【薅羊毛教程】LLaMaFactory 不用本地跑!免费 GPU,一键微调大模型
本文介绍了在阿里云魔搭社区免费GPU环境下部署LLaMaFactory平台并微调大模型的完整流程。详细记录了操作过程中的关键步骤和常见问题解决方法,如tokenizer配置错误处理等,最终在不花费成本的情况下完成了从环境搭建到模型微调的全流程演示。
一、环境
之前介绍过本地部署LLaMaFactory微调平台(https://blog.csdn.net/m0_73982863/article/details/159208213?spm=1001.2014.3001.5501),如果你还在为设备问题而烦恼,那就来薅羊毛吧(手动狗头)。
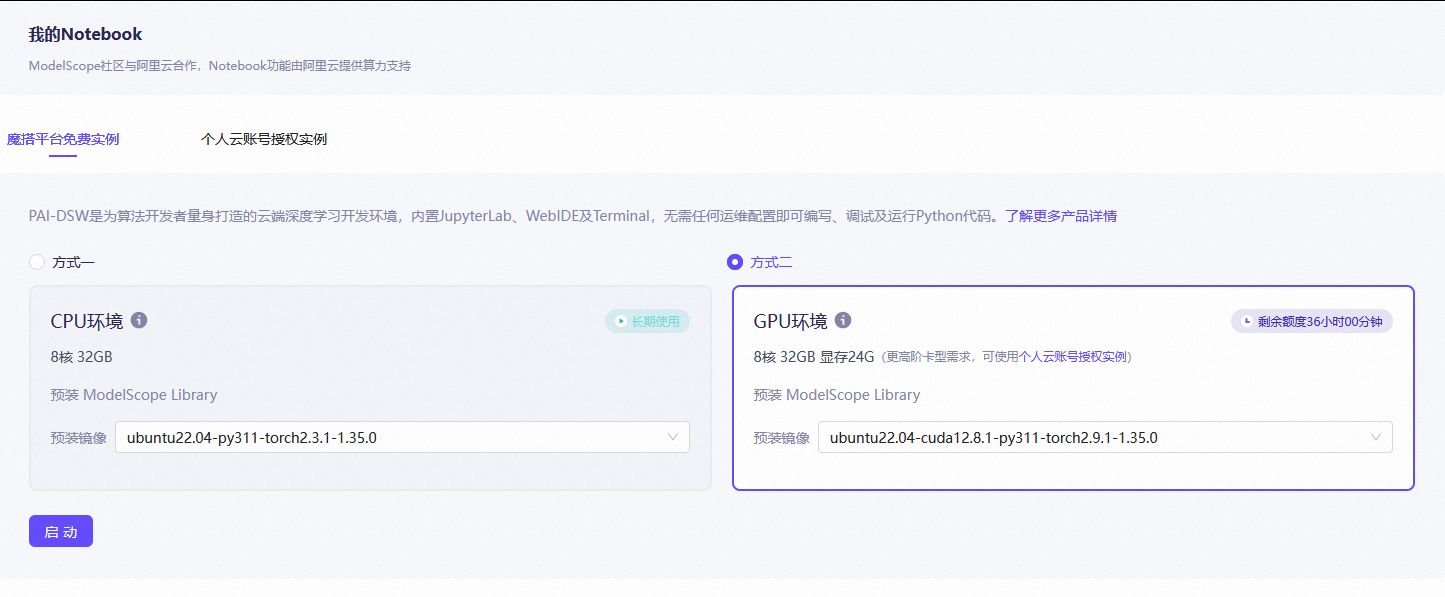
首先注册魔搭社区,绑定个人阿里云账号即可,详情见:https://www.modelscope.cn/my/mynotebook ;然后就可免费获得36小时GPU环境。
8核:CPU有8个核心,主要负责数据的调度和预处理;32GB:内存,数据从硬盘加载后会暂时存放这里;显存24G;(比我自己的老古董好多 T-T)
Ubuntu 22.04:Linux操作系统;
CUDA 12.8.1:英伟达的并行计算平台。12.8版本意味着它支持最新的RTX 40系列或H系列显卡;
Python 3.11:编程语言版本;
PyTorch 2.9.1:目前最主流的深度学习框架;2.9.1也是比较新的版本;
1.35.0:预装的ModelScope版本号;
安装LLaMaFactory
老操作了,这里就不过多赘述,git克隆llama-factory项目,执行 【pip install -e .】,结果出现提示:

错误信息表示 pip 在安装新包时检测到依赖冲突,为避免 pip 导致权限混乱,这里推荐使用虚拟环境(venv);
创建虚拟环境
创建虚拟环境:python -m venv llmVenv (llmVenv可自定义名称);
激活虚拟环境:source llmVenv/bin/activate
退出虚拟环境:deactivate
在虚拟环境中执行升级:pip install --upgrade pip
后续老操作【pip install -e .】和【pip install -r requirements/metrics.txt】,执行【llamafactory-cli webui】可以启动,并在控制台中直接点击【http://127.0.0.1:7860】可完成浏览器访问;
二、模型选择
2.1. 模型分类和区别
此处我随手选中一个模型【Qwen3-4B-Base】,跳出了告警提示。这是因为【Base】表示基座模型,而不是经过指令微调【Instruct】的模型。
两者区别在于:
Base:基座模型,只完成了预训练,擅长续写文本,不擅长直接理解并回答人类的问题或指令。
Instruct:指令模型,在基座模型的基础上,使用大量【用户指令和期望回答】的数据进行微调,能够正确理解并遵循人类指令。

后续选择【Qwen3.5-2B-Base】,此时模型名称同样带【Base】,却没有弹出告警提示。
Qwen3.5是后训练模型,已经经历了至少一轮指令微调或强化学习(RL),具备对话能力。RL训练的模型其指令遵循能力通常优于单纯的监督微调(SFT)模型。

2.2.加载模型对话
我们可以点击【Chat】进行加载模型对话,可以看到其中的如下参数:
2.2.1.【推理引擎】:
Hugging Face: transformers 库,是 LLM 领域最通用的原生推理框架。开箱即用,配置灵活,适合调试、开发、原型验证。默认使用PyTorch动态图,速度相对较慢,显存占用较高。
vLLM:高性能和服务框架,专为高吞吐、低延迟设计。支持连续批处理,自动合并请求,提高吞吐。适合生产环境部署、高并发API服务、需要最大化吞吐量的离线推理。
SGLang:较新的推理框架,专注于结构化生成和复杂推理任务。吞吐量接近vLLM,适合需要复杂生成逻辑,对推理过程有精细控制要求的场景。
2.2.2.【推理数据类型】:控制模型加载和推理时使用的数值精度。
auto:自动选择,框架会根据模型配置和硬件能力自动决定最优精度。如果支持bfloat16,通常会优先使用,否则回退到float16或32。
float32:最精确,显存占用最大,速度最慢,通常不推荐用于推理。
float16:显存较fp32减半,速度更快,精度损失小。大多数GPU支持。
bfloat16:与fp16同显存占用,但动态范围更大,训练和推理更稳定。
2.2.3.【额外参数】:
{"vllm_enforce_eager": true},vLLM专用参数,在vLLM中会强制使用eager模式(不使用CUDA图优化),通常用于调试或避免某些显存问题;此处当前推理引擎是 huggingface,理论上这个参数不会生效,但是我这里默认自带,还是手动删除(即仅保留 {},否则会出现Json格式错误);

点击【加载模型】后,可以看到控制台会自动下载对应的模型。

当然也可以手动下载魔搭社区的模型,默认存储路径也是一样的,访问:https://modelscope.cn/models ,此处以Qwen3.5-2B举例:modelscope download --model Qwen/Qwen3.5-2B (详情见:https://www.modelscope.cn/models/Qwen/Qwen3.5-2B)
之前文章提到过,这里就不过多赘述。有兴趣的同学可以看:https://blog.csdn.net/m0_73982863/article/details/159208213?fromshare=blogdetail&sharetype=blogdetail&sharerId=159208213&sharerefer=PC&sharesource=&sharefrom=from_link 中的4.1.2.3;
这里等待模型加载成功后,就可以正常聊天了。
三、数据集
魔搭社区中提供大量数据集,我们学习过程中可以下载使用,详情见:https://www.modelscope.cn/datasets
3.1. 获取源数据
此处随便举个例子,随手拿了个【蚂蚁金融语义相似度数据集】,详情见:https://www.modelscope.cn/datasets/modelscope/afqmc
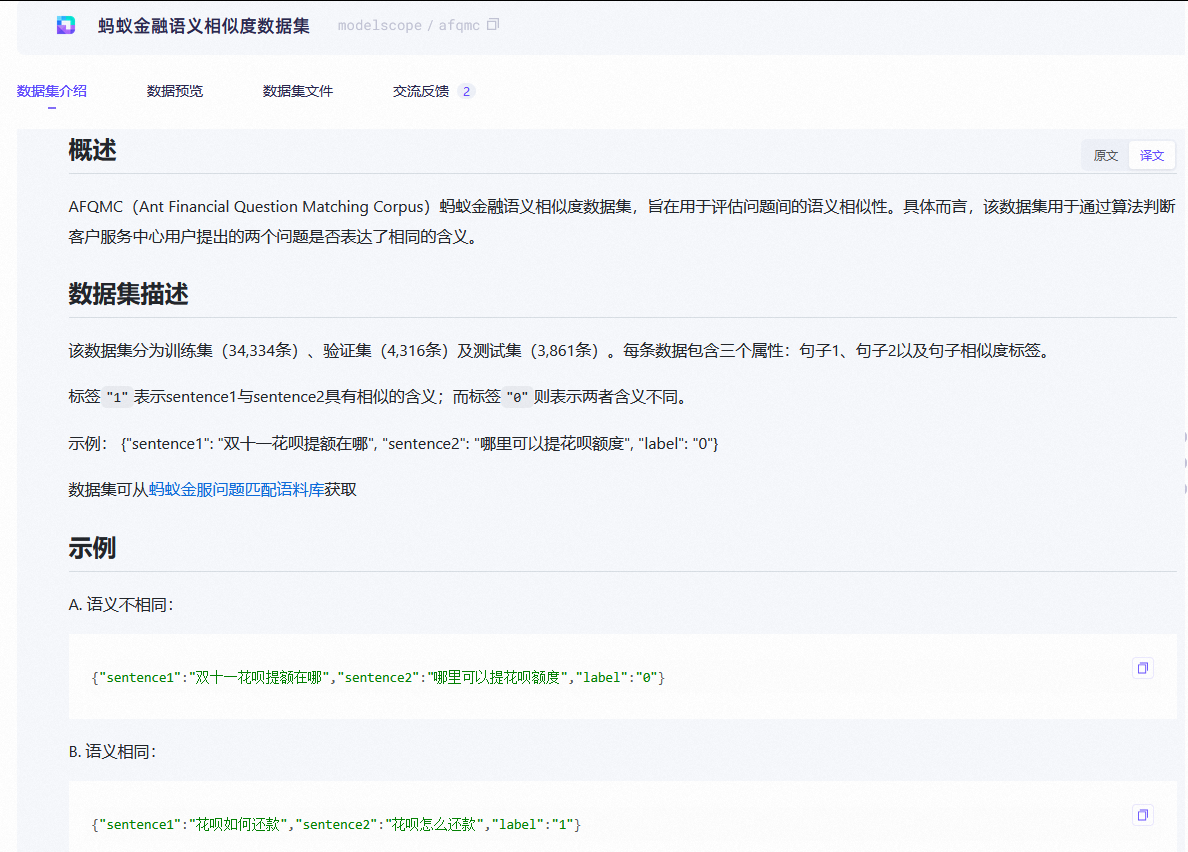
在【数据集文件】中下载【train.csv】,下载完成后,我可能可以得到如下数据,可以看出此数据集是用于评估问题间的语义相似性。
【sentence1 = 句子1】【sentence2 = 句子2】【label = 0表示两者语义不同、1表示语义相同】

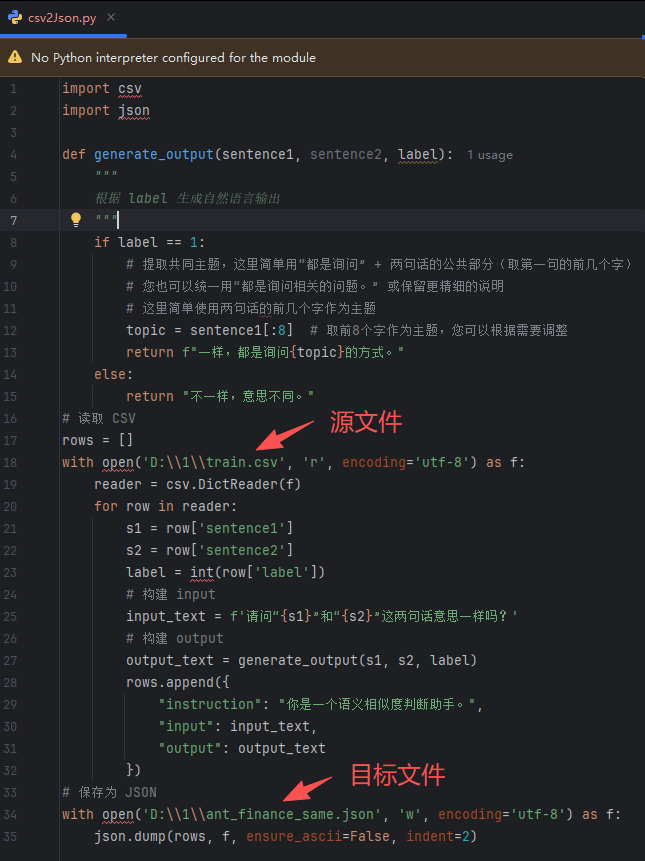
3.2. 编写转换脚本
我们通过脚本将csv转换成LLaMaFactory需要的json格式,脚本如下,不熟练的小伙伴可借助AI工具。
3.3. 生成数据集
在py脚本目录下执行【python csv2Json.py】可以得到目标文件json如下:
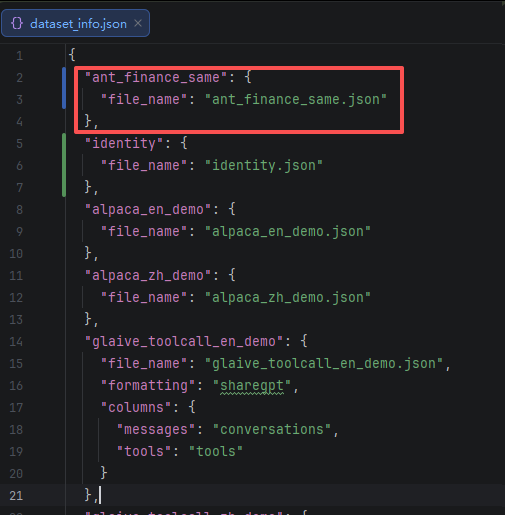
将生成的 【ant_finance_same.json】移动至【LLaMA-Factory】项目中的【data】文件夹中,再修改【dataset_info.json】加入刚才生成的json,其余保持不动;
dataset_info.json是LLaMaFactory中用于注册和管理数据集的配置文件。主要作用是配置数据集文件路径。
四、训练
4.1.加载并预览数据集
现在,我们就可以在【数据集】中选中刚才配置的数据,点击【预览数据集】后可以看到示例;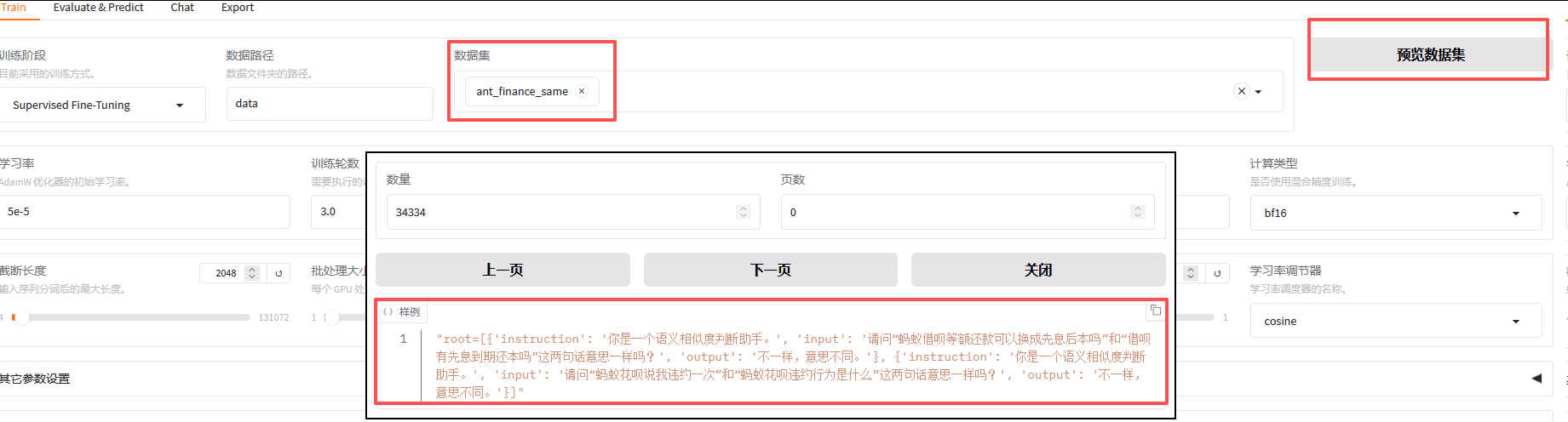
4.2.执行微调
点击【开始】微调模型,大约一两分钟后可以看到下方控制台输出日志,然后就是耐心的等待(GPU环境超过1小时无操作将触发自动关闭功能,要记得点下控制台);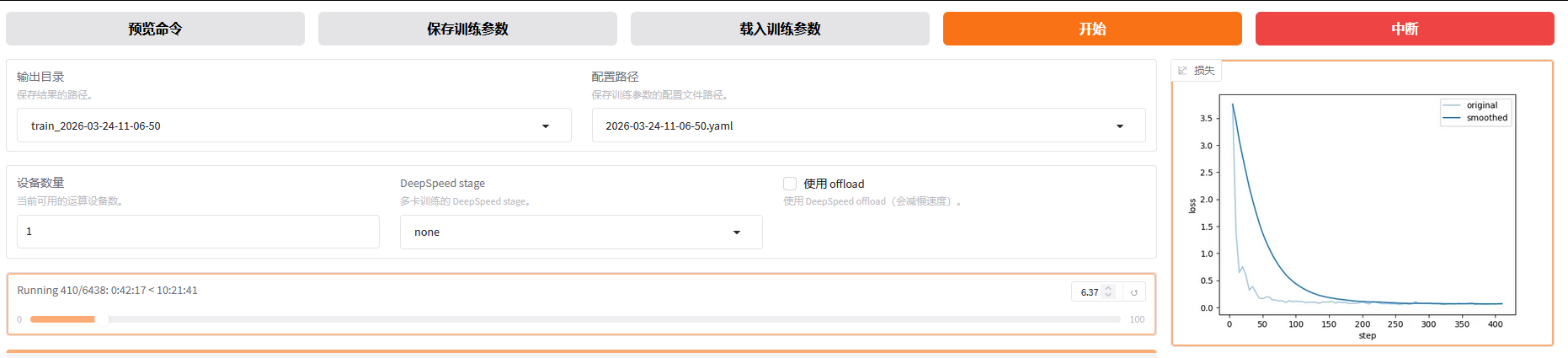
上图可知,此次训练需要大约10.5小时,但是单次实例连接时间最长是8小时,尽管可以中途中断,后续再继续,但是我执行1个小时后,环境直接卡死,什么都动不了。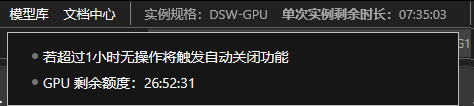
本次演示我还是希望能够走完一遍流程,于是将数据集做了份删减版。mini版数据集仅1000条数据,训练需要不到20分钟;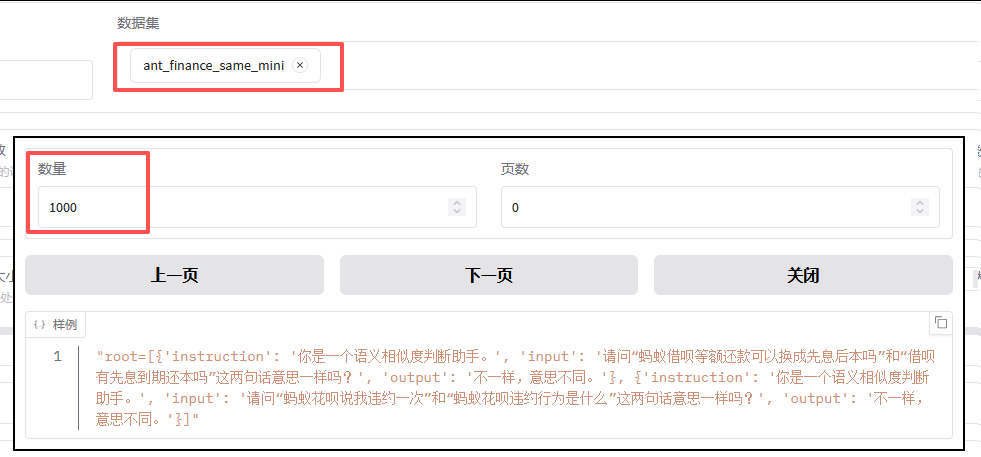

上图中右边的趋势图表示训练过程中损失值Loss随训练步数Step变化的曲线,用于监控模型的学习情况。
original原始曲线:每个记录点实际计算出的损失值,由于单批次数据存在随机性,曲线往往会有很多噪声毛刺;
smoothed平滑曲线:对原始损失进行移动平均或指数平滑后的曲线,能更加清晰地反映损失的整体变化趋势,滤除短期波动;
4.3.导出微调结果
等到【训练完毕】,我们可以在【检查点路径】找到刚才微调后的模型;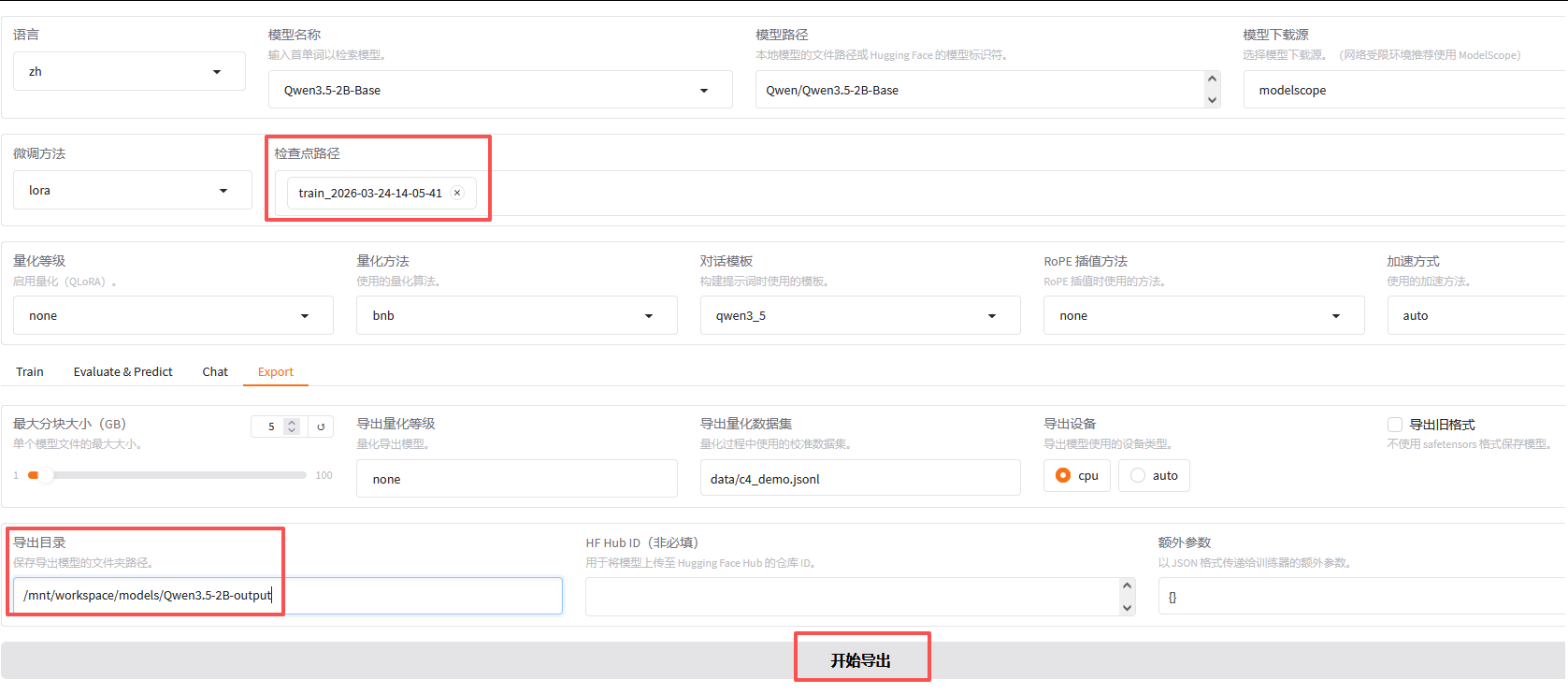
导出完成后,我们可以看到路径下对应的文件;
我们尝试加载微调后的模型,进行对话。
五、转换GGUF
为了能够让 ollama 或 llama.cpp 直接使用,需要将 Hugging Face 格式模型转换成GGUF格式的文件。
5.1.创建环境
为避免冲突,建议创建一个独立的Python环境:
python -m venv cppVenv
source cppVenv/bin/activate
克隆llama.cpp,该工具可转换GGUF:
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
pip install -r requirements.txt
5.2.执行转换
python convert_hf_to_gguf.py /mnt/workspace/models/Qwen3.5-2B-output --outfile /mnt/workspace/gguf/Qwen3.5-2B-output.gguf --outtype q8_0
Qwen3.5-2B-output 为【model.safetensors】文件所在路径;
--outtype q8_0 表示量化类型,默认输出f16格式;
执行过程中会出现异常:
File "/mnt/workspace/git_src/llama.cpp/cppVenv/lib/python3.11/site-packages/transformers/models/auto/tokenization_auto.py", line 1153, in from_pretrained
raise ValueError(
ValueError: Tokenizer class TokenizersBackend does not exist or is not currently imported.
原因是在合并模型时,无法正确加载模型的tokenizer导致的,通常是因为模型文件夹中的 tokenizer_config.json 配置缺少必要的tokenizer文件。
1.检查当前 tokenizer_config.json 内容:
cat /mnt/workspace/models/Qwen3.5-2B-output/tokenizer_config.json | grep tokenizer_class![]()
2.Qwen3.5-2B模型对应的tokenizer类是Qwen2Tokenizer,使用sed直接替换:
sed -i 's/"tokenizer_class": "TokenizersBackend"/"tokenizer_class": "Qwen2Tokenizer"/g' /mnt/workspace/models/Qwen3.5-2B-output/tokenizer_config.json
替换后再执行转换命令即可,最后可以得到GGUF文件。
六、总结
终于,我们在不花费一毛钱的前提下,完成了环境搭建到模型微调的整个流程。
欢迎继续关注后续的分享,我下次再来填坑。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 35
35 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)