扩散模型(DDPM)经典论文推荐(三):Video Diffusion Models
《Video Diffusion Models》论文开创性地将扩散模型从图像生成拓展到视频领域。通过构建时空U-Net架构,VDM首次实现同时建模空间细节和时序关联;采用图像-视频联合训练策略解决数据稀缺问题;提出梯度条件采样技术生成长视频。相比传统方法,VDM在生成质量、时序连贯性上取得突破,为后续视频扩散研究奠定基础。尽管存在生成时长短、计算成本高等局限,但其务实创新的思路启示我们:技术突破往
在AI生成内容(AIGC)的浪潮中,扩散模型早已在静态图像领域站稳脚跟——从DDPM奠定基础,到Stable Diffusion实现民用化,我们已经能轻松生成照片级别的静态画面。但动态视频的生成,始终是横在研究者面前的一道难关:如何让模型既生成清晰的单帧画面,又保证帧与帧之间的时序连贯性,避免出现“画面跳跃”“动作割裂”的尴尬?
2022年,Jonathan Ho与William Chan联合发表的《Video Diffusion Models》(VDM)论文,给出了第一个令人眼前一亮的答案。这篇论文没有盲目追求复杂的全新架构,而是巧妙地将成熟的图像扩散模型延伸到时序维度,用简洁且有效的设计,首次证明了扩散模型在视频生成领域的巨大潜力,为后续所有视频扩散研究(如CogVideo、DynamiCrafter)奠定了基础。今天,我们就来拆解这篇里程碑式的论文,看看它是如何让扩散模型“动”起来的。
一、研究背景:视频生成的痛点与扩散模型的机遇
在VDM出现之前,视频生成领域的主流方案主要是GANs、自回归模型和VAEs,但这些方法都存在难以逾越的缺陷:
-
GANs擅长生成高保真图像,但在视频生成中容易出现模式崩溃,而且难以保证长序列的时序一致性,经常出现“前一帧人物抬手,后一帧手突然消失”的bug;
-
自回归模型虽然能较好地建模时序关系,但生成速度极慢,且容易积累误差,生成的视频越长,画面质量越差;
-
VAEs则受限于潜在空间的表达能力,生成的视频分辨率和细节丰富度不足,难以满足实际需求。
与此同时,扩散模型在图像领域的爆发式发展,让研究者看到了新的可能。扩散模型通过“正向加噪、反向去噪”的渐进式过程,不仅生成质量高、稳定性强,而且可控性极佳——这正是视频生成所需要的核心能力。但视频和图像最大的区别在于:图像是“空间维度”的单一数据,而视频是“空间+时间”的二维数据,需要同时建模单帧的空间细节和帧间的时序关联。
VDM论文的核心目标,就是解决一个关键问题:如何将扩散模型从“静态图像”无缝迁移到“动态视频”,在不牺牲生成质量的前提下,保证视频的时序连贯性,同时控制计算成本,让模型具备实际应用的可能。
二、核心创新:不造新架构,只做“精准延伸”
VDM最亮眼的地方,在于它没有盲目设计复杂的全新网络,而是基于成熟的图像扩散模型(DDPM),做了“最小化修改”,却实现了视频生成的突破。其核心创新主要集中在3个方面,每一个都直击视频生成的痛点。
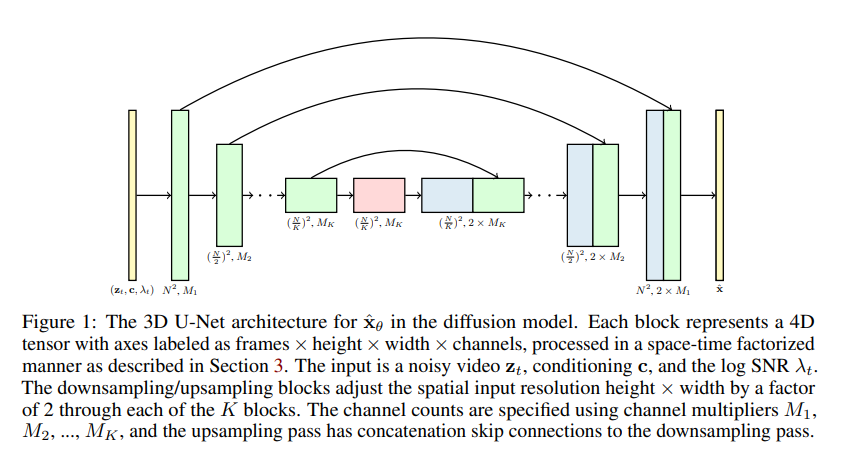
创新1:时空U-Net架构——让模型“看懂”时间与空间
图像扩散模型的核心 backbone 是2D U-Net,主要负责捕捉图像的空间特征(如纹理、形状)。而VDM将其升级为时空U-Net(3D U-Net),这是整个模型最基础的改造,也是最关键的一步。
与2D U-Net仅处理“宽度×高度”的空间维度不同,时空U-Net增加了“时间维度”(帧序列),通过3D卷积操作,同时捕捉视频的空间特征和时序特征——简单来说,它不仅能“看到”单帧画面里的物体是什么,还能“记住”这个物体上一帧的位置,预判下一帧的运动轨迹。
更巧妙的是,这种架构是“因子化”设计的,能够在深度学习加速器的显存限制内,高效处理视频数据,避免了因视频序列过长导致的内存溢出问题。可以说,时空U-Net是VDM能够实现视频生成的“基石”,它让扩散模型第一次具备了“时序感知”能力。
创新2:图像+视频联合训练——提升稳定性,降低训练成本
视频数据的标注成本高、数量少,单独用视频数据训练模型,不仅容易过拟合,还会导致训练梯度方差过大,模型难以收敛。VDM提出了一个非常实用的解决方案:联合训练图像和视频数据。
具体来说,模型在训练时,既会输入单帧图像(相当于“时长为1的视频”),也会输入完整的视频序列。这种训练方式有两个核心优势:一是图像数据数量庞大、获取容易,能够帮助模型快速学习空间特征,提升单帧生成质量;二是视频数据能让模型学习时序关联,同时联合训练还能降低minibatch梯度的方差,加快模型优化速度,让训练过程更稳定。
这一设计看似简单,却完美解决了视频数据稀缺的痛点,也让VDM在有限的计算资源下,实现了更好的生成效果——这也是后续很多视频扩散模型沿用的核心训练策略。
创新3:梯度条件采样——实现长视频与高分辨率生成
早期的视频生成模型,要么只能生成短时长视频(通常只有几帧),要么生成的长视频出现时序断裂。VDM提出了一种全新的条件采样技术(梯度方法),专门解决长视频扩展和高分辨率生成的问题。
其核心思路是:先训练一个固定帧数的视频扩散模型,然后通过“块自回归”的方式,利用梯度条件采样技术,将生成的视频片段逐步扩展——简单来说,就是先生成前N帧,再以这N帧为条件,生成接下来的N帧,以此类推,实现长视频生成。
与当时的基线方法(如“替换法”)相比,这种梯度条件采样技术能更好地保证扩展后视频的时序一致性,避免出现“画面断层”“动作不连贯”的问题。实验表明,VDM能够生成更长、更高分辨率的视频,且生成质量远超当时的主流方法。
三、技术细节:VDM的核心工作流程
理解了核心创新,我们再梳理一下VDM的完整工作流程,其实它完全遵循扩散模型“正向加噪、反向去噪”的核心逻辑,只是在细节上适配了视频数据:
1. 正向扩散过程(加噪)
与DDPM类似,VDM的正向过程是一个马尔可夫链,逐步向真实视频序列中添加高斯噪声,直到视频完全变成随机噪声。这里的关键区别是:加噪过程不仅作用于每帧的空间维度,还会保持帧间的时序关系——也就是说,噪声的添加是“时空同步”的,不会破坏视频原本的运动规律。
从数学上看,正向过程遵循高斯扩散模型的标准公式,通过预设的噪声调度(α_t、σ_t),逐步降低视频的信号噪声比,最终让视频序列逼近标准高斯分布。
2. 反向去噪过程(生成)
反向过程是VDM的核心,也是生成视频的关键。模型通过时空U-Net,从随机噪声出发,逐步去噪,还原出清晰、连贯的视频序列。
与图像扩散模型不同,VDM的去噪过程需要同时预测“空间噪声”和“时序噪声”——也就是说,模型不仅要还原单帧画面的细节,还要修正帧间的运动偏差,保证时序连贯性。而联合训练学到的空间特征和时序特征,正是支撑这一过程的关键。
3. 采样与扩展
在采样阶段,VDM首先生成一个固定帧数的视频片段(如16帧),然后利用梯度条件采样技术,以该片段为条件, autoregressively 扩展视频长度。这种方式既保证了生成效率,又能有效维持时序一致性,让模型能够生成更长的视频序列。
四、实验结果:用数据证明实力
VDM在多个基准测试中展现出了当时的SOTA(state-of-the-art)水平,主要体现在三个任务上:
-
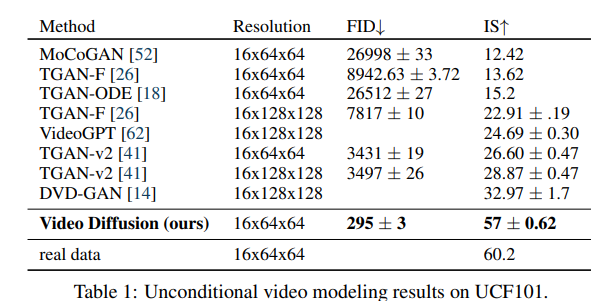
无条件视频生成:在主流基准数据集上,VDM生成的视频在视觉质量、时序一致性上远超GANs、自回归模型等基线方法,获得了最优的样本质量分数;
-
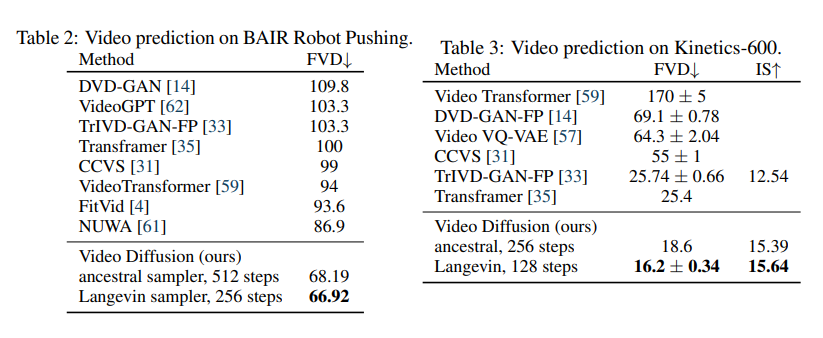
视频预测:能够基于前几帧,准确预测后续帧的运动轨迹,预测结果的连贯性和准确性显著提升;
-
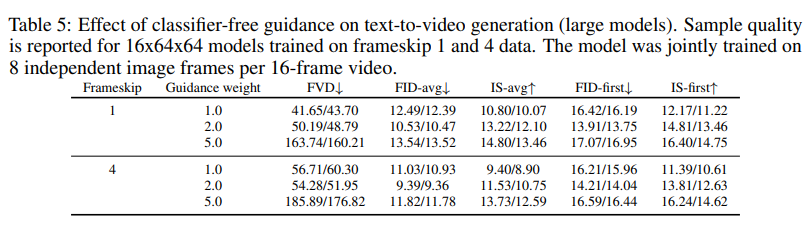
文本条件视频生成:首次实现了基于扩散模型的文本驱动视频生成,虽然生成的视频时长较短(约2-4秒),但已经能较好地匹配文本提示(如“烟花绽放”),展现出了强大的可控性。
论文中还给出了直观的对比示例:用梯度条件采样生成的视频,比基线方法生成的视频更连贯,动作更自然,单帧细节也更清晰——这充分证明了VDM核心创新的有效性。



五、论文意义与局限:承前启后,指明方向
作为第一篇将扩散模型成功应用于视频生成的里程碑论文,VDM的意义远不止“生成了一段连贯的视频”,它更重要的贡献在于:
-
验证了扩散模型在视频领域的可行性,为后续视频扩散研究开辟了道路——此后的Latent Video Diffusion、DiT-Video等模型,都沿用了VDM的核心思路,在其基础上优化升级;
-
提出的“图像+视频联合训练”“梯度条件采样”等方法,成为视频扩散模型的“标配”,解决了视频生成中的核心痛点;
-
首次实现了文本条件视频生成,为后续多模态视频生成(如文生视频、图生视频)奠定了基础,推动了AIGC从静态向动态的跨越。
当然,受限于当时的技术水平,VDM也存在一些明显的局限,这也为后续研究指明了方向:
-
生成视频时长较短:当时VDM最多只能生成几十帧的视频(约2-4秒),难以满足实际应用中对长视频的需求;
-
计算成本较高:3D卷积的计算量远大于2D卷积,生成高分辨率视频时,对硬件资源的要求较高;
-
时序建模精度有限:虽然解决了基本的时序连贯性问题,但在复杂动作(如人物跑步、物体旋转)的生成上,仍会出现轻微的动作割裂。
六、总结:VDM的启示与后续发展
《Video Diffusion Models》这篇论文,最打动我的地方,在于它的“务实”——没有追求炫技式的复杂架构,而是基于现有技术,做精准的延伸和优化,用最简单的方法解决最核心的问题。它证明了:扩散模型的潜力,不仅在于静态图像,更在于动态视频、3D等更复杂的模态。
从VDM发表到现在,视频扩散模型已经取得了翻天覆地的进步:Latent Video Diffusion通过潜在空间压缩降低了计算成本,DiT-Video用Transformer取代U-Net提升了时序建模能力,CogVideo、DynamiCrafter等模型更是实现了分钟级长视频的生成。但所有这些进步,都离不开VDM打下的基础——它就像一盏灯,照亮了扩散模型进入动态世界的道路。
对于研究者而言,VDM的思路值得借鉴:有时候,解决复杂问题的关键,不是从零创造,而是在成熟技术的基础上,找到适配新场景的核心痛点,做精准的优化和延伸。对于普通用户而言,VDM的意义在于,它让我们看到了“AI生成动态内容”的可能性——如今我们能用到的文生视频工具,背后都有VDM的影子。
如果你想入门视频扩散模型,《Video Diffusion Models》绝对是必读的第一篇论文——它不仅能让你理解视频扩散的核心逻辑,更能让你明白:AI技术的突破,往往藏在“务实的创新”里。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)