Gemini、ChatGPT、Claude、Grok四大模型关键能力横向评测:选型依据与场景适配指南
2026年的大模型选型,核心逻辑已经从“找最强的模型”转变为“找最适合的模型”。本文以聚合站点 solo.kulaai.cn 为测试入口,在同一网络环境、同一对话界面下,对上述四款模型的关键能力维度进行横向评测,重点分析各模型的能力边界与适用场景,所有测试数据基于2026年4月的实测结果。对于以下需求场景,聚合方案具有较高的参考价值:日常工作中需要同时调用多个AI模型的开发者、希望在统一环境下对比
2026年的大模型领域已形成多个技术方向并行发展的格局,模型之间的差异化定位日益清晰。根据第三方评测机构LMArena的综合排名数据,Gemini 3.1 Pro、GPT-5.4、Claude Opus 4.6与Grok 4.2四款模型占据当前AI对话能力的第一梯队,彼此之间在Elo评分上的差距已缩小至个位数。这意味着单纯比较“谁更强”已没有太大意义——选型的关键不在于模型本身,而在于任务特征与模型能力的匹配度。
本文以聚合站点 solo.kulaai.cn 为测试入口,在同一网络环境、同一对话界面下,对上述四款模型的关键能力维度进行横向评测,重点分析各模型的能力边界与适用场景,所有测试数据基于2026年4月的实测结果。
一、模型基础参数对比
在进行具体能力评测之前,先梳理四款模型的基本技术指标: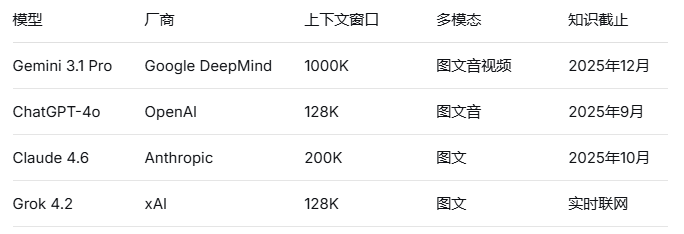
从基础参数来看,上下文窗口是四者之间差距最大的维度。Gemini的1000K窗口意味着可以一次性处理约75万英文单词的内容,约等于整部《红楼梦》的字数。这一参数差异在实际使用中对长文档处理能力产生了直接影响,下文将详细展开。
二、关键能力维度横向评测
以下选取四个对日常技术工作影响最大的能力维度,对四款模型进行同题实测。
维度一:长文档处理能力
任务:上传一份约120页的嵌入式开发手册PDF(约18万字),要求模型提取各章节的核心要点并标注原文页码。
Gemini表现:完整加载全部120页内容,约8秒后开始输出。摘要按照手册的目录结构逐章组织,每个要点均标注了原文页码,信息覆盖率接近完整。在处理跨章节的信息关联时,Gemini能自动将分散在不同位置的相关内容整合为统一观点。
Claude表现:受200K上下文限制,一次性上传120页文档超出其处理能力上限。实测需分两次上传,两次分析结果之间存在少量信息重复,需要人工合并。在细节捕捉方面表现优秀,对技术参数、版本号、限定条件等细微信息的识别精度较高。
ChatGPT表现:128K上下文窗口限制使其无法一次性处理该文档,需要拆分为三次分别上传。拆分后的摘要质量尚可,但跨片段的信息关联出现断层,部分章节之间的逻辑关系需要人工补全。
Grok表现:同样受限于128K窗口,需要拆分处理。在文档分析方面,Grok更倾向于给出高度概括的要点列表而非详细的结构化摘要,适合快速浏览而非深度研读。
维度小结:对于超过200K的超长文档,Gemini的1000K窗口具有显著优势,一次加载即可完成全文档分析;Claude在200K以内的文档分析中细节捕捉最为到位;ChatGPT和Grok受上下文限制,更适合处理中短篇幅的文档。
维度二:代码生成与调试
任务:编写一个Python异步爬虫程序,从指定API接口获取分页数据,包含请求重试、并发控制、数据去重和异常处理机制。
Claude表现:代码健壮性最优。异步队列管理、信号量限流、指数退避重试等机制均正确实现,边界条件处理到位。注释详尽,变量命名规范,代码结构清晰易维护。在处理复杂并发逻辑时,Claude对潜在竞态条件的考虑更为周全。
Gemini表现:代码生成速度最快,约2秒完成全部输出。asyncio和aiohttp的标准用法掌握熟练,代码执行效率较高。在错误处理分支的覆盖面上略少于Claude,但核心逻辑完整可运行。
ChatGPT表现:方案多样性最好,在基础实现之外主动提供了使用httpx替代aiohttp的备选方案。对于初学者而言,这种多方案对比具有参考价值。但代码注释的详细程度略逊于Claude。
Grok表现:在快速查询特定语法和库函数用法方面表现出色,比如“aiohttp的ClientTimeout如何设置”这类具体问题能得到准确回答。但在编写完整项目级代码时,代码的组织结构和健壮性不如前三者。
维度小结:对于需要长期维护的生产级代码,Claude的健壮性和注释质量更具优势;Gemini在迭代速度和效率上领先;ChatGPT适合多方案探索和原型验证;Grok更适合作为代码查询的辅助工具。
维度三:中文语义理解与生成
任务:撰写一份面向非技术人员的“AI辅助开发工具”产品介绍文案,要求语言通俗易懂,避免技术术语堆砌。
ChatGPT表现:中文输出流畅度最高,语句自然不生硬。能准确理解“避免术语堆砌”的要求,将“上下文窗口”“多模态”等技术概念转化为“一次性读完整本书”“既能看懂文字也能识别图片”等通俗表述。整体文风温和,适合大众传播。
Claude表现:用词精准,句子结构完整,在专业性与通俗性之间取得了较好平衡。文案的逻辑层次清晰,从“问题”到“方案”再到“效果”的叙事结构完整。在涉及技术细节时,Claude倾向于保留必要的专业词汇但会附上通俗解释。
Gemini表现:语言规范但稍显平实,更偏向事实陈述而非情感表达。在技术描述的准确性上表现良好,但在语言的表现力和感染力方面略逊于ChatGPT。
Grok表现:风格最为鲜明,适合需要幽默感或个性化表达的场景。但在正式文案写作中,其风格可能不够“稳妥”,需要人工删减和调整。
维度小结:ChatGPT在中文文案写作的综合表现最为均衡;Claude适合专业性较强的技术文档;Gemini适合对准确性要求高于表现力的场景;Grok适合轻松非正式的内容。
维度四:逻辑推理与问题拆解
任务:分析一个技术选型问题——“对于一个用户量约50万的中型电商平台,选择单体架构还是微服务架构?请给出分析框架和判断依据。”
Claude表现:逻辑链条最为完整。先拆解问题中的关键变量(用户量、业务复杂度、团队规模、未来增长预期),逐一分析每个变量对架构选择的影响权重,再综合各维度给出判断。整个推导过程可追溯,读者可以清楚看到结论是如何得出的。
ChatGPT表现:回答最为全面,从架构演进历史、主流实践案例、团队能力匹配、成本收益分析四个维度展开。分析框架清晰,适合作为决策参考文档的素材。
Gemini表现:偏重信息汇总,将单体架构和微服务架构的优缺点以结构化方式呈现,信息来源标注较为规范。但在给出明确判断建议方面相对保守,更多是“供参考”而非“推荐”。
Grok表现:推理风格直接,不绕弯子。回答明确给出“50万用户量、中等复杂度场景,推荐单体架构先行,预留微服务演进空间”的判断,并附有三条简明扼要的判断标准。适合需要快速决策的场景。
维度小结:Claude在需要完整推理过程的复杂问题分析中表现最优;ChatGPT适合多维度参考和文档素材整理;Gemini适合信息汇总和结构化呈现;Grok适合快速决策和明确判断。
三、综合能力雷达图
基于以上四个维度的评测结果,以5分为满分,各模型的能力得分如下:
长文档处理:Gemini 5,Claude 4,ChatGPT 3,Grok 3
代码生成:Claude 5,Gemini 4,ChatGPT 4,Grok 3
中文表达:ChatGPT 5,Claude 4,Gemini 3,Grok 3
逻辑推理:Claude 5,ChatGPT 4,Gemini 4,Grok 4
四个维度没有哪一个模型在所有方面都领先——这正是聚合方案存在的价值:让开发者可以根据具体任务特征,灵活选择最适合的模型,而非被锁定在单一生态中。
四、场景化选型建议
基于上述评测结果,针对不同工作场景的模型选择建议如下:
技术文档与长文处理:首选Gemini。对于PDF手册、技术白皮书、学术论文等超过200K的超长文档,Gemini的1000K上下文窗口是决定性优势。如果文档长度在200K以内,Claude的细节捕捉能力更值得考虑。
生产级代码开发:首选Claude。Claude在代码健壮性、注释质量和边界条件处理上的表现,使其更适合需要长期维护的生产代码场景。对于快速原型验证,Gemini的速度优势更突出;对于多方案探索,ChatGPT更具参考价值。
技术文案与方案撰写:首选ChatGPT。中文输出的流畅度和自然度使其在技术博客、产品介绍、方案文档等场景中表现最佳。如果对专业术语的准确性有更高要求,Claude是更好的选择。
复杂问题分析与决策:首选Claude。逻辑推导的完整性和可追溯性使其在技术选型、架构设计等需要深度思考的场景中具有优势。如果只需要快速获取明确判断,Grok的直接风格可能更有效率。
实时信息查询与热点追踪:首选Grok。内置的实时知识检索能力使其在查询最新技术动态、API版本更新、开源项目进展等方面具有不可替代的价值。
五、聚合方案的适用边界
聚合方案在多模型切换场景下解决了几个实际问题:统一的对话界面消除了不同平台之间的操作差异;国内节点优化后,海外模型的访问体验与国内服务基本持平;一次登录即可在多个模型间切换,省去了多账号管理的麻烦。
同时也存在一些需要如实说明的局限:
跨模型上下文不互通:在模型A中进行的多轮对话切换到模型B后无法自动继承历史。这一限制源于各模型API接口的无状态设计,属于行业通用问题,非单一平台所能解决。
部分模型版本差异:聚合平台接入的模型版本可能与官方最新版存在滞后,建议在使用前核对平台标注的模型版本号是否满足需求。
免费额度有限:聚合方案通常提供免费体验额度,但高频使用场景可能需要付费。长期使用前建议评估成本与收益。
六、总结
2026年的大模型选型,核心逻辑已经从“找最强的模型”转变为“找最适合的模型”。不同模型在长文档处理、代码生成、中文表达、逻辑推理等维度上各有专长,单一模型很难在所有场景中都表现最优。聚合方案的意义不在于“替代”任何一家官方服务,而在于为多模型协同使用提供一个更便捷的入口。
对于以下需求场景,聚合方案具有较高的参考价值:日常工作中需要同时调用多个AI模型的开发者、希望在统一环境下对比不同模型输出质量的技术人员、因网络环境受限而难以直接访问海外模型的国内用户。
对于仅使用单一模型或对数据安全有严格合规要求的使用场景,直接使用官方API或自建网关可能更为合适。最终如何选择,取决于具体工作场景和需求优先级。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)