如何避免[特殊字符]烧光Token还出错?OpenClaw日志 x AnalyticDB Trace诊断实战
摘要:Gartner预测超40%的AgenticAI项目将因评估体系错位而失败。本文基于阿里云AnalyticDB MySQL的Agent日志分析能力,提出高ROI的解决方案:1、通过SQL引擎实现日志结构化处理,快速定位292次工具调用中的失效链路;2、利用AI函数自动标注15%的高风险任务,发现工具参数幻觉消耗Token量达成功任务3.27倍;3、形成"日志分析-根因诊断-提示优化&
据 Gartner 预测,未来几年将有超过 40% 的 Agentic AI 项目因无法达成商业目标而被取消。核心原因之一:团队构建了错位的评估体系——过度依赖“幻觉率”等通用指标,无法捕获真正导致 Agent 表现失控的根因。而成功交付生产级 Agent 的研发团队做法恰恰相反:大家选择深入剖析底层 Traces,从真实数据中推演出专属评估指标。
在 OpenClaw 时代,Agent Trace 日志记录了用户 Query、模型推理、工具调用及最终输出的完整的物理执行计划。本文借助阿里云瑶池旗下的云原生数据仓库 AnalyticDB MySQL 版(以下简称为ADB MySQL)完整的 Agent 日志可观测能力,在 SQL 引擎里闭环的跑通这套高 ROI 的 Agent 数据工程实践。同时,相比于 Python 代码的单机处理,ADB MySQL 强大的分布式计算和向量化执行引擎能够在秒级完成大规模 Agent 日志 Trace 的复杂解析任务。
1、AnalyticDB MySQL提供的Agent日志可观测能力
在深度拥抱 Agent 的企业里,我们反复看到三层痛点:
-
集体失忆:上下文窗口一清空,排障经验就蒸发,高价值过程无人整理。
-
TokenOps 成本失控:50 万 Token 消耗里,多少是推理,多少在和错误 API 死磕?
-
观测盲区:Agent 时代真正有价值的是 Trace 链路——谁调用了什么工具、结果如何。
ADB MySQL 面向基于 OpenClaw 等 Agent 生态构建了统一的日志分析基础设施,一站式建立从日志采集和语义提取的完整解决方案。
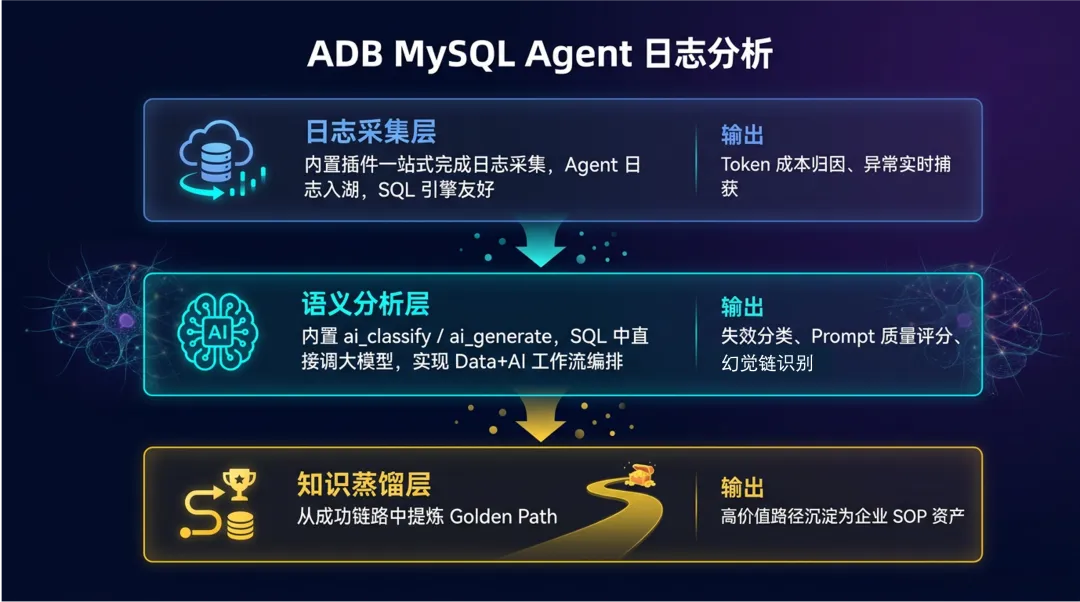
日志采集层,可使用我们提供的OpenClaw for ADB MySQL日志采集上报工具,详见链接:https://click.aliyun.com/m/1000411480/,以下是基于产研团队内部 OpenClaw 日常类似的真实日志数据,来进行实操复现。
2、实战:从原始日志到 Token 归因与 Prompt 优化
Step 1:从非结构化日志提取完整执行链路
Agent 日志是高度非结构化的,首先要将线性日志切分为有业务意义的“任务链”。在 ADB MySQL 中,一个窗口函数即可完成:
WITH TaskBoundaries AS (
SELECT *,
SUM(CASEWHENrole = 'user'THEN1ELSE0END)
OVER (PARTITIONBY session_id ORDERBY row_id) AS chain_id
FROM openclaw_logs.openclaw_sessions
WHEREroleISNOTNULL
),
TaskChains AS (
SELECT
CONCAT(session_id, '_', chain_id) AS unique_chain_id,
GROUP_CONCAT(... ORDERBY row_id SEPARATOR ' >>> ') AS full_trace,
COUNT(CASEWHEN tool_name ISNOTNULLTHEN1END) AS tool_usage_count,
...
FROM TaskBoundaries
GROUPBY session_id, chain_id
)
SELECT chain_id, session_id, tool_usage_count, LEFT(full_trace, 200) AS trace_preview
FROM TaskChains LIMIT5;
执行结果:1484 行日志 → 171 个完整任务链,292 次工具调用。

Step 2:用 AI 函数自动标注失败模式
ADB MySQL 的ai_classify在 SQL 中直接调大模型完成失效分类,ai_generate自动生成根因诊断——零 Python 代码:
WITH TaskBoundaries AS ( ... ), -- 同 Step 1
TaskChains AS ( ... )
SELECT
unique_chain_id,
ai_classify('qwen_max_test', LEFT(full_trace, 600),
'["死循环", "工具参数幻觉", "拒绝执行", "逻辑断裂", "成功解决"]'
) AS failure_label,
ai_generate('qwen_max_test',
CONCAT('你是OpenClaw AI诊断员。分析以下任务链...', LEFT(full_trace, 400))
) AS root_cause_notes
FROM TaskChains
WHERE tool_usage_count > 0 OR last_stop_reason IS NULL OR last_stop_reason != 'stop';
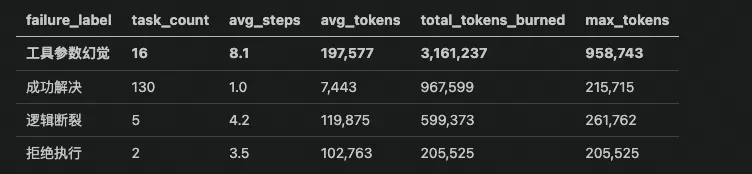
分析结果:15% 的任务链存在失败风险,其中 10.5% 陷入"工具参数幻觉"。100% 的根因指向工具返回数据质量问题(API 密钥缺失、路径越界等),而非模型推理缺陷。

Step 3:量化各失效模式的 Token 消耗
失效模式定义后,下一步量化它——幻觉让我损失了多少 Token,修哪个 Prompt 收益最大?
WITH TaskBoundaries AS ( ... ),
ChainTokens AS (
SELECTCONCAT(session_id, '_', chain_id) AS unique_chain_id,
SUM(IFNULL(total_tokens, 0)) AS chain_total_tokens
FROM TaskBoundaries GROUPBY session_id, chain_id
)
SELECT a.failure_label, COUNT(*) AS task_count,
ROUND(AVG(ct.chain_total_tokens)) AS avg_tokens,
SUM(ct.chain_total_tokens) AS total_tokens_burned
FROM openclaw_logs.t_ai_audit_results a
JOIN ChainTokens ct ON a.unique_chain_id = ct.unique_chain_id
GROUPBY a.failure_label
ORDERBY total_tokens_burned DESC;
结论令人震惊:工具参数幻觉仅占 15% 的任务量,却烧掉了 3,161,237 Token——是全部成功任务总量的 3.27 倍! 单条最高消耗达 958,743 Token。
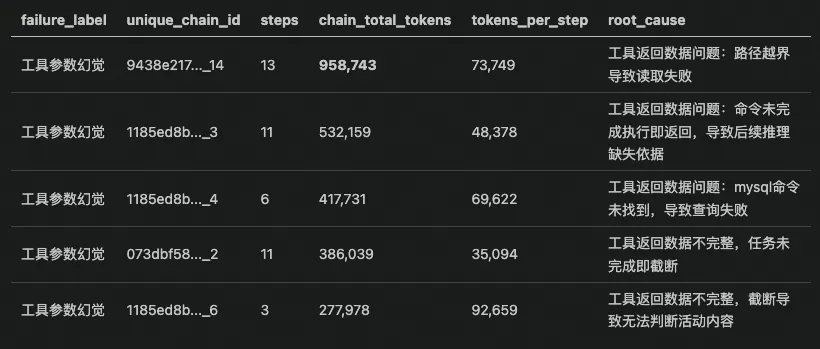
进一步通过 tokens_per_step 下钻,可精准定位每条失败链路的单步消耗密度:
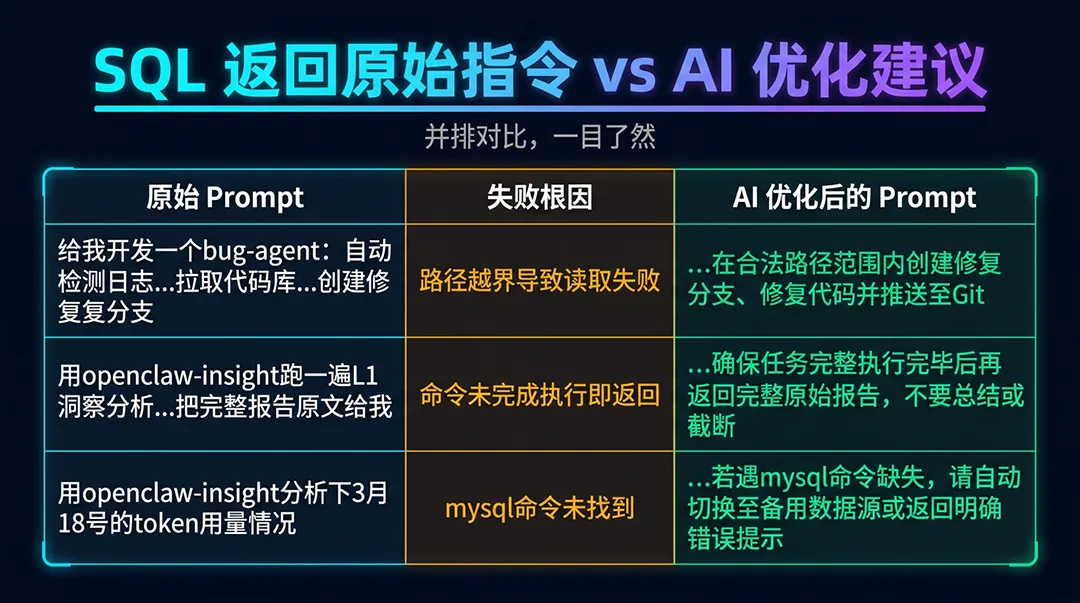
Step 4:基于根因生成Prompt优化建议
Agent 失败分两种:规范失败(指令不清晰)和泛化失败(模型无法应用指令)。最优先动作:先修 Prompt,别急着建评估器。利用ai_generate,一条 SQL 同时提取原始指令和优化 Prompt 做并排对比:
WITH TaskBoundaries AS ( ... ),
ChainTokens AS ( ... ),
FirstUserMsg AS (
SELECTCONCAT(session_id, '_', chain_id) AS unique_chain_id,
SUBSTRING_INDEX(content_text, CONCAT('```', CHAR(10), CHAR(10)), -1) AS original_prompt,
ROW_NUMBER() OVER (PARTITIONBY session_id, chain_id ORDERBY row_id) AS rn
FROM TaskBoundaries WHERErole = 'user'
),
FailedChains AS (
SELECT unique_chain_id, failure_label, root_cause_notes,
ROW_NUMBER() OVER (PARTITIONBY unique_chain_id ORDERBY created_at DESC) AS rn
FROM openclaw_logs.t_ai_audit_results
WHERE failure_label != '成功解决'
)
SELECT fc.unique_chain_id, LEFT(fu.original_prompt, 200) AS original_prompt,
fc.root_cause_notes AS root_cause,
ai_generate('qwen_max_test',
CONCAT('你是Prompt优化专家。...原始指令:', LEFT(fu.original_prompt, 500),
'失败根因:', fc.root_cause_notes)
) AS optimized_prompt
FROM FailedChains fc
JOIN ChainTokens ct ON ...
JOIN FirstUserMsg fu ON ... AND fu.rn = 1
WHERE fc.rn = 1
ORDERBY ct.chain_total_tokens DESCLIMIT3;
3、结语
我们用 4 条 SQL 走完了从原始日志到闭环修复的全链路。
3 个 insight:
-
Agent 的失败是概率性的。 同一条指令 10 次执行可能成功 7 次,每次失败路径不同。传统测试无效,你需要基于统计分布的失效模式分析——SQL 引擎天然擅长。
-
Token 异常是最好的异常检测器。 16 条幻觉链路消耗 310 万 Token,是成功任务总和的 3.27 倍。Token 飙升意味着模型在“打转”,远比规则检测灵敏。
-
AI 可观测性的终局是“闭环”。 数据库充当“反射弧”——失败 Trace 进去,优化 Prompt 出来。封装为定时任务,Agent 就获得了持续运转的免疫系统。
不要把 AI 的命脉交给通用外部指标。 死磕 Trace,围绕真实问题构建专属评估体系——ADB MySQL 把这套工程压缩成了几行 SQL,轻松的嵌入到企业日常的 workflow 里。这为企业提供了一个绝佳的“经验回放缓冲区”,让高价值的 SOP 在 Agent 进行 Bootstrapping 的过程里得以沉淀。欢迎钉钉搜索“173295003853”加入钉群交流。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 1
1 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)