【论文笔记】GaussianPretrain: A Simple Unified 3D Gaussian Representation for Visual Pre-training in Auton
【论文笔记】GaussianPretrain: A Simple Unified 3D Gaussian Representation for Visual Pre-training in Autonomous Driving
GaussianPretrain: A Simple Unified 3D Gaussian Representation for Visual Pre-training in Autonomous Driving
原文链接:https://arxiv.org/pdf/2411.12452
简介:自动驾驶中,现有的自监督图像处理方法关注几何信息,而忽视纹理或与纹理分开对待,阻碍了场景的全面理解。本文提出GaussianPretrain,将场景的几何和纹理表达整合起来实现对场景的完整理解。本文方法将3D高斯锚点定义为体积激光雷达点,能加深对场景的理解,并提高几何和纹理的预训练性能。相比于NeRF方法,本文的速度和GPU存储消耗均更低;在多个下游任务上的实验均表明,GaussianPretrain能提高性能。
1. 引言
3D高斯溅射(3D GS)将场景表达为点云,通过位置、色彩、旋转、尺度和不透明度等属性,编码了几何和纹理信息。相比NeRF,3D GS能更快地在训练中收敛,且存储消耗低。
本文将3D GS与MAE结合,提出预训练方法GaussianPretrain,用于3D视觉学习。方法的关键创新有二:(i)激光雷达深度指导的掩膜生成器。为提高效率,本文仅在多视图图像有限的有效掩膜区域学习高斯。这些掩膜区域被MAE确定,且只保留其中有激光雷达深度监督的部分。(ii)基于射线的3D高斯锚指导策略:对于每个有激光雷达点投影的像素,射线投射操作会在体素中采样点。本文引入可学习高斯锚,指导从3D体素学习高斯属性。这样模型可以同时学习几何和纹理信息。最后,通过解码高斯参数,可在有效掩膜区域内重建RGB、深度和占用属性。
3. 准备知识
3.1 3D高斯溅射
高斯被定义为
G ( x ) = e − 1 2 ( x − μ ) T Σ − 1 ( x − μ ) G(x)=e^{-\frac12(x-\mu)^T\Sigma^{-1}(x-\mu)} G(x)=e−21(x−μ)TΣ−1(x−μ)
其中 μ \mu μ和 Σ \Sigma Σ分别为均值和协方差矩阵。投影到2D的协方差矩阵为 Σ ′ = J W Σ W T J T \Sigma'=JW\Sigma W^TJ^T Σ′=JWΣWTJT,其中 W W W表示视角变换,雅可比矩阵 J J J为变换的线性近似。像素颜色可通过 N N N个排序的高斯、使用混合方程渲染:
C ( p ) = ∑ i = 1 N c i α i τ C(p)=\sum_{i=1}^Nc_i\alpha_i\tau C(p)=i=1∑Nciαiτ
其中 c i c_i ci为球面谐波表示的高斯颜色, α i \alpha_i αi为不透明度的影响, τ = ∏ j = 1 i − 1 ( 1 − α j ) \tau=\prod_{j=1}^{i-1}(1-\alpha_j) τ=∏j=1i−1(1−αj)为透明度。
4. 方法
如图所示,给定带有效掩膜区域的多视图图像,目的是通过解码高斯参数 { ( μ j , α j , Σ j , c j ) } j = 1 K \{(\mu_j,\alpha_j,\Sigma_j,c_j)\}_{j=1}^K {(μj,αj,Σj,cj)}j=1K重建RGB、深度和占用,其中 K K K为高斯锚的最大数量。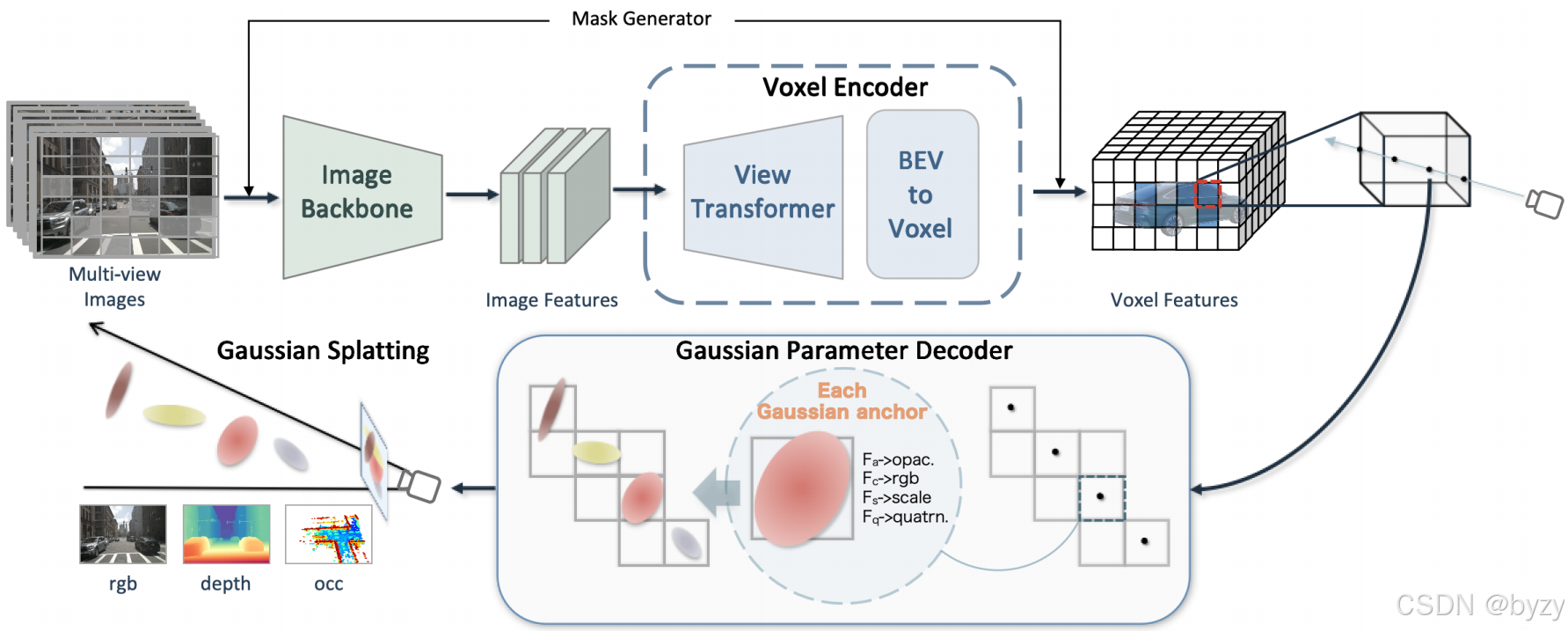
4.1 激光雷达深度指导的掩膜生成器
本文使用随机区块掩膜 M M M,并在图像主干中使用稀疏卷积替代传统卷积。为提高效率,本文仅在有效掩膜区域的子集内学习高斯参数。
如图所示,通过检查掩膜区域 M i M_i Mi中是否存在深度在范围 [ a , b ] [a,b] [a,b]内的激光雷达点来判断有效性:
M i = 1 ′ n = 有效 , 若 P r o j ( S e t ( p c ) ) ∈ { [ a , b ] , M } M'^n_{i=1}=有效, 若Proj(Set(pc))\in\{[a,b],M\} Mi=1′n=有效,若Proj(Set(pc))∈{[a,b],M}
其中 n ≤ m n\leq m n≤m为有效掩膜区块的数量。该策略能保证模型关注前景。
4.2 基于射线指导的3D高斯锚
为保证模型同时理解几何与纹理,本文引入可学习高斯锚,作为体积激光雷达点指导高斯参数的学习。记有激光雷达点投影的像素 u = ( u 1 , u 2 , 1 ) u=(u_1,u_2,1) u=(u1,u2,1)对应射线 R R R。采样 D D D个射线点 { p j = u d j ∣ j = 1 , ⋯ , D , d j < d j + 1 } \{p_j=ud_j|j=1,\cdots,D,d_j<d_{j+1}\} {pj=udj∣j=1,⋯,D,dj<dj+1},其中 d j d_j dj为对应的射线深度。有效掩膜区域 M ′ M' M′内的采样射线点 p p p可立即投影到3D空间,作为3D高斯锚 G p M ′ ( ⋅ ) G_p^{M'}(\cdot) GpM′(⋅)。这样既可避免对整个图像渲染从而降低存储消耗,还能同时重建RGB、深度和占用。
4.3 体素编码器
本文使用LSS生成3D体素特征 V ∈ R C × Z × H × W V\in\mathbb R^{C\times Z\times H\times W} V∈RC×Z×H×W。对每个有激光雷达投影的像素,使用射线投射操作从 V V V中提取 N t N_t Nt个采样的目标体素 V t V_t Vt,目标体素内存在高斯锚。
4.4 高斯参数解码器
将 G p M ′ G_p^{M'} GpM′作为3D高斯锚,可有效捕捉高质量、细粒度的细节。高斯锚 G = { x ∈ R 3 , c ∈ R 3 , r ∈ R 4 , s ∈ R 3 , α ∈ R 1 } G=\{x\in\mathbb R^3,c\in\mathbb R^3,r\in\mathbb R^4,s\in\mathbb R^3,\alpha\in\mathbb R^1\} G={x∈R3,c∈R3,r∈R4,s∈R3,α∈R1},高斯图 G G G被定义为
G ( x ) = { M c ( x ) , M r ( x ) , M s ( x ) , M α ( x ) } G(x)=\{M_c(x),M_r(x),M_s(x),M_\alpha(x)\} G(x)={Mc(x),Mr(x),Ms(x),Mα(x)}
其中 x x x为高斯锚的位置, M c , M r , M s , M α M_c,M_r,M_s,M_\alpha Mc,Mr,Ms,Mα分别为颜色、旋转、尺度和不透明度的高斯参数图。
由于多视图图像存在重叠区域,逐像素的预测会导致冲突,本文直接从3D体素特征预测高斯参数。给定体素特征 V V V和中心位置 x x x,使用三线性插值采样特征 f ( x ) f(x) f(x):
f ( x ) = T r i I n t e r ( V , x ) f(x)=TriInter(V,x) f(x)=TriInter(V,x)
各高斯参数图通过预测头 h = M L P ( ⋅ ) h=MLP(\cdot) h=MLP(⋅)生成,其中颜色和不透明度使用Sigmoid函数归一化到 [ 0 , 1 ] [0,1] [0,1]范围内。
旋转图表达四元数,需要进行 N o r m ( ⋅ ) Norm(\cdot) Norm(⋅)以确保单位幅值。尺度图则需要Softplus激活函数以满足范围要求。
4.5 重建信号的监督
仅在有效掩膜区域内进行高斯锚参数解码和重建。
RGB重建:本文直接预测固定视角的RGB,使用3.1节中的第二式渲染RGB C ^ \hat C C^。
深度重建:按下式渲染深度 D ^ \hat D D^:
D ^ = ∑ i = 1 N d i α i τ \hat D=\sum_{i=1}^Nd_i\alpha_i\tau D^=i=1∑Ndiαiτ
其中 N N N为高斯锚的数量, d i d_i di为第 i i i个高斯锚的深度。
占用重建:本文直接使用不透明度表示占用:
O ^ = max j = 1 k ( M α j ( x ) ) ∣ x ∈ V t \hat O=\max_{j=1}^k(M_\alpha^j(x))|x\in V_t O^=j=1maxk(Mαj(x))∣x∈Vt
其中 k k k为目标体素 V t V_t Vt中高斯锚的数量。
损失函数:包括颜色损失、深度损失和占用损失:
L = λ R G B N t p ∑ i = 1 N t p ∣ C i − C ^ i ∣ + λ d e p t h N t p ∑ i = 1 N t p ∣ D i − D ^ i ∣ + λ O c c N t v ∑ i = 1 N t v ∣ O i − O ^ i ∣ L=\frac{\lambda_{RGB}}{N^p_t}\sum_{i=1}^{N_t^p}|C_i-\hat C_i|+\frac{\lambda_{depth}}{N^p_t}\sum_{i=1}^{N_t^p}|D_i-\hat D_i|+\frac{\lambda_{Occ}}{N^v_t}\sum_{i=1}^{N_t^v}|O_i-\hat O_i| L=NtpλRGBi=1∑Ntp∣Ci−C^i∣+Ntpλdepthi=1∑Ntp∣Di−D^i∣+NtvλOcci=1∑Ntv∣Oi−O^i∣
其中 C i , D i C_i,D_i Ci,Di为真实色彩和深度, O i O_i Oi为真实占用(至少包含一个激光雷达点)。 N t p N_t^p Ntp和 N t v N_t^v Ntv分别为目标像素 P t P_t Pt和体素 V t V_t Vt的数量。
实验表明,本文的预训练方法还能降低对标注的依赖。即相比传统方法,使用更少的标注训练就能达到更高的性能。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 27
27 0
0- 0



 已为社区贡献45条内容
已为社区贡献45条内容

所有评论(0)