软件工程原则在多智能体系统中的应用:分层与解耦
ChatGPT 发布之后,AI 智能体的概念就一直牵动着整个行业的想象力。它描绘的场景很诱人:给 AI 系统一个目标,让它自行拆解问题、调用工具、收集信息,最终综合出结果。围绕这个概念的框架生态已经相当拥挤了:LangChain、CrewAI、AutoGen、Semantic Kernel、Agent Framework……新框架层出不穷,个个声称能简化智能应用的构建。但大多数还停留在 hello
ChatGPT 发布之后,AI 智能体的概念就一直牵动着整个行业的想象力。它描绘的场景很诱人:给 AI 系统一个目标,让它自行拆解问题、调用工具、收集信息,最终综合出结果。
围绕这个概念的框架生态已经相当拥挤了:LangChain、CrewAI、AutoGen、Semantic Kernel、Agent Framework……新框架层出不穷,个个声称能简化智能应用的构建。但大多数还停留在 hello world 级别:一个智能体回答问题,顶多再调一两个工具。
构建一个多智能体系统,核心挑战不在于让智能体跑起来,因为任何框架都能做到,而在于如何让系统可维护、可测试、可扩展。本文围绕一个实际项目(多智能体协作从 YouTube 视频中提取、摘要和整理信息),探讨智能体系统的架构设计。涉及的关键问题包括:为什么智能体系统跟其他复杂应用一样需要分层架构,工具(LLM 接口)和服务(业务逻辑)的分离为何是智能体设计的核心洞见,领域驱动设计的概念如何自然映射到智能体架构,以及编排器模式下四个专业化智能体如何协调工作。
这个项目基于 Microsoft Agent Framework 构建,这是 Semantic Kernel 和 AutoGen 的继任者,融合了两者的优势。不过具体框架不是重点,后面讨论的原则无论用哪个框架都适用。
架构挑战
框架们都擅长帮你快速搭出 demo,但没有一个在引导你走向可维护、可扩展的架构。比如说各种示例代码中LLM 调用、工具集成、业务逻辑和编排之间的边界模糊得一塌糊涂。关注点分离这个概念在软件工程里存在几十年了,但在智能体领域,框架们集体选择了"快速上手"而非架构指导。教程优化的是"看多简单!"而不是"看多可维护!"
下面是一个典型的单体写法的简化版本,把所有东西混在一起:
# orchestrator.py - 智能体、工具、提示词和业务逻辑全部在一起
def run_research(query: str) -> str:
# 搜索智能体,工具定义在行内
def search_youtube(q: str) -> str:
response = requests.get(f"https://youtube.com/results?q={q}")
return parse_html_for_videos(response.text)
search_agent = ChatAgent(
name="SearchAgent",
instructions="""You search YouTube. Use search_youtube to find videos.
Return video IDs and titles as JSON.""",
tools=[search_youtube]
)
# 字幕智能体,有自己的行内工具
def get_transcript(video_id: str) -> str:
transcript = YouTubeTranscriptApi.get_transcript(video_id)
return " ".join([t["text"] for t in transcript])
transcript_agent = ChatAgent(
name="TranscriptAgent",
instructions="Fetch transcripts using get_transcript tool.",
tools=[get_transcript]
)
# 摘要智能体,提示工程嵌入其中
summarize_agent = ChatAgent(
name="SummarizeAgent",
instructions=f"""Summarize cooking content. Focus on:
- Temperatures and timing
- Key techniques
- Pro tips
Format as markdown."""
)
# 编排逻辑与智能体调用交织在一起
client = AzureOpenAI(api_key=os.environ["KEY"], ...)
videos = search_agent.run(query, client=client)
transcripts = []
for vid in parse_json(videos)[:3]:
text = transcript_agent.run(f"Get transcript for {vid['id']}", client=client)
transcripts.append(text)
summary = summarize_agent.run(f"Summarize:\n{transcripts}", client=client)
Path(f"./outputs/{query}.md").write_text(summary)
return summary上面代码拿来做 demo 没问题,快速验证想法也完全合适。但问题是如果你要继续修改呢?
为什么这是一个架构问题
LLM 调用工具其实是两件事:用简单参数(字符串、数字)调用一个函数,然后解释返回的字符串结果。
但实际干活的部分:搜索 YouTube、解析 HTML、处理错误要复杂得多。涉及配置、错误处理、重试,返回的是带多个字段的结构化对象。
这两件事是不同的关注点,LLM 要的是简单字符串,应用要的是合理的抽象。把它们搅在一起就像把 SQL 查询直接写在视图层:能跑,但架构上是错的。
分离这两个职责,可测试性、可复用性、代码清晰度全都跟着出来了。
如何分离?
工具 = LLM 接口
工具是 LLM 和应用之间的薄适配层。接受简单参数(字符串、数字、布尔值),调用对应的服务,把结果格式化成 LLM 能理解的字符串。无状态。
# tools/youtube.py
async def fetch_video_transcript(
video_id: Annotated[str, Field(description="YouTube video ID")]
) -> str:
"""Fetch the transcript for a YouTube video.
Returns the full transcript text with video metadata.
"""
result = await fetch_transcript(video_id) # calls service
## Format for LLM
return f"Transcript for '{result.metadata.title}':\n\n{result.transcript.full_text}"工具没有做的事:没有配置管理,没有复杂返回类型,没有业务逻辑。它只干一件事:调用服务、格式化结果。纯粹的适配。
服务 = 业务逻辑
服务才是真正实现所在。它们是带配置的可复用类,返回丰富的领域对象(模型),可以从 CLI、测试、其他服务任何地方调用,可能维护状态或连接。
# services/youtube.py
class YouTubeTranscriptFetcher:
"""Fetches transcripts from YouTube videos."""
def __init__(self, proxy_url: str | None = None):
self.proxy_url = proxy_url
async def fetch(
self,
video_id: str,
languages: list[str] | None = None
) -> TranscriptResult:
"""Fetch transcript with full metadata.
Returns a TranscriptResult containing the transcript text,
video metadata, and language information.
"""
# Real implementation with error handling, retries, etc.
raw_transcript = await self._fetch_from_api(video_id, languages)
metadata = await self._fetch_metadata(video_id)
return TranscriptResult(
metadata=metadata,
transcript=Transcript(
full_text=self._format_transcript(raw_transcript),
segments=raw_transcript,
language=self._detect_language(raw_transcript),
),
)复杂性就该待在这里。配置、缓存、错误处理、重试、类型化返回,这些全归服务管。脱离 LLM,服务照样能用。
流程
LLM 决定获取字幕时的调用链:
LLM decides to call "fetch_video_transcript"
↓
tools/youtube.py::fetch_video_transcript(video_id)
↓
services/youtube.py::YouTubeTranscriptFetcher.fetch(video_id)
↓
Returns TranscriptResult object
↓
Tool formats as string for LLM为什么这很重要
先说可复用性。服务可以直接从 CLI、测试脚本、批处理任何入口调用,完全绕过 LLM:
# 从 CLI 使用,完全绕过智能体
@click.command()
def download_transcript(video_id: str, output: str):
fetcher = YouTubeTranscriptFetcher()
result = fetcher.fetch(video_id)
Path(output).write_text(result.transcript.full_text)
# 在测试中使用,无需模拟 LLM
def test_fetcher_handles_unavailable_videos():
fetcher = YouTubeTranscriptFetcher()
with pytest.raises(TranscriptDisabledError):
fetcher.fetch("video_with_disabled_transcript")
# 在批处理中使用
async def process_videos(video_ids: list[str]):
fetcher = YouTubeTranscriptFetcher()
results = await asyncio.gather(*[fetcher.fetch(id) for id in video_ids])
return results再说可测试性。服务返回类型化对象,断言写起来干脆利落。工具返回格式化字符串,验证起来就费劲多了:
# 测试服务 - 清晰的断言
def test_fetcher_returns_transcript():
result = fetcher.fetch("abc123")
assert result.transcript.full_text
assert result.metadata.video_id == "abc123"
assert result.transcript.language in ["en", "en-US"]
# 测试工具 - 需要字符串解析
def test_tool_formats_correctly():
output = fetch_video_transcript("abc123")
assert "## " in output # Has title?
assert "Transcript" in output # Has section header?
# Much harder to validate structure然后是关注点分离。工具代码管"怎么呈现给 LLM",服务代码管"怎么真正干活"。YouTube API 改了?只动
services/youtube.py。想换输出格式?只改工具就可以了。
分层架构
工具和服务的分离只是一条边界。完整的智能体系统需要更多结构。经过反复实验,最终落地了一个六层架构,每层一个明确的职责。熟悉领域驱动设计的话,应该会觉得眼熟:

实际代码中是这样的:
# presentation/cli.py - 表示层
@click.command()
def search(query: str):
"""Search for videos on YouTube."""
agent = create_search_agent()
result = agent.run(query)
click.echo(result) # agents/search.py - 智能体层(仅配置)
def create_search_agent() -> ChatAgent:
"""Factory function that creates a Search Agent."""
return ChatAgent(
chat_client=get_chat_client(),
name="SearchAgent",
instructions=SEARCH_AGENT_INSTRUCTIONS,
tools=[search_youtube_formatted],
) # tools/youtube.py - 工具层(薄 LLM 适配器)
async def search_youtube_formatted(query: str) -> str:
"""Search YouTube for videos matching the query."""
results = await search_youtube(query) # calls service
return format_for_llm(results) # formats for LLM # services/youtube.py - 服务层(业务逻辑)
async def search_youtube(query: str) -> list[VideoResult]:
"""Search YouTube - returns rich domain objects."""
url = build_search_url(query)
html = await fetch_html(url) # calls infra
return parse_video_results(html) # models/youtube.py - 模型层(领域对象)
@dataclass
class VideoResult:
video_id: str
title: str
channel: str # infra/http_client.py - 基础设施层(HTTP 传输)
async def fetch_html(url: str, timeout: float = 10.0) -> str:
"""Fetch HTML content with browser-like headers."""
async with httpx.AsyncClient() as client:
response = await client.get(url, headers=DEFAULT_HEADERS, timeout=timeout)
response.raise_for_status()
return response.text每层各司其职:智能体配置行为,工具做 LLM 适配,服务实现逻辑,模型定义结构。测试也更直接了:在层边界 mock,不深入内部。
DDD 的映射不是硬凑的,它自然浮现,因为智能体系统跟其他复杂应用面对的是同样一组关注点:
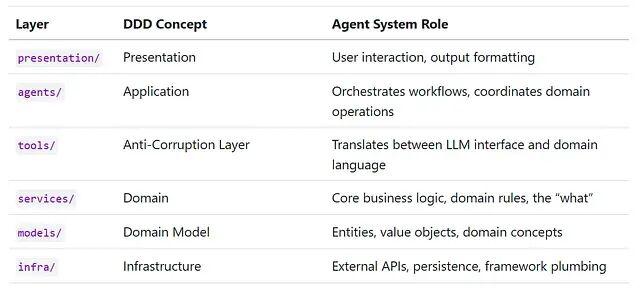
tools/层作为防腐层这个对应关系特别精准。在 DDD 里,防腐层保护领域模型不被外部系统的概念入侵。这里也一样——它隔离了 LLM 的接口需求,在"LLM 能推理的字符串"和"代码使用的丰富领域对象"之间做翻译。
调用流程严格向下。智能体用工具,工具调服务,服务操作模型。这个约束逼着你想清楚每段代码该放在哪。
何时需要这种架构
对简单项目来说是不是过度设计?算是,但有几种情况下值得从一开始就这么做:要上生产、在用 AI 编码助手(GitHub Copilot、Claude Code 这类工具在结构清晰的代码上表现好得多)、多人协作、需要正经测试、领域本身复杂(多个外部 API、复杂业务逻辑、丰富数据模型),或者预期会持续扩展。
智能体系统里的"混乱"都是渐进发生的。一开始图快用内联工具,后来要复用一个,再后来要测试某个东西,再后来要加错误处理。每改一次,代码就纠缠一分。
AI 编码助手时代的架构
还有一个越来越重要的维度:结构清晰的代码跟 AI 编码助手配合得更好。
GitHub Copilot、Cursor、Claude Code 这些工具已经成了开发工作流的标配。一个很明显的规律是,面对结构良好的代码,它们的表现远胜于面对全新项目或纠缠的代码库。配上文档提供上下文的话效果更好。
比如让 Claude Code "实现按最短时长过滤搜索结果的功能",它会精准地找到
services/youtube.py。服务层边界清晰、接口有类型、模式一致。AI 不需要理解整个系统就能推理出该怎么改。
如果工具定义散在编排代码里,AI 就得先搞清楚工具在哪定义、跟智能体怎么耦合、改了会不会影响其他地方、依赖关系怎么走。
让代码对人类可维护的那些架构原则,同时也让代码对 AI 助手可导航。清晰的边界让 AI 能聚焦单一层而不用理解全栈。一致的模式让 AI 学会之后可以一致地应用。类型提示不只是文档,它们是 AI 生成正确代码的约束。单一职责让 AI 改一个服务时不用推理多个关注点。
这不是为了"对 AI 友好"而牺牲设计,而是真正让代码对 AI 系统可理解的东西。
AI 编码助手越普及,架构纪律就越有价值。从 AI 辅助中获益最多的永远是本来就结构良好的代码库。混乱的代码库只会继续混乱,因为 AI 会放大已有的模式——不管好坏。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)