Agent 上下文管理
Agent 上下文管理
目录
LLM 每次调用都是无状态的。它不记得你上一轮说了什么,除非你把之前的对话历史重新发给它。Agent 框架做的事情,就是维护一个 messages 数组,每轮对话都把完整历史发给模型。
回到 AgentLoop 的核心结构:
messages = [{"role": "user", "content": user_input}]
while True:
response = call_llm(messages)
messages.append(response)
if not response.has_tool_use():
break
result = execute_tool(response)
messages.append(result)
每一轮循环,messages 都在增长。用户输入、模型回复、工具调用、工具结果,全部堆积在里面。假设一轮对话产生 4 条消息,每条平均 500 token,那 20 轮下来就是 40000 token。而且每一轮 API 调用,都要把这个 40000 token 的数组完整发送一遍——前面的内容反复发送,后面的内容不断累加。
问题来了:模型的上下文窗口是有限的。 Claude 的上下文窗口是 200K token,听起来很大,但一个复杂的编码任务,读几个文件、跑几次测试、来回改几轮代码,很容易就会逼近上限。一旦超出,只能报错,或者被迫丢弃早期消息,而那些消息里可能包含你最初的需求描述和关键设计决策。
上下文管理要解决的就是这个问题:在有限的窗口里,让模型始终看到最有价值的信息。
上下文是什么
在讨论管理策略之前,先搞清楚上下文到底由哪些部分组成。
每次调用 LLM API,发送的内容大致是这样的:
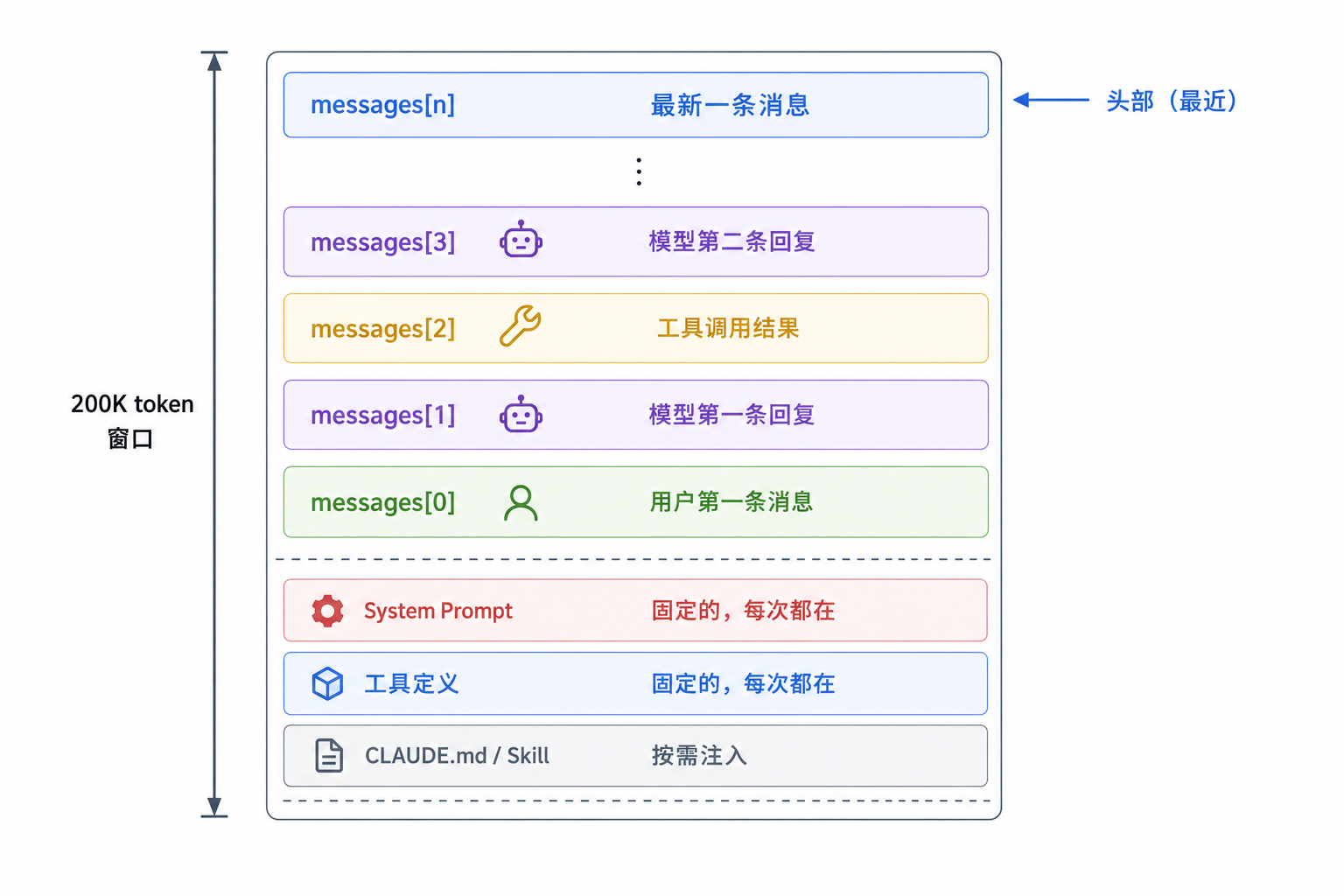
System prompt 和工具定义是固定开销,通常占几千到一两万 token。真正快速增长的是 messages 数组——也就是对话历史。
对话历史是上下文里的大头,而且它的增长是线性的:每多一轮对话,就多几条消息,每条消息几百到几千 token。跑个十几轮,对话历史就能占据大半窗口。
工具输出是另一个容易被忽略的大头。Agent 读一个文件,几百行代码全部塞进上下文;跑一个测试,控制台输出可能几千行。这些原始数据里可能只有一小部分对决策有用,但全部都要算 token。
上下文都去哪了
来看一个具体例子。你让 Agent 帮你实现一个用户注册模块,它需要读现有代码、写新代码、跑测试。假设跑了 10 轮:
轮次 操作 新增 token(估算)
──────────────────────────────────────────────────────
1 用户输入需求 ~100
2 Agent 读了 3 个文件 ~3000(文件内容)
3 Agent 写了注册代码 ~800
4 Agent 跑测试,输出测试日志 ~2000
5 测试失败,Agent 读错误日志 ~1500
6 Agent 修改代码 ~600
7 Agent 再次跑测试 ~2000
8 测试通过,Agent 读了另一个文件 ~1500
9 Agent 做了一些重构 ~1000
10 Agent 输出最终总结 ~300
──────────────────────────────────────────────────────
累计 ~12800 token
这只是一个相对简单的任务。如果任务更复杂,比如涉及多个模块、需要反复调试、中间有大量试错,token 消耗会轻松翻几倍。而且每一轮 API 调用,都要把这 12800 token 的历史完整发送一遍。第 10 轮调用时,第一轮的需求描述已经离"头部"很远了,但它依然占着 token。
更要命的是,早期那些消息里包含了大量"过程性"信息——测试失败的堆栈、读文件的原始输出、中间版本的代码。这些在任务完成后对模型决策几乎没有帮助,但它们一直待在那里,挤占空间。
所以问题的本质是:不是上下文不够大,是里面塞了太多"没用的东西"。 管理上下文的核心,就是决定什么该留、什么该扔、什么该压缩。
上下文压缩
最直接的策略:当对话历史太长时,自动压缩它。
Claude Code 内置了一个叫 auto-compact 的机制。当 token 用量逼近窗口上限时,它会自动触发压缩,把早期的对话历史做一次总结,用一段精炼的文本替代原来的大段消息。
压缩前:
messages[0]: 用户需求(100 token)
messages[1]: Agent 读文件 A 的完整内容(2000 token)
messages[2]: Agent 读文件 B 的完整内容(1500 token)
messages[3]: Agent 的分析(400 token)
messages[4]: 工具调用结果(800 token)
messages[5]: Agent 修改代码(600 token)
messages[6]: 测试输出(2000 token)
...
压缩后:
messages[0]: "用户要求实现注册模块。已读取文件 A(UserService.java)和文件 B
(UserController.java)。第一版代码已写好,测试失败原因是参数校验
逻辑有误,已修复并通过测试。"(~150 token)
messages[n-2]: 最近的几条消息(保留原始内容)
messages[n-1]: 最新消息
原来几千 token 的历史,被压缩成了一小段摘要。模型依然知道之前发生了什么,但不需要看那些冗长的原始数据。
压缩本质是用模型的理解能力换 token 空间。让模型读一遍早期消息,提炼出关键信息,用更少的文字表达同样的意思。代价是丢失一些细节,但对于大多数任务来说,那些细节本来也不需要了。
实际使用中,你可以在 Claude Code 里手动触发压缩:输入 /compact 就会执行一次。或者等它自动触发:当 token 用量超过 80% 时,Claude Code 会主动压缩。
上下文隔离
压缩解决的是"消息太长"的问题,但有一种情况压缩也帮不了:当 Agent 需要同时处理多个子任务时,所有子任务的中间过程都堆在同一个上下文里,互相挤占空间。
这就是 SubAgent 要解决的问题。
回忆一下 SubAgent 的核心思路:主 Agent 不亲自执行复杂子任务,而是派一个"下属"去做。这个下属有自己的上下文,干完活只把结论交回来,中间过程自己消化掉。
主 Agent(上下文保持精简)
│
├── SubAgent A → 独立上下文,执行完只返回结论
├── SubAgent B → 独立上下文,执行完只返回结论
└── SubAgent C → 独立上下文,执行完只返回结论
来看一个对比。不用 SubAgent 的情况下,主 Agent 自己去读 5 个文件、写代码、跑测试:
主 Agent 上下文:
[用户需求]
[读文件 A 的完整内容] ← 2000 token
[读文件 B 的完整内容] ← 1500 token
[读文件 C 的完整内容] ← 1800 token
[Agent 分析]
[写代码]
[测试输出] ← 2000 token
[修改代码]
[再次测试输出] ← 2000 token
[最终结论]
总计:~12000 token
用 SubAgent 的情况下,主 Agent 把"实现注册模块"这个任务派给 SubAgent:
主 Agent 上下文:
[用户需求]
[SubAgent 返回的结论] ← 200 token
总计:~500 token
SubAgent 上下文(独立的,执行完就销毁):
[任务描述]
[读文件 A/B/C]
[写代码]
[测试输出]
[修改代码]
[再次测试]
[结论]
主 Agent 的上下文从 12000 token 降到了 500 token。那些文件内容、测试输出、代码迭代,全部留在 SubAgent 自己的上下文里,不会污染主 Agent。
SubAgent 同时做了两件事:隔离(中间过程不回流到主 Agent)和压缩(只返回精炼结论,不返回原始数据)。
上下文按需加载
前面讲的压缩和隔离,都是在"已经产生了大量上下文"之后的应对策略。有没有办法从源头上减少上下文的膨胀?
有。核心思路是:不要提前加载用不到的东西。
Skill 机制就是一个典型例子。如果你有 50 个 Skill,每个 Skill 的完整内容平均 2000 token,全塞进 system prompt 就是 100000 token——一半的窗口直接被吃掉了,而且大部分 Skill 在当前对话里根本用不到。
Skill 的做法是分两层:
第一层:目录(始终在 system prompt 里,~100 token/Skill)
- code-review: 审查代码变更
- api-doc: 生成 API 文档
- db-migration: 数据库迁移
第二层:完整内容(按需通过工具调用加载,~2000 token/Skill)
- 只有 Agent 决定使用某个 Skill 时,才加载它的完整内容
Agent 每轮都能看到"我有哪些技能可用",但只看到名字和描述。真正需要某个 Skill 时,调用 load_skill 工具把完整内容拉进来。这样 50 个 Skill 的目录只占 5000 token,而不是 100000 token。
CLAUDE.md 也是类似的道理。你每次对话都要告诉 Agent “我们用 SpringBoot”、“测试用 JUnit”、“接口风格是 RESTful”,这些信息每次都要说一遍,每次都要花 token。写进 CLAUDE.md 之后,它作为 system prompt 的一部分自动加载,你不用再重复。虽然单次省的不多,但几十轮对话下来,避免的重复 token 消耗是很可观的。
更重要的是,CLAUDE.md 减少了"模型忘了你的偏好 → 输出不符合要求 → 你纠正 → 模型重来"这种返工循环。每一次返工都在花费额外的 token,而且返工产生的中间消息还会进一步膨胀上下文。
上下文持久化
还有一种场景:你在对话中确定了一些重要信息——技术方案、架构决策、API 设计——这些信息在后续对话中需要反复引用。如果每次都要从对话历史里找,不仅浪费 token,还容易被压缩掉。
解决方案是把关键信息持久化到文件里。
比如你让 Agent 设计一个微服务架构,讨论了半小时,确定了服务拆分方案、数据库选型、接口规范。这些决策如果只存在对话历史里,随着后续讨论越来越多,它们会被推到早期位置,可能在下一次压缩时被摘要掉。
更好的做法是让 Agent 把这些决策写进一个文件(比如 DESIGN.md 或 ARCHITECTURE.md)。后续对话中,Agent 需要参考这些决策时,读文件就行,不需要从对话历史里翻。
不用持久化:
对话历史里找决策 → 对话越长越难找 → 可能被压缩掉 → Agent"忘了"之前的决策
用持久化:
写进文件 → 需要时读文件 → 不依赖对话历史 → 压缩也不影响
表格总结
| 策略 | 解决什么问题 | 核心思路 | 代价 |
|---|---|---|---|
| auto-compact | 对话历史太长 | 用 LLM 总结早期消息 | 丢失细节 |
| SubAgent | 多任务互相挤占 | 独立上下文 + 只返回结论 | 额外 API 调用 |
| Skill 懒加载 | 系统指令太多 | 目录常驻,内容按需加载 | 需要一次工具调用 |
| CLAUDE.md | 重复配置浪费 token | 写一次,每次自动加载 | 内容需要维护 |
| 文件持久化 | 关键信息被压缩丢失 | 写进文件,需要时读取 | 需要主动管理文件 |
这五个策略本质上就做三件事:少发(Skill 懒加载、CLAUDE.md)、压缩(auto-compact)、隔离(SubAgent)。再加上持久化把关键信息从上下文里"搬"到文件里,就是一个完整的上下文管理方案。
小结
上下文管理的核心:在有限的窗口里,让模型始终看到最有价值的信息。
理解了上文中提到的这些策略,你就能理解为什么有时候 Agent 表现好、有时候表现差,不是模型变蠢了,在于它的上下文管理得好不好。当你发现 Agent 开始"忘事"或者重复劳动时,大概率是上下文膨胀了。这时候可以手动 /compact 一下,对于Agent开发者来说也要做好上下文管理的工作。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)