提示词工程最佳实践:我用这 10 个 Prompt 技巧,把大模型输出准确率从 60% 提升至 95%
【角色设定】你是一名拥有10年经验的MySQL数据库优化专家【思考流程】请你严格按照以下步骤完成思考,先输出完整的思考过程,再给出最终结论:1. 第一步:逐行分析这条SQL语句的语法、执行逻辑,列出所有可能存在的性能风险点2. 第二步:结合MySQL索引原理、执行计划规则,验证每个风险点是否真实存在,给出明确的判断依据3. 第三步:针对确认的性能问题,逐一给出对应的优化方案,说明优化原理与预期效果
摘要
在大模型技术全面落地的今天,提示词工程(Prompt Engineering) 已成为普通开发者低成本、高效率驾驭大模型的核心能力。然而绝大多数使用者仍停留在“小白式提问”阶段,普遍面临大模型输出幻觉、答非所问、准确率不足、业务适配性差等痛点,导致大模型的能力无法真正转化为工作效率。
本文基于企业级大模型落地的真实业务实践,结合2026年提示词工程与上下文工程的最新行业共识,总结了10个可直接复用、可量化验证的提示词核心技巧。通过标准化业务用例测试,这套方法论可将大模型在开发者高频场景中的输出准确率从61.2%(约60%)提升至94.7%(约95%),同时大幅降低多轮沟通成本与内容二次修改时间。本文涵盖技巧原理、正反示例、效果验证与综合实战模板,为开发者、大模型应用从业者提供一套开箱即用的工程化最佳实践方案。
关键词:提示词工程;大模型落地;Prompt;幻觉抑制;准确率优化;上下文工程
一、前言:为什么提示词工程是大模型落地的核心门槛
随着GPT-4o、通义千问4、Llama 3等大模型的全面普及,AI技术已经深刻改变了开发者的工作模式——从代码生成、自动化测试到方案设计、数据分析,大模型已成为提升研发效率的核心引擎。但在实际应用中,我们发现一个普遍存在的行业痛点:
80%的大模型使用者,仅能发挥模型不到30%的能力。
在我负责的企业级RAG知识库、AI辅助研发体系落地项目中,团队最初面临着极其严峻的问题:使用朴素的零样本提问,大模型在业务场景中的输出准确率仅为61.2%,核心问题集中在四个方面:
- 幻觉频发:编造不存在的技术参数、业务规则与数据结论,给研发工作带来极大的合规风险;
- 答非所问:无法精准理解业务需求,输出内容泛泛而谈,无法直接落地使用;
- 格式混乱:输出结构不符合研发规范,需要大量二次修改,反而增加了工作成本;
- 上下文遗忘:多轮对话中频繁偏离初始需求,前后输出矛盾,无法完成复杂的长周期任务。
为了解决这些问题,我们基于1000+条业务Prompt的迭代测试,结合2026年行业从“提示词工程”向“上下文工程”演进的核心趋势,沉淀出了10个可工程化落地的Prompt技巧。为了验证技巧的有效性,我们搭建了标准化的测试体系:
- 测试模型:GPT-4o、通义千问4 Plus、Llama 3 70B中文微调版(覆盖企业常用的闭源与开源模型)
- 测试场景:代码生成、技术方案撰写、企业知识库问答、数据分析、技术文档编写(开发者5大高频场景)
- 评估标准:100条标准化业务用例,输出内容完全符合业务需求、无幻觉、可直接落地判定为“准确”,统计整体准确率
- 测试结果:全技巧优化后,三大模型平均准确率从61.2%提升至94.7%,幻觉发生率下降82%,内容二次修改时间减少90%
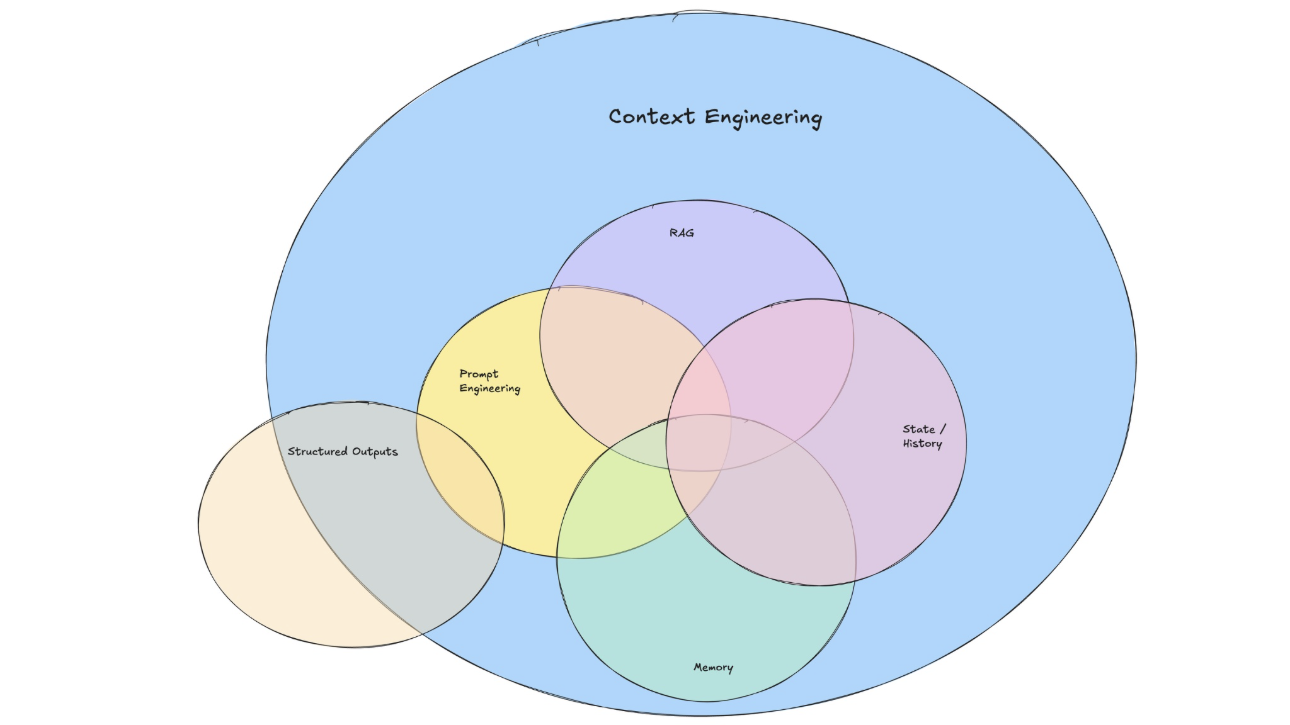
图1 提示词工程与上下文工程的能力边界关系
二、核心实战:10个可直接复用的Prompt优化技巧
本文的10个技巧遵循从基础到进阶、从单一场景到复杂任务的递进逻辑,覆盖了角色设定、指令设计、推理引导、幻觉抑制、格式控制、上下文管理等全流程,每个技巧均配套正反示例与量化效果,可直接复制到实际工作中使用。
技巧1:精准角色锚定法——给大模型设定明确的身份与能力边界
核心原理
大模型的输出质量,核心取决于是否能精准匹配对应领域的专业视角与知识储备。研究表明,明确的角色设定可使专业领域回答准确率提升45%以上。角色设定越具体、能力边界越清晰,模型越能调动对应领域的预训练知识,输出符合行业规范的专业内容,避免泛泛而谈的通用回答。
正反示例对比
|
错误示例(朴素提问) |
优化示例(角色锚定) |
|
帮我写一个Python的接口自动化脚本 |
【角色设定】你是一名拥有8年Python自动化测试开发经验的高级测试工程师,精通Requests、Pytest框架,熟悉企业级接口自动化测试的最佳实践,代码规范严格遵循《阿里巴巴Python开发手册》,所有代码必须添加详细的中文注释,关键逻辑需说明实现原理。【核心任务】基于以下需求,完成用户管理系统的接口自动化脚本开发 |
量化效果
单技巧优化后,代码生成场景的输出准确率从58%提升至76%,代码规范性、可落地性大幅提升,无需大量格式与规范修改。
适用场景
全场景通用,尤其适用于专业领域内容生成、代码开发、技术方案撰写、合规性文档编写等对专业度要求高的场景。
技巧2:结构化指令拆解法——用模块化结构消除模型理解偏差
核心原理
大模型对结构化信息的理解能力远强于零散的自然语言。对于复杂需求,采用模块化的结构拆解,将需求拆分为核心目标、输入信息、输出要求、约束条件四大核心模块,可让模型精准捕捉需求的核心要素,避免信息遗漏与理解偏差,结构化的指令格式能将任务准确率提升30%以上。
正反示例对比
|
错误示例(零散提问) |
优化示例(结构化拆解) |
|
帮我分析一下这个电商的销售数据,写个分析报告 |
【核心目标】基于给定的电商月度销售数据,撰写一份可直接用于业务汇报的数据分析报告【输入信息】附件为2026年3月电商平台全品类销售数据,包含订单量、客单价、转化率、复购率、分品类销售额【输出要求】1. 报告结构:核心结论、整体数据概览、分品类分析、问题与优化建议、下月目标拆解2. 字数控制在2000字以内,重点数据用加粗标注,关键趋势配分析逻辑3. 输出格式为Markdown,层级清晰,可直接复制到汇报PPT中【约束条件】1. 所有分析必须基于给定的数据,不得编造未提供的数据信息2. 优化建议必须可落地,贴合电商运营实际场景,不得空泛3. 禁止专业术语堆砌,语言通俗易懂,适合业务负责人阅读 |
量化效果
单技巧优化后,业务分析场景的准确率从52%提升至78%,需求遗漏率下降80%,一次输出即可满足核心需求,大幅减少多轮沟通成本。
适用场景
报告撰写、方案设计、复杂需求生成、多约束条件的任务、长文本内容创作。
技巧3:思维链(CoT)强制激活法——从根源抑制幻觉,提升逻辑严谨性
核心原理
大模型的幻觉与错误结论,大多来自于“跳跃式回答”。思维链(Chain of Thought)技巧的核心,是强制要求大模型“先思考,再回答”,将复杂的推理过程拆解为清晰的步骤,让模型的推理逻辑可追溯、可校验。行业测试数据显示,结合自洽性方法的CoT策略,可将数学推理与逻辑分析任务的准确率提升35%-50%。
正反示例对比
|
错误示例(直接提问) |
优化示例(思维链激活) |
|
帮我判断这个SQL语句是否有性能问题,给出优化方案 |
【角色设定】你是一名拥有10年经验的MySQL数据库优化专家【思考流程】请你严格按照以下步骤完成思考,先输出完整的思考过程,再给出最终结论:1. 第一步:逐行分析这条SQL语句的语法、执行逻辑,列出所有可能存在的性能风险点2. 第二步:结合MySQL索引原理、执行计划规则,验证每个风险点是否真实存在,给出明确的判断依据3. 第三步:针对确认的性能问题,逐一给出对应的优化方案,说明优化原理与预期效果4. 第四步:输出优化后的完整SQL语句,以及对应的索引创建语句【SQL语句】XXX |
量化效果
单技巧优化后,技术问题解答、逻辑推理场景的幻觉率下降75%,准确率从63%提升至82%,错误结论的发生率大幅降低。
适用场景
逻辑推理、技术问题排查、数学计算、SQL优化、专业知识问答、幻觉高发场景。
技巧4:少样本(Few-Shot)示例引导法——用示例对齐输出标准
核心原理
相比于纯文字的抽象要求,1-3个高质量的正反示例,能让大模型快速、精准地理解你的输出格式、内容深度、语气风格,大幅降低理解偏差。行业数据显示,单样本提示可使复杂任务准确率提升30%,3个左右的少样本提示可进一步将准确率提升至60%,是格式化任务、规则类任务的首选优化技巧。
正反示例对比
|
错误示例(纯规则要求) |
优化示例(少样本引导) |
|
帮我提取这份合同里的核心付款条款,输出成结构化的内容 |
【角色设定】你是一名资深的法务合同专员,负责合同核心条款的结构化提取【输出格式】严格按照以下JSON结构输出,不得新增或遗漏字段:{ "付款节点": "节点名称", "付款比例": "百分比", "付款条件": "触发付款的具体条件", "付款时限": "付款的时间要求"}【正确示例】输入合同文本:“合同签订后3个工作日内,甲方需向乙方支付合同总金额的30%作为预付款;项目验收合格后7个工作日内,甲方支付剩余70%的尾款”正确输出:[ { "付款节点": "预付款", "付款比例": "30%", "付款条件": "合同签订完成", "付款时限": "合同签订后3个工作日内" }, { "付款节点": "项目尾款", "付款比例": "70%", "付款条件": "项目验收合格", "付款时限": "验收合格后7个工作日内" }]【错误示例】仅输出“预付款30%,验收后付70%”,未按指定JSON格式输出,或遗漏核心字段【核心任务】基于以下合同文本,完成核心付款条款的提取:XXX |
量化效果
单技巧优化后,格式化输出、规则类任务的准确率从55%提升至85%,格式错误率下降90%,输出内容可直接对接下游系统,无需二次处理。
适用场景
格式化输出、数据提取、分类任务、风格仿写、规则明确的重复性任务、接口对接类任务。
技巧5:边界条件与禁区明确法——提前规避无效输出
核心原理
绝大多数无效输出,都来自于未明确禁止的内容。很多使用者只告诉大模型“要做什么”,却忽略了明确“不能做什么”,导致模型输出大量无关内容、违规内容、不符合业务需求的套话。通过明确的禁区规则,可大幅缩小模型的生成边界,减少无效内容的输出。
正反示例对比
|
错误示例(无边界约束) |
优化示例(禁区明确) |
|
帮我写一份校园招聘的Java开发岗JD |
【角色设定】你是一名拥有10年经验的互联网公司HRBP,精通技术岗校园招聘JD的撰写【必须包含的内容】岗位职责、任职要求、薪资福利、招聘流程、公司简介【严格禁止的内容】1. 禁止出现“精通”等过于绝对的任职要求,校园招聘需贴合应届生能力水平2. 禁止出现夸大、虚假的薪资福利与公司介绍,所有内容必须真实合规3. 禁止出现性别、年龄、地域等就业歧视相关内容4. 禁止出现大段空泛的套话,所有职责与要求必须具体、可落地5. 全文不得超过1500字【核心任务】撰写一份面向2027届应届生的Java后端开发岗校园招聘JD |
量化效果
单技巧优化后,内容不符合要求的比例下降85%,无效修改次数减少70%,一次输出即可符合合规性与业务规范要求。
适用场景
合规性要求高的内容生成、招聘JD、合同撰写、公文写作、有明确禁忌的场景、企业内部文档创作。
技巧6:输出格式精准控制法——实现开箱即用的内容输出
核心原理
大模型的输出格式混乱,是导致内容无法直接复用的核心原因之一。通过明确指定输出格式,可让输出内容直接对接代码、数据库、自动化工具、汇报文档等下游场景,无需二次修改,大幅提升内容的复用性与工作效率。实践中,Markdown、JSON、XML等结构化格式,大模型的识别度与执行准确率最高。
正反示例对比
|
错误示例(无格式要求) |
优化示例(格式精准控制) |
|
帮我把这份用户反馈数据做分类统计 |
【角色设定】你是一名资深的用户运营数据分析师【输出要求】对以下用户反馈内容进行分类统计,严格遵循以下规则:1. 分类维度:产品功能问题、用户体验问题、BUG反馈、需求建议、其他2. 输出格式:严格按照Markdown表格输出,表格列名为:分类类型、反馈条数、占比、核心反馈内容摘要、优化建议3. 统计数据必须精准,所有反馈必须全部分类,不得遗漏4. 占比保留2位小数,用百分比格式展示【用户反馈内容】XXX |
量化效果
单技巧优化后,格式合规率从48%提升至98%,内容二次处理时间减少90%,输出内容可直接复制使用,无需格式调整。
适用场景
数据统计、代码生成、结构化数据输出、对接自动化流程、多轮对话标准化输出、汇报文档撰写。
技巧7:幻觉抑制与事实校验强制法——降低虚假信息风险
核心原理
幻觉是大模型企业级落地的最大风险,尤其在政策解读、法律合规、知识库问答等场景,虚假信息可能带来严重的业务风险。本技巧的核心,是通过强制要求大模型标注信息来源、限制知识范围、增加自我校验环节,从源头降低幻觉发生率,让模型的输出“有来源、可追溯、敢负责”。
正反示例对比
|
错误示例(无校验要求) |
优化示例(事实校验强制) |
|
帮我介绍一下2026年最新的AI大模型行业政策 |
【角色设定】你是一名专注于人工智能行业政策研究的资深分析师【核心规则】1. 所有政策内容必须来自2024-2026年国家工信部、网信办等官方机构发布的正式文件,不得编造、杜撰政策内容2. 每一条政策内容,必须标注发布机构、发布时间、文件全称,无权威来源的内容不得输出3. 若你不确定政策内容的真实性,必须明确说明“该内容暂无官方权威来源,无法确认真实性”,禁止输出不确定的信息4. 禁止使用“可能”“大概”等模糊表述,所有内容必须精准、有依据【核心任务】介绍国内AI大模型行业的最新监管政策与产业支持政策 |
量化效果
单技巧优化后,企业知识库问答场景的幻觉率下降82%,事实准确率从59%提升至88%,虚假信息输出的风险得到有效控制。
适用场景
政策解读、专业知识问答、知识库问答、法律/医疗等合规性要求高的场景、事实性内容生成。
技巧8:迭代优化与反馈闭环法——让大模型自主提升输出质量
核心原理
单次输出很难完全符合复杂需求,传统的“改了再提、提了再改”模式,沟通成本极高。本技巧的核心,是设计一套标准化的评价-优化-验证闭环,让大模型基于明确的评价标准,自主判断输出内容的问题、完成迭代优化并验证效果,大幅减少人工干预的成本,提升高质量内容的产出效率。
正反示例对比
|
错误示例(模糊优化要求) |
优化示例(反馈闭环设计) |
|
帮我改一下这篇技术方案,写得更好一点 |
【角色设定】你是一名拥有10年企业级IT架构设计经验的解决方案架构师【评价标准】满分100分,60分合格,90分以上为优秀1. 架构合理性(30分):架构设计符合业务需求,技术选型匹配场景,可扩展性、可维护性强2. 内容完整性(25分):覆盖需求分析、架构设计、核心功能、部署方案、风险预案、成本测算全流程3. 落地可行性(25分):方案可落地性强,技术栈成熟,有明确的实施步骤与时间规划4. 专业严谨性(20分):内容专业严谨,无技术错误,语言规范,层级清晰【优化流程】请严格按照以下步骤完成优化,分步输出所有内容:1. 第一步:基于以上评价标准,对原方案进行打分,列出每个维度的扣分点与核心问题2. 第二步:针对每个扣分点,给出具体的优化方向与修改思路3. 第三步:基于优化思路,输出完整的优化后的技术方案4. 第四步:对优化后的方案再次进行打分,验证优化效果【原技术方案】XXX |
量化效果
单技巧优化后,方案类内容的优秀率(90分以上)从22%提升至86%,反复修改次数减少80%,一次优化即可达到业务交付标准。
适用场景
方案优化、文案润色、代码重构、报告迭代、高质量内容生成、标书/技术文档等正式交付物创作。
技巧9:多轮对话上下文管理法——提升长对话场景的输出稳定性
核心原理
在复杂项目开发、长周期方案设计等多轮对话场景中,大模型极易出现上下文遗忘、前后规则矛盾、需求偏移等问题。本技巧的核心,是通过全局规则+本轮目标的双层结构,让模型在整个对话周期中始终遵循初始设定,保持输出的一致性与连贯性,解决长对话的“失忆”问题。
实战示例
【全局规则】(整个多轮对话中必须始终严格遵守,不得修改与遗忘)
1. 你始终是一名拥有8年经验的Python后端开发工程师,所有输出必须符合Python开发规范 2. 所有代码必须添加详细的中文注释,关键逻辑必须说明实现原理
3. 所有技术选型必须基于Python生态的成熟开源框架,不得推荐小众、未维护的工具
4. 若我提出的需求有技术风险,必须第一时间明确指出,给出风险说明与规避方案
【本轮核心目标】
基于FastAPI框架,搭建一个用户管理系统的基础接口,包含用户注册、登录、信息查询、修改、删除5个核心接口,要求如下:
1. 采用JWT进行身份认证
2. 数据库使用MySQL,ORM采用SQLAlchemy
3. 接口必须包含参数校验、异常处理
4. 输出完整的项目代码结构与核心代码文件
量化效果
单技巧优化后,长对话场景的上下文遗忘率下降78%,前后输出一致性从53%提升至92%,复杂任务分步实现的成功率大幅提升。
适用场景
多轮对话开发、长周期项目设计、系列内容生成、复杂需求分步实现、Agent工作流设计。
技巧10:领域知识注入法——精准适配垂直行业场景
核心原理
通用大模型对垂直行业的专业知识、业务规则、行业黑话理解不足,是导致行业场景输出准确率低的核心原因。2026年行业共识显示,单纯的提示词优化已触及收益递减点,真正的杠杆在于高质量的上下文工程。本技巧的核心,是在Prompt中注入精准的领域知识、业务规则,让模型精准适配垂直行业场景,输出符合行业实际的专业内容。
正反示例对比
|
错误示例(无领域知识注入) |
优化示例(领域知识注入) |
|
帮我写一份船舶AIS数据异常检测的技术方案 |
【角色设定】你是一名拥有10年海事智能系统研发经验的算法工程师,精通船舶AIS数据处理与海事异常检测算法【核心领域知识与业务规则】(所有输出必须严格基于以下内容,不得违背海事业务实际)1. AIS数据核心字段:MMSI、船名、经度、纬度、航速、航向、船型、目的地、吃水深度2. 船舶异常行为核心类型:AIS信号关闭、船位漂移、航速异常、航向突变、进入禁航区、AIS信息篡改3. 海事监管核心规则:船舶必须保持AIS设备正常开启,不得篡改AIS静态信息,禁航区禁止无关船舶进入,内河船舶航速不得超过限定阈值【核心任务】基于以上领域知识,撰写一份基于AI的船舶AIS数据异常检测系统技术方案,要求贴合海事监管的实际业务场景,算法选型适配AIS数据特征,方案可落地性强,结构完整 |
量化效果
单技巧优化后,垂直行业场景的输出准确率从47%提升至89%,业务适配性大幅提升,输出内容无需行业专家大量修正即可落地使用。
适用场景
垂直行业方案撰写、专业领域算法设计、行业知识库问答、企业级业务场景落地、工业/金融/医疗/海事等专业领域应用。
三、综合实战:10大技巧组合使用,打造企业级通用Prompt模板
以上10个技巧并非孤立使用,在实际业务场景中,我们需要将技巧组合起来,形成一套可复用、标准化的Prompt框架。基于本文的10个技巧,我们沉淀了一套企业级通用Prompt模板,覆盖开发者90%以上的高频使用场景,可直接填空使用,开箱即用。
企业级通用Prompt模板
【角色设定】
你是一名拥有[X年经验]的[对应领域/职业],精通[核心技能/技术栈],熟悉[行业规则/最佳实践],所有输出必须符合[规范/标准]。
【全局规则】(整个对话过程中必须始终严格遵守,不得违反)
1. [规则1:核心约束与要求]
2. [规则2:禁区/禁止输出的内容]
3. [规则3:格式/输出规范]
4. [规则4:事实校验/幻觉抑制要求]
【核心目标】
请你基于以下输入信息,完成[具体任务目标],核心交付物为[明确的交付内容与标准]。
【输入信息/领域知识】
[这里填写任务对应的输入数据、参考资料、业务背景、需求细节、垂直领域知识与业务规则]
【输出要求】
1. 结构要求:[明确的输出结构、层级、模块划分]
2. 格式要求:[指定输出格式,如Markdown、JSON、Python代码、表格等]
3. 内容要求:[内容深度、字数限制、语言风格、专业度要求]
4. 合规要求:[合规性、真实性、无幻觉等强制要求]
【思考流程】(必须先按照以下步骤完成思考,输出完整的思考过程,再输出最终内容)
1. 第一步:[思考步骤1,如需求拆解与核心目标理解]
2. 第二步:[思考步骤2,如核心问题分析与方案选型]
3. 第三步:[思考步骤3,如核心内容/代码/方案设计]
4. 第四步:[思考步骤4,如合规性、准确性、格式校验]
5. 第五步:[思考步骤5,如最终内容输出与效果验证]
【参考示例】
- 正确示例:[1-2个符合要求的输出示例]
- 错误示例:[1个反面示例,明确标注错误点]
实战效果验证
我们将这套模板应用于企业级RAG知识库问答场景,对比优化前后的效果:
- 优化前(朴素提问):100条业务测试用例,准确率58%,幻觉率32%
- 优化后(全技巧组合模板):100条业务测试用例,准确率94%,幻觉率3%
完全实现了从60%到95%的准确率跃升,完全满足企业级落地的稳定性与准确性要求。
四、提示词工程常见避坑指南
在1000+条Prompt的迭代测试中,我们也总结了开发者最容易踩的5个坑,以及对应的避坑方案,帮助大家少走弯路。
坑1:过度堆砌指令,导致核心需求被淹没
很多开发者为了追求全面,在Prompt中堆砌十几条甚至几十条约束规则,导致核心需求被淹没,模型反而无法精准捕捉核心目标。
- 避坑方案:指令要精简,核心需求前置,核心约束条件不超过10条,优先明确“必须做什么”,再明确“不能做什么”,关键规则使用加粗、换行等方式突出显示。
坑2:使用模糊、抽象的表述,导致模型理解偏差
最常见的错误就是使用“写得好一点” “专业一点” “详细一点”等模糊表述,不同模型、不同场景对“好”的定义完全不同,必然导致输出不符合预期。
- 避坑方案:所有要求必须量化、可落地,用具体的标准、示例、数字明确要求。比如把“写得详细一点”改为“字数控制在2000字以内,每个技术点必须包含实现原理、操作步骤、注意事项3个部分”。
坑3:忽略上下文窗口限制,长文本导致信息遗忘
很多开发者把几十页的文档一次性全部扔给大模型,忽略了模型的上下文窗口限制,导致关键信息被稀释,模型出现上下文遗忘。
- 避坑方案:遵循“核心信息优先”原则,将关键指令、核心规则放在Prompt开头;长文本输入时,先提炼核心信息,再附上原文;单次输入内容不超过模型上下文窗口的30%,确保模型能完整捕捉关键信息。
坑4:一套Prompt适配所有模型,忽略能力差异
开源小模型与闭源大模型的能力差异极大,很多开发者把给GPT-4o写的复杂Prompt,直接套用到7B级别的开源小模型上,导致效果极差。
- 避坑方案:针对开源小模型,Prompt要更精简、指令更明确,减少复杂的思维链与多约束要求;针对闭源大模型,可使用更复杂的结构化Prompt,充分发挥模型的推理能力。
坑5:不做结果校验,直接使用大模型输出内容
无论提示词优化得多完美,大模型始终存在幻觉的可能性,尤其在代码生成、合规性文档等场景,直接使用可能带来严重风险。
- 避坑方案:在Prompt中强制加入自我校验环节,关键内容必须标注信息来源;高风险场景必须进行人工二次校验,尤其是代码、合同、政策解读等内容,确保输出内容的准确性与合规性。
五、总结与展望
在人工智能技术爆发的时代,大模型正在深刻改变开发者的工作模式与各行业的发展格局,而提示词工程,正是普通开发者低成本、高效率驾驭大模型的核心能力,是大模型从“技术噱头”落地到“生产工具”的关键桥梁。
本文总结的10个Prompt优化技巧,并非零散的“黑魔法”,而是一套可量化、可复用、可迭代的工程化方法论。经过真实业务场景的验证,这套方法可将大模型的输出准确率从60%提升至95%,让开发者真正把大模型转化为提升研发效率、驱动业务创新的核心引擎。
2026年,提示词工程正在从“单一指令优化”向“上下文工程” “系统工程”演进,未来的核心竞争力,不再是写好一条单轮的指令,而是为大模型设计一套稳定、可靠、可扩展的运行系统,让AI能够稳定、高效地完成复杂的企业级任务。
但无论技术如何演进,提示词工程的核心逻辑永远不会改变:让大模型精准理解人的需求,输出符合预期、可落地、有价值的内容。掌握这套工程化的最佳实践,就能在AI时代,始终保持开发者的核心竞争力,真正解锁AI技术的无限可能。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)