当 AI 开始自己写代码,我更在意的是它到底做了什么
过去一段时间,我在用 OpenCode 写代码的时候,越来越明显地有一个感觉:AI Coding 现在缺的,可能已经不是“它会不会写”,而是“它这次到底是怎么写的”。在 demo 里,AI 工具看起来都很顺。你提一个需求,它吐一段代码,事情好像就结束了。但真到了日常开发里,情况没这么简单。一个任务会有 session 分叉,会不断有 message 更新,会反复调用工具,还可能在不同 agent
过去一段时间,我在用 OpenCode 写代码的时候,越来越明显地有一个感觉:AI Coding 现在缺的,可能已经不是“它会不会写”,而是“它这次到底是怎么写的”。
在 demo 里,AI 工具看起来都很顺。你提一个需求,它吐一段代码,事情好像就结束了。但真到了日常开发里,情况没这么简单。一个任务会有 session 分叉,会不断有 message 更新,会反复调用工具,还可能在不同 agent 之间切来切去。这个时候,终端当然还能看,但它更像是一个结果窗口,不太像一个观察窗口。
你能看到最后输出了什么,但很难很快回答这些问题:
- 这个任务到底经过了几个 session
- 哪一步开始分叉了
- 中间调用了哪些工具
- 哪些内容是流式更新出来的
- 某条异常前后的 payload 到底是什么
- 这次大概花了多少 token 和 cost
而这些问题,恰恰是你真正把 AI Coding 用进真实开发之后,越来越常见的问题。
所以我做了一个 OpenCode 插件,叫 @wentianen/opencode-viewer。
先看一眼界面:
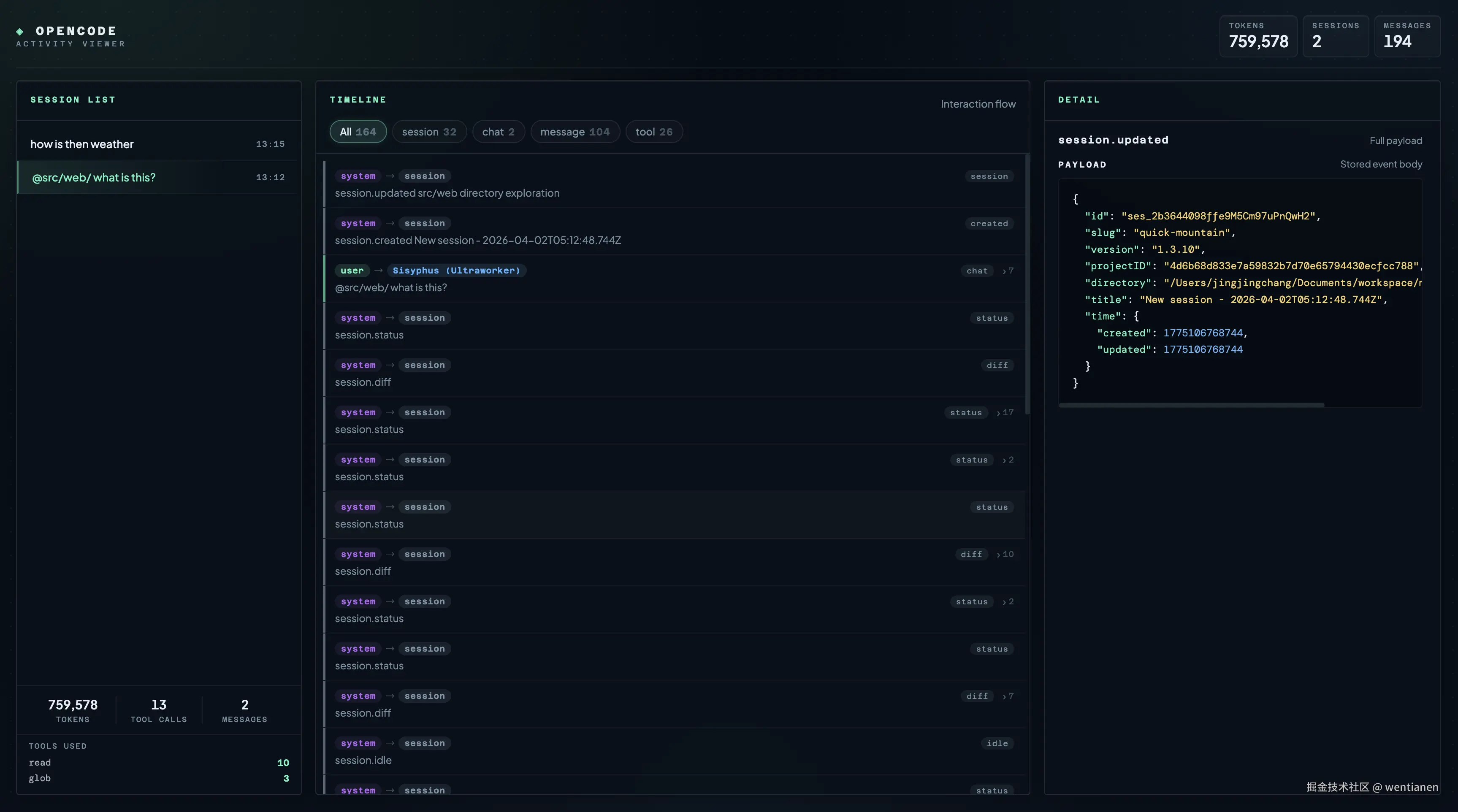
它不是要替代 OpenCode,也不是想把终端再包一层更花的 UI。它更像是给 OpenCode 加了一个“活动观察层”:把本地运行过程中产生的 session、message、tool、chat 这些事件记录下来,然后在浏览器里用一个 Viewer 把它们组织起来。
这件事听起来不复杂,但我觉得很有必要。因为 AI Coding 一旦进入深水区,你需要的就不只是“生成代码”,而是“看清过程”。
opencode-viewer 现在做的事情也很直接。
它会在本地接入 OpenCode 的活动事件,当前已经覆盖了 session.*、message.updated、message.part.updated、message.part.removed、tool.execute.before、tool.execute.after 和 chat.message。这些信息不是只用来看热闹的,它们拼起来,基本就能把一次 agent 执行链路还原个七七八八。
在界面上,我主要做了四块内容。
第一块是 Session List。它不是简单列一个 session id,而是把 session 的层级关系摊开,让你能看到任务是怎么一路分出去的。对于已经开始用多 session、分支协作的人来说,这一点很重要,因为很多问题本来就不是发生在“最后那个结果”里,而是发生在某一次分叉之后。
第二块是 Timeline。这个区域把 chat、message、tool、session 这些记录揉在一条交互流里看,你可以按类型筛,也可以点进具体记录。终端的问题在于它天然是线性的,但 agent 的执行过程其实不是。Timeline 的价值,就是把这种非线性的执行过程,尽量压成一个能读懂的顺序视图。
第三块是 Detail。很多时候你不是不知道“出问题了”,而是不知道“到底哪段 payload 不对”。所以我把原始事件体保留下来,点开就能直接看完整 payload。调工具、看 message 细节、复盘一次异常,这种时候就会很省事。
第四块是 Usage Overview。这个部分会把 tokens、cost、sessions、messages 汇总出来。平时大家都在聊模型能力,但真到长期使用阶段,你迟早会开始关心另外几个问题:这次为什么更贵了,这个任务为什么消息数突然变多了,某个 session 为什么明显更重。到这一步,可观察性就不再是锦上添花,而是实用功能了。
我自己觉得,这个插件至少适合三种场景。
第一种,是你已经开始频繁用 OpenCode 做真实开发,不再满足于“能跑就行”,而是想知道它到底做了哪些动作。
第二种,是你在排查 agent 行为。比如它为什么调了这个 tool,为什么这轮 message 是这样长出来的,为什么某个 session 后面突然开始偏题。这个时候,有一个能回看的 Viewer,比翻终端历史轻松得多。
第三种,是你开始在意成本和复盘。AI Coding 一旦从玩具变成生产力工具,你就会关心 token、cost、消息数量、工具调用频率这些东西。你不一定每天都盯着它们,但当它们异常的时候,你需要一个地方能把原因翻出来。
还有一点我自己比较在意:这个 Viewer 是本地的。
它默认会在本地启动一个 service,然后用浏览器打开页面。日志也是本地落地,不是把你的活动数据扔到远端再给你一个后台看。对这类开发工具来说,我觉得“离你近”很重要。你装上、启动、看结果,整个反馈链路应该尽量短。
如果你想试一下,配置也很简单。把插件加到 opencode.json 里就行:
{
"$schema": "https://opencode.ai/config.json",
"plugin": ["@wentianen/opencode-viewer"]
}
这个配置可以放在 ~/.config/opencode/opencode.json,也可以放在项目根目录的 opencode.json。正常启动 OpenCode 之后,插件会自动安装,并尝试拉起本地 Viewer service。
我并不觉得 AI Coding 接下来的关键,只是“再换一个更强的模型”。至少对已经开始重度使用的人来说,下一步很可能是把 agent 的执行过程看清楚。
很多时候,效率提升不是来自“它又多写了多少代码”,而是来自“你能不能更快弄明白刚才到底发生了什么”。
这也是我做 opencode-viewer 的原因。
如果你也在用 OpenCode,而且已经开始碰到“过程看不清、问题不好复盘、成本没法感知”这些问题,那这个插件大概率会比你想象中更有用。
学习资源推荐
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 1
1 0
0- 0



 已为社区贡献395条内容
已为社区贡献395条内容

所有评论(0)