大模型低精度量化详细原理指南(Quantization)
摘要 大模型量化技术通过降低参数精度(如FP32→INT4)大幅减少内存占用(70B模型从280GB压缩到35GB),使大模型能在消费级硬件上运行。量化核心机制包括对称/非对称映射、异常值截断和校准优化。
文章参考https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-quantization撰写,这些高质量的图片均来自原文。
前言
如果你最近关注过开源大模型的部署,一定见过这些词:Q4_K_M、GPTQ、GGUF、AWQ……它们都属于同一个概念的范畴——量化(Quantization)。
量化是当前让大模型"跑得起来"的最核心技术之一。一个 70B 参数的模型,原始精度下光加载就需要近 280GB 内存,绝大多数消费级硬件根本摸不到边。而经过量化,同一个模型有时候只需要 40GB 甚至更少,就可以在普通的工作站上运行。
但量化到底是怎么工作的?压缩的代价是什么?怎么压才能尽量不损失模型质量?本文从最基础的比特表示讲起,一步步走完这整个故事。

目录
非对称量化(Asymmetric Quantization)
第一部分:大模型的"内存问题"
1.1 数字是怎么存在计算机里的?
在理解量化之前,必须先搞清楚计算机是怎么表示数字的。
计算机中的数值用浮点数(floating point)来表示,依照 IEEE-754 标准,一个浮点数由三部分组成:
- 符号位(Sign):1 bit,表示正负
- 指数位(Exponent):决定数值的范围(量级)
- 尾数位(Fraction / Mantissa):决定数值的精度(小数部分)
这三个部分共同决定了一个浮点数具体代表多少。位数越多,能表示的数值范围越广,精度也越高。
常见的浮点格式对比如下:
FP32(全精度):32 位,1 位符号 + 8 位指数 + 23 位尾数。精度最高,数值范围约 [-3.4×10³⁸, 3.4×10³⁸],是绝大多数模型训练时使用的默认精度。

FP16(半精度):16 位,1 + 5 + 10 的结构。精度减半,但关键问题是指数位从 8 变成了 5,导致可表示的数值范围大幅缩小,容易出现溢出。
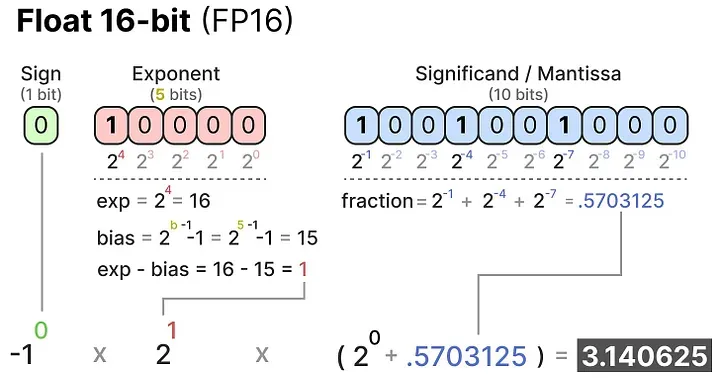
BF16(Brain Float 16):同样是 16 位,但结构是 1 + 8 + 7——保留了和 FP32 相同的 8 位指数,只是尾数精度减少了。这使得 BF16 在保持与 FP32 相似数值范围的同时节省了一半内存,是目前深度学习训练中最常用的"缩减"格式。
INT8:8 位整数,范围是 [-128, 127]。不再是浮点格式,而是整数,精度进一步压缩。
这里有两个关键概念需要区分:
- 动态范围(Dynamic Range):这种数据格式能表示的最大值和最小值之间的区间,由指数位决定。
- 精度(Precision):相邻两个可表示数值之间的间距,由尾数位决定。
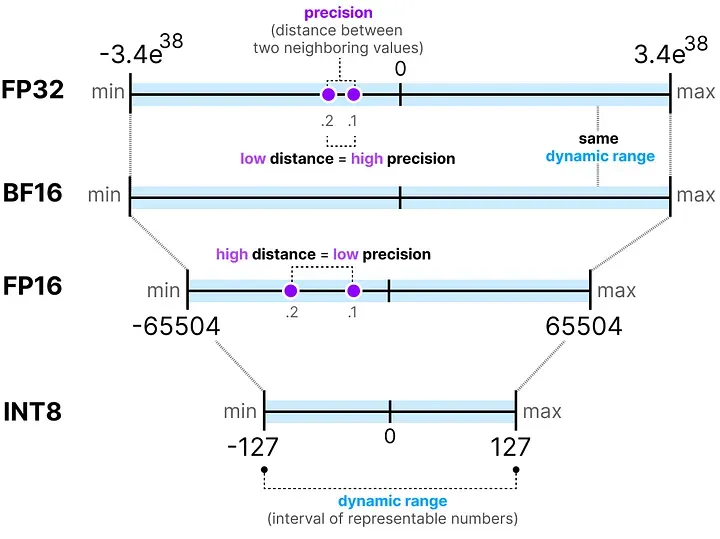
位数减少,要么动态范围缩小,要么精度下降,或者两者都有损失。
1.2 内存占用有多大?
估算模型的内存占用非常简单,公式是:
其中:
- N:参数量
- b:每个参数所占比特数(如 16, 8, 4)
以一个 70B 参数的模型为例:
- FP32(32 bit):70×10⁹ × 32 / 8 = 280 GB
- FP16 / BF16(16 bit):140 GB
- INT8(8 bit):70 GB
- INT4(4 bit):35 GB
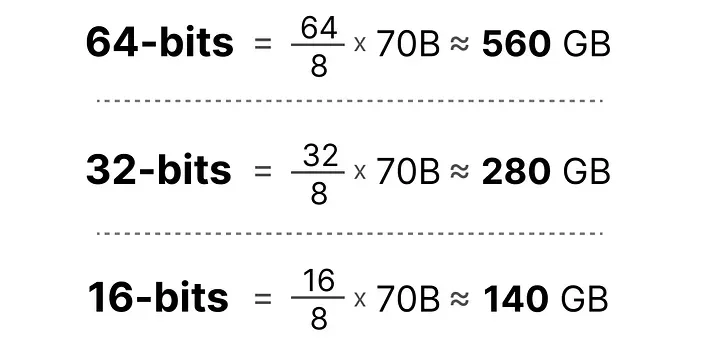
280GB vs 35GB——同一个模型,存储需求相差 8 倍。这就是为什么量化如此重要。问题只有一个:从高精度压缩到低精度,怎么做才能尽量不损失模型的表现?
第二部分:量化的核心机制
量化的本质,就是把一堆用 FP32 表示的数值,通过一个映射函数,转换成用更少 bit(比如 INT8)表示的数值,同时尽可能保留原始数值所携带的信息。
用一个直觉性的比喻:把一张照片从全彩色(数百万种颜色)转成只用 8 种颜色来表示——整体轮廓保留了,但细节变粗糙了。原文中这张量化前后图片对比的图非常直观地展示了这种"粗粒度化"的效果:远看差不多,放大就能看到明显的色块感。

好的量化方案要做的事情,就是在尽量少的 bit 预算下,让这个"粗粒度化"的损失最小。
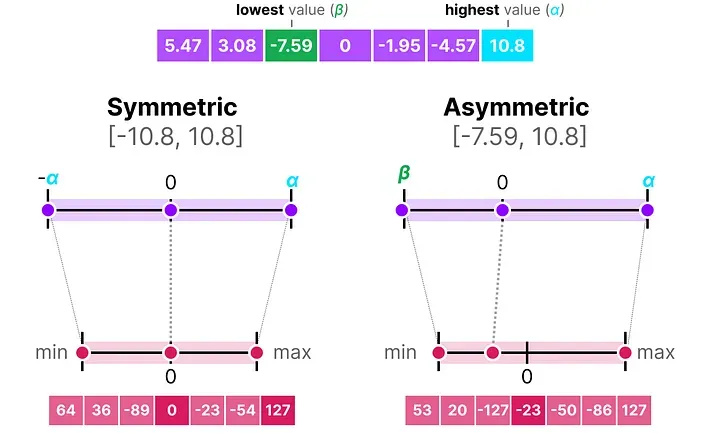
2.1 对称量化(Symmetric Quantization)
对称量化是最直观的方式:把浮点数的范围关于 0 对称地映射到整数范围。
最典型的实现叫绝对值最大量化(absmax quantization)。做法是:找到向量中绝对值最大的那个数 α,然后用它来计算一个缩放因子 s,把所有值映射到 [-127, 127](或 [-128, 127])的整数区间。
计算步骤:
- 找到
- 计算缩放因子:
- 量化:
反量化(恢复回浮点数)只需要:
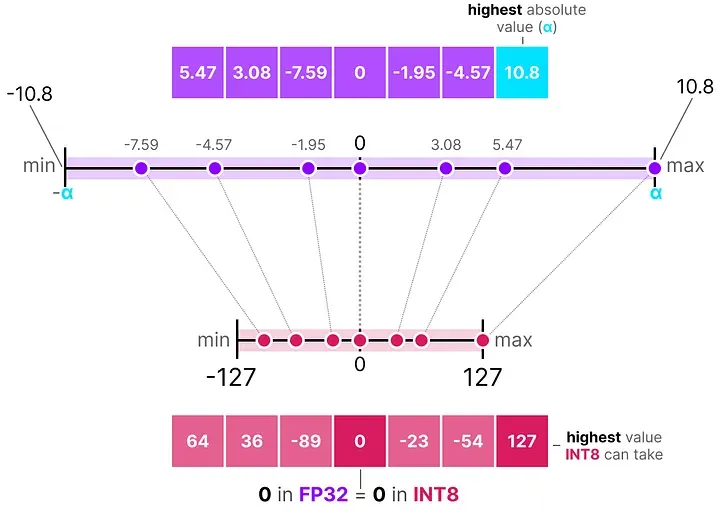
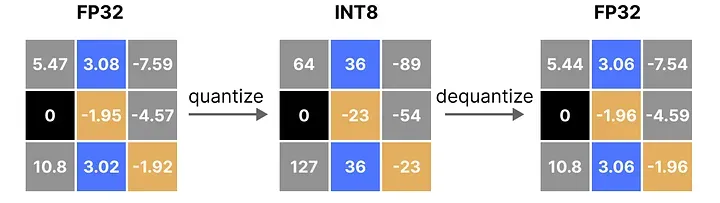
注意,量化再反量化之后,某些原本不同的数值可能会被映射到同一个整数,再恢复时就变得无法区分——这个误差叫做量化误差(quantization error)。

对称量化的优点是简单,计算高效;缺点是当数据分布不对称时(比如 ReLU 之后全是正数),量化后负数区间根本没有数,会有很多 bit 的表达能力被浪费。
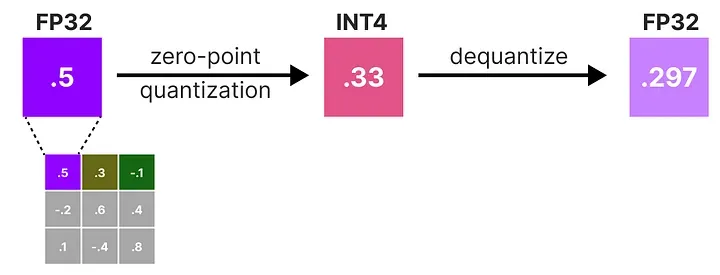
2.2 非对称量化(Asymmetric Quantization)
非对称量化解决了这个问题。它不强迫映射关系关于 0 对称,而是把数据实际的最小值 β 和最大值 α,分别映射到整数区间的两端(比如 -128 和 127)。
这种方法常叫做零点量化(zero-point quantization),因为"0"在浮点空间中对应的整数不再是 0,而是一个偏移量,叫做零点 z。
计算步骤:
- 确定浮点数据的范围
- 计算缩放因子:
- 计算零点:
- 量化:
反量化:
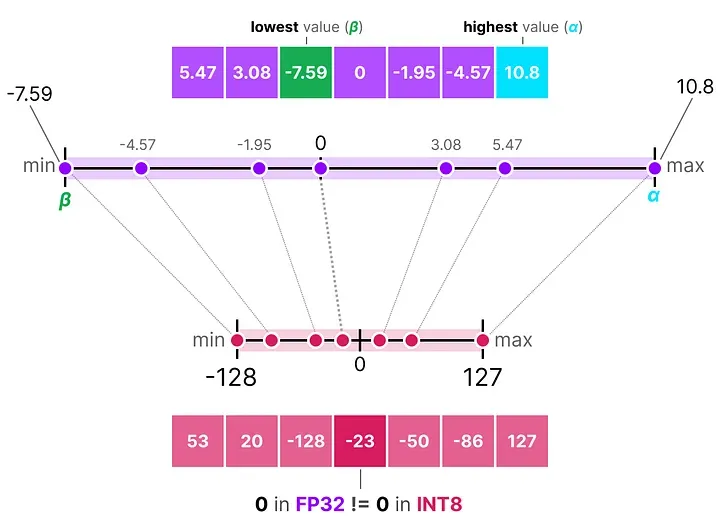
非对称量化在数据分布偏斜时精度更高,但多了一个零点参数需要存储和计算,稍微复杂一些。
2.3 异常值与 Clipping:量化的最大敌人
在实际操作中,浮点数据往往不是均匀分布的——偶尔会出现个别远超其他数值的异常值(outliers)。
问题在于:absmax 量化用的是整个向量里最大的绝对值来确定缩放因子。如果有一个极端异常值,缩放因子就会被它"拉大",导致其他所有正常值在压缩后都挤到了一个很窄的整数区间里,区分度完全丧失。

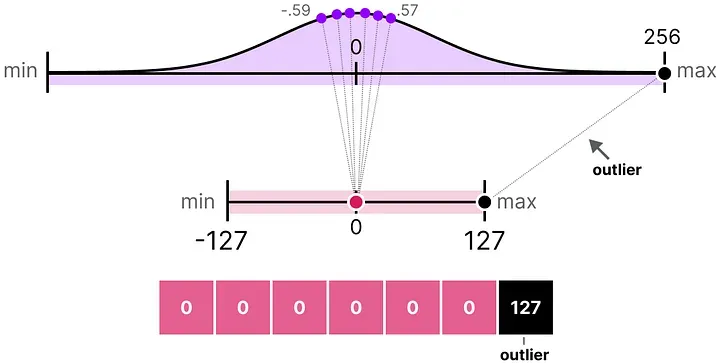
解决思路是截断(Clipping):手动设定一个动态范围(比如 [-5, 5]),超出这个范围的值就直接截到边界值(-127 或 127),而不再用真实值决定缩放因子。代价是异常值本身的量化误差变大了,但好处是大多数正常值的量化精度显著提升了。
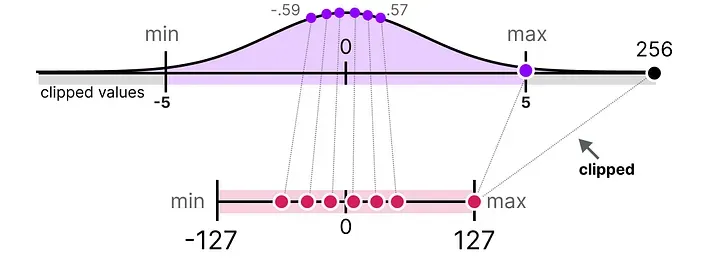
这引出了一个问题:这个截断阈值怎么选?
2.4 校准(Calibration):找到最优的量化范围
选择量化范围的过程叫做校准(calibration)。目标是找到一个范围,在包含尽量多有效数值的同时,把量化误差最小化。
具体策略因参数类型而异。
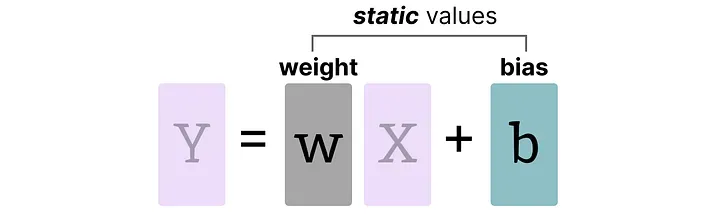
对于权重(Weights):权重是模型文件里存好的静态数值,在推理之前就完全可知。因此可以离线、充分地分析它的分布,常见的校准策略有:
- 选取某个百分位数作为截断上限,忽略极端离群值;
- 最小化原始权重和量化后权重之间的均方误差(MSE);
- 最小化两者分布之间的 KL 散度,即最大限度地保留信息熵。

由于模型中偏置(biases)数量远少于权重(通常少几个数量级),偏置往往保留在更高精度(如 INT16 或 FP16),量化的重点集中在权重上。
对于激活值(Activations):激活值是输入数据流过每一层时动态产生的中间结果,每条不同的输入都会产生不同的激活值。它们无法提前知晓,只能在推理过程中实时获得。
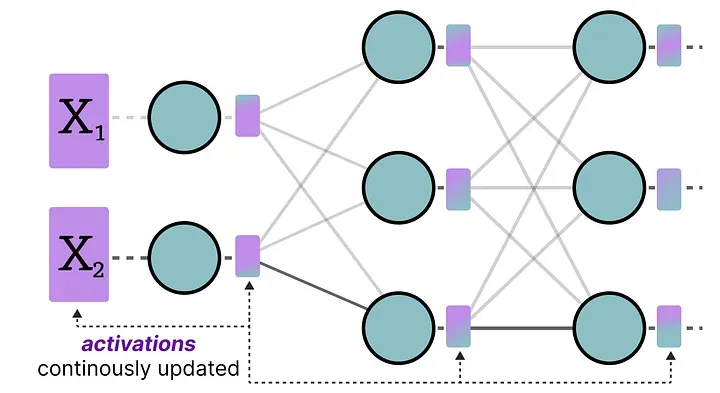
正是激活值的这种动态性,让它的量化比权重困难得多——这也是接下来要讲的训练后量化的核心挑战。
第三部分:训练后量化(PTQ)
训练后量化(Post-Training Quantization,PTQ)是最实用的量化方式:模型已经训练完毕,我们直接对它做量化,不需要重新训练。权重的量化相对简单,激活值的量化则需要进一步分类。
3.1动态量化(Dynamic Quantization)
在模型推理时,当输入数据通过某一层网络,激活值被计算出来后,实时根据这一批激活值的分布计算缩放因子 s 和零点 z,然后立刻对激活值做量化。
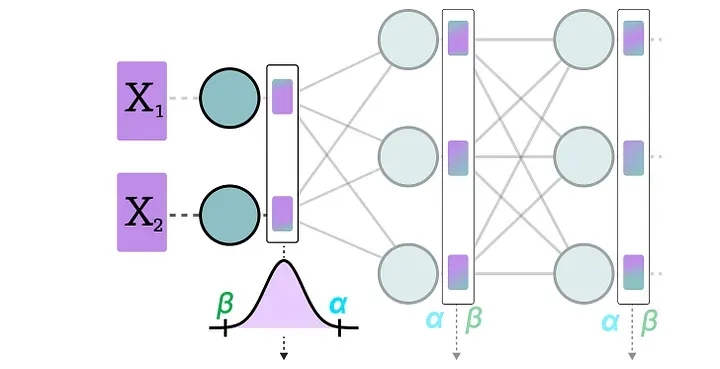
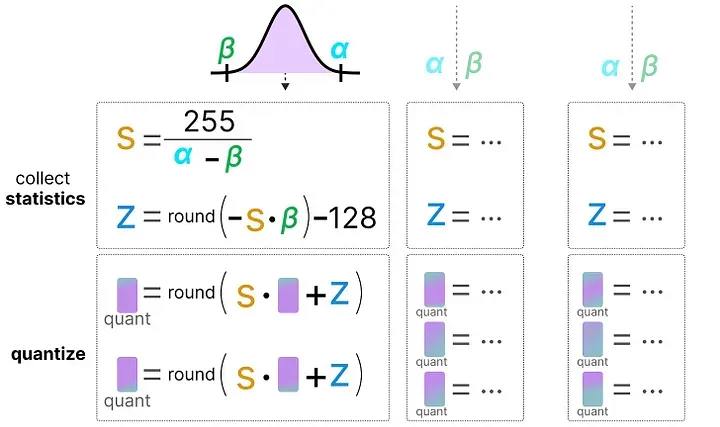
每一层都有自己独立的 s 和 z,量化方案因层而异,因输入而异。
好处是精度相对高——永远根据当前数据的实际分布来量化;代价是每次推理都要在运行时计算这些量化参数,增加了计算开销。
3.2 静态量化(Static Quantization)
静态量化的策略正好相反:推理之前,用一批校准数据集(calibration dataset)提前跑一遍模型,收集每一层激活值的分布统计信息,预先计算好 s 和 z,固定下来。
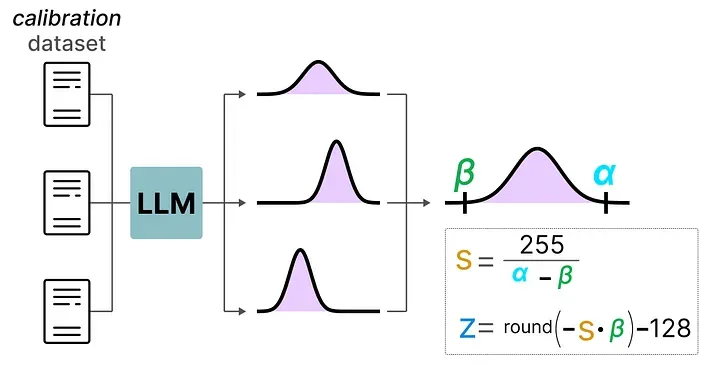
正式推理时,不再重新计算这些参数,直接套用预先算好的 s 和 z。
好处是推理速度快;代价是校准数据不一定能完全代表实际输入,当真实输入的分布和校准集偏差较大时,静态量化的误差就会比动态量化大。
总结来说:动态量化精度更好,静态量化速度更快,实践中根据场景权衡选择。
3.3 深入 4-bit 量化:GPTQ 与 GGUF
从 8-bit 再往下压,量化误差会迅速增大,因此需要更精巧的方案。目前社区中最常见的两种 4-bit 量化格式是 GPTQ 和 GGUF,分别针对不同的使用场景。
3.3.1 GPTQ:逐层智能纠错
GPTQ 的出发点是:与其试图让每一个权重单独的量化误差尽可能小,不如让整层网络量化后的输出尽可能接近量化前的输出。这是一个整体性的目标,而不是逐点最优化。
要实现这个目标,GPTQ 利用了两个关键工具:Hessian 矩阵的逆和误差传播补偿。接下来我们一步步拆解。
先从一个简单问题出发:
假设有一层线性变换,输入是
,权重矩阵是
,输出是
。现在我们要把 W 里的某个权重
量化,它从原来的
,产生了量化误差
。
这个误差会导致这一层的输出发生变化,进而影响最终的模型损失。我们希望这个输出变化尽可能小。
一个直觉是:如果我们能在量化
GPTQ 的本质就是把这个直觉变成了一套严格的数学方案。
Hessian 矩阵:权重重要性的度量
在正式进入 GPTQ 之前,要先理解 Hessian 矩阵在这里的角色。
对于一个损失函数 ,它对权重矩阵
的二阶偏导数构成了 Hessian 矩阵
:
Hessian 的含义是:当权重 发生微小变化时,损失函数的变化率本身如何随着
的变化而变化 。换句话说,它描述了损失函数曲面的"曲率"信息。
对角线上的 尤其重要:它告诉我们,改变权重
对损失函数影响有多大。
越大,这个权重越敏感,量化它带来的损失越大;
越小,这个权重越不敏感,量化它对模型输出的影响越小。
注意 GPTQ 用的是 Hessian 的逆矩阵 ,逻辑正好反过来:
越小,对应的权重越敏感越重要;
越大,对应的权重越不重要、越"可以被牺牲"。
在 GPTQ 的实现里,Hessian 矩阵是对每一层单独计算的,使用该层的输入激活来近似:
其中 是在一批校准数据(calibration data)上收集到的该层输入激活矩阵。这个近似之所以成立,是因为对于线性层来说,损失函数关于权重的二阶导数恰好与输入的协方差矩阵成正比。
说明:
对线性层 + 平方误差损失这种最简单的损失
,直接求二阶导数(Hessian),你会得到:
,
,所以 GPTQ 根本不用算真 Hessian!
GPTQ具体流程如下:
第一步:逐层处理。 模型的每一层独立进行量化,完成后固定,再继续下一层。
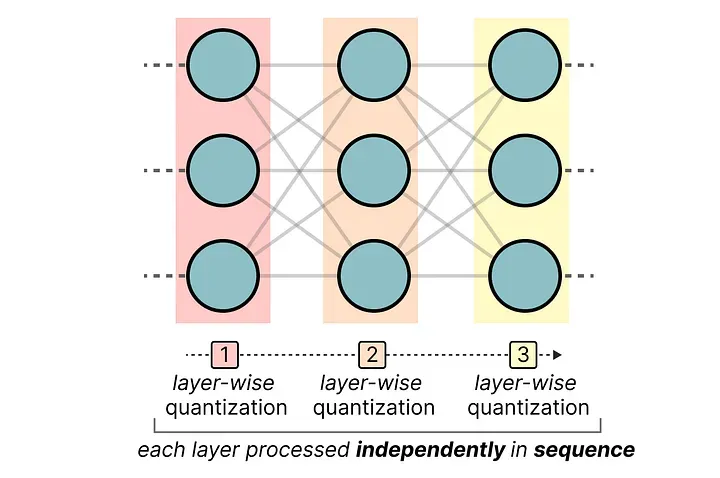
第二步:计算权重重要性。 对当前层,计算权重矩阵的 Hessian 矩阵的逆。它告诉我们:改变这个权重,模型输出会有多敏感?
在 Hessian 逆矩阵中,数值小的位置对应更重要的权重——这类权重一旦变化,模型输出变化很大,量化时要特别小心。
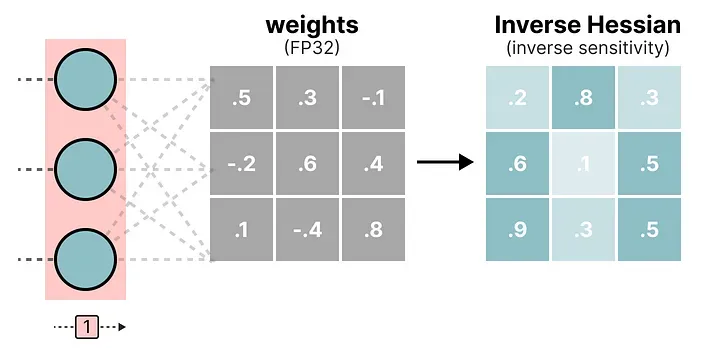
第三步:量化第一个权重并计算误差。 对权重矩阵的第一行第一个权重进行量化(FP32 → INT4),然后反量化回 FP32,得到量化误差 q。

第四步:用 Hessian 加权,把误差传播给剩余权重。 量化某个权重产生的误差 q,会根据该权重与其他权重之间的 Hessian 关联性,按比例"补偿"到本行其他还未量化的权重上。这样,其他权重在被量化时,已经把前面权重的误差吸收进去了,整体上尽可能保持这一行输出的不变性。
0.203)
例如,如果要对第二个权重进行此操作,我们就会将量化误差(q)乘以第二个权重的 Hessian 矩阵的逆矩阵()加上去。

这个过程本质上是在说:权重之间是相互关联的,一个权重的误差可以通过相邻权重的调整来弥补。GPTQ 将这种补偿系统化,在 4-bit 精度下仍能保持相当好的模型质量,并且可以将整个模型装在 GPU 上运行。
注:关于GPTQ的公式推导这里较为粗糙简洁,如想深入了解请阅读原论文或其他数学教程。
3.3.2 GGUF:灵活的分层卸载
如果 GPU VRAM 不够用,GGUF 提供了另一种思路:允许把模型的部分层卸载到 CPU 上运行,让 CPU 和 GPU 协同完成推理——虽然速度比纯 GPU 慢,但至少"跑得起来"。
GGUF 的量化机制核心是分块量化(block-wise quantization):
把一层权重按层级分成"超块(super block)"和"子块(sub block)":
- 每个超块由若干子块组成;
- 每个子块使用 absmax 量化,提取自己的缩放因子
;
- 这个
进行量化。
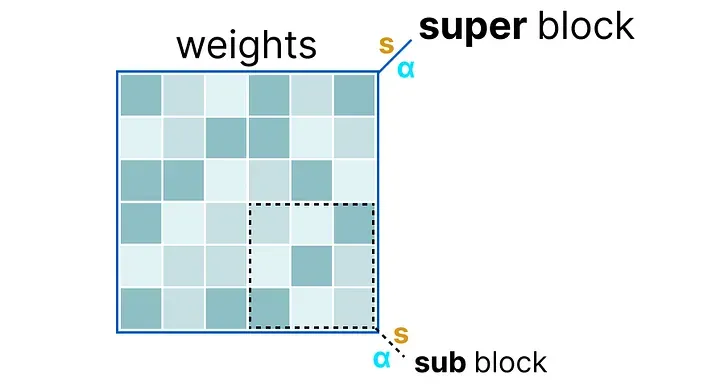
这种层级量化的好处是:不同层级可以使用不同的精度——超块的缩放因子精度较高(因为它影响范围大),子块的权重精度较低。这在整体极低 bit 的情况下,仍能通过精心设计的层级结构来控制整体误差。
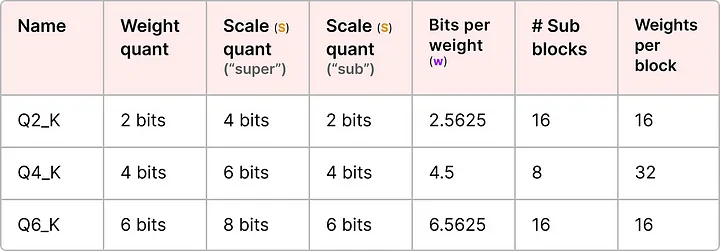
GPTQ 和 GGUF 的对比总结:
| GPTQ | GGUF | |
|---|---|---|
| 运行位置 | 全量在 GPU | 可 GPU + CPU 混合 |
| 核心原理 | Hessian 误差补偿 | 分块层级量化 |
| 适合场景 | VRAM 充足,追求推理速度 | VRAM 有限,或需要 CPU 卸载 |
第四部分:量化感知训练(QAT)
PTQ 的根本局限性在于:量化发生在训练之后,模型的权重在训练时完全不知道自己将来会被压缩——训练找到的最优解,在量化之后可能反而变差。
量化感知训练(Quantization-Aware Training,QAT)的解法是:把量化过程融入训练本身,让模型在训练时就学会"在量化条件下如何表现好"。
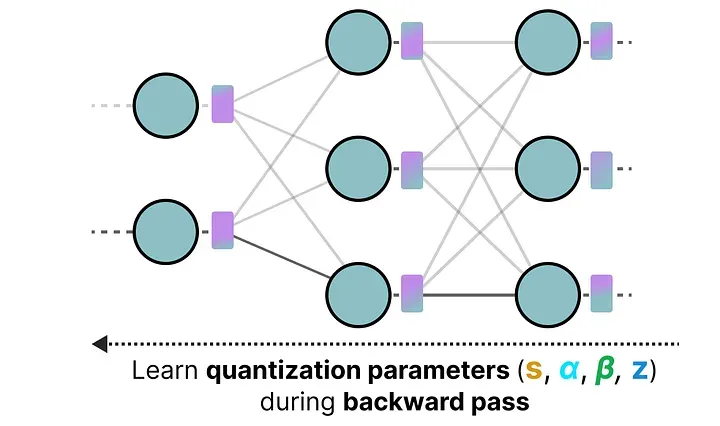
4.1 伪量化(Fake Quantization)
QAT 的具体实现方式是引入伪量化(fake quantization)节点:在前向传播时,将权重先量化(比如到 INT4),然后立刻反量化回 FP32 继续计算;损失函数因此反映了量化带来的精度损失;在反向传播时,梯度流过这个"量化-反量化"操作,通过一个叫做Straight-Through Estimator(STE)的技巧绕过不可微分的取整操作,权重得到更新。
在量化感知训练(QAT)中,权重和激活需要通过取整(round)操作变成整数,才能模拟真实推理时的量化误差。但取整是一个不可微分的操作:输入微小变化时,输出几乎不变,梯度会直接归零,导致权重无法更新。为了解决这个问题,量化训练普遍使用 Straight-Through Estimator(STE,直通估计器) 这一梯度近似技巧。
STE 的思想非常简洁:前向传播正常执行量化取整,反向传播直接忽略取整操作,让梯度 “直通” 过去。它不改变前向的量化逻辑,只在反向时把不可导的取整函数当作恒等映射,让梯度原封不动地传递给输入,从而让模型可以正常更新权重。
举一个直观例子:假设某权重的原始浮点值为
2.7,在前向传播中会经过round(2.7) = 3完成量化,参与后续计算并得到损失。反向传播时,STE 不会计算round函数的导数(原本导数为 0),而是直接将梯度原样传回给2.7这个原始值。比如回传的梯度是-0.5,权重就会按照2.7 - 学习率 × 0.5正常更新,就像中间没有经过取整一样。这种做法虽然是一种近似,但在实际训练中极其稳定:前向传播让模型持续适应量化带来的误差,反向传播保证权重朝着减小任务损失的方向优化,两者结合,就能让模型在低比特量化约束下,依然学到高精度的权重分布。

这样训练出来的权重,打从一开始就已经"适应"了量化误差的存在。
4.2 宽极值 vs 窄极值
QAT 的一个关键直觉是损失面的形状。想象模型的损失函数在参数空间形成一个高维曲面,有的地方是"宽谷"(wide minima),有的地方是"窄谷"(narrow minima)。
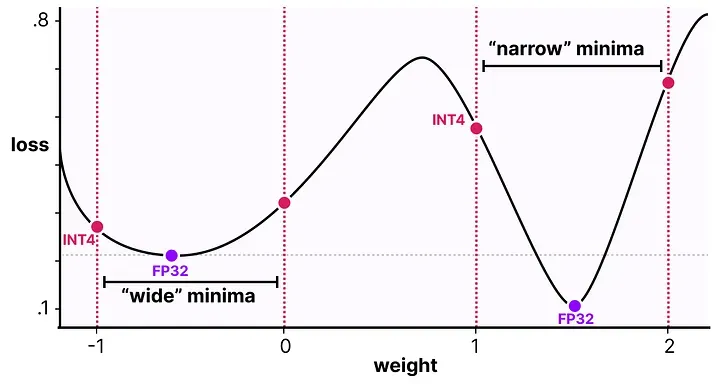
PTQ 找到的最优权重可能正好落在一个窄谷里——在高精度下损失很低,但一量化权重稍微移动,损失就猛烈反弹。
QAT 通过在训练中引入量化扰动,引导优化器找到宽谷中的解——在高精度下损失可能稍微高一点点,但量化之后损失变化不大,最终低精度下的表现反而更好。
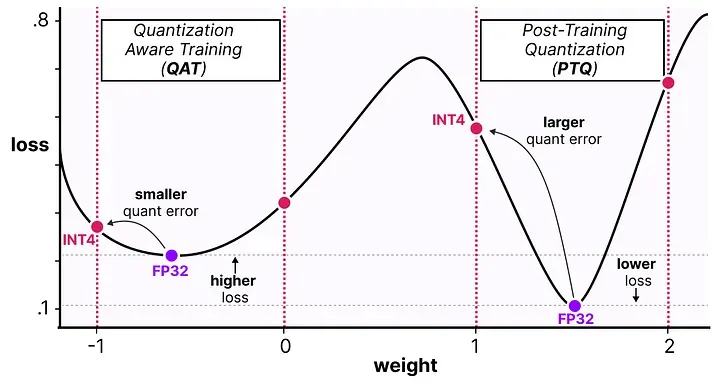
结论:QAT 在低精度下通常比 PTQ 表现更好,代价是需要额外的训练计算资源。
第五部分:极限压缩——BitNet 与 1-bit 时代
如果说 4-bit 已经很激进了,研究者们还在继续追问:能不能更少?
5.1 BitNet:把权重压到 1-bit
BitNet(2023 年)将大胆的想法付诸实现:模型的每个权重只能取 -1 或 +1 两个值。整个网络的权重矩阵变成了一张"正负号表格"。
BitNet 直接修改了 Transformer 的架构:把标准的线性层(Linear layer)替换为BitLinear 层,将权重存储和计算统一在 1-bit 框架下。
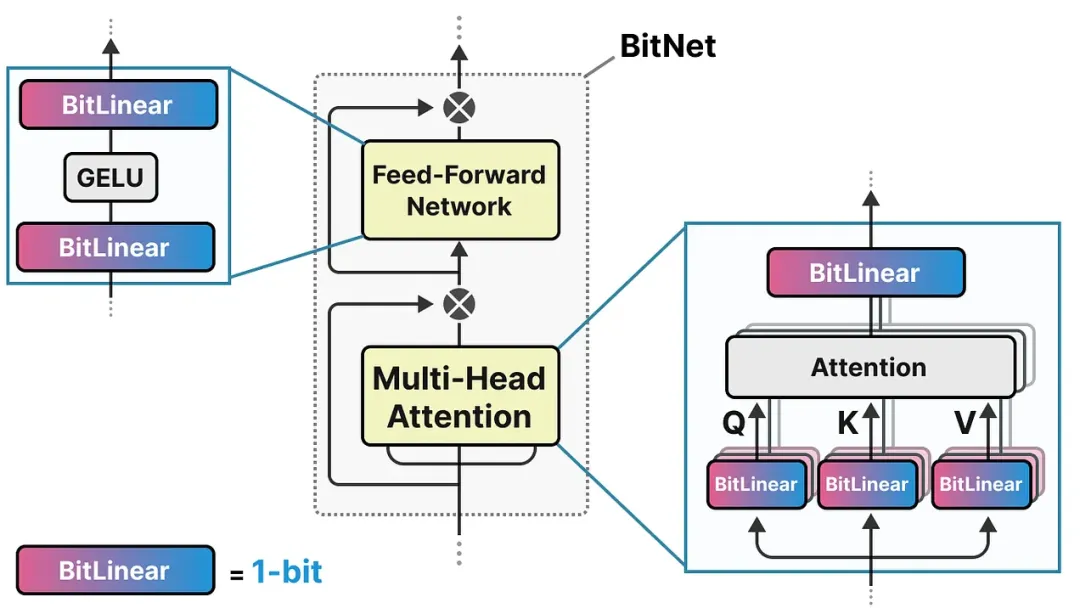
BitLinear 层的工作流程:
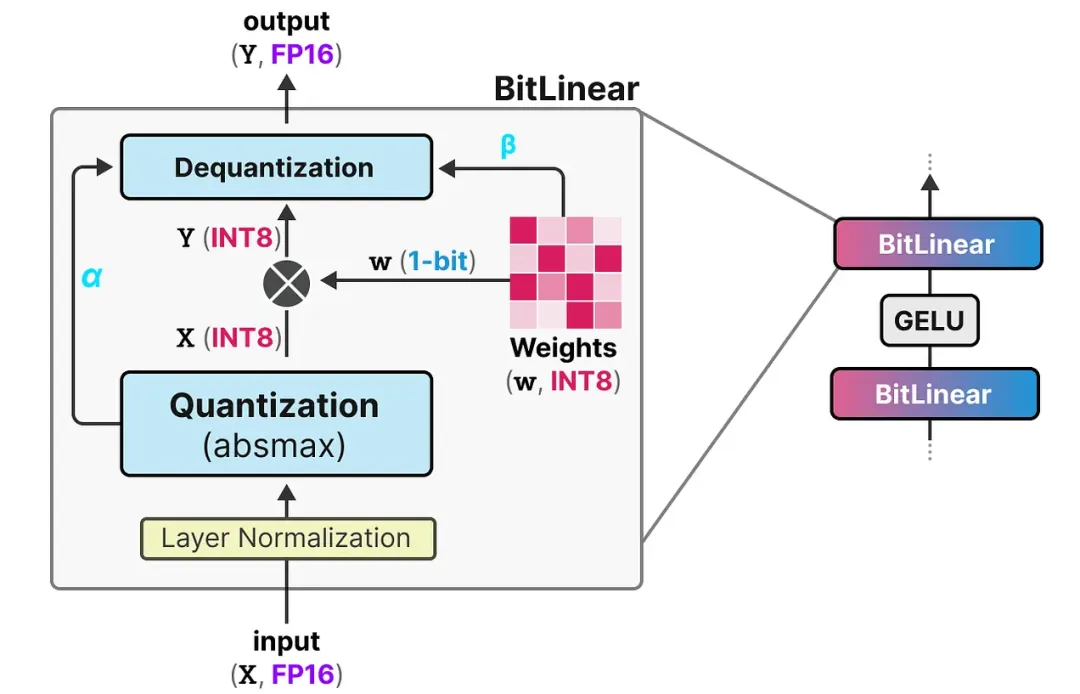
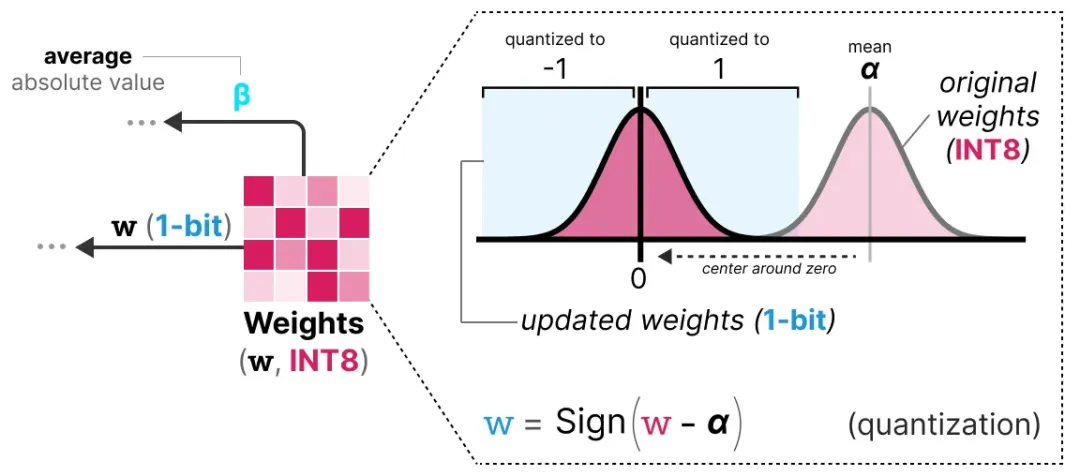
权重量化:训练时权重存储为 INT8,每次前向传播时用 signum 符号函数将其压成 1-bit:先把权重分布中心化(减去均值),然后大于等于 0 的变成 +1,小于 0 的变成 -1。同时记录下权重的平均绝对值 β,用于后续反量化。
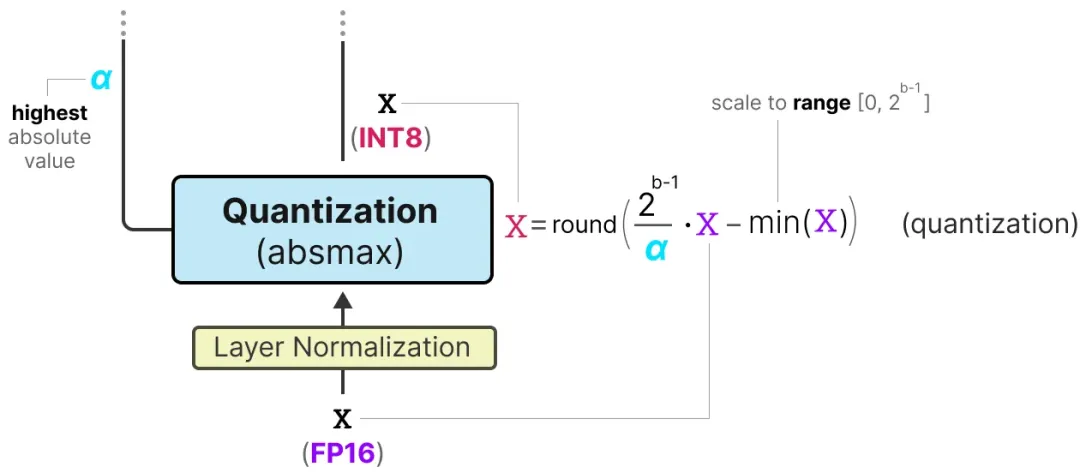
激活量化:激活值用 absmax 量化从 FP16 转为 INT8,并记录激活值的最大绝对值 α。
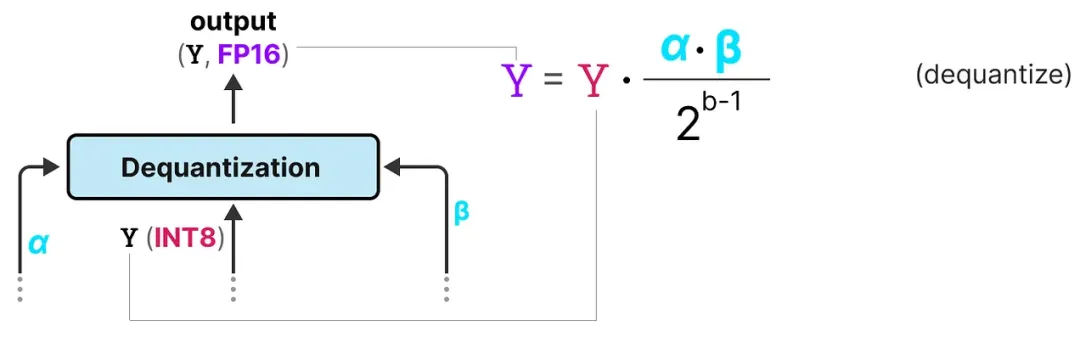
矩阵乘法 + 反量化:用 1-bit 权重与 INT8 激活做矩阵乘法,然后用保存的 α 和 β 缩放,将结果反量化回 FP16。
BitNet 的实验发现:随着模型参数量的增大(>30B),1-bit 训练和 FP16 训练之间的性能差距在缩小。小模型的差距仍然明显,但大模型中 1-bit 逐渐可以"追上来"。
5.2 BitNet b1.58:加入"0",性能飞跃
BitNet b1.58(2024 年)做了一个看似微小实则关键的改动:在 -1 和 +1 的基础上,允许权重取 0,变成三元值 {-1, 0, +1}。
这个 0 的加入,从信息论角度看只是从 1-bit 增加了极少量信息(log₂3 ≈ 1.58 bit,这就是"1.58"的由来),但从计算效率角度看,意义重大。
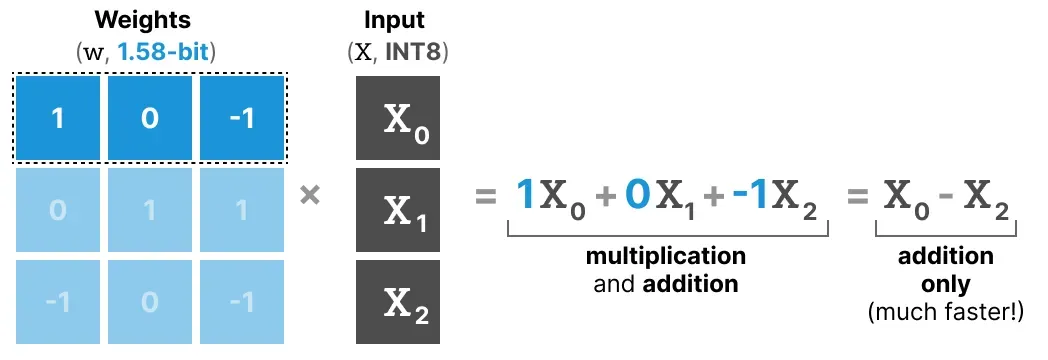
原因在于:传统矩阵乘法需要大量"乘法 + 加法"的组合。而当权重只有 {-1, 0, +1} 时:
- 权重 = +1:把这个激活值加进来
- 权重 = 0:忽略这个激活值
- 权重 = -1:把这个激活值减掉
不再需要任何乘法,只需要加法和减法——这在硬件层面可以带来极大的效率提升。同时,0 权重天然实现了特征过滤,模型可以选择性地忽略某些输入维度,而不是像 1-bit 那样被迫对每个值要么加要么减。
权重量化方法:BitNet 1.58b 使用绝对均值量化(absmean quantization)——以权重的绝对均值 α 为尺度,将每个权重除以 α 后取整到最近的 -1、0 或 +1。
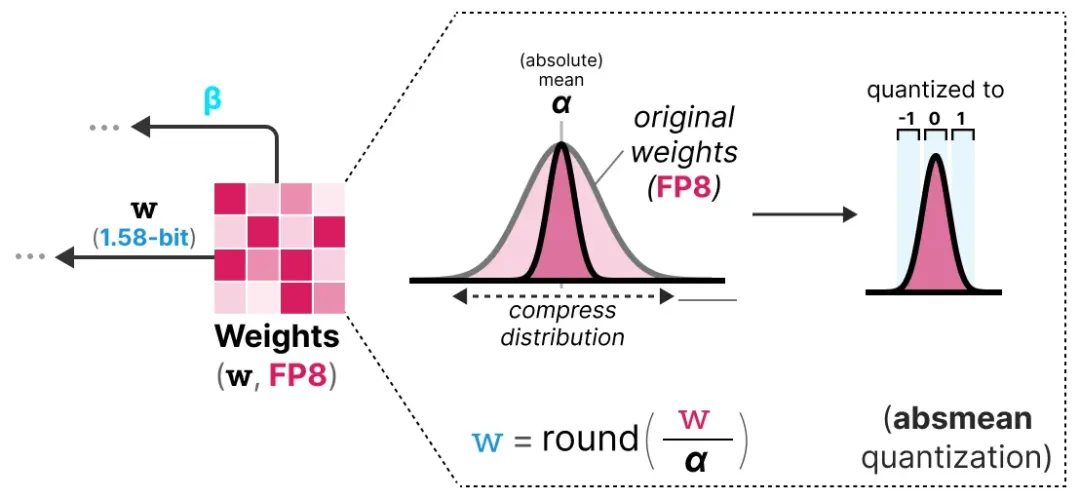
实验数据颇为惊人:论文指出,13B 参数的 BitNet b1.58 模型在延迟、内存和能耗上,全面优于 3B 参数的 FP16 模型——用更少的权重位数,实现了更好的效率,同时维持了相当的能力。
总结:量化的全景地图
至此,我们走完了量化技术的完整旅程。回顾一下核心脉络:
为什么需要量化:大模型参数量庞大,用全精度 FP32 存储时内存需求极高。量化通过降低每个参数的 bit 数,大幅减少内存占用,同时通常也加速推理。
量化的基本操作:无论哪种方案,核心都是设计一个从浮点值到低 bit 整数的映射——对称量化(absmax)和非对称量化(zero-point)是两种基础形式,Clipping 和 Calibration 是处理异常值、找到最优映射范围的手段。
PTQ 的两条路:动态量化(精度高,稍慢)和静态量化(速度快,需要校准集)分别适合不同场景。
进一步压缩的工程方案:GPTQ 用二阶导数信息做误差补偿,实现高质量 4-bit 量化;GGUF 用分块层级结构实现灵活的 CPU+GPU 混合部署。
QAT:让量化感知嵌入训练过程,找到对量化更鲁棒的权重解,低精度下表现优于 PTQ。
极限压缩:BitNet 和 BitNet b1.58 把权重压到 1-bit 和 1.58-bit,将矩阵乘法变成加减法,代表了量化技术的前沿探索方向。
量化还在快速发展中。从 GPTQ 到 AWQ,从 BitNet 到最新的各种混合精度方案,研究者们不断在"模型质量"与"计算效率"之间寻找更好的平衡点。可以预见,随着硬件对低精度计算的原生支持越来越完善,量化技术将在大模型落地部署中扮演越来越核心的角色。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)