手写 STL string: 从接口到底层基本常用功能的实现
文章目录
前言:为什么要手写STL string
在学习了类与对象之后,我们可能对它的理解还不够,写一下用类封装的对象能让我们巩固并对类与对象的默认成员函数加深理解。
也是对我们手写代码的练习,在ai高速发展的时期,我个人认为培养自己写代码能力与调试能力还是有必要的
也是自己对自己的输出会写是一回事,能讲出来又是一回事。
因此这篇文章也是给自己也是给和我一样想努力提升自己的能力的小伙伴的一些参考
string常用的接口
namespace TAO {
class string {
public:
static const size_t npos;
typedef char* iterator;
iterator begin();
iterator end();
string(const char* str="");
string(const string& s);
string& operator=(const string& s);
char* c_str();
size_t size();
size_t size()const;
char& operator[](size_t i);
char& operator[](size_t i)const;
void push_back(char ch);
void append(const char* str);
void reserve(size_t n);
void clear();
string& operator+=(char ch);
string& operator+=(const char* str);
void insert(size_t pos, char ch);
void insert(size_t pos, const char* str);
void erase(size_t pos, size_t len = npos);
size_t find(char ch, size_t pos = 0)const;
size_t find(char* str, size_t pos = 0)const;
string substr(size_t pos, size_t len = npos)const;
bool operator<(const string& s)const;
bool operator<=(const string& s)const;
bool operator==(const string& s)const;
bool operator>(const string& s)const;
bool operator>=(const string& s)const;
bool operator!=(const string& s)const;
private:
char* _str=nullptr;
size_t _size;
size_t _capacity;
};
ostream& operator<<(ostream& out, const string& s);
istream& operator>>(istream& is, string& s);
istream& getline(istream& is, string& str, char delim);
}
创建对象时需要注意的事项
你自己实现string时,一定要把它写在你自己写的命名空间域里面,要不然会与c++库里面的string命名冲突,所以这是为了避免这种情况,但在里面的细节还要说明,一般我们是在vs这样写代码的
头文件、测试文件、代码实现文件在这三个,在头文件比如这样写
namespace TAO{
class string
.......
}
后续在代码文件、测试文件都要把它写在你自己命名的空间域里面,代码文件其实可以不用但你在头文件声明后,在代码文件定义你需要这样写 TAO::string::(函数)太麻烦了,所以写了之后就只要写string::(函数)就舒服很多,后续你以后写项目把每个板块的代码写在对应的命名空间域也好查询与维护。
核心的接口函数
首先解释一下私有成员的代码意思:
char* _str这是一个待动态扩容的私有成员变量的定义
size_t _size这是计算有效个数的变量它在字符串末尾的下一个,这个位置的下标就是有效个数的个数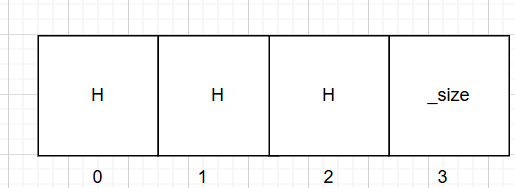
如图可看出(我知道很基本因为应该有没有学过c语言数据结构的不懂)
_capacity这个是指当前对象的总容量也就是最多能装下的字符数量
构造函数
string::string(const char* str)
:_size(strlen(str))
{
_str = new char[_size + 1];
_capacity = _size;
memcpy(_str, str, _size+1);
}
剖析代码:
为什么初始化列表只给_size呢?为什么不这样写
:_size(strlen(str))
, _capacity(strlen(str))
, _str(new char[_size + 1])
首先我们知道strlen是C语言的函数,你的构造函数是要频繁调用的因为创建对象就要调用构造函数,因此strlen它每创建一个对象就要创建两次,创建一亿个,调用strlen一亿次,效率就会大大减慢,因此我们初始化列表就只要_size就行
那我知道你们肯定有疑问为什么不这样?
:_size(strlen(str))
, _capacity(_size)
, _str(new char[_size + 1])
这样不就每次创建对象调用就一次strlen吗?这里就是对类与对象的初始化列表的坑了: 在初始化列表中,它的顺序是与你的私有成员定义的顺序一致的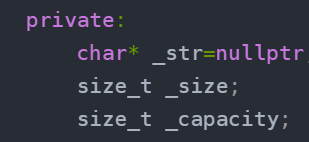
因为我们写成员一般都是这样写,故它是先初始化_str然后才是_size那这样除了_size其他两个不都成随机值赋值了,可是可以把_size写在_str前面但一点都不美观也不是我们程序员的习惯,故
string::string(const char* str)
:_size(strlen(str))
{
_str = new char[_size + 1];
_capacity = _size;
memcpy(_str, str, _size+1);
}
这样写构造函数是我自己认为的最优解,把_str与_capacity的初始化写在函数体内,初始化列表只走_size即可,_str动态扩容需要多扩一个存放’\0’,(很重要)
_capacity开始与_size一样即可后续对_capacity扩容我会在后面写(这里的_size和_capacity都不包含’\0’,保持与c++库里的string一致)
memcpy是将你在创建对象时你给的字串给它,不给默认给空串。
memcpy的说明:(给不懂得小伙伴的解释)
第一个参数_str是你的目的对象,s._str是你要复制的对象,是把s._str里的数据复制到_str里(注意memcpy前两个参数都是指针类型),第三个参数是你要拷贝多少个字节,需要注意的是:char类型是一个数据是1个字节故可以直接写size(有效个数),那如果是整型如 int类型 就需要这样写sizeof(int)size.sizeof能算出你所给的类型一个数据占多少字节。
这里的size多加1是因为把’\0’复制过去这样的字串更合理。
拷贝构造函数*
string::string(const string& s) {
_str = new char[s._capacity+1];
memcpy(_str, s._str, s._size + 1);
_size = s._size;
_capacity = s._capacity;
}
代码剖析:
你看懂了构造函数,拷贝构造就差不多也能写,_str一样给’\0多开个空间, _size和_capacity与你·形参的对象的一样。
析构函数
string::~string() {
delete[] _str;
_str = nullptr;
_size = _capacity = 0;
}
这个就很简单了,这个就不做详细解释了。
基本的接口函数
计算对象中有效个数
size_t string::size()const {
return _size;
}
size_t string::size() {
return _size;
}
const版本写的意义是c++库里也是写两个而已,size()函数本来也就是拿到当前对象有效个数。
返回字串中首元素地址
char* string::c_str() {
return _str;
}
打印的时候这样写也行cout<<s.c_str()<<endl;
这个函数的作用并不大。
对[ ]的函数重载
char& string::operator[](size_t i) {
return *(_str + i);
}
char& string::operator[](size_t i)const {
return *(_str + i);
}
代码剖析:
对[ ]重载后访问_str里的数据就能像访问数组里的数据一样的方式访问
比如你创建 string s(“hello world”),cout<<s[0]<<endl; 输出的就是 ‘h’,
s[0]也是转化为这样的形式调用s.operator , const版本就是只访问不修改。
扩容函数reserve
void string::reserve(size_t n) {
if (n > _capacity) {
char* new_str = new char[n + 1];
memcpy(new_str, _str, _size + 1);
delete[] _str;
_str = new_str;
_capacity = n;
}
}
代码剖析:
首先if这个判断条件发生是如果你给的值是大于之前的容量那就进行,因为一般只扩容不缩容。然后先在堆上创建new_str新的字符串数组,大小为你需要扩成n的容量再加1给’\0’的。然后将原来对象成员里的字符数组的数据先给new_str,然后再释放掉旧数据(只是初始化数据地址还是存在的)_str=new_str不会发生对空指针的赋值。
常用的接口函数
尾插函数——push_back()
**解释:**也就是在字符串后面尾插你给的字符或字符串
尾插单个字符:
void string::push_back(char ch) {
if (_size == _capacity) {
size_t newcapacity = _capacity == 0 ? 4 : 2 * _capacity;
reserve(newcapacity);
}
_str[_size++] = ch;
_str[_size] = '\0';
}
代码剖析:
首先你插入单个字符肯定要考虑容量够不够,所以当有效个数_size和容量_capacity相等时那就是装满了没有空间再插入字符,故需要扩容,根据我前面写的扩容函数一般是二倍扩容。然后再在_size所在的位置那插入你想插入的字符ch,_size++这样的后置++是先使用当前_size的位置进行操作后_size再++;你也可以在后面写_size++;看个人习惯,最后在_size上填上’\0’。这个是很有必要的,一是C语言的字符串也有’\0’的结束标志,二是你如果是调用我上面给的cout<<c_str(),这个函数打印字符串的话,会出现乱码,因为cout和C语言的scanf都是以’\0‘作为标志结束的。
尾插函数——append(const char* str)
尾插一个字符串:
形参的注意事项:
这里的字符串的形参部分一定要加const 因为字符串是常量的字符串,不能对它进行修改,所以形参加const避免发生权限的放大
void string::append(const char* str) {
size_t len = strlen(str);
if (_size + len > _capacity) {
size_t newcapacity = _size + len > 2 * _capacity ? (_size + len) : 2 * _capacity;
reserve(newcapacity);
}
memcpy(_str + _size, str, len);
_size += len;
_str[_size] = '\0';
}
代码剖析:
首先计算出你所要插入的字符串长度,你原来的有效个数_size加上你要插入的字符串长度 len如果大于你当前的容量,就需要扩容,其次,这里的扩容有讲究的,我那个三目操作符的意思是,(我这里就用代码所代表的参数写)len+_size的个数如果二倍扩容都装不下的话,那扩容就扩成len+_size的大小,最好是二倍扩容能装得下,因为能避免频繁扩容。
然后就是把串插入到_str的后面,_str+_size的意思是_str是首元素,+_size就到了末尾位置,也就正好是在尾部插入字串,长度len就是字串的长度
_size的有效长度就变为_size+len,再在_size位置插入’\0’;
指定位置插入函数——insert()
指定位置插入单个——insert(size_t pos,char ch):
void string::insert(size_t pos, char ch) {
assert(pos < _size);
if (_size == _capacity) {
size_t newcapacity = _capacity == 0 ? 4 : 2 * _capacity;
reserve(newcapacity);
}
size_t end = _size + 1;
while (end > pos) {
_str[end] = _str[end - 1];
--end;
}
_str[pos] = ch;
_size += 1;
_str[_size] = '\0';
}
代码剖析:
首先这个assert是一个断言,如果传入的pos值大于有效个数,那就直接停止代码并发生报错
扩容跟尾插入一个字符一样的写这里不再作解释
下面while循环是对在pos位置及之后的数据向后挪动一位的操作
注:pos指的是下标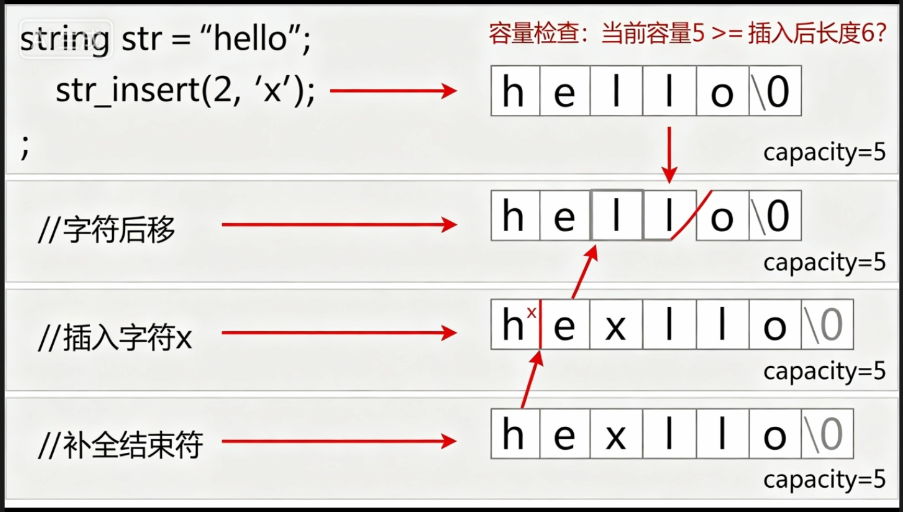
具体操作如上面的例子
为什么循环终止条件是end>pos,因为end=pos+1时,_str[end] = _str[end - 1];
它已经把pos位置的字符向后挪了,故当end=pos是已经挪动完了。
最后在pos位置插入你给的字符,size的有效长度就变为_size+1,再在_size位置插入’\0’;
当然看到这里你肯定会有自己的想法
size_t end = _size;
while (end >= pos) {
_str[end] = _str[end + 1];
--end;
}
我觉得你会这样写,你想肯定要与博主来点不同的代码,但你自己写一个样例来测试时,而且你是s.insert(0,‘x’),你会出现
没错,程序崩了你会疑问,为什么呢?你看着代码当end=-1时,不是会跳出循环码,但你忽略了一点 你写的类型时size_t。 这里我插一嘴,为什么我的所有变量要写size_t 呢,size_t 表示的类型为无符号整型 也就是只有正数,因为你所进行的所有操作都不可能传负数,所以用size_t。 所以当end=-1时,就会把-1转化为无符号整数的最大值,最大值那肯定比pos大所以一直循环程序崩溃。想修改很简单一种是按我的写,或者这样定义
int end=_size;
while(end>=(int)pos){
...........
}
把end为int类型
强转pos为int类型。
指定位置插入单个字符串——insert(size_t pos,const char str):*
void string::insert(size_t pos, const char* str) {
assert(pos < _size);
size_t len = strlen(str);
if (_size + len > _capacity) {
size_t newcapacity = _size + len > 2 * _capacity ? (_size + len) : 2 * _capacity;
reserve(newcapacity);
}
size_t end = _size + len;
while (end > pos + len - 1) {
_str[end] = _str[end - len];
--end;
}
for (size_t i = 0; i < len; i++) {
_str[pos + i] = str[i];
}
_size += len;
_str[_size] = '\0';
}
代码剖析:
一样的插入字符串扩容就按照我给的append函数的扩容搞
我这里的挪动就按插入一个字符的方式挪动(你觉得麻烦也能写我给的第二种强转方式写,与插入一个字符的代码类似)
end在你要插入字符串长度改变之后的位置,如,我插入两个字符的字符串在pos=2的位置
所以len=2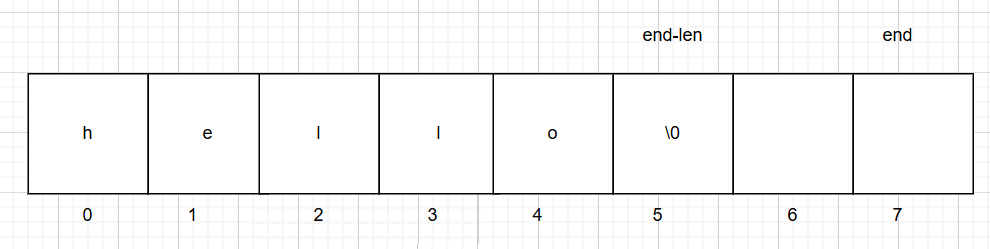
然后把end-len的数据挪到end位置,–end;
当到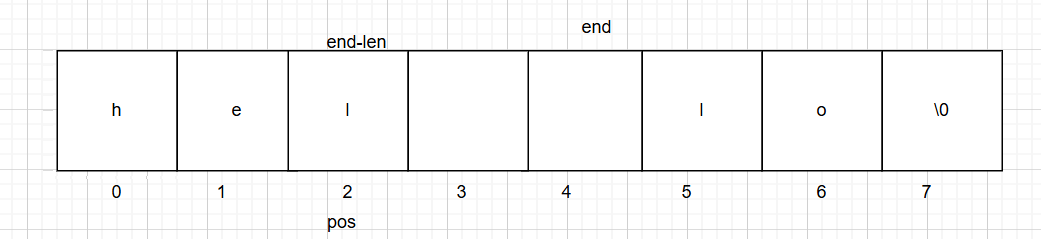
要把pos位置的数挪走后,–end到3这个位置就挪动完了,所以终止条件为pos+len-1(=3)的时候循环结束,
后面就用for循环插入数据最后在改变_size并且加上’\0’.
指定位置删除函数——erase()
void string::erase(size_t pos, size_t len ) {
assert(pos < _size);
if (len == npos || len > _size - pos) {
_size = pos;
_str[pos] = '\0';
return;
}
size_t tmp = pos;
for (size_t i = 0; i < _size - len - pos + 1; i++) {
_str[pos + i] = _str[tmp + len];
++tmp;
}
_size -= len;
}
代码剖析:
首先断言没得说
然后npos是在类里面在public里或private里都行,这样声明
static const size_t npos;它是静态变量
然后在代码文件中所对应的命名空间域里任意位置定义:const size_t string::npos = -1;
因为是无符号整型,所以npos为最大整数
void erase(size_t pos, size_t len=npos );//这是在头文件的声明
if条件中如果len没给值或者给的len大于从pos位置到_size的个数的话,那就是删除从pos到_size的全部数据,_size就=pos,然后在pos位置给’\0’
如果不满足if条件就执行下面的for循环
代码含义是先将要删除字符后面的数据包括’\0’先挪动过来,在改变_size就相当于删除了数据(在数组中的删除数据并不是真正的把内存释放掉,而是覆盖数据或者通过_size来记录去除后的有效数据)
边界条件i<_size-len-pos的解释,_size为总的有效个数 pos对应的下标是不用删除的数据个数,len为删除的个数,然后相减之后就是剩下要挪动的数据,再加上一也就是’\0’也要挪动
查找字符函数——find()
从指定位置查找单个字符的位置——find(char ch, size_t pos)const:
解释:
就是在你所给的字符串中查找第一个你想查找的字符下标位置
size_t string::find(char ch, size_t pos)const {
assert(pos < _size);
for (size_t i = pos; i < _size; i++) {
if (_str[i] == ch) {
return i;
}
}
return npos;
}
代码剖析:
这个for循环当找到了对应字符就返回下标即可,没找到返回npos;
从指定位置查找一个字符串的位置——find(const char str, size_t pos)const:*
解释:
跟查找一个字符类似,当它在你所给的字符串中找到了对应的字符串,就会返回这个字符串的首元素的下标位置
size_t string::find(char* str, size_t pos)const {
assert(pos < _size);
char* p1=strstr(_str + pos, str);
if (p1 == nullptr) {
return npos;
}
return p1 - _str;
}
代码剖析:
strstr是C语言里查找字符串的函数,当它在你所给的字符串中找到了对应的字串,就会返回这个字符串的首元素的地址
一般是从当前你给的字符串首元素地址开始,这里则是从pos位置开始找字串——str。
没找到返回npos
找到了返回下标, **p1-_str解释:**因为数组中的地址是连续的两个地址相减就是p1也就是找到的子串中首元素的下标。
string substr(size_t pos, size_t len)const
解释:
拷贝一个对象中的从pos这个位置,由len个生成字串并返回以这个字串初始化的string的临时对象
可能利用这个临时对象去初始化另一个对象
string string::substr(size_t pos, size_t len)const {
assert(pos < _size);
if (len == npos || len > _size - pos) {
len = _size - pos;
}
string ret;
ret.reserve(len);
for (size_t i = 0; i < len; i++) {
ret._str[i] = _str[pos + i];
}
ret._size += len;
ret._str[ret._size] = '\0';
//cout << ret << endl;
return ret;
}
代码剖析:
if条件中如果len没给值那就是默认的缺省值npos或者len大于从pos到_size之间的有效数据个数
那len就=从pos到_size之间的有效数据个数
创建临时对象 ret来接受从pos这个位置起长度为len的字串
然后返回这个临时对象。
需要注意的是:
因为你是传类类型返回不是, 并不是直接返回ret给你要初始化的对象,而是ret又创建了一个临时对象,它是经过拷贝构造而形成的,并且是深拷贝,所以为什么我所写的拷贝构造函数是核心函数 如果不写拷贝构造函数的话那就会是浅拷贝,浅拷贝就会导致ret与它的临时对象的_str都指向同一个地址当substr的栈帧销毁就会调用析构函数,当临时对象初始化完另一个对象也会调用析构函数,但是ret已经析构完了把堆上的资源清空了,那临时对象又去对堆上同一块空间再次析构就会报错,因为同一块空间不能连续析构两次。
所以这个函数也证明了有些编译器默认给的构造函数有时候不满足我们的需求因此当需要在堆上额外申请空间的时候一定要写拷贝构造进行深拷贝
一些常用的重载运算符函数
opeartor+=()
解释:
这个运算符重载跟push_back()和append()一样,能在字符串尾插字符或字符串
也是我们在日常练习或者算法题喜欢写的
string& string::operator+=(char ch) {
push_back(ch);
return *this;
}
string& string::operator+=(const char* str) {
append(str);
return *this;
}
代码剖析:
这里就不多做解释就是对我们自己写的成员函数的复用,push_back()和append()的详细请看目录的常用函数
赋值运算符opeartor=(const string& s)
解释:
就是将一个已实例化对象赋值给另一个实例化对象
string& string::operator=(const string& s) {
if (this != &s) {
char* new_str = new char[s._capacity + 1];
delete[] _str;
memcpy(new_str, s._str, s.size()+1);
_str = new_str;
_size = s.size();
_capacity = s._capacity;
}
return *this;
}
代码剖析:
if条件是防止自己给自己赋值这种无用操作,里面的操作跟拷贝构造一样,就是多了一步delete释放掉被赋值的对象的旧数据,然后指向新数据也就是给他赋值对象的拷贝的数据。
一些两个类对象比较运算符重载函数
bool operator<(const string& s)const;
bool operator==(const string& s)const;
bool operator<=(const string& s)const;
bool operator>(const string& s)const;
bool operator>=(const string& s)const;
bool operator!=(const string& s)const;
只要实现了operator <和operator==就能复用给其他的比较运算符函数
bool string::operator<(const string& s)const {
size_t i1 = 0;
size_t i2 = 0;
while (i1 < _size && i2 < s._size) {
if (_str[i1] < s._str[i2]) {
return true;
}
else if (_str[i1] == s._str[i2]) {
i1++;
i2++;
}
else {
return false;
}
}
return i2 < s._size;
}
bool string::operator==(const string& s)const {
size_t i1 = 0;
size_t i2 = 0;
while (i1 < _size && i2 < s._size) {
if (_str[i1] != s._str[i2]) {
return false;
}
else {
i1++;
i2++;
}
}
return i1 == _size && i2 == s._size;
}
代码剖析:
字符的比较是比较字符下的ASCII值,这两个的代码应该很容易看懂
我来解释一下return i2 < s._size; 这段代码的妙处,比如
比较 “hello” 和 “hello” 返回false
比较 “hellox” 和 “hello” 返回false
比较 “hello” 和 “hellox” 返回 true
你看只有当i2<它的有效个数才是返回true
所以return i1 == _size && i2 == s._size;也是如此只有每个字符比较都相等也就是i1和i2跳出while都=各自的_size才返回true。
其它几个都是复用它们两个
bool string::operator<=(const string& s)const {
return *this < s || *this == s;
}
bool string::operator>(const string& s)const {
return !(*this < s);
}
bool string::operator>=(const string& s)const {
return !(*this < s) || *this == s;
}
bool string::operator!=(const string& s)const {
return !(*this == s);
}
对流输入和流输出的重载函数
流输出(<<)ostream& operator<<(ostream& out, const string& s)
解释:
string s;
因为库里的string可以支持cout<<s;这样的打印,故我们自己实现的string也要有这样的功能
并且它的声明在类的外面或者全局中声明都行
ostream& operator<<(ostream& out, const string& s) {
for (size_t i = 0; i < s.size(); i++) {
out << s[i];
}
return out;
}
代码剖析:
就是个简单的for循环,这样写的好处是如果你在_size位置如果忘加’\0’做字符串的结束符号也不要紧,因为它只输入有效个数。
流输入istream& operator>>(istream& is, string& s)
解释:
与流输出同理我们自己写的string可以支持输入
istream& operator>>(istream& is, string& s) {
s.clear();
char ch = is.get();
char buff[128];//用这个数组暂存流输入
int i = 0;
while (ch != ' ' &&ch != '\n') {
buff[i++] = ch;
if (i == 127) {
buff[i] = '\0';
s += buff;
i = 0;
}
ch = is.get();
}
if (i > 0) {
buff[i] = '\0';
s += buff;
}
return is;
}
代码剖析:
get()函数是是能获取你输入里打的字符,
buff数组是暂存你所输入的字符,这样做的好处如果直接s+=ch就会频繁的扩容,暂存到一个数组中然后再一并插入到s中能减少很多次扩容
一个字符串的终止条件是空格或者换行符’\n’
if 条件是如果buff满了就先输入到s里,再i重置为0从buff[0]开始接受数据
没满就终止的话就输入当前的buff里所有的字符
扩展函数:istream& getline(istream& is, string& str, char delim)——以任意字符当作结束符号
解释:
因为有时候我们可能想用cin>>输入的字符串想要是这样的"hello world"带有空格,因为一般cin或C语言的scanf输入都是以空格或换行符’\n’来判断一个串的结束标志。所以需要一个函数来实现这种功能
istream& getline(istream& is, string& str, char delim) {
str.clear();
char ch = is.get();
char buff[128];//用这个数组暂存流输入
int i = 0;
while (ch !=delim) {
buff[i++] = ch;
if (i == 127) {
buff[i] = '\0';
str += buff;
i = 0;
}
ch = is.get();
}
if (i > 0) {
buff[i] = '\0';
str += buff;
}
return is;
}
}
代码剖析:
其实和流输入代码差不多,就是改一下while的条件是以你所给的字符当结束标志
结语
每次写博客都是对知识的输出,但我相信我每次的博客花六七个小时的时间输入的付出总会有结果的
创作不易,还妄各位看到或看完的小伙伴点个赞支持一下,谢谢!!!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)