C-MAPSS航空发动机寿命预测MATLAB代码,基于SE-ResNet网络的发动机寿命预测
那么train_FD001.txt对应的真实寿命在哪里呢,其实官方给出的四个训练集,每个训练集中的每个id发动机都是从当前时刻跑到寿命为0就结束,因此训练集中每个ID寿命的最后一个周期都是0,其他的周期依次递增上去即可。很多文献对此做了工作,如果你想在你的论文中附上此图以增加工作量,那么你就可以重新分析一遍,如果你的论文有篇幅要求,那么你也可以直接引用一些大佬的文献,直接给出重要特征即可。原始的R
本期概述:本期全程采用matlab代码实现:对C-MAPSS数据集提取进行分析,筛选重要特征,然后基于混合SE注意力机制的ResNet网络来进行寿命预测模型训练。具体步骤如下:
01
数据分析: 对原始C-MAPSS数据分析,筛选特征
02
数据划分: 编写脚本,一键实现对C-MAPSS数据划分训练集、测试集、验证集
03
模型改进: 采用SE注意力机制对ResNet网络进行改进
04
模型训练: 训练和预测,并对指定id号的发动机进行全寿命预测
05
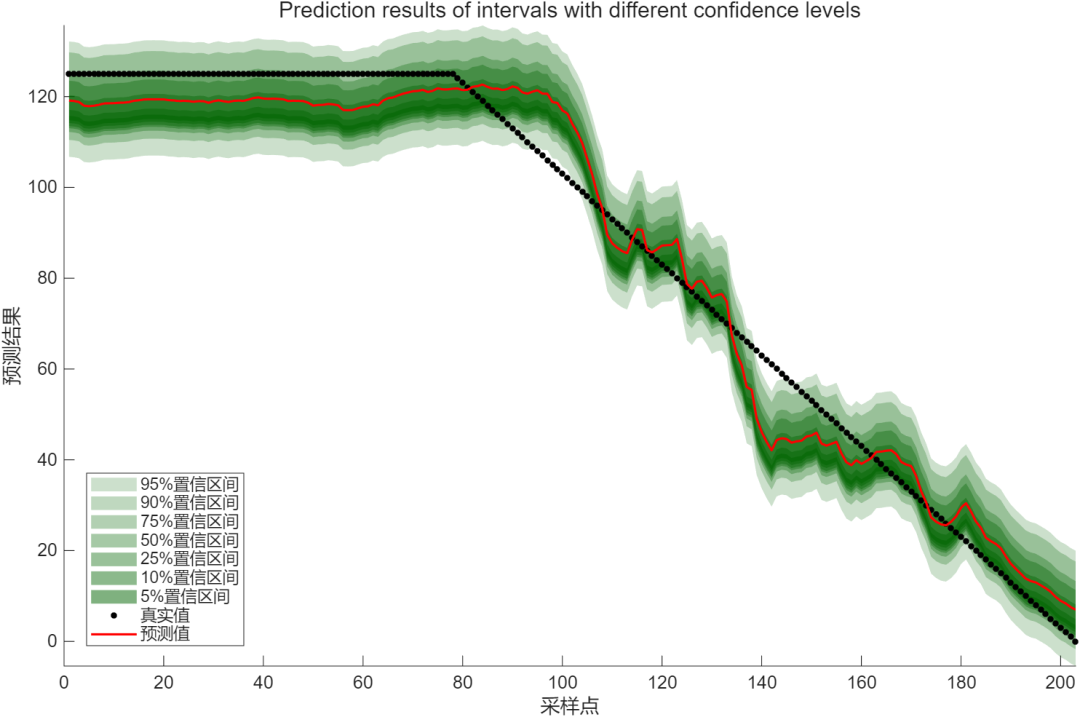
区间置信度: 统计置信区间并绘图
C-MAPSS数据集需要注意的地方
网上关于C-MAPSS数据集的介绍有很多,我这里不再啰嗦,也可以看我之前的推文:C-MAPSS数据集可视化与预处理:MATLAB完整代码解析,发动机寿命预测必学数据集!我这里说一下关于该数据需要注意的地方。
该数据包含四种工况,从官网下载下来的数据的目录长这样:
其中RUL_FD001记录的是test_FD001.txt测试集中每个id发动机的真实剩余寿命,其他文件一一对应。那么train_FD001.txt对应的真实寿命在哪里呢,其实官方给出的四个训练集,每个训练集中的每个id发动机都是从当前时刻跑到寿命为0就结束,因此训练集中每个ID寿命的最后一个周期都是0,其他的周期依次递增上去即可。
其中还有两点要理解的是:
①建立退化模型
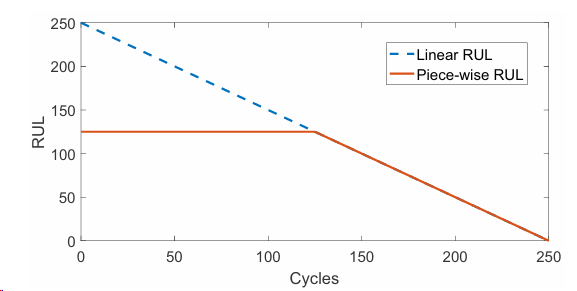
在预测维护中,当设备的剩余寿命较长时,精确预测其具体值的重要性较低。因为维护计划通常关注的是设备何时会接近失效(例如,RUL小于某个值)。因此,当RUL较大时,将其限制在一个上限值可以减少预测任务的难度。
如果不设置阈值,RUL的值可能非常大(例如,有的发动机在训练数据开始时还有200多个循环)。这些大值的RUL样本可能会对模型训练产生负面影响,因为: 模型可能会被这些大值样本所主导,导致在预测小值RUL(即接近失效时)时表现不佳。 大值RUL的预测误差(如绝对误差)会很大,从而在整体上增加损失函数的值,使得模型优化方向偏离我们最关心的区域(即接近失效的区域)。通过设置阈值,我们将所有大于125的RUL都视为125,这样模型只需要关注RUL在0到125范围内的预测。这相当于将问题转化为预测一个上限为125的RUL值。许多关于C-MAPSS数据集的经典论文使用了125作为阈值。这样设置便于与已有研究结果进行比较。
这里列出一篇博士参考论文:徐甜甜.航空发动机剩余使用寿命智能预测方法研究[D].大连理工大学,2024.DOI:10.26991/d.cnki.gdllu.2024.000331.
发动机的寿命 T 可 以表示为:
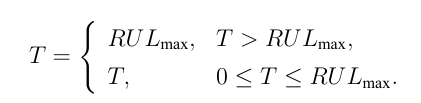
体现在程序中就是训练集的部分标签,在未达到剩余寿命125的情况下,将当前周期的寿命统统视为125。程序中已经设置好接口,可以随意更改,有些文献还会将这个阈值改成120。
②测试集的划分
测试集的划分也有一定的门道,其中以test_FD001为例,原数据一共是13096行×26列,但是划分完数据之后,神奇的发现测试集变成了100×15×14的大小,那么其他数据去哪里了?
其实预测时我们只关心发动机当前衰退状态,历史中间状态不影响当前RUL,因此只保留每台发动机的最后N个周期 (N可变)这里设定为15,而100就是对应100个id,14就是选择的14个重要的传感器。程序中这个序列也设置好了接口,可以随意更改。
理解上述关键的两点,那么你就对C-MAPSS数据集的整理有了更深一步的理解。
①C-MAPSS数据分析
关于C-MAPSS数据分析,可以参考这篇文章,也是完全由MATLAB代码实现的:C-MAPSS数据集可视化与预处理:MATLAB完整代码解析,发动机寿命预测必学数据集!
该代码分析了每个数据集
操作设置分布图:
操作设置随周期变化图:
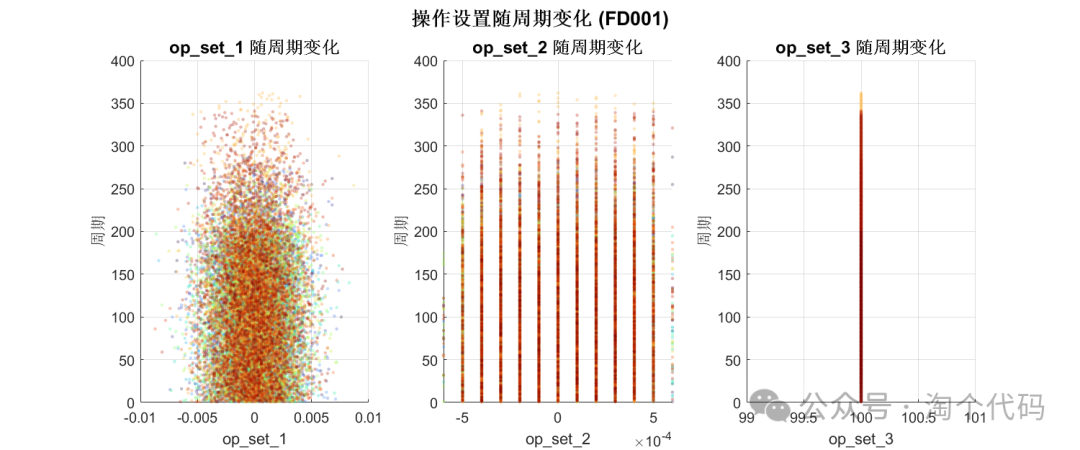
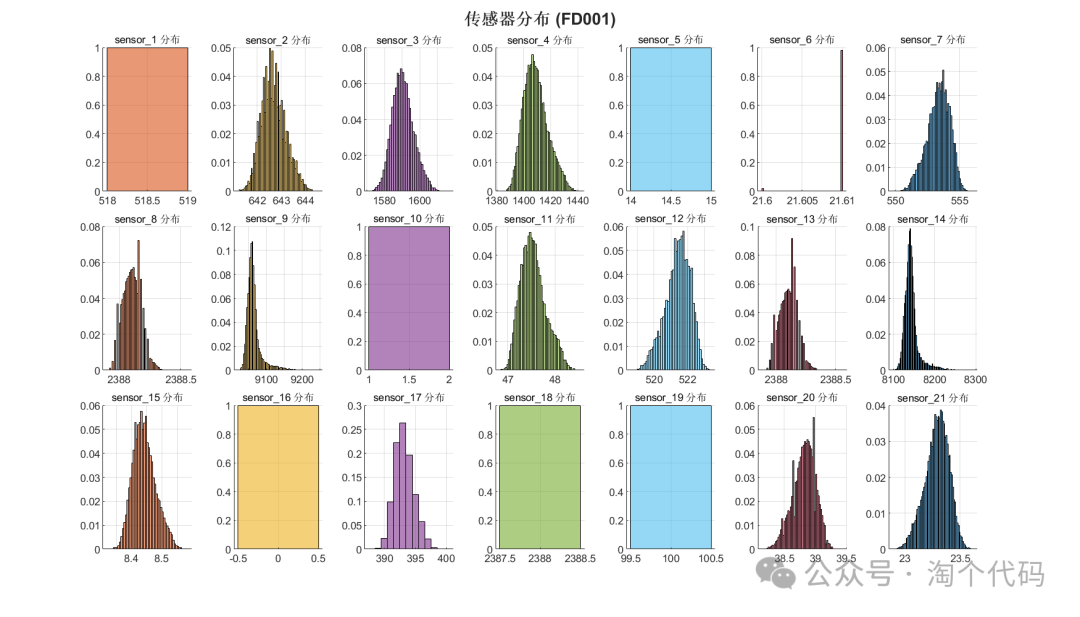
每个传感器分析 (FD001)
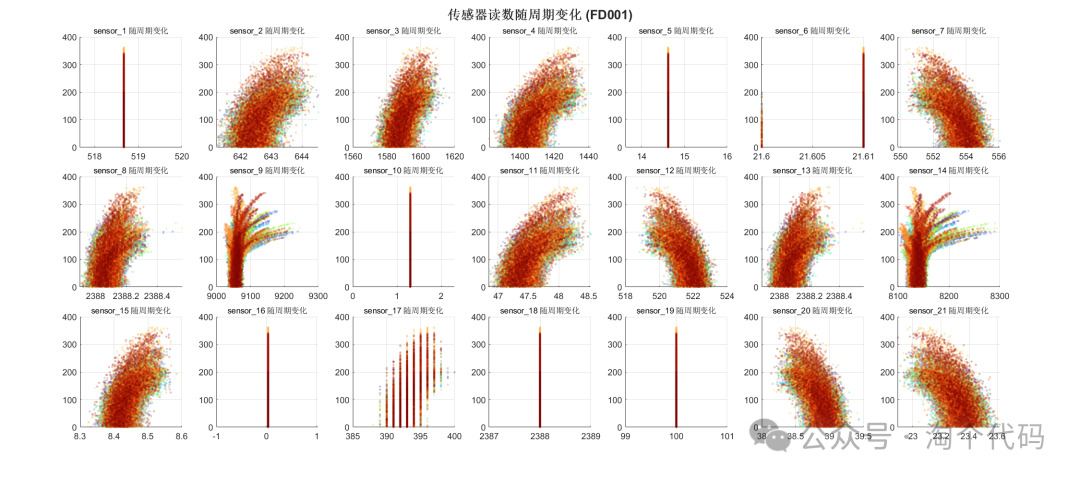
传感器随周期变化
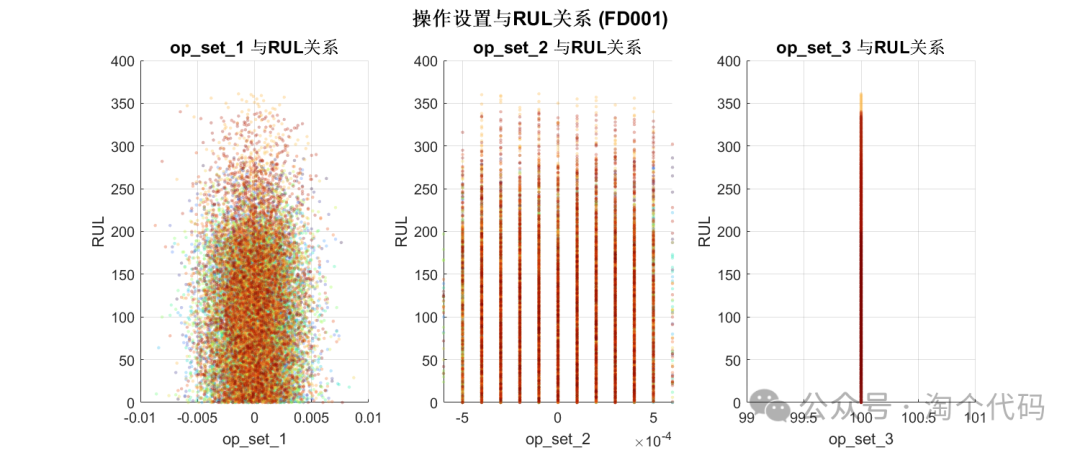
操作设置与RUL(剩余寿命)的关系
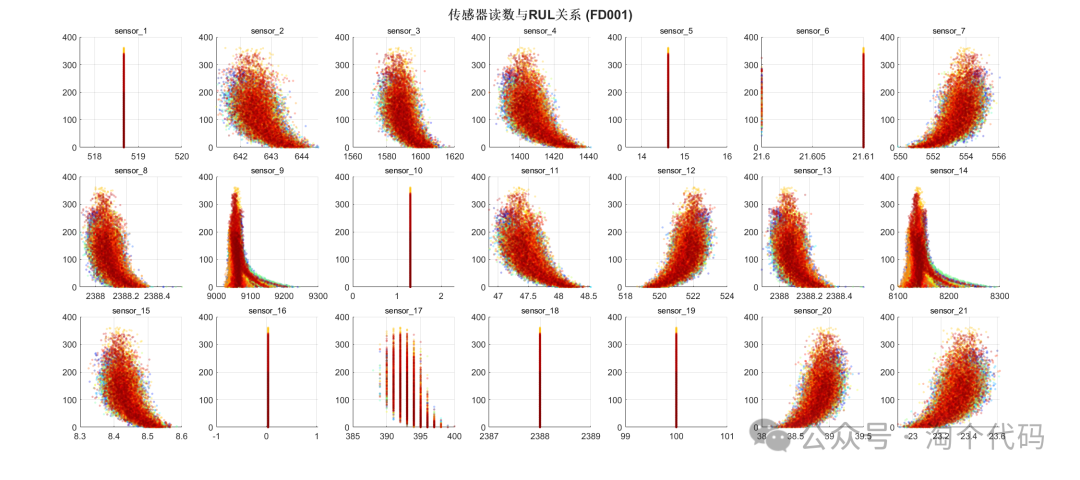
传感器与RUL的关系
随机选择5个引擎进行趋势分析
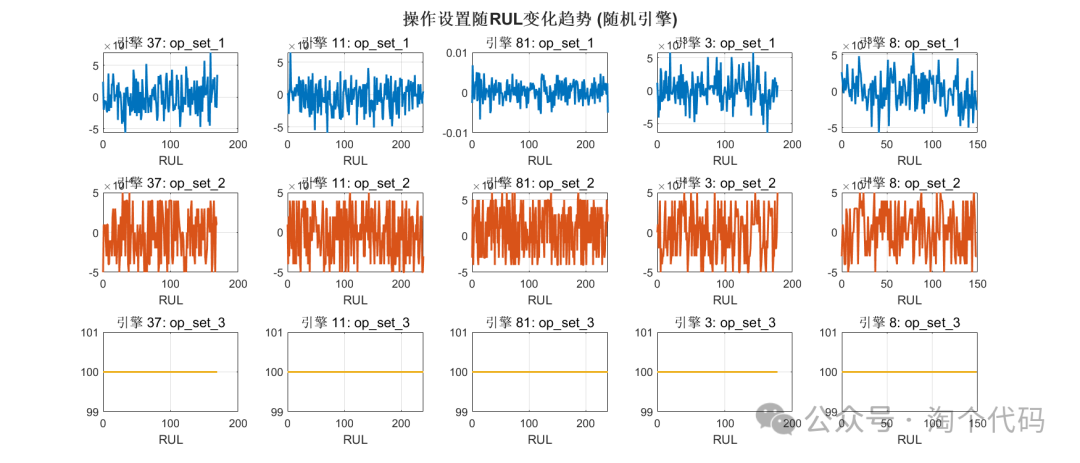
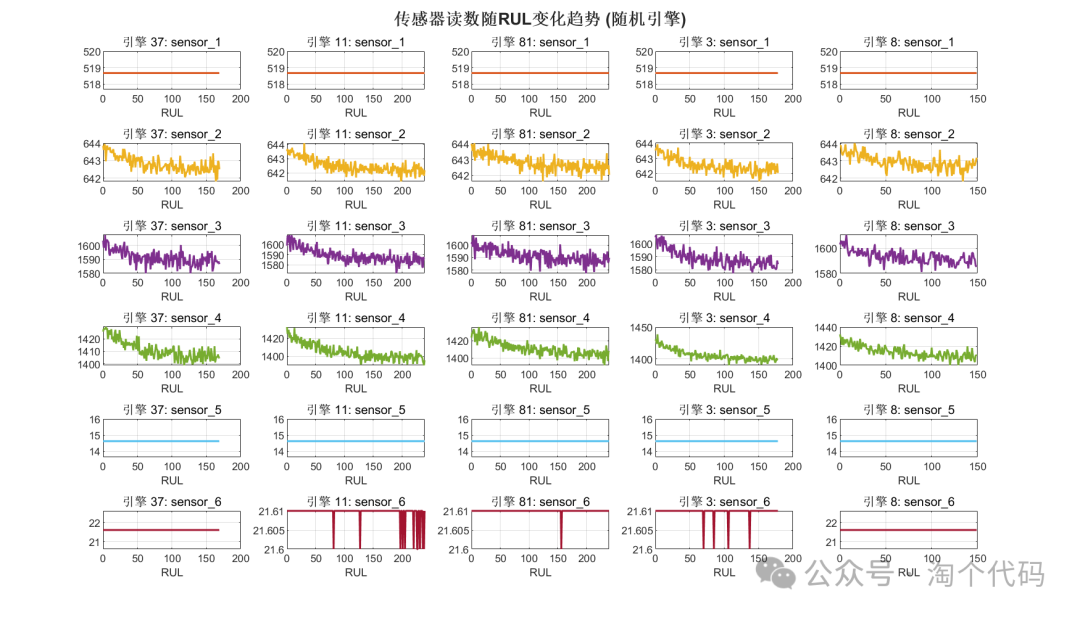
由以上数据分析即可筛选出来C-MAPSS的重要特征。
很多文献对此做了工作,如果你想在你的论文中附上此图以增加工作量,那么你就可以重新分析一遍,如果你的论文有篇幅要求,那么你也可以直接引用一些大佬的文献,直接给出重要特征即可。
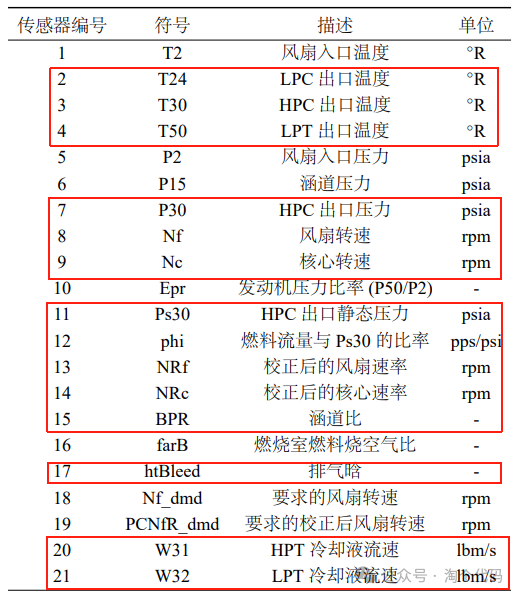
重要特征一般取的就是下面几个传感器:
{'s_2', 's_3', 's_4', 's_7', 's_8', 's_9', 's_11', 's_12', 's_13', 's_14', 's_15', 's_17', 's_20', 's_21'};对应的实际物理含义如下:
②SE-RESNET网络模型构建
近年来,各种注意力机制横空出行,将注意力机制与各种深度学习模型结合,模型对特征提取的能力相较于一般的深度学习网络更加强大,在降低网络学习的参数量的同时也提高了网络模型的泛化能力。
SE-ResNet(Squeeze-and-Excitation ResNet)是ResNet的一种改进版本,它结合了Squeeze-and-Excitation(SE)模块来提升网络的性能。SE模块通过对通道进行重新加权,使网络能够更好地自适应地关注不同通道的重要性。SE-ResNet的优势包括:
-
增强的特征表达能力:通过对特征通道进行重要性建模,SE模块能够提升网络对重要特征的敏感度,从而增强特征的表达能力。
-
更少的计算开销:尽管SE模块引入了额外的计算,但其设计相对简单,计算开销相比于网络其他部分较小,且通常带来性能的显著提升。
-
易于集成:SE模块可以与现有的网络架构(如ResNet、Inception等)无缝集成,提升网络性能而不需要重新设计整个网络架构。
-
SE机制的论文地址:https://arxiv.org/abs/1709.01507
下图是在提出SE模块的原文截取的,原文作者将SE模块应用在Resnet模块为例进行了展示。
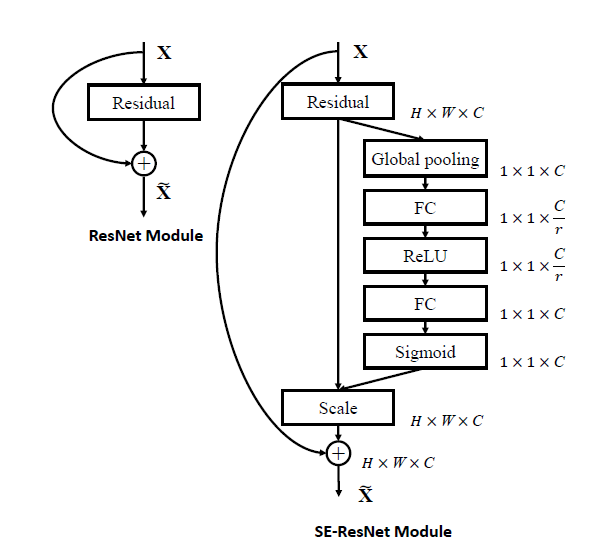
可以看到SEmodule被应用到了Resnet模块的残差分支上。为了更好解释SE模块为什么能提高Resnet网络的泛化能力,这里附上一张更加形象的图。
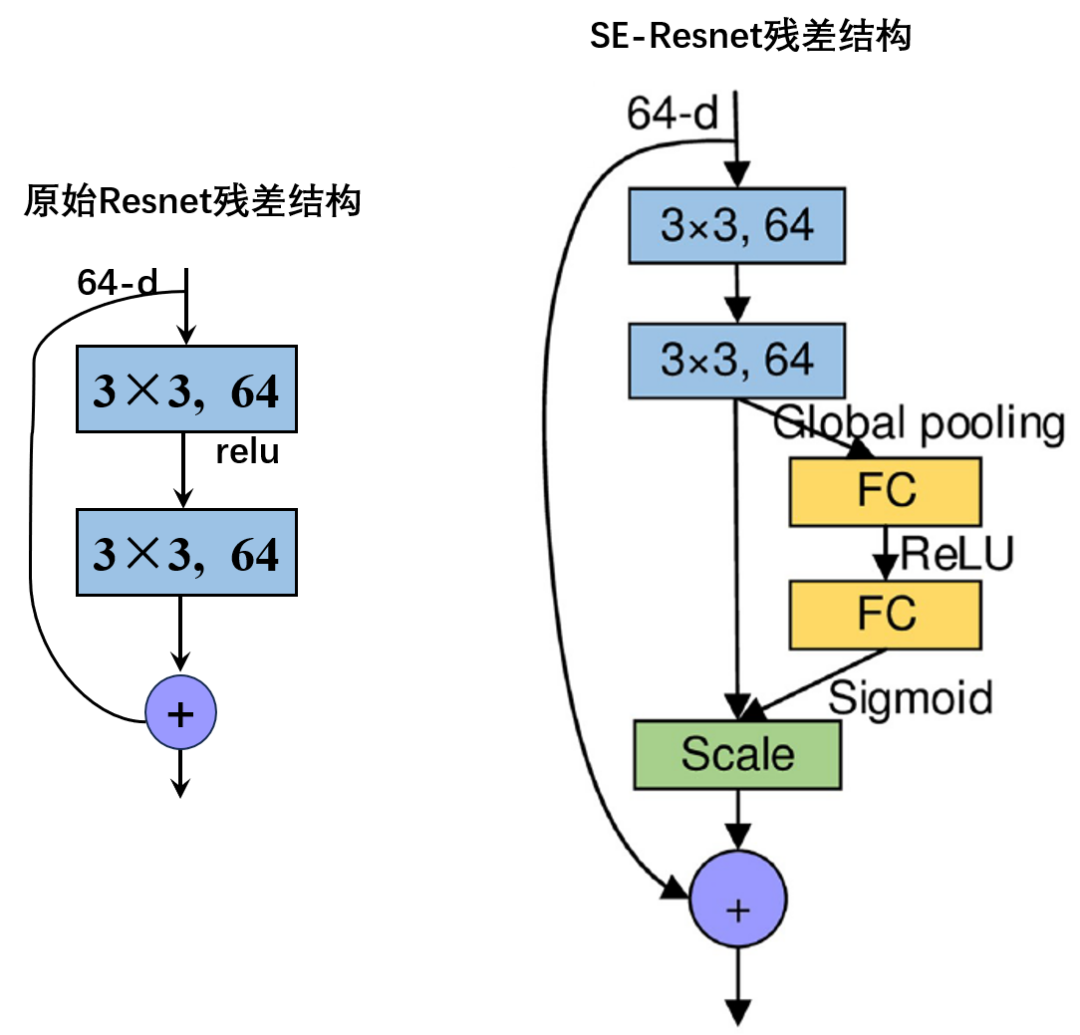
原始的Resnet网络(图左),在进行两次3×3的卷积后,直接与上一步的池化或卷积的结果进行相加。
而在SE-Resnet结构(图右),首先将两次卷积后的特征维度进行全局池化处理,然后经过两个全连接层,而玄妙就在这两个全连接层,其中第一个全连接层将特征维度降低到输入的1/r,然后经过ReLu激活后再通过第二个全连接层升回到原来的维度。这样做比直接用一个全连接层的好处在于:①具有更多的非线性,可以更好地拟合通道间复杂的相关性;②极大地减少了参数量和计算量。最后再通过一个Sigmoid的门获得[0,1]之间归一化的权重。最后通过一个Scale的操作(也就是对应通道相乘)来将归一化后的权重加权到每个通道的特征上。相当于对每个通道的权重特征进行了一个标定,使得注意力集中在权重较高的通道上。不得不说,秒啊!
SE-Resnet的MATLAB实现
本期代码将SE机制在MATLAB中实现,并缝合到Resnet18网络中。看一下网络结果图吧,左边是SE-ResNET模块的结构图,右边是在MATLAB中实现的网络结构,完美实现了一一对应!
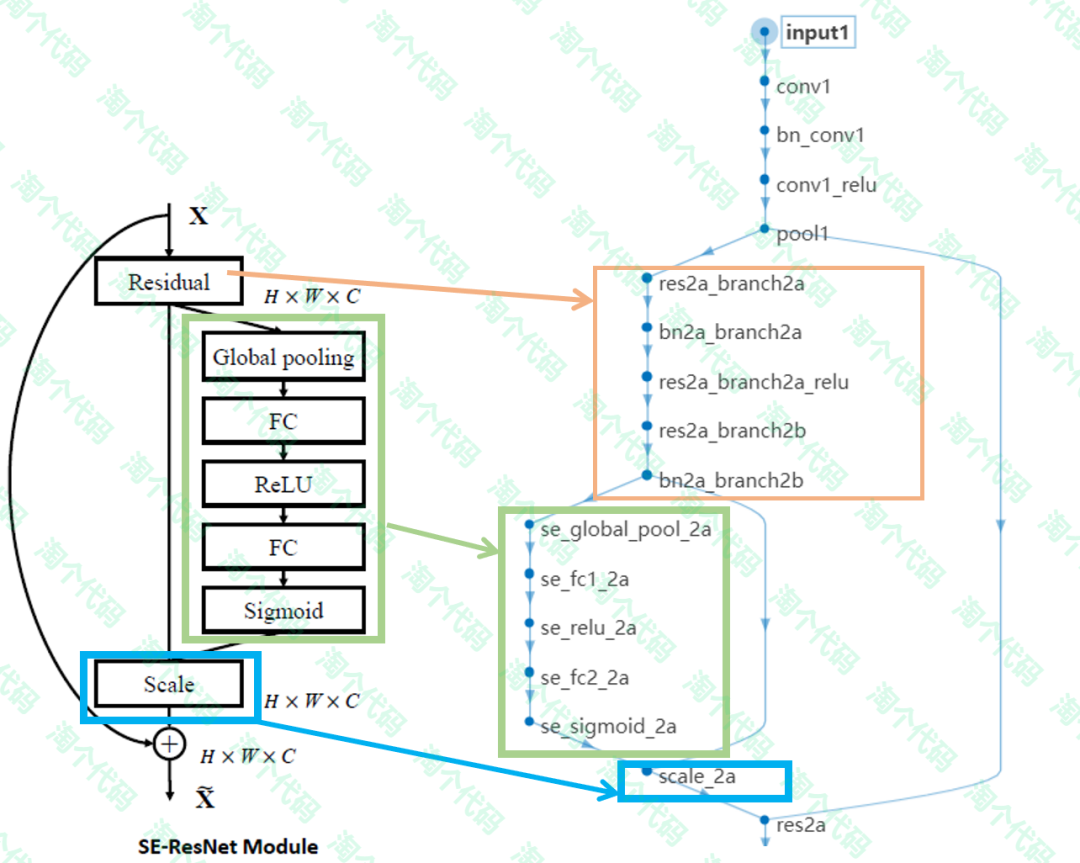
核心代码如下:这里展示了如何将SE模块缝合进去。
% Then, you need to connect the SE block properlySEblockName = '2a';ecaLayers = SEBlock(64,16,SEblockName); % Example parameterslgraph = addLayers(lgraph, ecaLayers);lgraph = disconnectLayers(lgraph, 'bn2a_branch2b', 'res2a/in1');lgraph = connectLayers(lgraph, 'bn2a_branch2b', ['se_global_pool_',SEblockName]);mul = multiplicationLayer(2,'Name',['scale_',SEblockName]);lgraph = addLayers(lgraph, mul);lgraph = connectLayers(lgraph, 'bn2a_branch2b', ['scale_',SEblockName,'/in1']);lgraph = connectLayers(lgraph, ['se_sigmoid_',SEblockName],['scale_',SEblockName,'/in2']);lgraph = connectLayers(lgraph, ['scale_',SEblockName], 'res2a/in1');③实验验证
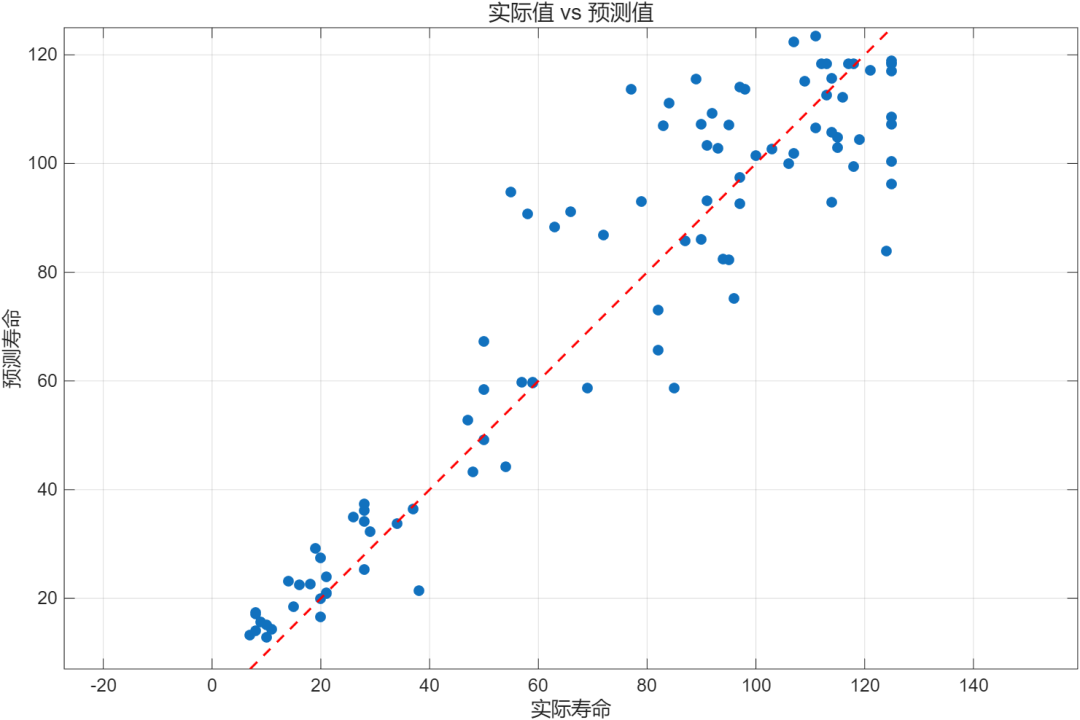
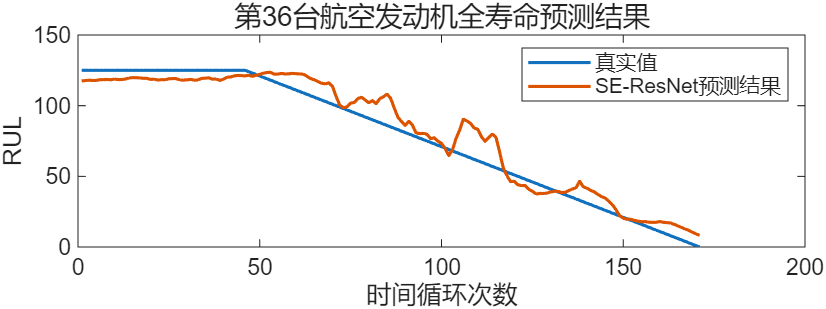
在FD001上的训练结果,将训练集中的10%拿出来作验证集,测试集就直接选用官方给出的数据。结果如下:
测试集预测结果:
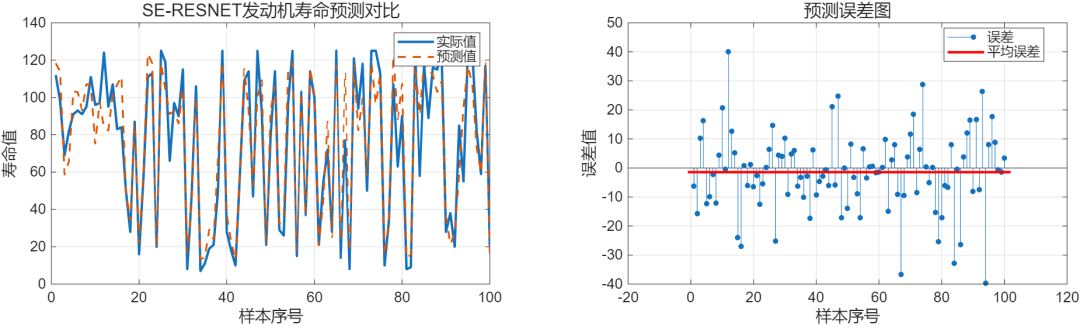

抽取2台发动机进行全寿命预测:
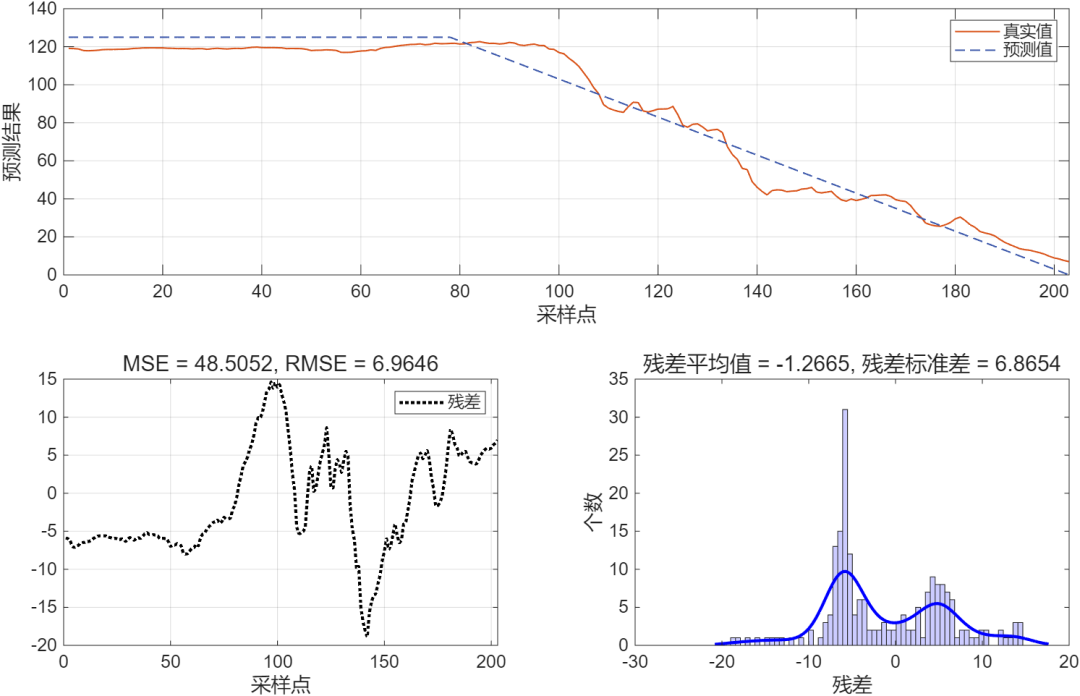
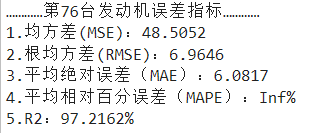
第76台发动机全寿命预测结果:
第18台发动机全寿命预测结果:

代码目录截图:
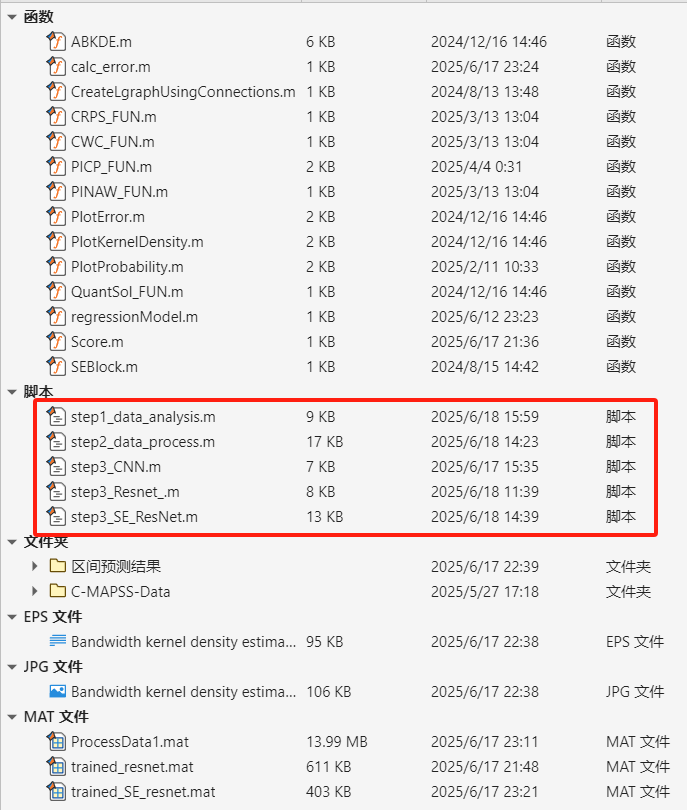
注意:运行的时候运行脚本文件,也就是上面标红的文件。不要运行函数文件!
本期代码获取
直接复制下方链接跳转:
或者点击下方阅读原文跳转链接。
获取更多代码:
点击下方卡片获取

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 19
19 0
0- 0



 已为社区贡献60条内容
已为社区贡献60条内容

所有评论(0)