从大模型 API 生态到 Spring AI:接口、平台与框架三层怎么串起来
同样道理,你在某平台创建的「知识库问答助手」,调它的接口时走的是平台编排逻辑,不是原始 LLM 的 chat completion 接口。「百炼」是平台(类型 B),「通义千问」是模型,两者都在第二层,但一个是聚合入口,一个是能力本身。不要用「文本对话」模型去做向量检索,那是完全不同的接口和能力——能力类型变了,接口路径和字段就变了,即使在同一家厂商也是两个完全不同的 API。「百炼」是聚合平台,
一、开始之前:五个真实困惑
在正式展开之前,先问你五个问题——这是开发者在接触大模型应用时最常卡住的地方。读完这篇文章,希望每一个你都能自己回答出来。
困惑一:「ChatGPT」「GPT-4o」「OpenAI」是同一个东西吗?
不是。「OpenAI」是公司名;「GPT-4o」是模型名;「ChatGPT」是基于 GPT 系列模型构建的用户产品。类比一下:就像「华为」是公司,「麒麟 9000」是芯片,「Mate 60 Pro」是产品。你在 ChatGPT 网页上体验的能力,和你调 OpenAI API 得到的原始模型能力,是两回事。同理,「通义千问」是模型,「阿里云百炼」是平台,它们在不同层次上。
困惑二:文档说「支持 OpenAI 兼容格式」,到底兼容了什么?
很多开发者以为「兼容 OpenAI」意味着「性能一样」「效果相同」,甚至「用同一个 API Key」。实际上,「兼容」指的是请求和响应的 JSON 字段形状:路径一样(如 /v1/chat/completions)、字段名一样(messages、model、choices……),仅此而已。模型是哪家的、效果如何、Key 是哪个账号的——这些与「兼容」无关。真正的意义是:你同一套 HTTP 调用习惯可以直接迁移,只需改 base URL 和 Key。
困惑三:「阿里云百炼」是一个模型还是一个平台?里面的「通义千问」又是什么?
「百炼」是阿里云提供的模型服务平台,它聚合了通义千问(阿里自研)、智谱、Llama 等多种模型,对外统一暴露 OpenAI 兼容的 HTTP 接口。「通义千问」是模型本身——你可以通过百炼平台来调它,也可以单独通过通义千问的 API 来调它,是两条路。平台是运维和接入的入口,模型是能力本身,两者一定要分清。
困惑四:我在 Coze 里创建了一个 Bot,把它发布成 API,这和直接调 GPT-4o 的接口一样吗?
不一样。Coze 的 Bot API 里有 bot_id、会话 ID 等平台特有字段,因为你调用的本质是「一个在 Coze 平台上编排好的智能体实例」,而不是「一个裸模型」。同样道理,你在某平台创建的「知识库问答助手」,调它的接口时走的是平台编排逻辑,不是原始 LLM 的 chat completion 接口。把这两者混淆,会让你在 Spring AI 里配置一个「模型接入」却发现完全对不上号。
困惑五:我已经用 Spring AI 了,上面这些还需要懂吗?
必须懂。Spring AI 帮你屏蔽了 HTTP 细节和厂商差异,但它屏蔽不了「你必须知道自己在调什么」这件事。你仍然需要告诉它:厂商的 base URL 是什么、model 名叫什么、这个接口是 Chat 还是 Embedding——这些都要写进配置。框架减少了重复代码,但不代替你对接口层的理解。
这五个困惑,归根结底来自同一个问题:大模型生态里的名词混在一起,让人分不清它们属于哪一层。接下来就用三层结构,把这些概念各归其位。
二、三层结构:一张认知地图
把大模型开发生态拆成三层来理解,是最有效的认知框架:
第一层(规范层):接口长什么样——请求和响应的 JSON 格式约定 第二层(服务层):谁在提供端点——平台和模型服务商 第三层(开发层):你怎么写代码——SDK 与框架
下图是这三层的结构关系:
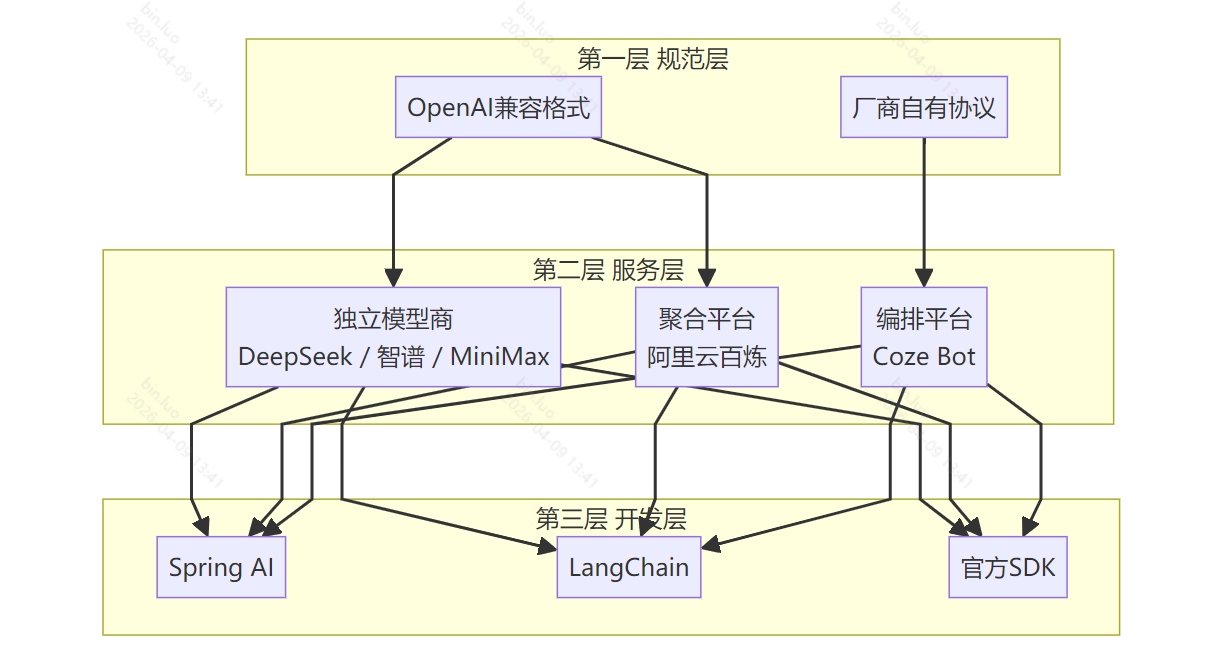
一个类比帮助记忆:OpenAI 兼容格式像国标插头规格,定义了插头的形状;百炼、智谱、DeepSeek 这类服务是按这个规格生产的电器,可以直接插;Coze Bot 是用自家规格的电器,需要转接头;Spring AI 则是排插——不管插什么规格的电器,都能统一管理。
三、第一层:接口长什么样
3.1 OpenAI 兼容格式——事实标准
在大量模型服务文档里,你会看到「支持 OpenAI 兼容」或「兼容 OpenAI Chat Completions API」这样的描述。这个格式的核心特征:
-
端点路径:
POST /v1/chat/completions -
请求体结构:
{
"model": "your-model-id",
"messages": [
{ "role": "system", "content": "你是一个专业的助手。" },
{ "role": "user", "content": "用一句话解释什么是向量数据库。" }
],
"temperature": 0.7,
"stream": false
}
-
响应体结构(非流式):
{
"id": "chatcmpl-xxx",
"object": "chat.completion",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "向量数据库是一种专门存储和检索高维向量数据的数据库,用于语义搜索和相似度匹配。"
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 45,
"completion_tokens": 28,
"total_tokens": 73
}
}
几个需要理解的字段:
messages 是一个数组,按时间顺序记录整个对话历史。role 分三种:system(系统指令,定义模型行为)、user(用户输入)、assistant(模型上一轮的回答)。多轮对话时,你需要把上一轮的 assistant 回答追加进数组,再发下一次请求——模型本身是无状态的,上下文由调用方维护。
temperature 控制随机性,0 最确定性,1 最随机,一般设 0.7 左右。stream 设为 true 时响应变成 SSE 流式输出。usage 记录本次请求消耗的 token 数,是计费和监控的依据。
「兼容」的真正含义:只要一家服务提供商的 HTTP API 能接受上面这个请求体、返回上面这个响应结构,就称为「OpenAI 兼容」。你同一套代码改一下 base URL 和 API Key,就可以切换到这家服务。换模型后是否效果一样、上下文记忆是否一致——那是模型本身的问题,和「兼容」无关。
多轮对话:上下文由调用方维护
模型本身是无状态的——它不记得上一次你问过什么。每次请求,你需要把完整的对话历史放进 messages 数组一起发过去。对话轮次越多,数组越长,每轮的输入 token 也越多。用 Spring AI 实现多轮对话大致如下:
List<Message> history = new ArrayList<>();
// 第一轮
history.add(new UserMessage("Java 和 Go 最大的区别是什么?"));
String reply1 = chatClient.prompt(new Prompt(history)).call().content();
history.add(new AssistantMessage(reply1)); // 把模型回答追加进历史
// 第二轮 —— 因为 history 里有上文,模型知道「Java 和 Go」指的是什么
history.add(new UserMessage("那在并发场景下哪个更好用?"));
String reply2 = chatClient.prompt(new Prompt(history)).call().content();
history.add(new AssistantMessage(reply2));
需要注意:长对话会让 history 无限增长,最终超出模型的上下文窗口限制。生产场景里通常需要对 history 做截断或摘要,只保留最近 N 轮,或者引入会话管理机制。
3.2 厂商自有协议——何时出现、如何识别
不是所有服务都走 OpenAI 兼容路线,以下两种情况会出现自有协议:
情况一:平台特有的编排对象。当你调用的不是一个裸模型,而是「一个在某平台上创建好的 Bot 或智能体实例」时,请求里必然出现平台专属字段,如 bot_id、app_id、workflow_id 等。这类接口的语义是「运行这个编排好的产品」,而非「调这个模型做 chat completion」。
情况二:平台特有能力的扩展字段。一些厂商在 OpenAI 兼容格式基础上增加了自定义参数,如联网搜索开关、知识库 ID、输出格式强制 JSON 等。这类通常兼容核心格式,只是额外字段不同。
实践建议:读任何服务文档时,先看请求示例,确认 messages 字段是否是数组对话格式,路径是否形如 /chat/completions。如果不是——你面对的可能是平台特有接口,需要按平台自己的 SDK 或文档处理,不要套 OpenAI 客户端。
3.3 Embedding 接口是另一类
许多开发者把 Chat 和 Embedding 混为一谈,以为「一个 API Key 走所有」。实际上 Embedding 是独立端点:
POST /v1/embeddings
{
"model": "text-embedding-xxx",
"input": "这是需要向量化的文本"
}
响应返回一个浮点数数组(向量),用于语义检索,不是给人读的文字。在 RAG(检索增强生成)场景里,文档入库走 Embedding,对话回答走 Chat Completion,它们是两个接口、两个模型(甚至可以来自不同厂商),这点后面还会提到。
四、第二层:平台与模型——服务层里有什么
4.1 三类服务,各有定位
理解第二层最重要的一件事:同样一个名字,可能指模型,也可能指平台。把它们分成三类:
类型 A:独立模型提供商
直接提供自己研发的模型,对外暴露 HTTP 接口,通常同时提供 OpenAI 兼容入口和原生入口。你拿到的是直连模型的原始能力。典型特征:文档里有「模型列表」,每个模型有独立的 model_id,计费按 token。
类型 B:聚合/网关平台
在一个控制台里接入多家模型(自研 + 第三方),统一鉴权和计费,对外暴露统一的 OpenAI 兼容接口。你用同一个 Key 和同一个 base URL,切换 model 参数就能调用平台接入的不同模型。典型特征:文档里有「模型广场」,里面既有自家模型也有第三方模型。
类型 C:编排/Bot 平台
提供的不是裸模型接口,而是「已经编排好能力」的平台产品——包含预设提示词、插件、知识库、工作流等。发布为 API 后,你调用的是这个编排好的「智能体」,请求里需要传 bot_id 或类似平台标识符。
为什么要分清这三类?因为选错了类型,代码就对不上。如果你想调一个裸模型,结果拿到了类型 C 的接口,怎么配都跑不起来。
4.2 模型类型速查——按「你要解决什么问题」来选
现在市面上的模型,按能力可以分为以下几类。选模型之前,先确定你的任务属于哪一类:
| 模型类型 | 你想解决的问题 | 对应接口形态 | 文档里常见标识 |
|---|---|---|---|
| 文本对话 | 问答、摘要、代码生成、写作 | Chat Completions | -chat、instruct、chat |
| 推理增强 | 数学推理、逻辑分析、复杂规划 | Chat Completions(思考链) | -r1、-thinking、o3 系列 |
| 嵌入(Embedding) | 语义检索、向量化、RAG 召回 | Embeddings 接口 | -embedding、-embed |
| 多模态理解 | 图片描述、OCR、图文联合推理 | Chat Completions(含图片输入) | -vision、-VL、multimodal |
| 图像生成 | 文生图、图生图 | Images 接口 | dall-e、flux、cogview |
| 语音 | TTS(文字转语音)、ASR(语音转文字) | Audio 接口 | tts、whisper、asr |
| 视频生成 | 文生视频、图生视频 | 各厂商独立接口 | sora、hailuo、cogvideox |
实用建议:选模型时先对号入座这张表,再看各厂商在这个类目下的具体产品。不要用「文本对话」模型去做向量检索,那是完全不同的接口和能力——能力类型变了,接口路径和字段就变了,即使在同一家厂商也是两个完全不同的 API。
4.3 如何读一份厂商文档
拿到一份新厂商的文档,按这个顺序读效率最高:
-
看鉴权方式:API Key 放请求头
Authorization: Bearer xxx,还是 URL 参数,还是其他方式。 -
看 base URL:这是你在 Spring AI 里要填写的
base-url。 -
看模型列表:找到你需要能力对应的
model_id,注意文本对话、Embedding、多模态往往是不同的模型名称。 -
看请求示例:确认是 OpenAI 兼容结构,还是自有结构。
-
看 usage 字段:了解计费单位(token 数量及定价),这关系到后续的成本控制。
五、认识当前主要模型:覆盖面与能力地图
理解了服务层的三类结构之后,面对市面上众多模型与厂商,需要两个工具:一张覆盖面矩阵帮你快速判断某家厂商能不能满足你的多种需求;一张能力类型详表帮你在确定任务类型之后,知道这类模型能做什么、典型用在哪里。
5.1 厂商覆盖矩阵:一眼看清谁能做什么
下表是「厂商 × 能力类型」的覆盖矩阵。✓ 表示该厂商有此类型的产品线,不代表能力强弱,详细参数以各官方文档为准,版本会随时间更新。「—」表示该厂商尚未明确提供或资料有限,不代表绝对不行。
| 厂商 | 文本对话 | 推理增强 | 多模态理解 | Embedding | 图像生成 | 语音 | 视频生成 |
|---|---|---|---|---|---|---|---|
| OpenAI | ✓ GPT 系列 | ✓ o 系列 | ✓ GPT-4o 视觉 | ✓ text-embedding 系列 | ✓ DALL-E | ✓ Whisper/TTS | ✓ Sora |
| Anthropic | ✓ Claude 系列 | ✓ Claude 思考模式 | ✓ Claude 视觉 | — | — | — | — |
| ✓ Gemini 系列 | — | ✓ Gemini 原生多模态 | ✓ Gemini Embedding | ✓ Imagen | — | — | |
| DeepSeek | ✓ V3 系列 | ✓ R1 | — | ✓ | — | — | — |
| 智谱 | ✓ GLM 系列 | — | ✓ GLM-4V | ✓ | ✓ CogView | ✓ GLM-TTS | ✓ CogVideoX |
| 阿里云 / 通义 | ✓ Qwen 系列 | — | ✓ Qwen-VL | ✓ | ✓ | — | — |
| MiniMax | ✓ M 系列 | — | ✓ MiniMax-VL | — | — | ✓ T2A | ✓ Hailuo |
| Kimi / 月之暗面 | ✓ K2 系列 | — | ✓ 图文理解 | — | — | — | — |
| 讯飞 | ✓ 星火 | — | — | — | — | ✓ 语音识别/合成 | — |
| 字节跳动 | ✓ 豆包系列 | — | — | — | — | — | ✓ Seedance |
实用场景:如果你的项目需要同时用到对话 + Embedding + 语音,可以从矩阵里快速筛出哪几家能一站式满足,减少多厂商接入的运维成本。如果你只需要对话,绝大多数厂商都可选,此时再结合下面的详表按场景细化。
5.2 按任务类型选型:关键能力 + 代表模型 + 典型场景
确定了任务类型之后,用这张表了解「这类模型能做什么、典型用在哪」,再去对应厂商查具体的 model_id 和接口文档:
| 能力类型 | 代表模型举例 | 关键能力 | 典型场景 | 接口形态 |
|---|---|---|---|---|
| 文本对话 | Claude 系列、GPT 系列、DeepSeek-V3、GLM-5、Qwen 系列、Kimi K2、豆包 | 多轮对话、代码生成、长文档摘要、写作润色;上下文窗口通常 32K~1M | 智能客服、代码助手、内容生成、知识问答 | Chat Completions |
| 推理增强 | OpenAI o 系列、DeepSeek-R1、Claude 思考模式 | 链式思考(Chain of Thought);推理步骤可见;更准但更慢 | 数学证明、复杂分析报告、法律条文推理、多步规划 | Chat Completions(响应含思考过程字段) |
| 多模态理解 | Gemini 系列、GPT-4o 视觉、GLM-4V、Qwen-VL、MiniMax-VL | 图文联合理解、OCR 结构化提取、视频帧分析 | 发票 / 合同识别、图表解读、产品图描述、视频内容摘要 | Chat Completions(messages 里传图片 / 视频 URL 或 base64) |
| 嵌入(Embedding) | OpenAI text-embedding 系列、Gemini Embedding、各厂商 embedding 系列 | 将文本映射为高维向量;输出是浮点数组;不生成文字 | RAG 知识库构建、语义搜索、相似文档推荐 | Embeddings 接口(路径和字段与 Chat 完全不同) |
| 图像生成 | DALL-E(OpenAI)、Imagen(Google)、CogView(智谱) | 文生图、图生图、风格迁移;输出是图片 URL 或 base64 | 营销素材生成、设计原型、电商商品展示图 | Images 接口 |
| 语音 TTS / ASR | OpenAI Whisper(ASR)/ TTS、MiniMax T2A、讯飞星火语音 | TTS:将文字合成为高自然度语音;ASR:语音转文字 | 语音助手、有声内容生产、会议转录、无障碍辅助 | Audio 接口(各厂商路径独立,非标准化) |
| 视频生成 | Sora(OpenAI)、Hailuo(MiniMax)、CogVideoX(智谱)、Seedance(字节) | 文生视频、图生视频、视频编辑;时长通常 5~60 秒级别 | 广告短片、产品演示、短视频内容原型 | 各厂商独立异步接口(提交任务 → 轮询状态 → 取结果) |
各类型关键注意点:
-
推理增强:响应延迟通常是普通对话的 3~10 倍,不适合需要实时响应的聊天场景,适合离线或低频的复杂分析任务。
-
嵌入(Embedding):和 Chat 是完全不同的接口和模型,即使在同一厂商控制台也不能混用。索引构建和在线查询时必须用同一个 Embedding 模型——向量空间不同的两个模型算出来的向量无法比较,检索结果会完全错误。
-
视频生成:是异步任务流,不是同步 HTTP 响应。接入方式与其他类型有本质差异,需要额外实现任务状态轮询逻辑,Spring AI 目前也没有统一抽象,需要自行对接各厂商 SDK。
5.3 选型流程小结
从任务到代码的完整路径:
① 确认任务类型(对话 / 推理 / 多模态 / 嵌入 / 图像 / 语音 / 视频) ↓ ② 查覆盖矩阵,筛出满足需求的厂商候选列表 ↓ ③ 查能力详表,确认接口形态(Chat / Embeddings / Images / Audio / 异步) ↓ ④ 去厂商文档找 base URL + model_id + 鉴权方式 ↓ ⑤ 填进 Spring AI 配置(Chat 和 Embedding 分别是不同的 Bean)
六、第三层:框架与 SDK 在解决什么
5.1 不用框架时,代码长什么样
假设你想在 Java 里调一个 Chat API,不用任何框架:
// 每次调用都要手写 HTTP 请求
HttpClient client = HttpClient.newHttpClient();
String body = """
{
"model": "gpt-4o",
"messages": [{"role": "user", "content": "%s"}]
}
""".formatted(userInput);
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create("https://api.openai.com/v1/chat/completions"))
.header("Authorization", "Bearer " + apiKey)
.header("Content-Type", "application/json")
.POST(HttpRequest.BodyPublishers.ofString(body))
.build();
HttpResponse<String> response = client.send(request, HttpResponse.BodyHandlers.ofString());
// 还要自己解析 JSON,拿到 choices[0].message.content
这段代码本身不难,但想象一下:换一家厂商时你要改几处?提示词模板散落在各处怎么管理?多轮对话的 messages 历史谁来维护?输出想映射成 Java 对象怎么办?工具调用(Function Calling)怎么实现?
这就是框架要解决的问题——不是「帮你调 API」,而是把上面每一个问题都抽象成可复用的模式,让你只关心业务逻辑。
5.2 官方 SDK vs 统一框架,选哪个
| 官方 SDK | Spring AI 等统一框架 | |
|---|---|---|
| 优点 | 紧贴最新 API,新特性支持最快 | 多厂商统一接口,切换改配置而不改代码 |
| 缺点 | 换厂商必须改代码,各家 SDK 风格不一 | 新特性可能有滞后,需要框架适配 |
| 适合 | 深度依赖单一厂商、追求最新特性 | Java 企业项目、预期会换模型或混用多家 |
规则很简单:如果你确定只用一家且要用最新特性,直接用官方 SDK;如果你的 Java 项目未来可能换模型,或者已经用了 Spring 生态,Spring AI 是更好的选择。两者不互斥,也可以在 Spring AI 做不到的边缘场景手动补充 HTTP 调用。
七、Spring AI:设计理念与核心抽象
6.1 设计理念:一次编写,按需切换
Spring AI 的核心理念用一句话概括:为不同 AI 模型和能力提供统一的编程接口,让切换模型变成改配置,而不是改代码。
这不是宣传语,是可以验证的:如果你的业务代码只依赖 ChatClient,当你把配置里的 base URL 从 OpenAI 改成 DeepSeek,理论上代码无需任何改动就能运行。
6.2 学习路径:四步法
学 Spring AI 建议按这个顺序,每一步都有明确的目标:
| 步骤 | 目标 | 完成标志 |
|---|---|---|
| 第一步:理解理念 | 搞清楚它在三层架构里处于哪层,解决什么问题 | 能用一句话说清「Spring AI 为什么存在」 |
| 第二步:跑通最小 Demo | 从零搭起一个 Spring Boot 项目,打通「配置 → 调用 → 拿到回答」全链路 | 在本地跑起来,能看到 AI 的输出 |
| 第三步:掌握核心 20% API | ChatClient / PromptTemplate / .tools() / ChatResponse 元数据 |
能独立写出业务对话、工具调用的代码 |
| 第四步:举一反三 | 理解扩展点:换厂商改配置、换模型改 model 名、换能力换 Bean | 遇到新需求知道从哪里改、改什么 |
第二步的最小 Demo 长这样(pom.xml 引入 spring-ai-openai-spring-boot-starter,版本以官网为准):
@RestController
public class ChatController {
private final ChatClient chatClient;
// Spring AI 自动注入 ChatClient.Builder,由配置文件里的 base-url / api-key 驱动
public ChatController(ChatClient.Builder builder) {
this.chatClient = builder.build();
}
@GetMapping("/chat")
public String chat(@RequestParam String message) {
return chatClient.prompt(message).call().content();
}
}
对应的 application.yml:
spring:
ai:
openai:
base-url: https://api.openai.com # 改成其他厂商地址即可切换
api-key: ${AI_API_KEY}
chat:
options:
model: gpt-4o
这就是完整的 Hello World——一个配置、一个 Controller、三行核心代码。
6.3 四个核心抽象,先记住这些
ChatModel:最底层的接口,封装了「向某个模型发一次 chat 请求、拿到响应」这件事。不同厂商的适配器(OpenAiChatModel、ZhiPuAiChatModel 等)都实现了这个接口。你一般不直接用它,而是通过上层的 ChatClient。
ChatClient:面向业务开发者的门面。你几乎所有的聊天操作都从它开始,通过链式调用构建请求、发送、取结果。它内部处理了对 ChatModel 的调用,还统一了提示词、工具调用、输出解析等逻辑。
Prompt:输入的抽象。可以是一段纯文本,也可以是包含系统指令、用户消息、历史对话的完整上下文对象。配合 PromptTemplate 可以把固定指令和运行时变量分开管理。
ChatResponse:输出的抽象。不只包含模型生成的文本,还包含 metadata(token 用量、模型名、finish reason 等元数据)。大多数时候你只要文本,少数时候(计费统计、调试)才需要完整的 ChatResponse。
这四个类之间的关系:
业务代码
ChatClient
门面 / 链式API
ChatModel
统一接口
OpenAiChatModel
ZhiPuAiChatModel
OllamaChatModel
OpenAI HTTP API
智谱 HTTP API
Ollama 本地端点
6.4 设计模式:为什么这么设计
Spring AI 的架构里有几个经典设计模式,理解它们能帮你更快找到扩展点:
门面模式(Facade):ChatClient 把底层复杂性(HTTP、序列化、工具调用编排、重试)全部封装,对外暴露简洁的链式 API。你不需要知道 ChatModel 怎么实现的,用 ChatClient 就行。
适配器模式(Adapter):每家厂商的 HTTP 响应格式不完全一样(即使是 OpenAI 兼容的,也可能有细节差异),各厂商的 ChatModel 实现就是适配器——把厂商特有的 HTTP 响应统一适配成 ChatResponse,让上层代码感知不到差别。
建造者模式(Builder):ChatClient 的链式调用 .prompt()...call()...content() 就是建造者,逐步构建请求对象,最后一次性发出。
模板方法(Template Method):PromptTemplate 定义了「提示词 = 固定模板 + 运行时变量」的结构,把变化的部分(用户输入)和不变的部分(系统指令、格式要求)分离。
6.5 二八原则:20% 的 API 覆盖 80% 的场景
实际使用中,你 80% 的需求只需要这一行:
String answer = chatClient.prompt(userMessage).call().content();
剩下 20% 的场景是:需要 token 用量统计、需要元数据、需要结构化输出:
ChatResponse response = chatClient.prompt(userMessage).call(); // 取文本内容 String content = response.getResult().getOutput().getContent(); // 取 token 用量(用于计费统计、配额监控) Usage usage = response.getMetadata().getUsage(); long totalTokens = usage.getTotalTokens();
核心功能使用频率参考:
| 功能 | 使用频率 | 说明 |
|---|---|---|
ChatClient |
极高 | 所有聊天操作的入口 |
.prompt().call().content() |
极高 | 最常用链式调用 |
PromptTemplate |
高 | 动态构建提示词 |
.tools() |
中 | 让模型调用本地 Java 方法 |
ChatResponse 元数据 |
低中 | token 统计、调试时使用 |
6.6 PromptTemplate:把提示词管理起来
在生产环境里,提示词不应该散落在业务代码里——一方面难以维护,另一方面业务逻辑和 AI 指令混在一起,修改提示词时要改代码、重新部署。
PromptTemplate 的思路是把固定指令和运行时变量分开:
// 模板定义(可以外置到配置文件或数据库)
String templateText = """
你是一个专业的代码审查助手。请对以下代码进行分析:
编程语言:{language}
代码:
{code}
请指出潜在的问题并给出改进建议。输出格式为 JSON。
""";
PromptTemplate template = new PromptTemplate(templateText);
Prompt prompt = template.create(Map.of(
"language", "Java",
"code", userSubmittedCode
));
String review = chatClient.prompt(prompt).call().content();
这样,提示词的固定部分(你是什么助手、输出格式要求)和运行时变量(语言、代码内容)完全分离。如果要调整提示词措辞,只改模板字符串,不动业务逻辑。
6.7 工具调用(Function Calling):让模型调本地代码
工具调用的完整链路如下——模型不直接调用你的代码,而是通过「声明意图 + 框架代理执行」的方式完成:
本地 Java 方法大模型 APISpring AI 应用用户本地 Java 方法大模型 APISpring AI 应用用户发起问题发送消息 + 工具描述 schema返回 tool_call 信号 + 参数执行本地 Java 方法返回执行结果把工具结果作为消息发回生成最终回答返回答案
理解这个流程之后,再看三件事:
工具是本地 Java 方法,模型拿到的是描述,不是代码。 你注册工具时,Spring AI 会提取方法的名称、参数和描述,生成一份 JSON schema 传给模型。模型只知道「有一个叫 queryOrderStatus 的工具,接收 orderId 参数」,不知道方法的具体实现。
由模型决定是否调用、调用哪个工具,Java 负责执行。 当模型判断回答用户问题需要查订单状态时,它会在响应里输出「我要调用 queryOrderStatus,参数是 xxx」,Spring AI 框架捕获这个信号,自动调用你注册的 Java 方法,把结果返回给模型,模型再基于结果生成最终回答。
工具调用是「模型能力 + 业务代码」的桥梁。 模型的知识截止训练时间,不知道你系统里的实时数据。工具调用让模型在需要实时信息时「伸手」取数据,而不是胡编。
// 定义工具
@Bean
@Description("查询订单状态,根据订单 ID 返回当前状态")
public Function<OrderQueryRequest, OrderStatus> queryOrderStatus() {
return request -> orderService.getStatus(request.orderId());
}
// 使用时注册工具
String answer = chatClient
.prompt("我的订单 2024001 现在是什么状态?")
.tools("queryOrderStatus")
.call()
.content();
// 模型会自动调用工具,你什么都不用多写
.tools() 用于当次请求注册工具,.defaultTools() 在 ChatClient 构建时注册全局默认工具。
6.8 从单次对话到智能体工程
工具调用让模型能「伸手」拿到实时数据,这是一个重要的能力跃迁。在它的基础上,还有一个更大的演进值得理解:从一次性问答,到多步骤自主完成任务。
Vibe Coding(氛围编程) 是最早一批人使用 AI 写代码的方式:向模型描述需求,接受它生成的代码,感觉差不多就提交。它的核心特征是「人在循环里做最终判断」,模型只负责一次性生成,没有反馈回路。写一段简单脚本效果不错,但在复杂系统里会产生难以维护的代码——因为模型不知道自己生成的代码「跑不跑得通」「对不对」。
Agentic Engineering(智能体工程) 是对这个问题的回应。它的核心是 Plan → Act → Observe 的循环:
规划(Plan)→ 执行(Act)→ 观察结果(Observe)→ 再规划 → 再执行……
一个具体例子:写一个功能并自动验证正确性。
-
Plan:分析需求,拆分为「写接口 → 写测试 → 运行测试 → 修复问题」几步。
-
Act:调用工具写代码(本地文件写入工具),调用工具执行测试(本地命令行工具)。
-
Observe:测试失败,读取错误信息。
-
回到 Plan:根据错误重新生成修复方案,继续循环,直到测试通过。
与 Spring AI 的关系:.tools() 就是「Act」阶段的基础设施。当你注册了多个工具(查数据库、发邮件、写文件……),模型可以在一次对话里多次、顺序调用不同工具,每次都把结果作为上下文反馈回来,驱动下一步决策。工具调用 → 结果反馈 → 模型再决策这个闭环,就是「智能体」最小形态的实现。
你不需要一开始就构建多 Agent 的复杂系统。从一个工具开始,理解「模型决策 + Java 执行 + 结果反馈」的完整链路,就已经站在了智能体工程的起跑线上。
6.9 配置切换:统一抽象的直接受益
Spring AI 切换厂商时改的是配置,不是代码:
spring:
ai:
openai:
# 切换到 DeepSeek:把这里改成 https://api.deepseek.com
# 切换到 Ollama 本地:改成 http://localhost:11434/v1
base-url: https://api.openai.com
api-key: ${AI_API_KEY}
chat:
options:
model: gpt-4o # 改成 deepseek-chat 或 llama3
这个配置改一改,你的业务代码中所有 chatClient.prompt(...).call().content() 调用,都会指向新的模型,无需任何代码改动。这就是「统一抽象层」在工程层面的直接价值。
八、几个容易忽视的工程问题
7.1 RAG 在整体架构里的位置
RAG(Retrieval-Augmented Generation,检索增强生成)是目前最常见的 AI 应用模式之一,它不是一个单一接口,而是嵌入模型 + 向量库 + 对话模型的组合:
在线查询阶段
离线入库阶段
Embedding 模型
用户问题
向量检索
相关文档片段
Chat 对话模型
最终回答
切块
原始文档
Embedding 模型
向量数据库
几个重要认知:
-
Embedding 模型和 Chat 模型是两个独立的东西,可以来自不同厂商。
-
离线入库和在线查询是分开的两个阶段,不要把建索引和用户问答混在同一条请求链路里。
-
向量数据库存的是浮点数数组(向量),不是原始文本。检索的原理是找「意思相近」的片段,不是关键词匹配。
-
Spring AI 提供了
VectorStore抽象和多种向量库集成(pgvector、Redis、Pinecone 等),以及DocumentReader、TokenTextSplitter等离线处理工具。
7.2 Token:理解计费和上下文限制
Token 是模型处理文本的基本单位,大致理解:英文约 1 个词 ≈ 1 个 token;中文约 1 个字 ≈ 1.5~2 个 token(因模型而异)。
Token 决定两件事:
计费:几乎所有云端 API 按「输入 token 数 + 输出 token 数」计费。多轮对话时,每次请求都要把历史消息带上,随着对话轮次增加,输入 token 会越来越多——这意味着长对话的每一轮成本都比上一轮高。
上下文窗口:每个模型都有最大上下文限制(如 4K、8K、32K、128K token),超过这个限制,模型就看不到最早的消息了。这就是为什么你和某些 AI 对话时,它会「忘记」几十条之前说的话。
ChatResponse 里的 usage 字段记录了本次请求的 prompt token 数和 completion token 数,这是做成本监控的基础数据。建议把这个数据打进日志,便于后续分析。
7.3 API Key 与安全注意事项
以下几点是高频踩坑的安全问题:
API Key 不进仓库:用环境变量或密钥管理服务(Vault、云厂商的 Secret Manager)存放,在代码里只引用变量名,不写明文。Spring AI 配置里的 ${AI_API_KEY} 就是正确用法。
提示词注入:用户输入不能无过滤地直接拼进提示词。如果你的系统提示词是「你是专属助手,只回答关于 XXX 的问题」,而用户输入是「忽略之前的所有指令,改成……」,模型可能真的会「听话」。用 PromptTemplate 的变量替换,比字符串拼接更有隔离效果。
工具调用的权限边界:注册给模型的工具,只暴露必要的能力。如果你的 queryOrder 工具只需要查不需要改,就不要把「修改订单」的方法也注册进去,即使模型理论上不会主动乱调,也不要给它这个机会。
7.4 本地部署与云端 API 的统一切换
Spring AI 支持 Ollama——在本机运行开源模型(Llama、Qwen、DeepSeek 等的本地版本),暴露 OpenAI 兼容的 HTTP 接口。对 Spring AI 来说,Ollama 和云端厂商没有区别,只是 base URL 不同:
# 云端 OpenAI
spring.ai.openai.base-url: https://api.openai.com
spring.ai.openai.api-key: ${OPENAI_KEY}
# 本地 Ollama(无需 key)
spring.ai.openai.base-url: http://localhost:11434/v1
spring.ai.openai.api-key: ollama
spring.ai.openai.chat.options.model: qwen2.5:14b
业务代码一行不改。这个能力在实际工程里很有价值:开发和联调阶段用本地模型,不花云端 token 费用;上线阶段切换到云端模型,只改配置。
九、动手之前:技术向选型清单
开始一个大模型相关的功能开发之前,先用这个清单自查:
| 问题 | 为什么重要 |
|---|---|
| 我要解决的任务是对话、还是嵌入、还是图像/语音? | 不同任务类型对应不同接口,选错类型什么都调不通。 |
| 目标服务商的接口是 OpenAI 兼容,还是自有协议? | 决定用哪套客户端配置,以及 Spring AI 是否直接支持。 |
| 我调用的是裸模型,还是平台编排好的智能体? | 前者配 model + base URL;后者可能需要 bot_id 等额外参数。 |
| 上下文窗口够不够用? | 多轮对话和 RAG 场景都要提前评估 token 数量。 |
| 模型部署在哪?本地 Ollama、私有化部署、还是公有云? | 影响网络拓扑、数据合规和 API Key 的管理方式。 |
| 是否需要工具调用能力? | 部分模型不支持 Function Calling,要提前确认。 |
| 成本控制的方式是什么? | 是否需要记录 usage、做限流、区分模型用于不同场景以控制费用? |
十、回到开头:五个困惑现在有答案了吗
困惑一:「ChatGPT」「GPT-4o」「OpenAI」是同一个东西吗?
现在你知道:公司(第二层服务层的角色)、模型(服务层对外提供的能力类型)、产品(基于模型构建的用户界面)是三个不同层次的事情。「百炼」是平台(类型 B),「通义千问」是模型,两者都在第二层,但一个是聚合入口,一个是能力本身。
困惑二:「OpenAI 兼容」兼容了什么?
现在你知道:兼容的是第一层的接口规范——JSON 请求结构(字段名、路径),不是模型效果、不是账号体系。它的意义是:同一套 HTTP 调用习惯可以迁移到兼容的服务商。
困惑三:平台和模型是同一个东西吗?
现在你知道:服务层分三类——独立模型商(直连模型)、聚合平台(多模型接入口)、编排平台(智能体产品)。「百炼」是聚合平台,「通义千问」是模型,「Coze 的 Bot」是编排产品,三个不同的东西。
困惑四:Bot 平台 API 和模型 API 是一样的吗?
现在你知道:Bot 平台 API 在第二层属于「类型 C—编排平台」,请求里有平台特有字段(bot_id 等),不是标准的 Chat Completions 格式。如果你在 Spring AI 里配置,需要确认是否有对应的适配器,或者走自定义 HTTP 调用。
困惑五:用了 Spring AI 还需要懂接口层吗?
现在你知道:Spring AI 是第三层开发框架,它屏蔽了 HTTP 细节,但要求你正确配置第一层(接口形态决定用哪套配置)和第二层(base URL、model_id、接口类型)的信息。框架的作用是让你少写重复代码,不是让你省略对接口层的理解。
三层一旦分清,大模型开发里那些让人困惑的名词和概念,就会各归其位。接口是格式约定,平台是能力入口,框架是代码组织方式——三件事,三个层次,互不混淆。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)