顶级模型得分低于1%:ARC-AGI-3全新人机较量,揭开智能体真实水平
ARC-AGI-3正式推出,把当前最聪明的智能体扔进一个没有任何说明书的简单像素游戏里,得分连1%都不到。人工智能可以编写复杂的代码,顺利通过各类高难度考试,给人带来一种机器智慧已经比肩人类的错觉。ARC-AGI-3正式推出,把当前最聪明的智能体扔进一个没有任何说明书的简单像素游戏里,得分连1%都不到。ARC-AGI-3通过剥离语言和外部记忆,把行动效率作为唯一标尺,无比清晰地揭开了当前机器智能与
ARC-AGI-3正式推出,把当前最聪明的智能体扔进一个没有任何说明书的简单像素游戏里,得分连1%都不到。
人工智能可以编写复杂的代码,顺利通过各类高难度考试,给人带来一种机器智慧已经比肩人类的错觉。
ARC-AGI-3正式推出,把当前最聪明的智能体扔进一个没有任何说明书的简单像素游戏里,得分连1%都不到。
ARC-AGI-3通过剥离语言和外部记忆,把行动效率作为唯一标尺,无比清晰地揭开了当前机器智能与真正人类适应力之间的巨大鸿沟。
揭开智能的底色
回溯到2019年,人工智能专家François Chollet提出抽象与推理语料库,也就是最初的ARC-AGI-1版本。
该论文主张用获取新技能的效率来衡量通用智能,彻底抛弃单纯比拼特定任务准确率的旧路。
早期的测试采用静态网格任务,解题者只看少量输入输出示例,必须在脑海中推导出一套全新的转换规则。
测试题目最多包含30乘30的网格,使用了10种独特颜色,完全基于客体性或基础几何等核心知识先验。没有任何外部常识,抑或死记硬背的经验,能够帮上智能体的忙。
早期版本的基准有效抵御了让机器在围棋等领域称霸的记忆检索捷径。每道题独一无二,少量示例彻底杜绝了海量数据训练带来的统计模式匹配。
2020年举办的Kaggle挑战赛吸引了913支队伍,冠军方案在私有测试集上拿到20%的准确率,主要依靠暴力程序搜索手工制作的基元库。
在2022年和2023年,Lab42接连举办两场相关赛事,奖金达到100000美元,进一步扩大了国际参与度。
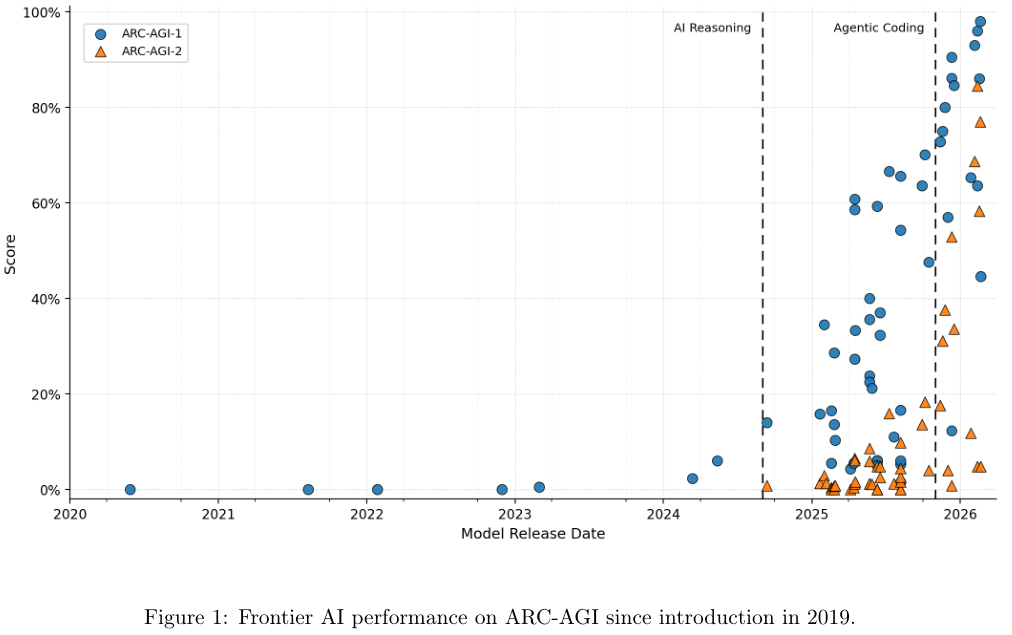
到了2024年,新一届比赛奖金池高达1000000美元,吸引了1430支队伍参与,深度学习方案初露锋芒,测试时训练技术实现突破,得分达到了53.5%。
2025年3月推出的第二代基准增加了多步推理要求,英伟达团队利用合成数据和40亿参数模型拿下24%的胜率,高达85%的大奖门槛依然无人触及。
伴随2017年Transformer架构的问世,预训练规模扩展成为主流研究范式。纯粹依靠堆砌数据和算力,基础大语言模型的能力不断攀升。
2022年出现的思维链提示技术改善了模型的推理表现,顺势开启了测试时适应的新范式,大型推理模型逐渐走入大众视野。
OpenAI推出的o1和o3系统率先在旧版测试中展现出流体智力,让公众见证了前沿AI推理能力的萌芽。
大模型依然存在明显的局限。现代大型推理模型能在代码等特定领域大显身手,前提是基础模型包含充足的相关领域知识储备,并且环境能提供精准的正确性反馈。
人类的推理能力根本不受领域知识束缚。大模型表现出的能力更像是被局限在特定逻辑链条上的机械运作。
收集领域数据和构建验证器成本高昂,2025年底有学者利用自动化系统在量子物理领域发现了新成果,单纯依靠机器实现高效适应并产出颠覆性创新的愿景,依旧相去甚远。
过拟合与记忆捷径同样是不容忽视的隐患。传统模型在训练时学得太多,死记硬背特定特征,导致部署后难以泛化。
前沿模型如今面对看似独立的数据集,依然有办法走捷径。公开训练集和私有测试集分布过于相似时,模型可以通过自动生成数百万个相似任务,用极高的数据密度覆盖目标领域,强行消除对测试时适应能力的依赖。
Gemini 3深度思考版本在验证过程中,推理链条里竟然直接输出了洋红色和绿色等字眼。官方提示词中从没提过颜色映射,模型却能熟练运用,充分暴露了底层模型早已把此类数据的结构特征背得滚瓜烂熟。
未来的评测基准必须完全脱离公开数据的分布,也就是走向分布外测试,方能检验真实的泛化能力。
打造纯粹的试炼场
为准确测量现有人工智能与人类通用智能之间的残余差距,ARC-AGI-3应运而生。新版本将考核重点转向代理智能,采用一套交互式回合制环境,重点考察智能体的四项核心能力。
其一是探索,真实世界里的信息极少主动呈现,智能体必须与环境互动来获取情报。
其二是建模,把原始观察转化为能预测未来状态的通用世界模型。
其三是目标设定,在没有明确指令的环境下,凭借内在驱动和环境线索弄清楚该干什么。其四是规划与执行,准确制定从当前状态到目标的行动路线,并根据意外反馈灵活调整。
测试全程不交代任务目标,也不提供任何说明书。智能体必须自主摸索环境机制和获胜条件。
每个环境分为多个关卡,达到获胜条件才会结束。回合制界面专门为离线推理设计,有意避开了对实时反应速度的考察。智能体每次收到一帧,或者一系列过渡动画,采取一个行动进入下一帧,环境状态绝不会在智能体未操作时自行改变。
视野是一个64乘64的网格,每个单元格有16种可选颜色。操作空间十分精简,仅包含5个方向或功能键,外加1个撤销键,以及1个点击网格单元格的坐标选择动作。简化的操作排除了控制难度,把核心挑战牢牢锁定在环境逻辑上。
一次行动被严格定义为向环境发送指令,并成功改变状态的回合。模型内部的工具调用或重试不计入行动次数。

为了批量打造高质量环境,研发团队搭建了内部游戏工作室,采取流水线作业。
开发人员写出概念说明,团队共同审查,接着制作原型并进行内部试玩,随后引入外部人员测试,达标后才算定稿。最初团队尝试用Unity引擎开发,发现其过于笨重,迭代速度太慢,最终改用Python自行编写了定制环境引擎,确保最低性能达到每秒1000帧。
所有环境强制遵循核心知识先验原则,绝不使用数字,字母,红绿灯或花朵等文化符号,确保只测试先天的推理能力。
客体性,基础几何形态,拓扑关系,重力,动量以及意图识别,成为仅有的环境规则来源。
环境设计必须新颖,既要区别于现有电子游戏,也不能跟题库里的其他题目撞车。难度递进依靠概念组合,后期关卡需要融合前期学到的多种机制。每个环境至少包含6个关卡,首关通常是极易上手的教程关。研发团队坚决抵制仅靠单一机制,单纯放大规模来增加难度的做法。
自动验证环节为环境质量把关。首轮随机运行50000步,排查意外通关的漏洞。次轮扩展到1000000步,确保非教程关卡在随机瞎按的情况下绝对无法通关。
系统还会构建有向图来探索状态空间,把重复的模拟转化为紧凑的图结构,精确计算获胜概率,要求随机策略通关的概率必须低于10000分之1。

完整数据集依据公开程度,被严谨地切分为三个功能各异的子集。

与前代版本10比1的公私比例截然不同,新基准完全以私有集作为评估核心。公共集转变为单纯的演示窗口,极大地降低了针对性优化的风险。
效率是真正的标尺
在新版本基准的理念里,智能从根本上等同于效率。高智能系统不仅能解决问题,还能把资源消耗降到最低。
无论探索数据,计算时间还是承担风险,最终统统被折算成一个标量化指标,即行动效率。
通过计算初次接触新环境并通关所消耗的回合数,直接衡量探索与执行的综合表现。盲目试错会被严厉扣分,行动越少,暴露在环境危险中的几率就越低,正好也方便拿来跟人类的行动基准直接对比。
计分系统采用相对人类行动效率指标。
具体规则十分严谨,计算公式会比较AI耗费的行动数和人类基准。人类基准被定义为所有参与测试的人类中,行动数第二少的成绩,排除了极个别天才的异常值。假设第二快的人类用了10步,AI用了100步,比值就是10除以100。
系统采用幂律计分法则,将该比值平方,最终此关卡AI得分为1%。大幅拉开低效方案和接近人类水平方案的分数差距,严厉惩罚低效表现。
分数的汇总按关卡独立进行,防止单关成绩被过长关卡淹没。
为避免AI利用单个关卡的机制漏洞刷出超高分,单关效率得分设置了1.0倍人类基准的上限。另外配有关卡权重机制,难度更高的后期关卡得分占比更大。以5关环境为例,第一关占总分的15分之1,第五关占15分之5。
各关卡加权平均得出环境得分,所有环境得分汇总求平均值,最终得出0%到100%的总分。此种计分方式深受机器人导航领域中路径长度加权成功率指标的启发。
官方排行榜的设计极度警惕过拟合。任何针对公共环境特制的程序外壳或硬编码策略,都有可能在公共集上拿满分,完全无法反映系统在未知领域的真实智能水平。
排行榜严格剔除经过专门准备的系统,只评估通过通用API接入的基础模型。官方仅提供一段简单的提示词,告诉模型它在玩一个游戏,目标是获胜,并要求回复具体动作。
考虑到高推理前沿模型单次运行的API成本高昂,系统强制设定了上限,达到人类平均步数的5倍后就会被切断。
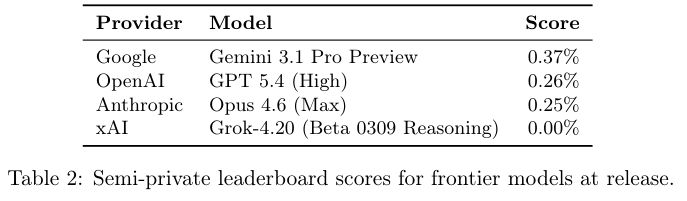
最新测试中,前沿模型的表现令人遗憾。在半私有排行榜上,表现最好的模型依然难以突破1%。
为了鼓励社区进行任务自动化创新,官方同时维护了一个基于自述成绩的社区排行榜。
虽说特定定制的程序外壳不足以代表通用智能的进步,那些优秀的上下文管理和任务编排思路,未来极有可能被直接整合进下一代基础模型内部。
真实的较量
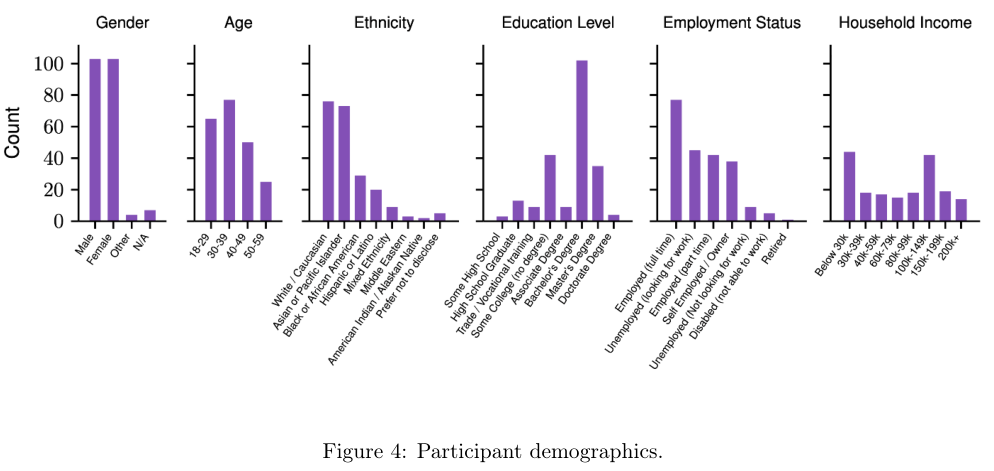
为了确立人类基准,研发团队在旧金山的专门测试中心开展了高频次的线下评估。能够纳入基准库的环境,必须保证至少有两名完全没受过特殊训练的普通人能独立通关。
参与者每人可获得115至140美元的出场费,每通关一个环境还能额外拿到5美元奖励。
总计486名背景各异的参与者完成了2893次环境挑战,累计耗时427.9小时。
每次挑战时长通常限制在30分钟以内。成功通关的玩家耗时中位数为8.1分钟,失败尝试的耗时中位数为5.9分钟。
大量真实的影像回放和按关卡统计的完成率数据,帮助团队反复剔除那些机制含糊或难度飙升的不合理设计。
人类效率的衡量包含三个参照点,分别是最优解估算值,单关最佳表现组合,以及作为计分标准的人类基准。
在正式发布前,官方通过代理预览赛收集了早期反馈。
2025年8月的比赛中,Tufa实验室的方案拿下12.58%的成绩位居榜首,采用卷积神经网络结合强化学习,分析64乘64像素帧的变动。
排名第二的盲松鼠方案拿到6.71%的分数,依靠观察帧构建有向状态图。前列方案普遍采用启发式搜索,尽可能多地试探动作空间,以期碰上正确组合。
学术界也贡献了精彩的探索。
杜克大学团队敏锐察觉到上下文管理的瓶颈,64乘64的像素网格极耗上下文额度,便编写程序让大模型选择性提取历史动作状态,在三个公共环境里跑出了媲美人类的出色效率。
Symbolica AI团队采用协调器加子代理架构,顶层协调器不直接接触环境,依靠专业子代理返回压缩后的文本摘要,巧妙规避了上下文超限的问题。
新一届ARC挑战赛将于2026年继续在Kaggle平台展开,公开悬赏总奖金池高达2000000美元。
前路漫漫,挑战依然艰巨。在有限的时间和步数内,人类总能凭借直觉和适应力拨开迷雾,现有的AI系统却在假设修正,不确定性规划和高效探索上接连碰壁。
作为少有的未被攻克的智能体测试基准,该项人机较量才刚刚拉开帷幕。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 0
0 0
0- 0



 已为社区贡献253条内容
已为社区贡献253条内容

所有评论(0)