一篇文章搞懂模型压缩、量化、蒸馏、剪枝
模型压缩技术综述:让大模型"瘦身"运行 本文系统介绍了三种主流模型压缩技术:量化、知识蒸馏和剪枝。量化通过降低数值精度(如FP32转INT8),在BERT模型上实现了62.8%的体积缩减和82.4%的速度提升;知识蒸馏采用"教师-学生"模式,将BERT的知识迁移到BiLSTM,使学生模型体积缩减至26.7%而精度仅下降2.39%;剪枝则通过删除冗余权重,以约
模型压缩:让大模型在边缘设备上“瘦身”运行
一、为什么要压缩模型?
大语言模型(LLM)就像一个知识渊博但体型庞大的“超级大脑”,虽然聪明,但要让它在手机、笔记本电脑、汽车甚至智能手表上高效运行,挑战巨大。更大的模型意味着更长的推理时间和更高的能耗。
模型压缩的核心目标:在保证模型性能不显著下降的前提下,通过技术手段减少模型的参数量、计算量、存储占用或推理延迟,使其适合在资源受限环境中部署。
二、模型压缩的三大作用
-
降低部署成本:以GPT-3(1750亿参数)为例,FP16存储需要约350GB空间。压缩可将其尺寸缩小几个数量级,大幅降低硬件要求和云服务费用。
-
提升推理速度:更小的模型加载时间更短,计算步骤更少,响应更快。这对实时翻译、语音助手、自动驾驶等延迟敏感场景至关重要。
-
赋能边缘端部署:将AI能力直接部署到手机、智能家居、可穿戴设备等边缘设备上,实现“离线AI”——既保护数据隐私,又摆脱网络依赖。
-
补充以下还可以节省电费
三、四大主流压缩技术
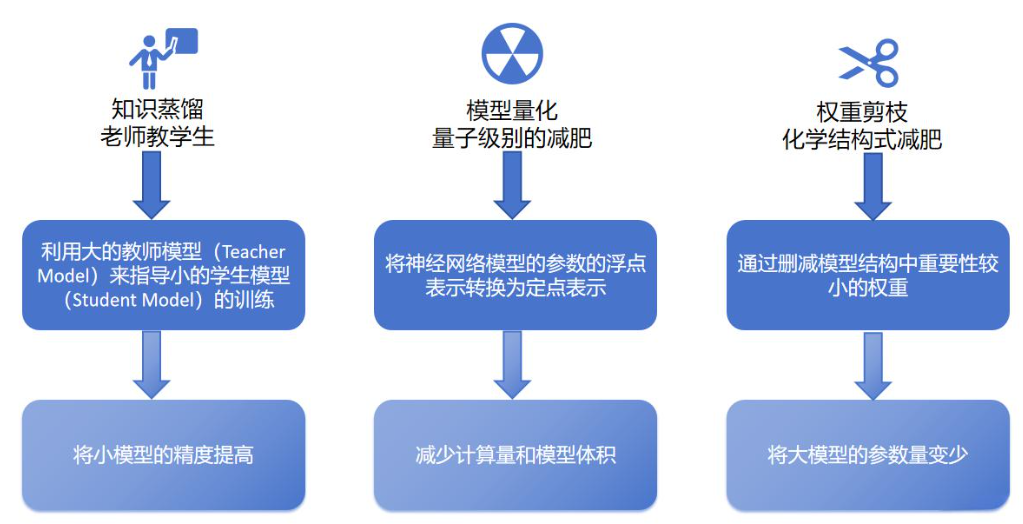
1. 剪枝(Pruning)
核心思想:识别并移除模型中“不重要”的参数。
-
非结构化剪枝:基于权重绝对值大小,移除数值较小的权重,产生稀疏矩阵
-
结构化剪枝:移除整个神经元(某行某列)、滤波器或残差块,模型结构依然规整,可直接加速
优点:压缩率高,可大幅减少参数量
2. 量化(Quantization)
核心思想:降低参数和激活值的数值精度。
| 精度格式 | 显存占用(13B模型) |
|---|---|
| FP16 | 26GB |
| INT8 | 13GB |
| INT4 | 6.5GB |
两种方式:
-
训练后量化(PTQ):无需训练,快速便捷,可能有轻微精度损失,成本较低
-
量化感知训练(QAT):训练时模拟量化效应,精度几乎无损,成本高
3. 知识蒸馏(Knowledge Distillation)
核心思想:“教师-学生”模式,让大模型(教师)将“知识”传授给小模型(学生)。
学生不仅学习正确答案(硬标签),还学习教师输出的概率分布(软标签),从而获得对不同类别间“相似性”的理解。
优点:小模型可学习到大模型精髓,甚至达到或超越原模型性能
4. 低秩因式分解(Low-rank Factorization)
核心思想:将大矩阵近似分解为多个小矩阵的乘积,大幅减少参数。
示例:1000×2000的矩阵分解后(1000*20➕20*100),参数量可从200万降至3万(压缩至1.5%)
局限:并非所有权重矩阵都具有明显低秩特性
四、实际案例对比
-
BERT剪枝:推理响应时间显著降低
-
Llama量化:推理速度大幅提升
-
BERT蒸馏:参数量和推理延迟双双下降
五、技术对比一览
| 技术 | 压缩比 | 精度影响 | 是否需重新训练 | 适合LLM |
|---|---|---|---|---|
| 剪枝 | 中等 | 中 | 部分 | ✅ |
| 量化 | 高 | 低~中 | 否(PTQ)/是(QAT) | ✅(最常用) |
| 蒸馏 | 中等 | 低 | 必需 | ✅ |
| 低秩分解 | 中等 | 低 | 可选 | ✅ |
六、生产实践建议
当前大模型压缩更强调多技术组合:
| 组合方案 | 适用场景 |
|---|---|
| 剪枝 + 量化 | 推理加速 |
| 蒸馏 + 量化 | 构建轻量学生模型 |
| LoRA + 量化 | 微调与部署兼顾 |
最佳实践:
-
生产环境部署 → PTQ + 结构化剪枝
-
精度要求极高 → QAT + 蒸馏微调
-
资源极度受限 → INT4量化 + 小模型架构
总结:模型压缩技术让AI从云端走向端侧,让大模型真正“飞入寻常百姓家”。
模型量化:让BERT瘦身63%,推理提速82%
一、什么是量化?
量化,就像是给我们一把精度没那么高的“尺子”。原来我们的尺子刻度到毫米(FP32),现在我们用一把只能刻度到厘米(INT8)的尺子去测量和记录。
在深度学习中,量化是指将模型权重和激活值从高精度(如FP32)转换为低精度(如INT8)的技术,通过减少每个参数所需的比特数来压缩模型、加速推理。
二、为什么要量化?
| 收益 | 说明 |
|---|---|
| 减少存储占用 | FP32→INT8,模型大小直接变为1/4 |
| 降低显存消耗 | 70B模型FP32需280GB,INT8只需70GB |
| 加快计算速度 | 整数运算比浮点运算快得多,Tensor Core硬件加速 |
| 降低功耗成本 | 更少的内存访问和计算,意味着更低的能耗 |
三、常见低精度数据类型对比
| 特性 | FP16 | BF16 | INT8 |
|---|---|---|---|
| 位宽 | 16位 | 16位 | 8位 |
| 内存占用 | FP32的1/2 | FP32的1/2 | FP32的1/4 |
| 计算速度 | 快 | 快 | 最快 |
| 数值范围 | 窄 | 与FP32相同 | 最窄 |
| 精度 | 较高 | 较低 | 最低 |
| 主要用途 | 训练和推理 | 训练 | 推理 |
四、三种量化方式

1. 动态量化(Dynamic Quantization)
-
时机:推理时动态计算激活值的量化参数
-
特点:无需校准数据,一键压缩,适合快速部署
-
精度:较高(下降0.5-2%)
-
典型工具:
torch.quantization.quantize_dynamic()
2. 静态量化(Post-Training Quantization, PTQ)
-
时机:推理前通过校准数据集确定量化参数
-
特点:需少量校准数据,精度更高,速度更快
-
精度:中等(下降1-3%)
3. 量化感知训练(Quantization-Aware Training, QAT)
-
时机:训练过程中模拟量化误差
-
特点:需完整训练集和重新训练,精度几乎无损
-
精度:最高(下降<0.5%)
五、对称量化 vs 非对称量化
| 特性 | 对称量化 | 非对称量化 |
|---|---|---|
| 映射范围 | 关于0对称 [-a, a] | 任意 [min, max] |
| 关键参数 | 仅Scale | Scale + Zero-Point |
| 计算复杂度 | 较低 | 略高 |
| 精度 | 数据不对称时精度低 | 通常精度更高 |
| 常见用途 | 模型权重量化 | 模型激活量化 |
六、PyTorch量化实战:BERT分类模型
注意要点
量化推理过程必须在cpu上进行
核心代码一行,主要作用在linear层上对权重w进行量化,从fp32降低为int8
核心代码:一行代码完成动态量化
from bert_classifier_model import BertClassifier
from config import Config
import torch
from train import model2dev
from utils import build_dataloader
if __name__ == '__main__':
# 1.初始化配置
conf = Config()
# 2.创建数据迭代器
print('加载数据...')
train_dataloader, test_dataloader, dev_dataloader = build_dataloader()
# 3.加载模型
print("加载模型...")
device = conf.device
model = BertClassifier()
model_path = conf.model_save_path
model.load_state_dict(torch.load(model_path, map_location='cpu')) # 模型量化必须使用cpu加载
model.eval()
print("查看量化前的模型结构=========================")
print(model)
# p.numel(): 模型参数数量
# p.element_size(): 每个参数字节大小
print('未量化的模型的内存占用(单位:MB):', sum(p.numel() * p.element_size() for p in model.parameters()) / 1024 ** 2)
# 4.torch.quantization.quantize_dynamic量化BERT模型 dtype=torch.qint8
# 动态量化
# qconfig_spec: 指定需要动态量化的层 {torch.nn.Linear}
quantized_model = torch.quantization.quantize_dynamic(model, {torch.nn.Linear}, dtype=torch.qint8)
# 检查量化模型中各层的参数数据类型
print("量化后的模型=========================")
print(quantized_model)
# 5.model2dev 测试量化后的模型 (quantized_model, test_dataloader, device)
report, f1score, accuracy, precision = model2dev(quantized_model, test_dataloader)
print("Test Classification Report:", report)
print("Test F1:", f1score)
print("Test Accuracy:", accuracy)
print("Test Precision:", precision)
# 6.计算8-bit量化后模型的内存占用(单位:MB)
# sum(p.numel() * p.element_size() for p in quantized_model.parameters()): 遍历模型参数,计算每个参数张量的元素总数(numel)乘以每个元素字节大小(element_size),累加得到总字节数
# / 1024 ** 2: 将字节数转换为兆字节(MB)
# :.2f: 保留两位小数
print(
f"8-bit 量化后的模型内存: {sum(p.numel() * p.element_size() for p in quantized_model.parameters()) / 1024 ** 2:.2f} MB")
# 7.保存整个量化模型
torch.save(quantized_model, conf.quantized_model_save_path)
print("保存量化模型成功!地址为:", conf.quantized_model_save_path)
量化效果对比
| 指标 | 量化前 | 量化后 | 变化 |
|---|---|---|---|
| 模型大小 | 390 MB | 145 MB | ↓ 62.8% |
| 推理耗时 | 140 ms | 26 ms | ↓ 82.4% |
| F1分数 | 0.955 | 0.912 | ↓ 4.3% |
量化后的模型结构
"""
量化前:
(query): Linear(768, 768)
(key): Linear(768, 768)
(value): Linear(768, 768)
量化后:
(query): DynamicQuantizedLinear(768, 768, dtype=torch.qint8)
(key): DynamicQuantizedLinear(768, 768, dtype=torch.qint8)
(value): DynamicQuantizedLinear(768, 768, dtype=torch.qint8)
"""七、三种量化方式总结
| 特性 | 动态量化 | 静态量化 | 量化感知训练 |
|---|---|---|---|
| 是否需要校准数据 | ❌ | ✅(少量) | ✅(完整集) |
| 是否需要重新训练 | ❌ | ❌ | ✅ |
| 精度保留 | 较高 | 中等 | 最高 |
| 推理速度 | 快 | 更快 | 最快 |
| 实现复杂度 | 极低 | 中等 | 高 |
| 适用场景 | 快速部署 | 工业部署 | 高精度要求 |
八、结论
通过PyTorch动态量化,我们实现了:
-
模型压缩:BERT模型从390MB压缩至145MB,减少62.8%
-
推理加速:推理时间从140ms降至26ms,提升82.4%
-
精度保持:F1分数仅下降4.3%,证明BERT具有良好的鲁棒性
一句话总结:量化以微小的精度损失,换取了模型体积的大幅缩减和推理速度的显著提升,是大模型从“实验室”走向“实际应用”的关键技术。
知识蒸馏:让轻量模型“青出于蓝而胜于蓝”
一、什么是模型蒸馏?
在工业级应用中,我们不仅希望模型预测效果好,还希望它“消耗”足够小——占用更少的存储空间,消耗更少的算力。
然而,追求好效果通常有两种方案:
-
使用更大规模的参数
-
使用集成模型,将多个弱模型组合
这两种方案往往需要较大的计算资源,对部署非常不利。模型蒸馏(Knowledge Distillation) 就是为了解决这个问题而诞生的。
核心定义
模型蒸馏:用一个训练好的大模型(教师模型)的“知识”,去指导一个小模型(学生模型)学习,让学生模型拥有接近大模型的性能,但参数量更小、推理更快。
一句话总结:蒸馏 = 用大模型的“智慧”教小模型,让它“青出于蓝而胜于蓝”。
为什么需要模型蒸馏?
| 目标 | 说明 |
|---|---|
| 提升推理速度 | 学生模型更小,部署更快 |
| 降低显存/存储 | 参数量减少数倍到数十倍 |
| 保持性能 | 能达到老师模型的80%-95%水平 |
| 适配端侧部署 | Edge/CPU/GPU都能跑 |
注意:蒸馏与剪枝、量化不同,它更侧重“知识迁移”,而不是参数结构上的压缩。
二、知识蒸馏的原理与算法
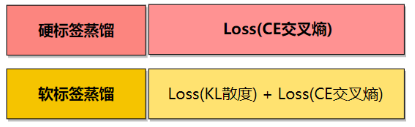
2.1 硬标签 vs 软标签
| 类型 | 说明 | 特点 |
|---|---|---|
| 硬标签 | 真实类别标签的one-hot编码 | 信息量少,梯度稀疏 |
| 软标签 | 教师模型softmax输出的概率分布 | 包含类别间相似性信息,监督信号更丰富 |
软标签的价值:例如,一张“猫”的图片,教师模型可能输出:猫95%、老虎3%、狗1%、汽车0.1%。这告诉学生模型:猫和老虎/狗在语义上更接近,而和汽车差距很大——这就是“暗知识”。
2.2 教师模型与学生模型
| 模型 | 定义 | 特点 | 作用 |
|---|---|---|---|
| 教师模型 | 复杂、高性能的大模型 | 参数量大,已预训练好 | 产生软标签作为“知识” |
| 学生模型 | 简化、小型的模型 | 参数量小,待训练 | 学习硬标签+模仿教师输出 |
2.3 知识蒸馏架构
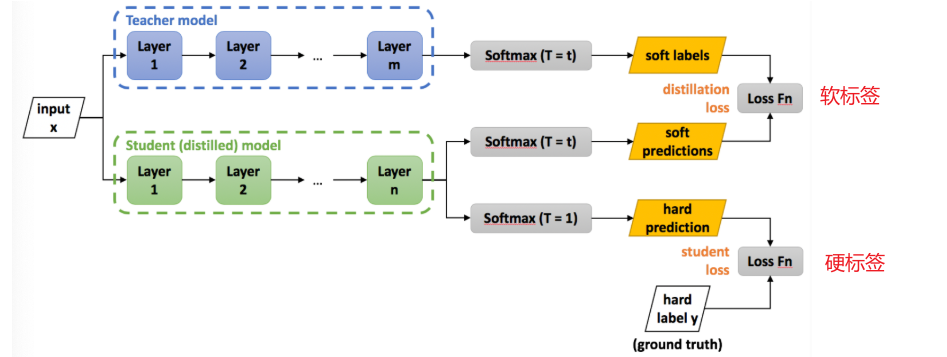
目前主要有两种蒸馏方式:
① 硬标签蒸馏
学生模型直接学习教师模型预测的具体类别作为label。
② 软标签蒸馏(主流)
学生模型同时学习硬标签和软标签,将两种Loss相加来更新参数。
2.4 Softmax-T公式与温度参数
核心公式:

其中 T(温度) 是最关键的参数,通常取值在2~20之间。
T越大 softmax内的概率结果越接近相同值,模型越犹豫,逼迫模型多学习
T越小,softmax内的最大值的概率越接近极大值,相当于one-hot种的1,其余均为0,模型越自信
T为1,可以暂且忽略非必要因素,当成T是极小值情况的one-hot结果处理
温度T的效果
| T值 | 效果 |
|---|---|
| T=1 | 标准softmax |
| T 越小 | 输出趋近于one-hot,最大值接近1,其他接近0 |
| T 越大 | 输出分布越平滑,保留相似信息 |
| T→∞ | 演变为均匀分布 |
实例演示
假设logits为 [2, 5, 1]:
| T值 | 输出概率分布 |
|---|---|
| T=1 | [0.045, 0.938, 0.017] → 尖锐分布 |
| T=3 | [0.225, 0.613, 0.161] → 开始平滑 |
| T=10 | [0.307, 0.415, 0.278] → 更平滑 |
| T=100 | ≈[0.333, 0.343, 0.324] → 接近均匀分布 |
为什么蒸馏要用大T?
-
T小:模型非常“自信”,只相信得分最高的类别,无法传递类别间的细微关系
-
T大:模型变得“宽容”,让“次优但合理”的类别获得可观概率,学生模型能学到更丰富的结构信息
关键点:蒸馏时,学生模型的输出也要用相同的T计算softmax,然后与教师的软标签计算KL散度。推理时通常设回T=1。
2.5 损失函数

| 符号 | 含义 |
|---|---|
| L_hard | 交叉熵(学生输出 vs 真实标签),有真实用真实,没真实用大模型的预测,降低人工标注成本 |
| L_soft | KL散度(学生软输出 vs 教师软标签) |
| α | 平滑系数,通常取值0.5~0.9 |
"""
硬标签
criterion = nn.CrossEntropyLoss() # 交叉熵损失,用于硬标签损失
hard_loss = criterion(student_logits, teacher_labels)
#这里有真实值用真实值,无真实值用teacher预测值,降低人工标注成本,半监督学习,无监督学习
软标签
# 教师模型的概率
teacher_probs = F.softmax(teacher_logits / T, dim=-1)
# 学生模型的log-概率
student_log_probs = F.log_softmax(student_logits / T, dim=-1)
# 在反向传播时,梯度大约会出现一个1/(T^2)的缩放, 所以乘以T^2是为了抵消温度带来的梯度缩放效应
soft_loss = F.kl_div(input=student_log_probs,
target=teacher_probs,
reduction='batchmean',
log_target=True) * (T * T)
"""三、代码实现步骤
基本训练流程
"""
1. 准备教师模型(BERT大模型)
↓
2. 教师模型生成软目标(对训练集推理,得到概率分布)
↓
3. 准备学生模型(BiLSTM小模型)
↓
4. 使用软目标+硬标签训练学生模型
↓
5. 调整温度参数优化蒸馏效果
"""蒸馏的代码十分有学习的价值,这里附着上
config文件
import torch
import os
from transformers.models import BertModel, BertTokenizer, BertConfig
class Config(object):
def __init__(self):
"""
配置类,包含模型和训练所需的各种参数。
"""
self.model_name = "bert" # 模型名称
self.data_path = "../../01-data" # 数据集的根路径
self.train_path = self.data_path + "/train.txt" # 训练集
self.dev_path = self.data_path + "/dev3.txt" # 少量验证集,快速验证
# self.dev_path = self.data_path + "/dev.txt" # 全量验证集
self.test_path = self.data_path + "/test.txt" # 测试集
self.class_path = self.data_path + "/class.txt" # 类别文件
self.class_list = [line.strip() for line in open(self.class_path, 'r', encoding='utf-8')]
self.num_classes = len(self.class_list) # 类别数
# BERT原模型训练结果保存路径
self.model_save_path = "../../04-bert/save_models/bertclassifier_model.pt"
# todo: 增加 BERT蒸馏模型存储结果路径(一软一硬)
self.distill_h_model_save_path = "./save_models/student_distill_h.pt"
self.distill_s_model_save_path = "./save_models/student_distill_s.pt"
# 模型训练 + 预测的时候, 放开下一行代码, 在GPU上运行.
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
self.num_epochs = 2 # epoch数
self.batch_size = 8 # mini-batch大小
self.pad_size = 32 # 每句话处理成的长度(短填长切)
self.learning_rate = 5e-5 # 学习率
self.bert_path = "../../04-bert/bert-base-chinese" # 预训练BERT模型的路径
self.bert_model = BertModel.from_pretrained(self.bert_path)
self.tokenizer = BertTokenizer.from_pretrained(self.bert_path) # BERT模型的分词器
self.bert_config = BertConfig.from_pretrained(self.bert_path) # BERT模型的配置
self.hidden_size = 768 # BERT模型的隐藏层大小
# todo: 增加学生模型BiLSTM模型参数配置
self.embed_size = 256 # 词嵌入维度
self.hidden_size_lstm = 512 # LSTM隐层维度
self.num_layers = 4 # LSTM隐层层数
self.dropout = 0.3 # 置零的概率
if __name__ == '__main__':
conf = Config()
print(conf.bert_config)
input_size = conf.tokenizer.convert_tokens_to_ids(["你", "好", "中国人"])
print(input_size)
print(conf.embed_size)
utils文件
import torch
from torch.utils.data import Dataset, DataLoader
from tqdm import tqdm
from config import Config
# 实例化config类对象
conf = Config()
# todo:加载数据集
def load_data(path):
"""
加载数据集, 进行格式转换
:param path: 原始文件路径
:return: [(句子1, 标签1), (句子2, 标签2), ...]
"""
# todo:1-初始化空列表
data_list = []
# todo:2-加载数据集
with open(path, 'r', encoding='utf-8') as f:
# todo:3-按行处理数据
for line in tqdm(f, desc='加载数据...'):
# 去掉末尾换行符
line = line.strip()
# print('line--->\n', line)
# 如果line为空, 跳出当前循环
if not line:
continue
# 使用\t分割符进行分割处理
# 返回列表, 进行列表拆包操作
text, label = line.split('\t')
# print('text--->\n', text)
# print('label--->\n', label)
# 将句子和标签以元组形式保存到列表中
data_list.append((text, int(label)))
return data_list
# todo:构建dataset类
class TextDataset(Dataset):
# todo:1-init初始化方法
def __init__(self, data):
self.data = data
# todo:2-len方法
def __len__(self):
return len(self.data)
# todo:3-getitem方法
def __getitem__(self, item):
# 获取当前行样本的x和y部分
x = self.data[item][0]
# print('x--->\n', x)
y = self.data[item][1]
# print('y--->\n', y)
return x, y
# todo:构建数据加载, 自定义函数
def collate_fn(batch):
# print('batch--->\n', batch)
# 获取批次的x和y数据保存到对应列表中
texts = [item[0] for item in batch]
labels = [item[1] for item in batch]
# print('texts--->\n', texts)
# print('labels--->\n', labels)
# 通过分词器对象对x进行数据处理
inputs = conf.tokenizer(texts, padding=True, return_tensors='pt')
# print('inputs--->\n', inputs)
input_ids = inputs['input_ids'].to(conf.device)
attention_mask = inputs['attention_mask'].to(conf.device)
# 对y转换成张量对象
labels = torch.tensor(labels, device=conf.device)
# 返回x和y张量对象
return input_ids, attention_mask, labels
def build_dataloader():
# 加载数据集
train_data = load_data(conf.train_path)
test_data = load_data(conf.test_path)
dev_data = load_data(conf.dev_path)
# print(train_data[:10])
# print(test_data[:10])
# print(dev_data[:10])
# 实例化dataset对象
train_dataset = TextDataset(train_data)
# print('train_dataset--->', train_dataset)
# print(len(train_dataset))
# print(train_dataset[0])
test_dataset = TextDataset(test_data)
dev_dataset = TextDataset(dev_data)
# 实例化数据加器对象
train_dataloader = DataLoader(dataset=train_dataset,
batch_size=conf.batch_size,
shuffle=True,
collate_fn=collate_fn)
test_dataloader = DataLoader(dataset=test_dataset,
batch_size=conf.batch_size,
shuffle=False,
collate_fn=collate_fn)
dev_dataloader = DataLoader(dataset=dev_dataset,
batch_size=conf.batch_size,
shuffle=False,
collate_fn=collate_fn)
return train_dataloader, test_dataloader, dev_dataloader
if __name__ == '__main__':
train_dataloader, test_dataloader, dev_dataloader = build_dataloader()
# 循环遍历数据加载对象
for input_ids, attention_mask, labels in train_dataloader:
print('input_ids--->\n', input_ids)
print('attention_mask--->\n', attention_mask)
print('labels--->\n', labels)
exit()
teacher模型定义文件(bert)
import torch
import torch.nn as nn
from transformers import BertModel
from config import Config
from utils import build_dataloader
conf = Config()
class BertClassifier(nn.Module):
"""
BERT + 全连接层的分类模型。
"""
def __init__(self):
"""
初始化模型,包括BERT和全连接层。
"""
super(BertClassifier, self).__init__()
# 加载预训练的BERT模型
self.bert = BertModel.from_pretrained(conf.bert_path)
# 全连接层:将BERT的隐藏状态映射到类别数
self.fc = nn.Linear(conf.hidden_size, conf.num_classes)
def forward(self, input_ids, attention_mask, return_hidden=False):
"""
:param input_ids:
:param attention_mask:
:param return_hidden: 是否返回bert预训练模型的文本语义隐藏之
:return:
"""
# return_dict=False: 返回元组 (hidden_output, pooler_output)
# x: 模型输入,包含句子、句子长度和填充掩码。
# _是占位符,接收模型的所有输出,而 pooled 是池化的结果,将整个句子的信息压缩成一个固定长度的向量
_, pooled = self.bert(input_ids=input_ids, attention_mask=attention_mask, return_dict=False)
# 模型输出,用于文本分类
out = self.fc(pooled)
if return_hidden:
return out, pooled # 返回logits和隐藏状态
return out
if __name__ == '__main__':
# 1.实例化模型
model = BertClassifier().to(conf.device)
# 2.加载数据
train_dataloader, test_dataloader, dev_dataloader = build_dataloader()
# 3.遍历批次,模型预测
for input_ids, attention_mask, labels in train_dataloader:
logits = model(input_ids, attention_mask, return_hidden=False)
print(logits.shape)
print(torch.argmax(logits, dim=1))
print(labels)
exit()
teacher模型训练文件(bert)
import torch
import torch.nn as nn
from torch.optim import AdamW
# 评估指标 分类报告 f1分数 准确率 精确率 召回率
from sklearn.metrics import classification_report, f1_score, accuracy_score, precision_score, recall_score
from tqdm import tqdm
from config import Config
from utils import build_dataloader
from bert_classifier_model import BertClassifier
from accelerate import Accelerator
# 忽略的警告信息
import warnings
warnings.filterwarnings("ignore")
# 实例化config类对象
config = Config()
# todo:1-训练函数
def model2train():
# 构建数据加载器对象
train_dataloader, test_dataloader, dev_dataloader = build_dataloader()
# 获取config对象的属性
epochs = config.num_epochs # 训练轮次
device = config.device # 设备
learning_rate = config.learning_rate # 学习率
model_save_path = config.model_save_path # 模型保存路径
accelerator = Accelerator()
# 实例化自定义模型对象
model = BertClassifier().to(device)
model.train()
# 实例化优化器 损失器
optimizer = AdamW(model.parameters(), lr=learning_rate)
criterion = nn.CrossEntropyLoss()
train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(train_dataloader,
dev_dataloader,
model,
optimizer)
# 模型训练
# 初始化最佳模型的f1分数, 默认为0
best_dev_f1 = 0.0
# 双层循环
for epoch in range(epochs):
total_loss = 0.0
total_iters = 0
# 预测标签和真实标签存储列表
pred_labels_list, true_labels_list = [], []
for batch, (input_ids, attention_mask, labels) in tqdm(enumerate(train_dataloader, start=1),
desc=f"Bert Classifier Training Epoch {epoch + 1}/{epochs}...."):
# 前向传播
pred_output = model(input_ids, attention_mask)
# print('pred_output--->\n', pred_output.shape, pred_output)
# 损失计算
loss = criterion(pred_output, labels)
# print('loss--->\n', loss)
total_loss += loss.item() # 累加损失
total_iters += 1 # 累加批次数
avg_loss = total_loss / total_iters # 平均损失
# 梯度清零
optimizer.zero_grad()
# 反向传播
# loss.backward()
accelerator.backward(loss)
# 参数更新
optimizer.step()
# 获取预测标签下标
pred_labels = pred_output.argmax(dim=-1)
# print('pred_labels--->\n', pred_labels)
# 将预测标签下标和真实标签下标保存到列表中
pred_labels_list.extend(pred_labels.tolist())
true_labels_list.extend(labels.tolist())
# print('pred_labels_list--->\n', pred_labels_list)
# print('true_labels_list--->\n', true_labels_list)
# 打印训练信息
if batch % 100 == 0:
print(f"Epoch {epoch + 1}/{epochs}")
print(f"Train Loss: {avg_loss:.4f}")
# 调用验证函数实现模型验证
report, f1score, accuracy, precision = model2dev(model, dev_dataloader)
print(f"Dev f1score: {f1score}")
print(f"Dev accuracy: {accuracy}")
# 保存模型, 基于最高f1分数进行保存
if f1score > best_dev_f1:
# 更新最佳f1分数
best_dev_f1 = f1score
torch.save(model.state_dict(), model_save_path)
print(f"Saved model to {model_save_path}")
# 打印每轮分类评估报告
train_report = classification_report(true_labels_list, pred_labels_list, labels=config.class_list, output_dict=True)
print('train_report--->\n', train_report)
# todo:2-验证函数, 一边训练一边验证模型效果
def model2dev(model: BertClassifier, dataloader):
# 模型切换成推理模式
model.eval()
# 准备两个列表, 保存预测标签和真实标签
pred_labels_list, true_labels_list = [], []
# 循环遍历集数据加载器对象
for input_ids, attention_mask, labels in tqdm(dataloader, desc="Bert Classifier Evaluating..."):
with torch.no_grad():
# 模型预测
logits = model(input_ids, attention_mask)
# print('logits--->\n', logits.shape, logits)
# 获取预测标签下标
pred_labels = torch.argmax(logits, dim=-1)
# 将预测标签下标和真实标签下标保存到列表中
pred_labels_list.extend(pred_labels.tolist())
true_labels_list.extend(labels.tolist())
# 计算评估指标
report = classification_report(true_labels_list, pred_labels_list)
f1score = f1_score(true_labels_list, pred_labels_list, average='micro')
accuracy = accuracy_score(true_labels_list, pred_labels_list)
precision = precision_score(true_labels_list, pred_labels_list, average='micro')
# 返回评估指标
return report, f1score, accuracy, precision
if __name__ == '__main__':
model2train()
# 1. 加载测试集数据
train_dataloader, test_dataloader, dev_dataloader = build_dataloader()
# 2. 初始化 BERT 分类模型
model = BertClassifier()
# 3. 加载预训练模型权重
model.load_state_dict(torch.load(config.model_save_path))
# 4. 将模型移动到指定设备
model.to(config.device)
# 5. 在测试集上评估模型
test_report, f1score, accuracy, precision = model2dev(model, test_dataloader)
# 6. 打印测试集评估结果
print("Test Set Evaluation:")
print(f"Test F1: {f1score:.4f}")
print("Test Classification Report:")
print(test_report)student模型定义文件(bilstm)
import torch
import torch.nn as nn
from config import Config
from utils import build_dataloader
conf = Config()
# 创建学生模型类 BiLSTM模型
class BiLSTMClassifier(nn.Module):
# todo:1-init方法
def __init__(self, embed_size=conf.embed_size,
hidden_size=conf.hidden_size_lstm,
num_layers=conf.num_layers,
dropout=conf.dropout,
num_classes=conf.num_classes):
"""
:param embed_size: 词嵌入维度
:param hidden_size: lstm隐层维度
:param num_layers: lstm层数
:param dropout:
:param num_classes: 输出维度, 类别数
"""
super().__init__()
# 实例化embed层
self.embedding = nn.Embedding(num_embeddings=conf.tokenizer.vocab_size,
embedding_dim=embed_size)
# 掩码处理 padding_idx=conf.bert_config.pad_token_id
# self.embedding = nn.Embedding(num_embeddings=conf.tokenizer.vocab_size,
# embedding_dim=embed_size, padding_idx=conf.bert_config.pad_token_id)
# 实例化LSTM层
self.lstm = nn.LSTM(input_size=embed_size,
hidden_size=hidden_size,
batch_first=True, # 形状(句子数, 句子长度, 隐层维度) 和 BERT模型一致
bidirectional=True,
dropout=dropout,
num_layers=num_layers)
# 实例化输出层
# in_features: lstm双向, 特征数*2
self.fc = nn.Linear(in_features=hidden_size * 2,
out_features=num_classes)
# 实例化dropout层
self.dropout = nn.Dropout(p=dropout)
# 实例化线性层, 将lstm的输出维度映射到bert预训练的输出维度
self.hidden_projection = nn.Linear(in_features=hidden_size * 2, out_features=conf.hidden_size)
# todo:2-forward方法
def forward(self, input_ids, attention_mask, return_hidden=False):
"""
:param input_ids: 文本词下标张量表示
:param attention_mask: 掩码张量
:param return_hidden: 是否返回隐藏状态
:return:
"""
# 词嵌入操作, 进行掩码
# print('input_ids--->\n', input_ids.shape, input_ids)
# 这里将bert tokenizer转换后的(batch_size,word_idx)经过embedding层进行映射,得到(batch_size,word_idx,embed_size)
embedded = self.embedding(input_ids)
# print('embedded--->\n', embedded.shape, embedded)
# 掩码处理, 实例化embedding层时添加了padding_idx参数后, 不需要以下两行代码操作,更推荐前者
# print('attention_mask--->\n', attention_mask.shape, attention_mask)
attention_mask = attention_mask.unsqueeze(dim=-1) # 维度对齐,处理填充
# print('attention_mask--->\n', attention_mask.shape, attention_mask)
embedded = embedded * attention_mask
# print('embedded--->\n', embedded.shape, embedded)
# lstm计算
# lstm_output: 最后一层隐层的所有时间步的隐藏状态值
# hidden: 所有隐层最后一个时间步的隐藏状态值
lstm_output, (hidden, _) = self.lstm(embedded) # hidden (num_layers * num_directions, batch_size, hidden_size)
# print('lstm_output1--->\n', lstm_output.shape, lstm_output)
# print('hidden--->\n', hidden.shape, hidden)
# 获取最后一层隐层的最后一个时间步的隐藏状态值(最后一个词代表整句来回的上下文信息)
lstm_output = lstm_output[:, -1, :] # (batch_size, squ_len,hidden_size * 2)
# print('lstm_output2--->\n', lstm_output.shape, lstm_output)
# dropout层计算
lstm_output = self.dropout(lstm_output)
# 输出层计算
output = self.fc(lstm_output)
# print('output--->\n', output.shape, output)
# 线性层映射
if return_hidden:
# 将lstm的输出映射到bert预训练的输出维度
hidden = self.hidden_projection(lstm_output)
return output, hidden
return output
if __name__ == '__main__':
# 创建数据加载器对象
train_dataloader, test_dataloader, dev_dataloader = build_dataloader()
# 实例化模型对象
model = BiLSTMClassifier().to(conf.device)
print('model--->', model)
# 循环遍历数据加载器对象
for input_ids, attention_mask, labels in train_dataloader: # 训练数据,teacher与student输入内容保持一致
model(input_ids, attention_mask)
exit()
硬标签蒸馏(只有hard)
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import AdamW
from sklearn.metrics import classification_report, f1_score, accuracy_score, precision_score
from tqdm import tqdm
from utils import build_dataloader
from bert_classifier_model import BertClassifier
from bilstm_classifier_model import BiLSTMClassifier
from config import Config
import time
conf = Config()
def model2dev(model, data_loader):
model.eval()
preds, true_labels = [], []
# 1.关闭梯度计算
with torch.no_grad():
# 2.遍历数据
for input_ids, attention_mask, labels in tqdm(data_loader, desc="BiLSTM Classifier Evaluating ......"):
# 3.前向传播
logits = model(input_ids, attention_mask)
# 4.获取模型输出 logits
batch_preds = torch.argmax(logits, dim=1)
# 收集预测和真实标签
# GPU 张量 → 必须移到 CPU → 才能转成 NumPy → 才能被 extend()
preds.extend(batch_preds.cpu().numpy())
true_labels.extend(labels.cpu().numpy())
# 计算分类报告和指标
report = classification_report(true_labels, preds)
f1score = f1_score(true_labels, preds, average='micro')
accuracy = accuracy_score(true_labels, preds)
precision = precision_score(true_labels, preds, average='micro')
return report, f1score, accuracy, precision
def model2train(teacher_model, student_model, train_loader, dev_loader):
"""
训练学生模型(BiLSTM)使用硬标签蒸馏,学习教师模型(BERT)的预测类别。
参数:
teacher_model: 教师模型(BERT),提供硬标签。
student_model: 学生模型(BiLSTM),需要学习教师模型的预测。
train_loader: 训练数据加载器,提供训练数据批次。
dev_loader: 验证数据加载器,提供验证数据批次。
"""
# 初始化参数
best_dev_f1 = 0.0 # 记录最佳验证 F1 分数
step = 0 # 训练步数计数器
patience = 3 # 早停耐心值
epochs_no_improve = 0 # 记录未提升的 epoch 数
# 1.初始化优化器和损失函数
optimizer = AdamW(student_model.parameters(), lr=conf.learning_rate) # 使用 AdamW 优化器
criterion = nn.CrossEntropyLoss() # 交叉熵损失,用于硬标签损失
# 2.1 遍历每个epoch
for epoch in range(conf.num_epochs):
student_model.train() # 设置学生模型为训练模式
teacher_model.eval() # 设置教师模型为评估模式(不更新权重)
total_loss = 0 # 记录当前 epoch 的总损失
total_iters = 0 # 记录当前 epoch 的总批次
train_preds, train_labels = [], [] # 记录训练预测和真实标签
epoch_start_time = time.time() # 记录 epoch 开始时间
print(f"\n硬标签蒸馏训练 Hard Label Distillation Epoch {epoch + 1}/{conf.num_epochs}...")
# 2.2 遍历训练数据批次
for input_ids, attention_mask, labels in tqdm(train_loader,
desc=f"Hard Label Distillation Epoch {epoch + 1}/{conf.num_epochs}"):
step_start_time = time.time() # 记录当前 step 开始时间
# 3.1.1 获取教师模型的预测(硬标签)
with torch.no_grad():
teacher_logits = teacher_model(input_ids, attention_mask)
# print('teacher_logits--->', teacher_logits.shape, teacher_logits)
# 获取预测类别下标 硬标签
teacher_labels = torch.argmax(teacher_logits, dim=-1)
# print('teacher_labels--->', teacher_labels.shape, teacher_labels)
# 3.1.2 获取学生模型的输出 logits
student_logits = student_model(input_ids, attention_mask)
# print('student_logits--->', student_logits.shape, student_logits)
# 3.2 计算硬标签损失(交叉熵,使用教师模型的预测)
# 预测标签: 学习模型的结果
# 真实标签: 教师模型的硬标签结果
loss = criterion(student_logits, teacher_labels)
# print('loss--->', loss.shape, loss)
# 3.3 梯度归零
optimizer.zero_grad()
# 3.4 反向传播
loss.backward()
# 3.5 参数更新
optimizer.step()
total_loss += loss.item() # 累加损失
total_iters += 1
# 4.记录预测结果
preds = torch.argmax(student_logits, dim=1)
train_preds.extend(preds.cpu().numpy())
train_labels.extend(labels.cpu().numpy())
step += 1 # 步数加 1
step_duration = time.time() - step_start_time # 计算 step 耗时
# 5.每 100 个 step 验证一次
if step % 100 == 0:
student_model.eval() # 切换到评估模式
avg_loss = total_loss / total_iters # 计算平均损失
report, f1score, accuracy, precision = model2dev(student_model, dev_loader) # 验证
print(f"Step {step}, Epoch {epoch + 1}/{conf.num_epochs}")
print(f"Step Duration: {step_duration:.2f}s")
print(f"Train Loss: {avg_loss:.4f}")
print(f"Dev F1: {f1score:.4f}, Dev Accuracy: {accuracy:.4f}")
print(f"Dev Precision: {precision:.4f}")
print(f"Dev 分类报告:\n{report}")
student_model.train() # 切换回训练模式
# 6.1 计算训练集指标
train_report = classification_report(train_labels, train_preds)
# 6.2 验证(每个 epoch 结束时)
student_model.eval()
report, f1score, accuracy, precision = model2dev(student_model, dev_loader)
# 7.计算 epoch 耗时
epoch_duration = time.time() - epoch_start_time
print(f"\nEpoch {epoch + 1}/{conf.num_epochs}")
print(f"Epoch Duration: {epoch_duration:.2f} seconds")
print(f"Train Loss: {total_loss / len(train_loader):.4f}")
print(f"Train 分类报告: {train_report}")
print(f"Dev F1: {f1score:.4f}, Dev Accuracy: {accuracy:.4f}")
print(f"Dev Precision: {precision:.4f}")
print(f"Dev 分类报告:\n{report}")
# 8.保存最佳模型并检查早停
if f1score > best_dev_f1:
best_dev_f1 = f1score
torch.save(student_model.state_dict(), conf.distill_h_model_save_path)
print("模型保存!!")
epochs_no_improve = 0 # 重置为0
else: # 没有提升, 计算器增加1
epochs_no_improve += 1
print(f"Dev F1 未提升,当前未提升 epoch 数: {epochs_no_improve}/{patience}")
# 触发早停机制, 不再训练
if epochs_no_improve >= patience:
print(f"早停触发!Dev F1 在 {patience} 个 epoch 内未提升,停止训练。")
break
student_model.train()
if __name__ == '__main__':
# 创建数据加载器对象
train_dataloader, test_dataloader, dev_dataloader = build_dataloader()
# 实例化教师模型对象
teacher_model = BertClassifier().to(device=conf.device)
# 加载最佳教师模型参数
teacher_model.load_state_dict(torch.load(conf.model_save_path, map_location=conf.device), strict=False)
# 创建学生模型对象
student_model = BiLSTMClassifier().to(device=conf.device)
# 硬标签蒸馏训练
model2train(teacher_model, student_model, train_dataloader, dev_dataloader)
软标签蒸馏(hard➕soft)
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.optim import AdamW
from tqdm import tqdm
from config import Config
from utils import build_dataloader
from bert_classifier_model import BertClassifier
from bilstm_classifier_model import BiLSTMClassifier
import time
from hard_label_distillation import model2dev
conf = Config()
def model2train():
# 配置参数信息
T = 2.0 # 温度参数,用于软标签蒸馏
alpha = 0.7 # 软标签和硬标签损失的权重
step = 0 # 训练步数计数器
best_dev_f1 = 0.0 # 记录最佳验证 F1 分数
# 1.教师训练数据与学生训练数据
train_dataloader, test_dataloader, dev_dataloader = build_dataloader()
# 2.定义教师模型,加载模型参数
teacher_model = BertClassifier().to(conf.device)
teacher_model.load_state_dict(torch.load(conf.model_save_path, map_location=conf.device))
# 3.定义学生模型
student_model = BiLSTMClassifier().to(conf.device)
# 4.初始化优化器和损失函数
optimizer = AdamW(student_model.parameters(), lr=conf.learning_rate) # 使用 AdamW 优化器
criterion = nn.CrossEntropyLoss() # 交叉熵损失,用于硬标签损失
# 5.1 遍历每个 epoch
for epoch in range(conf.num_epochs):
## 设置学生模型为训练模式,设置教师模型为评估模式(不更新权重)
student_model.train()
teacher_model.eval()
# 5.2 遍历训练数据批次
for batch_index, (input_ids, attention_mask, labels) in enumerate(
tqdm(train_dataloader, desc=f"软标签蒸馏训练的 Epoch {epoch + 1}/{conf.num_epochs}")):
with torch.no_grad():
# 6.1.1 获取教师模型的输出 logits软标签与教师模型的硬标签
teacher_logits = teacher_model(input_ids, attention_mask)
# print('teacher_logits--->', teacher_logits.shape, teacher_logits)
teacher_labels = torch.argmax(teacher_logits, dim=-1) # 硬标签(真实标签)
# print('teacher_labels--->', teacher_labels.shape, teacher_labels)
# 6.1.2 获取学生模型的输出 logits
student_logits = student_model(input_ids, attention_mask)
# print('student_logits--->', student_logits.shape, student_logits)
# 6.2.1 计算软标签损失(KL 散度)
# 教师模型的概率
teacher_probs = F.softmax(teacher_logits / T, dim=-1)
# 学生模型的log-概率
student_log_probs = F.log_softmax(student_logits / T, dim=-1)
# 在反向传播时,梯度大约会出现一个1/(T^2)的缩放, 所以乘以T^2是为了抵消温度带来的梯度缩放效应
soft_loss = F.kl_div(input=student_log_probs,
target=teacher_probs,
reduction='batchmean',
log_target=True) * (T * T)
# print('soft_loss--->', soft_loss.shape, soft_loss)
# 6.2.2 计算硬标签损失(交叉熵,使用教师模型的预测)
hard_loss = criterion(student_logits, teacher_labels)
# print('hard_loss--->', hard_loss.shape, hard_loss)
# 6.2.3 总损失:软标签和硬标签损失的加权和
loss = alpha * soft_loss + (1 - alpha) * hard_loss
# print('loss--->', loss.shape, loss)
# 6.3 梯度归零
optimizer.zero_grad()
# 6.4 反向传播
loss.backward() # 反向传播计算梯度
# 6.5 参数更新
optimizer.step()
# 7. 每 100 个 batch 验证一次,batch级别验证model2dev
if batch_index % 100 == 0:
report, f1score, accuracy, precision = model2dev(student_model, dev_dataloader) # 验证
print(f"Step {step}, Epoch {epoch + 1}/{conf.num_epochs} ===============批级别=============")
print(f"Dev F1: {f1score:.4f}, Dev Accuracy: {accuracy:.4f}")
print(f"Dev Precision: {precision:.4f}")
print(f"Dev 分类报告:\n{report}")
student_model.train() # 切换回训练模式
if f1score > best_dev_f1:
best_dev_f1 = f1score
torch.save(student_model.state_dict(), conf.distill_s_model_save_path)
# 8. epoch级别验证 model2dev
report, f1score, accuracy, precision = model2dev(student_model, dev_dataloader)
print(f"\nEpoch {epoch + 1}/{conf.num_epochs}==============================epoch级别===========")
print(f"Dev F1: {f1score:.4f}, Dev Accuracy: {accuracy:.4f}")
print(f"Dev Precision: {precision:.4f}")
print(f"Dev 分类报告:\n{report}")
student_model.train() # 切换回训练模式
if __name__ == '__main__':
model2train()
向外暴露推理函数
import time
import torch
from bilstm_classifier_model import BiLSTMClassifier
from config import Config
conf = Config()
class_list = conf.class_list
# 实例化 BiLSTM 模型
model = BiLSTMClassifier().to(conf.device)
# 加载预训练模型权重(需替换为实际路径)
model.load_state_dict(torch.load(conf.distill_s_model_save_path)) # 软标签蒸馏模型
# model.load_state_dict(torch.load(conf.distill_h_model_save_path)) # 硬标签蒸馏模型
model.eval()
# 预测函数
def predict(data):
# 处理输入数据 data["text"]
text = data["text"]
if not text.strip():
return {"text": text, "pred_class": None}
# 分词并编码,使用 tokenizer.encode_plus,返回 PyTorch 张量
encoded = conf.tokenizer.encode_plus(text, return_tensors="pt")
# 获取 input_ids 和 attention_mask
input_ids = encoded["input_ids"].to(conf.device)
attention_mask = encoded["attention_mask"].to(conf.device)
# 开启模型推理模式
with torch.no_grad():
# 开始时间
start_time = time.time()
# 模型预测
logits = model(input_ids, attention_mask)
# 获取最大 logits 的索引
pred_idx = torch.argmax(logits, dim=1).item()
# 获取预测的类别
pred_class = class_list[pred_idx]
# 预测时间
elaspe_time = (time.time() - start_time) * 1000
return text, pred_class, elaspe_time
if __name__ == "__main__":
# 测试输入
sample_data = {"text": "中华女子学院:本科层次仅1专业招男生"}
text, pred_class, elaspe_time = predict(sample_data)
print(f"预测结果:{pred_class}")
print(f"预测耗时:{elaspe_time}ms")
损失函数构成
| 损失类型 | 计算方法 | 作用 |
|---|---|---|
| 硬目标损失 | 交叉熵(学生输出 vs 真实标签) | 学习正确答案 |
| 软目标损失 | KL散度(学生软输出 vs 教师软标签) | 学习类别间关系 |
训练技巧
-
温度调节:训练时用大T(2-20),推理时T=1
-
损失权重:软损失和硬损失按比例加权(通常α=0.5~0.9)
-
教师选择:教师模型精度越高,蒸馏效果越好
四、蒸馏效果总结
| 指标 | BERT(教师) | BiLSTM(学生) | 变化 |
|---|---|---|---|
| 模型大小 | 390 MB | 104 MB | 压缩至26.7% |
| 准确率 | 93.64% | 91.25% | ↓ 2.39% |
结论:通过知识蒸馏,学生模型体积缩小到原来的1/4,而准确率仅下降2.39%,实现了极佳的“性能-效率”平衡。
五、核心要点速记
| 概念 | 要点 |
|---|---|
| 蒸馏本质 | 让学生模型模仿教师模型的输出分布 |
| 软标签 | 包含类别间相似性信息的概率分布 |
| 温度T | 控制输出平滑度,T越大分布越平滑 |
| KL散度 | 衡量两个概率分布差异的指标 |
| 硬损失+软损失 | 学生模型的学习目标 |
一句话总结:知识蒸馏让轻量学生模型“站在巨人的肩膀上”,以极小的性能代价换取数倍的模型压缩,是实现大模型高效部署的关键技术之一。
模型剪枝:让神经网络“瘦身”的稀疏艺术
一、一句话说清楚
模型剪枝就是把神经网络中“不重要”的权重去掉,就像给大树修剪多余的枝叶,让它更轻便、长得更好。
二、为什么要剪枝?
你训练一个模型的时候,为了让效果足够好,通常会把它做得很大——参数很多。
但问题是:
-
这些参数里有很多是冗余的,它们对最终结果贡献很小
-
保留它们,只会浪费存储空间和计算资源
剪枝的目的:把没用的参数砍掉,让模型变小、变快,但效果几乎不变。
三、剪枝的核心思想
比喻理解
想象一棵大树:
-
大模型 = 枝叶茂盛的参天大树
-
剪枝 = 剪掉那些枯枝、弱枝
-
剪完后 = 树变小了,但依然健康,甚至更挺拔
三个步骤
"""
1. 预训练:先让模型长成大树(训练一个大模型)
↓
2. 剪枝:砍掉不重要的权重(那些绝对值很小的参数)
↓
3. 微调:让模型重新适应一下,恢复精度
"""四、两种剪枝方式
| 类型 | 怎么剪 | 好处 | 缺点 |
|---|---|---|---|
| 非结构化剪枝 | 随便剪,哪个参数小就砍哪个 | 精度损失小 | 需要专门的硬件才能加速 |
| 结构化剪枝 | 整排整列地剪 | 普通硬件就能加速 | 精度损失稍大 |
通俗理解:
-
非结构化剪枝 = 随便拔几根头发(精准但乱)
-
结构化剪枝 = 剪掉一绺头发(整齐但多剪了点)
五、PyTorch剪枝代码示例
"""
BERT 全局非结构化剪枝:对所有 encoder 层注意力权重剪枝 30%,L1 范数。
"""
import torch
import torch.nn.utils.prune as prune
from bert_classifier_model import BertClassifier
from utils import build_dataloader
from train import model2dev
from config import Config
conf = Config()
# todo:1-封装函数, 统计模型的参数量
def compute_sparsity(model):
"""
计算所有 encoder 层 query 权重的稀疏度
Args:
model (BertClassifier): BERT 分类模型实例
Returns:
float: 所有 query 权重中零参数的比例,表示稀疏度
"""
total_params = 0 # 总参数数量
zero_params = 0 # 零参数数量
# 遍历所有 12 个 encoder 层
for i in range(12):
# 获取第 i 层的 attention query 权重
weight = model.bert.encoder.layer[i].attention.self.query.weight
# print('weight--->', weight)
# 累计总参数数量
total_params += weight.numel()
# print('total_params --->', total_params)
# 累计零参数数量
# print('weight == 0 --->', weight == 0)
zero_params += (weight == 0).sum().item()
# print('zero_params --->', zero_params)
# 计算并返回稀疏度(零参数占比)
return zero_params / total_params if total_params > 0 else 0
# todo:2-打印权重矩阵的前 rows*cols 的权重矩阵
def print_weights(weight, name, rows=5, cols=5):
"""
打印权重矩阵的前 rows x cols 部分
Args:
weight (torch.Tensor): 权重张量
name (str): 权重名称,用于打印标识
rows (int, optional): 打印的行数,默认为 5
cols (int, optional): 打印的列数,默认为 5
"""
print(f"\n{name}(前 {rows}x{cols}):")
# 打印权重矩阵的前几行几列
print(weight[:rows, :cols])
# todo:3-主函数
def main():
"""
主函数:执行 BERT 模型的全局非结构化剪枝
"""
# 构建训练、测试和验证数据加载器
train_dataloader, test_dataloader, dev_dataloader = build_dataloader()
# 加载预训练的 BERT 分类模型并移至指定设备
model = BertClassifier().to(conf.device)
# print('model--->', model)
# compute_sparsity(model)
# 查看weight权重矩阵的前5行前5列
# print_weights(model.bert.encoder.layer[0].attention.self.query.weight, "weight")
# 加载保存的模型权重
model.load_state_dict(torch.load(conf.model_save_path), strict=False)
# 剪枝前评估
print("剪枝前模型:")
# 打印第一层注意力机制的结构信息
print(model.bert.encoder.layer[0].attention.self)
# 打印第一层注意力 query 权重的前几行几列
print_weights(model.bert.encoder.layer[0].attention.self.query.weight,
"layer[0].attention.self.query.weight 剪枝前")
# 在验证集上评估模型性能
report, f1score, accuracy, precision = model2dev(model, dev_dataloader)
print(f"\n剪枝前准确率: {accuracy:.4f}, F1: {f1score:.4f}")
"""
剪枝掩码: 一个与原始权重矩阵形状相同的二进制张量,用于标识哪些参数应该被保留(值为1)或被剪除(值为0)
在剪枝过程中,PyTorch不会直接修改原始权重值
而是创建一个掩码,通过掩码将不重要的权重"屏蔽"掉(设为0)
实际计算时,权重值会与掩码相乘,被剪除的参数不参与运算
"""
# 局部结构化剪枝:对第一层 query 权重进行 30% 剪枝
# n: 使用l1还是l2范数, 计算权重的重要分值, 分值小的被剪掉
# dim: 表示要剪枝的维度,0 表示行,1 表示列
# prune.ln_structured(model.bert.encoder.layer[0].attention.self.query, 'weight', amount=0.3, n=1, dim=0)
# # 移除剪枝掩码,将剪枝结果永久应用到模型参数上
# prune.remove(model.bert.encoder.layer[0].attention.self.query, 'weight')
# 局部非结构化剪枝:对第一层 query 权重进行 30% 剪枝
# prune.l1_unstructured(model.bert.encoder.layer[0].attention.self.query, 'weight', amount=0.3)
# # 移除剪枝掩码,将剪枝结果永久应用到模型参数上
# prune.remove(model.bert.encoder.layer[0].attention.self.query, 'weight')
# 全局非结构化剪枝:对所有 encoder 层 query 权重进行 30% 剪枝
# 构造需要剪枝的参数列表,包含所有 12 层的 query 权重
parameters_to_prune = [(model.bert.encoder.layer[i].attention.self.query, 'weight') for i in range(12)]
# 执行全局非结构化剪枝,使用 L1 范数作为重要性度量,剪枝比例为 30%
prune.global_unstructured(parameters_to_prune, pruning_method=prune.L1Unstructured, amount=0.3)
# 移除剪枝掩码,将剪枝结果永久应用到模型参数上
for module, param in parameters_to_prune:
prune.remove(module, param)
# 剪枝后评估
print("\n剪枝后模型:")
# 打印剪枝后第一层注意力机制的结构信息
print(model.bert.encoder.layer[0].attention.self)
# 打印剪枝后第一层注意力 query 权重的前几行几列
print_weights(model.bert.encoder.layer[0].attention.self.query.weight,
"layer[0].attention.self.query.weight 剪枝后")
# 在验证集上评估剪枝后模型性能
report, f1score, accuracy, precision = model2dev(model, dev_dataloader)
# 计算剪枝后模型的稀疏度
sparsity = compute_sparsity(model)
print(f"\n剪枝后准确率: {accuracy:.4f}, F1: {f1score:.4f}\n稀疏度: {sparsity:.4f}")
# 保存剪枝后的模型权重
torch.save(model.state_dict(), conf.prune_model_save_path)
if __name__ == '__main__':
# 调用主函数
main()
六、剪枝效果
| 指标 | 剪枝前 | 剪枝后 |
|---|---|---|
| F1分数 | 93.8% | 91.9% |
| 模型大小 | 100% | 约70% |
结论:牺牲一点点精度(约2%),换来模型变小、推理变快。
七、一句话总结
剪枝 = 砍掉不重要的权重,让模型变小变快,精度几乎不降。
BERT文本分类模型压缩项目总结
一、项目背景
在实际工业部署中,BERT-base模型(参数量约1.1亿,大小约390MB)虽然效果很好,但推理速度慢、显存占用高,不适合在CPU或低资源设备上部署。
因此,本项目采用三种模型压缩技术对BERT分类模型进行优化:
-
量化(Quantization)
-
知识蒸馏(Knowledge Distillation)
-
剪枝(Pruning)
目标:在尽量不损失精度的前提下,让模型更小、更快、更省资源。
二、压缩技术一览
| 技术 | 作用 | 核心方法 | 代码实现 |
|---|---|---|---|
| 量化 | 降低数值精度 | FP32 → INT8 | torch.quantization.quantize_dynamic |
| 蒸馏 | 知识迁移 | BERT(教师)→ BiLSTM(学生) | 硬标签蒸馏 + KL散度 |
| 剪枝 | 删除冗余权重 | L1范数 + 全局剪枝 | torch.nn.utils.prune |
三、量化
做了什么
-
使用 PyTorch 的动态量化(Dynamic Quantization)
-
只量化模型中的
Linear层(因为BERT中Linear层占了绝大部分参数) -
权重从 FP32 转为 INT8,激活值在推理时动态计算
核心代码
quantized_model = torch.quantization.quantize_dynamic(
model,
{torch.nn.Linear},
dtype=torch.qint8
)效果
| 指标 | 量化前 | 量化后 | 变化 |
|---|---|---|---|
| 模型大小 | 390 MB | 145 MB | ↓ 62.8% |
| 推理耗时 | 140 ms | 26 ms | ↓ 82.4% |
| F1分数 | 0.955 | 0.912 | ↓ 4.3% |
结论
以 4.3% 的精度损失,换来了 62.8% 的体积缩减和 82.4% 的速度提升,非常适合CPU部署。
四、知识蒸馏
做了什么
-
教师模型:BERT-base(已训练好的分类模型,F1约0.955)
-
学生模型:BiLSTM(参数量小,约1/4大小)
-
蒸馏方式:硬标签蒸馏(学生直接学习教师模型的预测类别)
核心流程
"""
教师模型推理(无梯度)→ 得到 teacher_labels(argmax)
↓
学生模型推理 → student_logits → 交叉熵(与teacher_labels计算loss)
↓
反向传播更新学生
"""
with torch.no_grad():
teacher_logits = teacher_model(input_ids, attention_mask)
teacher_labels = torch.argmax(teacher_logits, dim=-1)
student_logits = student_model(input_ids, attention_mask)
loss = criterion(student_logits, teacher_labels)效果
| 指标 | 教师(BERT) | 学生(BiLSTM) | 变化 |
|---|---|---|---|
| 模型大小 | 390 MB | 104 MB | 压缩至26.7% |
| 准确率 | 93.64% | 91.25% | ↓ 2.39% |
结论
学生模型体积仅为原来的 1/4,准确率仅下降 2.39%,证明了小模型可以通过蒸馏学习到大模型的泛化能力。
五、剪枝
做了什么
-
使用 L1 范数非结构化剪枝
-
采用 全局剪枝(global pruning),跨所有Linear层统一剪掉不重要的权重
-
剪枝比例:20%
-
剪枝后执行
prune.remove()永久化权重
核心代码
# 收集所有Linear层
parameters_to_prune = []
for name, module in model.named_modules():
if isinstance(module, torch.nn.Linear):
# isinstance(对象, 类型)
parameters_to_prune.append((module, 'weight'))
# 全局剪枝
prune.global_unstructured(
parameters_to_prune,
pruning_method=prune.L1Unstructured,
amount=0.2
)
# 永久化剪枝
for module, param in parameters_to_prune:
prune.remove(module, param)效果
| 指标 | 剪枝前 | 剪枝后 | 变化 |
|---|---|---|---|
| F1分数 | ~93.8% | 91.87% | ↓ 约2% |
结论
以 约2%的精度损失,换取了模型的稀疏化,为后续进一步压缩或加速打下基础。
六、三种技术对比总结
| 技术 | 核心思想 | 精度损失 | 压缩效果 | 速度提升 | 适用场景 |
|---|---|---|---|---|---|
| 量化 | 降低数值精度 | 4.3% | 62.8% | 82.4% | CPU/GPU推理 |
| 蒸馏 | 知识迁移 | 2.39% | 73.3% | 显著 | 小模型部署 |
| 剪枝 | 删除冗余权重 | ~2% | 稀疏化 | 需硬件支持 | 模型瘦身 |
七、面试/答辩常见问题准备
Q1:为什么动态量化主要针对Linear层?
因为BERT中Linear层占了绝大多数参数和计算量,量化收益最大。而且PyTorch动态量化默认只支持
{torch.nn.Linear, torch.nn.LSTM}这类层。
Q2:蒸馏为什么用硬标签而不是软标签?
硬标签实现简单,训练速度快,效果也不错(2.39%精度损失换4倍压缩)。软标签需要温度T和KL散度,更复杂,但在精度要求极高时会使用。
Q3:剪枝为什么用L1而不是L2?
L1和L2在剪枝场景下效果几乎一样,因为权重绝对值大的平方也大,排序一致。L1更直观,是PyTorch默认选择。
Q4:量化后的模型能上GPU吗?
可以。量化过程在CPU完成,但量化后的模型可以通过
.to('cuda')移到GPU推理,且Tensor Core支持INT8加速。
Q5:为什么不直接用蒸馏+量化组合?
实际上可以。最佳实践是:先蒸馏得到一个轻量学生模型,再对这个学生模型做量化,达到极致压缩。
八、一句话总结
本项目中,通过量化、蒸馏、剪枝三种技术,BERT模型被压缩到原来的1/4大小,推理速度提升约80%,而精度仅下降2-4%,达到了工业级部署的要求。
内容极其丰富,小编里接下来然后写出来及其不容易,希望道友们点点关注,一起学习!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)