
Agent Skills(智能体技能)快速入门
写完了让AI检查有没有错误字,它却说公众号文章最好有收尾,那就写点什么吧skill是一种新的范式,并不会取代 prompt 或者 mcpskill 适合高频、稳定、复用的场景,不是这些场景用 prompt 就挺好当你真的需要skill时,可以让AI来创建skill不论是使用skill还是创建skill,首先得有Agent(参见第二小节)从0到1!想入门大模型(LLM)却不知道从哪开始?我根据最新的

1. Skills是什么
Skills本质上是md文件,即"文件化的提示词",
显然,把越来越长的提示词文件化之后,更利于进行版本化、维护、分享、复用,这是Skills的特点和优势,也是Skills的不断火热的原因
之前聊过MCP(大模型上下文协议)快速入门,Skills和MCP有一个共同点:都由anthropic提出和贡献,成为了agent领域重要的通用标准,
而不同的地方则是:
-
MCP作为一种协议,为Agent远程地提供了接口/工具/服务,
-
Skills作为"提示词",是在本地透明地进行提供,使用可以看到甚至修改其中的内容
另外Skill允许"渐进式"加载,就是先加载一部分思考一下,再决定要不要继续加载或者加载哪一部分,就避免了内容太多时上下文爆炸和选择困难症
写到这里,我让分别让Deepseek、Qwen、ChatGPT、Gemini生成二者的对比,我比较认可Gemini的结果,贴在下面大家也看看:
📊 Skills vs MCP 核心对比表
|
对比维度 |
Skills (智能体技能) |
MCP (模型上下文协议) |
|---|---|---|
| 核心定义 |
传授给 AI 的行为准则和工作流(菜谱) |
提供给 AI 的执行工具和数据接口(厨房/厨具) |
| 主要功能 |
提供上下文、业务领域知识、代码规范、工作流引导 |
提供实时数据访问、系统操作、工具调用能力 |
| 架构与格式 | 静态文件
(通常是带有 YAML frontmatter 的 Markdown 文件,存储在本地或代码库中) |
客户端-服务端架构
(Client-Server,通过 JSON-RPC 通信的实时在线服务) |
| 执行性质 | 非确定性
(依赖 LLM 对自然语言指令的理解和推理) |
高度确定性
(基于严格的 API Schema 输入和输出进行系统级调用) |
| 基础设施要求 | 零部署成本
(无需服务器、无需网络通信,直接加载进上下文) |
需要部署和维护
(需配置服务器、处理身份认证、连接池、API 路由等) |
| 响应延迟与网络 | 零延迟
,完全离线可用(因为仅作为 Prompt 上下文传递给模型) |
有网络延迟
,依赖外部服务和 API 响应速度 |
| 实时性与状态 | 静态无状态
(受限于文件编写时的内容,无实时数据能力) |
动态有状态
(可随时连接数据库、SaaS API 获取最新数据) |
| 典型应用场景 |
团队代码规范、文档编写指南、特定业务的标准操作流程(SOP)、静态参考文档 |
查询生产数据库、读写 Jira/Notion、控制云服务器、执行 Web 爬虫任务 |
| 一句话比喻 | 教 AI "应该做什么、怎么做"
(提供思想) |
给 AI "执行任务的能力"
(提供行动) |
Skills 本质上是结构化的 Prompt 管理系统,负责调度大脑
MCP 本质上是标准化的 API 协议, 负责充当手脚
2. Skills怎么用
网页/APP的deepseek、qwen是用不了Skills 的,
或者说:Chatbot用不了Skills ,Agent 才可以
目前,如果你想使用支持自定义skills的Agent 有以下选择 :
-
Gemini-cli、codex、Claude Code:模型厂家的官方cli,需搞定决网络和付费门槛
-
OpenClaw、OpenCode: 开源agent,接入自定义(比如国产)模型
-
Cherry Stido、Cursor:使用支持agent模型的客户端
-
coze:云服务
云服务的优势是免部署免维护,有多种模型和skill可以选用,但是文件读写、内网服务等常场景有局限性,对于技术人员吸引力不是很大;
如果是纯互联网环境、大部分在手机上使用、主要用于生成文字、图片、视频、Excel文件,那么云服务的优势就体现出来了(比如用来打磨小说大纲,生成小红书配图,搬运抖音视频)
我之前用Gemini,但是Gemini从下周开始不让免费用户使用了,而Claude又丧心病狂地封号,
准备切换 OpenCode + Qwen-Plus的国内友好方案了
放心,就算选择不同,用法也相同,一般来说各家都会兼容Claude (anthropic)用法的,
具体来说:
-
在制定位置创建md文件,比如:
.claude/skills/pytest-yaml/SKILL.md -
在md文件中写入 frontmatter(技能信息) 和 技能内容
-
正常使用agent (会在合适的时候自动加载SKILL.md,并执行其中的内容)
3. Skills示例
.claude/skills/pytest-yaml/
├── SKILL.md # 技能内容
├── responses-validator.md # 断言格式完整文档
├── responses-validator-quick-reference-zh.md # 断言格式中文摘要
├── assets/
│ ├── conftest.py # 预制fixture和hook
├── pytest.ini # 预制配置文件
└── schema.json # 用例格式schema
└── scripts/
├── generate_tests.py # 测试用例生成的脚本
└── validate_tests.py # 验证测试用例格式的脚本
SKILL.md的内容:
---
name: pytest-yaml
description: 从 OpenAPI 规范生成 pytest-yaml 格式的 API 测试用例
license: MIT
metadata:
audience: qa-engineers
workflow: api-testing
---
## 我能做什么
- 解析 OpenAPI 3.0+ JSON 规范,理解 API 接口
- 设计全面的测试用例,包括正常场景、边界场景和错误场景
- 生成符合 pytest-yaml 格式的 YAML 测试用例文件
- 支持数据驱动测试(DDT),包含参数化功能
- 包含响应验证、状态码验证和变量提取步骤
## 何时使用我
当您需要以下功能时,可以使用我:
- 从现有的 OpenAPI 文档创建 API 测试套件
- 为基于 pytest-yaml 的测试框架生成测试用例
- 将 OpenAPI 端点定义转换为可执行的测试场景
- 为 RESTful API 构建自动化回归测试
## Agent 使用指南
本 skill 旨在帮助 agent 从 OpenAPI 规范自动生成 pytest-yaml 格式的 API 测试用例
### 完整工作流程
建议 agent 按照以下步骤使用本 skill:
#### 步骤 1:使用脚本生成基础测试用例
具体用法可见后文"脚本使用方法"
#### 步骤 2:分析接口关联
在使用脚本生成测试用例之后,agent 分析 OpenAPI 文档内容,理解接口之间的依赖关系:
1. **阅读 OpenAPI 文件**:理解 API 的整体结构
2. **识别登录接口**:找到返回 `access_token` 的接口(如 `/login/access_token`)
3. **识别资源接口**:找到创建资源的接口(如 `POST /todo`)
4. **识别依赖关系**:
- 创建资源返回的 ID 被哪些接口使用
- 需要认证的接口有哪些
- 接口之间的调用顺序
**Agent 应生成的分析文档(文件名readme.md)**,例如:
```markdown
# API 接口分析报告
## 登录接口
- POST /login/access_token
- 返回:access_token, token_type
- 依赖:无
## 宠物接口
- POST /pets(创建宠物)
- 返回:id, title, is_done, create_datetime, done_datetime
- 依赖:需要 access_token
- GET /pets/{petId}(获取宠物详情)
- 参数:petId(来自创建宠物的返回)
- 依赖:需要 access_token
- PUT /pets/{petId}(更新宠物)
- 参数:petId
- 依赖:需要 access_token
- DELETE /pets/{petId}(删除宠物)
- 参数:petId
- 依赖:需要 access_token
## 测试顺序建议
1. 先执行登录,获取 access_token
2. 创建宠物,获取 id
3. 使用 id 进行查询、更新、删除操作
```
#### 步骤 3:调整测试用例
根据生成的分析报告和基础测试用例,按顺序进行内容审查并进行必要的调整:
1. **接口依赖**:在需要token、id等依赖场景中,前置接口创建了合适的`extract`步骤来创建变量,后接口正确的使用了变量,变量名合理、正确
2. **测试顺序**:调整用例之间的依赖关系、执行顺序合理、正确(主要文件名控制顺序)
3. **额外断言**:根据业务逻辑添加**必要的**更详细的断言
4. **格式校验**:使用 schema.json 验证所有的用例文件均符合格式要求(见下方验证命令)
5. **注册函数**:创建 yaml_funcs.py,实现用例需要使用的变量和函数,可参考文档:https://pytest-yaml-doc.pages.dev/guide/7_functions)
6. **复制文件**: 将 `assets/conftest.py` 和 `assets/pytest.ini`复制到用例所在目录,作为运行时文件
### 脚本使用方法
运行测试生成器脚本:
```bash
python scripts/generate_tests.py openapi.json -o tests/
```
参数说明:
- `openapi_file`: OpenAPI JSON 规范文件的路径(必填)
- `-o, --output-dir`: 测试用例输出目录(默认为 tests)
使用验证脚本检查生成的测试用例是否符合 schema 规范:
```bash
# 验证单个文件
python scripts/validate_tests.py tests/test_example.yaml
# 验证整个目录
python scripts/validate_tests.py tests/
# 指定文件匹配模式
python scripts/validate_tests.py tests/ -p "test_*.yaml"
```
**参数说明**:
- `target`: 要验证的 YAML 文件或目录路径(必填)
- `-p, --pattern`: 文件匹配模式(仅对目录有效,默认为 `*.yaml`)
(后面还有一些示例、参考、能力边界的内容,篇幅原因没有完整粘贴)
使用效果
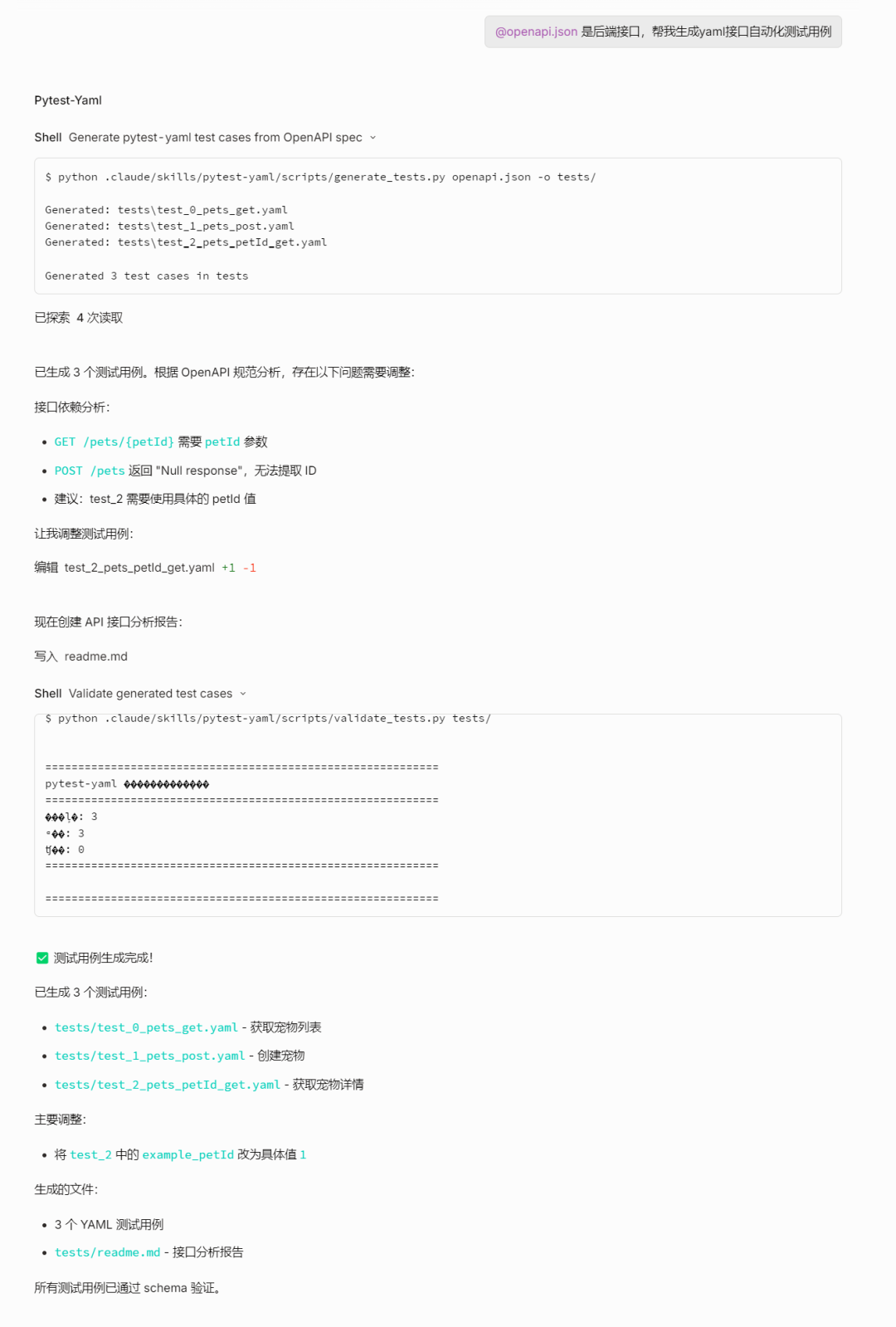
使用skill的过程
用例内容:
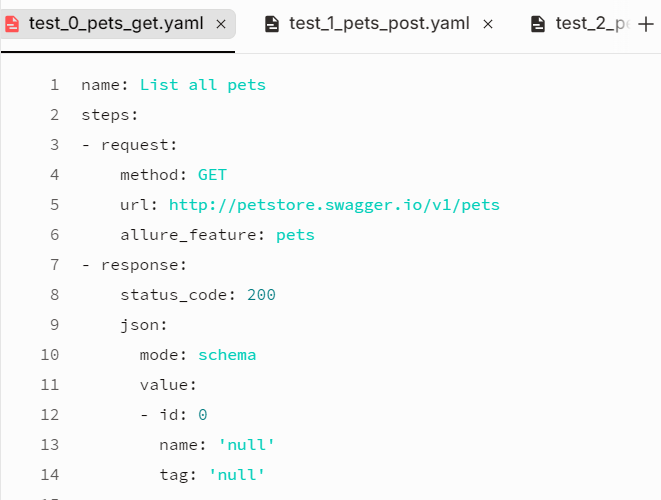
yaml用例文件1
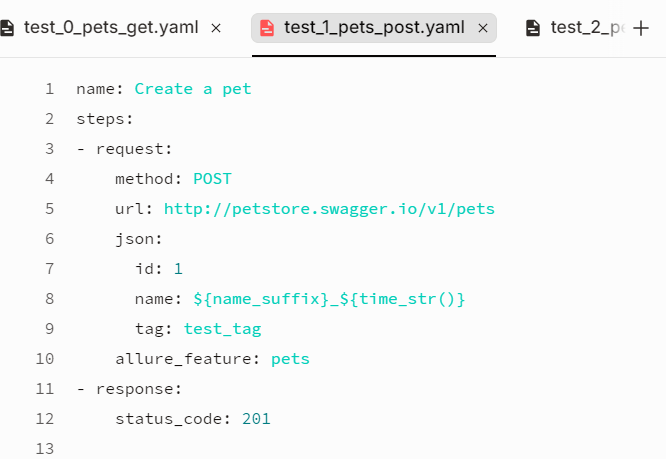
yaml用例文件2
注:本节所示Skill由Agent创建,提示词内容:
我想创建一个skill给agent使用:
1. 读取openapi(或其他文件)来了解接口,并设计接口测试用例
2. 创建yaml格式的测试用例:
- 整体思路参考这个示例:https://pytest-yaml-doc.pages.dev/example/3_api_test
- 其中:核心框架使用pytest,接口请求使用requests
- 用例加载使用pytest-yaml-sanmu,文档地址:https://pytest-yaml-doc.pages.dev/
- 断言使用responses-validator,文档地址:https://pypi.org/project/responses-validator/
3. example目录有一个openapi.json和我手动创建的一个用例示例,是理想情况下此skill的最终输出
尽管提供了 schema.json 和一个完整示例,但skill并非一次就创建好,也反复沟通了几次
4. Skills规则和技巧
基本规则官方文档写得很清楚,这里不再重复了,如果不愿意看官方文档也可以直接问AI,
这里分享我的一些体会:
多看别人写的skills,就像文学工作者一样,看到越多不同的作品,越能激发自己的灵感,比如把技能内容拆分成不同的小文件按需加载,以及使用预制代码完成一些固定性工作;
做好版本化,就像提示词一样,skills也是持续优化无止尽的, 建议使用git将skills管理起来,跟踪变化,自动更新;
坚持单一职责,skills之间是可以相互配合的,不需要要追求一个技能大而全比如生成接口测试用例的skill是输入openapi文件来,如果某项目没有openapi文档只有md文档的怎么办?不要让这个skill增加一个md转openapi的能力,而是额外创建一个其他格式转openapi的skill来进行辅助;
优化描述,描述(SKILL.md中的description)是Agent进行技能选择的依据,首先说清楚这个技能做什么,尽量多加相关的关键字,还可以举一些场景和例子(可以多看看LLM推理的内容找灵感),以便在skills很多的时候,也能被Agent准确选中;
不要盲从Skill,比如临时的、低频的、简短的、变动的、有复杂依赖、强制执行的内容,大可不必做成skill,可以写在某个文件里告诉agent去读取作为后续指令就就行了,不必为了skill而skill;
5. 总结
写完了让AI检查有没有错误字,它却说公众号文章最好有收尾,那就写点什么吧
-
skill是一种新的范式,并不会取代 prompt 或者 mcp
-
skill 适合高频、稳定、复用的场景,不是这些场景用 prompt 就挺好
-
当你真的需要skill时,可以让AI来创建skill
-
不论是使用skill还是创建skill,首先得有Agent(参见第二小节)
最后
从0到1!大模型(LLM)最全学习路线图,建议收藏!
想入门大模型(LLM)却不知道从哪开始? 我根据最新的技术栈和我自己的经历&理解,帮大家整理了一份LLM学习路线图,涵盖从理论基础到落地应用的全流程!拒绝焦虑,按图索骥~~
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取