\n 分割并合并续行 |
split_uri() |
将原始 URI 字符串拆解为路径、查询参数等 | 处理 // 前缀等边界情况 |
ChunkedReceiver |
处理 Transfer-Encoding: chunked 的请求体 |
逐块解析 chunked 数据 |
FixedStreamReceiver |
处理固定长度的请求体(基于 Content-Length) |
按指定字节数接收 |
OverflowableBuffer |
内存缓冲与磁盘溢出的抽象 | 小数据存内存,大数据落磁盘 |
状态标志位的设计智慧
HTTPRequestParser 类维护了几个关键的状态标志,形成了一套隐式的状态机:
| 标志位 | 含义 | 转换时机 |
|---|---|---|
completed |
整个 HTTP 请求(含请求体)已完整接收 | body_rcv 报告接收完成 |
headers_finished |
HTTP 头部已解析完成 | 在头部缓冲区中找到 \r\n\r\n |
empty |
没有接收到任何请求数据 | 连接建立但客户端未发送数据 |
expect_continue |
客户端发送了 Expect: 100-continue 头部 |
解析头部时检查 |
设计亮点:这些标志位让
received()方法能够准确知道当前解析处于哪个阶段,从而决定是继续找头部边界、解析头部字段,还是把数据喂给请求体接收器。这是一种典型的“状态模式”在纯 Python 中的轻量级实现。
四、为何如此设计?——权衡与演进
设计①:增量式解析应对海量并发
Waitress 需要同时处理成百上千个连接。如果每个连接都必须等待整个 HTTP 请求(尤其包含大文件上传)加载完毕才能开始处理,服务器内存将瞬间爆炸。增量式解析正是为了让内存使用量与请求体大小解耦——大请求的数据可以溢出到磁盘,而不是阻塞在内存中。
设计②:严格的头部验证防止攻击
历史版本曾因对 Transfer-Encoding 头部的解析不够严格而暴露出 HTTP 请求走私漏洞。
因此,最新代码进行了严格限制:
-
get_header_lines()函数禁止头部行内出现裸的\r或\n,以彻底封堵 HTTP 响应拆分攻击。 -
crack_first_line()强制要求 HTTP 方法必须为大写字母,与 RFC 7231 严格对齐。 -
Transfer-Encoding解析仅支持chunked作为最后一个编码,且只支持单一编码值。
设计③:模块化解耦便于测试和维护
将解析逻辑拆分为独立的函数和类(如 crack_first_line、split_uri、get_header_lines),每个单元都可以被单独测试。从 Debian 补丁记录可以看到,test_parser.py 的测试用例超过 270 行,覆盖了各种边界条件和异常场景。
设计④:WSGI 协议的忠实实现者
parser.py 的设计还有一个深层动机:WSGI 规范对请求环境变量的格式有严格定义。
| WSGI 环境变量 | 来源 | parser.py 的处理 |
|---|---|---|
REQUEST_METHOD |
请求行中的方法 | crack_first_line() 提取 |
PATH_INFO |
URI 中的路径部分 | split_uri() 解析 |
QUERY_STRING |
URI 中 ? 后的部分 |
split_uri() 解析 |
SERVER_PROTOCOL |
请求行中的 HTTP 版本 | crack_first_line() 提取 |
CONTENT_TYPE / CONTENT_LENGTH |
对应头部字段 | 头部解析时存入 environ |
wsgi.input |
请求体数据流 | get_body_stream() 返回 |
这些环境变量正是 WSGI 应用(如 Flask、Django)赖以运行的基础。parser.py 的设计确保了 Waitress 生成的 environ 字典完全符合 WSGI 规范,从而实现与任意 WSGI 框架的无缝兼容。
五、关键代码片段解析
5.1 请求行解析的正则表达式
first_line_re = re.compile(
b"([^ ]+) " # HTTP 方法,如 GET、POST
b"((?:[^ :?#]+://[^ ?#/]*(?:[0-9]{1,5})?)?[^ ]+)" # URI(支持完整 URL)
b"(( HTTP/([0-9.]+))$|$)" # HTTP 版本(可选)
)这个正则的精妙之处在于:它不仅支持常见的 GET /path 格式,还能正确解析代理转发的绝对 URI 格式(如 GET http://example.com/path HTTP/1.1),这种格式在处理反向代理场景时至关重要。
5.2 Transfer-Encoding 的严谨处理
encodings = [encoding.strip(" \t").lower() for encoding in te.split(",") if encoding]
for encoding in encodings:
if encoding not in {"chunked"}:
raise TransferEncodingNotImplemented(...)
if encodings and encodings[-1] == "chunked":
self.chunked = True
self.body_rcv = ChunkedReceiver(buf)这段代码体现了 Waitress 对 HTTP 规范的严格遵循:
-
按顺序解析:RFC 7230 要求 Transfer-Encoding 值按接收顺序处理
-
仅支持 chunked:只实现最常用的分块传输编码
-
chunked 必须为最后一个:这是 RFC 规定的,用于标识消息体的结束
5.3 折叠头部的合并逻辑
for line in lines:
if line.startswith((b" ", b"\t")): # 续行以空格或制表符开头
if not r: # 没有上一行则非法
raise ParsingError(...)
r[-1] += line # 合并到上一行
else:
r.append(line)HTTP 头部允许将长值折叠到多行,每行以空格或制表符开头。这个函数正确处理了这种边缘情况,确保头部字段的完整性。
六、parser.py 完整源代码
版本说明:以下代码基于 Waitress 3.0.x 版本,来源于官方 GitHub 仓库。
# -*- coding: utf-8 -*-
##############################################################################
#
# Copyright (c) 2001, 2002 Zope Foundation and Contributors.
# All Rights Reserved.
#
# This software is subject to the provisions of the Zope Public License,
# Version 2.1 (ZPL). A copy of the ZPL should accompany this distribution.
# THIS SOFTWARE IS PROVIDED "AS IS" AND ANY AND ALL EXPRESS OR IMPLIED
# WARRANTIES ARE DISCLAIMED, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED
# WARRANTIES OF TITLE, MERCHANTABILITY, AGAINST INFRINGEMENT, AND FITNESS
# FOR A PARTICULAR PURPOSE.
#
##############################################################################
"""HTTP Request Parser
This server uses asyncore to accept connections and do initial processing but
threads to do work.
"""
from io import BytesIO
import re
from urllib import parse
from urllib.parse import unquote_to_bytes
from waitress.buffers import OverflowableBuffer
from waitress.receiver import ChunkedReceiver, FixedStreamReceiver
from waitress.utilities import (
BadRequest,
RequestEntityTooLarge,
RequestHeaderFieldsTooLarge,
ServerNotImplemented,
find_double_newline,
)
from .rfc7230 import HEADER_FIELD
def unquote_bytes_to_wsgi(bytestring):
return unquote_to_bytes(bytestring).decode("latin-1")
class ParsingError(Exception):
pass
class TransferEncodingNotImplemented(Exception):
pass
class HTTPRequestParser:
"""A structure that collects the HTTP request.
Once the stream is completed, the instance is passed to a server task
constructor.
"""
completed = False # Set once request is completed.
empty = False # Set if no request was made.
expect_continue = False # client sent "Expect: 100-continue" header
headers_finished = False # True when headers have been read
header_plus = b""
chunked = False
content_length = 0
header_bytes_received = 0
body_bytes_received = 0
body_rcv = None
version = "1.0"
error = None
connection_close = False
# Other attributes: first_line, header, headers, command, uri, version,
# path, query, fragment
def __init__(self, adj):
"""adj is an Adjustments object."""
# headers is a mapping containing keys translated to uppercase
# with dashes turned into underscores.
self.headers = {}
self.adj = adj
def received(self, data):
"""Receives the HTTP stream for one request.
Returns the number of bytes consumed. Sets the completed flag once
both the header and the body have been received.
"""
if self.completed:
return 0 # Can't consume any more data for this request.
if self.empty:
return 0 # Can't consume any more data for this request.
datalen = len(data)
br = self.body_bytes_received
# In order to be careful of the number of bytes consumed we only
# increase header_bytes_received when we're still reading the header.
if not self.headers_finished:
# a header fragment is given, so we need to append to header_plus.
# we then search for the double newline in the header.
need = datalen
want = self.adj.max_request_header_size - self.header_bytes_received
if want < need:
# The header is too big
raise RequestHeaderFieldsTooLarge(
"Maximum request header size exceeded",
self.adj.max_request_header_size,
)
# This is fast because header_plus is a bytes object and
# find_double_newline uses a fast C loop to find the first
# occurrence of \r\n\r\n
self.header_plus += data[:need]
self.header_bytes_received += need
# if we find a double newline, we have the header
double_newline = find_double_newline(self.header_plus)
if double_newline >= 0:
self.headers_finished = True
header = self.header_plus[:double_newline]
rest = self.header_plus[double_newline + 4 :]
# parse the header
self.parse_header(header)
# and then treat the rest of the bytes we consumed as if they
# were part of the body
if rest:
data = rest + data[need:]
datalen = len(data)
# we've consumed all the header bytes, so we need to set the
# body_bytes_received to the number of body bytes consumed
br = self.body_bytes_received = self.header_bytes_received - len(rest)
else:
# we haven't found a double newline yet, we have to return
# since we can't do any body reading.
return need
# at this point we have the headers, and we can start reading the body.
if self.body_rcv is None:
# we have not yet set up the body receiver; we need to do that
# now that we have the headers.
self.setup_body_receiver()
# Give the rest of the data to the body receiver.
body_consumed = self.body_rcv.received(data)
self.body_bytes_received += body_consumed
if self.body_rcv.completed:
self.completed = True
self.get_body_stream().seek(0)
return datalen
def parse_header(self, header):
"""Parse the HTTP headers into self.headers.
Also sets the following attributes: command, uri, version,
path, query, fragment, expect_continue, connection_close, chunked,
content_length.
"""
# The header is received, now we need to parse it into the headers
# mapping.
# We have to handle multi-line headers.
lines = get_header_lines(header)
# first line is the request line: method, uri, version
first_line = lines.pop(0)
if not first_line:
raise ParsingError("Request line is empty")
# parse the first line
method, uri, version = crack_first_line(first_line)
if not method:
raise ParsingError("Malformed request line")
# This duplicates what WSGI does, but it's easier if we just
# pre-decode the uri here.
self.command = method.decode("latin-1")
self.version = version.decode("latin-1")
# split the uri into path, query, fragment
self.proxy_scheme, self.proxy_netloc, path, query, fragment = split_uri(uri)
self.path = path
self.query = query
self.fragment = fragment
# now parse the rest of the lines
for line in lines:
# split on the first colon
name, value = line.split(b":", 1)
name = name.strip()
# we don't allow newlines in the header value.
value = value.strip(b" \t")
name = name.decode("latin-1").upper().replace("-", "_")
# WSGI requires that HTTP_ variables are in the environ
# We use the same convention.
if name in ("CONTENT_TYPE", "CONTENT_LENGTH"):
self.headers[name] = value.decode("latin-1")
else:
self.headers["HTTP_" + name] = value.decode("latin-1")
# determine the connection close behavior
connection = self.headers.get("HTTP_CONNECTION", "")
if self.version == "1.0":
if connection.lower() != "keep-alive":
self.connection_close = True
if self.version == "1.1":
# since the server buffers data from chunked transfers and clients
# never need to deal with chunked requests, downstream clients
# should not see the HTTP_TRANSFER_ENCODING header; we pop it
# here
te = self.headers.pop("HTTP_TRANSFER_ENCODING", "")
# NB: We can not just call bare strip() here because it will also
# remove other non-printable characters that we explicitly do not
# want removed so that if someone attempts to smuggle a request
# with these characters we don't fall prey to it.
# For example \x85 is stripped by default, but it is not considered
# valid whitespace to be stripped by RFC7230.
encodings = [encoding.strip(" \t").lower() for encoding in te.split(",") if encoding]
for encoding in encodings:
# Out of the transfer-codings listed in
# https://tools.ietf.org/html/rfc7230#section-4 we only support
# chunked at this time.
# Note: the identity transfer-coding was removed in RFC7230:
# https://tools.ietf.org/html/rfc7230#appendix-A.2 and is thus
# not supported
if encoding not in {"chunked"}:
raise TransferEncodingNotImplemented(
"Transfer-Encoding requested is not supported."
)
if encodings and encodings[-1] == "chunked":
self.chunked = True
# we need to create a body receiver that can handle chunked
# encoding
buf = OverflowableBuffer(self.adj.inbuf_overflow)
self.body_rcv = ChunkedReceiver(buf)
elif encodings:
raise TransferEncodingNotImplemented(
"Transfer-Encoding requested is not supported."
)
# Check for the Expect header
expect = self.headers.get("HTTP_EXPECT", "").lower()
self.expect_continue = expect == "100-continue"
if connection.lower() == "close":
self.connection_close = True
if not self.chunked:
# No chunked encoding, so we need to read the body based on
# Content-Length
try:
cl = int(self.headers.get("CONTENT_LENGTH", 0))
except ValueError:
raise ParsingError("Content-Length is invalid")
self.content_length = cl
if cl > 0:
buf = OverflowableBuffer(self.adj.inbuf_overflow)
self.body_rcv = FixedStreamReceiver(cl, buf)
def setup_body_receiver(self):
"""Set up the body receiver based on the headers."""
if self.body_rcv is not None:
return
if self.chunked:
buf = OverflowableBuffer(self.adj.inbuf_overflow)
self.body_rcv = ChunkedReceiver(buf)
elif self.content_length > 0:
buf = OverflowableBuffer(self.adj.inbuf_overflow)
self.body_rcv = FixedStreamReceiver(self.content_length, buf)
else:
# no body
self.body_rcv = FixedStreamReceiver(0, None)
self.body_rcv.completed = True
def get_body_stream(self):
"""Return a file-like object for the request body."""
if self.body_rcv is not None:
return self.body_rcv.getfile()
else:
return BytesIO()
def close(self):
if self.body_rcv is not None:
self.body_rcv.getbuf().close()
def split_uri(uri):
"""Split a URI into scheme, netloc, path, query, fragment."""
scheme = netloc = path = query = fragment = b""
# urlsplit below will treat this as a scheme-less netloc, thereby losing
# the original intent of the request. Here we shamelessly stole 4 lines of
# code from the CPython stdlib to parse out the fragment and query but
# leave the path alone. See
# https://github.com/python/cpython/blob/8c9e9b0cd5b24dfbf1424d1f253d02de80e8f5ef/Lib/urllib/parse.py#L465-L468
# and https://github.com/Pylons/waitress/issues/260
if uri[:2] == b"//":
path = uri
if b"#" in path:
path, fragment = path.split(b"#", 1)
if b"?" in path:
path, query = path.split(b"?", 1)
else:
try:
scheme, netloc, path, query, fragment = parse.urlsplit(uri)
except UnicodeError:
raise ParsingError("Bad URI")
return (
scheme.decode("latin-1"),
netloc.decode("latin-1"),
unquote_bytes_to_wsgi(path),
query.decode("latin-1"),
fragment.decode("latin-1"),
)
def get_header_lines(header):
"""Split the header into lines, putting multi-line headers together."""
r = []
lines = header.split(b"\r\n")
for line in lines:
if not line:
continue
if b"\r" in line or b"\n" in line:
raise ParsingError(
'Bare CR or LF found in header line "%s"' % str(line, "latin-1")
)
if line.startswith((b" ", b"\t")):
if not r:
# https://corte.si/posts/code/pathod/pythonservers/index.html
raise ParsingError('Malformed header line "%s"' % str(line, "latin-1"))
r[-1] += line
else:
r.append(line)
return r
first_line_re = re.compile(
b"([^ ]+) " # method
b"((?:[^ :?#]+://[^ ?#/]*(?:[0-9]{1,5})?)?[^ ]+)" # uri (with optional scheme)
b"(( HTTP/([0-9.]+))$|$)" # version
)
def crack_first_line(line):
"""Parse the first line of a request.
Returns a tuple of (method, uri, version).
"""
m = first_line_re.match(line)
if m is not None and m.end() == len(line):
if m.group(3):
version = m.group(5)
else:
version = b""
method = m.group(1)
# the request methods that are currently defined are all uppercase:
# https://www.iana.org/assignments/http-methods/http-methods.xhtml
# and the request method is case sensitive according to
# https://tools.ietf.org/html/rfc7231#section-4.1
# By disallowing anything but uppercase methods we save poor
# unsuspecting souls from sending lowercase HTTP methods to waitress
# and having the request complete, while servers like nginx drop the
# request onto the floor.
if method != method.upper():
raise ParsingError('Malformed HTTP method "%s"' % str(method, "latin-1"))
uri = m.group(2)
return method, uri, version
else:
return b"", b"", b""七、总结
parser.py 通过增量式解析、严格的安全验证、模块化的协作组件和完整的WSGI兼容性,在纯 Python 环境中实现了一个健壮且高效的 HTTP 请求解析器。
它的设计充分体现了 Waitress “生产级、纯Python、跨平台” 的核心哲学,是连接底层 I/O 与上层业务逻辑之间不可或缺的一环。理解 parser.py,有助于掌握 HTTP 协议解析的核心原理、WSGI 规范的具体实现,以及 Waitress 如何处理海量并发的请求。
学习建议:建议配合阅读
receiver.py(请求体接收器)和rfc7230.py(头部字段验证),这三者共同构成了 Waitress 完整的 HTTP 请求解析体系。
本文为个人学习笔记,仅用于知识分享。如有错误,欢迎指正。
👍🏻 点赞 + 收藏 + 分享,让更多开发者看到这篇深度解析!❤️ 如果觉得有用,请给个赞支持一下作者!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)