RAG离线数据不分类直接解析,面试回去等通知吧!RAG离线数据采集需要注意的哪些坑-数据采集
上篇我们已经学会搭建Rag需要使用的框架、向量库、本地或远程大模型、Embedding模型等。那么本篇,我们开始第一大模块:“离线数据采集”这块的详细学习了。
上篇我们已经学会搭建Rag需要使用的框架、向量库、本地或远程大模型、Embedding模型等。那么本篇,我们开始第一大模块:“离线数据采集”这块的详细学习了。
为什么要离线采集
先搞清楚一件事:RAG(检索增强生成)的效果,80%取决于你喂给它的数据质量。
GPT-5 再强,你扔一堆脏数据进去,它也给你输出垃圾。所以:
-
向量数据库
是用来快速从海量文档里「捞」出最相关的几条,给 LLM 做上下文补充
-
离线数据采集
是把散落在各处的原始数据,洗净、切块、编码,存进向量库
整个链路大概是这样:
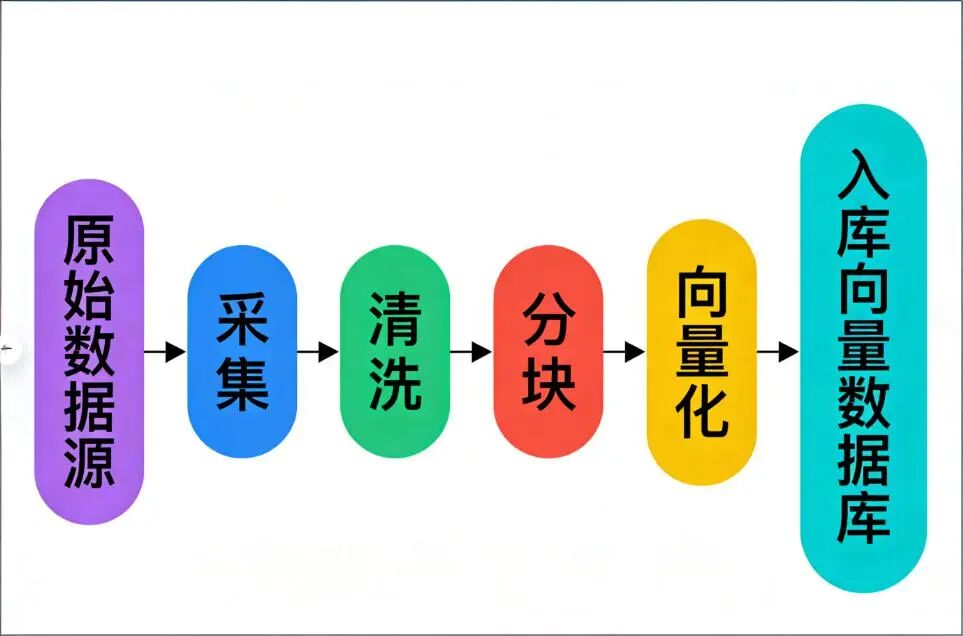
接下来我们就按这个流程,一个环节一个环节讲。
准备工作:创建向量库
我们先把离线向量库初始化,存到本地项目中。后续我们都是用这套库表。
- 向量数据库是什么?
简单地做一下科普。
传统数据库存的是「一行行结构化的数据」,查询靠的是精确匹配(WHERE id = 1)。
向量数据库存的是「向量」——也就是一串浮点数。查询靠的是「相似度」,找出和你问的问题在向量空间里最接近的文档。
类比一下 MySQL,更好理解:
| MySQL | Chroma | 说明 |
|---|---|---|
| Database(数据库) | Database | 同一个客户端下的数据集合 |
| Table(表) | Collection(集合) | 一组向量的容器 |
| Row(行) | 一条 Record | 包含 id + vector + metadata + document |
| Column(字段) | id / embedding / metadata / document | 各字段含义见下 |
核心思路:无论什么数据源,最后都转成 Document(text, metadata),统一后续处理。
数据采集
1)字符格式如何采集
假设你有一段文本,想存进向量库,最少需要几行代码?
和mysql等连接是否都很相似。连接数据库–>使用指定表–>注册信息到llamaindex–>文字转Document–> 入库。
当然后续批量入库的时候,前2步是一次初始化的,后面就是循环来入库了。
当然这样入库很暴力啦,读多少内容入库多少。对应的txt等文本格式,可以使用read操作进行入库。
值得注意的一点是注意文件大小,小心OOM。遇见大文档,记得分页或者按大小读取。
import chromadbfrom llama_index.core import Document, StorageContext, VectorStoreIndexfrom llama_index.vector_stores.chroma import ChromaVectorStore# ======================# 1. 连接你已有的 Chroma 库(持久化)# ======================chroma_client = chromadb.PersistentClient(path="./chroma_db") # 你的数据库路径collection = chroma_client.get_collection("knowledge_base") # 你已建好的表# ======================# 2. 对接 LlamaIndex# ======================vector_store = ChromaVectorStore(chroma_collection=collection)storage_context = StorageContext.from_defaults(vector_store=vector_store)# ======================# 3. 要入库的文本# ======================text = "RAG的核心是把检索和生成结合起来,提高回答质量"doc = Document(text=text)# ======================# 4. 写入向量库(自动向量化 + 入库)# ======================index = VectorStoreIndex.from_documents( [doc], storage_context=storage_context, show_progress=True)print("✅ 文本已成功入库 Chroma (knowledge_base)")
2)数据库格式
场景:你的数据在 MySQL / MongoDB 里,想把它灌进向量库。问题是数据库里是一条条的 Row,如何转换呢?
问题:
- 多张表的字段要聚合到一个文档里吗?不 JOIN 直接存,每条 Document 只有孤立字段,查不出关联关系。全量 JOIN 后存,Document 文本太长,分块困难,向量化效果差?分开存多个 Document:关联关系怎么表达?
- 文本太长怎么办?数据库字段是 TEXT / JSON,存几百KB 咋处理,比如存了用户合同?
- 数据库每天新增几百条记录,每次全量同步太慢,直接新增会重复入库。增量怎么追?新增一条、修改一条、删除一条分别怎么处理?
解决方案:
-
在 SQL 层面先 JOIN 成宽表,把关联字段(用户名、商品名)作为 metadata 存入,正文只放最核心的检索信息,不要把所有字段都塞进去。总结:合并多表数据,精简字段,只要核心字段。
-
长文本拆分,每块设定字符上限(如 1000 字符),块之间加 overlap(如 100 字符),保证块边界的内容不丢失。最后每块生成一个 Document,带上块序号和总数。总结:给同一条记录给出分页信息。
-
记录同步时间戳,每次只查大于时间戳的记录(覆盖新增和更新)。采用 Upsert 语义处理:先按 ID 删掉旧数据,再写入新数据。这样新增的数据能加进来,变了的数据能更新,删掉的数据在下次同步时自然消失。总结:按照时间或ID等标识性字段,进行增量标记,然后插入或更新。
极简代码演示
# MySQL → Document 转换示例import pymysqldef fetch_mysql_as_docs(db_config, table_name, id_field="id"): """ 把 MySQL 表转成 Document 列表 """ conn = pymysql.connect(db_config) cursor = conn.cursor(pymysql.cursors.DictCursor) cursor.execute(f"SELECT * FROM {table_name}") rows = cursor.fetchall() docs = [] for row in rows: # 把每行转成一个 Document # 把所有字段拼接成文本,关键位置,其实就是把记录拼接起来,和文档区别不大 #需要注意如果字符串过大需要分块 text_content = "/n".join([ f"{k}: {v}" for k, v in row.items() if v is not None ]) doc = Document( text=text_content, metadata={ "source": "mysql", "table": table_name, "id": row[id_field], "created_at": str(row.get("created_at", "")), } ) docs.append(doc) conn.close() return docs
3)网页数据怎么解析
场景:从网上爬了一堆文章,HTML 标签、广告、侧边栏全混在正文里,直接存进去检索效果很差。
问题:
解决方案:
- 语义标签优先 + 正文密度算法。
建立噪音标签识别规则,通过 class 和 id 判断常见噪音类型(nav、sidebar、ad、footer 等)。正文提取优先找语义化标签(<article>、<main>),找不到时用正文密度算法——遍历 div,计算每个区域的文本字数与链接数量的比值,比值越高的越可能是正文。
总结:先清洗噪音标签,再寻找核心文本。
正文密度算法: 遍历所有 div,计算每个 div 里的文本字数 / 链接数量的比值 比值越高的,越可能是正文区域
- 分步骤处理:先用 HTML 解码器把所有实体字符转成正常字符,再统一空白字符处理规则(Tab 和多余空格转普通空格,全角空格处理,不间断空格
/xa0替换),最后去掉行首行尾空格和多余的空行段落。总结:转换成正常HTML页面,然后去除无效字符。 - 为每个网站定义专属解析规则,包含站点名称、URL 匹配模式、正文标签选择器、噪音选择器、编码格式。根据 URL 自动匹配对应规则,找不到则用通用规则兜底。(经典策略模式) 。总结:单独定制,使用策略模式。
以下是极简操作代码
from bs4 import BeautifulSoupdef extract_main_content(html_path): with open(html_path, "r", encoding="utf-8") as f:#HTMLTagReader 对中文网页支持一般,实战更推荐自定义清洗: soup = BeautifulSoup(f.read(), "html.parser") # 去掉 script、style、nav、aside 等噪音 for tag in soup.find_all(["script", "style", "nav", "aside", "footer", "header"]): tag.decompose() # 优先找 <main> 或 <article>,没有就用 body content = soup.find("main") or soup.find("article") or soup.body # 转纯文本 text = content.get_text(separator="/n", strip=True) # 清理多余空行 import re text = re.sub(r"/n{3,}", "/n/n", text) return text
4)代码文件怎么解析
场景:你要做一个代码助手,把 Git 仓库里的代码存进向量库,方便后续问「这个函数是干什么的」。
问题:
- 注释和代码混在一起,全存进去检索太噪音?
- 代码跨文件引用,怎么还原上下文?
- 不同语言语法不同,要分语言处理吗?
解决方案:
-
代码文件的结构是线性的,没有段落概念。直接把整个文件存进去,检索粒度太粗。用 AST(抽象语法树)解析代码文件,按函数和类提取 docstring 和代码片段,把两者拼在一起存为一个 Document。这样既能保留函数的说明文档,又能关联对应代码。同时用文件名和语言类型作为 metadata 方便过滤。 总结:按类或函数提取:代码+注释片段。
-
分层存储 + 元数据关联。问「函数怎么用」→ 召回函数级 Document;问「文件结构」→ 召回文件级 Document;问「调用链」→ 先召回函数 Document,再通过 metadata 里的 called_by 字段追溯调用方同时,import 语句本身也可以单独提取成一个 Document,标注它来自哪个模块,检索时能回答「这个项目用了哪些依赖」。
总结:按照函数、文件、拆分并使用metadata记录关联关系。
第一层:函数级 Document └─ 每个函数一个 Document └─ metadata 里记录:file_path、imports(导入了哪些)、called_by(被谁调用)第二层:文件级 Document └─ 整个文件一个 Document,汇总文件内所有函数的摘要 └─ 适合问「这个文件是干什么的」
- 按扩展名按照不同的解析器。对于不能使用ast解析器的语言,使用正则降级处理。
.py → Python AST(ast 模块,标准库自带).js → JavaScript(esprima 或 babel-parser).ts → TypeScript(同上,加类型解析).go → Go(gopls 或 go/parser).java → Java(JavaParser)
极简代码演示
# 方法一:存代码 + 注释(保留上下文)import astdef extract_code_with_docstrings(file_path): """提取函数和类的 docstring,配合代码一起存储""" with open(file_path, "r", encoding="utf-8") as f: source = f.read() tree = ast.parse(source) docs = [] for node in ast.walk(tree): if isinstance(node, (ast.FunctionDef, ast.AsyncFunctionDef, ast.ClassDef)): docstring = ast.get_docstring(node) or "" code_segment = ast.get_source_segment(source, node) # 把 docstring + 代码片段拼一起 text = f"{docstring}/n/n{code_segment}" docs.append(Document( text=text, metadata={ "source": "code", "file": str(file_path), "func_name": node.name, "lang": "python" } )) return docs# 使用func_docs = extract_code_and_comments("./src/utils.py")# 方法二:纯代码存索引,注释单独存检索# 适合只关心"这个函数是干嘛的"的场景# 注释转成独立的 Document,关联到原文件
5)PDF文件怎么解析?
场景:公司内部很多都是转成PDF文件,如果都是文字都还好,但是如果碰到表格分页、图片该如何处理呢?
解决方案:
整体遵循一个先解析,不行降级到VLM模型,再不行人工审核的思路。
当然还有方式就是重构PDF文档(估计甲方爸爸都不乐意)
- PDF 本身没有「表格」这个概念,只是一堆文字和坐标信息,表格是人为识别出来的,分页后自然断开。
先按页读取并记录每页页码,然后检测相邻两页的列数是否相同来判断是否属于同一个跨页表格,最后让后一页沿用前一页的表头。
如果还不行就是用VLM(多模态模型识别)。
总结:先按照表格格式精确判断,根据识别率降级到VLM识别。
-
PDF 内部没有 “单元格”,只有线条 + 文字位置,合并格极易解析错乱。部分util(工具类)比如pdfplumber支持读取合并单元格属性。
遇到空值 → 复制上方 / 左方内容、遇到 “总计”“小计” → 标记为合并行、用 None 标记 合并单元格的空位,输出Markdown 表格,保留表格结构信息(逻辑有点复杂)
-
采用OCR识别,比如pytesseract(轻量)、EasyOCR(中文强)、PaddleOCR(最准)。PDF 图片 → 提取图片 → OCR → 得到文本 → 加入 chunk。
-
这种图用OCR识别估计也跪。
一般建议采用VLM(多模态模型)看图理解 +生成结构化数据,配上严格提示词。架构图的价值不是文字,是结构关系。OCR 只能提取字,VLM 能提取知识。当然你会发现,不同行业可能图不一样。所以这块又得给自己pdf解析不停的打各种解析插件了。
当然在做这种图片的意图识别也挺难,正常我们可能通过关键字,比如架构图、拓扑图等识别,同时可能文字混乱,不成句等判断是否上VLM模型。
本章总结
| 数据类型 | 解析方案 |
|---|---|
| 文本文件 (.txt, .md) | 直接读取,注意编码 |
| 按页读取 + 跨页表格合并 + OCR 识别图片文字 | |
| Word (.docx) | 专用解析器 |
| HTML | 语义标签优先 + 正文密度算法 + HTML 实体清理 |
| MySQL / MongoDB | SQL 查询后转 Document,注意超长文本分块和增量同步 |
| 代码文件 | AST 解析提取函数 + docstring,保留上下文 |
综上所述,我们已经介绍了大概5种常见的在原始数据采集方面可能会遇到的问题,在面试上如果细究的话,可能会考察的这些细节点。
本章节主要从一些常见问题入手,大概分析了数据解析需要注意的问题,下一章节我们聊聊数据清洗。
整体再概括一下数据抽取注意的问题。
架构方面:采取工厂+策略模式,制作可定制插拔的解析组件。
流程方面:先精确工具解析—>VLM降级识别—>人工兜底审核或标注(对于医疗、金融、律师、财务等行业:宁可少采,不可采错)
监控方面:监控每层的识别率、错误率。对于VLM模型还要做自带评分,防止自由发挥。
不要指望一个工具解决所有问题,设计好几层兜底机制,并在每层设置质量检查点,不达标就自动降级,才是稳定可用的采集系统。
其实,我们可以看出来一个简单逻辑,任何一个复杂的系统都是由于各种不规范、没有统一约定而产生的,而对于我们RAG为了兼容这些,就会变得越来越复杂(谁叫这个世界是个多元的世界呢),也因为此,程序员的价值也就在这,把纷杂变得统一。
这里给大家精心整理了一份全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!
👇👇扫码免费领取全部内容👇👇
1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。
2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2026行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

7. 资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 1
1 0
0- 0



 已为社区贡献696条内容
已为社区贡献696条内容

所有评论(0)