AI大模型开发
AI 大模型
1.大模型概念入门
①什么是大模型
-
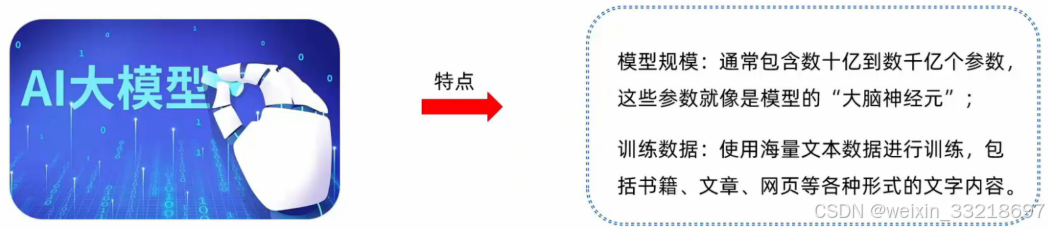
大模型,一般也称为 ‘大语言模型’, 是一种基于深度学习技术训练出来的人工智能系统,主要用于处理和生产人类语言.
-
-
大模型工作原理: 通过学习大量文本,掌握了语言的规律和知识,然后根据输入的提示(Prompt)生成响应的输出.
-
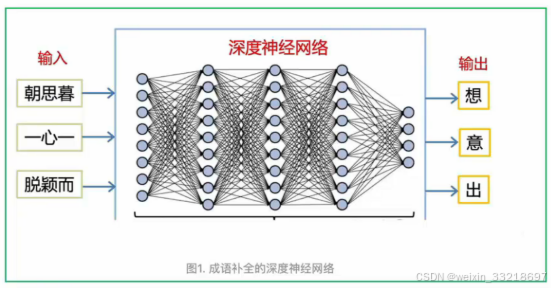
深度学习就是用层数较多(深)的人工神经网络从数据中学习输入和输出之间的映射关系的算法,而人工神经网络是受生物神经网络的结构和功能启发下设计的计算模型.
-
-
用深度学习训练得到的网络就叫深度神经网络,它可以简单的看成一个函数,能够完成任何输入到输出的转换.
-
比如:
- 我们可以用它玩成语补全的游戏,输入成语的前3个字, 让网络输出最后一个字. 如上图
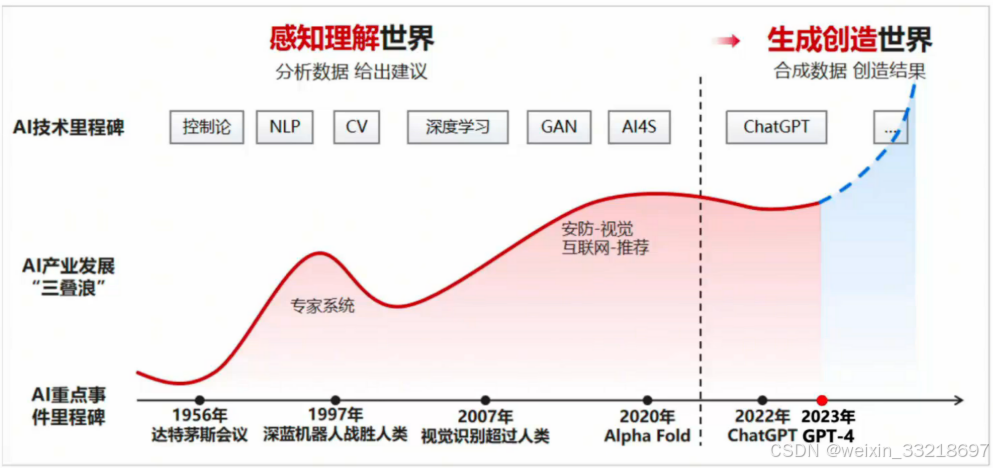
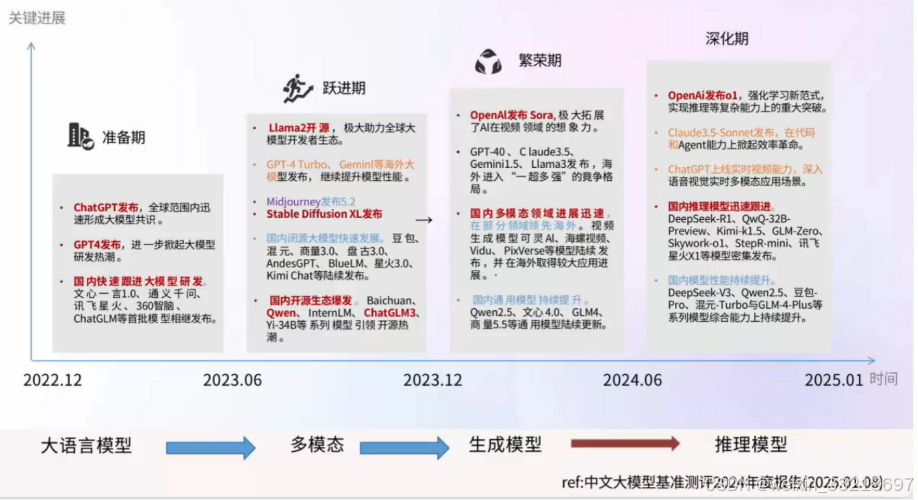
②大模型的发展
③大模型分类
- 大模型的分类:
- 语言大模型
- 语音大模型
- 图像处理大模型
- 多模态大模型
2.大模型核心运行机制
预训练大(语言)模型主要是基于深度学习技术所研发, 其核心开发的过程比较深奥,我们以简化的视觉去理解大模型是如何训练出来的.
大模型的实现原理可以简单归纳为: 三步走:
学会说话:
- 利用深度神经网络来训练语言模型,先收集尽可能多的文本,每次随机抽一段上文,让模型学会接着往下’背诵’. 由于看过和背锅的文字是在太多了(实际训练使用了几乎所有能从各种渠道获得的文字和图书资源),模型就可以像模像样的说话了
-
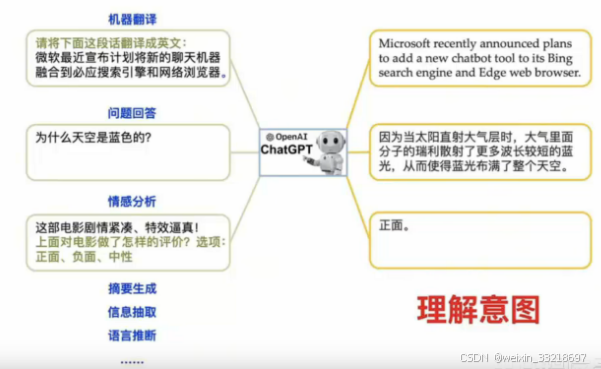
理解意图
- 简单的说就是理解用户的需求是什么?
- 自然语音(人类语音)是非结构化的,以中文为例,同样的含义可以有不同的说话.
- 通过训练,让大模型可以准确的识别用户的意图.
- 并基于 '给上文,补下文’的形式完成回答.
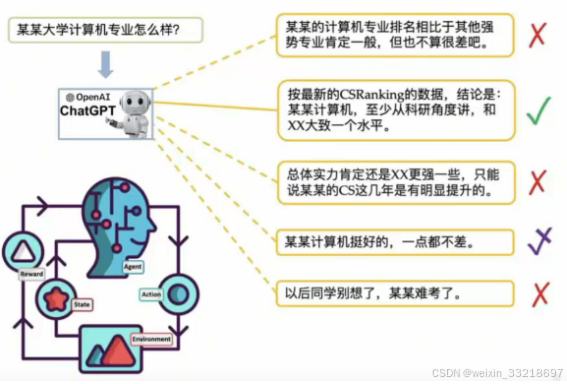
反馈择优
- 对于某些问题,模型可能会生成带有偏见,歧视或者令人不适的回答.另外,之前提到过.对于同一个问题,模型能够生成多个不同的回答.
- 这一步中我们让人们对同一问题的不同回答进行排序然后才有强化学习算法进一步调整模型,使输出回答更符合人们的期望.
3.DeepSeek和蒸馏模型
①DeepSeek介绍
- 公司简介:Deepseek全称杭州深度求索人工智能基础技术研究有限公司,简称深度求索 成立于2023年7月,是幻方量化旗下的AI公司,专注于实现通用人工智能(AGI),具有深 厚的软硬件协同设计底蕴,
- Deepseek共研发开源十余款模型,目前最受关注的有V3对话模型和R1推理模型,分别于 2024年12月26日和2025年1月20日先后发布。从反映关注度的微信指数上可以看出,两次 模型发布都造成了后续Deepseek关注度的飙升,12月28日DeepSeek指数达到约6000万,1 月31日达9.8亿;
-
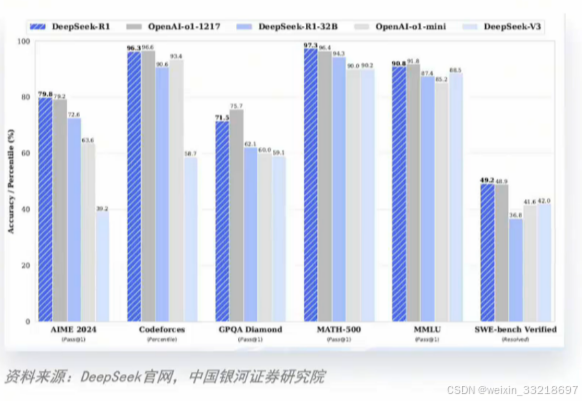
OpenAI的o1模型性能曾在推理模型领域难逢敌手;
-
Deepseek-R1模型,在AI模型基准能力的各大榜单中,得分与0penAI o1模型不相上下;
-
Deepseek R1 模型的出现,终结了中国AI落后的观点;
-
作为国产模型,Deepseek对中文支持更好
-
Deepseek-R1的推理能力进入了第一梯队(美0penAI01)
其训练和推理成本低(仅有openAI的十分之一)、速度快、技术全部开源; -
Deepseek打破了硅谷传统的“堆算力、拼资本”的大模型发展路径。
-
②如何得到模型
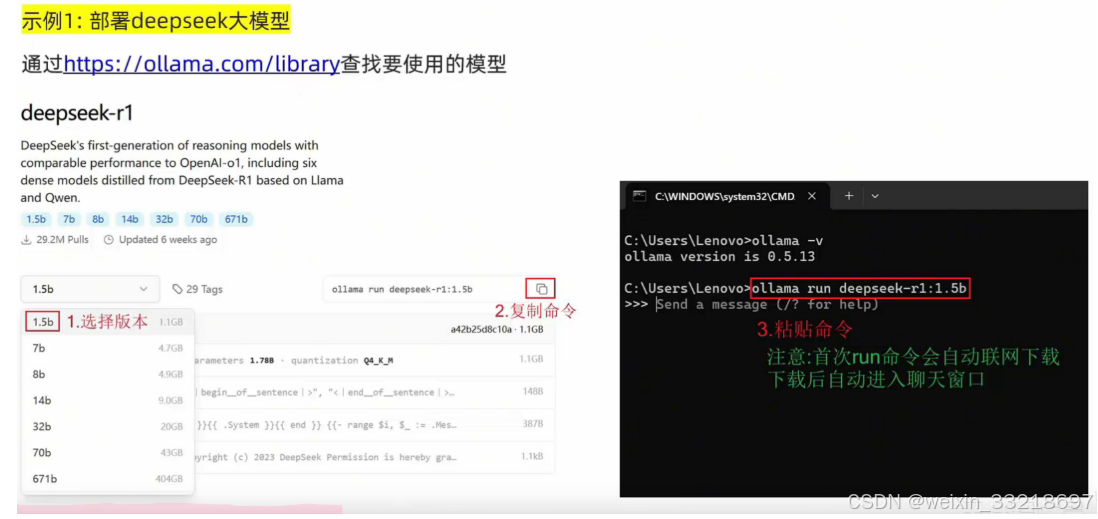
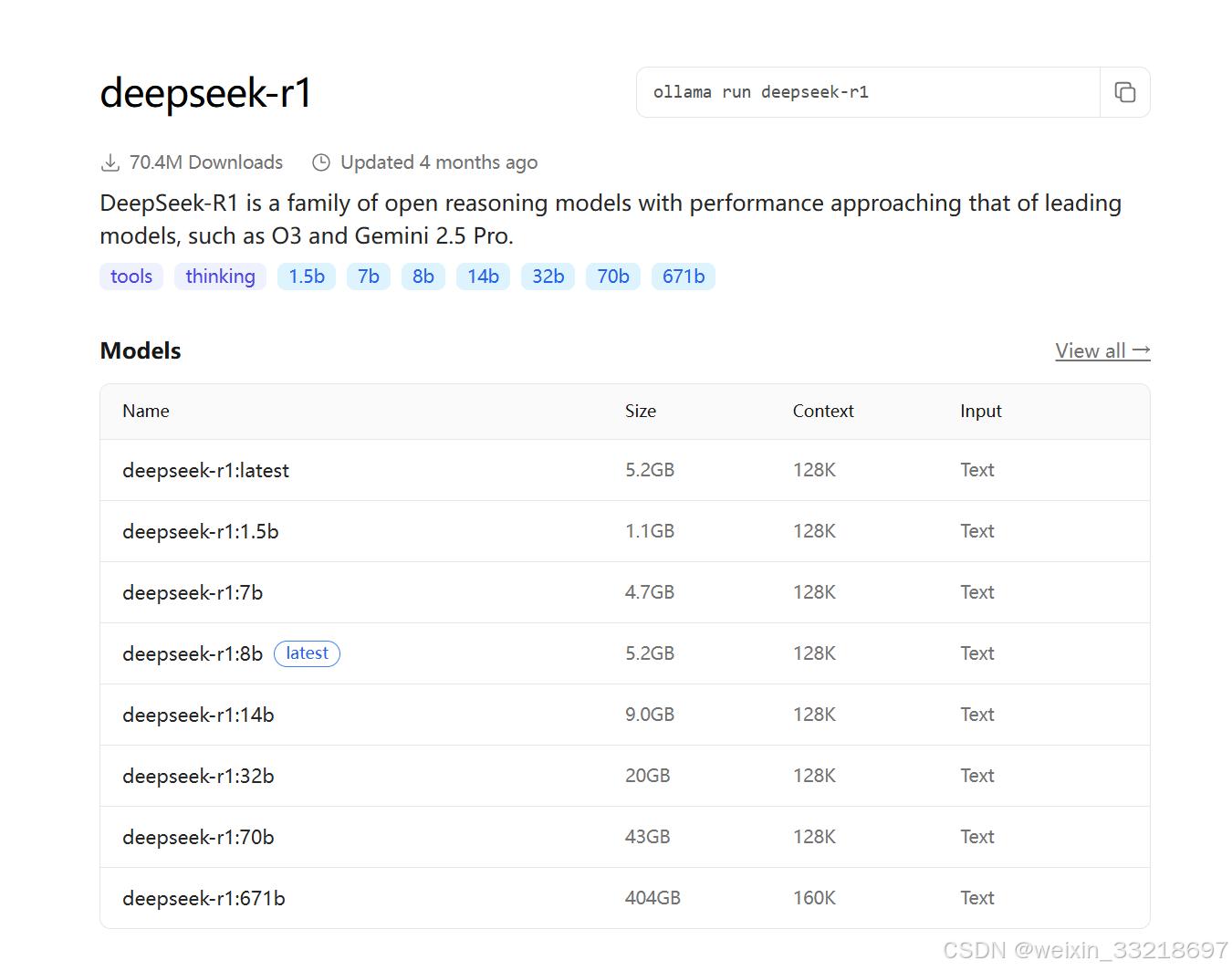
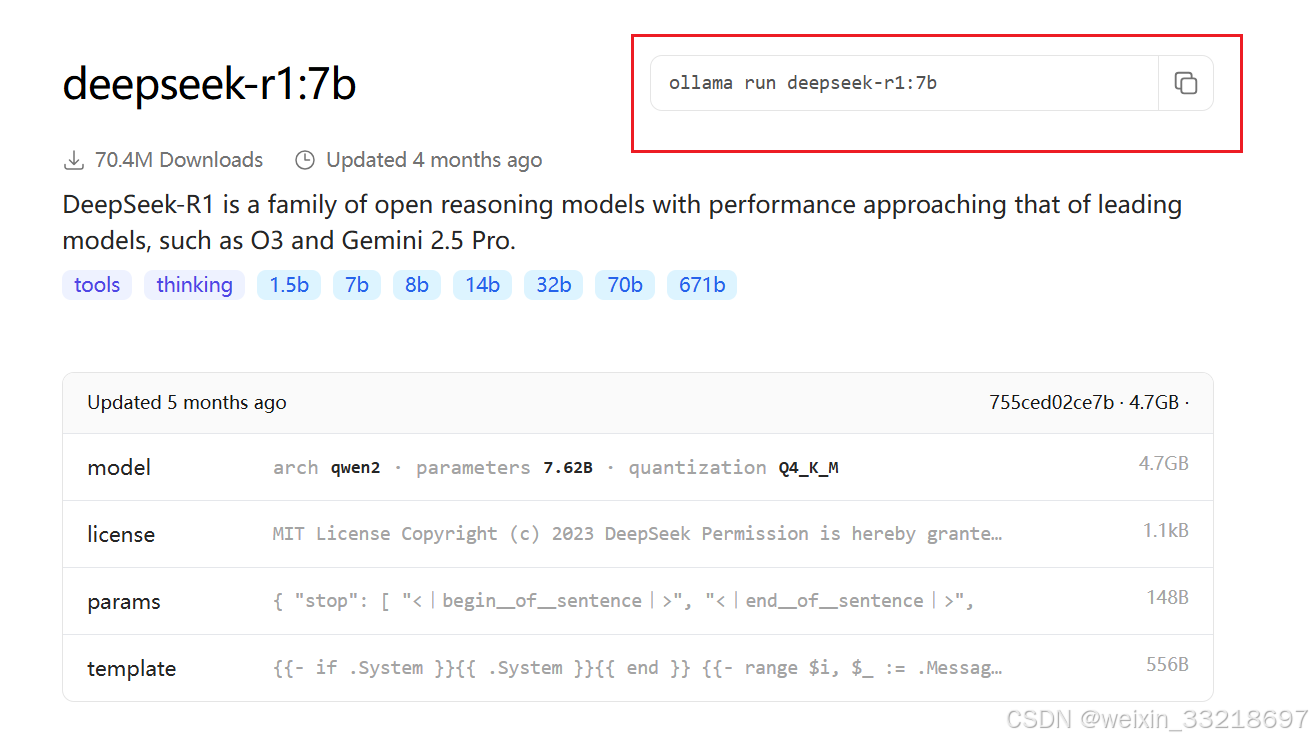
很多的大模型是开源的,以deepseek为例,其r1模型就是开源的,任何人都可以下载得到它的模型。
https://github.com/deepseek-ai/DeepSeek-R1
我们可以直接下载,得到deepseek-r1模型,如1.5b参数的蒸馏模型下载地址:
https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B/tree/main
③大模型的蒸馏
- 大模型的运行需要极高的硬件资源,通常都是服务器集群并挂载数量众多的GPU(显卡)
为了满足低性能设备的运行,可以对大模型进行蒸馏。 - 假设你有一个超强的老师(大模型),他能讲解很复杂的知识。
你想把这些知识传授给一群学生(小模型)。为了让学生们能
在不需要过多时间和资源的情况下,快速掌握老师的知识,你
可以通过“蒸馏”这种方式,让学生们只学习最精华、最重要
的部分。这样,学生虽然没有老师那样强大,但依然能做出优
秀表现。
4.私有化部署实战需求介绍
①什么是聊天机器人
②聊天机器人特点
- 1.自然语言理解(NLP):能够理解用户输入自然语言,并从中提取意图和关键信息
- 2.对话管理:通过对话引擎维持对话的连贯性,根据上下文生成合适的回答
- 3.个性化交互:可以根据用户的历史记录和偏好提供定制化的回答
- 4.多功能性:除了聊天,还可以执行任务,如查询信息、预订服务、提供帮助等。
③常见聊天机器人
- Deepseek
- 由杭州深度求索人工智能基础技术研究有限公司研发,其核心优势在于性能卓越、低成本开发和开源策略
- Kimi智能助手
- 由月之暗面科技有限公司开发,支持超长上下文(最高200万汉字),适合长文本处理和复杂对话
- 通义千问
- 阿里云推出的人工智能助手,适合办公场景,提供高效的信息处理能力。
- 讯飞星火
- 科大讯飞出品,支持语音输入和语音朗读回复,适合语音交互场景。
- 豆包
- 字节跳动推出,支持抖音和今日头条的内容信息获取,适合内容创作和信息检索。
智聊机器人效果展示
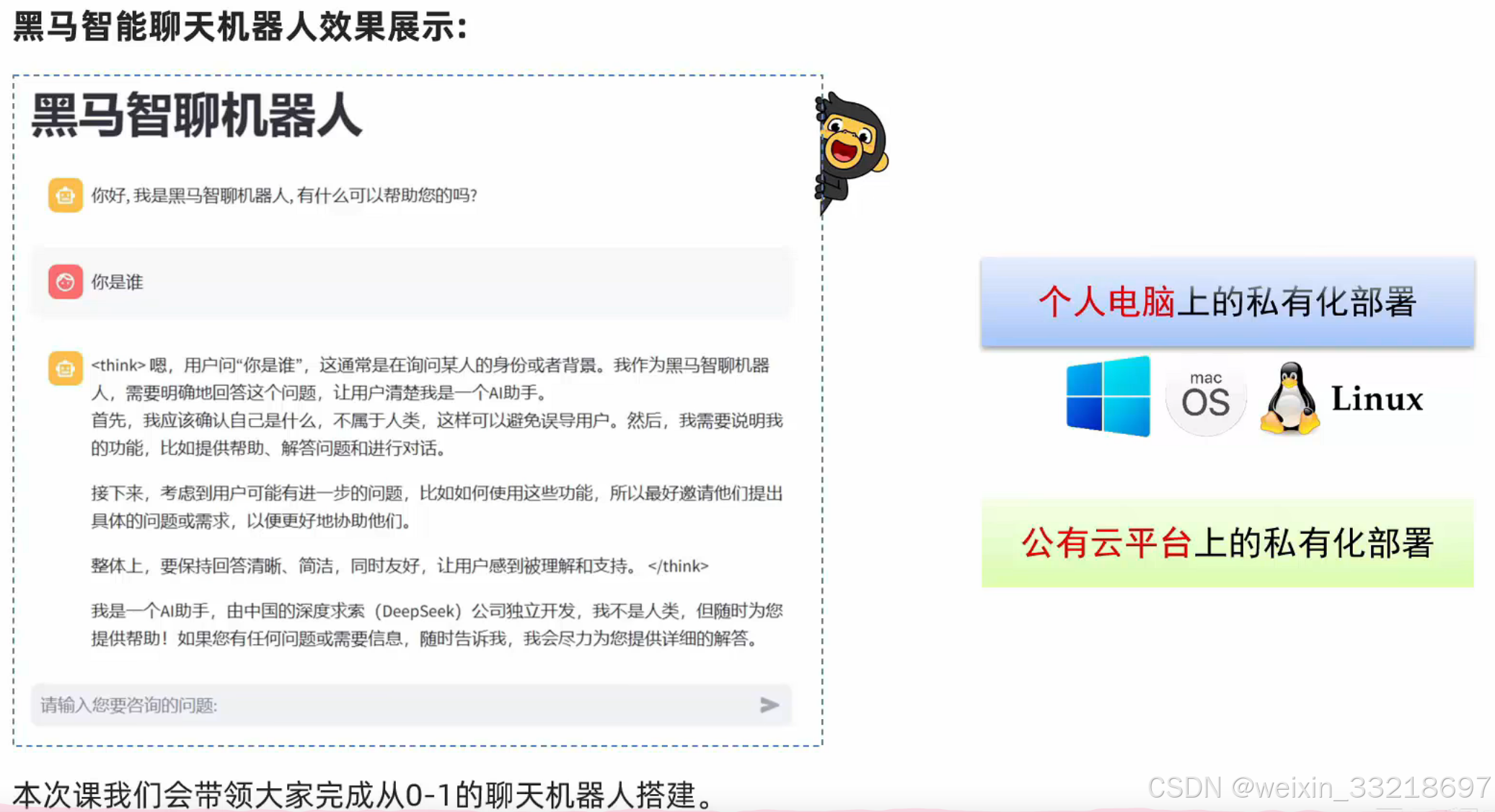
我们要学什么?
- 在自己的电脑上,部署属于自己的聊天机器人(Windows、MacOS、Linux)
- 在云平台服务器上(Linux),部署属于自己的聊天机器人
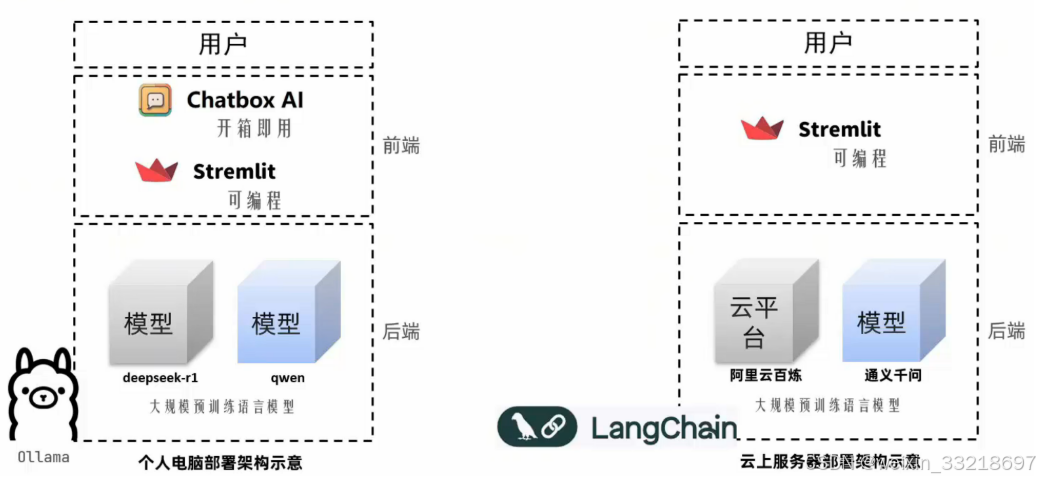
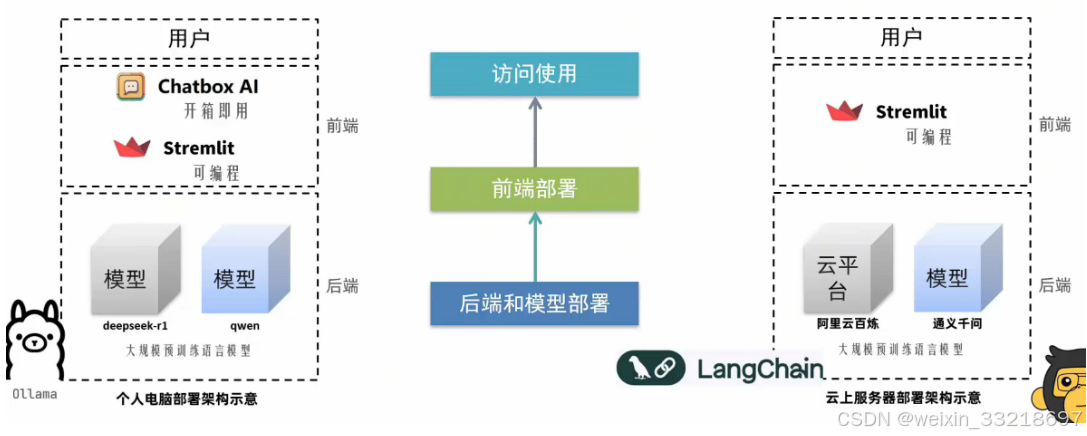
5.私有化部署实现项目架构分析
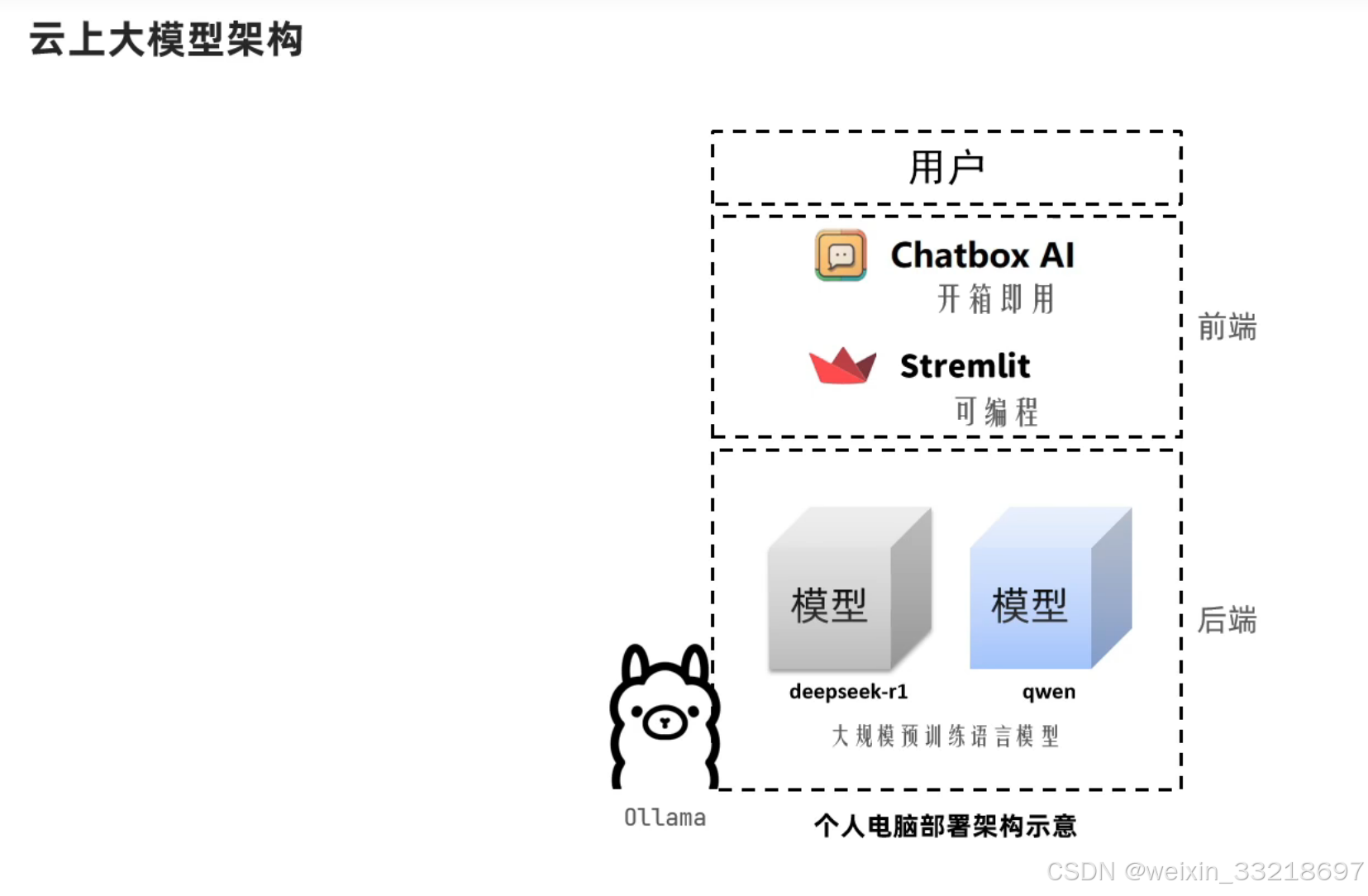
- 个人电脑智聊机器人技术架构
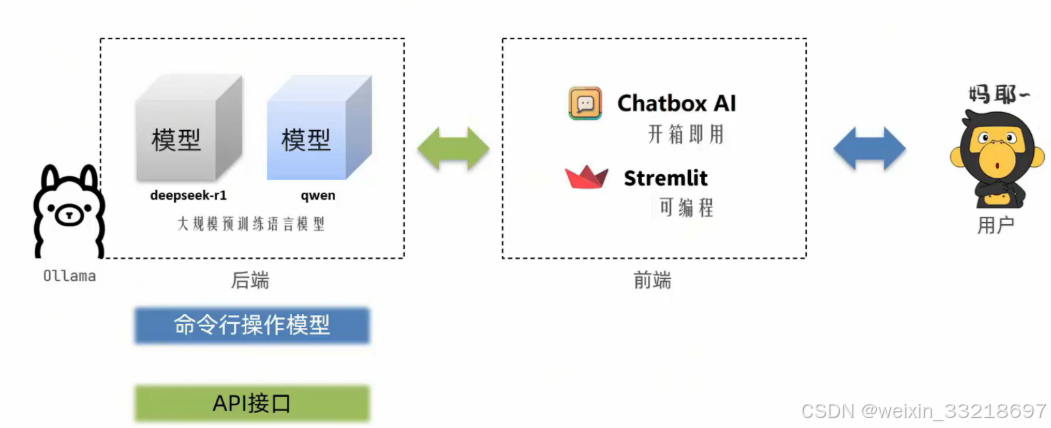
- 云平台智聊机器人技术架构
- 学习流程
6.Ollama介绍
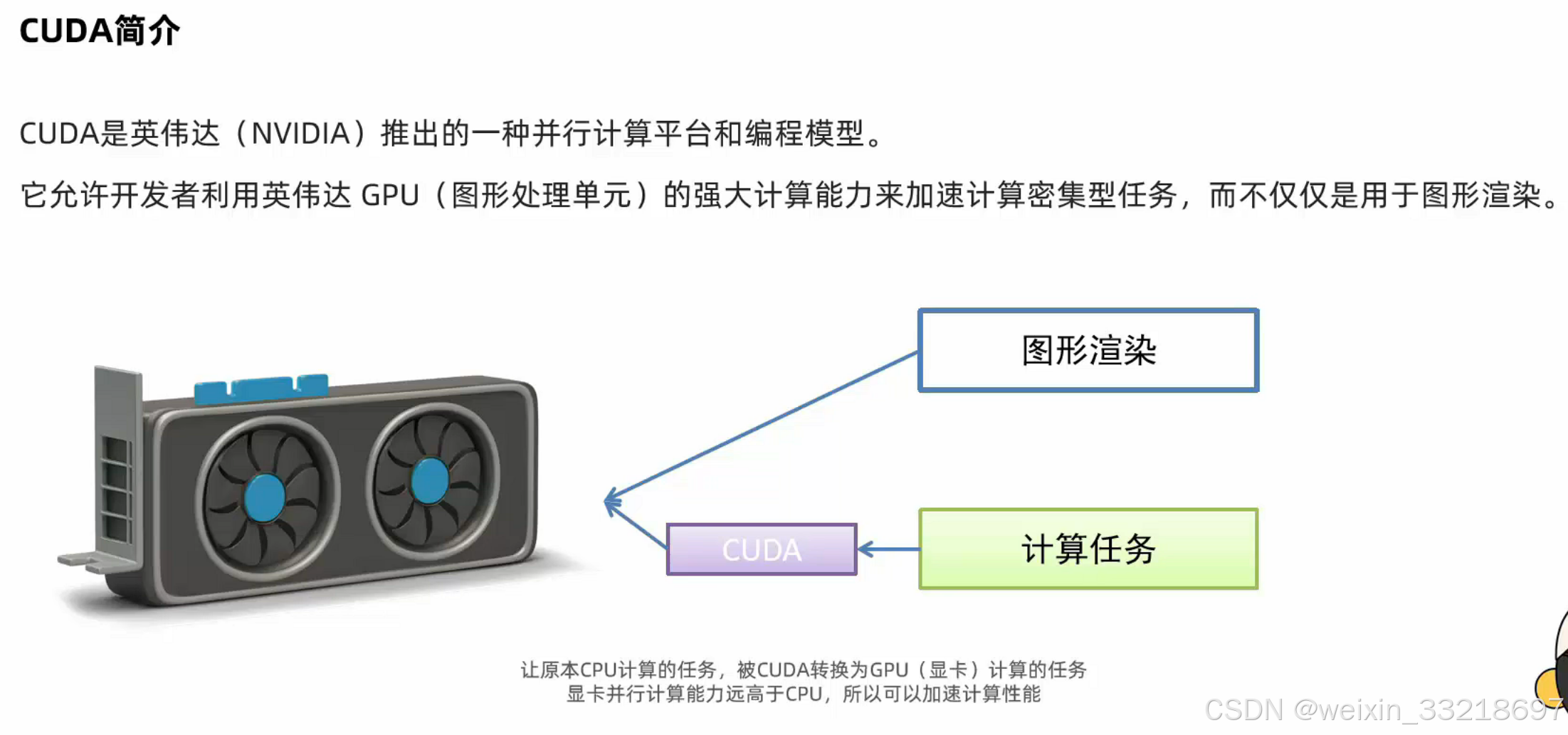
Ollama介绍
- ollama:是一款旨在简化大型语言模型本地部署和运行过程的开源软件。
- ollama提供了一个轻量级、易于扩展的框架,让开发者能够在本地机器上轻松构建和管理LLMS(大型语言模型
- 通过ollama,开发者可以导入和定制自己的模型,无需关注复杂的底层实现细节。
- 网址:https://ollama.com
Ollama模型库
- ollama 支持多种开源模型,涵盖文本生成、代码生成、多模态推理等场景。用户可以根据需求选择合适的模型,并通过简单的命令行操作在本地运行。
- ollama 官方模型库: https://ollama.com/library
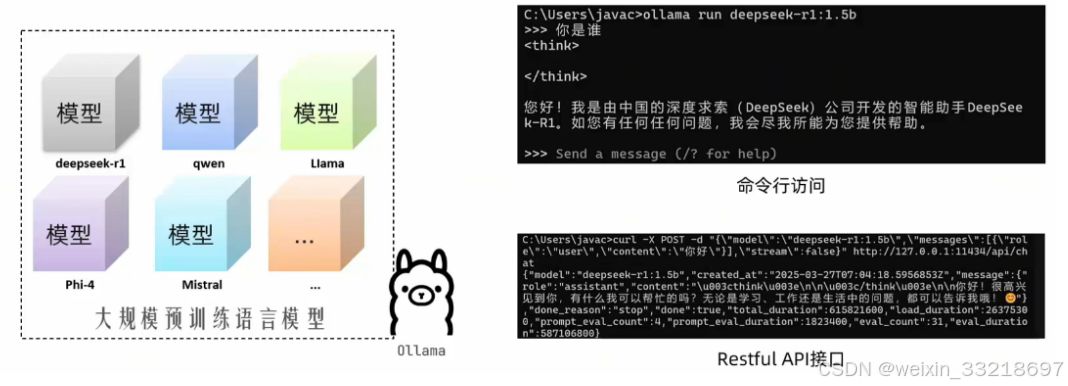
7.Windows系统Ollama私有化模型部署
Windows系统安装Ollama
- 1.下载Ollama,Windows系统安装包:https://ollama.com/download
- 2.双击提前下载好的0llamaSetup.exe安装包,选择install,然后一直默认安装即可


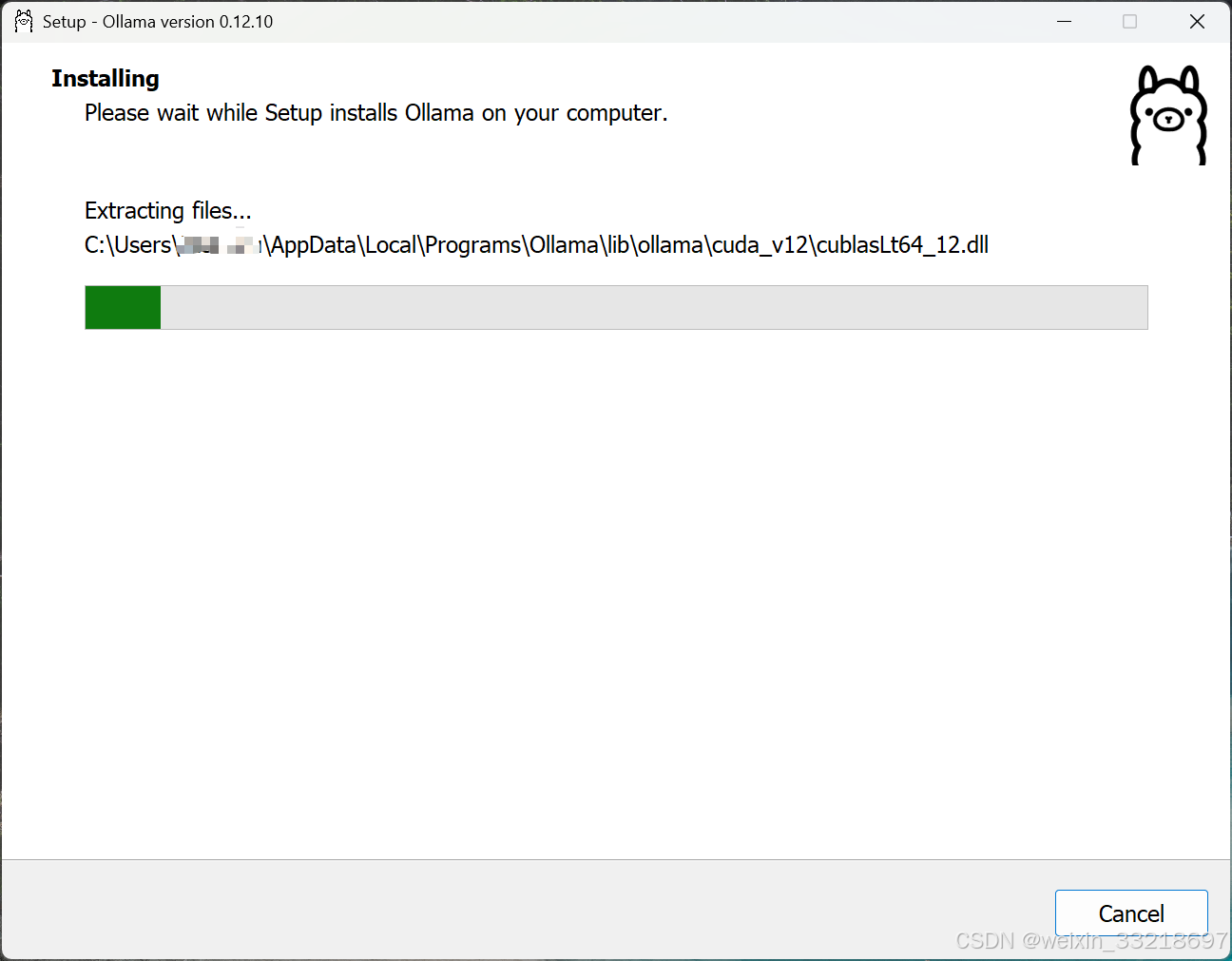
2.win+R打开终端,输入ollama-v命令查看是否安装成功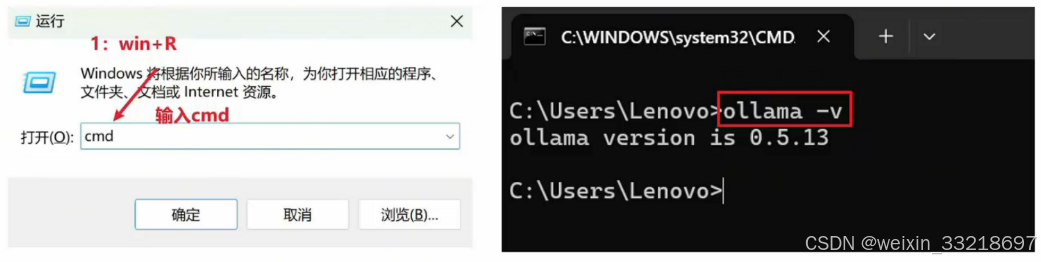

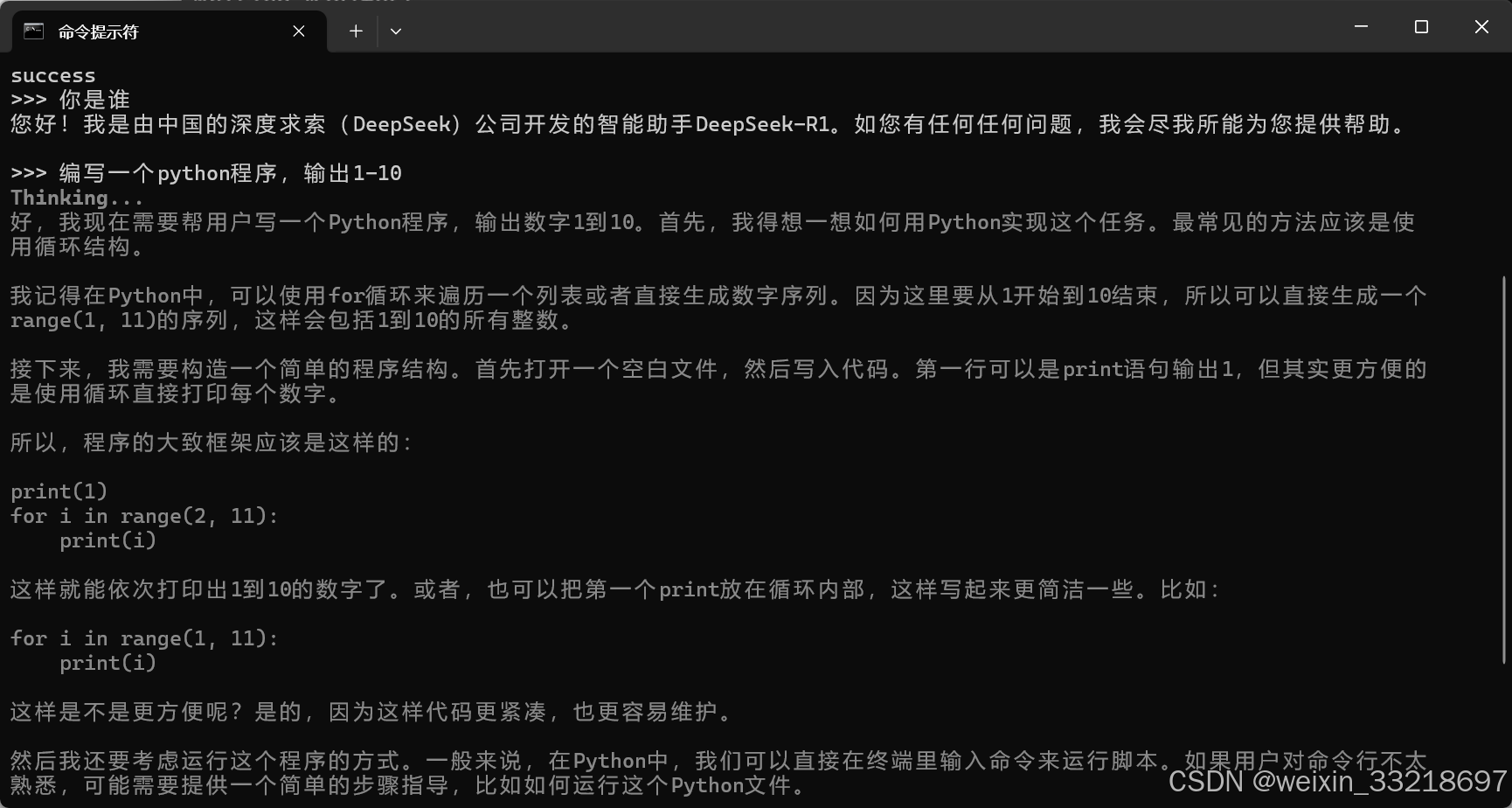
目前新的版本,只要下载Ollama就会自动弹出一个窗口,不再是之前只能通过命令行进行提问了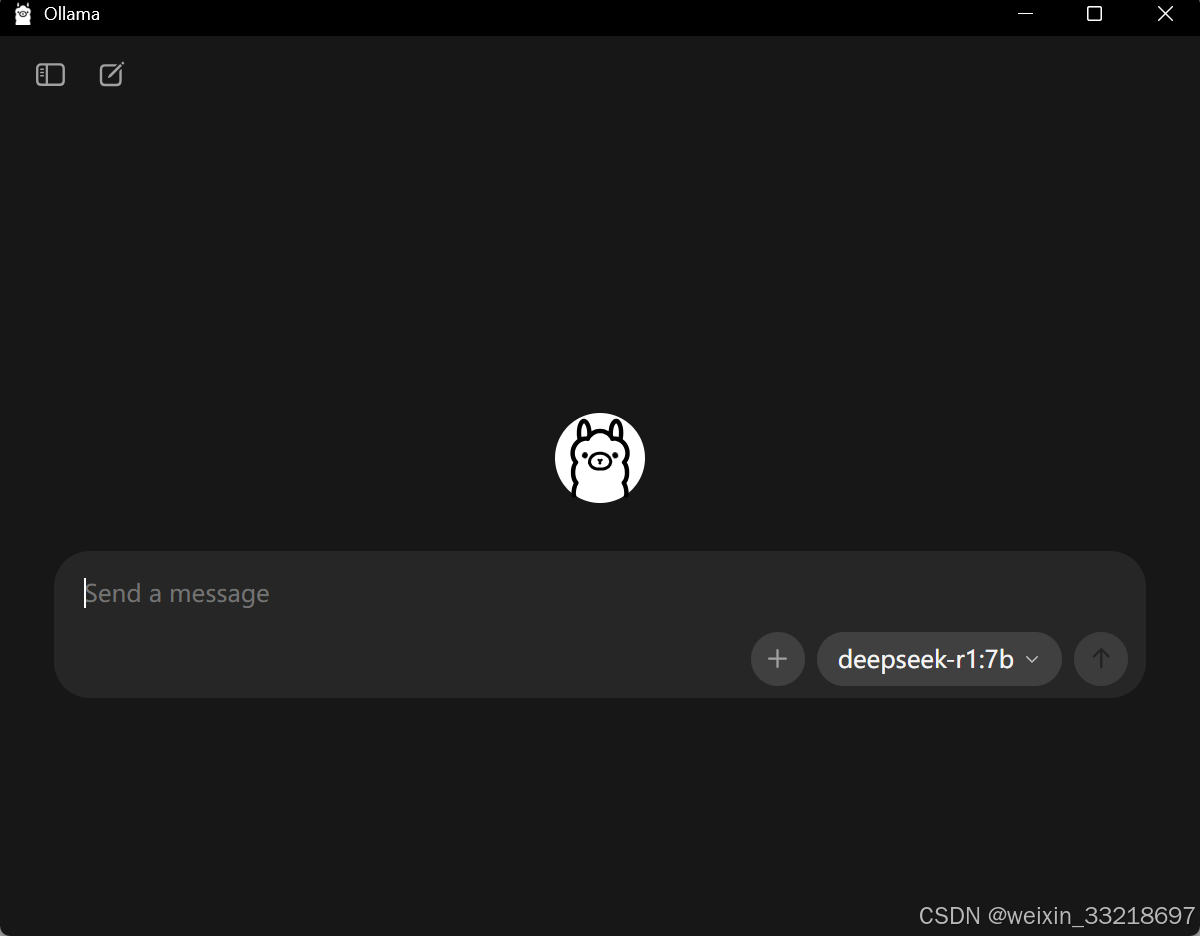
8.Windows系统-基于Chatbox部署大模型前端

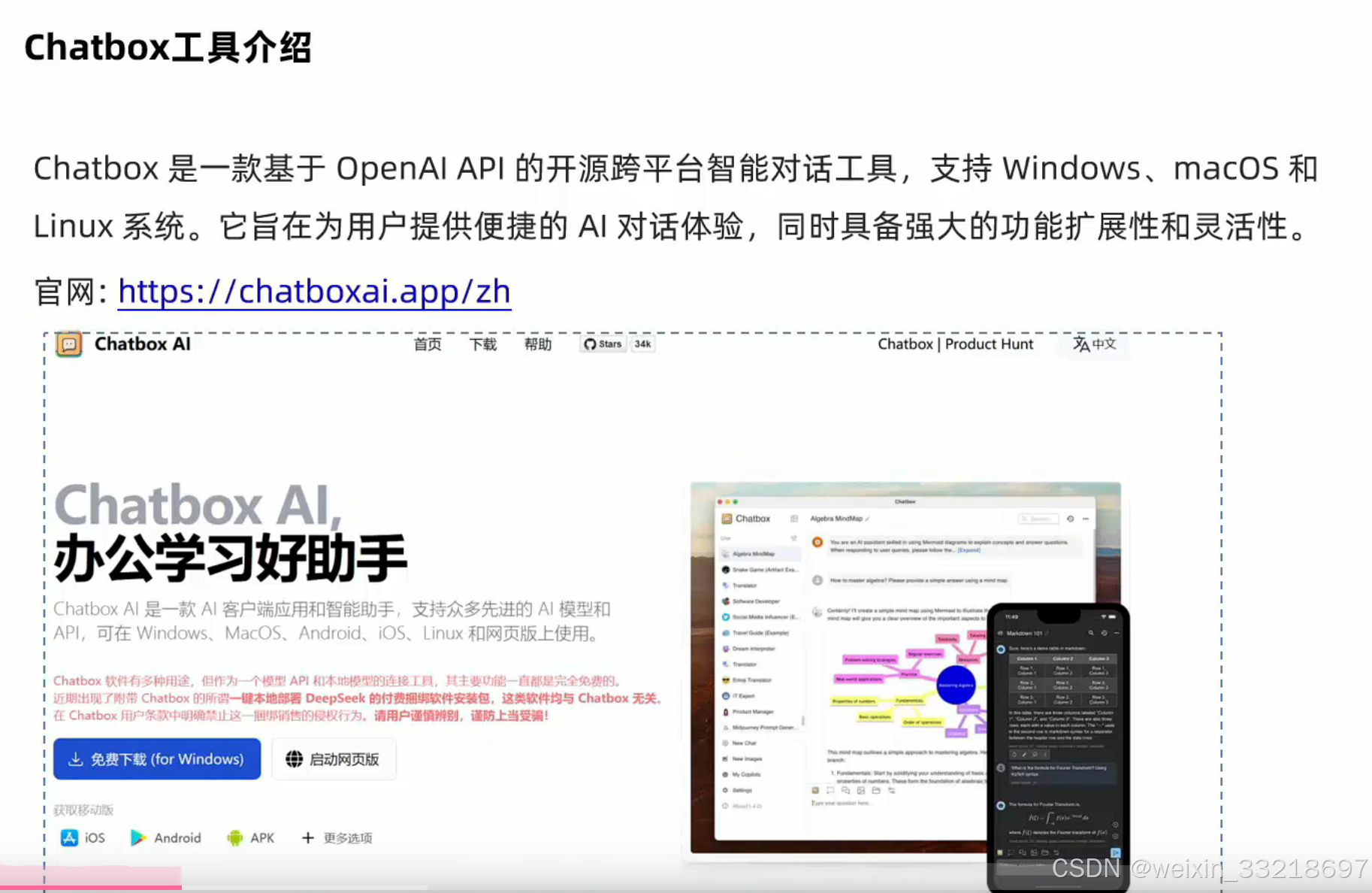
Chatbox 是一款功能强大、易于使用的开源 A1 工具,适合开发者、学生、办公人员等多种用户群体。
- 1.下载安装
- 访问 Chatbox 官网,下载并安装适合您操作系统的安装包(Windows、macOS 或 Linux)。
- 2.配置 API
- 打开 Chatbox,进入设置菜单。
- 选择ollama中本地部署的模型,并保存配置。
- 3.开始对话
- 主界面,创建对话窗口,在输入框中输入问题或指令
- 4.保存和退出
- 聊天记录会自动保存到本地。
新版界面点进去就是只有一个设置提供方,然后如下图点击Ollama,然后点击获取刷新一下。在Ollama是运行的情况下,刷新一下就会出现刚刚下载的deepseek大模型(我看c盘有点小就没有下qwen),然后点击加号就行。设置完成之后点击右上角的ESC退出设置的界面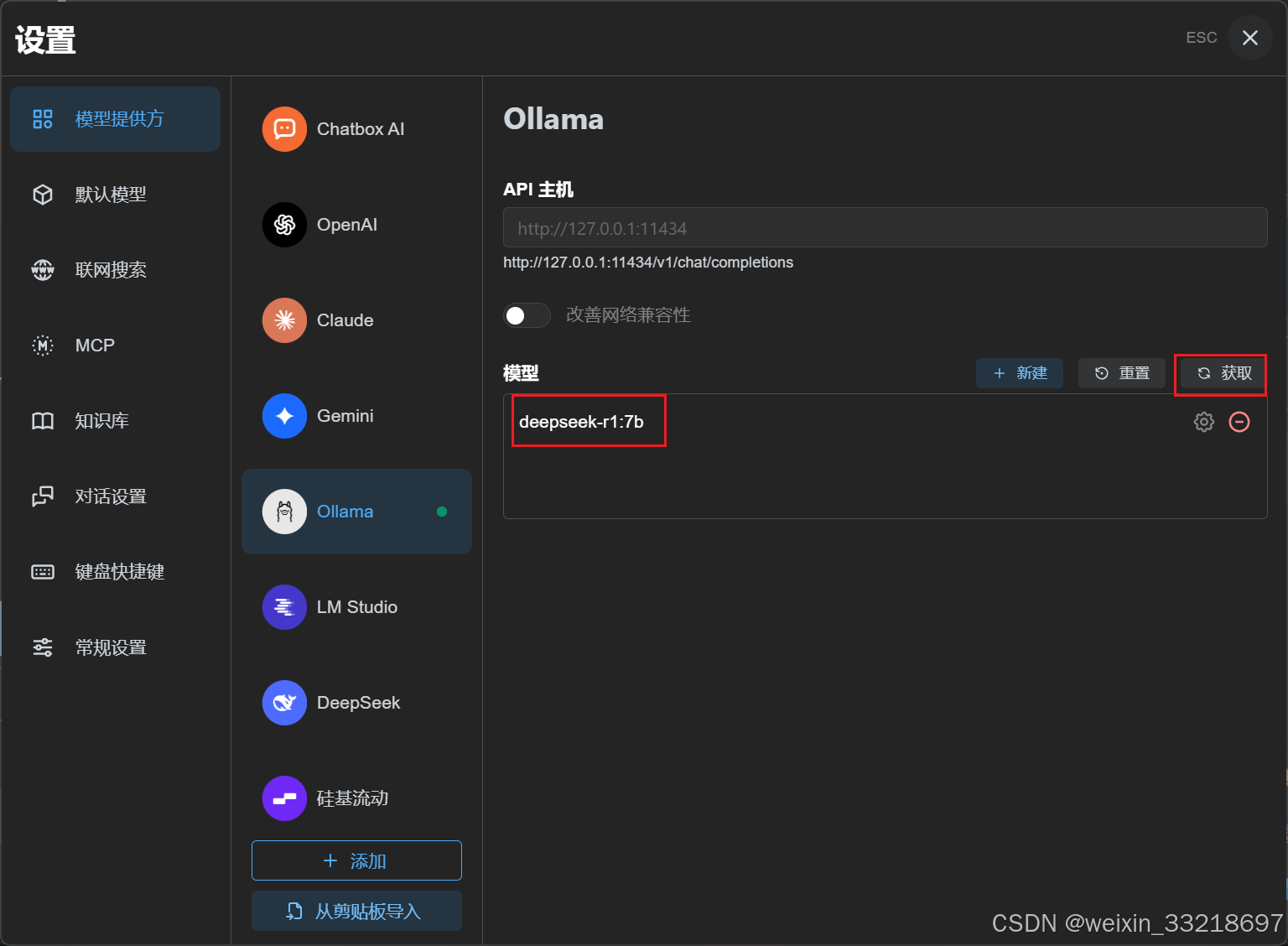
然后也可以进行提问,不过我问问题它回答的特别慢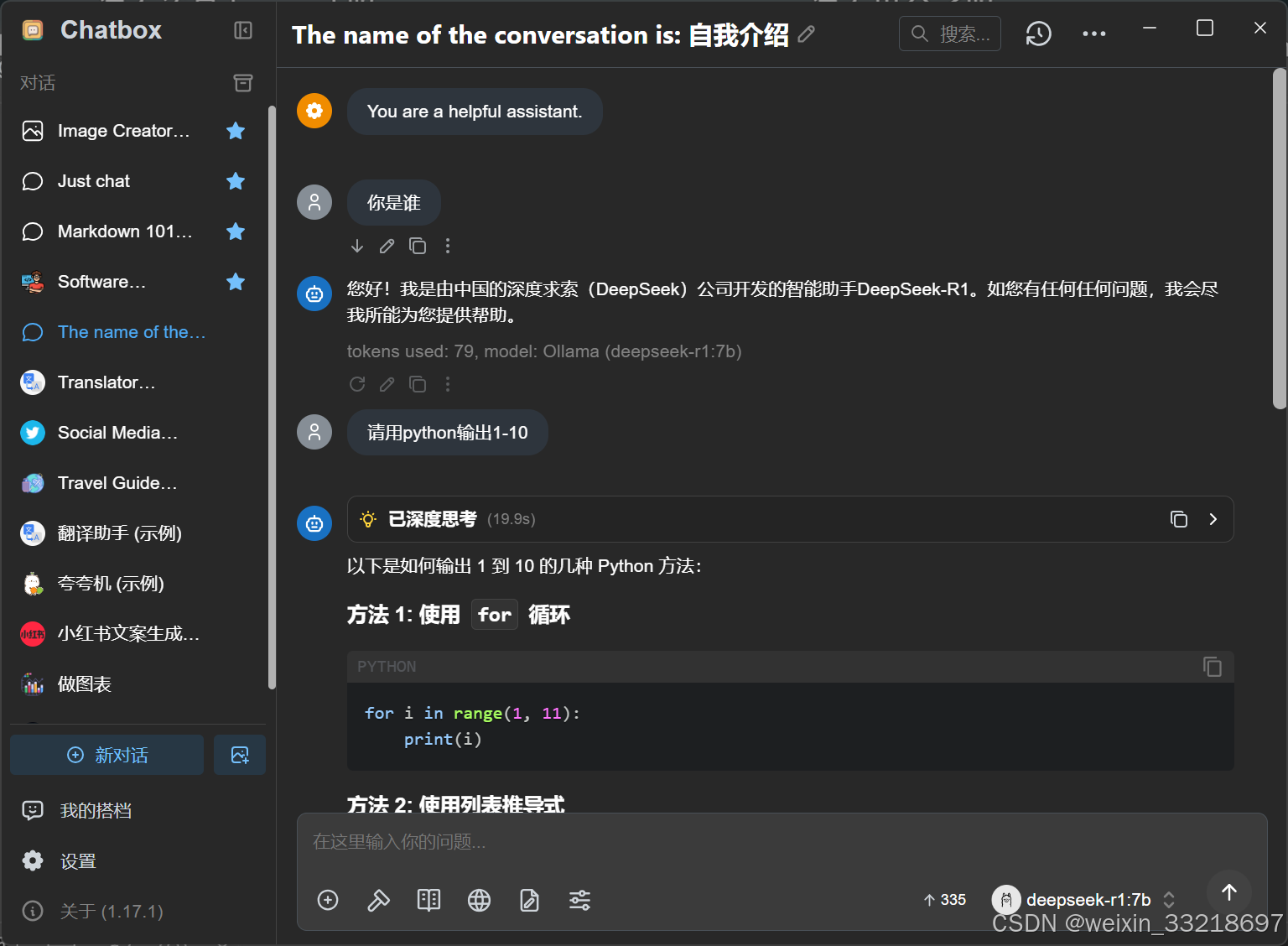
9.Windows部署WSL环境(Ubuntu)环境
为什么要用WSL
- WSL作为Windows10系统带来的全新特性,正在逐步颠覆开发人员既有的选择。
- 传统方式获取Linux操作系统环境,是安装完整的虚拟机,如VMware
- 使用WSL,可以以非常轻量化的方式,得到Linux系统环境
目前,开发者正在逐步抛弃以虚拟机的形式获取Linux系统环境,而在逐步拥抱WSL环境.所以,课程也紧跟当下趋势,为同学们讲解如何使用WSL,简单、快捷的获得Linux系统环境。所以,为什么要用WSL,其实很简单:
- 开发人员都在用,大家都用的,我们也要学习
- 实在是太方便了,简单、好用、轻量化、省内存
什么是WSL
WSL:Windows Subsystem for Linux,是用于Windows系统之上的Linux子系统
作用很简单,可以在Windows系统中获得Linux系统环境,并完全直连计算机硬件,无需通过虚拟机虚拟硬件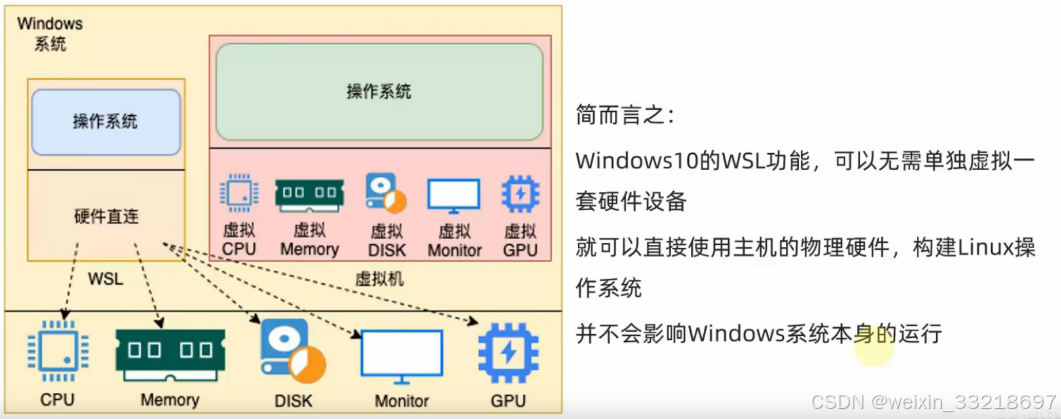
WSL部署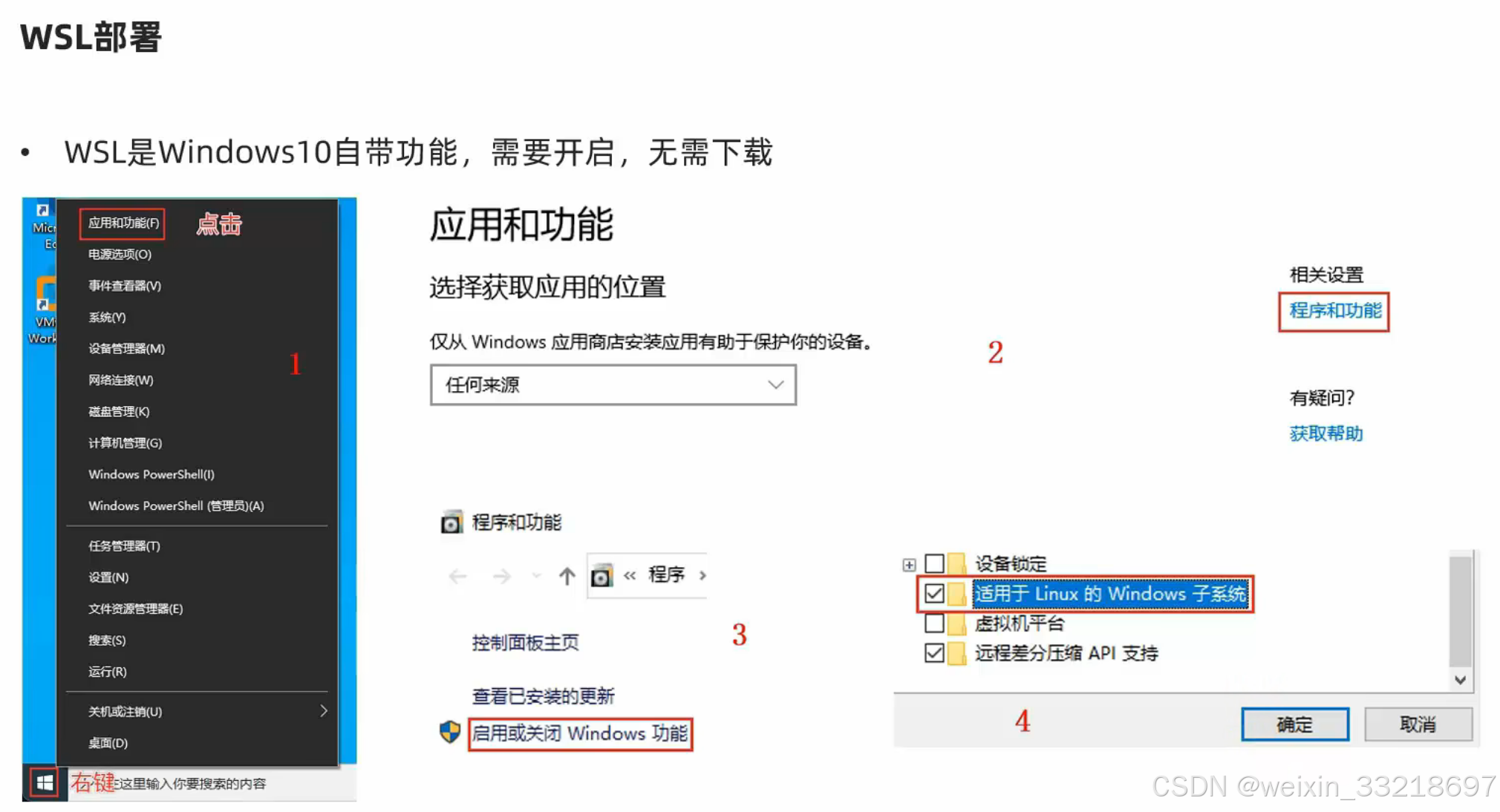
直接搜索就行
如下图,我看我这个打开就是勾选上的,我就没动了。大家没勾就按老师的进行操作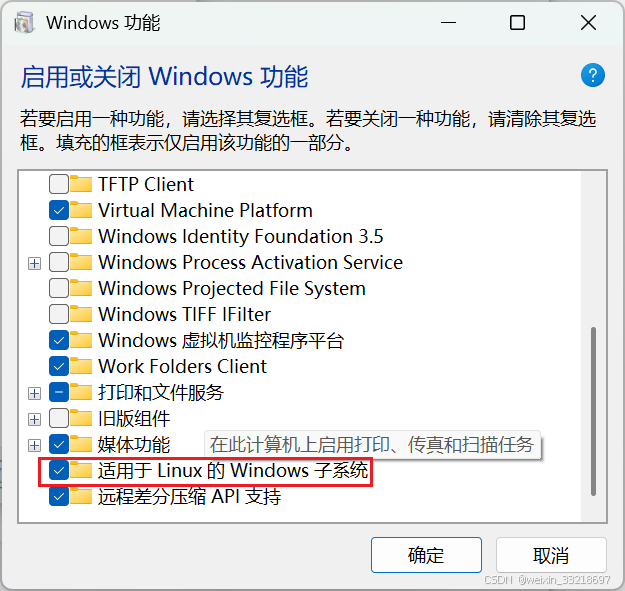
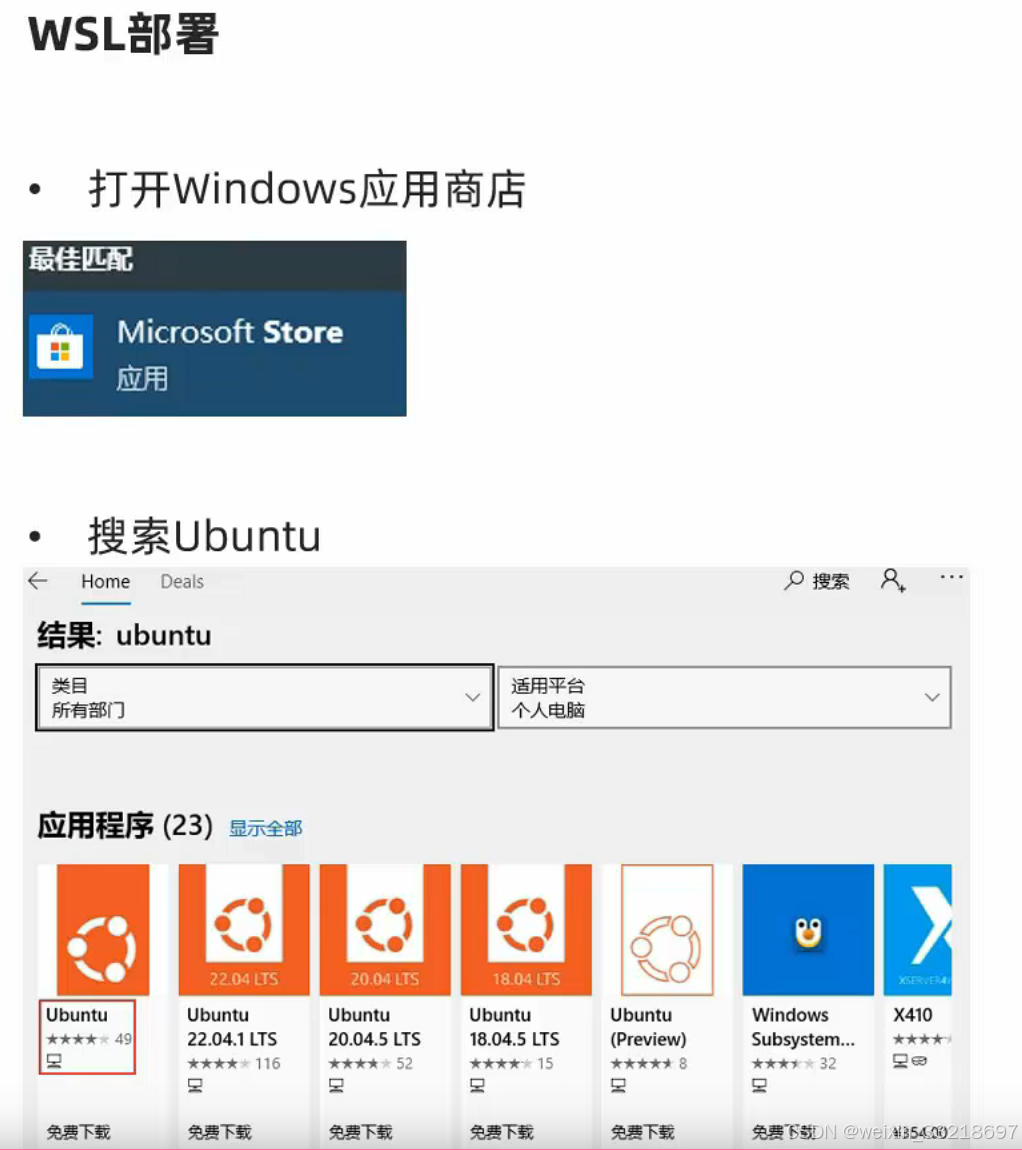

我就说我怎么前面那里不用勾选,我之前自己捣鼓安装过一个22.04.5 LTS版本的,当前研究半天搞不明白。视频中说直接下载Ubuntu即可,我也不懂,我先用我直接乱下的这个试试看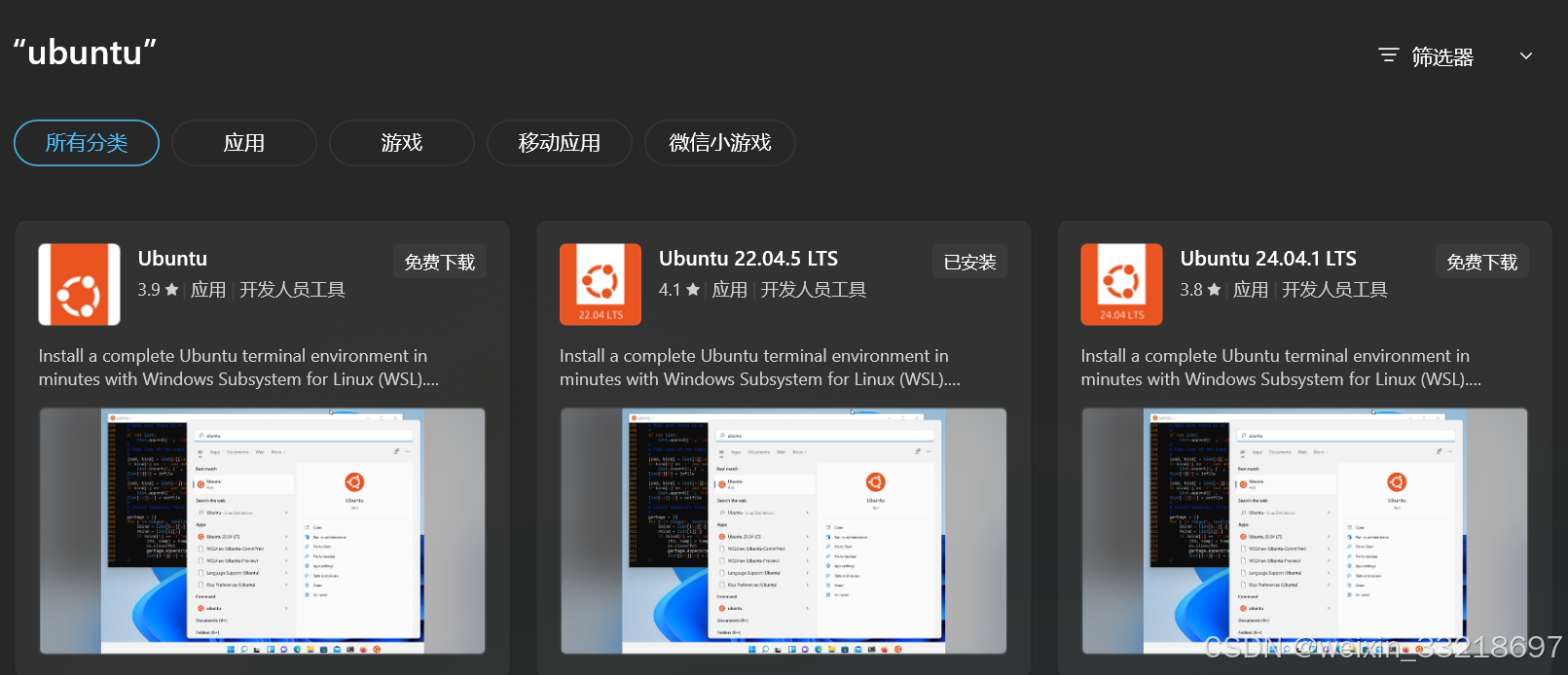
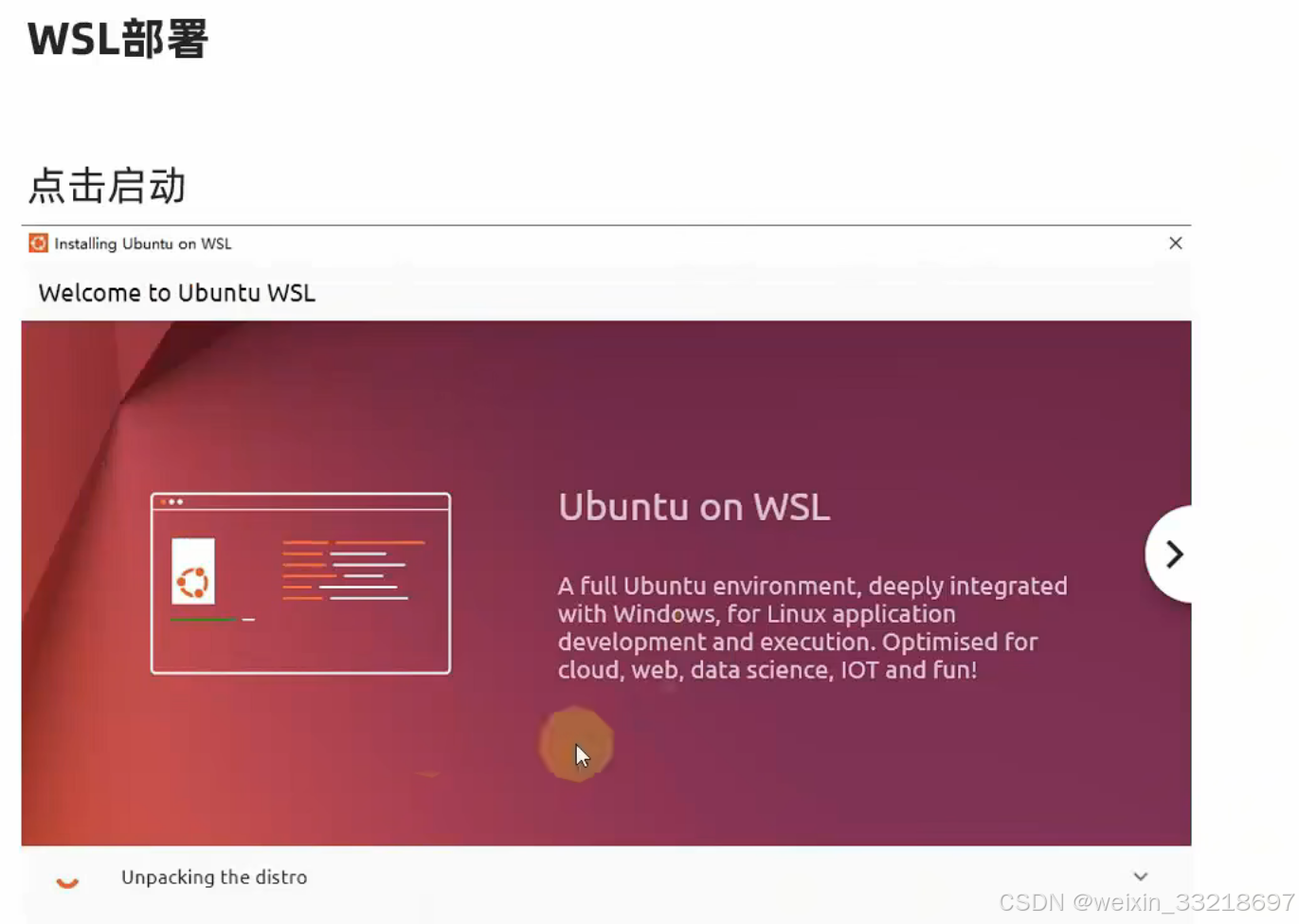

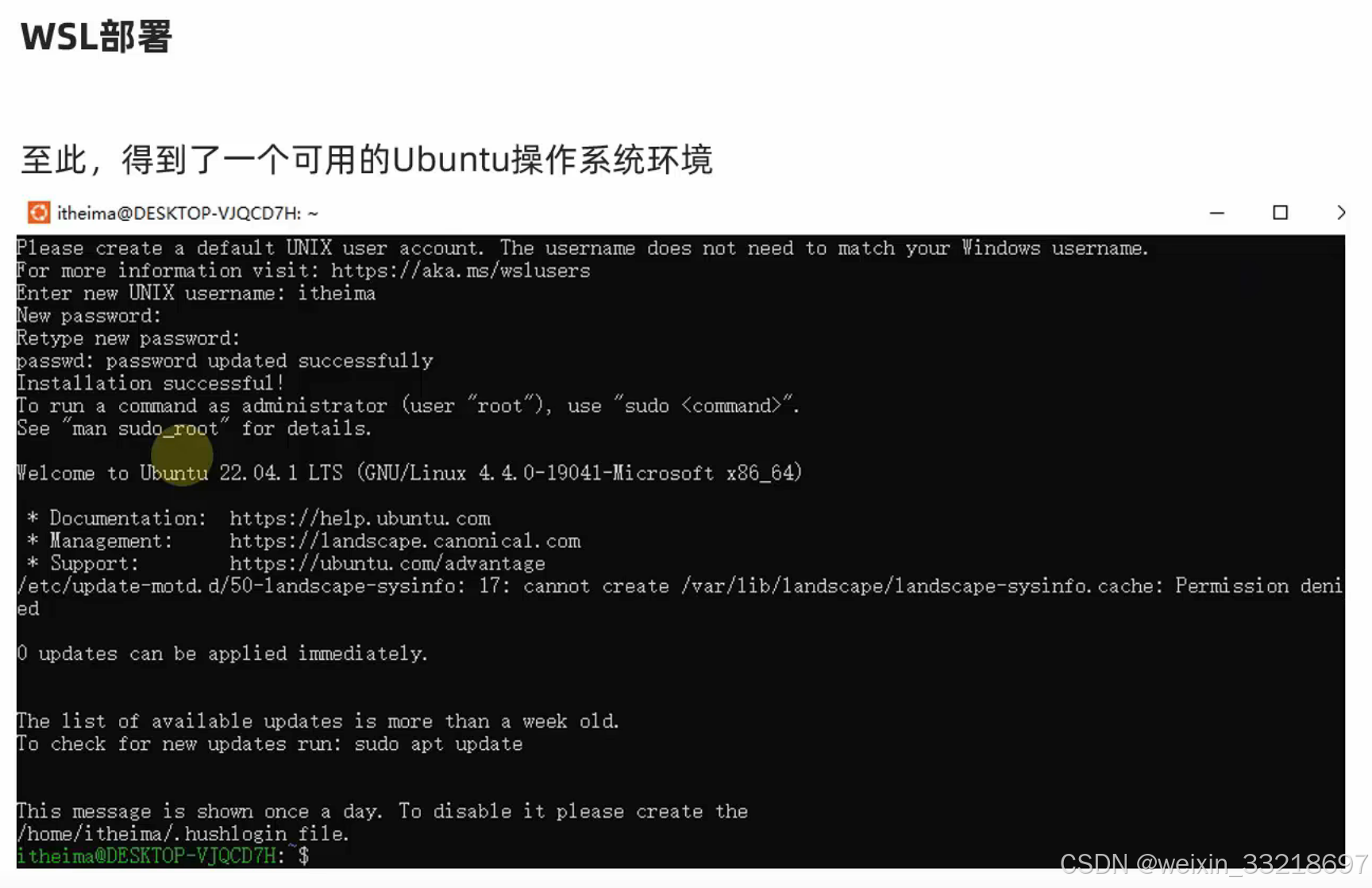
下面这个就是我自己搞的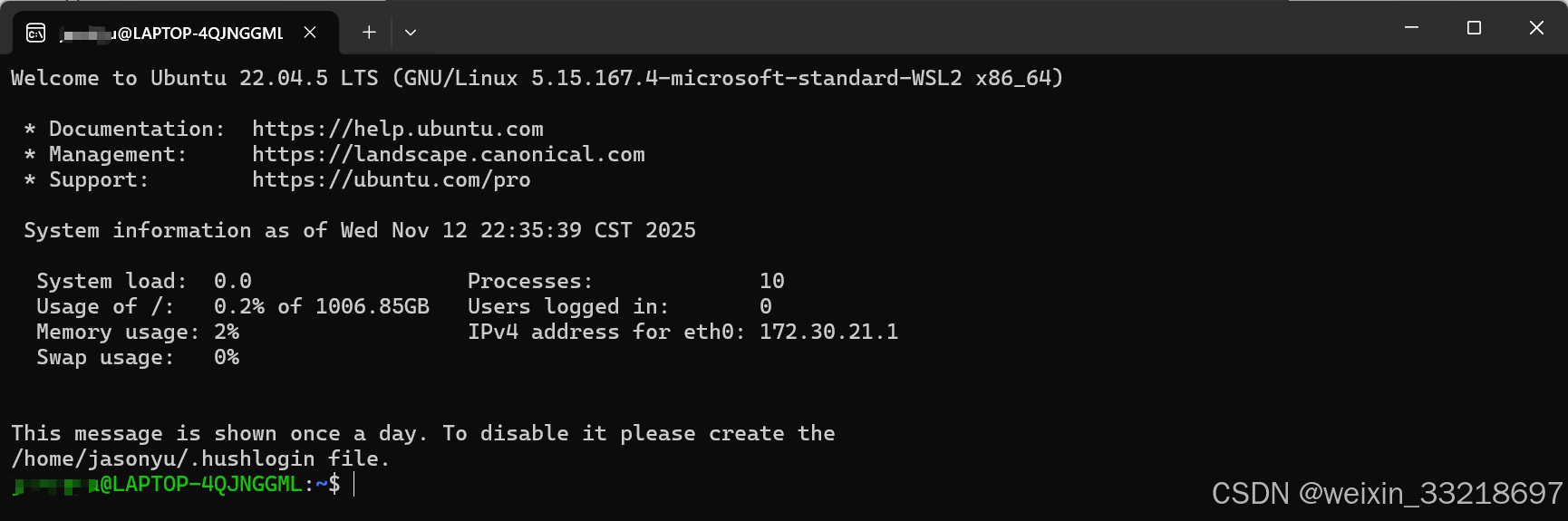
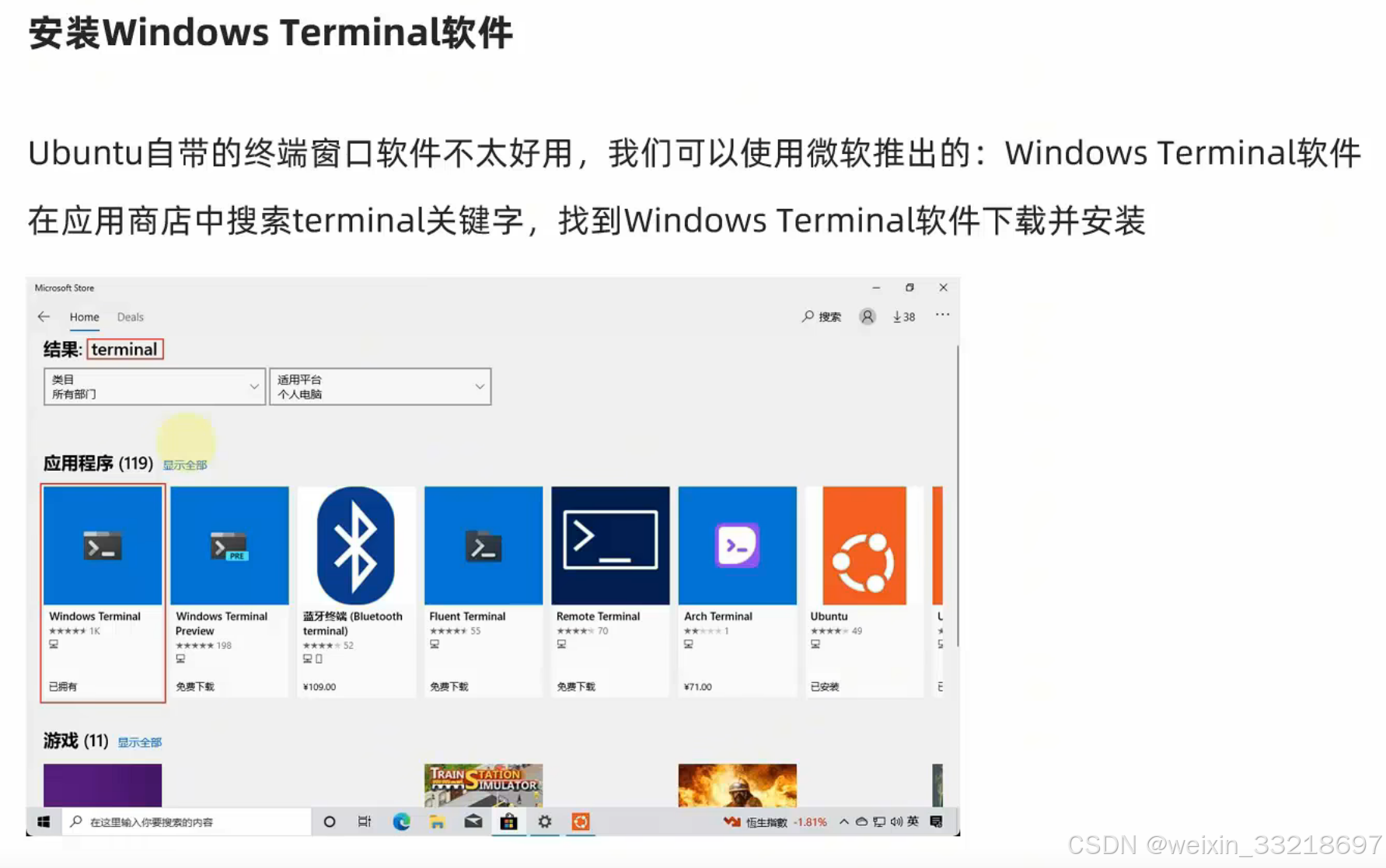
学着和老师一样配置默认打开Ubuntu(我这里就配的是22.04.5 LTS)之后,可以把终端和WindowsPowerShell都固定到开始屏幕上。然后点击终端就是和点击Ubuntu图标一样的效果
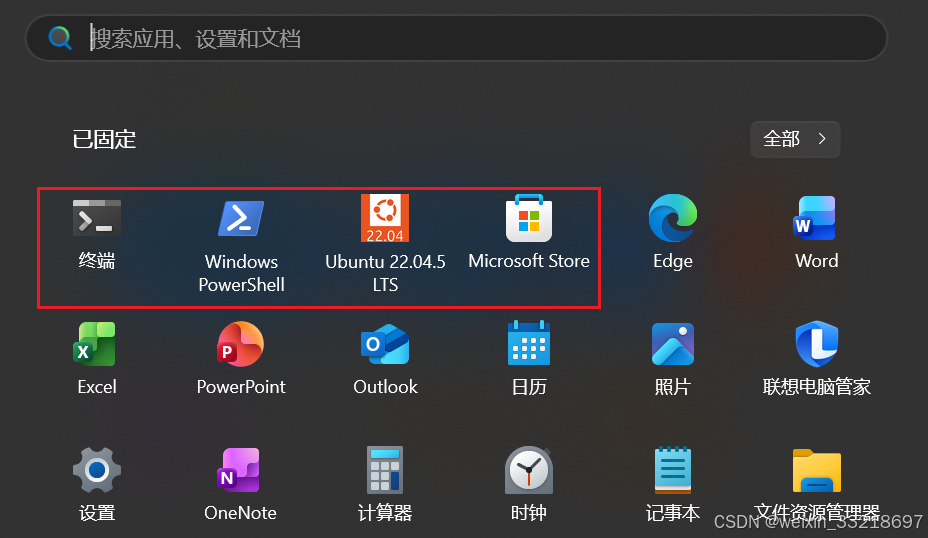
10.Linux部署Ollama

下图是我自己查出来的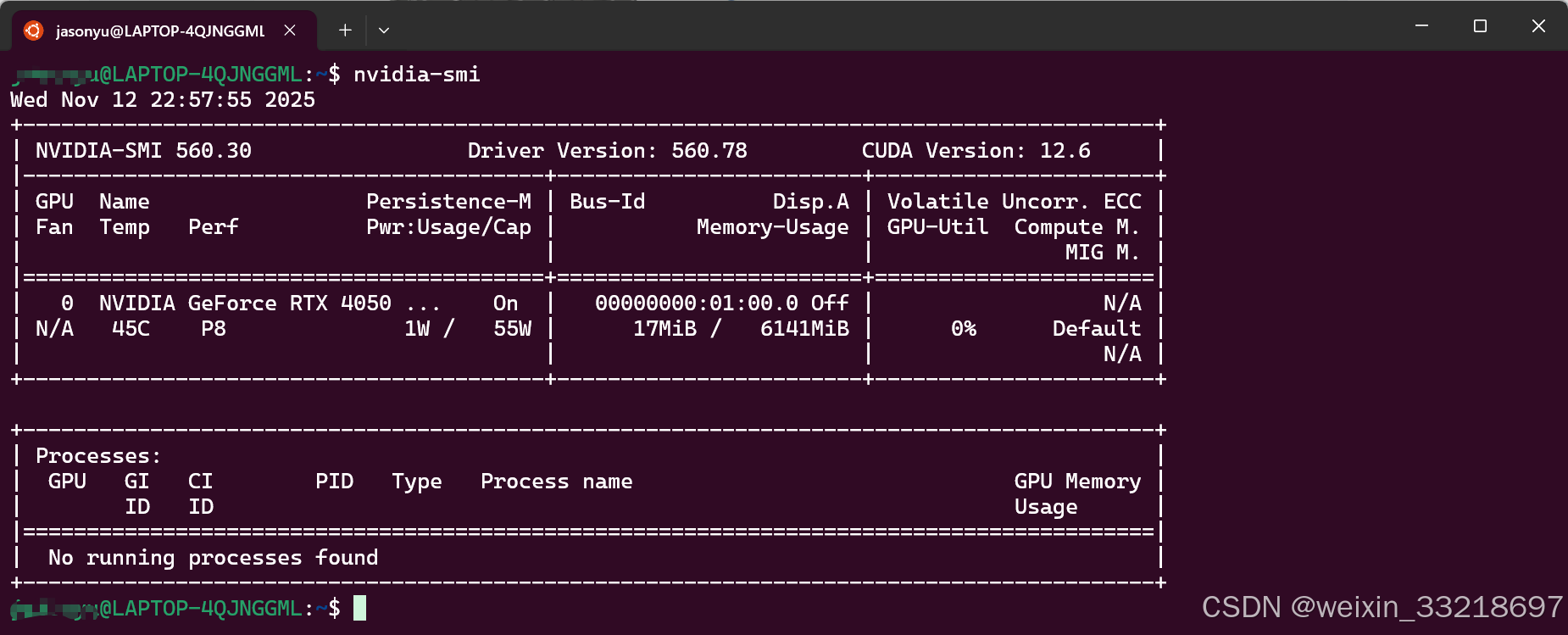
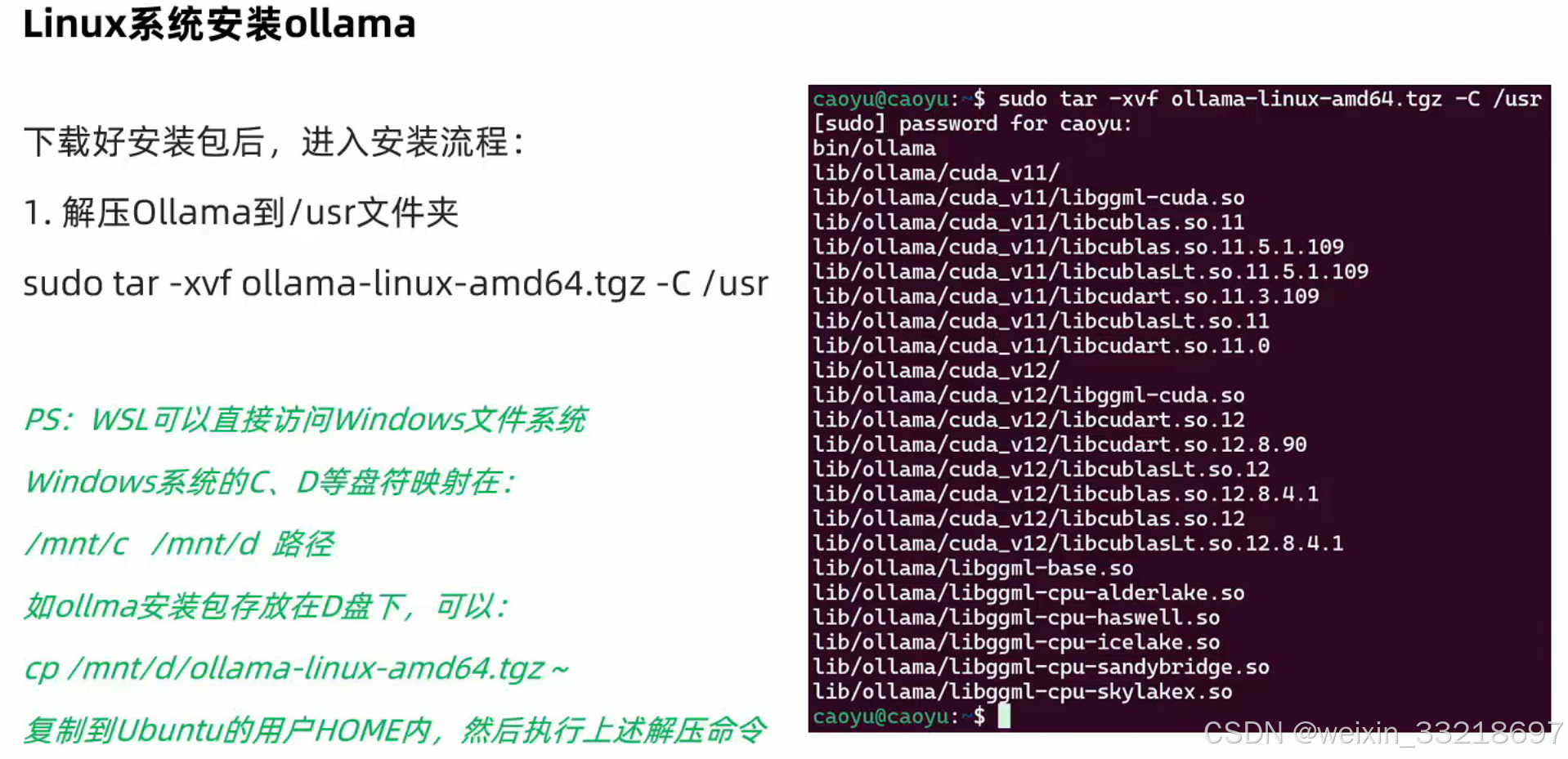

以下是我自己操作的截图记录
这里和老师视频一样复制蓝字的网址打开,建议科学上网,否则转半天都不开始下载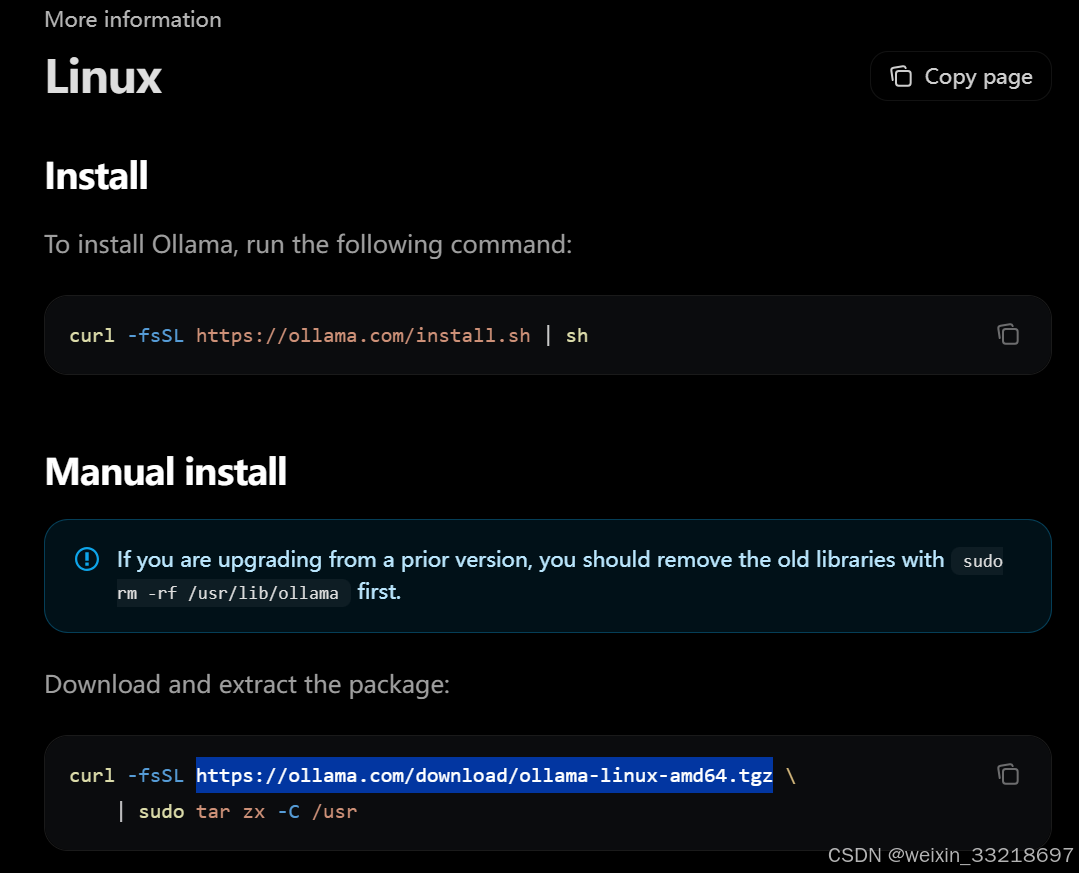
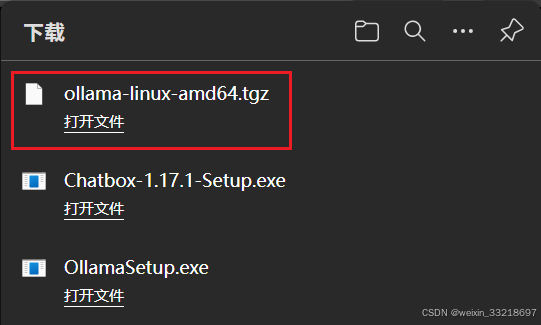
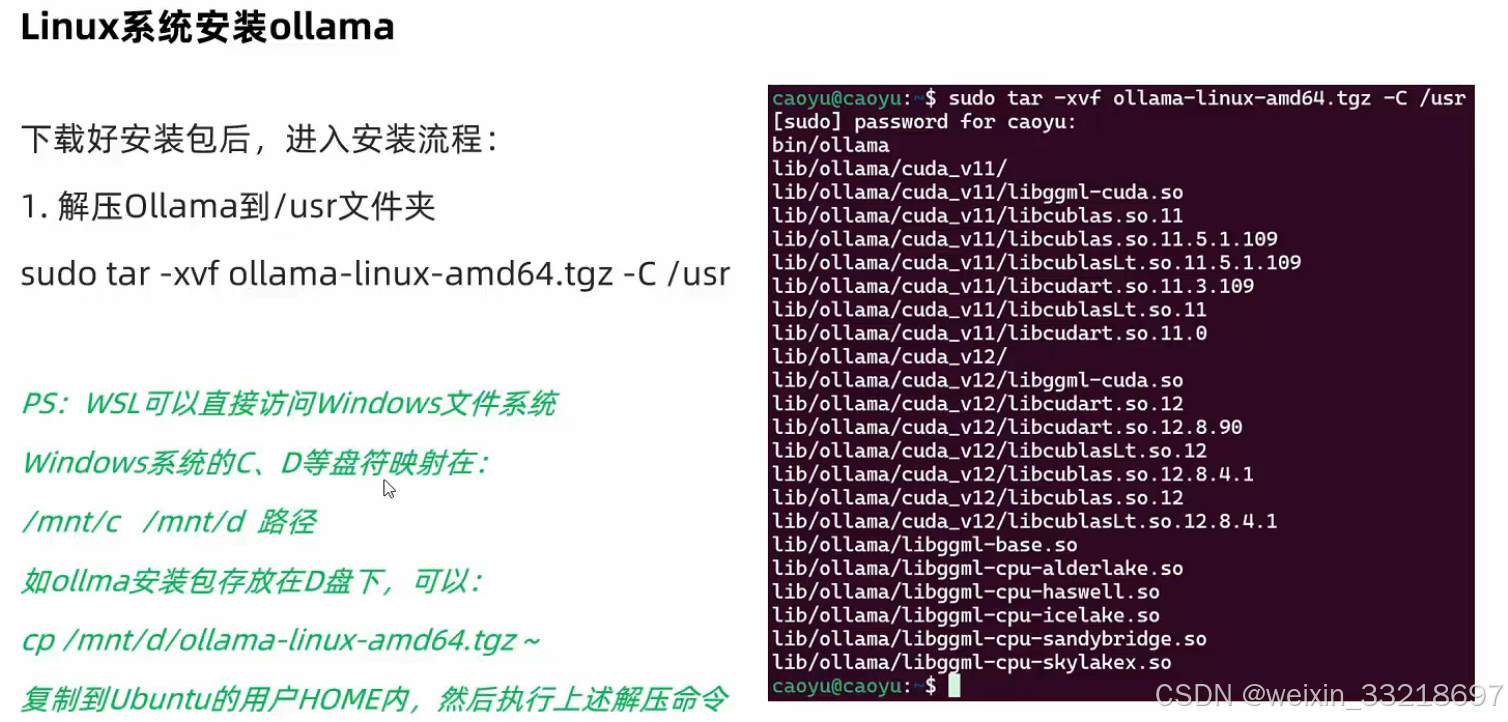
然后在终端进行如下命令操作(名字实在太多就不藏了),然后这里一开始我按照老师的命令输也改了自己的用户名就是不行,问了一下ai然后发现先cd /mnt/c就可以了,直接c/Users/…就是不行(不知道为什么老师可以)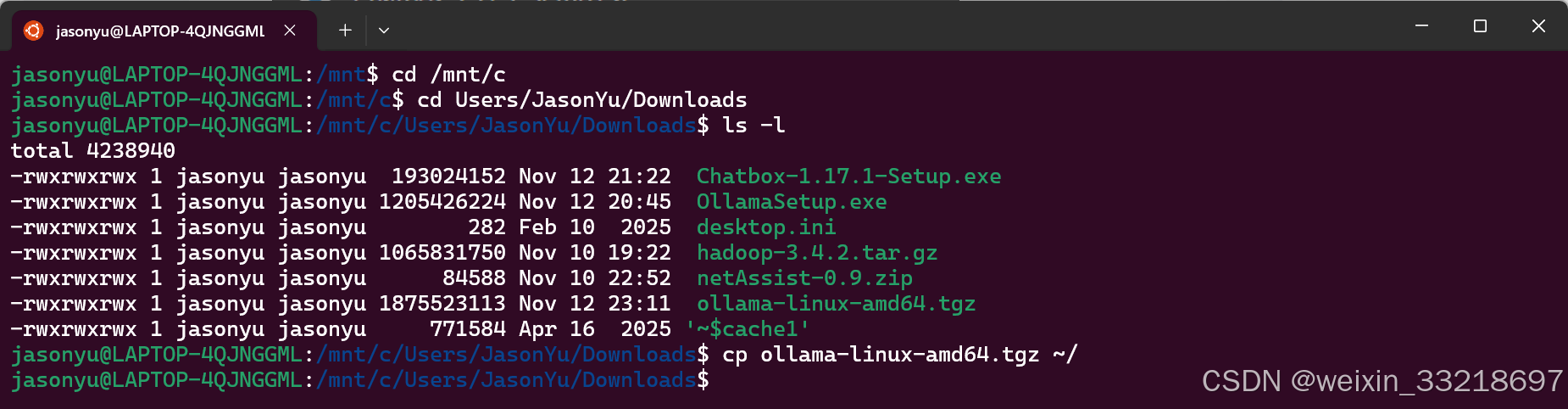
然后我这里是出现了一点个人的问题(因为我之前乱搞然后账号密码啥的都没记录下来,所以跟着ai重新建的这个用户和密码),大家如果有一样的问题可以参考,如果是一步步跟着视频学应该不会遇到这个问题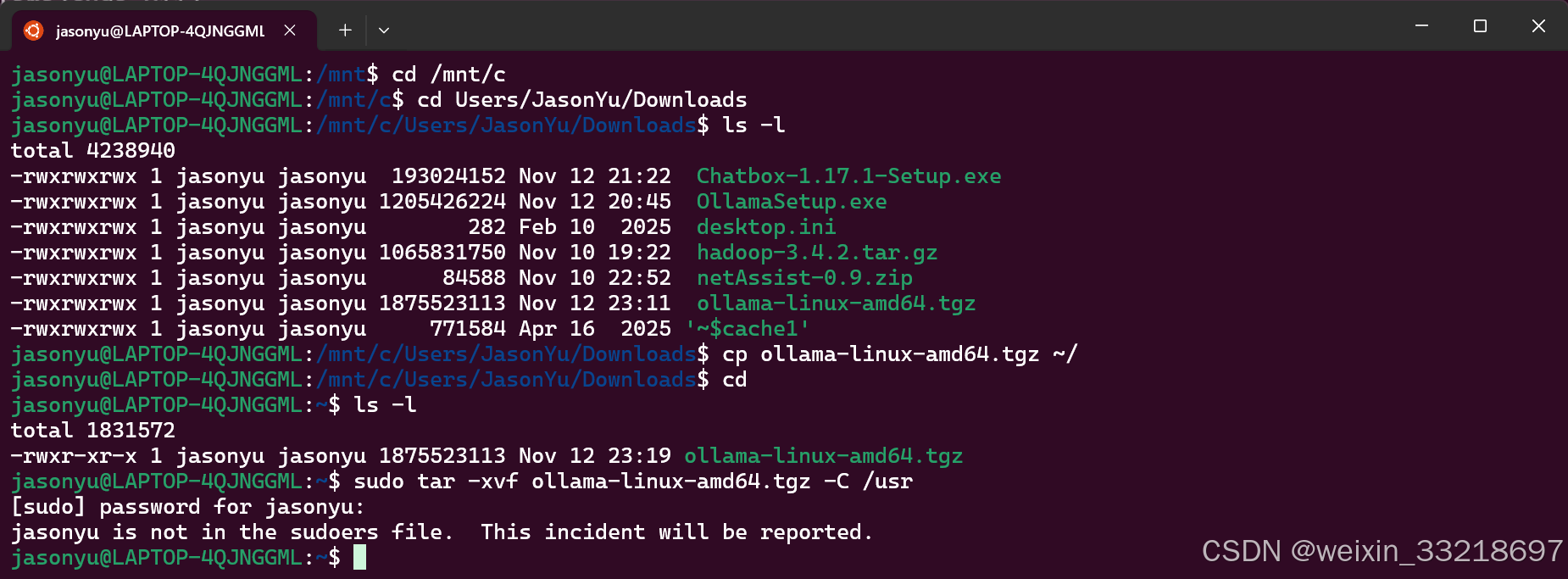

跟着ai的步骤操作一下之后就成功了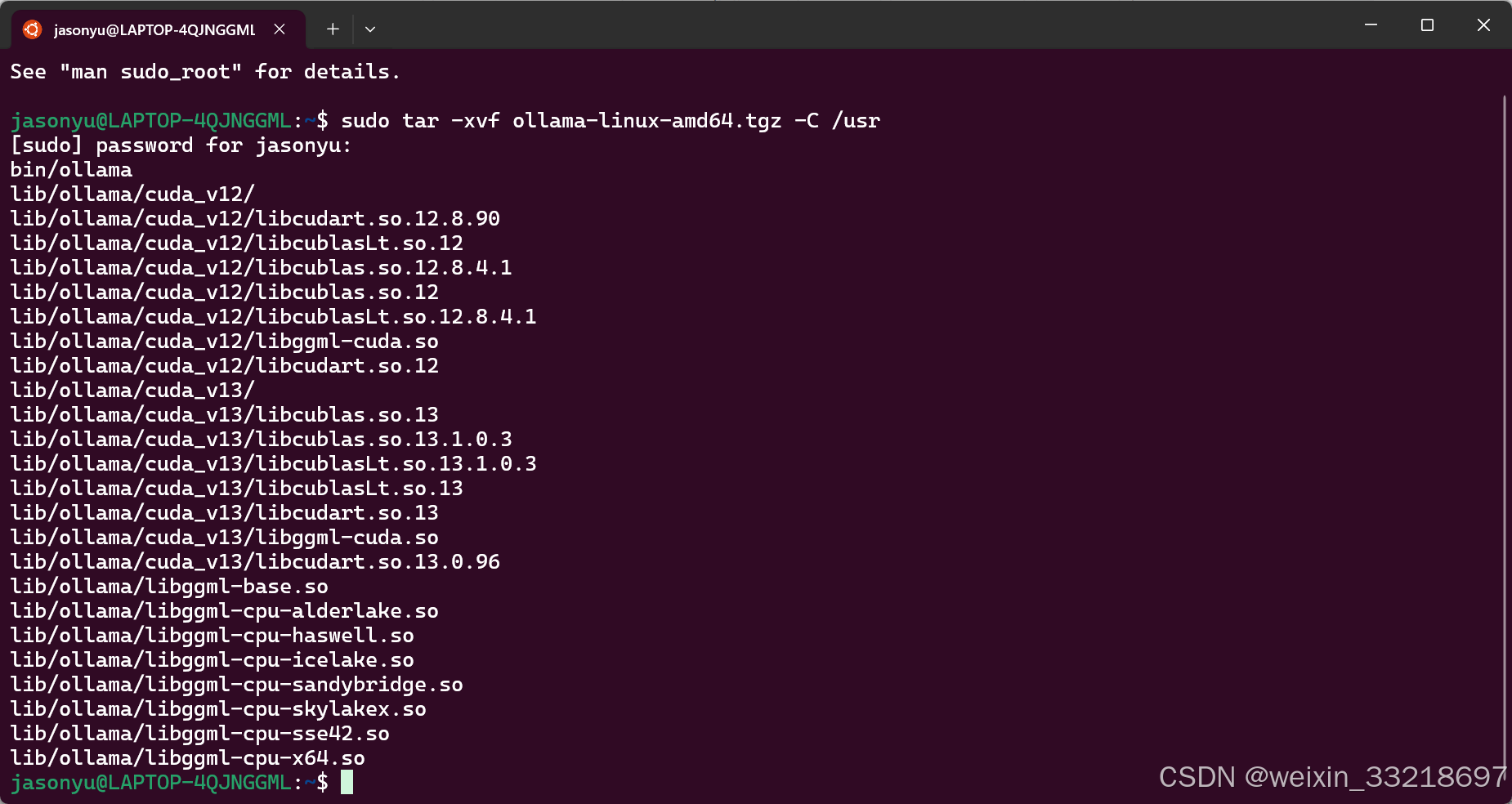
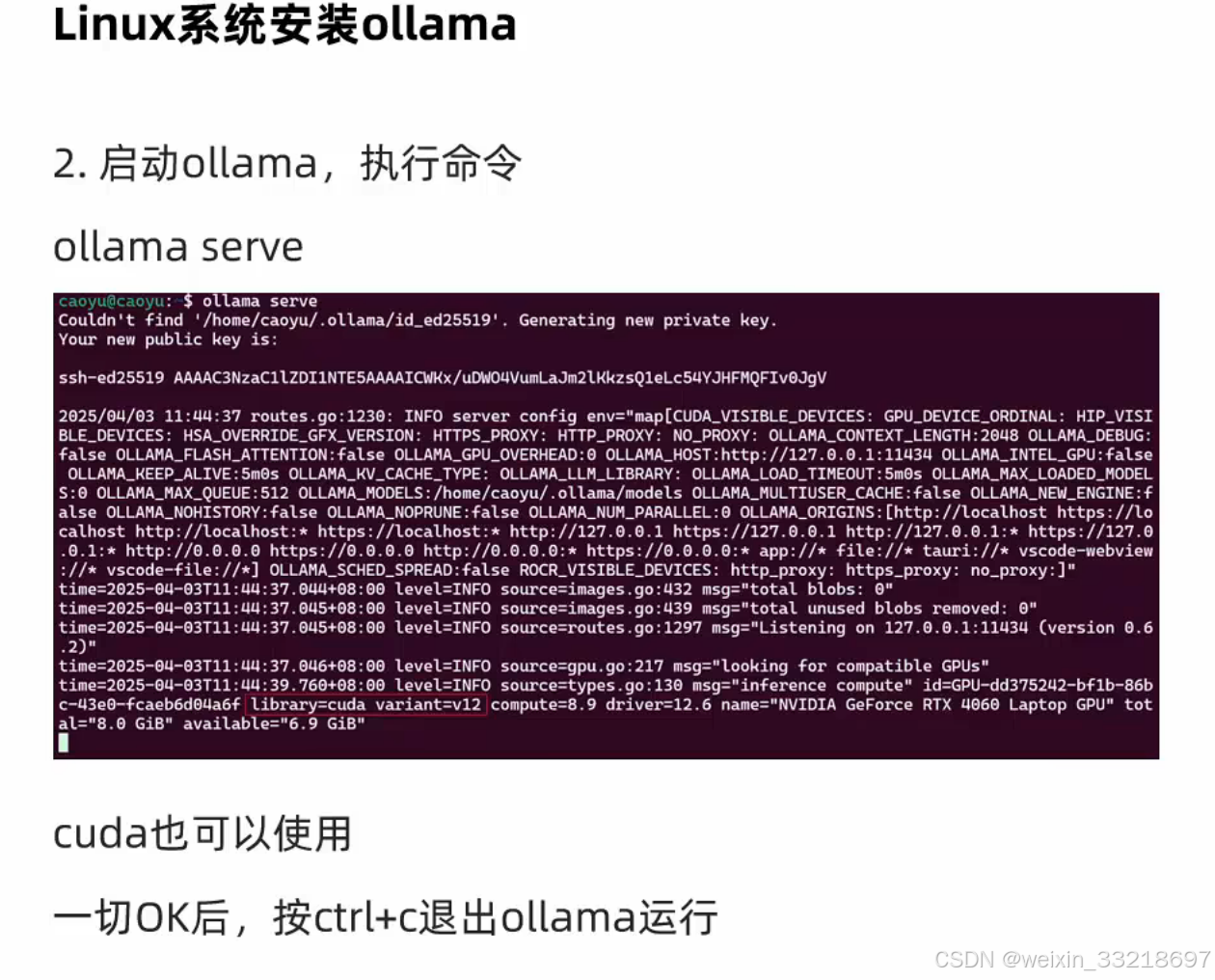
这个Warning是因为我们还没有启动ollama,是正常的不用管
然后启动我发现出现了个public key,后面询问ai知道这个是首次运行会出现,然后这个key也不需要记录。然后老师说这个是前台运行,通过Ctrl + C或者是叉掉窗口都会停止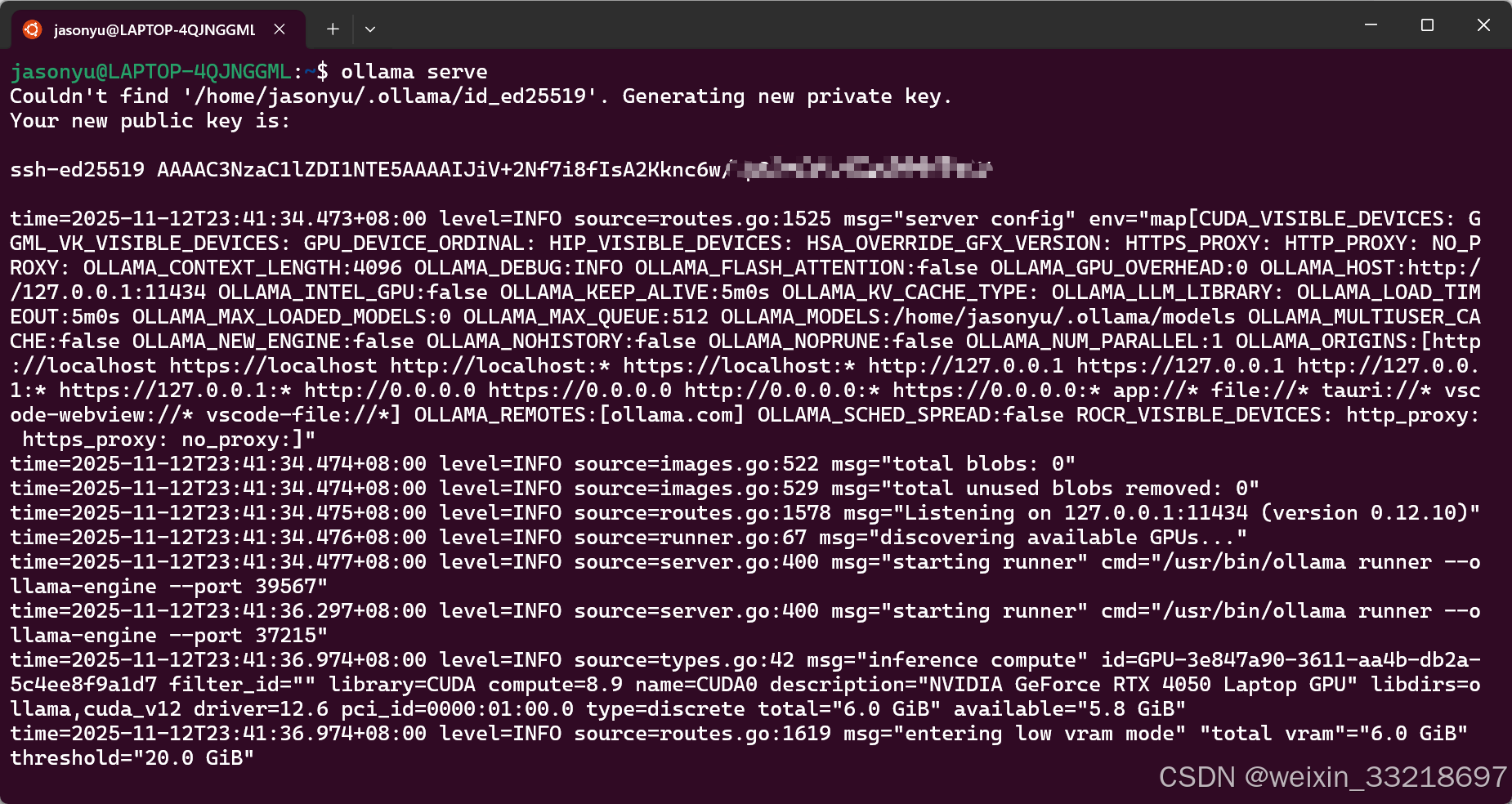


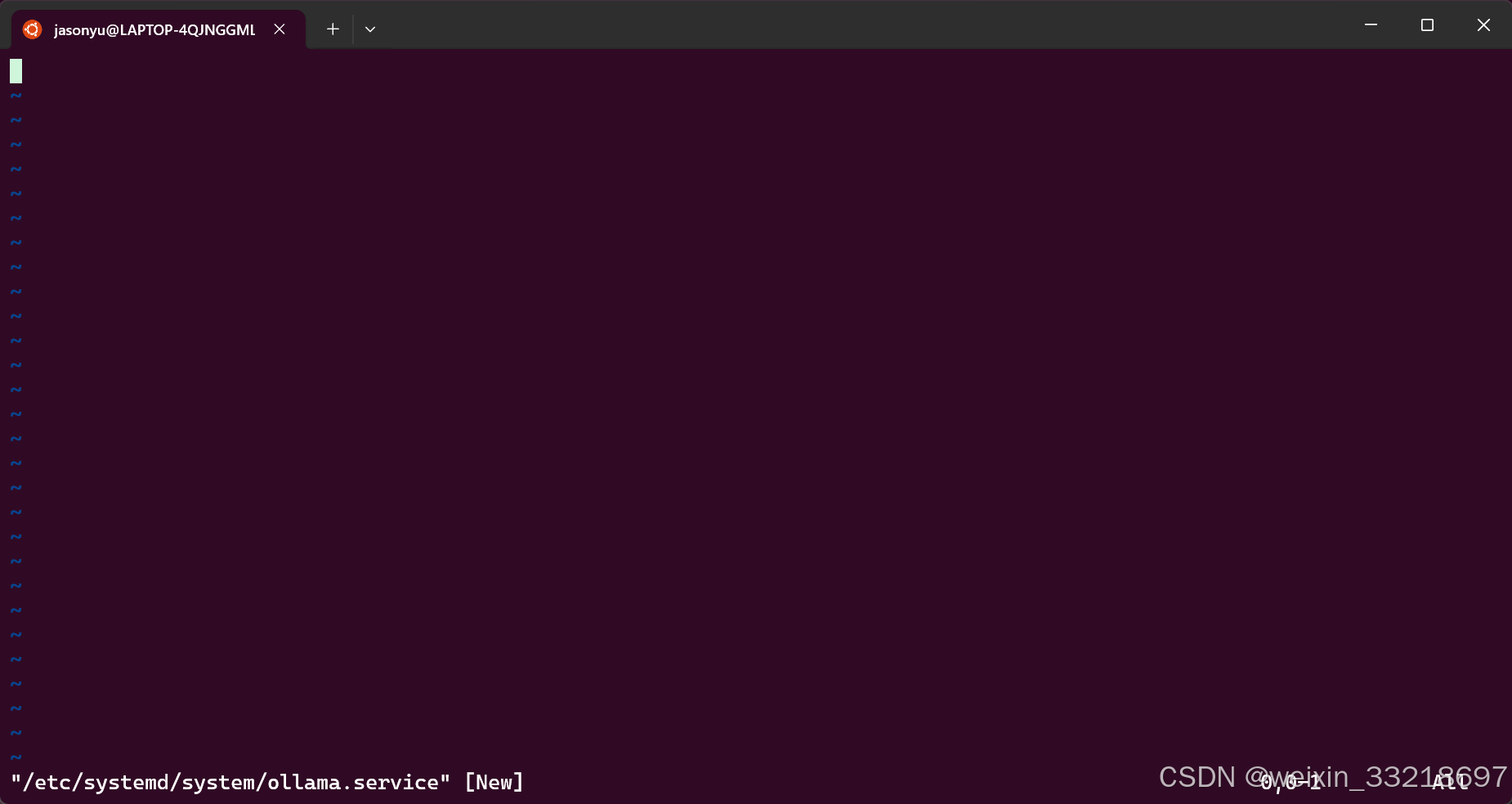
按 i 进入INSERT模式
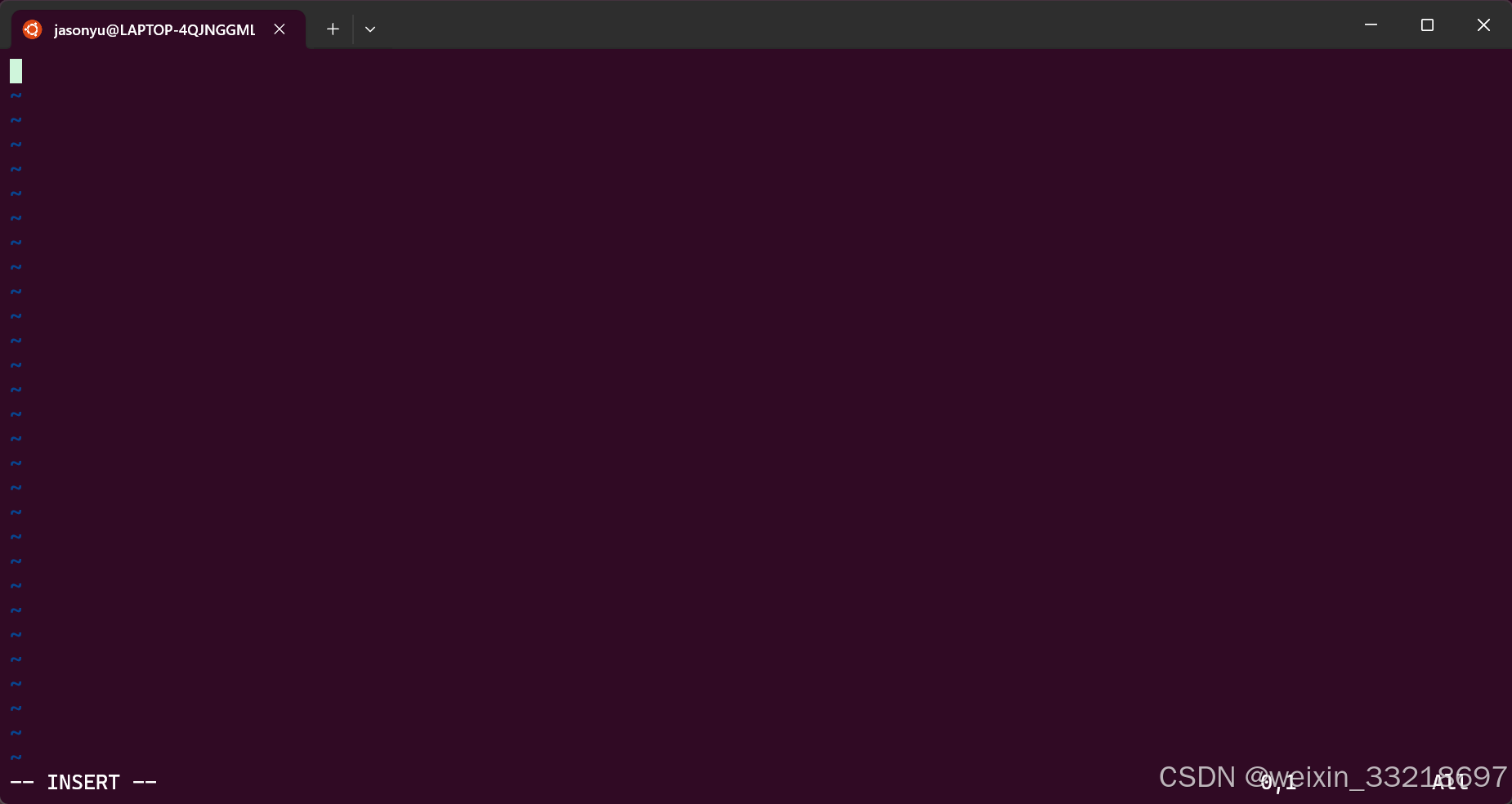
将指定的内容复制进来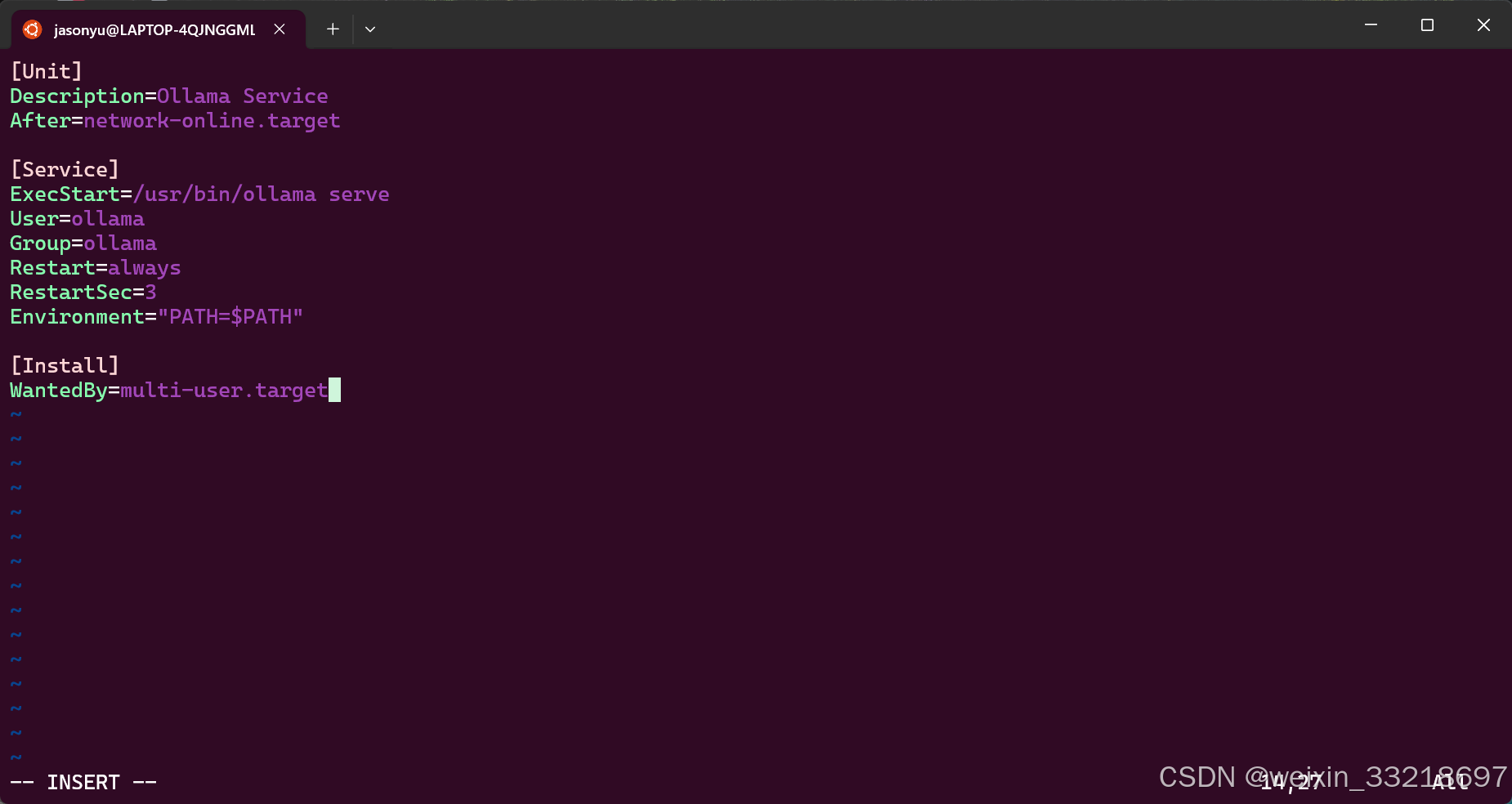
先按ESC在输入 :wq 再回车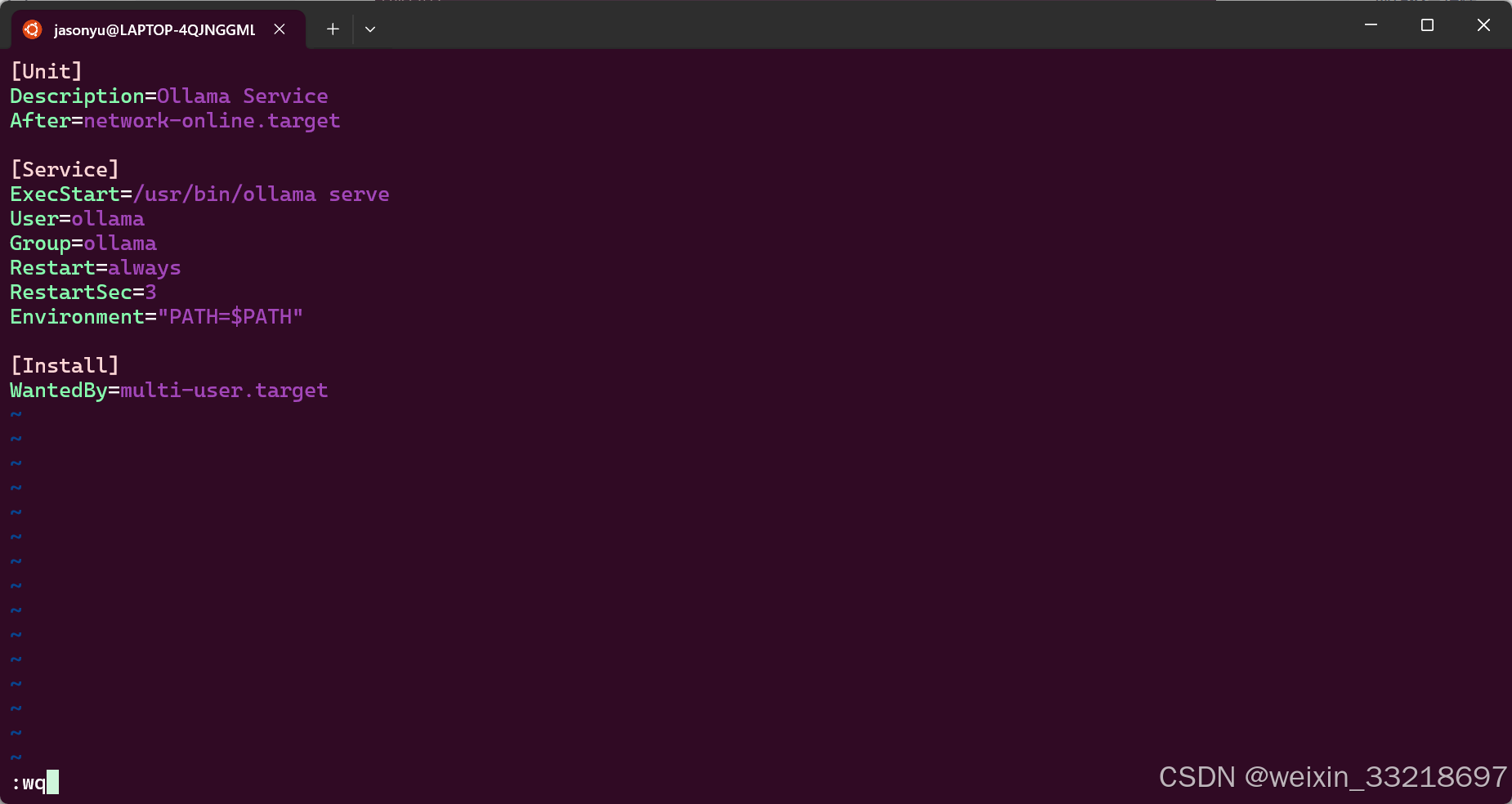
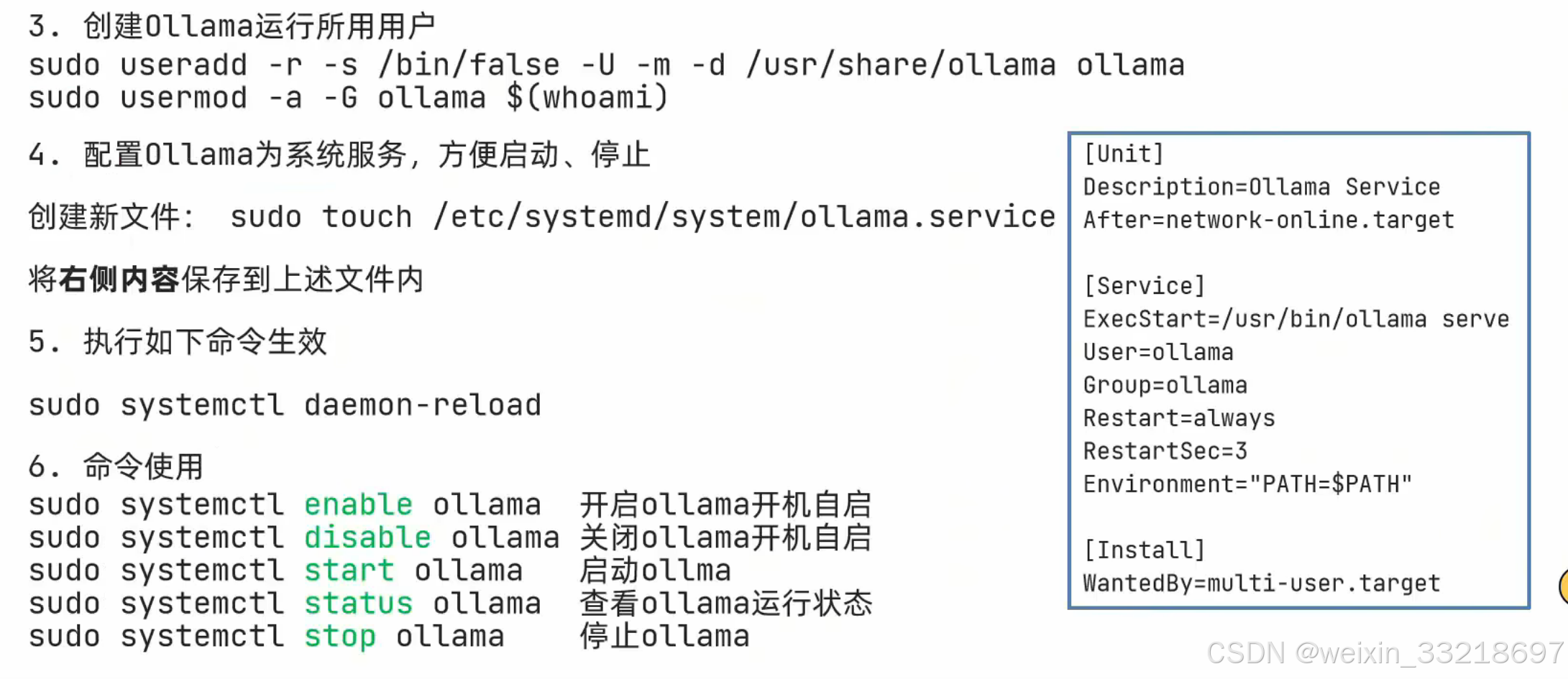
然后我发现我遇到了这个systemed的问题,和视频中不一样,然后我还是拷打了ai解决了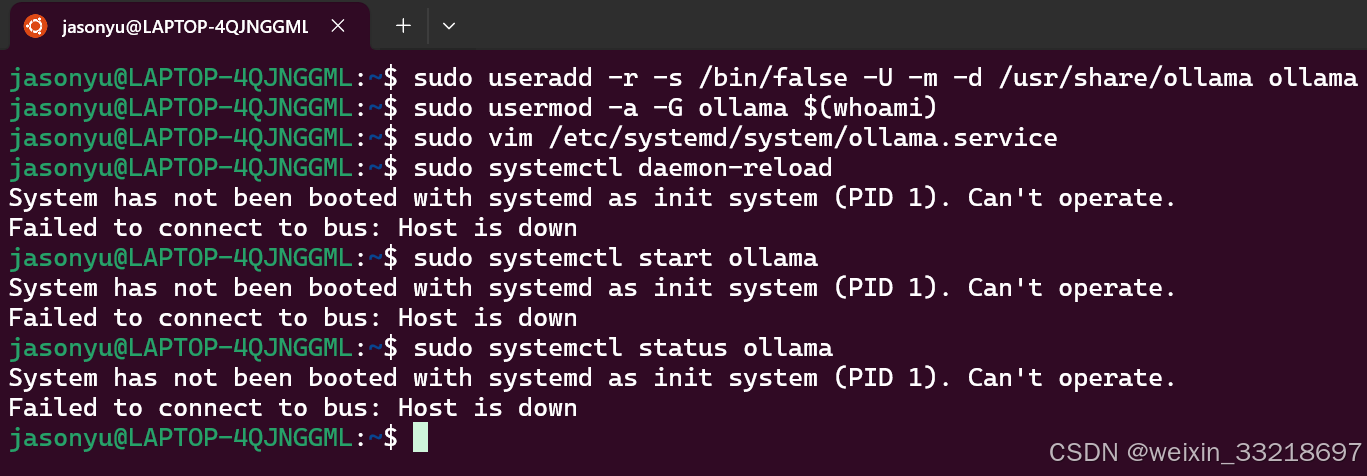
下面是ai给出的解决办法,我跟着一步步做是成功了的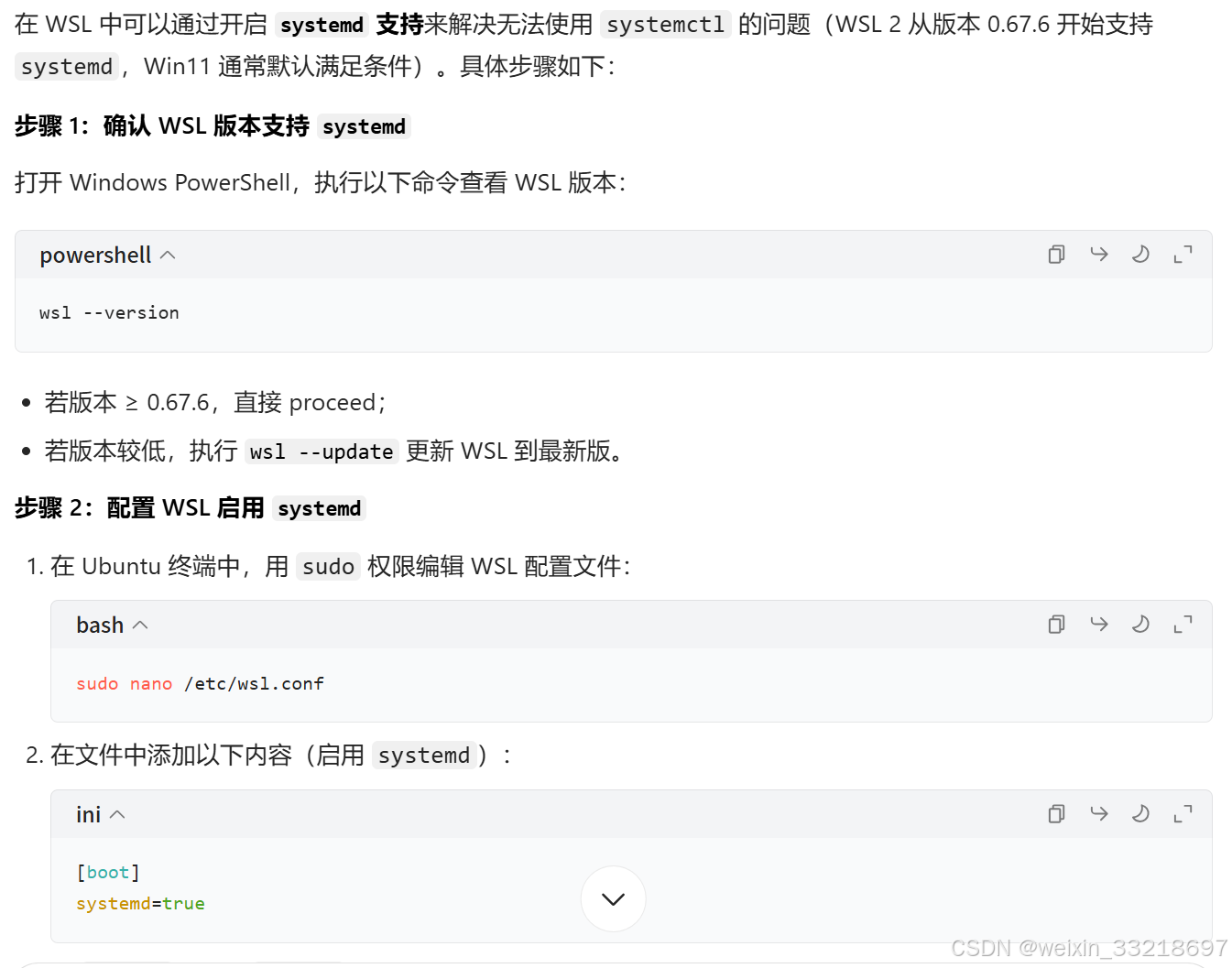
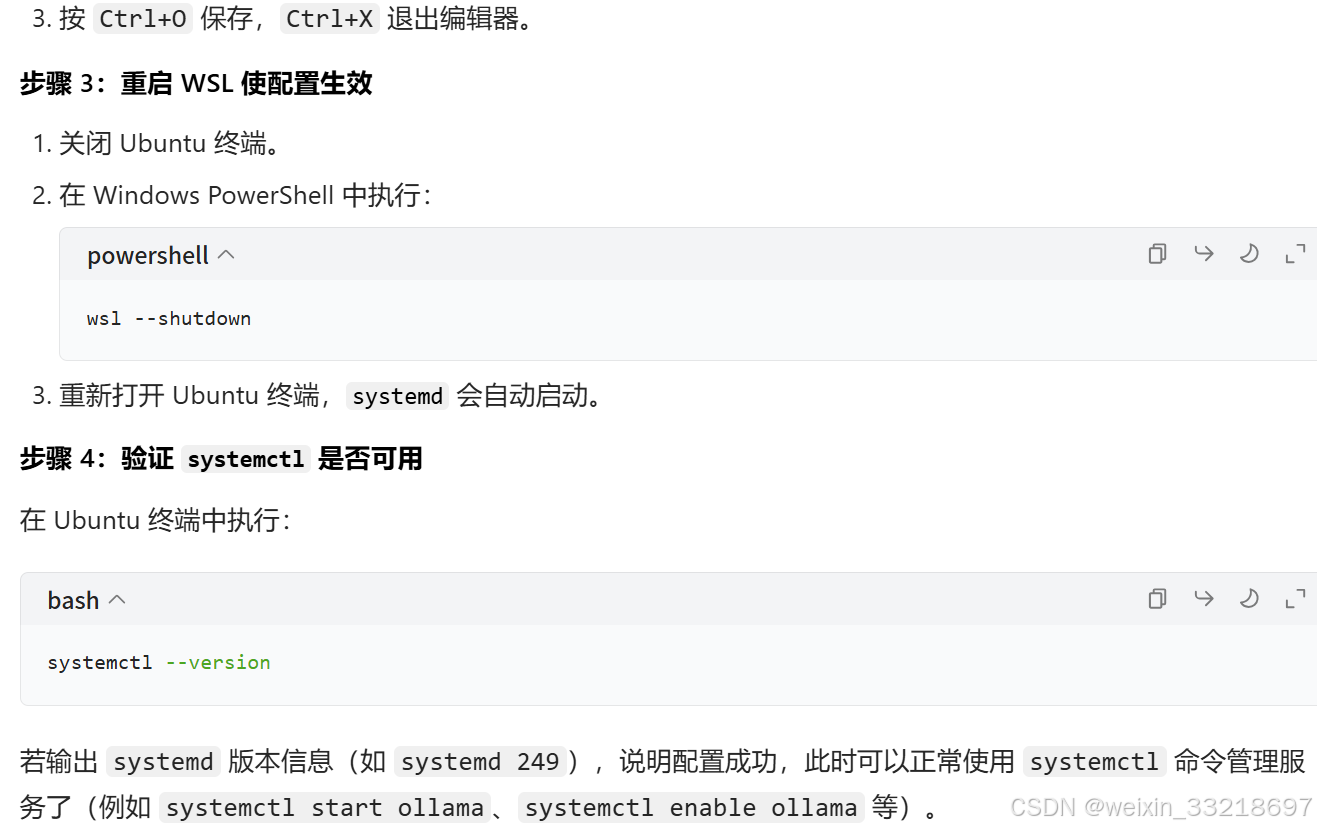
下面是我自己解决过程的一些小记录,正常跟着ai的步骤一步步做应该是没问题的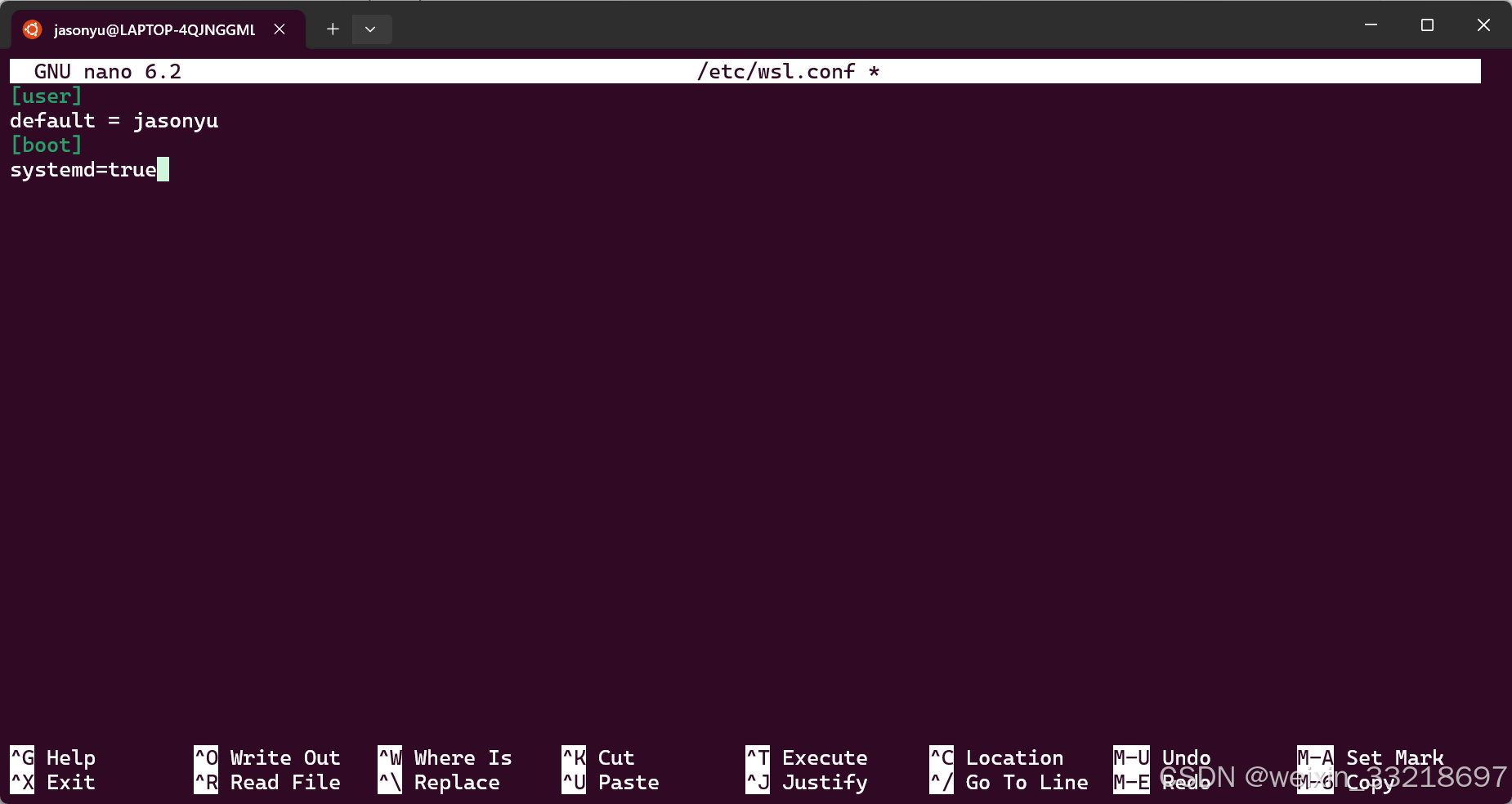

搞完之后就可以重新按照视频输入命令了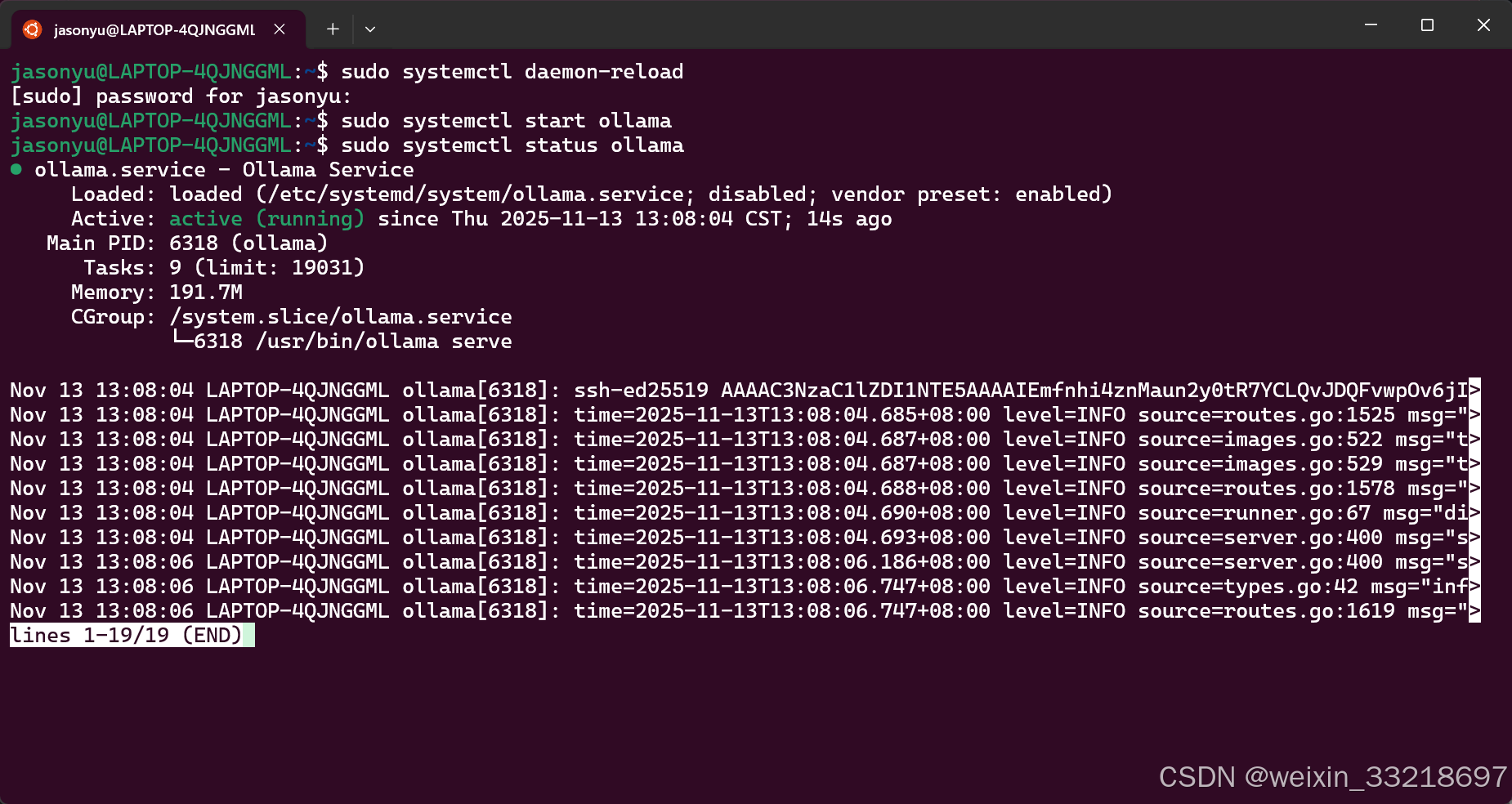
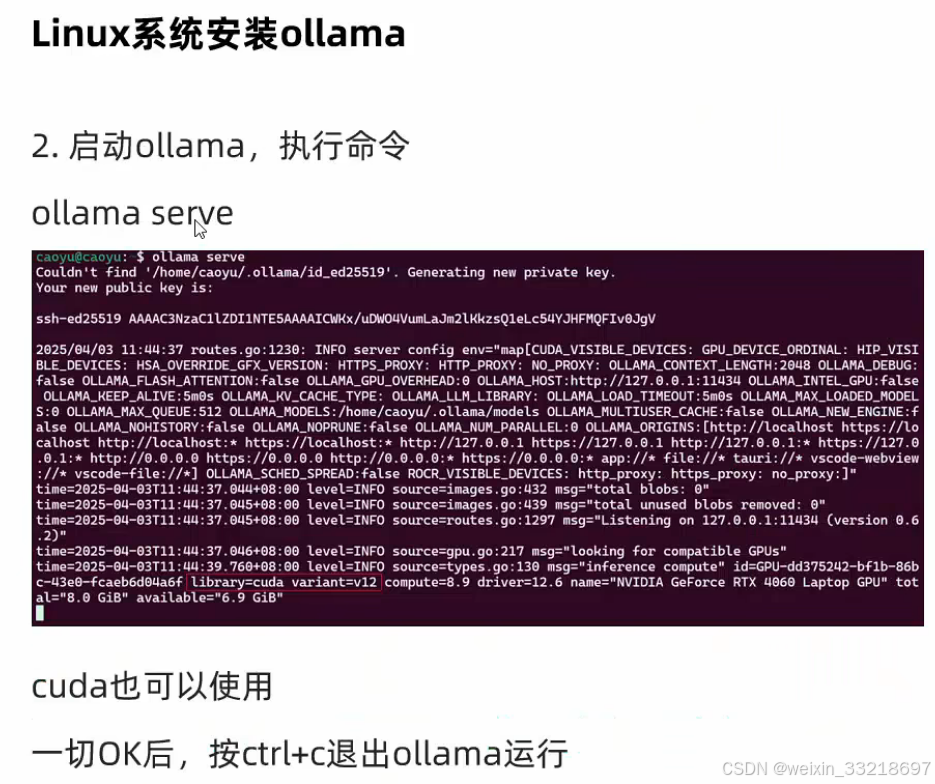


可以通过Ctrl + D退出ollama的运行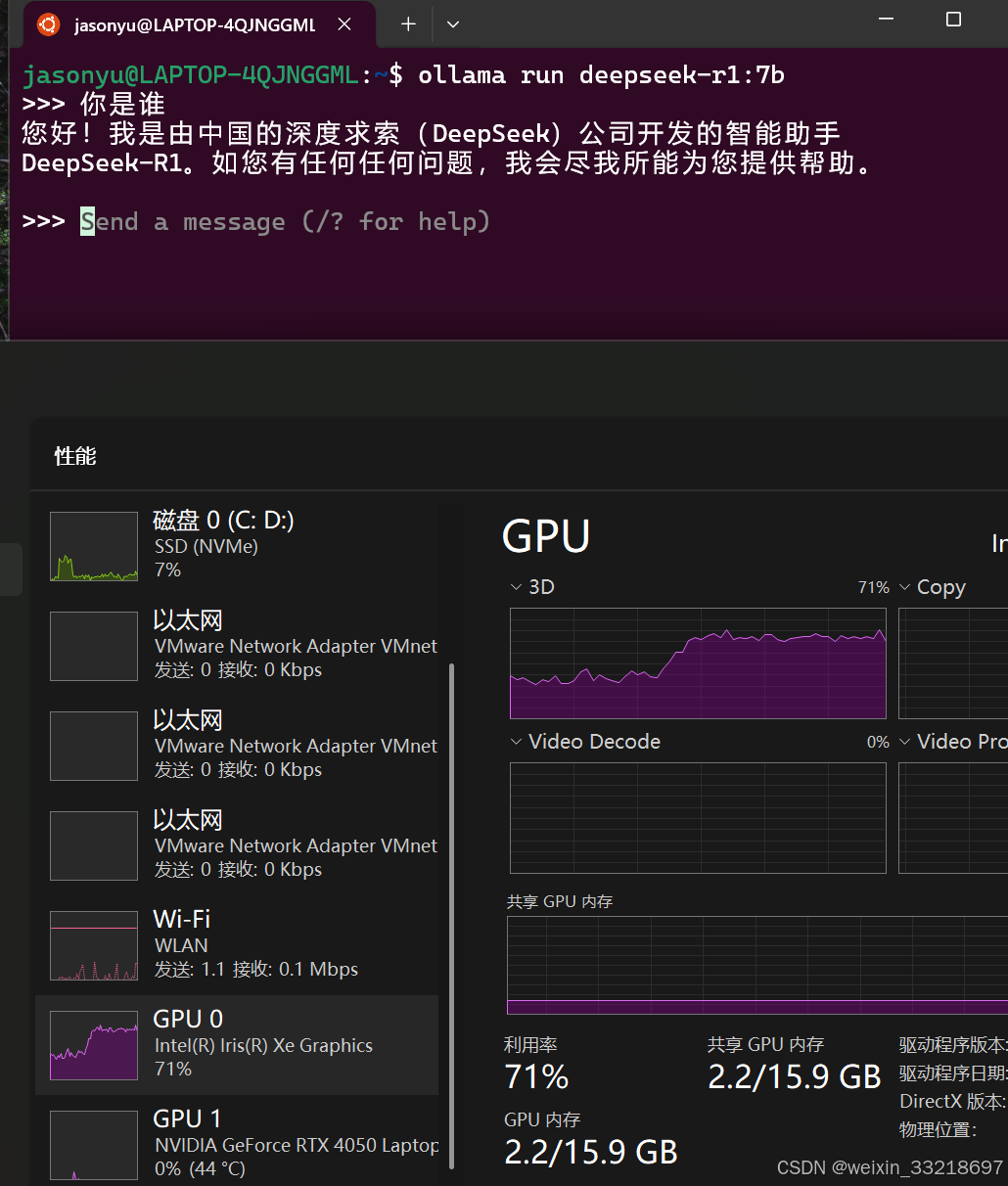
11.Linux部署Python开发环境

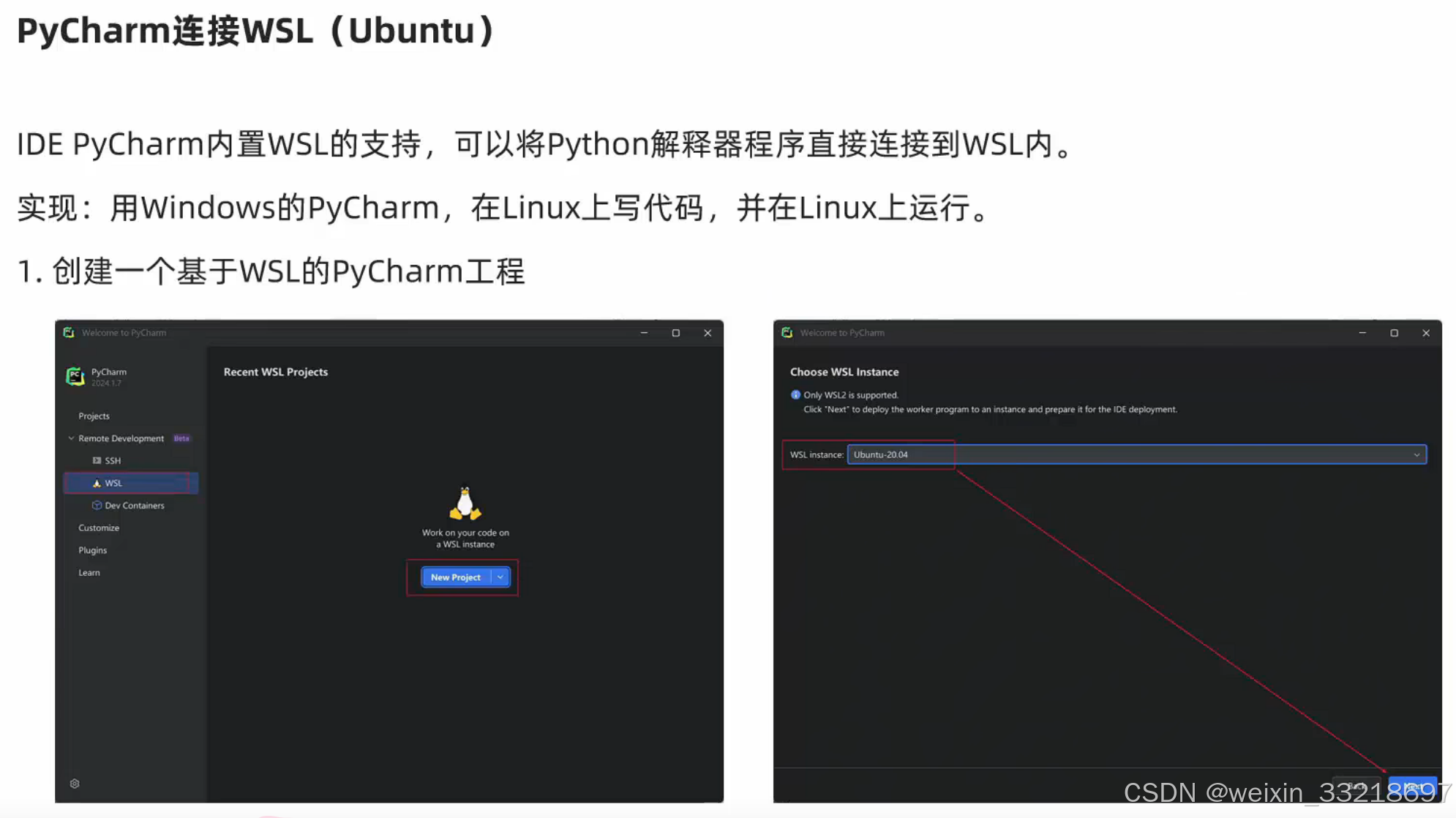
想要退出到如下的欢迎界面,就是在打开项目的界面左上角菜单栏点击文件,然后点击关闭项目即可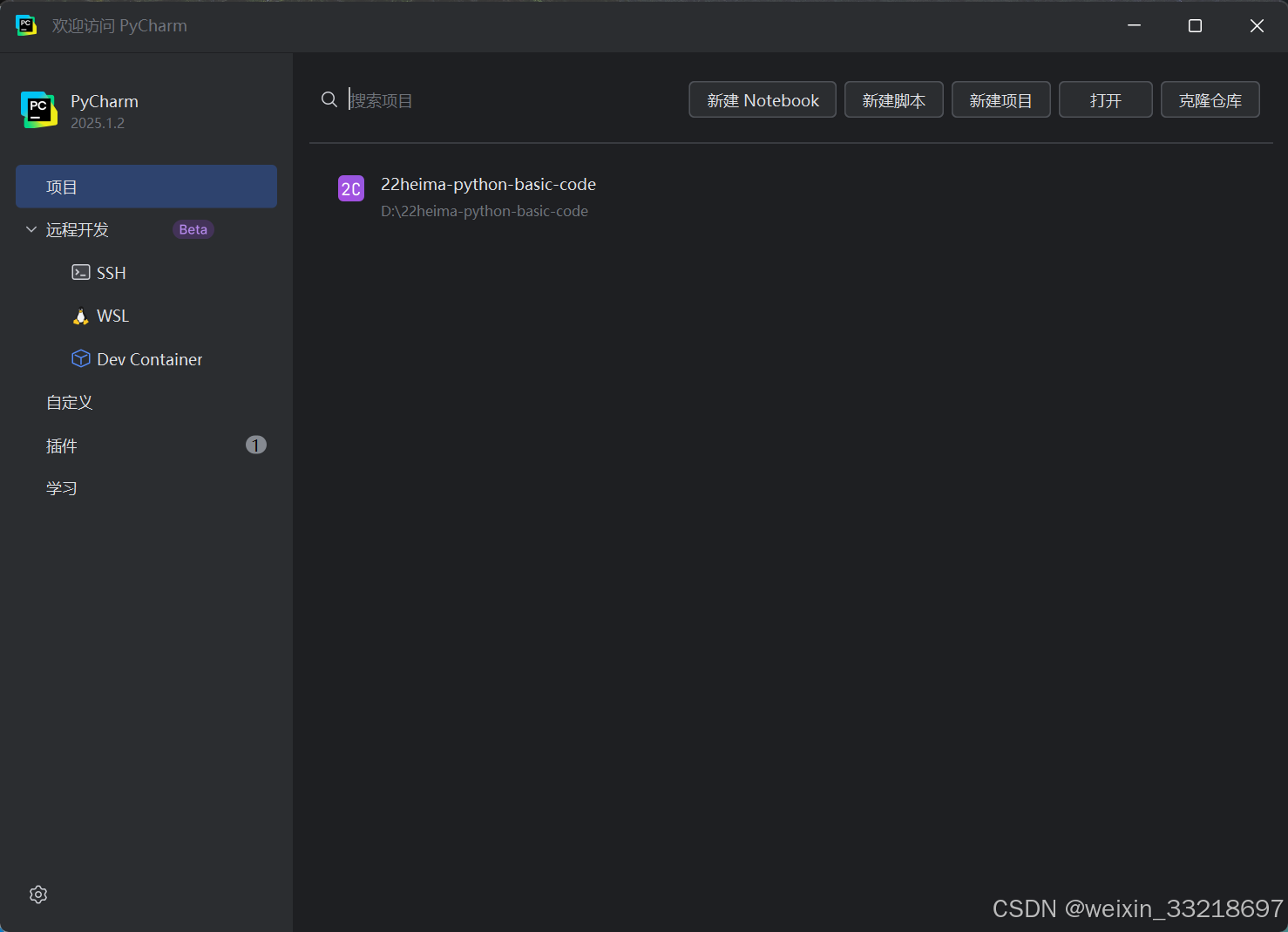
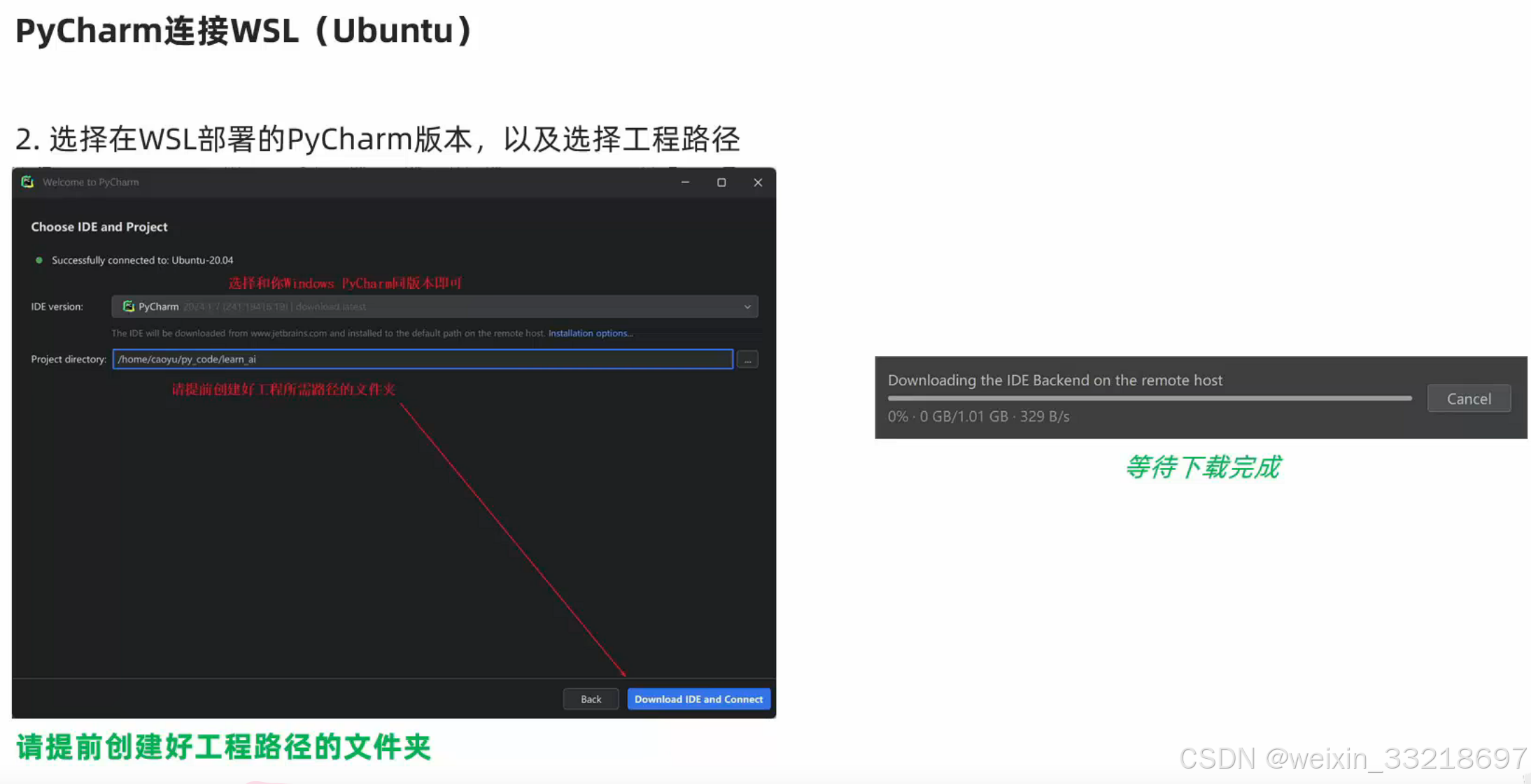
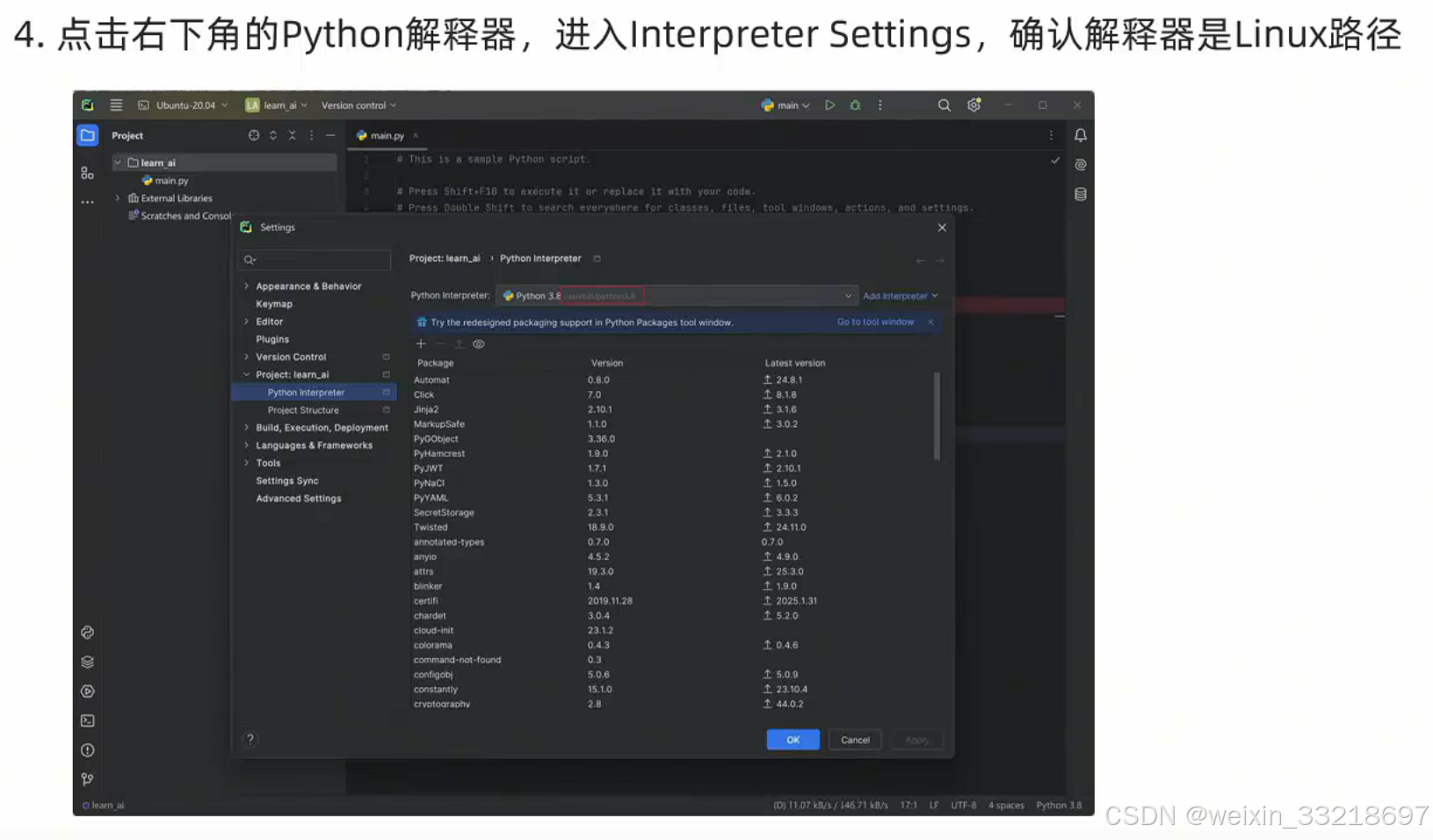
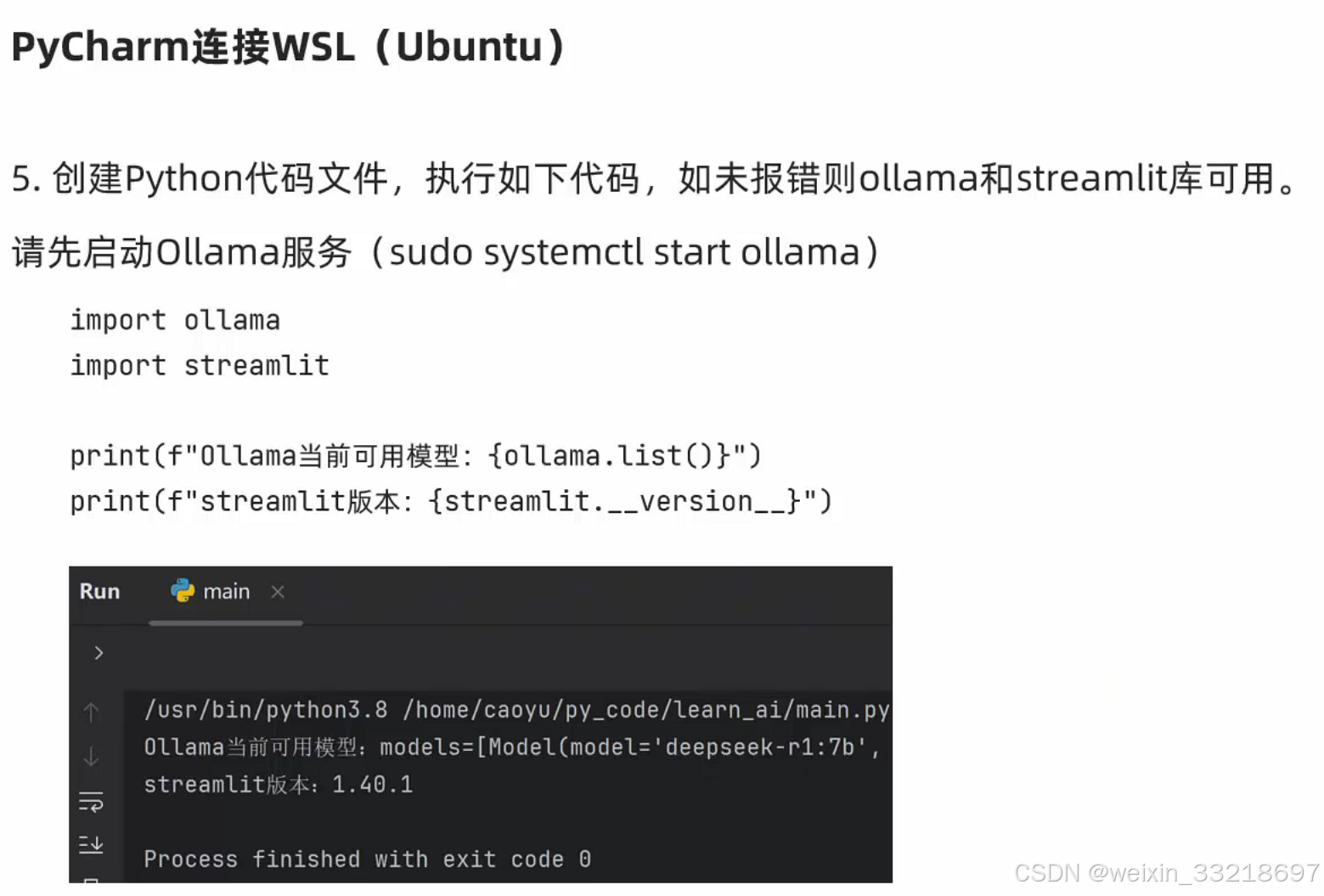
以下是我自己操作的记录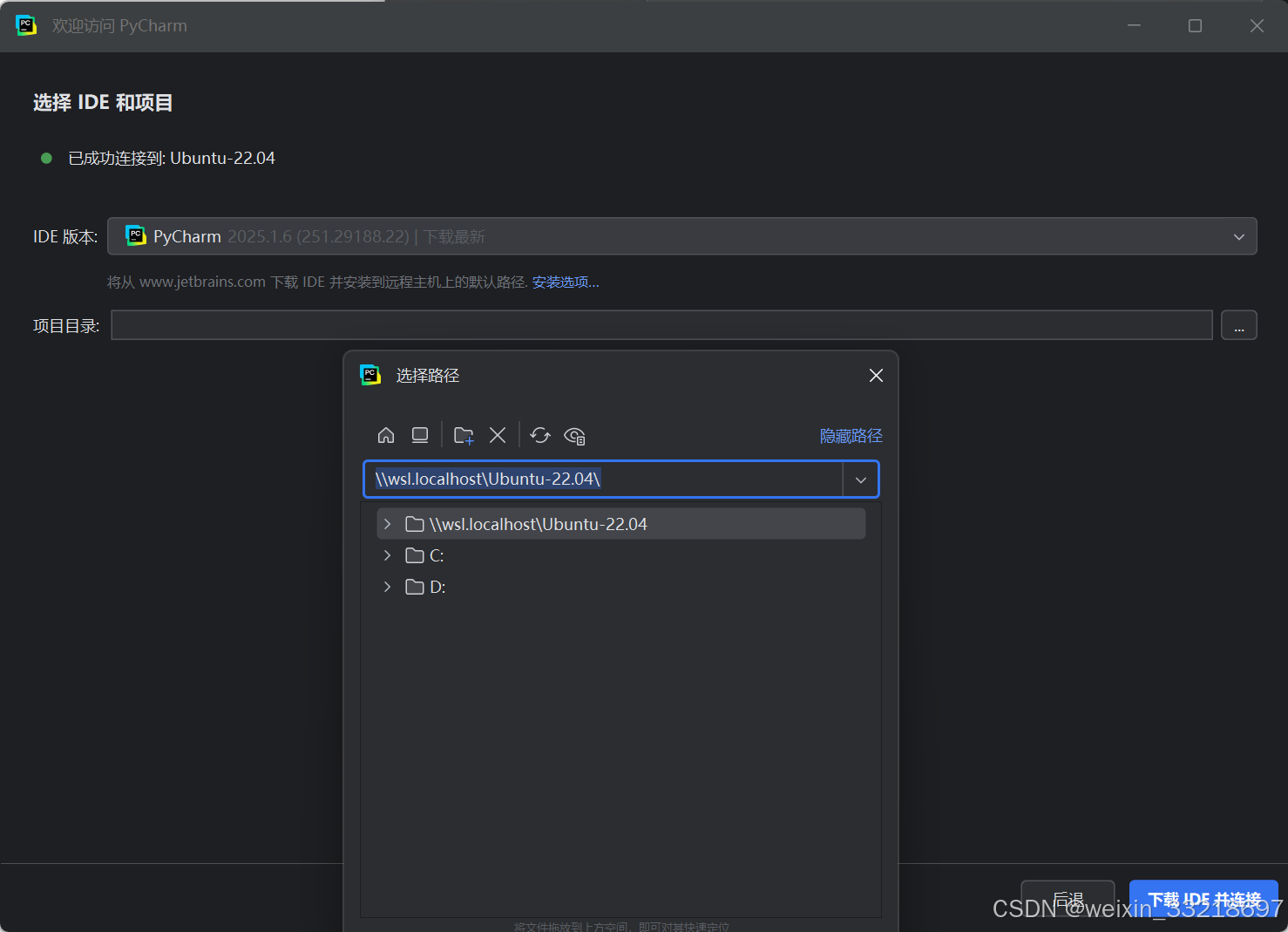
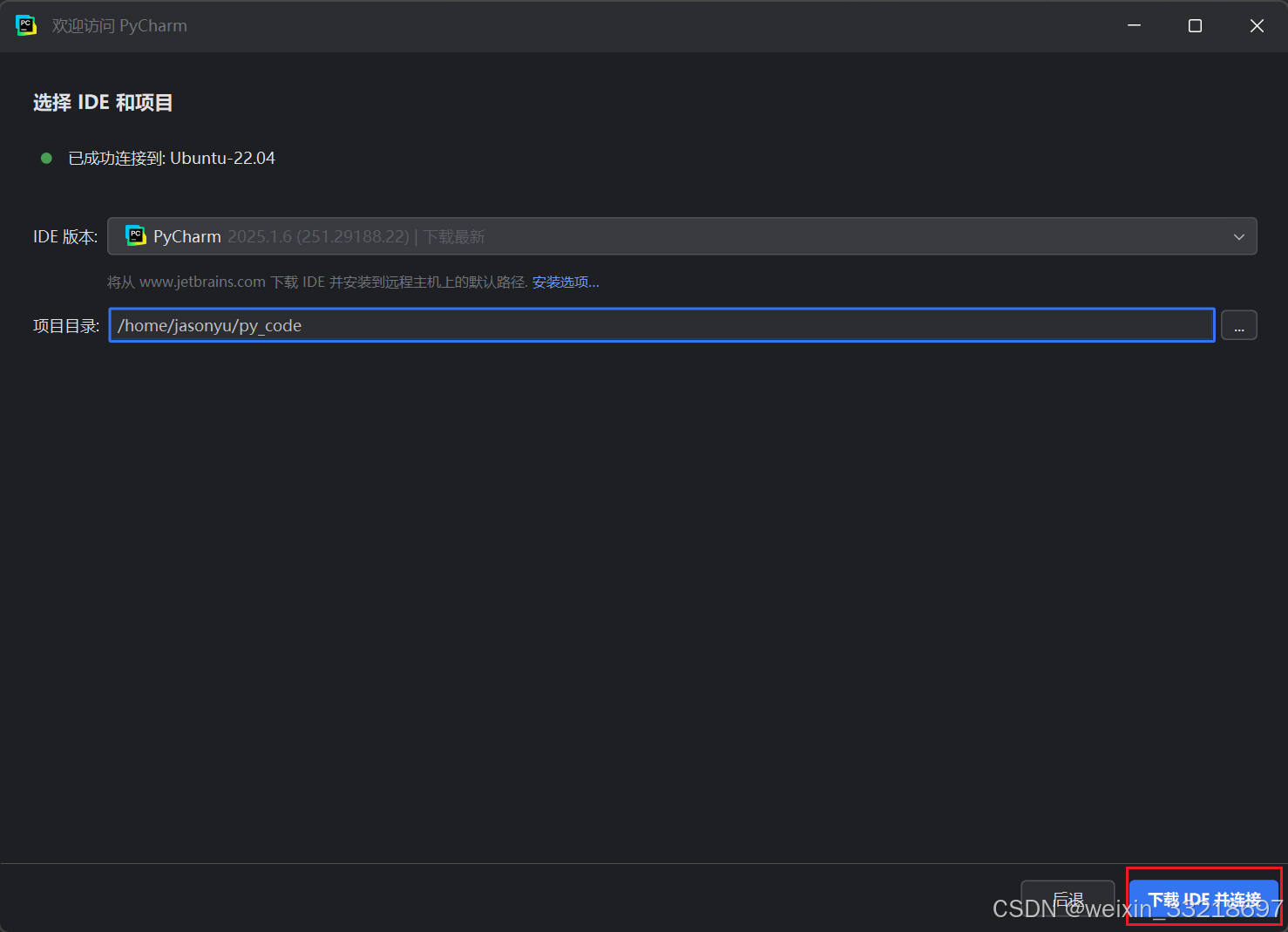
第一次点进来我们是没有py_code这个文件夹的,所以点击用户名右键新建目录再选择路径即可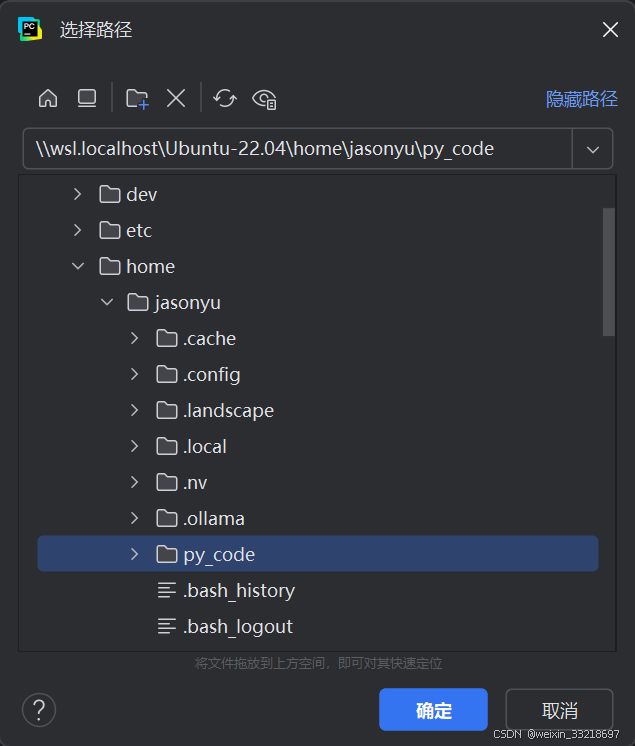

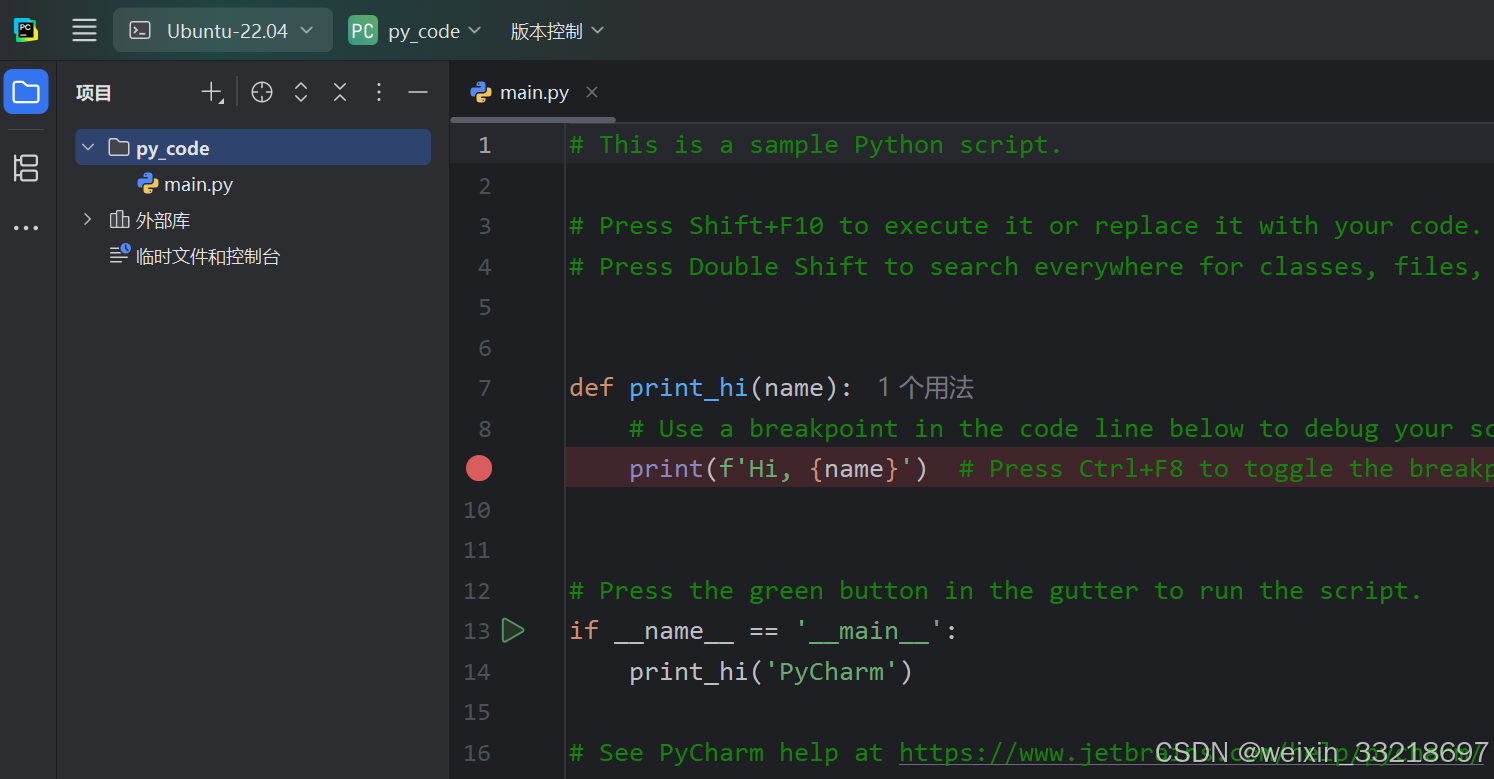
我这个打开就是3.10版本的,比视频的新一点
出现如下报错的原因其实是Ubuntu中的ollama没有运行起来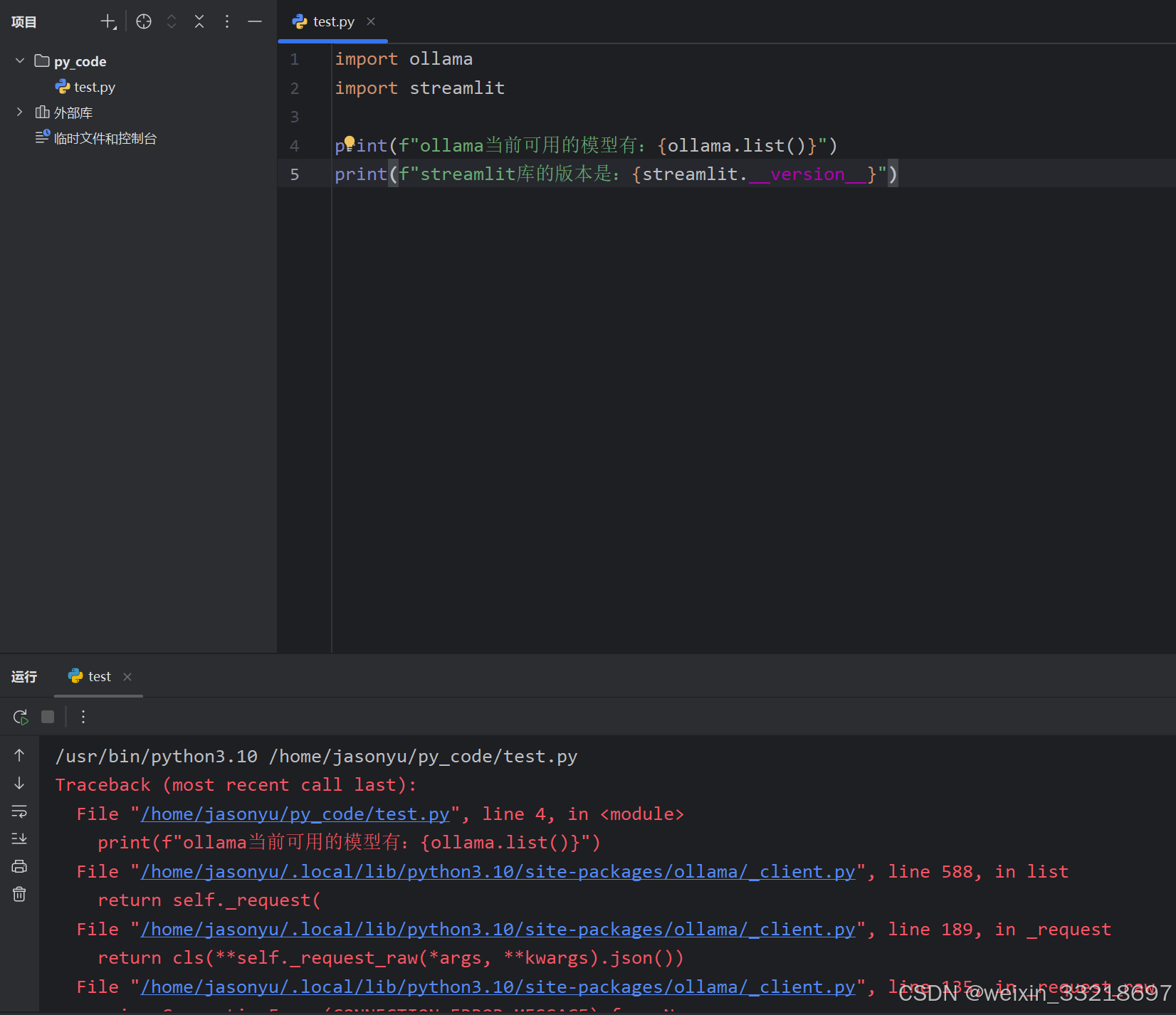
通过sudo systemctl start ollama将ollama在后台运行起来,然后可以通过sudo systemctl status ollama查看ollama的运行状态。最后执行ollama run deepseek-r1:7b运行大模型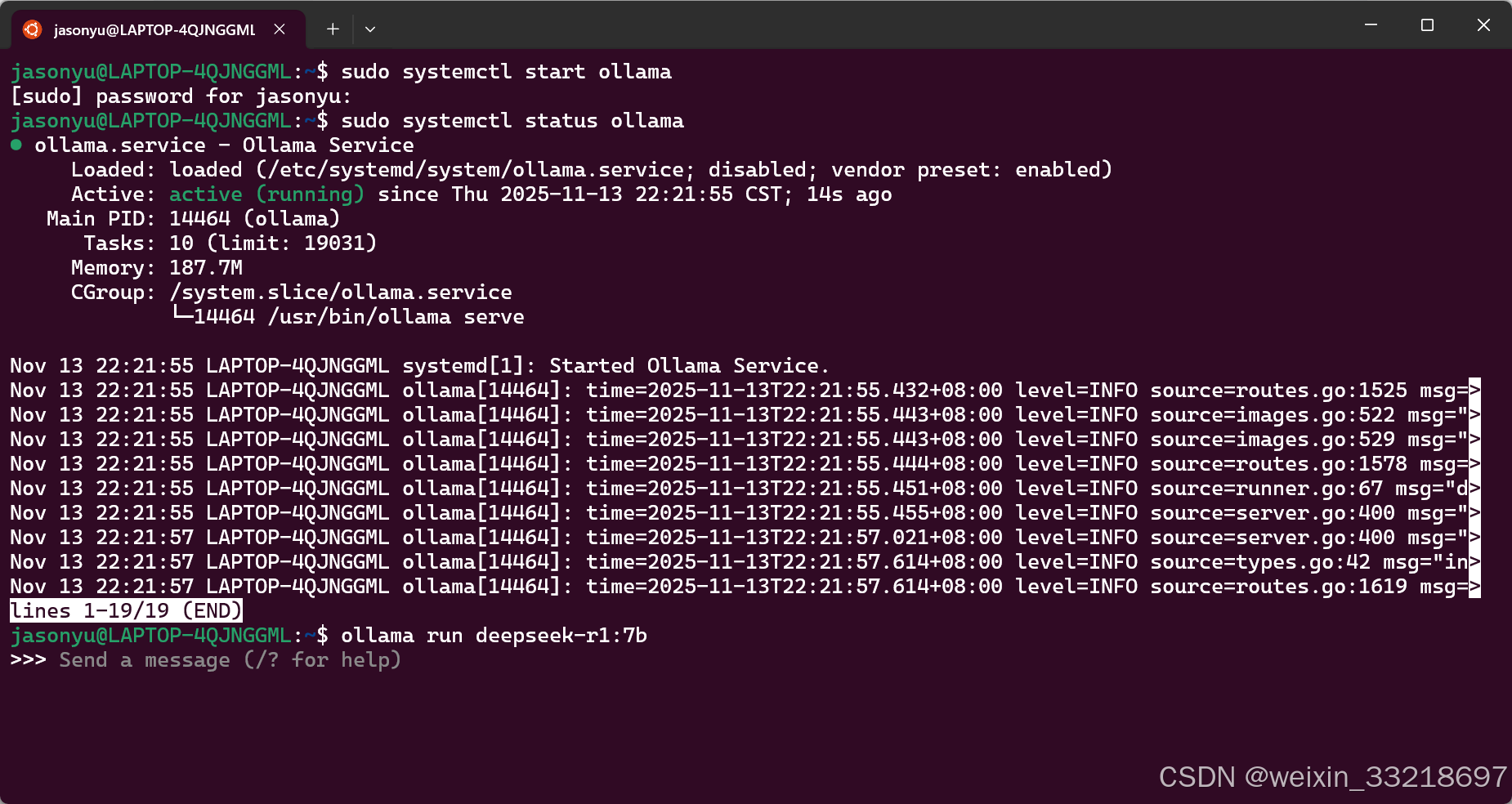
将ollama和大模型运行起来之后就不会再报错了,并且可以查询出ollama当前可用的模型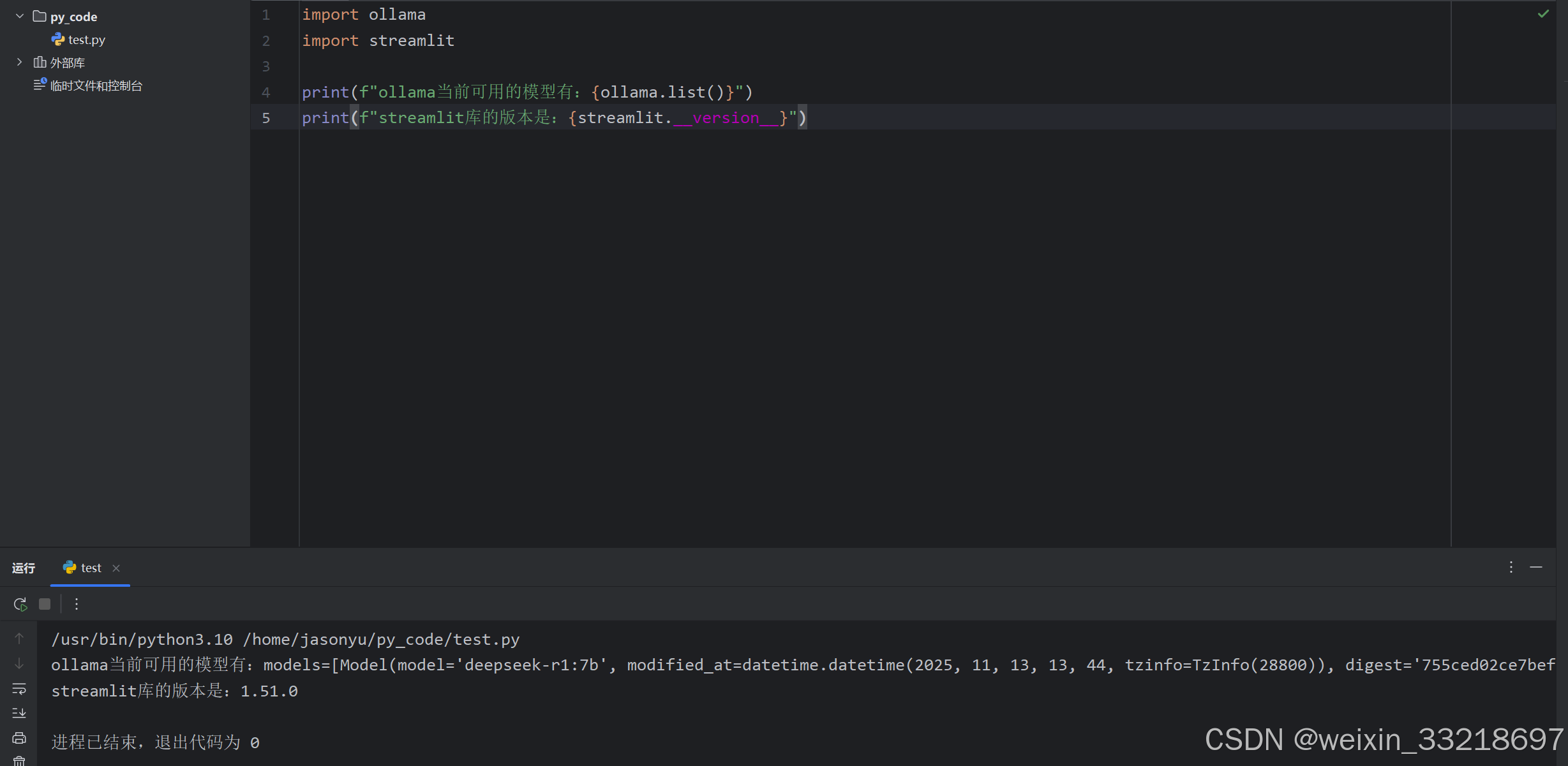
最后提一嘴,可以通过sudo systemctl enable ollama设置开机自启动,对于wsl系统来说,就是打开unbuut终端它就会自启动
12.Ollama基础Python代码


在运行python代码前先在Ubuntu终端输入ollama run deepseek-r1:7b命令并保证处于如下等待输入信息的状态。当然最后输出回答要等待一小会

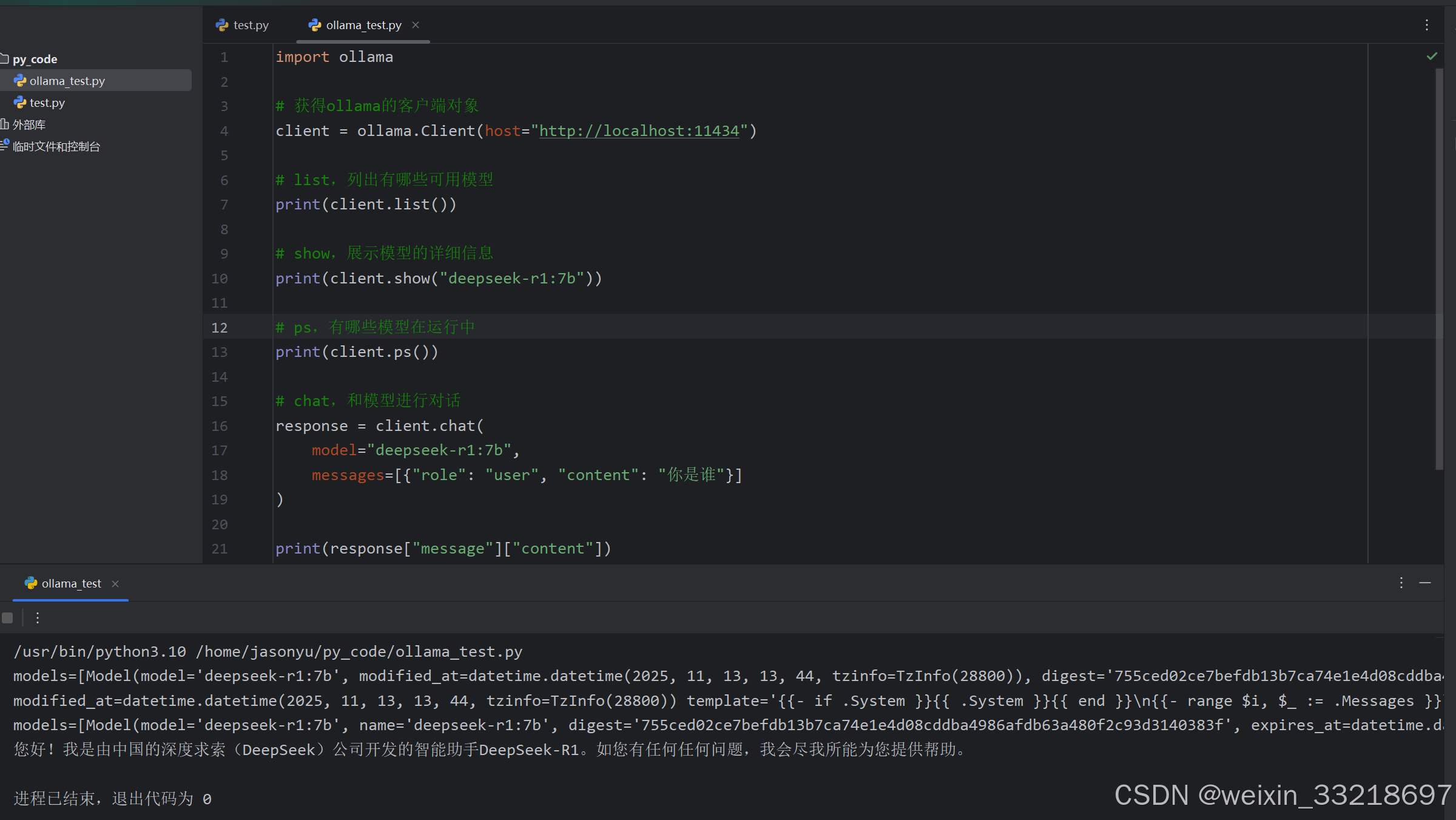
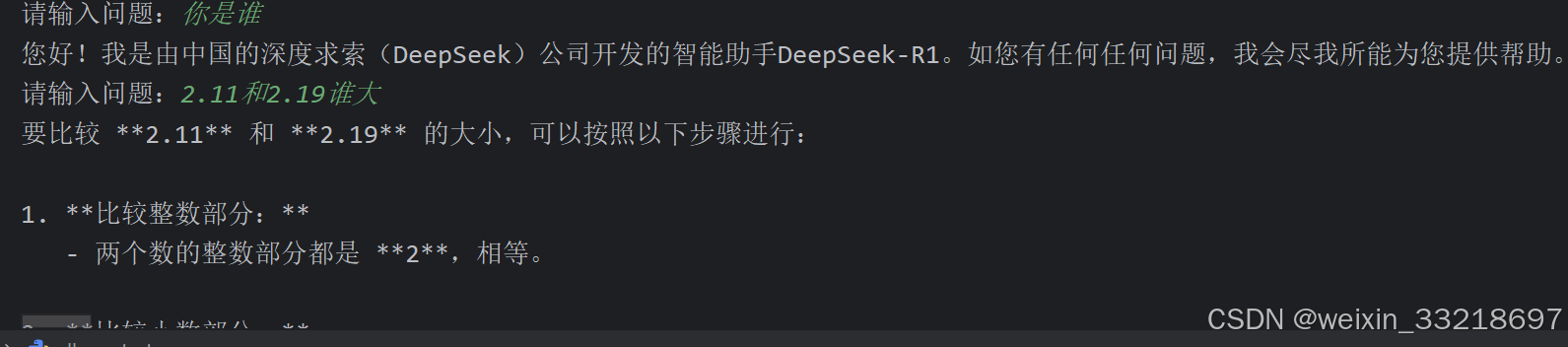
后面改为while循环之后就可以连续提问了,不过我这里回答速度还是有点慢的
13.Streamlit的基础API使用
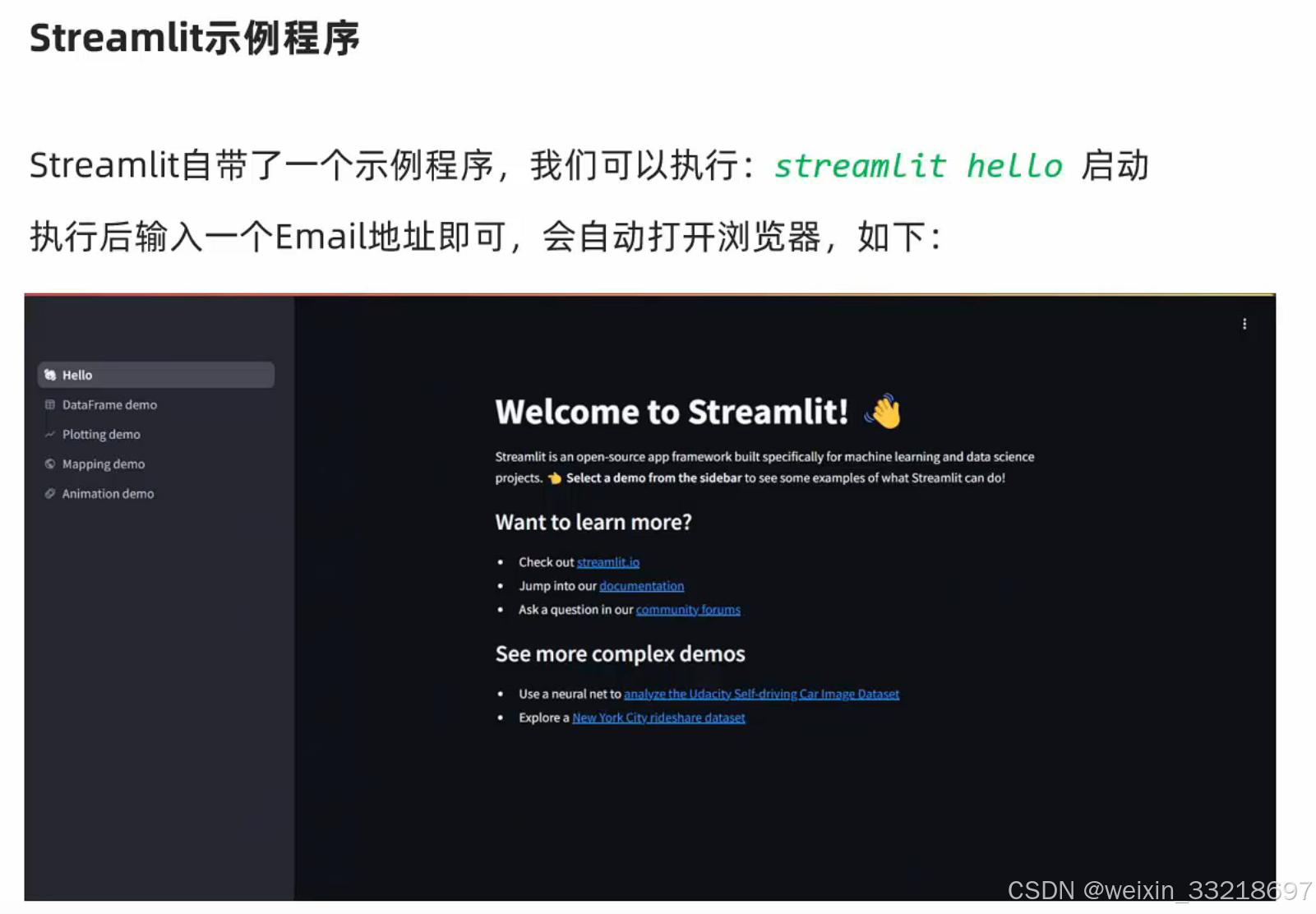
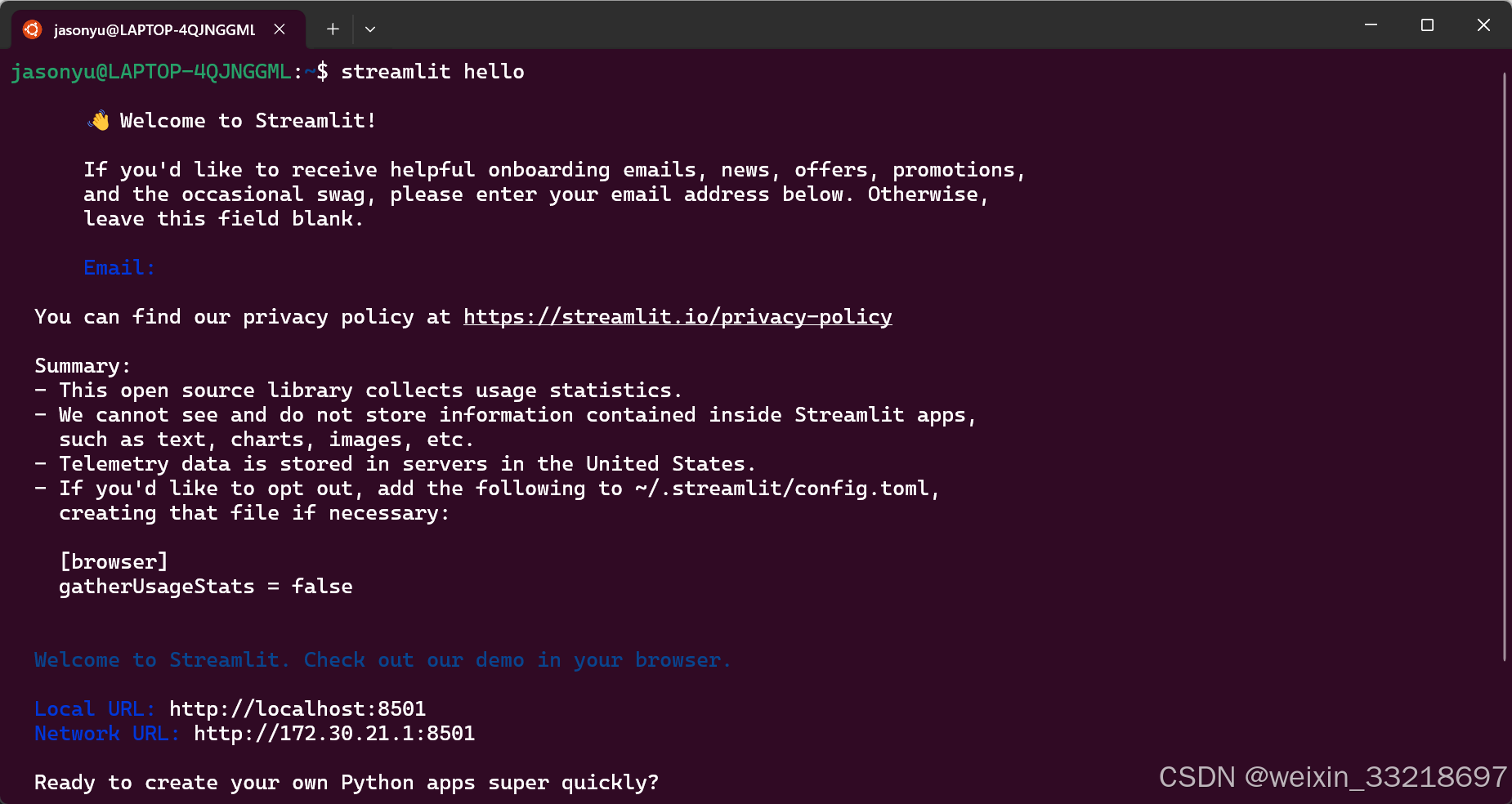
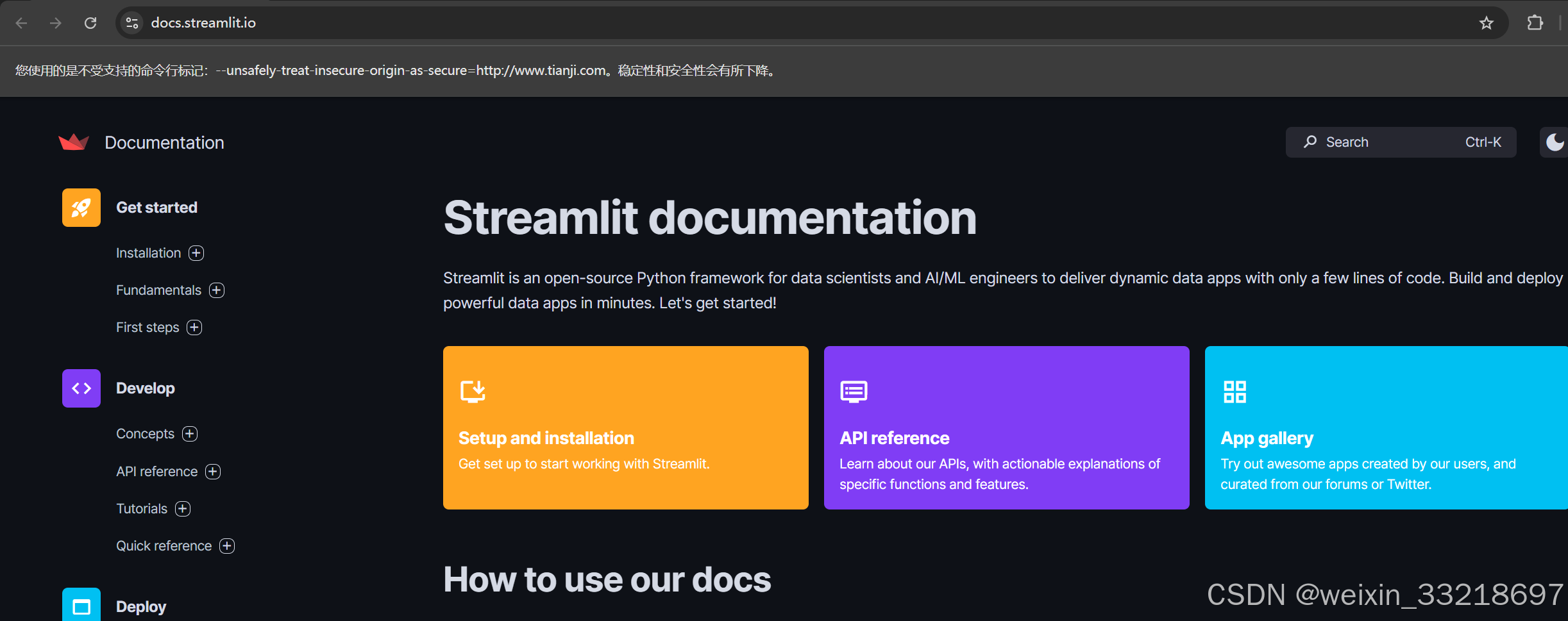
这里我输出streamlit hello有信息输出是没有任何问题的,但是最后并不是老师说的直接回车就能访问网址。我是长按Ctrl再点击https://docs.streamutl.io去访问网址的(建议科学上网访问)


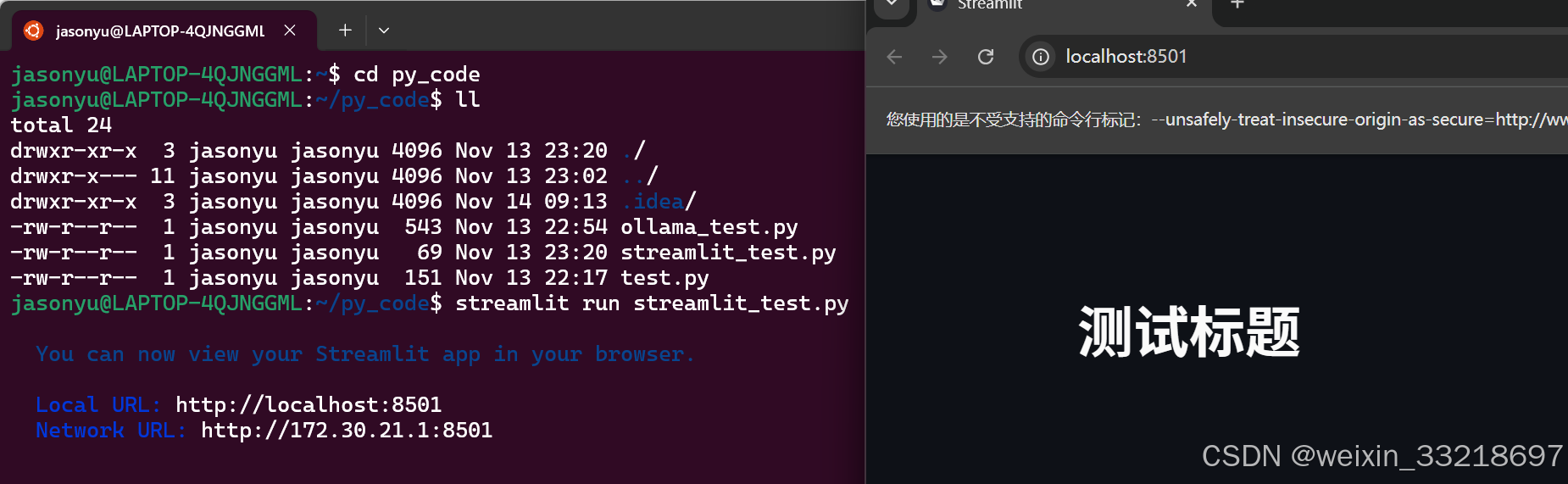
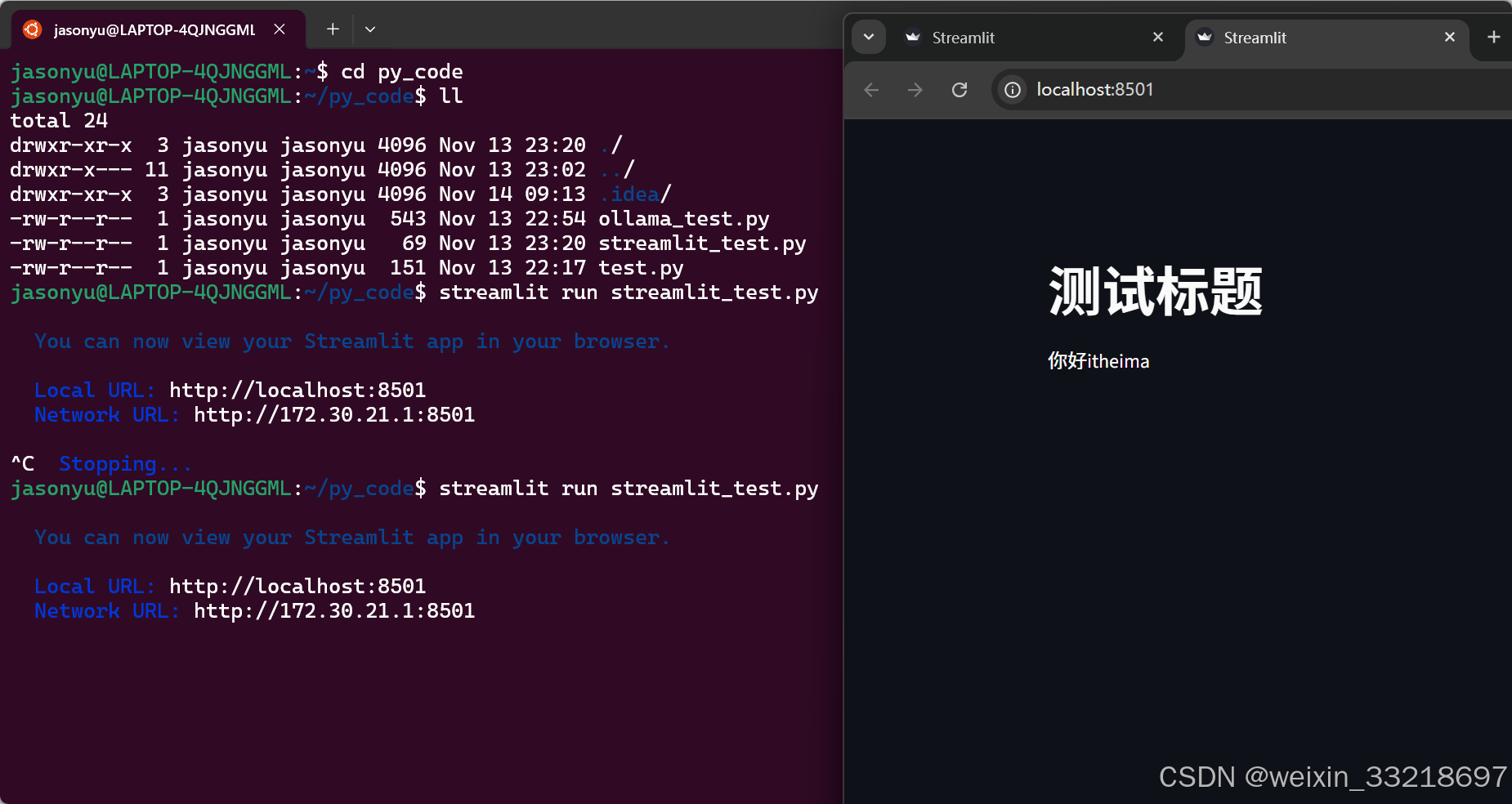
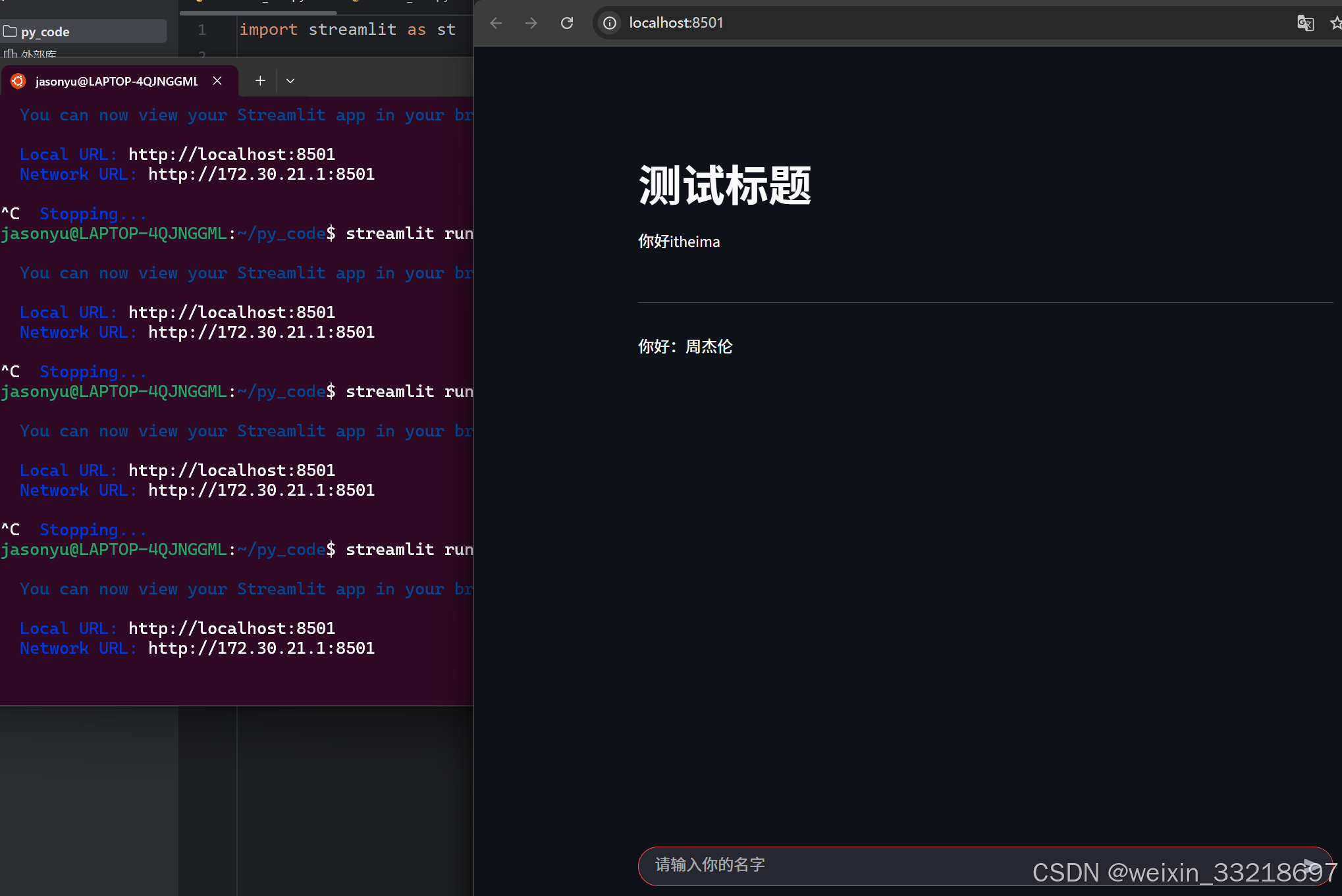
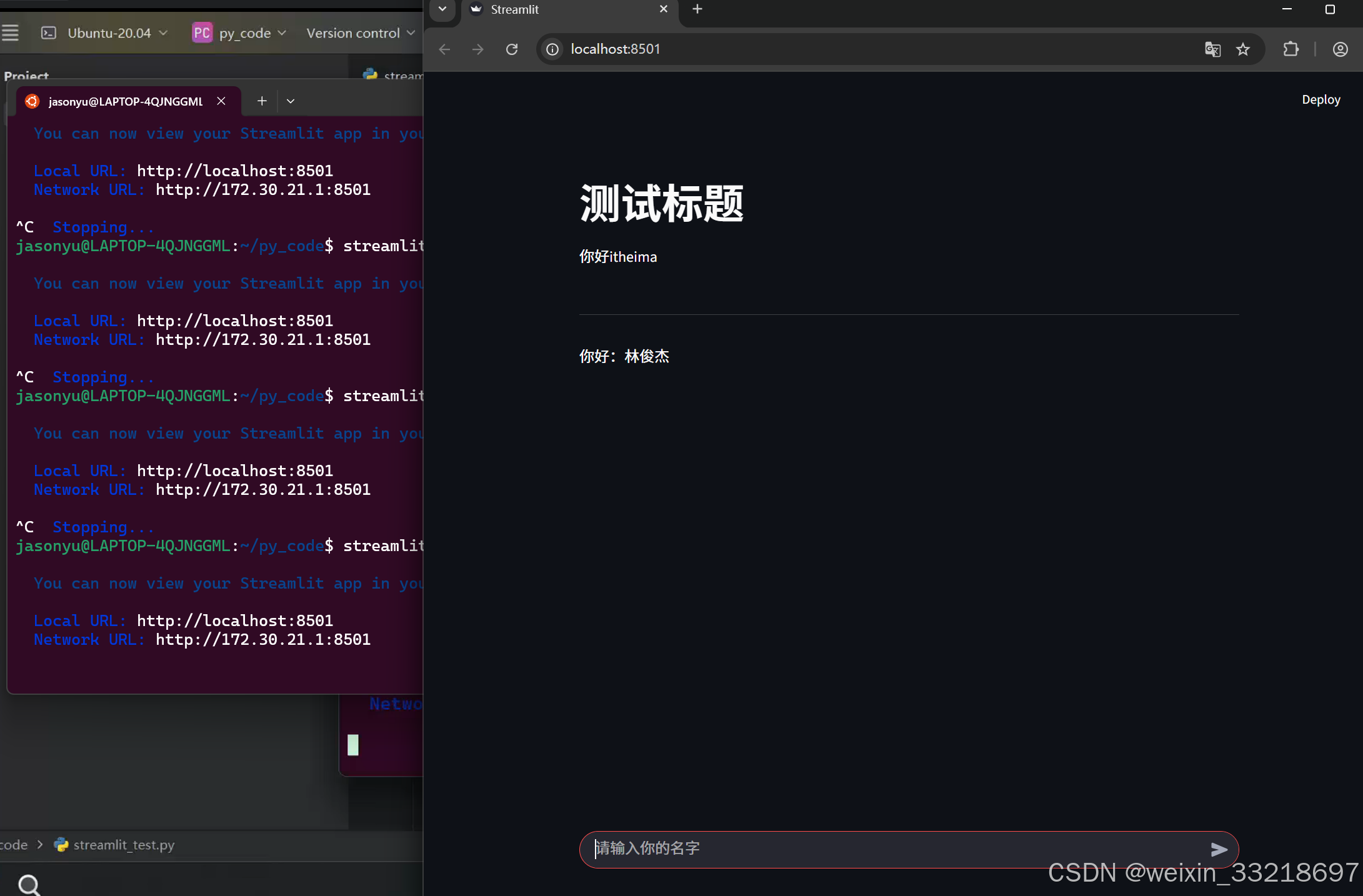
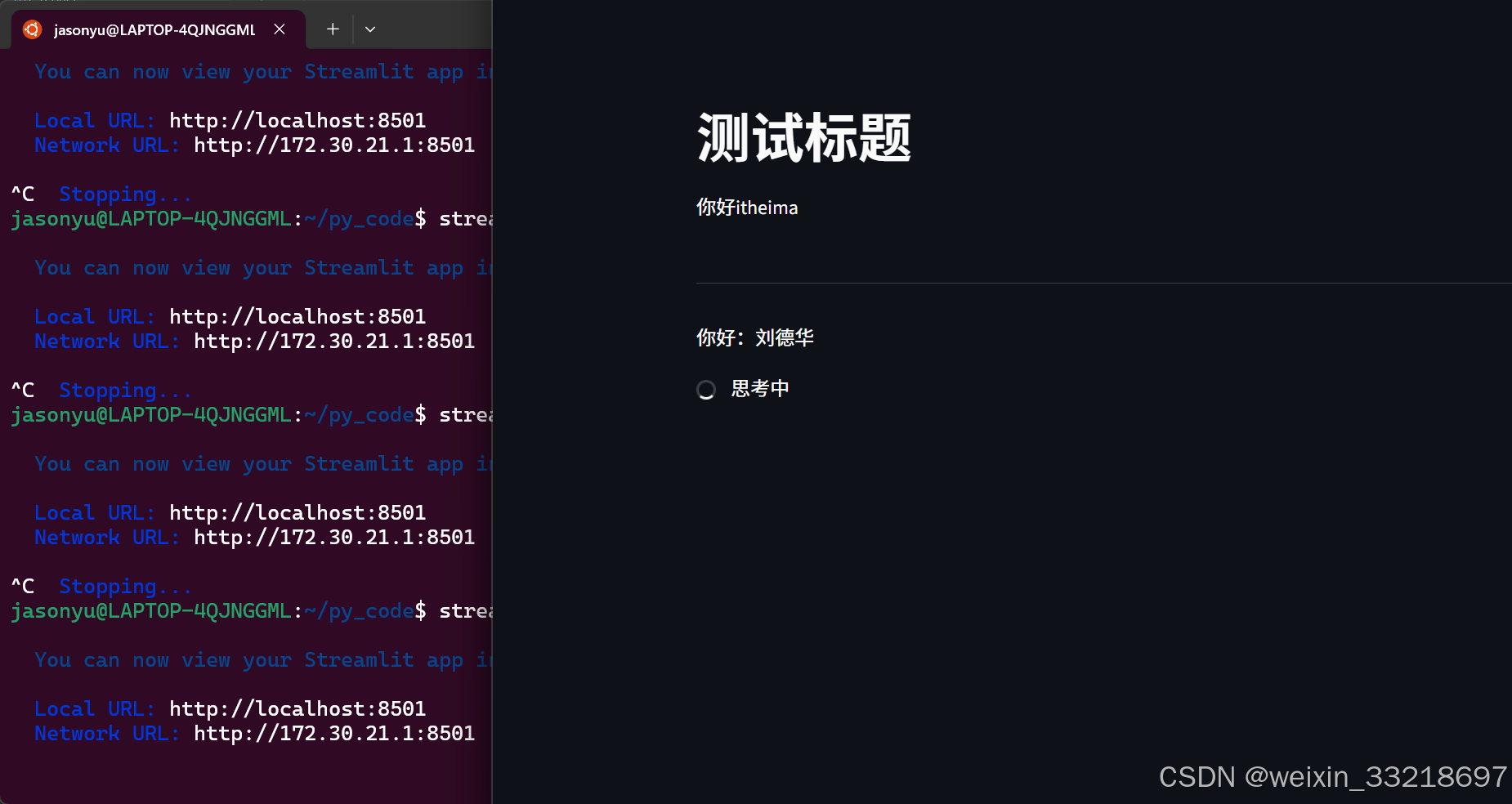
14.Streamlit开发对话网页

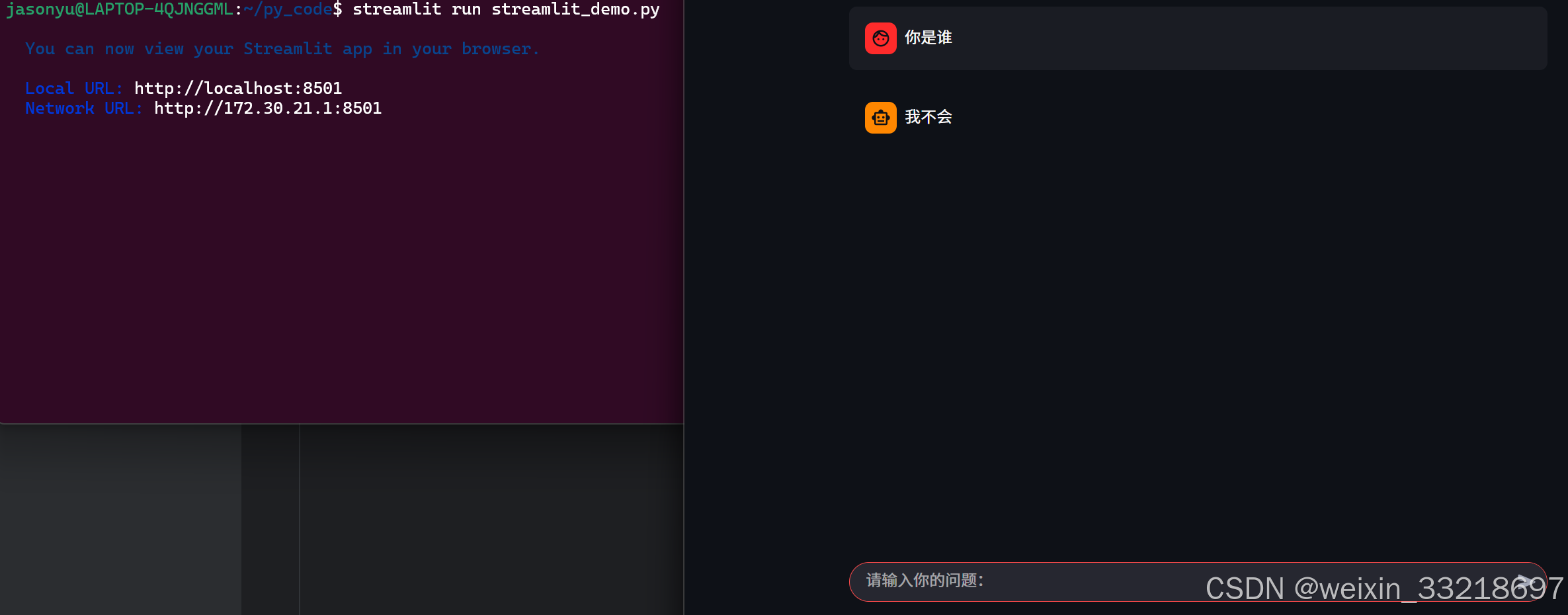
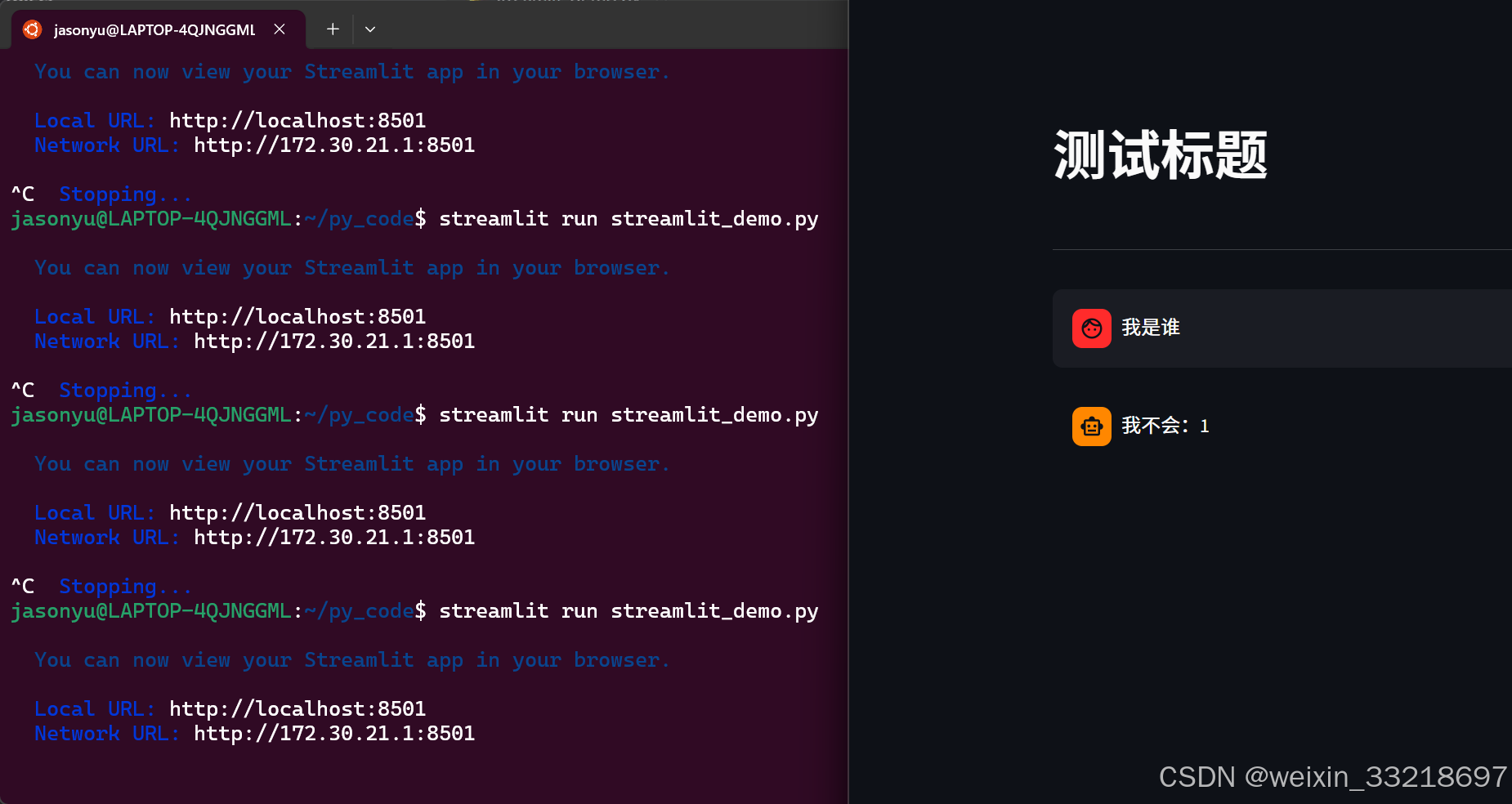

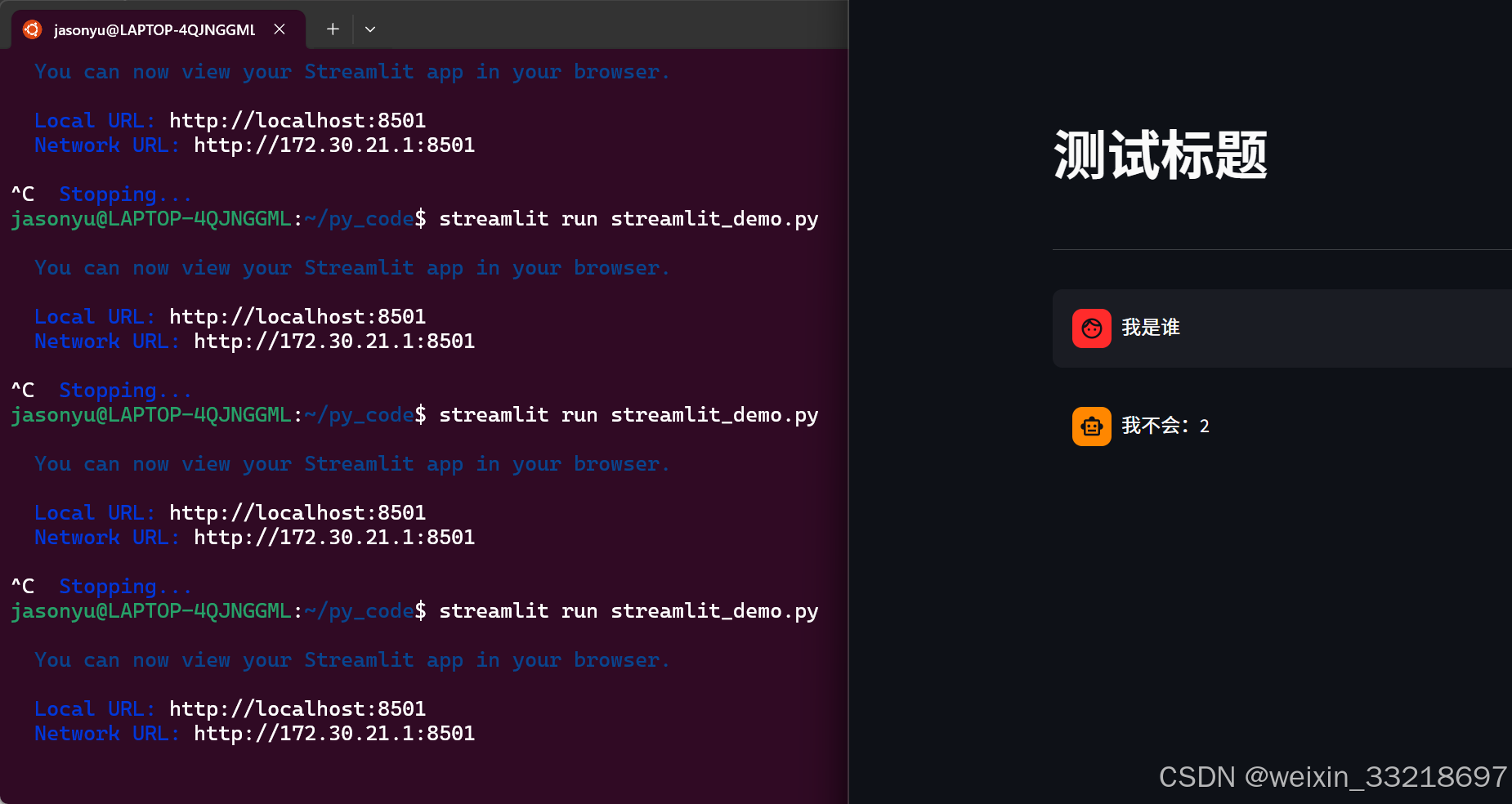
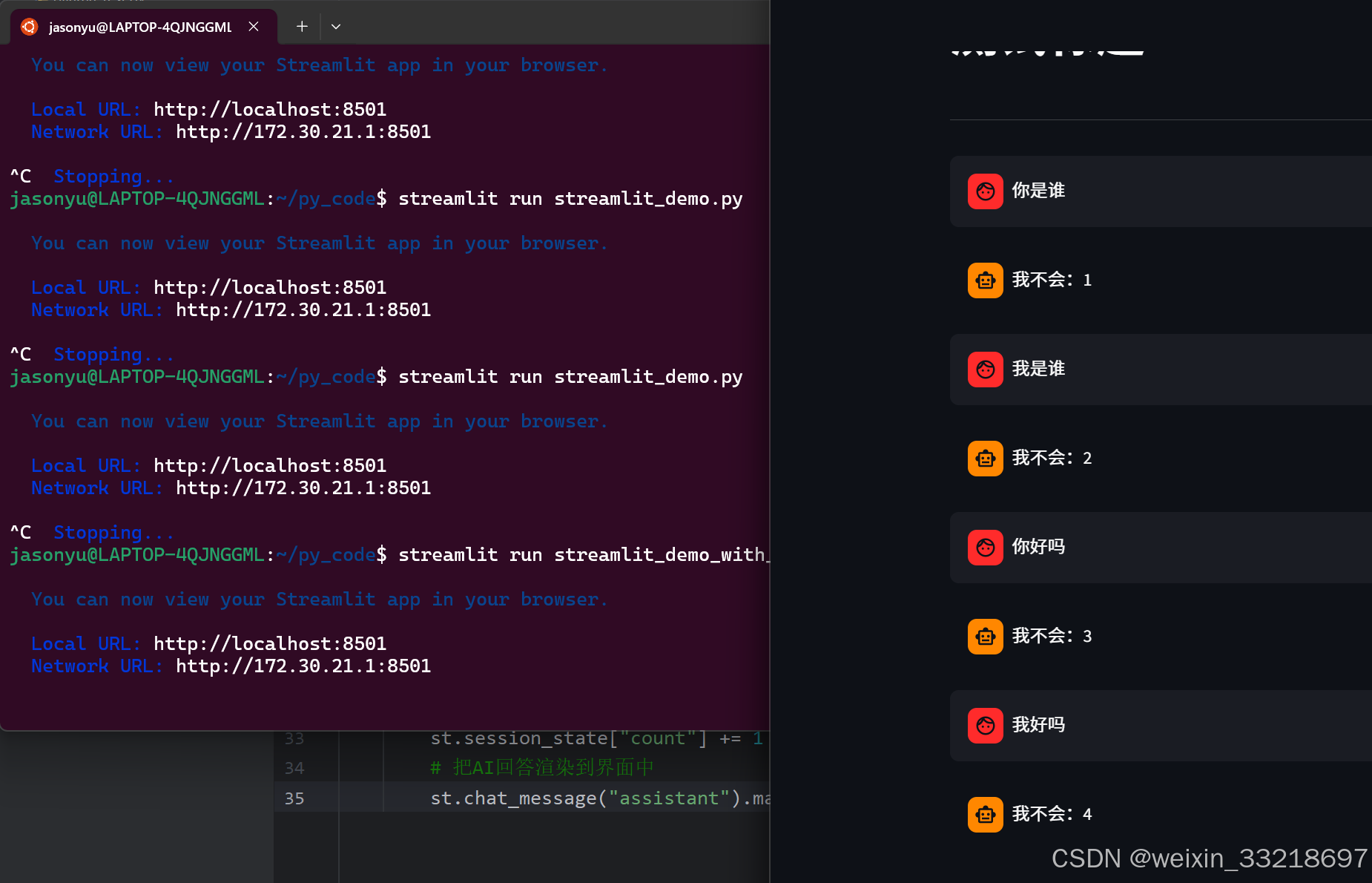
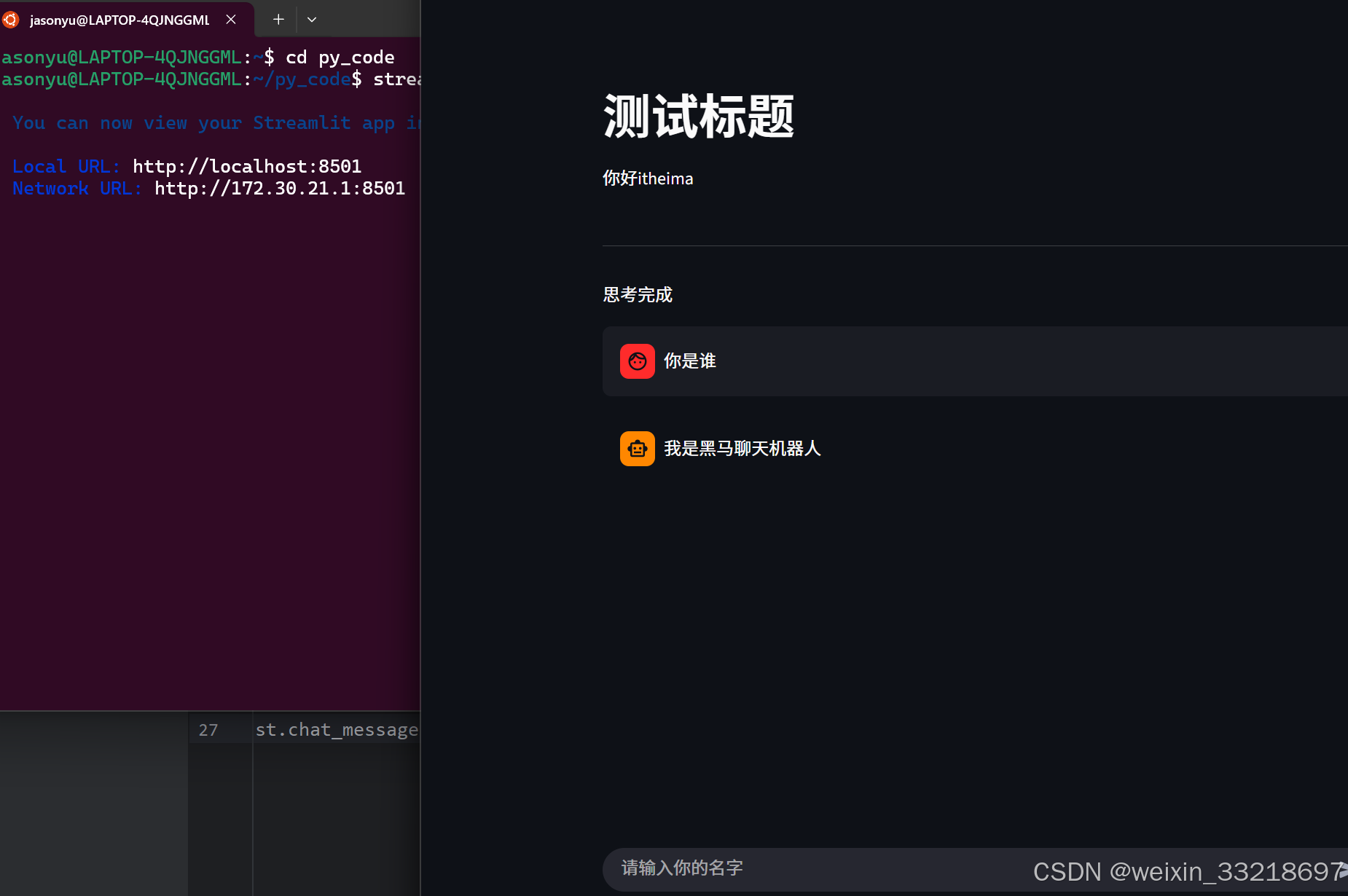
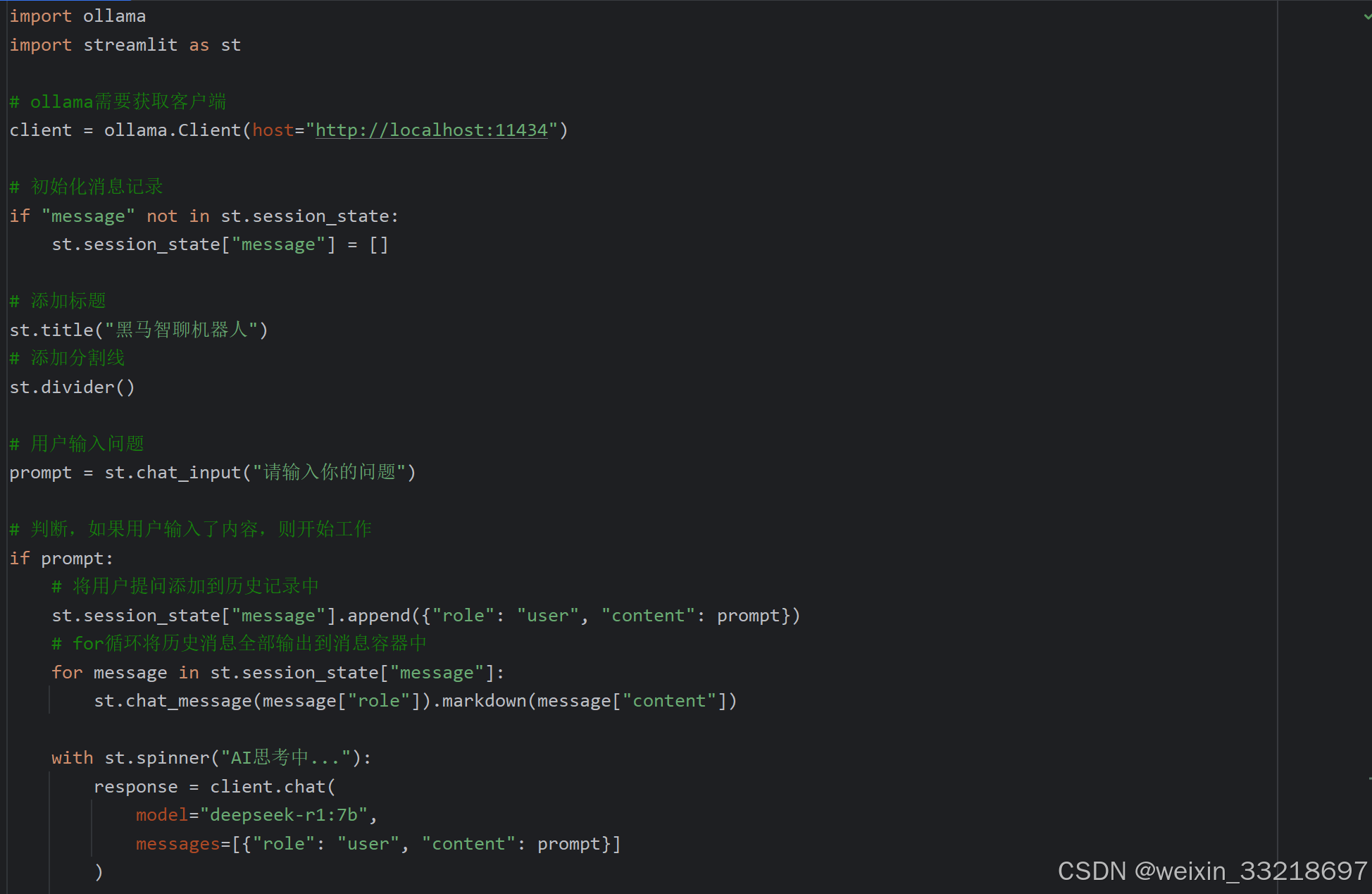
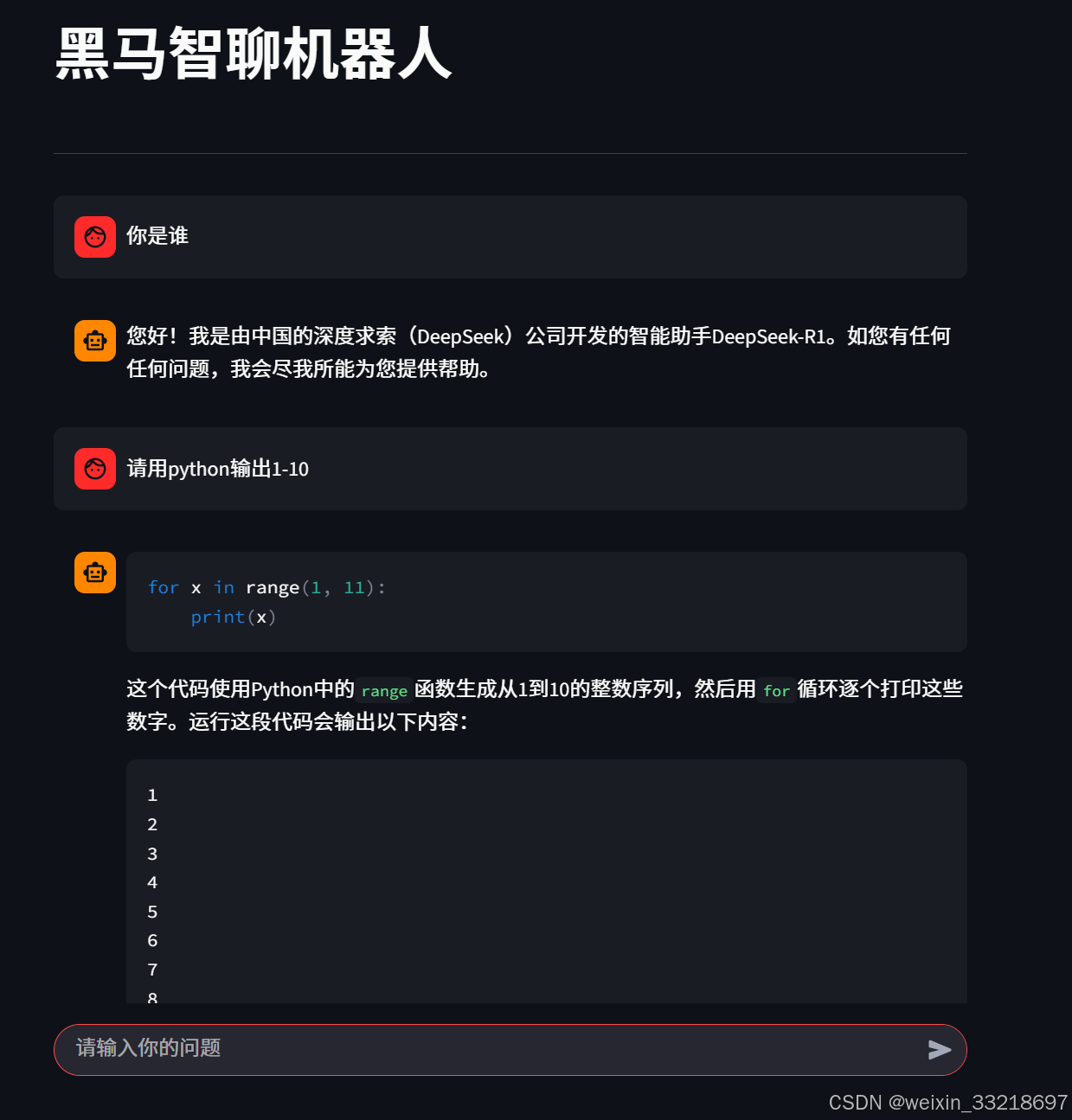
15.Ollama&Streamlit开发聊天机器人界面
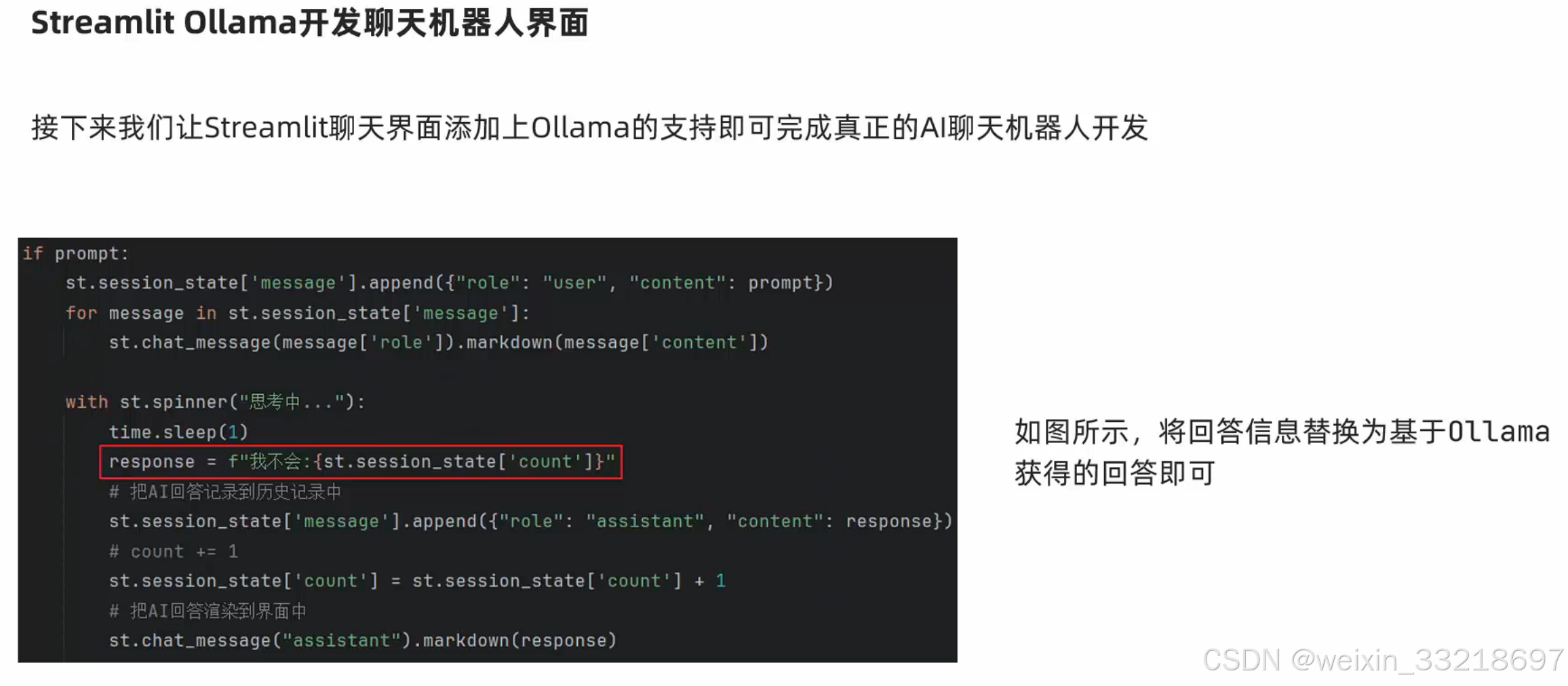

LangChain
16.云上大模型架构
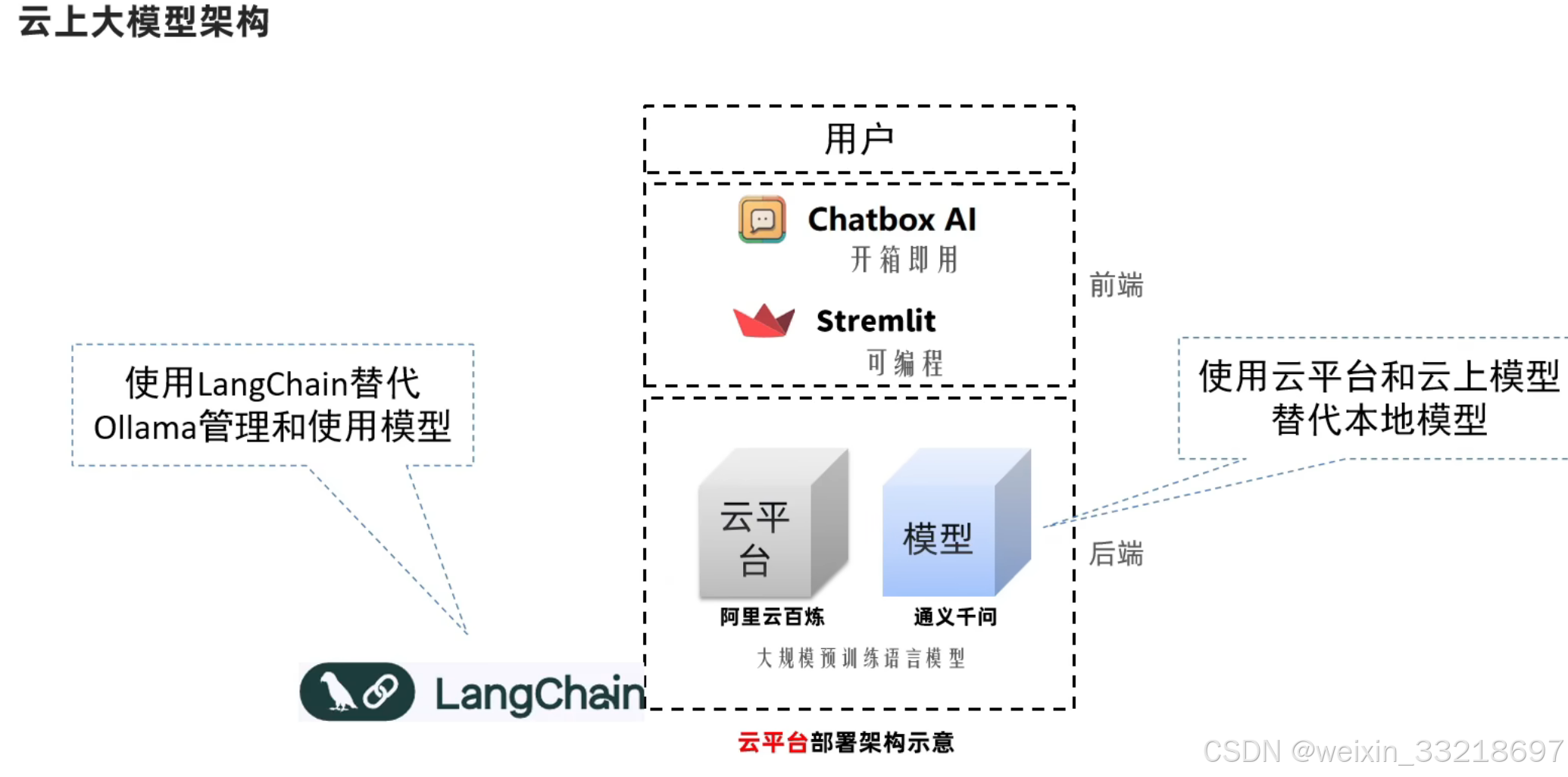

17.LangChain简介






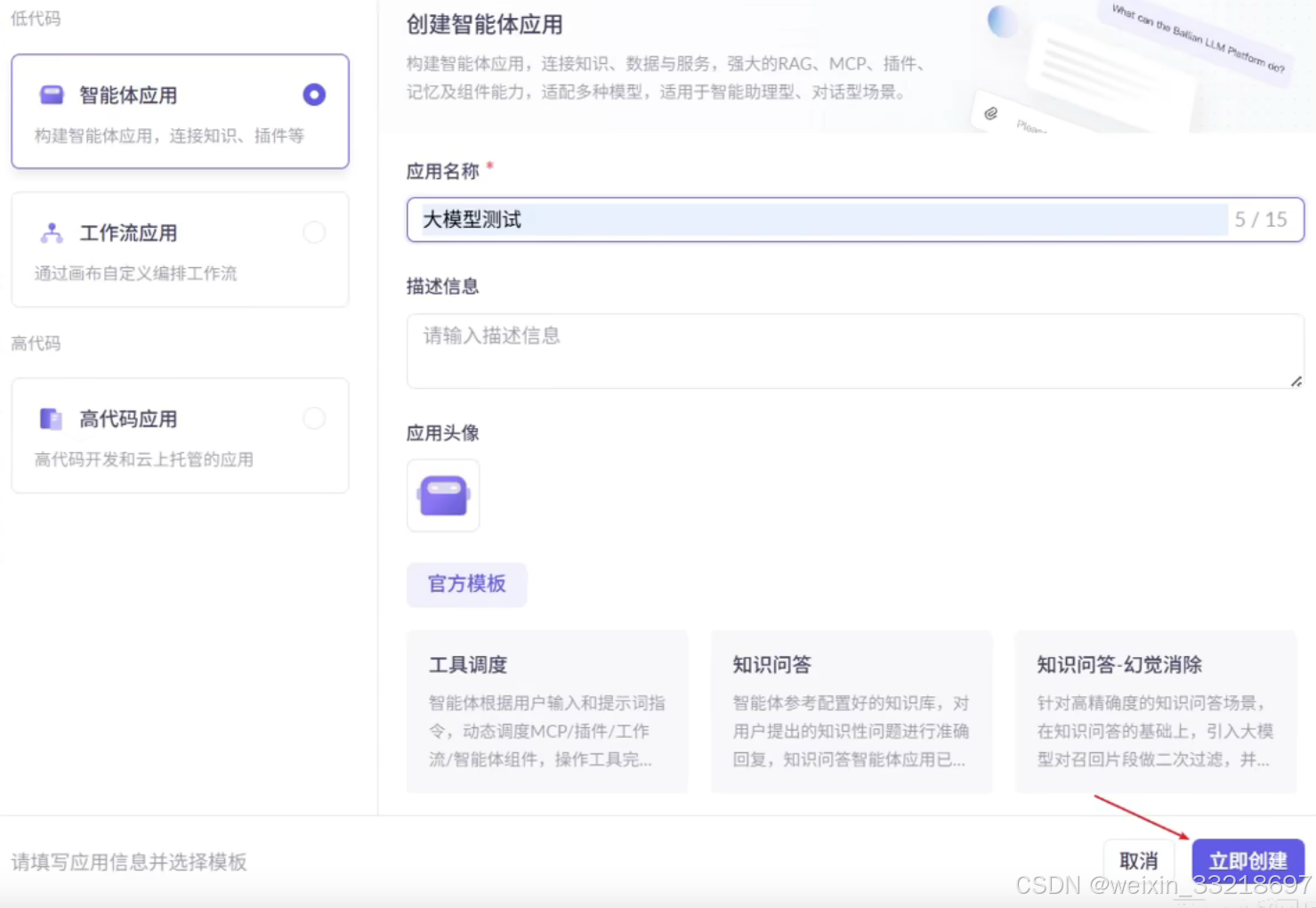
18.创建阿里云百炼平台APIKEY


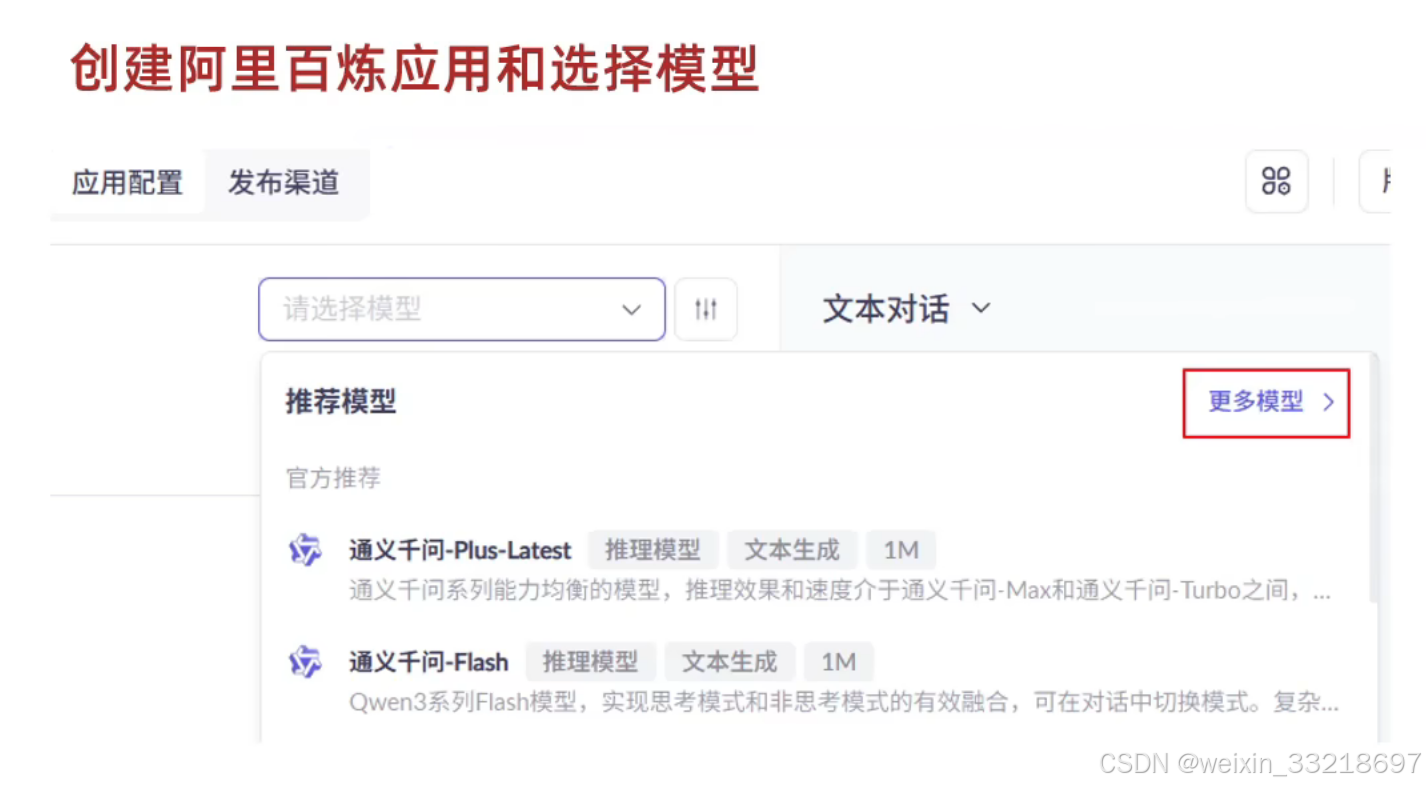
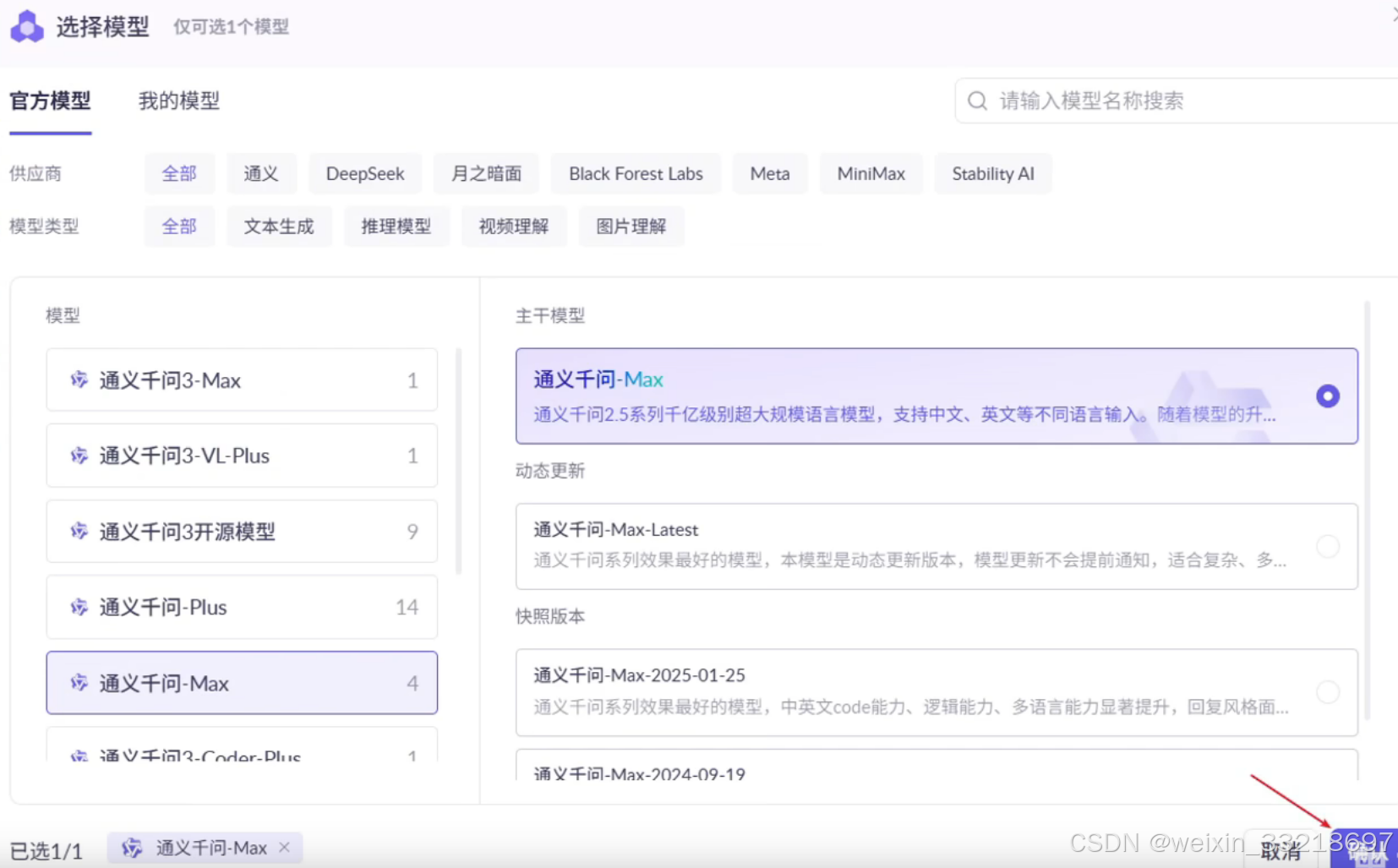
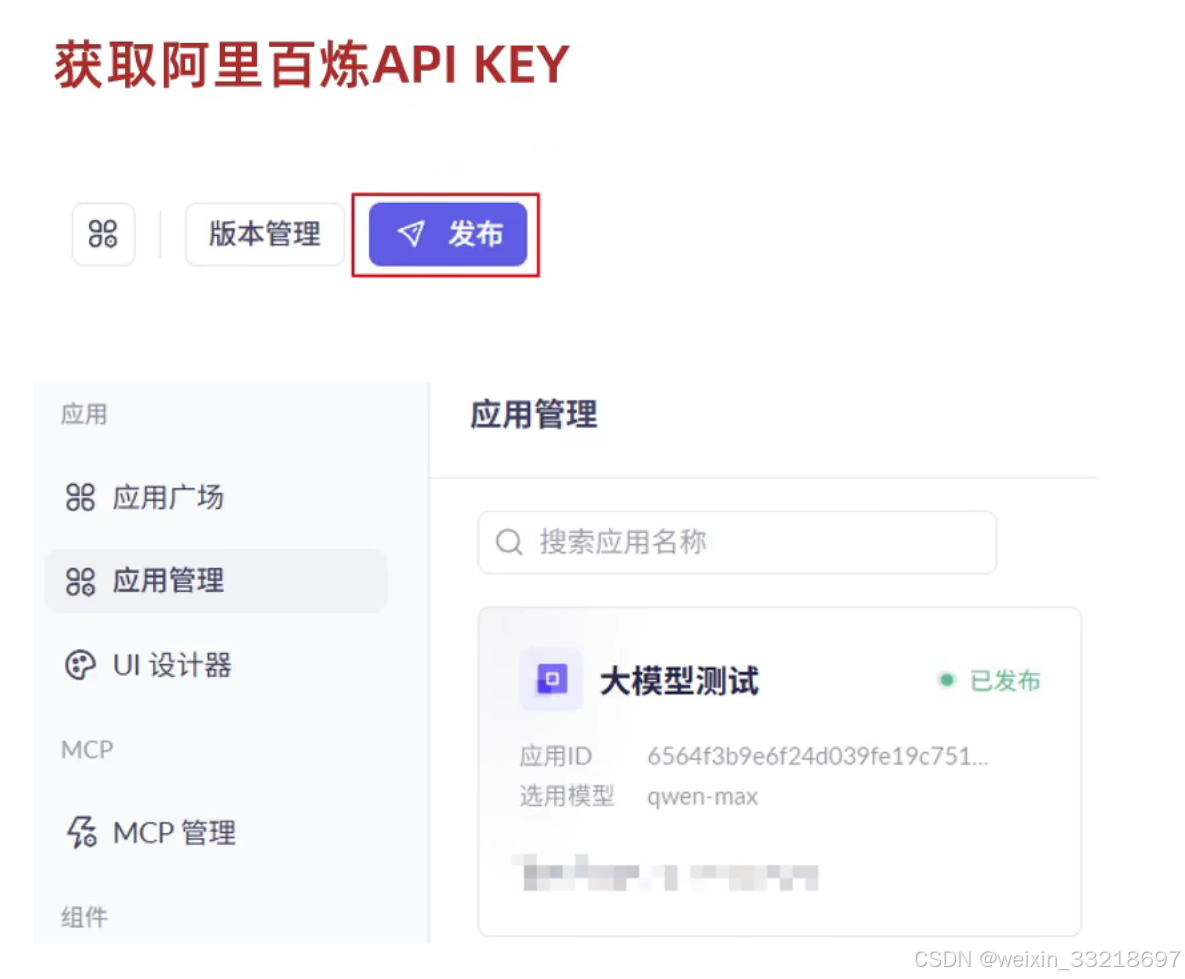
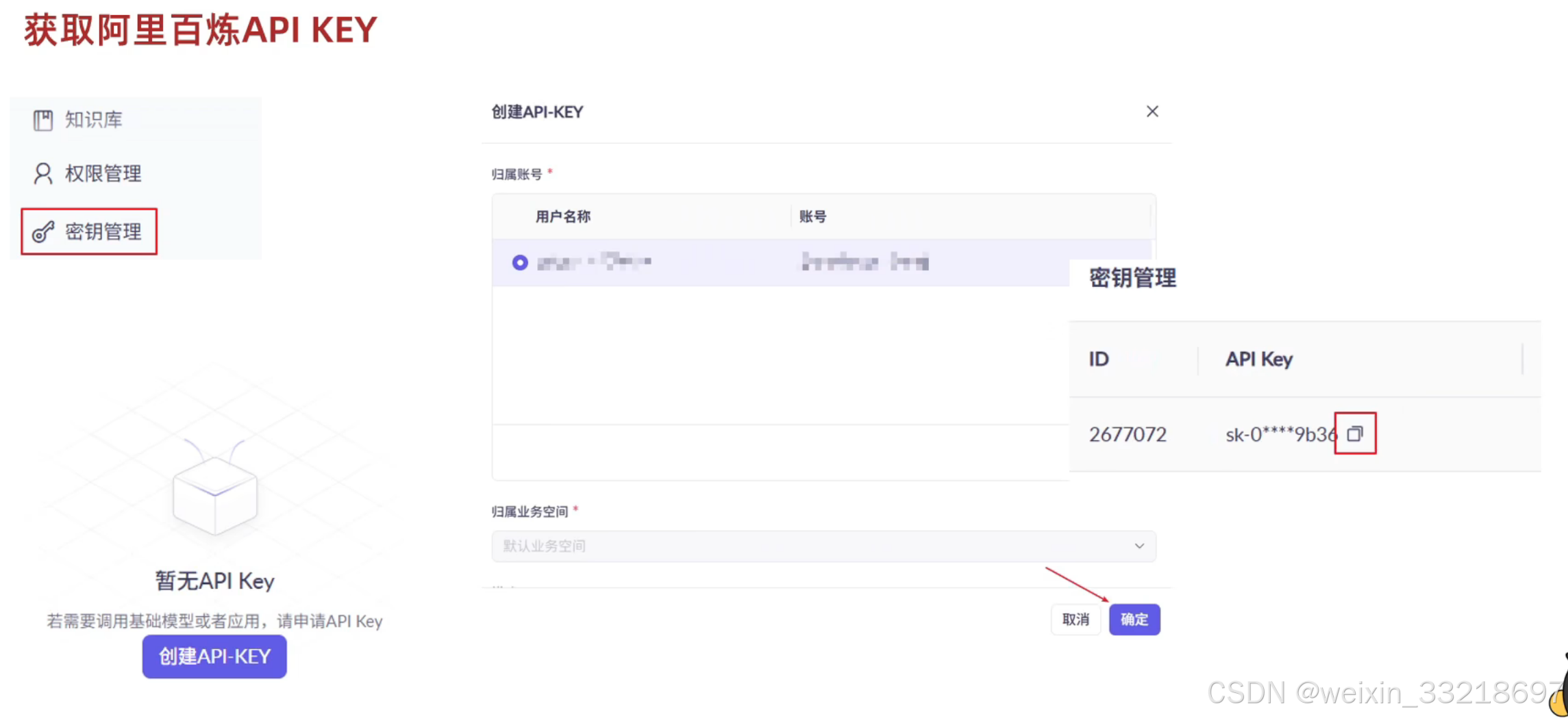
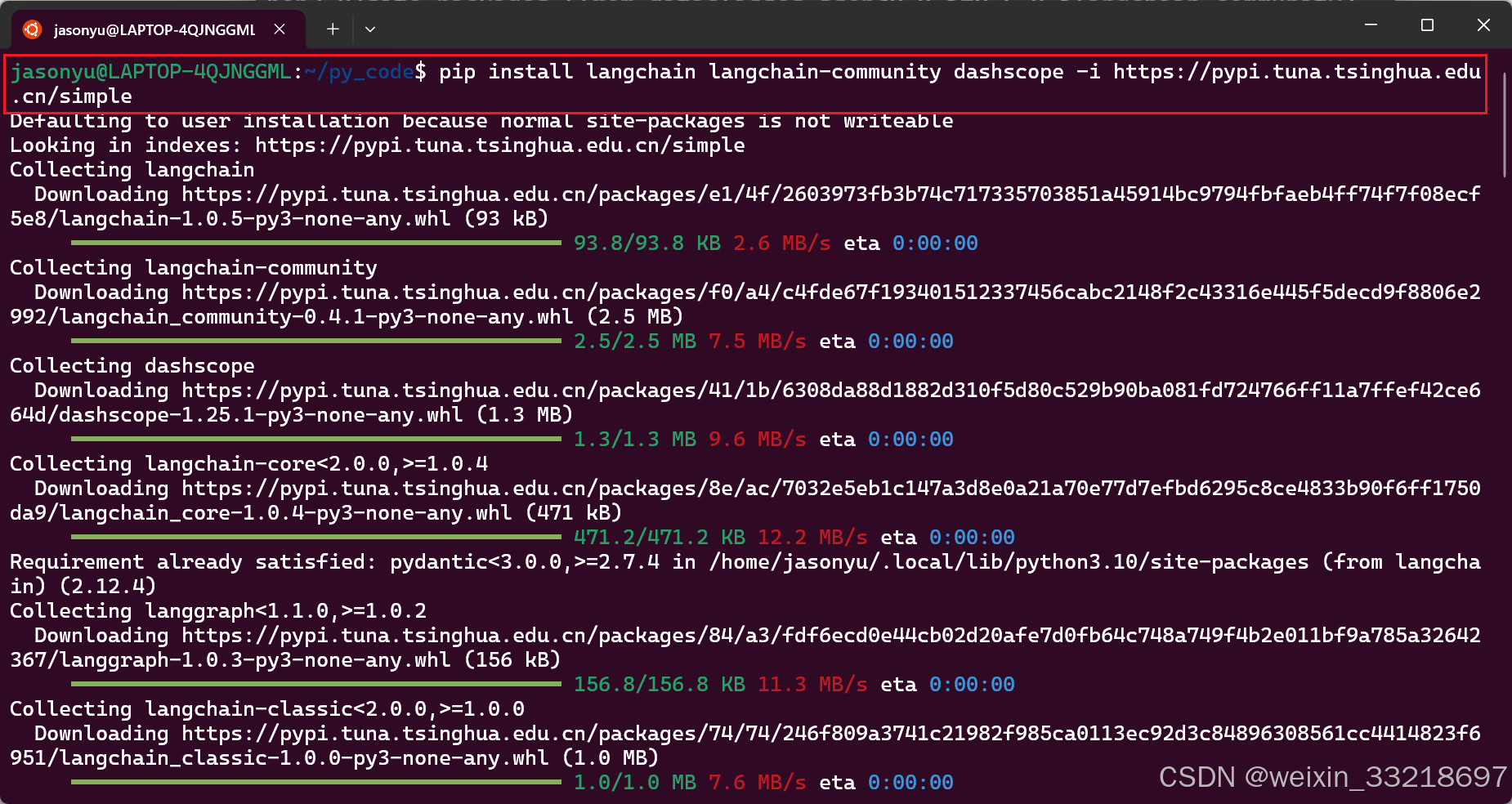
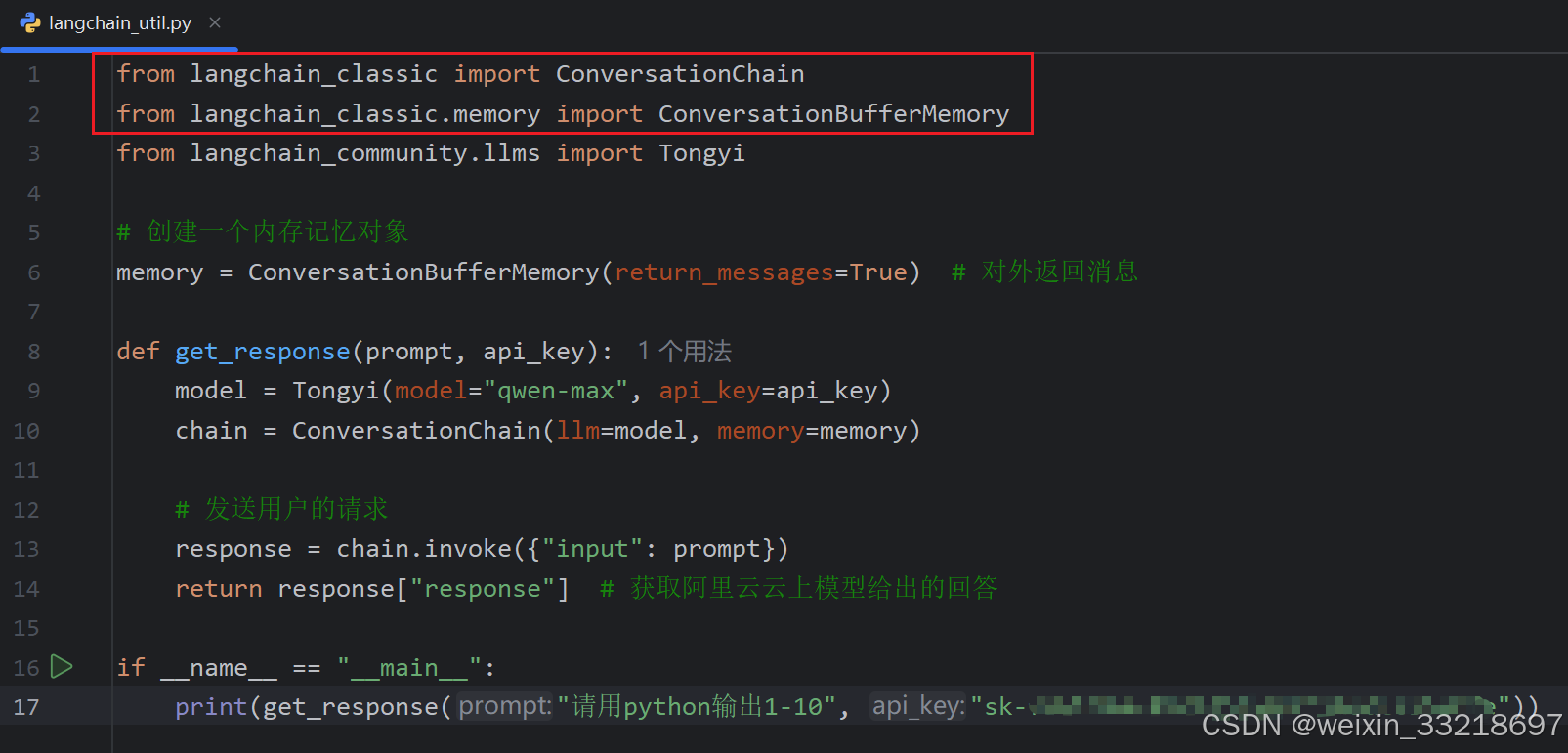
19.LangChain入门案例和APIKEY测试


上面两个导包的代码要修改一下
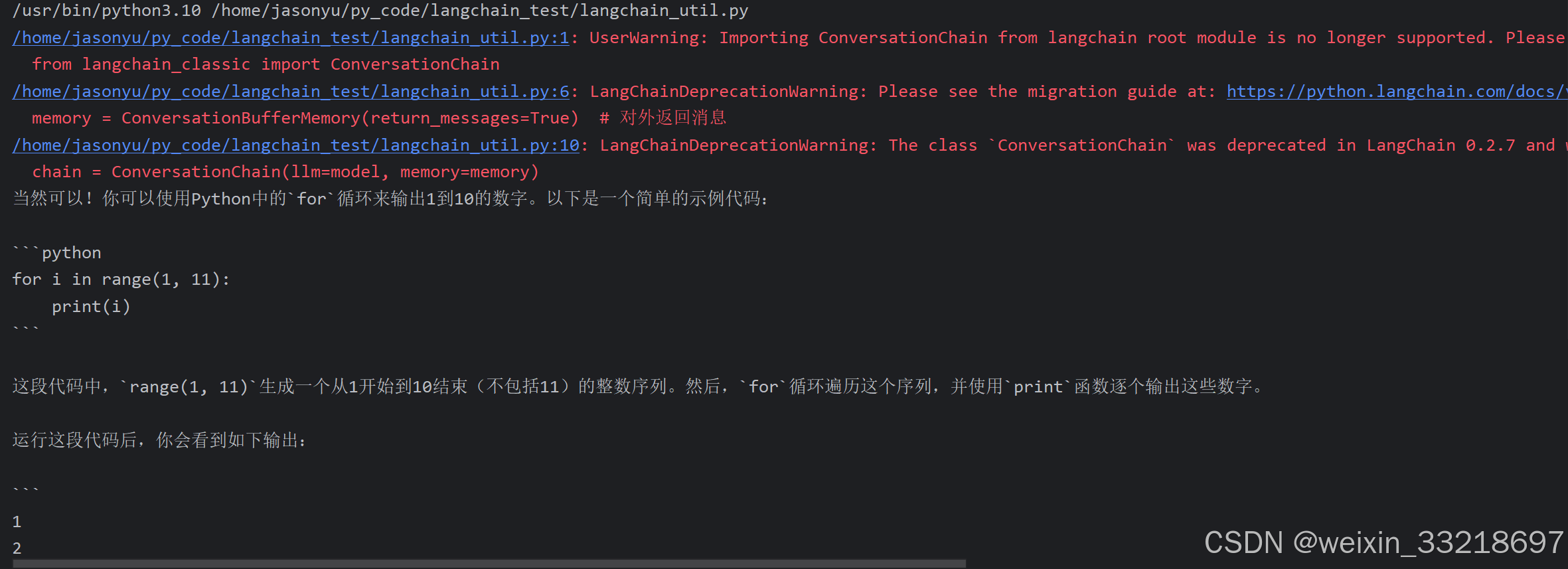
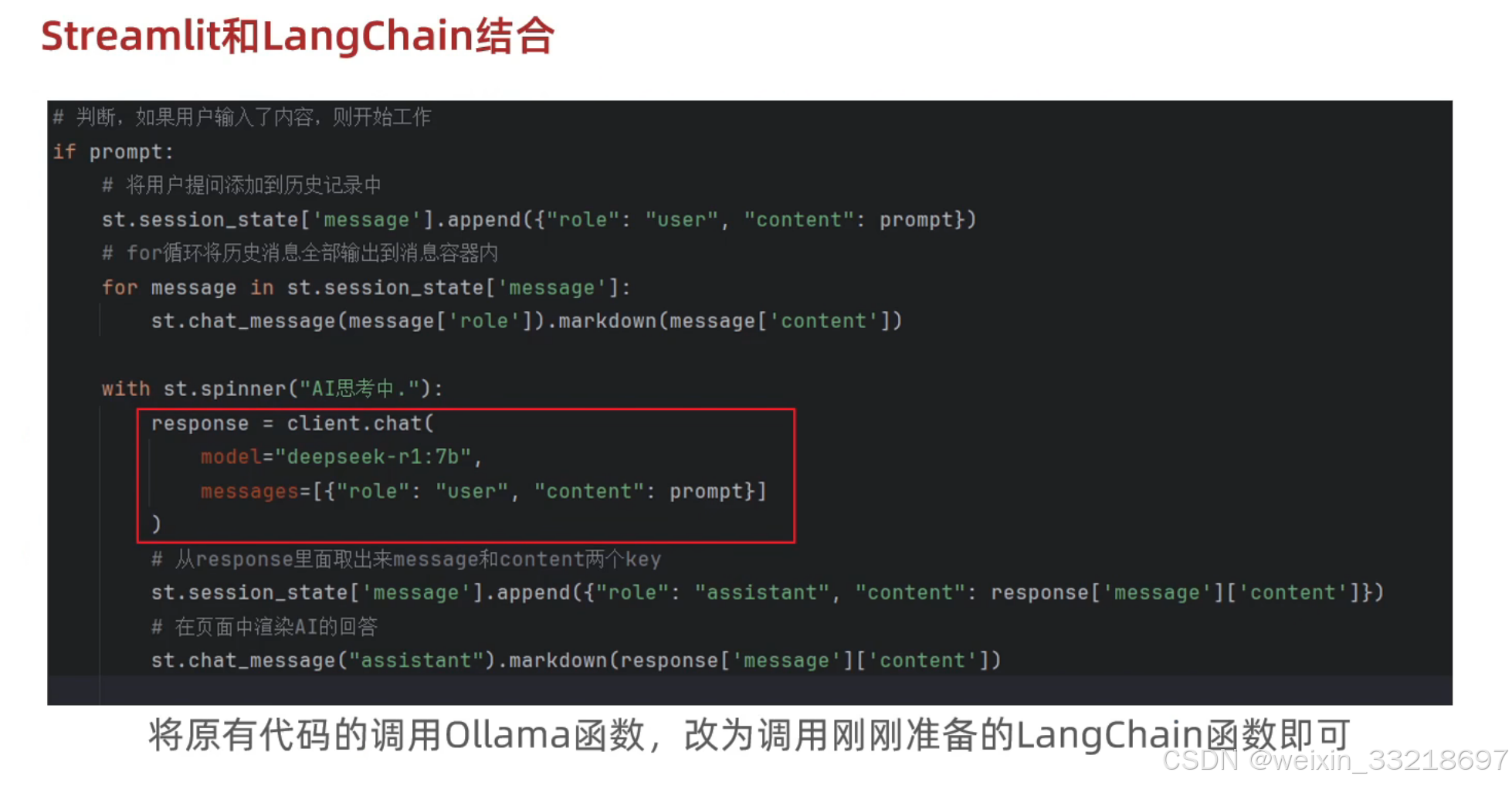
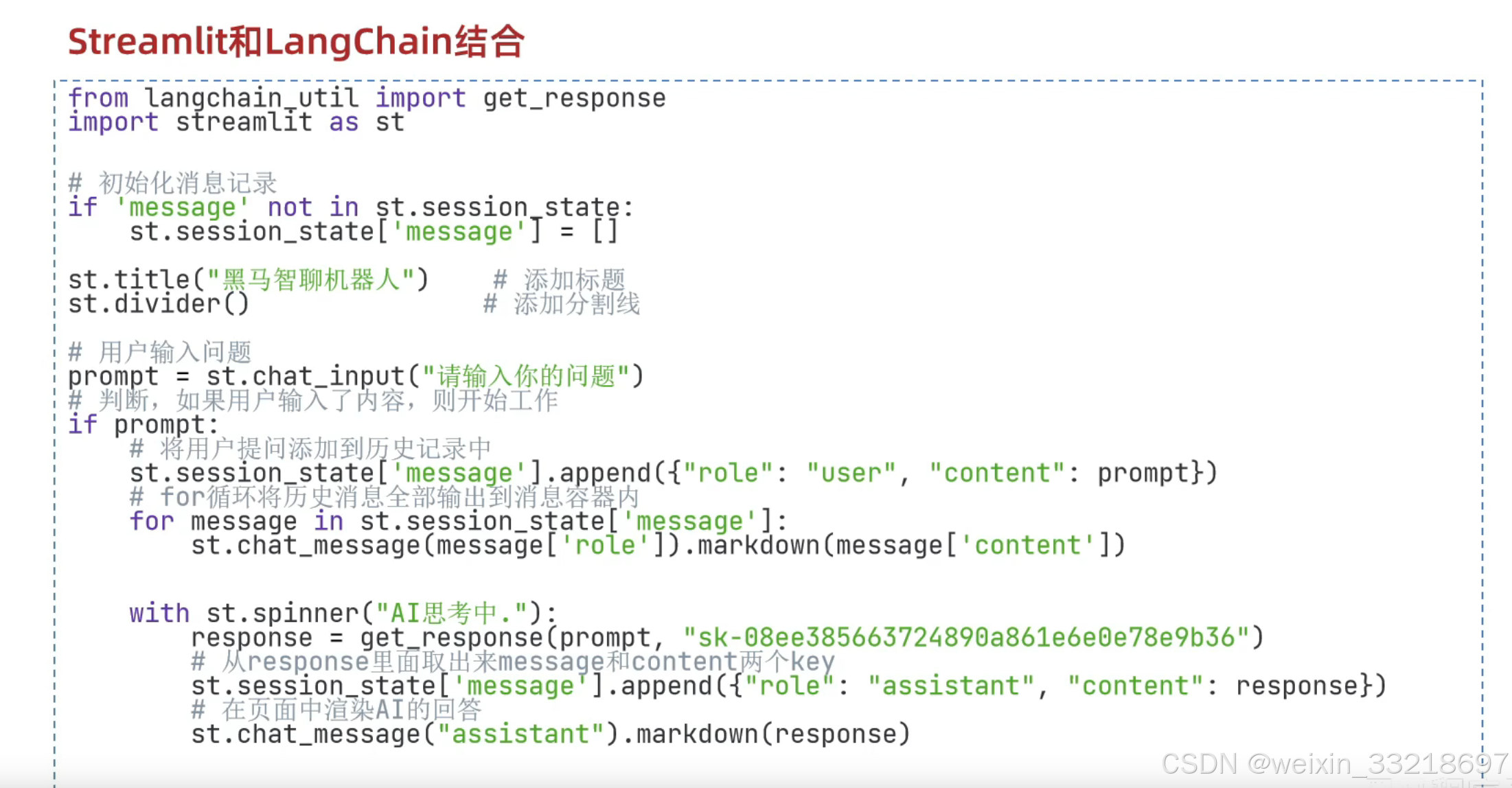
20.Streamlit和Langchain结合构建基于云平台的聊天机器人



有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)