大模型“幻觉“终结者!RAG技术揭秘:如何让AI随时查阅真实资料并给出准确回答?
RAG技术通过检索增强生成解决大模型三大痛点:知识过时、幻觉问题和领域局限。其核心原理是让大模型在回答前先检索外部知识库,基于真实资料生成答案。RAG技术已从基础检索演进到模块化架构,关键技术包括向量Embedding、数据库选择、混合检索算法和重排序等。企业实践中需构建完整技术链路,从文档解析到效果评估。未来趋势包括Graph RAG和多模态RAG,可显著提升回答的时效性、专业性和准确性,同时降
大模型存在知识过时、幻觉问题和领域局限三大痛点。RAG(检索增强生成)技术通过让大模型在回答前检索外部知识库,有效解决这些问题。本文系统介绍了RAG的核心原理、技术演进(从Naive RAG到Modular RAG)、关键技术(Embedding、向量数据库、检索算法等)、企业级实践(技术链路、框架选型)、效果评估方法以及未来趋势(Graph RAG、Multimodal RAG等)。通过RAG,大模型能像考试学生一样查阅真实资料,显著提升回答的时效性、专业性、准确性和可解释性,同时降低成本。
前言
你有没有遇到过这种情况:问大模型一个专业问题,它回答得头头是道,但仔细核对——数据过时了,事实不准确,甚至一本正经地胡说八道?
这是大模型最让人头疼的**「幻觉问题」**——模型不是在回答,而是在「创作」。
那有没有办法让大模型像带着笔记本考试的学生一样,随时查阅真实资料后再回答?
RAG(检索增强生成)恰好解决了这个问题。
本文将带你从零开始,系统掌握RAG的核心原理、技术演进、企业级实践和未来趋势。无论你是AI新手还是希望深入理解的开发者,都能从中获得有价值的内容。
一、为什么需要 RAG?
1.1 大模型的三大痛点
大模型虽然强大,但在真实业务场景中存在明显的局限性:
| 痛点 | 表现 | 典型场景 |
|---|---|---|
| 知识时效性差 | 训练数据有截止日期,无法回答最新问题 | 问"2024年奥运会金牌榜",模型可能完全不知道 |
| 幻觉问题严重 | 模型有时编造不存在的信息 | 问公司内部流程,给出根本不存在的规定 |
| 领域知识匮乏 | 通用模型在医疗、法律等专业领域深度不够 | 问具体法规条款,给出模糊或错误的回答 |
1.2 为什么不直接用长上下文?
你可能会想:现在大模型上下文窗口越来越大,直接把所有资料塞进去不就行了?
事实是:能处理长上下文 ≠ 能稳定、准确、可控地给出正确答案。
成本与效率问题
- 推理成本与上下文长度呈强正相关,8K Token与200K Token的价格和延迟完全不在一个量级
- 绝大多数任务只需少量高相关信息,全量塞入造成严重资源浪费
注意力与聚焦问题
- 上下文超过一定长度后,模型对前端和中端信息关注度会逐渐减弱
- 无关、重复甚至冲突的信息容易"带偏"模型,导致答案与核心问题脱节
知识更新与可控性问题
- 知识变更需要重新训练或手动维护提示词模板,成本高且易出错
- 模型回答的依据难以追溯,合规审计面临操作困难
1.3 RAG 的核心优势
RAG(Retrieval-Augmented Generation,检索增强生成)的核心思路是:让大模型在回答问题前,先从外部知识库检索相关信息,再基于真实资料生成答案。
相比单纯依赖模型参数或长上下文,RAG带来了:
- 时效性:直接读取最新文档,无需频繁重新训练模型
- 专业性:接入企业私有文档和行业标准,回答更权威
- 准确性:要求基于检索文档作答,附带出处引用,大幅减少幻觉
- 可解释性:每条回答可追溯到具体条款或文档
- 成本效益:知识存储在外部向量库,用较小模型即可获得高质量回答
二、RAG 的核心原理
2.1 一个通俗的类比
- 传统大模型(纯生成) = 考试时完全不翻书,全凭记忆和脑补来答题
- RAG(检索增强) = 考试时带着教材,先翻书找相关章节,再基于书上内容回答
2.2 RAG 的工作流程
一个完整的RAG系统包含以下阶段:
用户问题 → 知识检索 → 上下文增强 → 大模型生成 → 最终答案
步骤一:索引阶段(离线)
- 文档预处理:对原始文档进行清洗、格式解析
- 文本切分:将长文档拆分成语义完整的文本块(chunks)
- 向量化:使用Embedding模型将每个文本块转换为高维向量
- 存入向量数据库:构建支持语义相似度检索的索引
步骤二:检索阶段(在线)
- 问题向量化:将用户问题转换为语义向量
- 相似度检索:在向量库中找出与问题最相似的Top-K个文本块
- 重排序:使用Rerank模型对检索结果进行精细排序
步骤三:生成阶段(在线)
- 构建Prompt:将用户问题 + 检索到的文档片段组合成完整提示词
- 调用大模型:让模型基于真实参考资料生成答案
- 返回结果:附带引用来源,支持用户追溯验证
2.3 用"苹果"理解向量检索
假设知识库包含三个文档片段:
| 文档 | 内容 |
|---|---|
| A | 苹果公司于1976年4月1日由史蒂夫·乔布斯等人创立 |
| B | 苹果是一种水果,富含维生素C,有助于消化 |
| C | 苹果公司在2007年推出了第一款iPhone |
向量化后,每个文档变成一串数字:
文档A向量:[0.85, -0.23, 0.41, -0.56, ...] (关于公司创立)文档B向量:[-0.12, 0.95, -0.34, 0.67, ...] (关于水果营养)文档C向量:[0.79, -0.18, 0.52, -0.61, ...] (关于iPhone)
当用户问"苹果公司是什么时候创立的?"
系统将问题也转换为向量 [0.82, -0.21, 0.38, ...],然后计算与各文档的相似度:
- 与文档A相似度:0.97(高度相关)
- 与文档C相似度:0.88(相关,同属公司主题)
- 与文档B相似度:0.12(几乎不相关)
系统返回相似度最高的结果,模型基于真实文档片段生成准确答案。
三、RAG 的技术演进
3.1 第一代:Naive RAG(基础检索增强)
核心流程:文档切分 → 向量检索 → 简单拼接 → 生成回答
特点:
- 工程直接,"先查再答"的思路得到验证
- 解决了"要不要检索"的问题
- 分块策略粗糙,仅依赖向量相似度排序
局限性:
- 固定长度切分容易截断语义
- 检索噪声大,结果不经过筛选
- 上下文容易被低价值信息占据
3.2 第二代:Advanced RAG(精细化优化)
核心改进:在检索前和检索后引入系统化优化策略
检索前优化
| 技术 | 作用 |
|---|---|
| Query Rewrite | 将口语化问题转换为标准化检索表达 |
| Multi-Query | 生成多个角度的查询,覆盖潜在需求 |
| Sub-Query | 分解复合问题为多个简单子查询 |
| Step-back Prompting | 生成上位问题,避免细节偏差 |
检索后优化
| 技术 | 作用 |
|---|---|
| Rerank | 使用交叉编码器对候选文档重新排序 |
| 去重压缩 | 去掉无关和重复片段 |
| 引用约束 | 强制要求给出信息出处 |
3.3 第三代:Modular RAG(模块化架构)
核心理念:RAG不再是一条固定流水线,而是由可插拔的功能模块组成
| 模块 | 功能 |
|---|---|
| 查询理解与路由 | 意图识别、路径选择,决定使用哪个知识源 |
| 多源检索融合 | 同时查询向量库、全文检索、数据库、知识图谱 |
| 记忆与个性化 | 维护用户画像和会话历史 |
| 任务适配与治理 | 不同任务加载不同适配器,格式、风格约束 |
关键突破:支持多轮交互——生成过程中发现信息不足时,可主动触发新一轮检索。
四、RAG 的关键技术
4.1 向量 Embedding
作用:将文本转换为高维向量,让机器能理解语义相似性
关键参数:
- 维度:768维 vs 1024维 vs 1536维,维度越高语义细节越丰富
- 上下文长度:决定单次能处理的最大文本量
推荐模型:
| 模型 | 特点 | 适用场景 |
|---|---|---|
| text-embedding-3-large | 性能领先,成熟稳定 | 云端高性能场景 |
| BAAI/bge-m3 | 支持混合检索 | 多语言复杂场景 |
| Qwen2-Embedding | 中文能力强,开源可本地部署 | 中英文RAG |
| BAAI/bge-large-zh | 中文RAG稳定基线 | 纯中文项目 |
4.2 向量数据库
主流选择:
| 数据库 | 特点 |
|---|---|
| Chroma | 简单易用,新手友好 |
| Qdrant | 支持混合搜索,功能全面 |
| FAISS | Facebook开源,性能强悍 |
| Pinecone | 云端托管,无需运维 |
| Milvus | 支持增量更新,适合生产环境 |
4.3 检索算法
| 类型 | 原理 | 适用场景 |
|---|---|---|
| 密集检索 | 基于向量相似度 | 理解语义,开放性问题 |
| 稀疏检索(BM25) | 基于关键词匹配 | 精确术语,专业名词查询 |
| 混合检索 | 结合两者优势 | 最佳实践 |
4.4 重排序(Rerank)
初筛结果可能10条中只有3条真正相关,需要用Rerank模型进行二次排序。
推荐模型:
- Cohere Rerank 4 - 性能优秀,延迟低
- BAAI/BGE Reranker v2 M3 - 开源,支持多语言
- Voyage AI Rerank 2.5 - 速度快效果好
4.5 Prompt 工程
RAG效果很大程度上取决于Prompt设计:
你是一个专业的问答助手。请严格根据用户提供的【参考信息】来回答问题。【参考信息】{context}【用户问题】{question}【回答要求】1. 仅基于参考信息回答,不要编造信息2. 如果参考信息中没有答案,请明确告知3. 回答时注明信息来源
五、企业级 RAG 实践
5.1 完整技术链路
┌─────────────┐ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐│ 文档解析 │ → │ 知识库构建 │ → │ RAG问答 │ → │ 效果评估 ││ (PDF/Word) │ │ (切分+Embedding)│ │ (检索+生成) │ │ (指标+优化) │└─────────────┘ └─────────────┘ └─────────────┘ └─────────────┘
5.2 文档解析要点
不同格式需要不同处理策略:
| 格式 | 处理方式 |
|---|---|
| PDF/Word | 版面分析、结构抽取、表格识别 |
| 扫描件 | OCR识别 |
| 图片 | 多模态模型提取文字和描述 |
| HTML | 结构化解析,保留层级 |
5.3 文本分块策略
| 策略 | 说明 | 建议参数 |
|---|---|---|
| 固定长度 | 按token数切分 | chunk_size: 500, overlap: 50 |
| 语义分块 | 按段落、标题边界切分 | 保持语义完整性 |
| 滑动窗口 | 重叠切分 | 减少边界信息丢失 |
5.4 开发框架选择
| 类型 | 推荐工具 | 特点 |
|---|---|---|
| 低代码平台 | Dify | 可视化界面,快速上手 |
| Coze | 字节出品,插件丰富 | |
| FastGPT | 中文友好,开箱即用 | |
| 代码框架 | LangChain | 生态丰富,组件齐全 |
| LlamaIndex | 专注RAG,模块化程度高 |
5.5 模型选型建议
Embedding 模型
参考 MTEB Leaderboard,选择性价比高的模型。
Rerank 模型
参考 Agentset Reranker Leaderboard,平衡精度与延迟。
LLM 模型
参考 LMSYS Chatbot Arena,根据回答质量、响应速度和成本综合选择。
最佳实践:
- 构建20-30个典型业务问题的测试集
- 对候选模型进行端到端RAG流程评估
- 简单问题用小模型,复杂问题用大模型
六、RAG 效果评估
6.1 评估指标体系
检索效果评估
| 指标 | 说明 | 关注点 |
|---|---|---|
| Recall@K | 前K个结果中相关文档被找回的比例 | 覆盖面 |
| Precision@K | 前K个结果中真正相关的占比 | 准确度 |
| MRR | 第一个相关文档出现位置的倒数均值 | 排序质量 |
| NDCG@K | 综合相关性分级和位置衰减的排序指标 | 综合排序 |
生成质量评估
| 指标 | 说明 | 关注点 |
|---|---|---|
| EM | 答案与参考答案完全匹配 | 精确回答 |
| ROUGE-L | 基于最长公共子序列的相似度 | 流畅性 |
| BertScore | 基于语义向量的相似度 | 语义准确 |
| Faithfulness | 答案基于检索文档的比例 | 减少幻觉 |
LLM裁判评估
引入强能力模型从多维度打分:
- 问题相关性
- 信息完整性
- 事实忠实性
- 整体正确性
6.2 评测框架
| 框架 | 特点 |
|---|---|
| RAGAS | 综合性框架,LLM-as-Judge模式 |
| ARES | 分类器辅助评测 |
| TruLens-Eval | 与LangChain/LlamaIndex集成 |
| MedRAG | 医疗领域专用 |
6.3 构建评测集
- 从业务日志提取真实用户问题
- 分层采样(高频问题、边界情况、异常输入)
- 机器生成+人工校准降本
- 持续从线上反馈补充新用例
七、RAG 进阶优化
7.1 语义缓存
对于高频重复查询(如客服场景),引入缓存层可大幅降低延迟和成本:
- 双层检索:缓存层命中 → 直接返回
- 缓存未命中 → 走向量检索 → 更新缓存
- 实测效果:检索时间减半,性能提升90%-95%
7.2 混合检索策略
用户查询 ↓┌─────────┐ ┌─────────────┐│ BM25检索 │ │ 向量相似度 │└────┬────┘ └──────┬──────┘ ↓ ↓ └───────┬────────┘ ↓ 结果融合排序 ↓ Rerank精排 ↓ Top-K输出
7.3 分类型Prompt
根据问题类型使用不同模板:
| 问题类型 | Prompt策略 |
|---|---|
| 数字类 | 5步分析:识别指标→定位表格→提取数值→验证单位→交叉验证 |
| Yes/No类 | 严格基于文档判断,给出判断依据 |
| 列表类 | 分点列举,每点注明来源 |
7.4 上下文压缩
对于超长文档,采用基于BM25的压缩方法:
- 句子级切分
- 按相关性比例拼接高相关句子
- 实测:50%压缩率下,准确率达86.48%
八、RAG 的未来趋势
8.1 Graph RAG(图结构检索)
传统RAG找相似段落,Graph RAG找关系网络。
适用场景:
- 需要联系多份文档才能回答的复杂问题
- 关系推理(如"某系统的常见故障环节是什么")
核心思路:
- 从文本中抽取实体和关系,构建知识图谱
- 对实体进行主题分组
- 检索时先找相关局部结构,再扩展到原文
8.2 Multimodal RAG(多模态RAG)
不仅检索文本,还能检索图片、音频、视频。
应用场景:
- 运维场景:同时看监控图表、日志截图、系统架构图
- 医疗场景:CT/MRI影像 + 检查报告 + 电子病历
8.3 Late Chunking(后置分块)
传统方法"先切后编",Late Chunking采用"先编后切":
- 用长上下文模型(如8K tokens)处理整个文档
- 生成每个token的向量(已包含全文信息)
- 再进行分块平均池化
优势:跨段落的指代关系得到保留,检索准确率显著提升。
8.4 Agentic RAG(智能体RAG)
RAG从"被动检索"进化为"主动探索":
- 主动规划:理解复杂任务,自主拆解问题
- 迭代检索:评估结果质量,决定是否继续检索
- 长期记忆:积累用户偏好和领域知识
- 多轮交互:在生成过程中发现不足,主动触发新检索
九、快速上手指南
9.1 环境准备
# 安装依赖pip install langchain langchain-community chromadb sentence-transformers# 或使用 Ollama 本地运行模型brew install ollamaollama pull qwen2.5
9.2 最小示例
from langchain_community.document_loaders import TextLoaderfrom langchain.text_splitter import RecursiveCharacterTextSplitterfrom langchain_community.embeddings import HuggingFaceEmbeddingsfrom langchain_community.vectorstores import Chromafrom langchain.chains import RetrievalQAfrom langchain_community.llms import Ollama# 1. 加载文档loader = TextLoader("knowledge.txt")documents = loader.load()# 2. 文档切分splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)splits = splitter.split_documents(documents)# 3. 创建向量数据库embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")vectorstore = Chroma.from_documents(documents=splits, embedding=embeddings)# 4. 构建RAG链retriever = vectorstore.as_retriever(search_kwargs={"k": 3})qa_chain = RetrievalQA.from_chain_type(llm=Ollama(model="qwen2.5"), retriever=retriever)# 5. 提问result = qa_chain.invoke({"query": "文档中的核心概念是什么?"})print(result["result"])
9.3 推荐工具组合
| 组件 | 推荐方案 | 特点 |
|---|---|---|
| 向量数据库 | ChromaDB | 零配置,开箱即用 |
| 开发框架 | LangChain / LlamaIndex | 生态完善 |
| Embedding | BGE / Qwen2-Embedding | 开源可本地 |
| LLM | Ollama / DeepSeek API | 本地免费/云端性价比 |
| 低代码平台 | Dify / FastGPT | 快速验证 |
总结
RAG的核心价值:
- 解决大模型知识时效性、幻觉、专业性三大痛点
- 相比长上下文,成本更低、准确性更高、可控性更强
记住:没有最好的模型,只有最适合你业务场景的组合。多测试、多迭代,找到最优解。
01
什么是AI大模型应用开发工程师?
如果说AI大模型是蕴藏着巨大能量的“后台超级能力”,那么AI大模型应用开发工程师就是将这种能量转化为实用工具的执行者。
AI大模型应用开发工程师是基于AI大模型,设计开发落地业务的应用工程师。
这个职业的核心价值,在于打破技术与用户之间的壁垒,把普通人难以理解的算法逻辑、模型参数,转化为人人都能轻松操作的产品形态。
无论是日常写作时用到的AI文案生成器、修图软件里的智能美化功能,还是办公场景中的自动记账工具、会议记录用的语音转文字APP,这些看似简单的应用背后,都是应用开发工程师在默默搭建技术与需求之间的桥梁。
他们不追求创造全新的大模型,而是专注于让已有的大模型“听懂”业务需求,“学会”解决具体问题,最终形成可落地、可使用的产品。
CSDN粉丝独家福利
给大家整理了一份AI大模型全套学习资料,这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】

02
AI大模型应用开发工程师的核心职责
需求分析与拆解是工作的起点,也是确保开发不偏离方向的关键。
应用开发工程师需要直接对接业务方,深入理解其核心诉求——不仅要明确“要做什么”,更要厘清“为什么要做”以及“做到什么程度算合格”。
在此基础上,他们会将模糊的业务需求拆解为具体的技术任务,明确每个环节的执行标准,并评估技术实现的可行性,同时定义清晰的核心指标,为后续开发、测试提供依据。
这一步就像建筑前的图纸设计,若出现偏差,后续所有工作都可能白费。
技术选型与适配是衔接需求与开发的核心环节。
工程师需要根据业务场景的特点,选择合适的基础大模型、开发框架和工具——不同的业务对模型的响应速度、精度、成本要求不同,选型的合理性直接影响最终产品的表现。
同时,他们还要对行业相关数据进行预处理,通过提示词工程优化模型输出,或在必要时进行轻量化微调,让基础模型更好地适配具体业务。
此外,设计合理的上下文管理规则确保模型理解连贯需求,建立敏感信息过滤机制保障数据安全,也是这一环节的重要内容。
应用开发与对接则是将方案转化为产品的实操阶段。
工程师会利用选定的开发框架构建应用的核心功能,同时联动各类外部系统——比如将AI模型与企业现有的客户管理系统、数据存储系统打通,确保数据流转顺畅。
在这一过程中,他们还需要配合设计团队打磨前端交互界面,让技术功能以简洁易懂的方式呈现给用户,实现从技术方案到产品形态的转化。
测试与优化是保障产品质量的关键步骤。
工程师会开展全面的功能测试,找出并修复开发过程中出现的漏洞,同时针对模型的响应速度、稳定性等性能指标进行优化。
安全合规性也是测试的重点,需要确保应用符合数据保护、隐私安全等相关规定。
此外,他们还会收集用户反馈,通过调整模型参数、优化提示词等方式持续提升产品体验,让应用更贴合用户实际使用需求。
部署运维与迭代则贯穿产品的整个生命周期。
工程师会通过云服务器或私有服务器将应用部署上线,并实时监控运行状态,及时处理突发故障,确保应用稳定运行。
随着业务需求的变化,他们还需要对应用功能进行迭代更新,同时编写完善的开发文档和使用手册,为后续的维护和交接提供支持。
03
薪资情况与职业价值
市场对这一职业的高度认可,直接体现在薪资待遇上。
据猎聘最新在招岗位数据显示,AI大模型应用开发工程师的月薪最高可达60k。
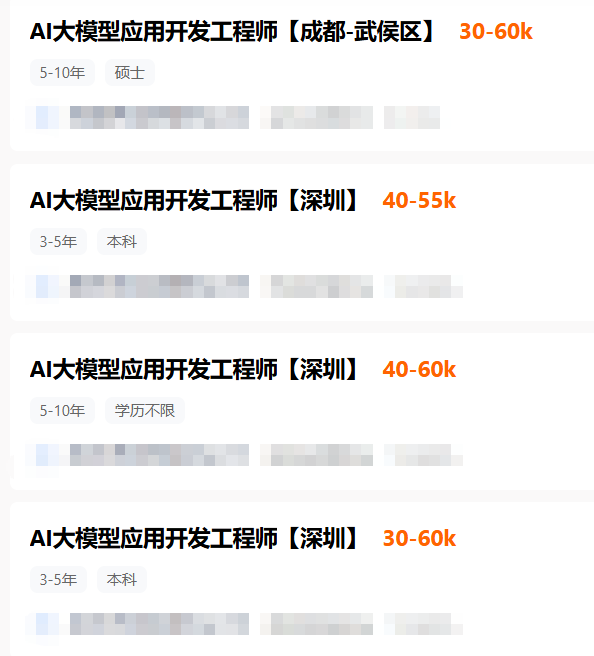
在AI技术加速落地的当下,这种“技术+业务”的复合型能力尤为稀缺,让该职业成为当下极具吸引力的就业选择。
AI大模型应用开发工程师是AI技术落地的关键桥梁。
他们用专业能力将抽象的技术转化为具体的产品,让大模型的价值真正渗透到各行各业。
随着AI场景化应用的不断深化,这一职业的重要性将更加凸显,也必将吸引更多人才投身其中,推动AI技术更好地服务于社会发展。
CSDN粉丝独家福利
给大家整理了一份AI大模型全套学习资料,这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 1
1 0
0- 0



 已为社区贡献724条内容
已为社区贡献724条内容

所有评论(0)