超越 RAG 的下一步:KAG(知识增强生成)架构解析
RAG 解决了大模型“不知道”的问题,而 KAG 正在解决“不可靠、不可控”的难题。随着知识自动化构建技术的成熟与图推理引擎的轻量化,KAG 将成为企业级 AI 从“演示原型”走向“生产系统”的关键基础设施。思考题:在你的业务场景中,哪些环节最需要“可追溯的推理”而非“流畅的生成”?欢迎在评论区交流架构选型心得。注:本文基于 Ant Group 开源 KAG 框架及行业实践总结。实际落地需结合具体
超越 RAG 的下一步:KAG(知识增强生成)架构解析
从“碎片检索”到“结构化推理”,企业级 AI 应用的可靠性跃迁
引言:当 RAG 撞上复杂业务天花板
过去两年,RAG(检索增强生成)凭借低成本、易部署的优势,成为大模型落地的标配。但在金融尽调、医疗指南、工业运维等场景中,RAG 的短板日益凸显:
- 多跳推理断裂:语义相似度无法替代实体间的逻辑关联
- 事实一致性弱:文档切片拼接易导致幻觉或上下文冲突
- 合规不可审计:生成过程缺乏可追溯的证据链与规则约束
面对“高准确、强逻辑、可审计”的企业级需求,KAG(Knowledge Augmented Generation,知识增强生成) 应运而生。它不是 RAG 的简单叠加,而是一次从“检索-拼接”到“图谱-推理-约束”的架构演进。
KAG 的核心设计哲学
KAG 的本质是 用结构化知识引导大模型生成。其工作流可抽象为三个关键阶段:
- 知识结构化:将非结构化文档转化为实体、关系、属性与业务规则,构建领域知识图谱
- 图增强检索:融合向量语义检索与图数据库查询,精准定位多跳路径与关联子图
- 约束化生成:将图谱逻辑与业务规则注入 Prompt 或解码过程,确保输出符合事实边界
与传统 RAG 相比,KAG 将“知识”从被动的检索素材,升级为主动的推理引擎。
KAG vs RAG:关键能力对比
| 维度 | 传统 RAG | KAG(知识增强生成) |
|---|---|---|
| 检索单元 | 文本块 / 向量切片 | 实体、关系、规则、子图 |
| 推理机制 | 语义相似 + LLM 自由生成 | 图遍历 + 逻辑约束 + 路径校验 |
| 事实一致性 | 依赖模型自我纠错,易漂移 | 图谱硬约束 + 可追溯证据链 |
| 典型场景 | 单轮问答、文档摘要、FAQ | 多跳推理、合规审查、复杂决策 |
| 维护成本 | 低(定期更新向量库) | 中高(需图谱构建/对齐/更新流水线) |
核心架构拆解:KAG 如何工作?
一个成熟的 KAG 系统通常包含以下核心模块:
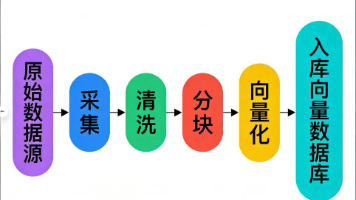
🔹 1. 自动化知识构建流水线
通过 LLM 进行实体/关系抽取,结合规则引擎进行消歧与校验,支持增量更新。无需完全依赖人工标注,但需领域专家定义核心本体(Ontology)以控制噪声。
🔹 2. 混合检索策略(Hybrid Retrieval)
Query → 向量召回(粗筛) → 图查询精排(Cypher/Gremlin) → 路径融合
图检索能精准捕捉“公司A-持股-公司B-受监管-条款C”这类多跳关系,有效避免向量空间的语义模糊与噪声干扰。
🔹 3. 逻辑约束与事实校验
KAG 在生成阶段引入“规则过滤”与“子图对齐”机制。模型输出前,系统会校验:
- 是否违反业务硬约束(如合规红线、阈值限制)
- 引用路径是否与图谱事实一致
- 置信度是否达标(低于阈值则触发降级回答或人工复核)
落地建议:何时该用 KAG?
KAG 不是银弹,选型需遵循 场景匹配原则:
- ✅ 优先 KAG:强规则领域、多跳关联查询、审计/合规要求高、知识边界清晰
- ✅ 继续 RAG:轻量级问答、内容摘要、知识冷启动期、预算/人力有限
- 💡 混合架构:RAG 处理泛化检索,KAG 接管核心推理链路,通过路由层动态切换
避坑指南
- 冷启动成本:图谱构建需明确本体设计,建议从“高频核心知识”切入,逐步扩展
- 更新延迟:动态业务需设计流式对齐机制,避免“图谱过时”导致推理失效
- 延迟控制:图遍历与校验会增加 P99 耗时,建议通过子图缓存、异步预计算优化
结语
RAG 解决了大模型“不知道”的问题,而 KAG 正在解决“不可靠、不可控”的难题。随着知识自动化构建技术的成熟与图推理引擎的轻量化,KAG 将成为企业级 AI 从“演示原型”走向“生产系统”的关键基础设施。
思考题:在你的业务场景中,哪些环节最需要“可追溯的推理”而非“流畅的生成”?欢迎在评论区交流架构选型心得。
注:本文基于 Ant Group 开源 KAG 框架及行业实践总结。实际落地需结合具体业务数据与工程环境进行验证。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)