AI人工智能-RAG方法-第十四周(小白)
RAG 不是替代大模型,而是 “给大模型装了一个可更新、可溯源的‘外置大脑’”—— 既保留了大模型的生成能力(能说人话、会总结),又解决了大模型的知识过时、容易瞎编、不可控的问题。不管是企业做智能客服、医生做辅助诊断,还是学生做学习辅导,只要需要 “基于权威资料的准确回答”,RAG 都是目前最实用的方案。
一、RAG到底是什么?
RAG是 Retrieval Augmengted Generation(检索增强生成)的缩写,核心逻辑特别好理解——就像我们写作文时,先查资料再动笔,而不是凭脑子硬记硬写。
简单说:AI回答问题时,不会只靠自己“记住”的知识,而是从外部文档库(或搜索引擎)里检索出和问题相关的“参考资料”,再把这些资料和问题一起传给大模型,让大模型基于“参考资料”生成回答。
它解决的核心问题是大模型的痛点——模型幻觉(就是AI瞎编答案)
二、RAG的核心流程
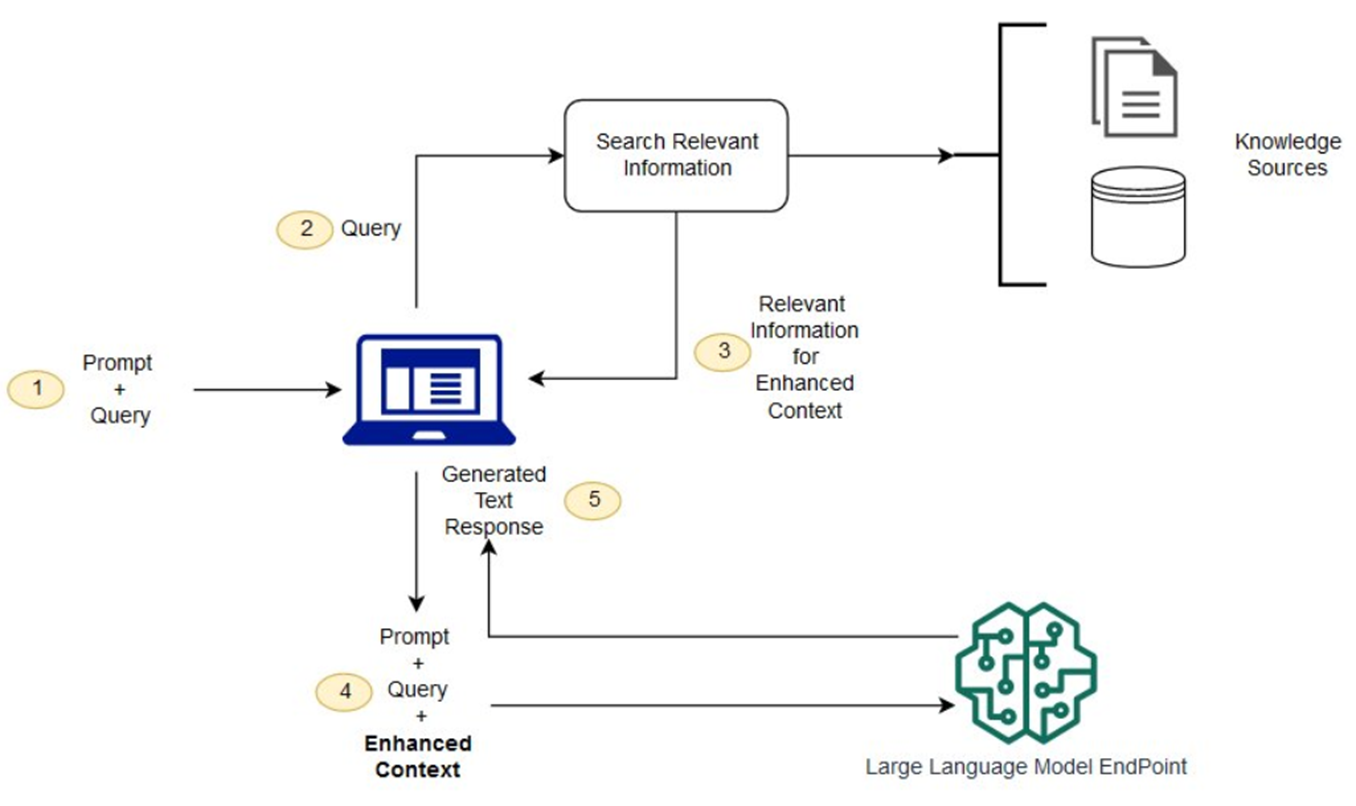
- 用户提问:比如“RAG怎么提升回答准确性”
- 检索相关信息:系统从文档库/搜索引擎里,找出和问题相关的文本片段(比如RAG的原理、优势文档)
- 增强上下文:把“用户问题+检索到的相关资料”整合起来,形成“增强版提问”
- 大模型生成:大模型只看“增强版提问”,基于里面的事实资料写回答
- 输出结果:不仅给答案,还能标注资料来源(比如“来自《RAG技术白皮书》第5页”)
三、RAG的5大核心优势(为什么要用RAG)
- 可扩展性强:不用把AI模型做的超大(省成本),想加新知识直接更新文档库,不用重新训练模型。比如公司出了新产品,直接把产品手册放进文档库,AI 就会回答相关问题,不用改模型。
- 准确性高:回答基于真实文档,少瞎编。比如医疗 AI 用 RAG 查《柳叶刀》论文,不会乱给治疗建议。
- 可控性好:知识能随时更、定制化。比如政策变了,替换文档库里的旧政策文档,AI 就会按新政策回答。
- 可解释性强:能告诉用户“答案来自哪”(比如某本书某页、某份表格),不像纯大模型“凭感觉”回答,适合需要溯源的场景(比如医疗、法律)
- 多功能性:能做回答、总结、聊天等。比如既能回答 “什么是 RAG”,也能总结 RAG 的优势,还能和用户聊 RAG 的应用场景。
四、RAG的难点
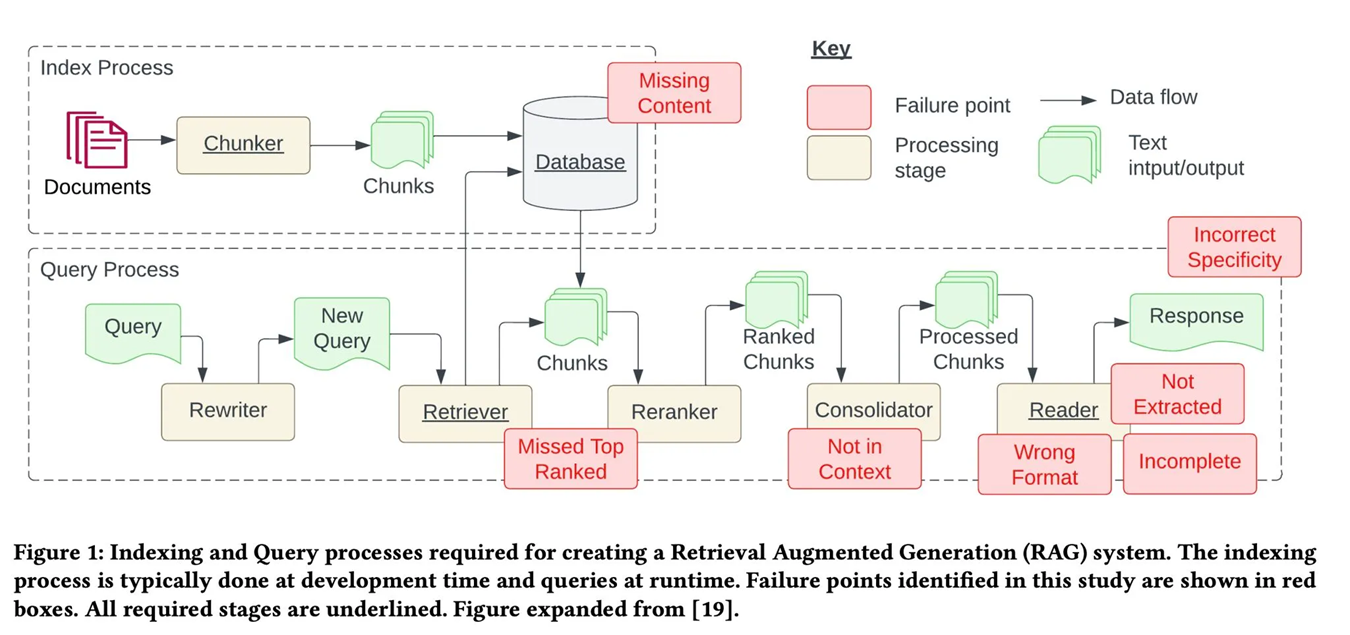
(图片里红色框是“容易出错的地方”,下划线是“必须做的步骤”,分两大流程)
1.索引阶段(相当于“整理资料”,开发时做)
- 文档拆分错了:比如把一个完整的知识点拆成两段,导致检索时找不到完整信息
- 向量转换不准:其纳入模型把文字转成向量时出错,语义相近的文字没被识别
- 数据库存错了:处理后的文档没有正确存入向量数据库,后续检索不到
2.查询阶段(相当于“找资料+用资料”,用户使用时做)
- 检索不到相关资料:比如用户问“RAG时检索模块怎么工作”,但文档库里没有相关内容
- 召回的资料不相关:嵌入模型找了一堆“看起来像”但实际无关的文档(比如把“RAG训练”当成"RAG检索")
- 重排序排错了:把不相关的文档排在前面,有用的排在后面
- 资料格式不对:检索到的资料是表格,但没有转换成文字,大模型看不懂
五、RAG的关键步骤:从文档到回答的全流程
第一步:文档数据预处理(把“杂乱文档”变“好用的资料”)
原始文档可能是PDF,Word,Excel,网页等,格式乱、内容杂,必须先“整理”,目标是3个:
- 结构化:每个片段都要有“来源标识” + “核心内容”
- 短文本化:每个片段100-500字,比如一本1000页的书,拆成2000个小片段
- 去冗余:删除广告、重复内容、格式标记,只留有用的意思
处理后是这样:
{
"source":"G技术白皮书.pdf(页码:5)",
"content":"RAG系统的检索模块需解决两个问题:如何快速找到与问题相关的文本,以及如何过滤噪声信息。"
},
{
"source":"产品信息表.xlsx(行ID:2)",
"content":"产品ID:P003;名称:智能音箱;价格:599元;库存:80台"
}第二步:文档拆分(Chunking)——怎么“切资料”才合理

- 固定长度切分:按字数切(比如每 300 字一段),简单省事,但可能把一个完整知识点切开(比如把 “猫喜欢吃鱼,狗喜欢啃骨头” 切成 “猫喜欢吃鱼” 和 “狗喜欢啃骨头”,没问题;但把 “猫喜欢吃鱼,尤其是海鱼” 切成 “猫喜欢吃鱼” 和 “尤其是海鱼”,就破坏语义了);
- 文章段落切分:按自然段落切,尊重文档结构,适合有清晰段落的文本(比如小说、散文);
- 循环递归切分:先按大分隔符切(比如标题),如果切出来的片段太大,再按小分隔符切(比如句子),直到符合长度要求,适合复杂文档(比如多栏 PDF);
- 语义向量切分:先把文字转成向量,语义相近的向量放一起形成片段,不会破坏语义,适合专业文档(比如医学论文);
- LLM 辅助切分:让 AI 帮忙切,AI 会判断 “哪里是语义边界”,切得最准但费算力;
- 后切分:先把整个文档转成向量,再拆分向量(不是先切文字再转向量),适合超长文档(比如 10 万字的报告)。
第三步:嵌入模型(Embedding Model)——把文字变成“电脑能懂的语言”
电脑看不懂文字,只能看懂 “数字向量”(比如 [0.12, 0.34, -0.05,...]),嵌入模型的作用就是 “文字→向量” 的转换器。
核心原理:语义相近的文字,向量距离越近。比如:
- “猫喜欢吃鱼” 的向量是 [0.1, 0.2, 0.3]
- “猫咪爱吃鱼” 的向量是 [0.11, 0.21, 0.32](距离近,语义像)
- “狗喜欢啃骨头” 的向量是 [0.8, 0.7, 0.6](距离远,语义不像)
流程:
- 文档嵌入:把处理好的文档片段转成向量,存进向量数据库(比如 Milvus、Pinecone);
- 问题嵌入:用户提问转成向量;
- 初步检索:数据库计算 “问题向量” 和 “所有文档向量” 的相似度,返回 Top10(或 TopN)最像的文档片段。
常见模型:OpenAI 的 text-embedding-ada-002、BGE 系列、Sentence-BERT(不用记名字,知道它们是 “文字转向量” 的工具就行)。
第四步:重排序模型(Reranker Model)——给“候选资料”挑最优
嵌入模型召回的 Top10 文档,可能有不相关的(比如用户问 “RAG 的检索模块”,嵌入模型召回了 “RAG 的训练方法”),这时候需要重排序模型 “精挑细选”。
核心原理:和嵌入模型 “单独看文字转向量” 不同,重排序模型会同时看用户问题和文档,理解两者的细粒度关联,给每篇文档打分(0-1 分),按分数排序。
流程:
- 输入:用户问题 “RAG 与传统问答的区别是什么?” + 嵌入模型召回的 3 篇文档;
- 打分:模型给 3 篇文档打分:B(0.92 分,“传统问答依赖自身知识,难处理时效性内容”)> A(0.85 分,“RAG 通过检索外部知识回答,无需改模型参数”)> C(0.61 分,“RAG 的检索模块用向量数据库”);
- 输出:按分数返回 Top3,作为大模型的 “参考资料”。
常见模型:轻量型(cross-encoder/ms-marco-MiniLM-L-6-v2,适合实时场景,比如智能客服)、高精度型(BAAI/bge-reranker-large,适合需要高准确性的场景,比如医疗)。
嵌入模型和重排序模型的关系:
- 嵌入模型:“广撒网”,快速从百万级文档里召回可能相关的(效率优先);
- 重排序模型:“精挑细选”,从召回的候选里挑最相关的(精度优先);
- 结合起来:又快又准,能处理海量文档的同时,保证答案质量。
流程总结:用户问题→嵌入模型→向量数据库召回 Top100→重排序模型→输出 Top5→大模型生成回答。
六、RAG+搜索引擎:让AI“懂实时、懂海量”
RAG不仅能用自己的文档库,还能结合搜索引擎,解决“文档库知识过时”“知识不够全”的问题,有两种用法:
1.搜索引擎当“外部知识库”
流程:
用户问题->调用搜索引擎获取最新资讯->预处理资讯(提取核心内容、去重、分块)->RAG检索+重排->大模型生成回答
例子:用户问 “2024 年人工智能领域的重大突破”,自己的文档库没有 2024 年的资料,就调用搜索引擎找 2024 年的 GPT-5、多模态模型相关资讯,处理后生成结构化总结。
2.RAG优化搜索引擎结果
流程:
搜索引擎返回10条网页链接->RAG处理链接(提取核心内容、按语义分类)->把链接变成“问题-答案”形式的摘要
例子:用户搜 “如何预防流感”,搜索引擎返回 10 个医学网站链接,RAG 把链接内容整理成 “症状识别→预防措施→治疗方法” 的结构化回答,而不是让用户一个个点链接看。
注意事项:
- 选权威来源:优先.gov(政府网站)、.edu(教育网站)或行业知名网站(比如医学领域的《柳叶刀》官网);
- 平衡性能:常见问题(比如 “如何退货”)缓存答案,不用每次都调用搜索引擎;
- 合规标注:告诉用户答案来自哪(比如 “参考某医学网站 2024 年 3 月文章”),遵守数据保护法规。
七、RAG的应用场景:在哪里能用到?
RAG 的核心是 “用外部知识增强 AI”,所以只要需要 “准确、权威、可溯源” 知识的场景,都能用,PPT 重点讲了 4 个行业:
1. 医疗健康行业(最需要 “准确”)
核心需求:知识专业(医学文献、指南)、不能出错(避免误诊)、个性化(患者病历不同)。
应用场景:
- 辅助诊断:医生输入 “患者症状 + 基因检测结果”,RAG 查相似病例、《柳叶刀》最新研究、WHO 治疗指南,辅助制定诊疗方案(例子:梅奥诊所、阿里健康);
- 患者自助问答:患者问 “糖尿病患者能吃苹果吗”,RAG 查《中国居民膳食指南》,给出答案并标注来源(例子:春雨医生、平安好医生);
- 医学教育:医学生问 “肺癌的鉴别诊断步骤”,RAG 查医学教材、手术视频脚本,生成教学内容(例子:哈佛医学院、丁香园)。
2. 电商与零售行业(最需要 “高效”)
核心需求:产品信息杂(规格、售后)、用户问题碎(“尺寸偏小吗”“多久发货”)、要实时信息(库存、活动)。
应用场景:
- 智能客服:用户问 “这款手机支持 5G 吗”,RAG 查产品详情页、实时库存,回答的同时,若库存不足推荐相似产品(例子:亚马逊、京东);
- 商家运营助手:商家想优化商品标题,RAG 查竞品热销关键词、平台规则,给出 “添加‘XX 材质’‘买一送一’” 的建议(例子:Shopify、拼多多)。
3. 教育行业(最需要 “个性化”)
核心需求:因材施教、知识结构化(教材、题库)、实时答疑(学生问题多样)。
应用场景:
- 智能学习辅导:学生问 “二次函数怎么求最值”,RAG 查教材、历年考题,给出步骤并推送同类练习题(例子:可汗学院、新东方);
- 教师备课辅助:老师备 “初中物理浮力” 课,RAG 查教学大纲、优质教案、实验视频,生成课堂设计(例子:好未来、麦格劳 - 希尔)。
4. 内容与媒体行业(最需要 “合规 + 高效”)
核心需求:素材多(文章、视频脚本)、创作快(快速写稿)、不违规(避免抄袭、敏感内容)。
应用场景:
- 内容创作:记者写 “AI 行业 2024 年度总结”,RAG 查历史报道、融资数据,生成初稿 + 关键事件时间线(例子:纽约时报、字节跳动);
- 版权审查:平台审核新上传的视频,RAG 查版权库,提示 “背景音乐未授权”“画面含敏感内容”(例子:华纳音乐、腾讯视频)。
5.金融行业(合规优先,实时性强,风险可控)
核心需求
金融行业对合规性要求极高(需符合监管政策、反洗钱规则),信息实时性强(市场行情、汇率、政策变动快),同时需要精准的风险控制(信贷评估、欺诈识别)和专业的金融知识支撑(产品规则、理财方案)。
应用场景
1.智能投顾与理财咨询
- 企业示例:高盛(Goldman Sachs)、蚂蚁集团(蚂蚁财富)、招商银行(招银理财)
- 功能:整合实时市场数据(股票、基金行情)、监管政策(如理财新规)、用户风险测评结果,为用户回答 “某基金的风险等级”“如何配置资产抵御通胀” 等问题,生成个性化理财方案,并标注 “参考 2024 年公募基金监管细则第 X 条”“数据来源:沪深交易所实时行情”。
2.风险管控与欺诈识别
- 企业示例:平安银行、支付宝(蚂蚁集团)、花旗银行
- 功能:检索用户交易历史、风控规则库(如反洗钱黑名单)、行业欺诈案例,实时监测 “大额异地转账”“异常消费频次” 等行为,提示 “该交易符合欺诈案例特征(参考案例 ID:FR202405)”,辅助风控人员决策;同时为信贷审批提供依据,比如检索企业征信报告、行业违约数据,回答 “某中小企业的信贷风险等级”。
3.客户服务与业务咨询
- 企业示例:工商银行、京东金融、微众银行
- 功能:整合银行产品手册(如信用卡权益、贷款申请条件)、业务流程(如开户、转账限额)、费率标准,回答用户 “信用卡分期利率多少”“公积金贷款怎么申请” 等问题,若用户符合业务条件,自动推送申请入口;同时处理售后疑问,如 “理财产品亏损了怎么办”,结合产品合同条款给出合规解释。
4.合规审查与政策解读
- 企业示例:摩根大通、中信证券、证监会信息科技中心
- 功能:检索金融监管政策(如《证券法》修订内容、央行货币政策)、行业合规标准,为金融机构生成 “2024 年反洗钱合规自查清单”,或解读 “最新房贷利率调整政策对业务的影响”,确保机构业务操作符合监管要求,避免违规风险。
6.法律行业(权威溯源、检索高效、文书规范)
核心需求
法律行业依赖权威的法律依据(法条、司法解释、判例),需要从海量法律文献中快速精准检索相关内容,同时要求法律文书格式规范(合同、起诉状),且所有结论需可溯源(明确法律依据来源)。
应用场景
1.法条与判例检索
- 企业示例:北大法宝、LexisNexis(律商联讯)、盈科律师事务所
- 功能:整合全国人大发布的法律条文、最高法判例库、司法解释文件,律师输入 “民间借贷纠纷中利息上限的规定”,RAG 快速返回《民法典》第 680 条、相关判例(如 “(2024) 最高法民终 XX 号”),并标注 “法条来源:《民法典》(2021 年施行)”“判例来源:中国裁判文书网”,辅助律师快速构建案件论据。
2.法律文书生成与审查
- 企业示例:金杜律师事务所、法大大、智谱 AI(法律版)
- 功能:检索各类标准文书模板(如劳动合同、借款合同)、法律风险点库(如合同无效情形),为律师 / 企业生成 “股权质押合同” 初稿,自动包含核心条款(如质押期限、违约责任);同时审查已拟文书,提示 “该条款可能违反《劳动合同法》第 19 条(试用期约定过长)”,并给出修改建议。
3.合规咨询与风险预警
- 企业示例:德勤(法律合规部)、华为法律部、腾讯合规中心
- 功能:检索行业合规政策(如数据安全法、反垄断法)、企业内部合规手册,为企业回答 “用户数据跨境传输需要哪些合规手续”“企业合并是否构成垄断” 等问题,生成 “合规风险评估报告”,明确 “高风险点:未获得用户数据授权跨境传输” 及应对措施。
4.普法与公众法律咨询
- 企业示例:中国法律服务网、百度法律、华律网
- 功能:基于通俗化的法律解读资料(如《民法典》科普手册)、典型案例,回答公众 “离婚时财产怎么分割”“被辞退后能要多少赔偿金” 等问题,用生活化语言解释法律依据,同时提示 “具体案件需结合实际情况,建议咨询专业律师”。
7.制造业与工业行业(技术密集、运维实时、协同高效)
核心需求
制造业涉及复杂的技术文档(设备手册、维修指南),需要实时响应生产运维需求(设备故障排查),同时依赖供应链信息协同(物料库存、订单进度)和严格的质量管控(生产标准、检测数据)。
应用场景
1.设备运维与故障排查
- 企业示例:西门子(Siemens)、三一重工、海尔卡奥斯(COSMOPlat)
- 功能:整合设备操作手册、维修案例库(如 “机床主轴故障处理记录”)、传感器实时数据,工人 / 工程师输入 “机床加工精度偏差大”,RAG 返回匹配的故障原因(如 “刀具磨损”“参数设置错误”)、处理步骤(如 “更换刀具后重新校准参数”),并标注 “参考设备手册第 3 章第 2 节”“相似案例:2024 年 5 月上海工厂故障处理记录”,缩短故障停机时间。
2.供应链与生产协同
- 企业示例:富士康、宁德时代、博世(Bosch)
- 功能:检索供应链数据库(物料库存、供应商资质)、生产计划(订单交付周期)、物流信息,回答 “某型号电池物料库存还能支撑多少订单”“供应商 A 的交货延迟是否影响生产线” 等问题,辅助生产管理者调整计划;同时为采购人员提供 “物料替代方案”,如 “物料 B 缺货时,可选用物料 C(参考技术参数匹配表第 5 页)”。
3.生产质量管控与标准查询
- 企业示例:丰田汽车、格力电器、中国商飞(C919 生产链)
- 功能:整合行业生产标准(如 ISO 9001)、企业内部质量检测规范、产品缺陷案例,实时检索生产过程中的检测数据,提示 “某批次零部件尺寸偏差超出标准(参考 GB/T XXXX-2023 第 4.3 条)”,并追溯偏差原因(如 “模具磨损”);同时为质检人员提供 “缺陷判定标准”,如 “表面划痕≤0.5mm 为合格”。
4.技术培训与知识传承
- 企业示例:GE(通用电气)、徐工集团、比亚迪工业大学
- 功能:检索设备操作视频脚本、技术教材、老工程师经验文档(如 “焊接工艺技巧”),为新员工生成 “机器人焊接操作培训手册”,包含操作步骤、安全注意事项、常见问题解答;同时支持 “经验问答”,如 “如何解决焊接时的气孔问题”,返回老工程师的实操经验和相关技术标准。
八、RAG的延伸技术
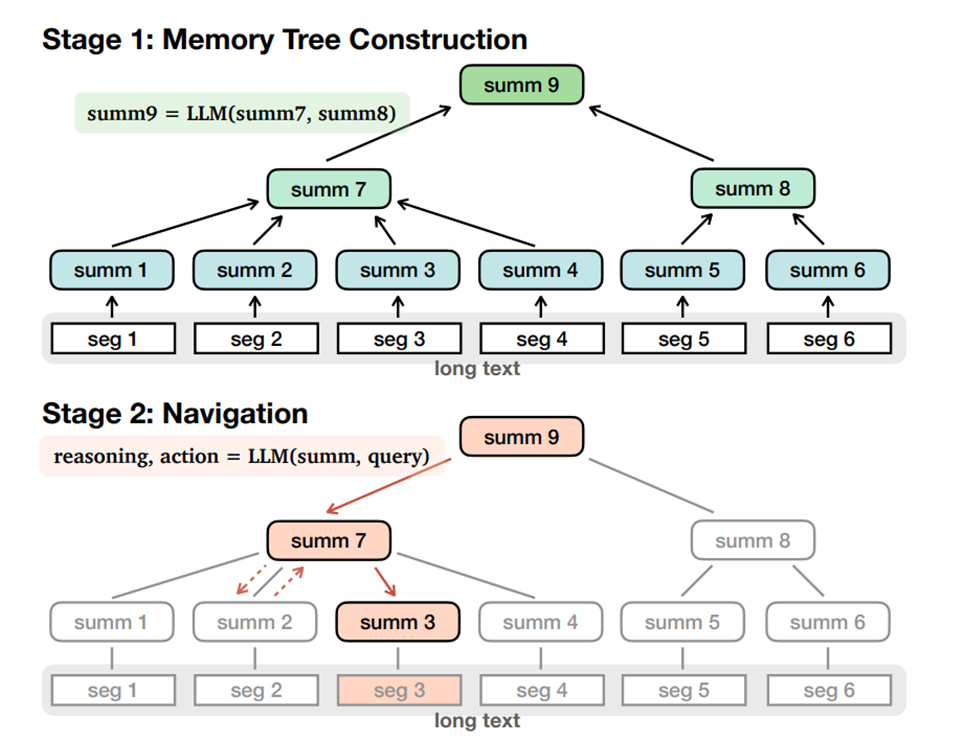
MemWalker:处理超长文本(比如 10 万字的报告),先把文本拆成小片段,再建 “记忆树”(片段摘要→层级汇总),用户提问时,先导航到记忆树的相关层级,再找具体片段,不会遗漏关键信息;
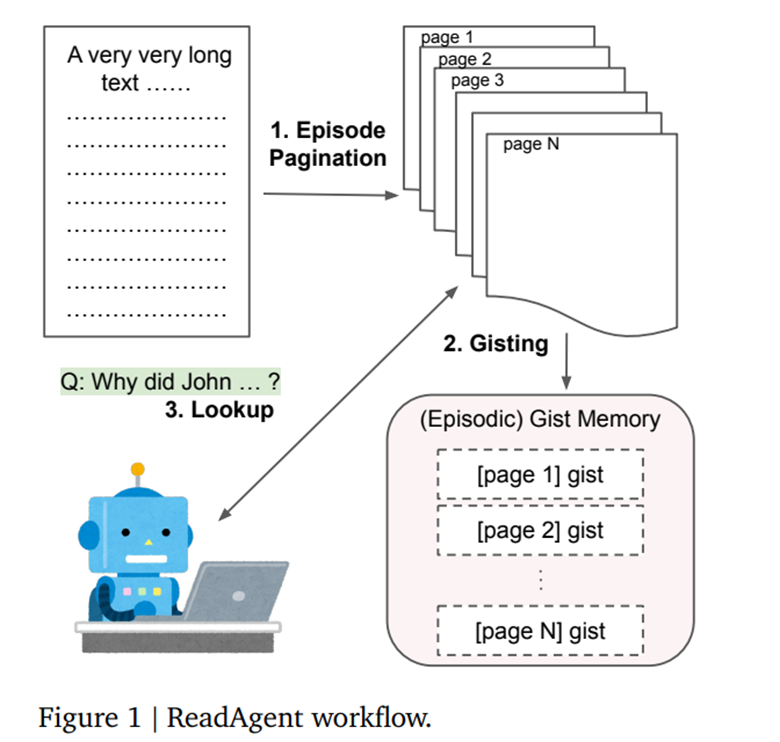
ReadAgent:像 “AI 读者”,先把长文本按页拆分,生成每一页的 “摘要”(gist),用户提问时,先找相关的摘要页,再从页里找具体内容,适合处理多页文档(比如 PDF 书籍);
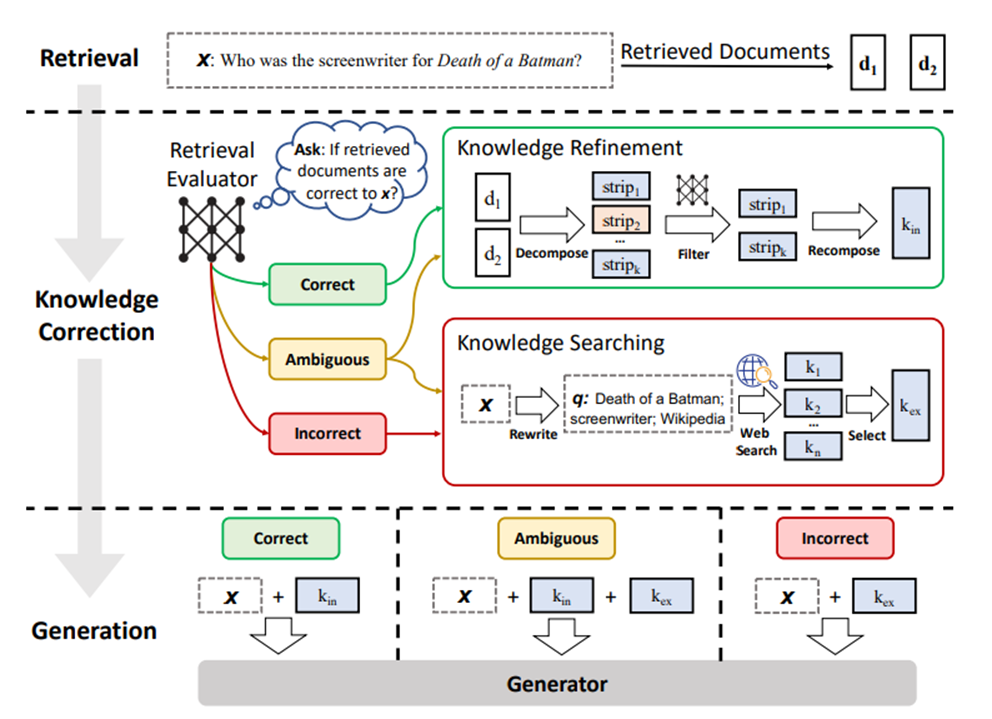
Corrective RAG:能 “自我纠错”,如果生成的回答有错误,会重新检索资料、修正答案;
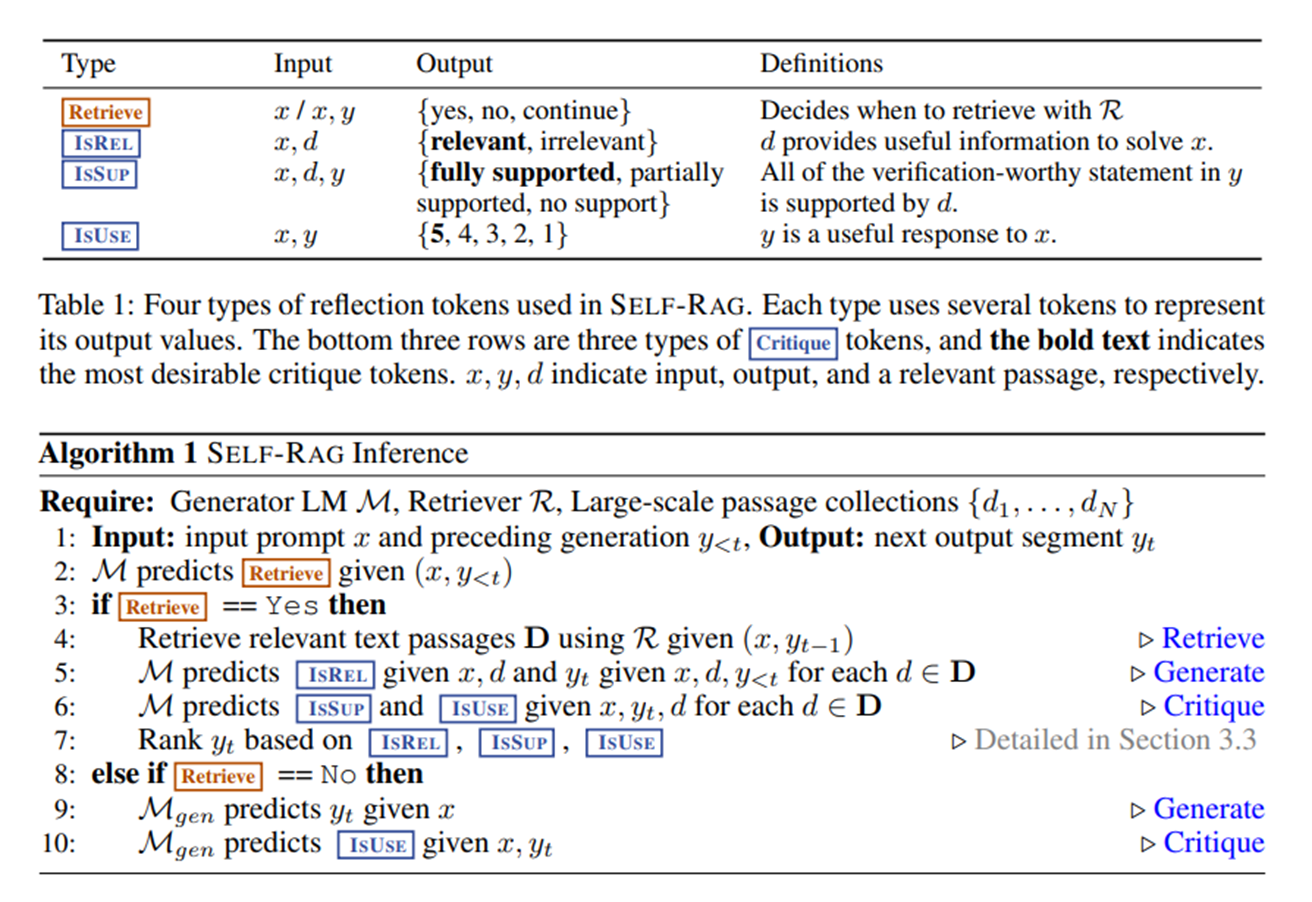
Self-RAG:让 AI 自己 “判断要不要检索”“检索的资料有没有用”“回答好不好用”,比如用户问一个简单问题(“1+1 等于几”),AI 判断 “不用检索,直接回答”;如果问复杂问题(“2024AI 突破”),AI 判断 “需要检索”,检索后还会自己检查 “资料相关吗”“回答有用吗”,全程自主决策。
总结:RAG 的核心价值
RAG 不是替代大模型,而是 “给大模型装了一个可更新、可溯源的‘外置大脑’”—— 既保留了大模型的生成能力(能说人话、会总结),又解决了大模型的知识过时、容易瞎编、不可控的问题。
不管是企业做智能客服、医生做辅助诊断,还是学生做学习辅导,只要需要 “基于权威资料的准确回答”,RAG 都是目前最实用的方案。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)