猎聘网职位数据爬取实战:逆向 API 接口获取招聘信息
本文介绍了如何通过逆向猎聘网API接口批量获取招聘信息。首先分析猎聘网搜索职位时的POST请求接口,对比直接解析HTML的优势。重点讲解了请求头构造的关键字段(如User-Agent、X-XSRF-TOKEN等)和JSON格式请求体的参数设置。提供了完整的Python代码示例,展示如何发送请求并解析返回的职位数据(公司名称、职位名称、薪资等)。最后解析了API返回的JSON数据结构层级和核心字段路
猎聘网职位数据爬取实战:逆向 API 接口获取招聘信息
本文以猎聘网(liepin.com)为例,介绍如何通过分析其 API 接口,使用 Python
requests库实现职位数据的批量抓取。
一、背景与思路
猎聘网是国内主流的中高端招聘平台之一。其前端页面在搜索职位时,会向后端发送 POST 请求,返回 JSON 格式的职位数据。
相比直接解析 HTML,直接调用 API 接口具有以下优势:
- 数据结构清晰,无需解析 DOM
- 响应速度快,数据完整
- 分页逻辑简单,易于批量抓取
二、接口分析
通过浏览器开发者工具(F12 → Network → XHR),可以捕获到猎聘搜索职位时的核心请求:
请求地址:
POST https://api-c.liepin.com/api/com.liepin.searchfront4c.pc-search-job
请求类型: application/json(JSON Body)
三、请求头构造
猎聘 API 对请求头有一定校验,需要携带以下关键字段:
head = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) ...',
'X-Client-Type': 'web',
'X-Fscp-Bi-Stat': '{"location": "https://www.liepin.com/zhaopin/..."}',
'X-Fscp-Fe-Version': '',
'X-Fscp-Std-Info': '{"client_id": "40108"}',
'X-Fscp-Trace-Id': '9af06d90-3711-42cf-a47d-63efe33830f8',
'X-Fscp-Version': '1.1',
'X-Requested-With': 'XMLHttpRequest',
'X-XSRF-TOKEN': 'kMRPI54CRpaEIb8Bgwup1A',
}
关键字段说明:
| 字段 | 说明 |
|---|---|
User-Agent |
模拟浏览器身份,避免被识别为爬虫 |
X-Client-Type |
标识客户端类型为 web |
X-Fscp-Bi-Stat |
携带当前搜索页面的 URL 及会话 ID 信息 |
X-Fscp-Std-Info |
客户端 ID,固定值 |
X-Fscp-Trace-Id |
请求追踪 ID,UUID 格式 |
X-XSRF-TOKEN |
CSRF 防护 Token,需从 Cookie 或页面中提取 |
⚠️ 注意:
X-XSRF-TOKEN和X-Fscp-Trace-Id在实际使用中需要动态获取,否则可能导致请求失败。
四、请求体构造
请求体为 JSON 格式,核心结构如下:
data = {
"data": {
"mainSearchPcConditionForm": {
"city": "410", # 城市编码,410 = 郑州
"dq": "410",
"pubTime": "", # 发布时间筛选
"currentPage": page, # 当前页码(从 0 开始)
"pageSize": 40, # 每页数量
"key": "python", # 搜索关键词
"workYearCode": "", # 工作年限
"salaryCode": "", # 薪资范围
"eduLevel": "", # 学历要求
# ... 其他筛选条件
},
"passThroughForm": {
"scene": "input",
"skId": "hwmufbahh4eacxrzevqwbxwfh36ui9d9",
"fkId": "hwmufbahh4eacxrzevqwbxwfh36ui9d9",
"ckId": "ir99pi6z8xxqaekuhh2aay60h8rc9gab"
}
}
}
参数说明:
| 参数 | 类型 | 说明 |
|---|---|---|
city / dq |
string | 城市编码,可在 URL 中获取 |
currentPage |
int | 页码,从 0 开始 |
pageSize |
int | 每页返回数量,最大 40 |
key |
string | 搜索关键词,如 python、Java |
salaryCode |
string | 薪资筛选编码 |
eduLevel |
string | 学历筛选 |
五、完整代码
import requests
# 目标 API 地址
url = 'https://api-c.liepin.com/api/com.liepin.searchfront4c.pc-search-job'
# 请求头
head = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36 Edg/138.0.0.0',
'X-Client-Type': 'web',
'X-Fscp-Bi-Stat': '{"location": "https://www.liepin.com/zhaopin/?city=410&key=python"}',
'X-Fscp-Fe-Version': '',
'X-Fscp-Std-Info': '{"client_id": "40108"}',
'X-Fscp-Trace-Id': '9af06d90-3711-42cf-a47d-63efe33830f8',
'X-Fscp-Version': '1.1',
'X-Requested-With': 'XMLHttpRequest',
'X-XSRF-TOKEN': 'kMRPI54CRpaEIb8Bgwup1A',
}
# 翻页抓取(第 0 ~ 2 页,共 3 页)
for page in range(0, 3):
data = {
"data": {
"mainSearchPcConditionForm": {
"city": "410",
"dq": "410",
"pubTime": "",
"currentPage": page,
"pageSize": 40,
"key": "python",
"suggestTag": "",
"workYearCode": "",
"compId": "",
"compName": "",
"compTag": "",
"industry": "",
"salaryCode": "",
"jobKind": "",
"compScale": "",
"compKind": "",
"compStage": "",
"eduLevel": "",
"salaryLow": "",
"salaryHigh": ""
},
"passThroughForm": {
"scene": "input",
"skId": "hwmufbahh4eacxrzevqwbxwfh36ui9d9",
"fkId": "hwmufbahh4eacxrzevqwbxwfh36ui9d9",
"ckId": "ir99pi6z8xxqaekuhh2aay60h8rc9gab"
}
}
}
# 发送 POST 请求
res = requests.post(url, json=data, headers=head)
# 解析职位列表
job_list = res.json()['data']['data']['jobCardList']
for item in job_list:
comp_name = item['comp']['compName'] # 公司名称
job_title = item['job']['title'] # 职位名称
salary = item['job']['salary'] # 薪资范围
print(comp_name, job_title, salary)
六、响应数据结构解析
API 返回的 JSON 数据层级较深,核心路径为:
res.json()
└── data
└── data
└── jobCardList ← 职位列表数组
├── comp
│ └── compName # 公司名称
└── job
├── title # 职位名称
└── salary # 薪资(如 "15k-25k")
示例输出:
字节跳动 Python后端工程师 25k-40k
阿里巴巴 数据开发工程师 20k-35k
腾讯 后端开发(Python)18k-30k
...
七、代码逻辑流程图
开始
│
├─ 构造请求头 (headers)
│
├─ 循环翻页 page = 0, 1, 2
│ │
│ ├─ 构造请求体 (JSON data),设置 currentPage = page
│ │
│ ├─ POST 请求 → api-c.liepin.com
│ │
│ ├─ 解析响应 JSON
│ │ └── res.json()['data']['data']['jobCardList']
│ │
│ └─ 遍历职位列表,提取并打印:
│ 公司名称 / 职位名称 / 薪资
│
结束
八、注意事项与优化建议
1. Token 动态化
X-XSRF-TOKEN 是 CSRF 防护 Token,实际使用中应从 Cookie 中动态提取,避免 Token 过期导致请求失败:
session = requests.Session()
session.get('https://www.liepin.com') # 先访问主页获取 Cookie
xsrf_token = session.cookies.get('XSRF-TOKEN')
head['X-XSRF-TOKEN'] = xsrf_token
2. 添加请求间隔
频繁请求容易触发反爬机制,建议加入随机延时:
import time, random
time.sleep(random.uniform(1, 3))
3. 异常处理
网络请求应加入异常捕获:
try:
res = requests.post(url, json=data, headers=head, timeout=10)
res.raise_for_status()
except requests.RequestException as e:
print(f"请求失败: {e}")
continue
4. 数据持久化
当前代码仅打印数据,实际项目中建议写入数据库或 CSV:
import csv
with open('liepin_jobs.csv', 'a', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow([comp_name, job_title, salary])
九、结果展示
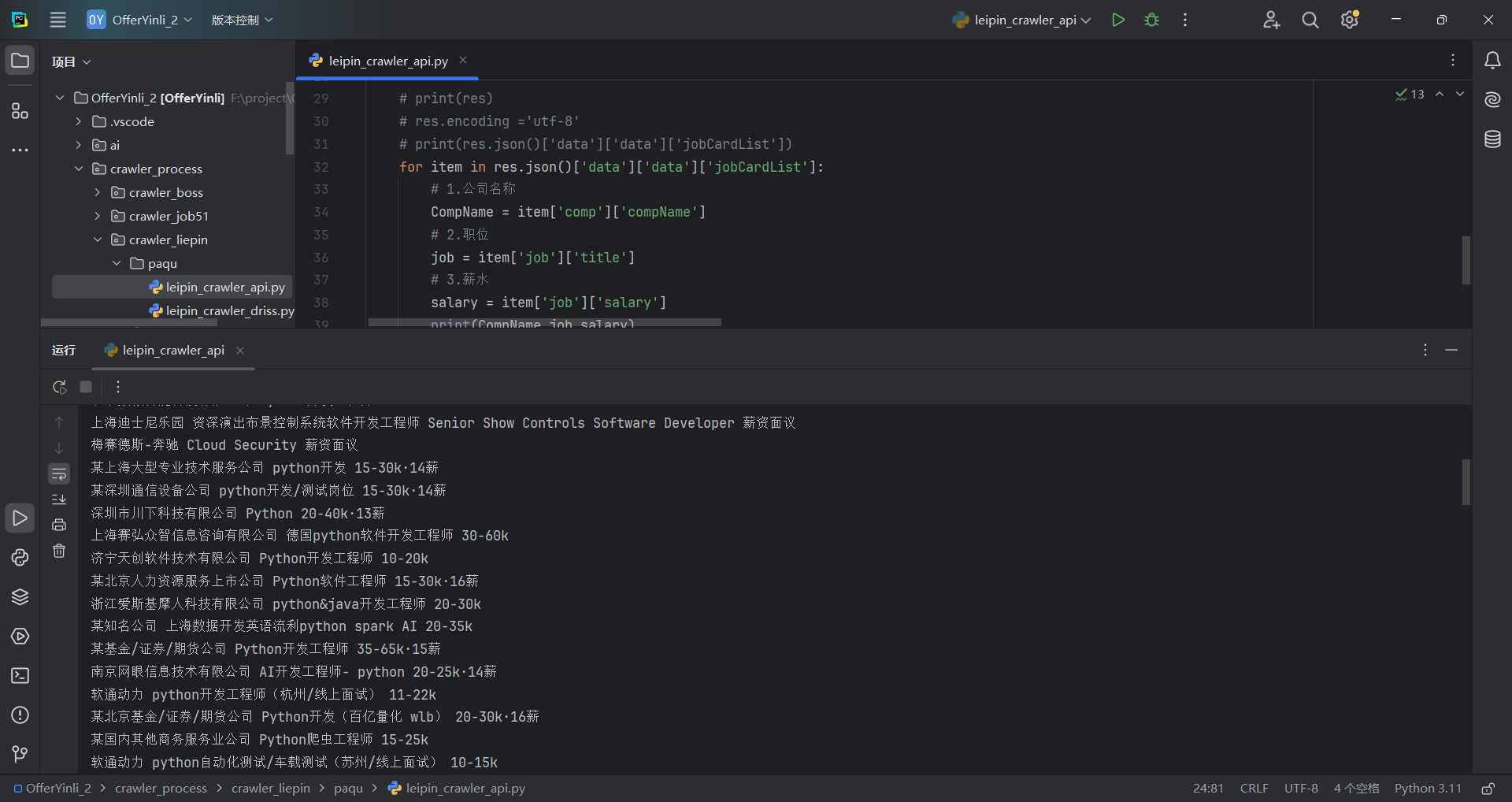
十、总结
本文通过逆向分析猎聘网的搜索 API,实现了职位数据的批量抓取。核心要点:
- 猎聘使用 POST + JSON Body 的方式传递搜索参数
- 分页通过
currentPage字段控制,从 0 开始计数 - 响应数据在
data.data.jobCardList路径下 - 实际部署时需关注 Token 动态获取 和 反爬策略
免责声明:
本文所有内容仅供学习与技术交流,不构成任何商业用途建议。
- 本文涉及的爬虫技术仅用于演示 HTTP 请求原理与数据解析方法,请勿将相关代码用于任何违反目标网站服务条款、用户协议或相关法律法规的行为。
- 在使用爬虫程序前,请务必查阅目标网站的
robots.txt文件,并严格遵守其规定。- 大规模、高频次的数据抓取可能对目标服务器造成压力,请控制请求频率,避免影响网站正常运营。
- 所抓取的数据涉及企业及个人信息,请勿传播、出售或用于任何侵犯他人隐私及知识产权的用途。
- 因使用本文代码所产生的任何法律责任,由使用者自行承担,作者不负任何连带责任。
请在合法、合规的前提下学习和使用相关技术。
如有问题欢迎评论区交流 👇

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)