[ 开源 ] FastAPI + LangGraph 实战智能客服 Agent:从工单分类到自动回复与业务回写 附github
github地址 https://github.com/baibai-awd/customer-support-agent.git
这篇文章分享一个 customer-support-agent 智能客服工单处理项目:它不是只做“AI 自动回复”,而是把客服工单处理拆成分类、检索、回复生成、人工介入判断、业务系统回写、指标评估几个可落地环节。
项目目标很明确:让客服 Agent 不只是能聊天,还能进入真实业务流程,并且能用数据衡量它到底节省了多少人工处理时间。
项目图片
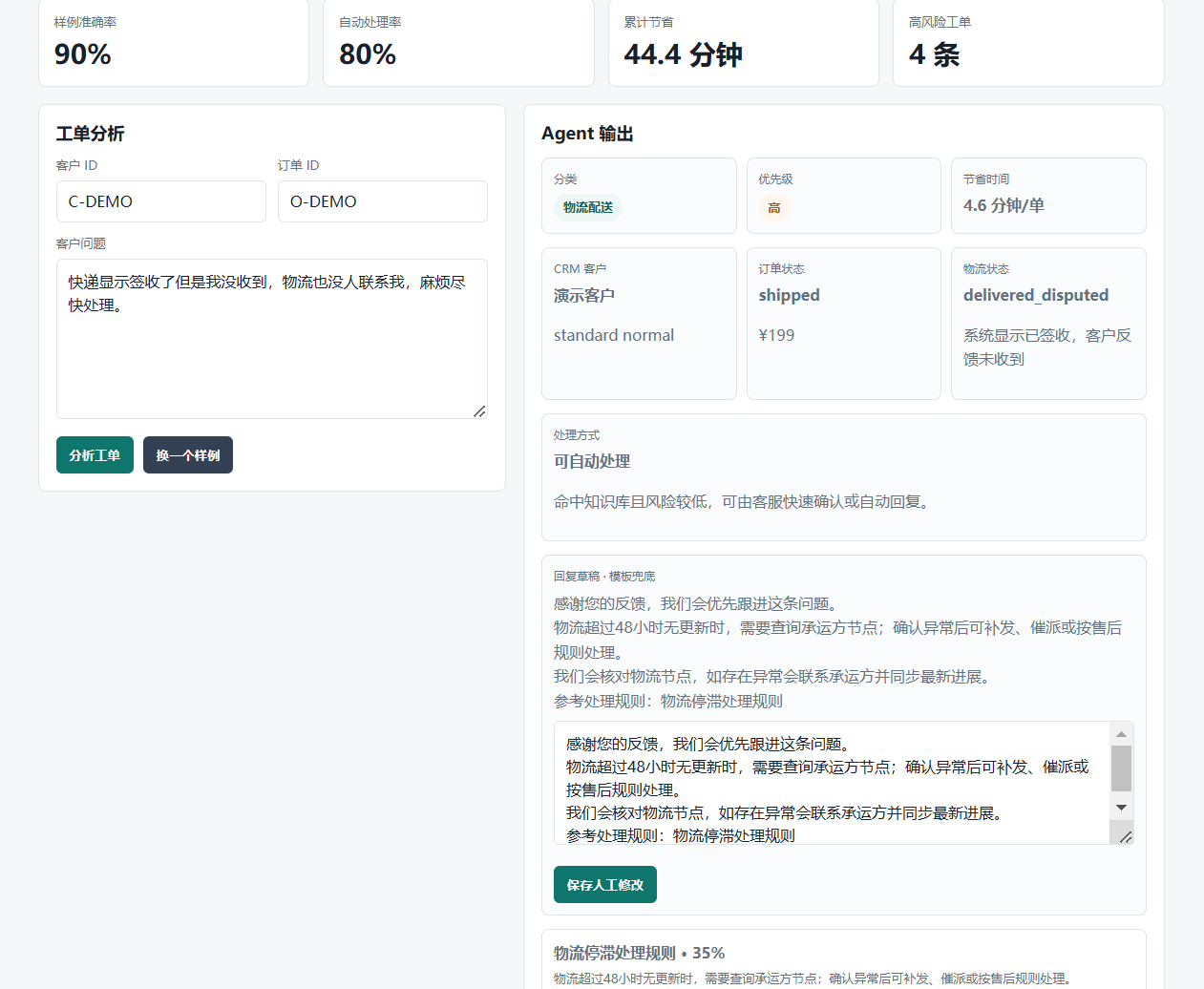
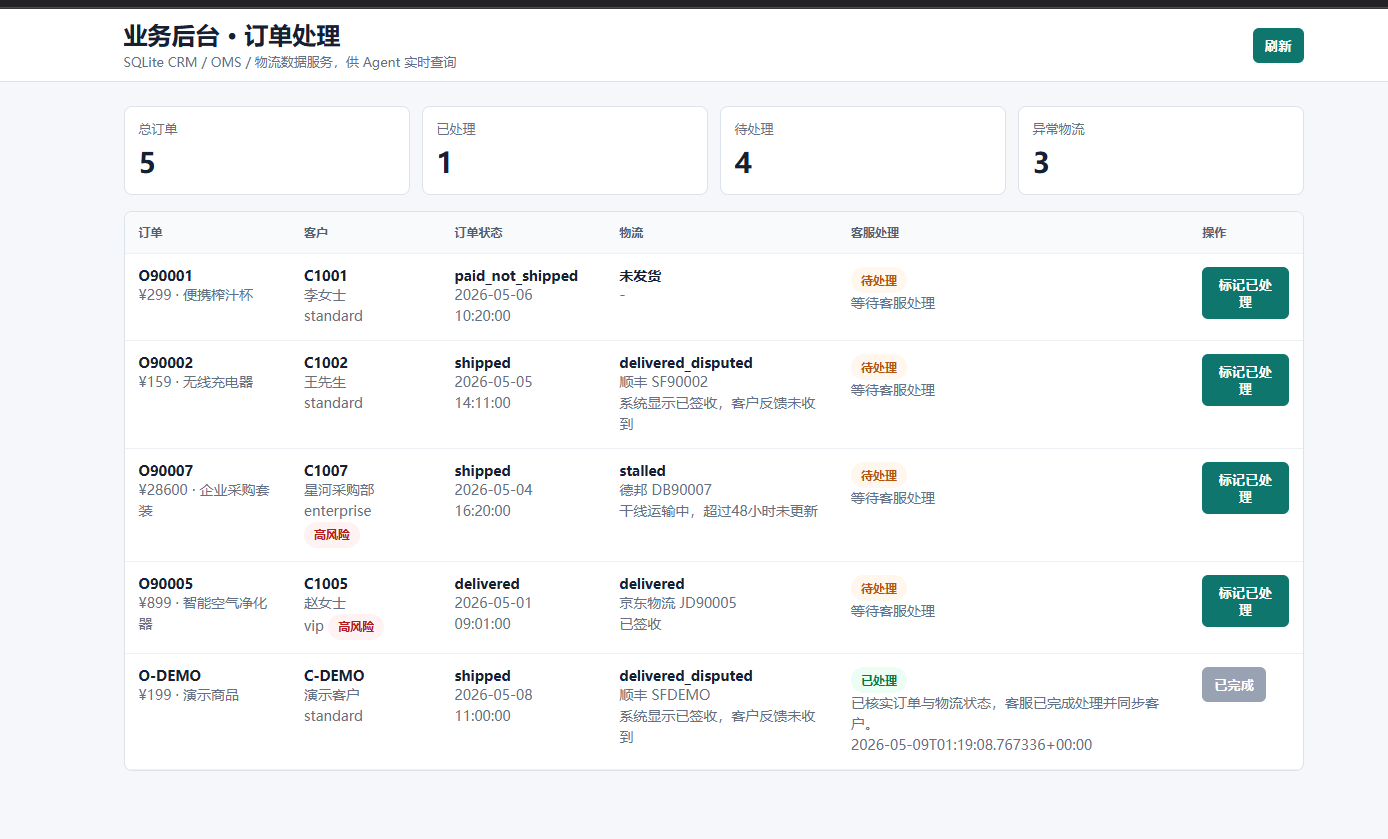
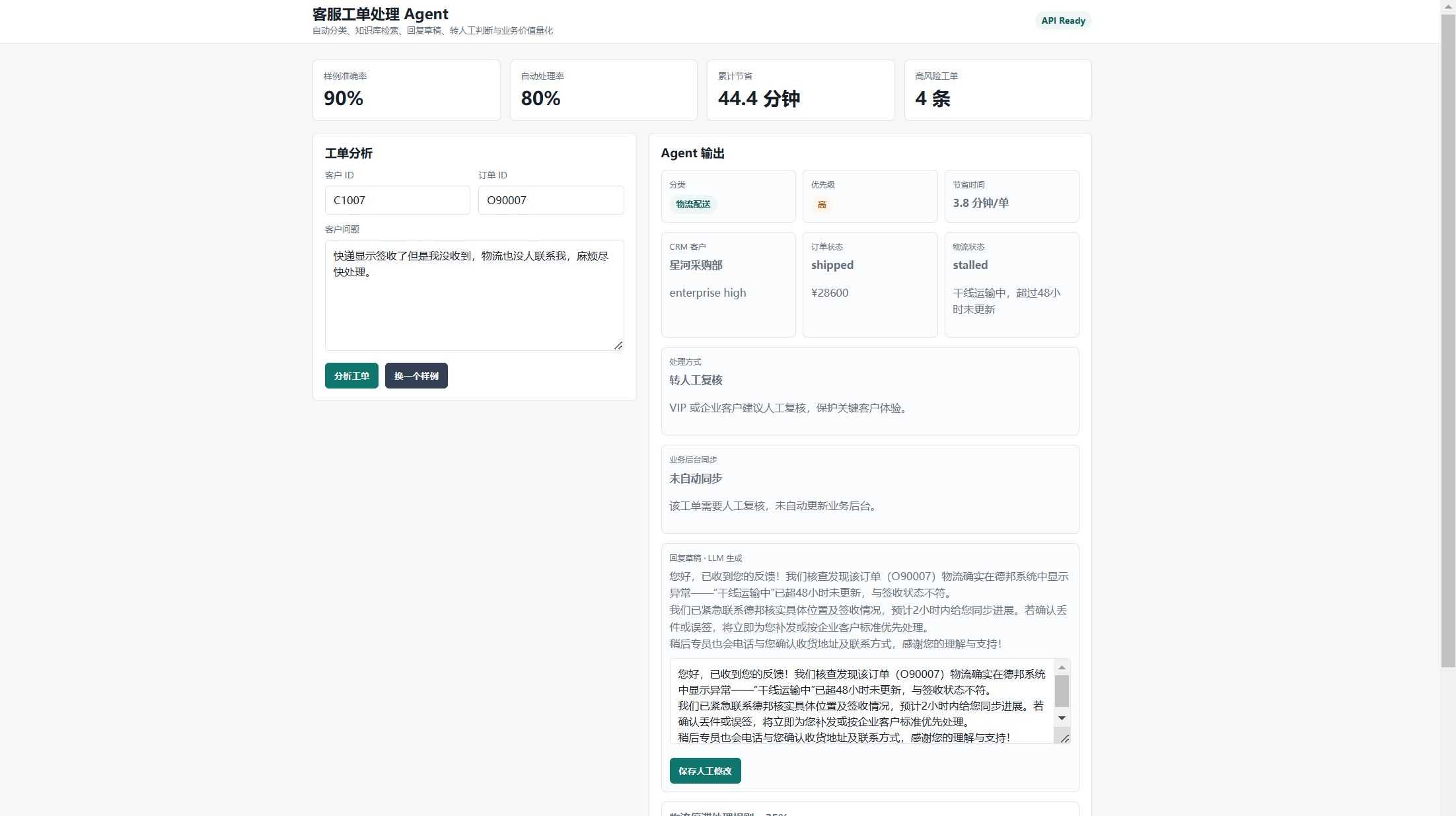
一、项目能解决什么问题?
传统客服系统里,用户咨询通常需要人工先判断问题类型,再查询订单、物流、客户信息,然后根据知识库写回复。如果咨询量变大,重复工单会占用大量时间。
这个项目做了一个 MVP 版本的智能客服 Agent,支持:
- 自动识别工单类型:退款、物流、账号、商品、投诉、发票等;
- 结合 CRM、订单、物流上下文判断优先级;
- 使用 RAG 知识库检索相关处理规则;
- 生成客服可审核的中文回复草稿;
- 判断是否需要转人工;
- 自动同步低风险订单处理状态;
- 统计分类准确率、自动处理率、节省工时、高风险工单数;
- 保存人工修改反馈,为后续优化回复质量做准备。
二、整体技术栈
项目主要使用:
- FastAPI:提供 Agent API、业务后台 API 和静态页面;
- LangGraph:编排工单处理流程;
- Pydantic:定义请求、响应、分类结果、业务上下文等结构化数据;
- OpenAI 兼容接口:可接入 Qwen、OpenAI 或其他兼容模型;
- SQLite:模拟业务系统和反馈数据存储;
- 本地 RAG 向量检索:使用 hashed n-gram embedding 实现轻量知识库召回;
- SSE:支持流式输出回复内容。
依赖配置在 pyproject.toml 中,核心依赖包括:
dependencies = [ "fastapi>=0.110.0", "httpx>=0.27.0", "langgraph>=0.2.0", "openai>=1.0.0", "python-dotenv>=1.0.0", "pydantic>=2.6.0", "uvicorn>=0.27.0", ]
三、Agent 的核心流程
这个项目的 Agent 流程非常清晰:
classify -> retrieve -> draft -> evaluate
对应含义如下:
| 阶段 | 作用 |
|---|---|
| classify | 读取客户、订单、物流上下文,并完成问题分类、优先级和风险标记 |
| retrieve | 根据用户问题和分类结果检索知识库 |
| draft | 优先调用 LLM 生成自然回复;未配置模型时使用模板兜底 |
| evaluate | 判断是否转人工,并计算节省工时、处理模式、业务价值指标 |
项目中的核心代码在:
customer-support-agent/app/agents/ticket_agent.py
LangGraph 编排逻辑大致如下:
graph = StateGraph(TicketState) graph.add_node("classify", self._classify) graph.add_node("retrieve", self._retrieve) graph.add_node("draft", self._draft) graph.add_node("evaluate", self._evaluate) graph.set_entry_point("classify") graph.add_edge("classify", "retrieve") graph.add_edge("retrieve", "draft") graph.add_edge("draft", "evaluate") graph.add_edge("evaluate", END)
这种写法的好处是:每一步都能单独测试,也方便后续扩展,比如增加质检节点、A/B 测试节点、人工反馈学习节点等。
四、工单分类:先判断用户到底在问什么
项目里定义了几类常见客服问题:
refund 退款 logistics 物流 account 账号 product 商品 complaint 投诉 invoice 发票 other 其他
分类逻辑会根据关键词匹配用户输入,并输出:
- category:问题类型;
- priority:优先级;
- confidence:置信度;
- matched_keywords:命中的关键词;
- risk_flags:风险标记。
例如用户说:
快递显示签收了,但是我没有收到,物流也没人联系我。
系统会倾向于识别为物流类问题,并继续查询订单和物流上下文。
更关键的是,分类结果还会被业务上下文增强。例如:
- 如果客户是 VIP 或企业客户,优先级会提高;
- 如果客户风险等级为 high,会加入风险标记;
- 如果物流状态是 stalled 或 delivered_disputed,也会提高处理优先级。
五、RAG 知识库:让回复有依据
项目没有强依赖外部向量数据库,而是实现了一个轻量本地 RAG 检索。
核心思路是:
- 读取 knowledge_base.json 中的知识库文章;
- 将标题、答案、关键词、分类拼成文章文本;
- 对中文字符生成 1-gram、2-gram、3-gram;
- 使用 hash bucket 构造稀疏向量;
- 通过余弦相似度、关键词重合度、分类加权综合打分;
- 返回 Top-K 知识库命中结果。
这个设计适合教学和 MVP,因为它不需要额外部署 FAISS、Chroma 或 Embedding 服务,但保留了和真实向量检索类似的接口。后续如果要升级,只需要把 _embed 替换成真实 embedding 模型即可。
六、回复生成:LLM 优先,模板兜底
项目支持两种回复方式:
| 模式 | 说明 |
|---|---|
| structured_llm | 使用 LLM 生成结构化决策和回复 |
| llm | 使用普通 LLM 回复生成 |
| template | 未配置模型或模型失败时使用模板兜底 |
这点很实用。很多 AI 项目一旦没有 API Key 就无法演示,而这个项目即使不配置大模型,也能完整跑通工单分类、知识库检索、回复草稿、人工介入判断和指标统计。
如果要启用 LLM,可以配置:
SUPPORT_AGENT_LLM_ENABLED=true SUPPORT_AGENT_LLM_API_KEY=your-api-key SUPPORT_AGENT_LLM_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1 SUPPORT_AGENT_LLM_REPLY_MODEL=qwen-plus SUPPORT_AGENT_LLM_TIMEOUT_SECONDS=45
同时也兼容常见 OpenAI 风格变量:
OPENAI_API_KEY=your-api-key OPENAI_BASE_URL=your-base-url DASHSCOPE_API_KEY=your-api-key DASHSCOPE_BASE_URL=your-base-url
七、转人工判断:不是所有问题都适合自动处理
客服 Agent 不能盲目自动回复,尤其是投诉、VIP 客户、低置信度、高风险情绪类工单。
项目中会在以下情况建议转人工:
- 命中紧急语气或强负面情绪;
- 工单类型是投诉;
- 客户是 VIP 或企业客户;
- 分类置信度偏低;
- 没有匹配到知识库规则;
- LLM 结构化决策明确要求人工复核。
这样可以保证低风险问题尽量自动化,高风险问题交给人工审核,比较符合真实客服系统的落地方式。
八、业务系统集成:不止生成回复,还能回写状态
项目内置了一个 SQLite 业务系统后端,用来模拟真实 CRM、订单系统和物流系统。
启动后可以访问:
http://127.0.0.1:8011/admin
业务后台支持查看订单处理状态,也可以查看 Agent 分析记录和转人工队列:
http://127.0.0.1:8011/admin/escalations
Agent 每次分析工单时,会把分析记录保存到业务系统中,包括:
- 分类结果;
- 优先级;
- 回复来源;
- 回复草稿;
- 是否转人工;
- 预计节省工时;
- 自动回写结果。
如果判断为低风险可自动处理,系统还会同步订单状态;如果需要人工复核,则不会自动更新业务后台。
九、API 使用示例
先启动业务系统后端:
uv run uvicorn app.business_api:app --reload --port 8011
再启动 Agent API:
uv run uvicorn app.main:app --reload --port 8010
分析单条工单:
curl -X POST http://127.0.0.1:8010/api/tickets/analyze ^ -H "Content-Type: application/json" ^ -d "{\"customer_id\":\"C1001\",\"order_id\":\"O90001\",\"message\":\"快递显示签收了,但是我没有收到,物流也没人联系我。\"}"
流式分析工单:
curl -N -X POST http://127.0.0.1:8010/api/tickets/analyze/stream ^ -H "Content-Type: application/json" ^ -d "{\"customer_id\":\"C1001\",\"order_id\":\"O90001\",\"message\":\"快递显示签收了,但是我没有收到,物流也没人联系我。\"}"
SSE 事件顺序如下:
classified -> retrieved -> reply_source -> reply_delta... -> completed
查看样例集评估:
curl -X POST http://127.0.0.1:8010/api/evaluate
查看看板数据:
curl http://127.0.0.1:8010/api/dashboard
查询外部系统上下文:
curl "http://127.0.0.1:8010/api/integrations/context?customer_id=C1007&order_id=O90007"
保存人工修改反馈:
curl -X POST http://127.0.0.1:8010/api/feedback/revisions ^ -H "Content-Type: application/json" ^ -d "{\"ticket_id\":\"T-DEMO\",\"original_reply\":\"原回复\",\"revised_reply\":\"人工修改后的回复\",\"category\":\"logistics\",\"accepted\":false,\"editor\":\"agent-reviewer\"}"
十、可量化指标:衡量 Agent 到底有没有业务价值
我觉得这个项目最值得保留的设计,是它没有只停留在“能生成回复”,而是把业务价值量化出来。
默认假设:
- 人工完整处理一单平均 5 分钟;
- Agent 生成草稿后人工复核平均 1.2 分钟;
- 低风险自动处理平均 0.4 分钟。
因此每条工单都会输出:
estimated_minutes_saved business_value
样例集评估会汇总:
- total_tickets:总工单数;
- classification_accuracy:分类准确率;
- auto_handle_rate:自动处理率;
- escalation_rate:转人工率;
- total_minutes_saved:总节省工时;
- avg_minutes_saved_per_ticket:平均每单节省时间;
- high_risk_tickets:高风险工单数;
- category_distribution:分类分布。
这对企业落地 AI Agent 非常重要,因为最后能回答一个问题:这个 Agent 到底节省了多少人力,降低了多少重复处理成本。
十一、项目亮点总结
这个 customer-support-agent 项目适合作为智能客服 Agent 的实战 Demo,亮点包括:
- 使用 LangGraph 把 Agent 流程显式编排,结构清楚;
- 支持分类、RAG、回复生成、转人工判断的完整链路;
- 支持 LLM 和模板两种回复模式,演示稳定;
- 使用 SSE 实现流式回复体验;
- 接入业务后台,能模拟订单处理状态回写;
- 提供反馈保存接口,方便后续做质量优化;
- 通过指标看板量化 Agent 的业务价值。
十二、后续可以怎么升级?
后续可以继续增强:
- 把本地 hashed embedding 替换成真实 embedding 模型;
- 接入真实 CRM、OMS、物流 API;
- 增加回复质量评分和合规质检;
- 把人工修改反馈沉淀成评估集;
- 做不同 Prompt 或模型的 A/B 测试;
- 增加多轮追问能力;
- 引入工单 SLA 和优先级调度。
结语
这个项目的重点不是炫技,而是把 AI Agent 放进真实客服流程里:先识别问题,再查业务上下文,再找知识库依据,再生成回复,最后判断是否可以自动处理,并把结果回写到业务系统。
如果你正在学习 LangGraph、FastAPI 或智能客服 Agent,这个项目可以作为一个不错的实战起点。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)