Ada-MSHyper: Adaptive Multi-Scale Hypergraph Transformer for Time Series Forecasting
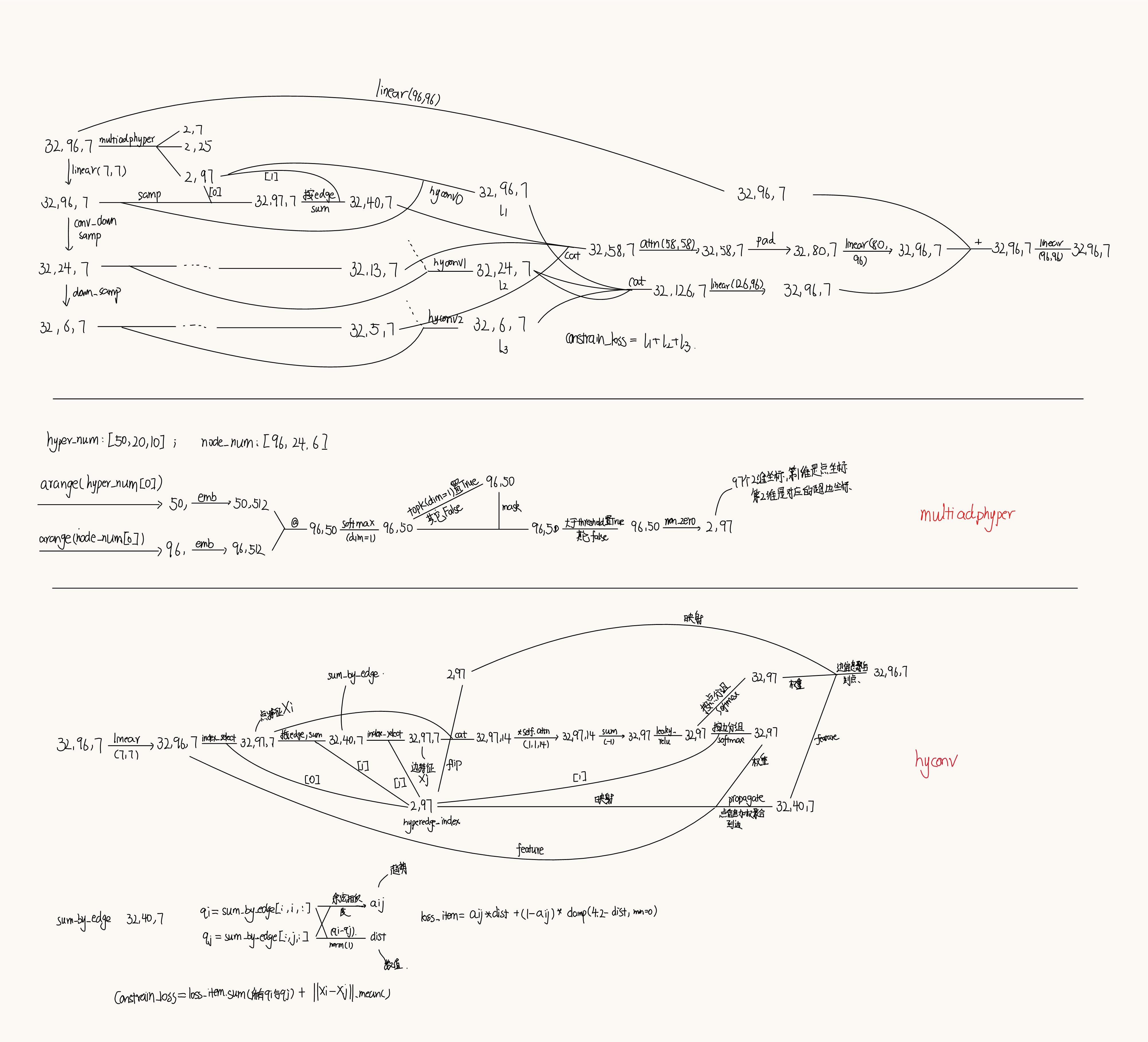
- multiadphyper做了什么:根据各个尺度的超图尺寸得到点边矩阵(先验,与输入无关),之后topkmask以及二值化处理,最终得到各个尺度下相似度分值较高的点边向量(2,97)
- hyconv做了什么:用一个不带可训练参数的"点–>超边,超边–>点"的超图两跳传播,先将点的信息聚合到自己所在的超边上,这相当于分类操作,再将超边信息回流到点上,此时同组点信息就会被均质化,因为来自同一个超边。这么做的核心含义是实现“类内紧、类间分”。此外,hyconv得到的损失也是为了辅助实现“类内紧、类间分”的效果,详细见下Q&A。
- 数据流图的“32,96,7–>32,97,7–>32,40,7”各个张量的含义:"32,96,7"该尺度的输入;"32,97,7"根据点边关系(2,97)得到的点特征集合;"32,40,7"根据点边关系聚合(sum)点的关系到边,得到的边特征集合
- 其实Ada-MSHyper每个时间点作为一个node,之后聚类到边,我认为就是为了解决“单点信息量过少”的问题。时序预测中分块已被证明有效,而作者的做法类似于一种自适应长度的分块,并使用对比损失,使得相似块的特征拉近,不相似块的特征拉远(作为一个分支)。
Q&A
-
Ada-MSHyper引入了一种NHC机制,分别对具有相似语义信息的节点进行聚类,并区分每个尺度内的时间变化。什么是NHC机制
NHC(Node and Hyperedge Constraint):在超图学习阶段加入的节点与超边约束机制,目的有二:1. 节点约束(Node Constraint):鼓励同一超边内语义相近的节点被聚在一起。具体做法是比较节点表示与其所属超边的聚合表示的“语义相似差异”,最小化该差异的损失,从而抑制把不相似的节点硬拉到同一组里的噪声。2. 超边约束(Hyperedge Constraint):在超边–超边空间上,同时利用余弦相似与欧氏距离:相似度高(余弦大)的两条超边应更近;相似度低(余弦小)的两条超边应至少相隔一个间隔(margin),即距离不足时施加惩罚(推远)。通过这种“拉近相似、推远不似”的对比式损失,区分同一尺度内不同的时间变化形态(上升/下降/震荡等),缓解“尺度内变化纠缠”。 -
NHC机制的节点约束具体体现在结构的哪里
constrain_loss = (x_i - x_j).mean().abs() + loss_hyper作为辅助损失,其中(x_i - x_j).mean().abs()属于节点约束,x_i:边上的节点特征(节点→超边的源端);x_j:同一条边所指向的超边特征(由该超边包含的节点聚合得到,并广播回边上)。它惩罚“节点表示”与其“所属超边表示”的差异,鼓励同一超边内部的节点语义一致。由于超边聚合了相似节点的特征,所以说其实这个的本质含义就是将该节点与其所属聚类中心对齐 -
NHC机制的超边约束具体体现在结构的哪里
aij = inner / (ni * nj) # 余弦相似 dist = (qi - qj).norm(dim=1, keepdim=True) loss_item = aij * dist + (1 - aij) * (torch.clamp(torch.tensor(4.2, device=device) - dist, min=0.0))qi,qj,ni,nj为第i号边和第j号边的特征(以及对应的模),loss_item作为超边约束,其作用是对于余弦相似度(aij)较高的i和j号边,拉近它们的距离,对于相似度较低的边,推开它们的距离。余弦相似(aij)更多体现的是两个超边的“形似”,而欧氏距离(dist)更多体现“值似”。那么超边约束起到的作用其实是:“形似的两组超边应该更加值似,应该推近,形不似的两组超边应该更加值不似,也因此应该推远”。这样做其实是:属于一类(余弦相似度高)的两个超边,特征值应该尽可能接近,属于不同类的两个超边,特征值应该尽可能远离。这就实现了“类内紧、类间分”,类内紧和类间分能够区分同一尺度内不同的时间变化形态(上升/下降/震荡等),缓解“尺度内变化纠缠”。这也是作者着重解决的问题之一。此外hyconv用一个不带可训练参数的"点–>超边,超边–>点"的超图两跳传播,先将点的信息聚合到自己所在的超边上,这相当于分类操作,再将超边信息回流到点上,此时同组点信息就会被均质化,因为来自同一个超边。这么做的核心含义是实现“类内紧、类间分”。
-
hyconv的结构以及损失都是为了实现聚类,但是类内紧同样可能带来“过平滑”的问题,也就是类内的点直接缺少了区分度从而丢失信息,作者是怎么解决这个问题的
hyconv的结果只是其中一个分支,除了hyconv外,还有两个分支:边信息分支(32,58,7);原始输入分支(最上边经过linear的)。这些残差链接保证了信息的不减少。 -
作者原文想要建模时间点间丰富且隐含的交互,不依赖固定窗口和预定义规则,作者的意思应该是构造一个与输入有关的多尺度超图,但是在代码实现中却是对arange(node_num)以及arange(hyper_num)进行了embedding,也就是与输入无关,这是为什么
hypidxc = torch.arange(self.hyper_num[i], device=device) nodeidx = torch.arange(node_num[i], device=device) hyperen = self.embedhy[i](hypidxc) # [H_i, d] nodeec = self.embednod[i](nodeidx) # [N_i, d]作者选择的“与输入无关”的超图构造更多的是带来数据集级别的先验,所以本质上是一种可学习的全局规则。可能是与完全输入related的效果不好。
-
数据流图可以看到三个分支,其中一个节点→超边做了一次无权重的聚合后送入注意力作为单独的一个分支,并由linear预测到 (32,96,7),还有一个分支是hyconv分支。我不是很理解,因为hyconv分支后得到的其实就是“类内均质化,类间差异化”的点特征(或者说是该点对应的边特征,因为点特征由边特征聚合过来,也可以看作是边特征),而无权重聚合分支也是点聚合得到了边特征。这两个我认为做的事情是差不多的,为什么要两个分支
我的理解是,在于是否有注意力操作,无权重聚合后加了注意力操作,来对各个尺度的超边(也就是原型或者类)进行交互,而hyconv分支没有超边交互(类交互)。有意思的是,作者使用的注意力操作并没有残差连接,也就是将score*V直接作为结果,此时,注意力就相当于做了一个筛选的操作,选择对预测帮助大的类特征进行增强,对预测帮助小的类特征进行抑制。 -
为什么hyconv称为“超图卷积注意力”,注意力体现在哪里,卷积体现在哪里
注意力:输入(32,97,14)经过可学习self.attn得到(32,97,14),之后softmax得到分数score,并作为权重加权聚合…。这种“打分–>加权聚合”就是一种注意力;卷积:作者指的是谱卷积,就是整个hyconv,不用特意了解。 -
self.att的shape是(1,1,14),是在channel维度进行操作,那么先*self.att再sum(-1)的做法是在干什么
相当于linear(14,1),也就是对某个点进行整体打分,去掉channel维度

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 10
10 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)