Tuna:超越show-o2,为多模态大模型构建“完美”的级联统一视觉编码器
在迈向通用人工智能(AGI)的路径上,**原生统一多模态模型(Native Unified Multimodal Models, UMMs)**被寄予厚望。这类模型试图在一个单一的框架内,无缝地完成文本、图像、视频的联合理解与生成。
一、引言:原生多模态大模型面临的核心困境
在迈向通用人工智能(AGI)的路径上,**原生统一多模态模型(Native Unified Multimodal Models, UMMs)**被寄予厚望。这类模型试图在一个单一的框架内,无缝地完成文本、图像、视频的联合理解与生成。
然而,在这个宏大的愿景面前,研究者们遇到了一个极其棘手的基础性问题:我们该如何表达视觉信息?
视觉表示(Visual Representations)是多模态模型的“词汇表”。当前的 UMM 领域存在两条截然不同的路线,但各自都陷入了瓶颈:
- 解耦表示路线(Decoupled Representations): 比如 BAGEL 和 Mogao。它们为“理解”和“生成”任务分别训练了不同的视觉编码器。为了处理这些不同的特征,模型通常需要引入复杂的 MoE(混合专家)架构来进行路由。这不仅显著增加了参数量与训练推理成本,更致命的是,不同编码器提取的特征在空间压缩比(如 16x 对比 8x)、时间压缩比以及通道维度上格式极不兼容,导致了严重的“表示冲突(Representation conflicts)”。
- 统一表示路线(Unified Representations): 比如 Chameleon、Transfusion、Harmon 和 Show-o2。它们试图用同一种表示通吃理解与生成任务。然而,现有的统一设计往往“偏科”——要么偏袒理解任务,要么偏袒生成任务。
**读完这篇文章,你会获得怎样的认知收益?**本文将深度拆解一篇近期极具启发性的工作:TUNA。你将清晰地理解,为什么离散的视觉 Token 正在被抛弃?为什么 TUNA 仅仅通过改变 VAE 与特征编码器的“连接顺序(早期级联)”,就能完美调和理解与生成之间的矛盾?以及,在处理高维度的视频序列时,TUNA 是如何通过张量重塑(Reshape)来规避计算量爆炸的。

图表解析: 本图概括了 TUNA 全面的多模态能力,涵盖图像/视频生成、图像编辑以及跨模态理解。核心结论: 这直观地证明了一个平衡的“统一视觉表示”能够打破任务壁垒——让单一模型在保留深刻理解能力的同时,输出极高保真度的生成结果。这也是本文接下来要拆解的核心技术体系。
二、直击痛点:早期级联 VS 后期融合
为了理解 TUNA 的核心贡献,我们必须先看清现有统一表示技术(如 Show-o2)的结构局限。
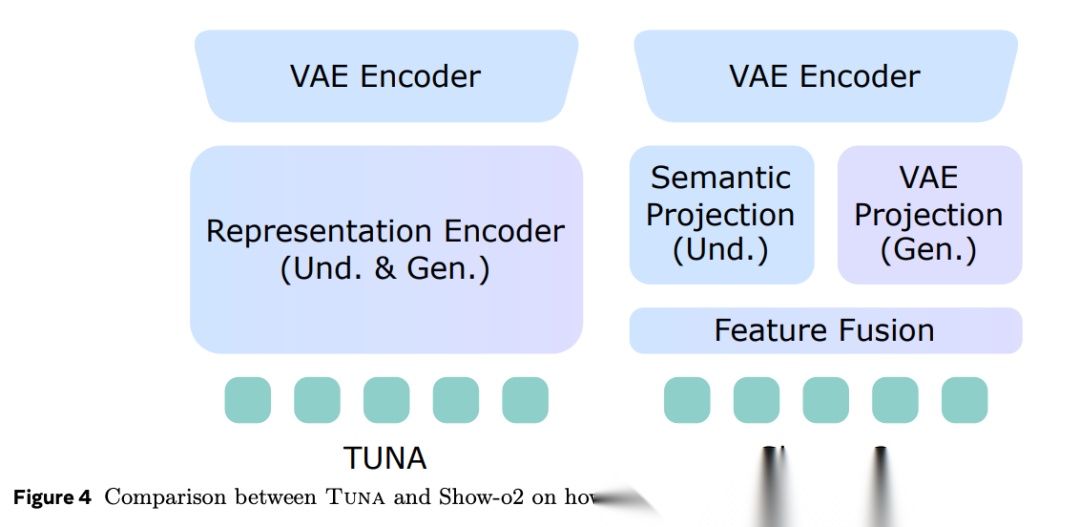
图表解析: 此图对比了 TUNA 与前作 Show-o2 在构建“统一视觉表示”时的结构差异。Show-o2 采用的是“双分支并联+后期融合”的结构;而 TUNA 采用的是“串联的早期级联”结构,将特征编码器直接接在 VAE 编码器之后。核心结论: 不同的连接顺序决定了多模态特征的融合质量。
**现有设计的局限与失效原因:**Show-o2 的双分支设计初衷是兼顾两头,但实际效果却存在明显短板。由于依赖特征融合层(Feature Fusion)在最后关头进行缝合,模型在端到端训练时,融合层不可避免地会产生倾向性。最终的特征极度偏向语义理解,从而大幅削弱了图像生成的像素级保真度。
TUNA 彻底抛弃了这种双分支设计。它的逻辑极其简洁:连续的 VAE 潜在空间(Latent space)本身就包含了极高保真度的视觉细节,且足够支撑语义理解。 因此,只要在这个连续空间上直接串联一个特征编码器,理解与生成的监督信号就能在编码器的每一层发生深度的“早期融合”。
三、TUNA 的全局架构:端到端的数据流转
理解了核心设计逻辑,我们来看看 TUNA 是如何将其落地成一个完整的端到端架构的。
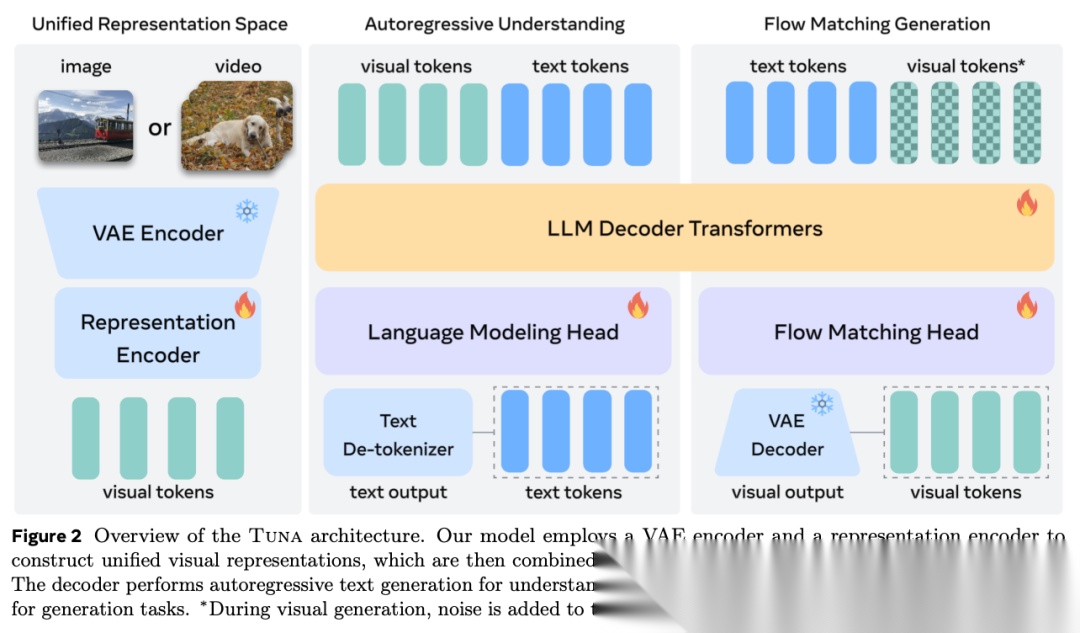
图表解析: 这是 TUNA 的全局架构图,数据流从左至右划分为三个核心区域:统一表示空间的构建(左侧)、自回归理解(中上)与流匹配生成(右侧)。核心结论: 通过一个共享的 LLM 引擎,模型可以同时驱动语言建模头和流匹配头,实现原生层面的任务统一。
架构由以下四个关键模块深度耦合而成:
1. VAE 编码器 (VAE Encoder)
- 机制: 采用冻结的 Wan 2.2 3D 因果 VAE 编码器。它的任务是将原始图像或视频压缩成一个连续的潜在表示。
- 为什么有效: 离散化(如 VQ-VAE)会丢失细节。保留连续的潜在空间,是 TUNA 实现高保真视觉生成的基础。
- 行为细节: 在视觉生成训练中,模型会对输出的潜在表示加入不同程度的噪声(时间步 );但在多模态理解任务中,输入时间步被严格固定为 ,确保大模型看到的是绝对干净、清晰的视觉特征。
2. 特征编码器 (Representation Encoder)
- 机制: TUNA 使用了强大的 SigLIP 2 视觉编码器作为核心引擎。它直接接收 VAE 输出的潜在表示,提取其中的高级语义,输出最终的 Visual Tokens。
- 关键改造: 为了解决 VAE 压缩后的特征图与 SigLIP 2 原本输入尺寸不匹配的问题,TUNA 将 SigLIP 2 默认的 16x16 补丁嵌入层(Patch embedding)替换为一个随机初始化的 1x1 嵌入层,并在其后加入了一个两层 MLP 连接器进行维度统一。
3. 多模态大语言模型解码器 (LLM Decoder Transformers)
- 机制: 采用 Qwen-2.5 (1.5B 或 7B) 作为推理大脑。它接收 Visual Tokens 与 Text Tokens 的拼接序列。为了处理复杂的交错指令与视觉内容,TUNA 在这里引入了多模态 3D-RoPE(旋转位置编码)。
4. 双路输出头 (LM Head & Flow Matching Head)
- 机制: 如果当前任务是“理解”,则激活语言建模头(Language Modeling Head),以自回归的方式预测文本 Token;如果任务是“生成”或“编辑”,则全序列被送入随机初始化的流匹配头(Flow Matching Head),预测流匹配的速度(Velocity),最后通过 VAE Decoder 还原出真实的视觉像素。
四、理解交错信号:注意力掩码的巧妙设计
在单一的 LLM 中同时处理自回归文本生成和扩散流匹配视觉生成,会引发注意力机制(Attention)的底层冲突。文本是线性的,而视觉是全局的。
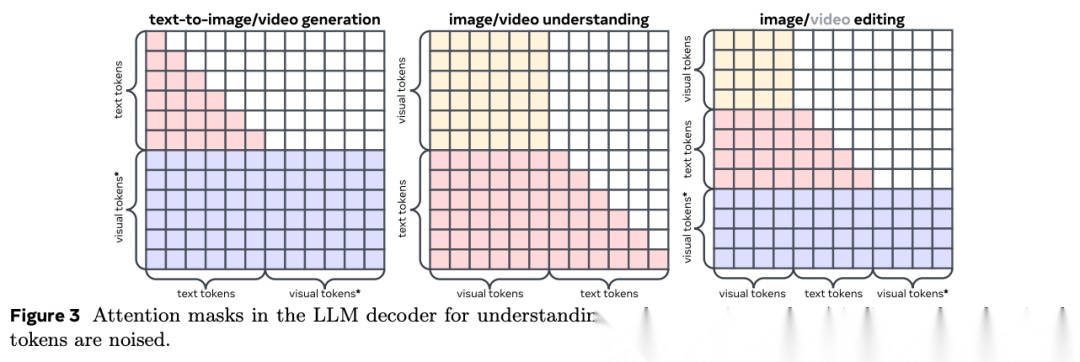
图表解析: 此图展示了 LLM 解码器在面对“生成”、“理解”以及“编辑”任务时的注意力掩码(Attention Masks)分配策略。红色区域代表因果掩码,蓝色/黄色区域代表双向掩码。核心结论: 通过为文本和视觉模态施加不同的注意力约束,TUNA 成功在一个自回归 Transformer 架构中兼容了扩散流匹配机制。
核心机制分解:无论执行什么任务,文本 Token 始终被强制使用因果注意力掩码(只能看到前面的词)。这保证了 LLM 强大的自回归文本生成能力不受破坏。而对于视觉 Token,TUNA 统一施加了双向注意力掩码。因为图像和视频本质上是空间或时空结构的整体,视觉 Token 必须拥有全局感受野,才能准确捕捉像素间的关联上下文。
五、张量重塑:如何高效处理高维视频序列?
图像可以通过切分 Patch 变成一维序列,但视频多了一个“时间帧”维度。如果直接把所有视频帧的潜在特征展平送入 SigLIP 2,序列长度会发生爆炸,导致计算量失控。
TUNA 给出了一套精确的张量重塑(Reshape)方案,仅用三行公式就化解了视频特征提取的计算瓶颈。
首先,TUNA 对输入的 VAE 潜在特征 进行维度重塑:
公式解析: 这里的 是批次大小, 是通道数, 是视频帧数, 和 是高和宽。这个重塑操作直接将“帧维度 ”融合到了“批次维度 ”中。在逻辑上,一段连续的视频被转换成了“一批独立的图像”。
接着,将重塑后的特征 送入修改后的特征编码器 和映射层 :
公式解析: 这里的 是隐藏层维度。这是控制计算量的核心步骤。因为前置的重塑操作,特征编码器 会被强制在每一个包含 4 帧的独立窗口上分别执行注意力计算,而不是在动辄数百帧的全局长序列上计算,从而呈指数级降低了显存占用和计算复杂度。
最后,将提取出的特征恢复回视频的序列维度:
公式解析: 恢复批次 和序列长度 ,打包送入后续的 LLM。这一系列张量形变,让 TUNA 以处理静态图像的算力代价,高效完成了视频高级特征的提取。
六、三阶段训练法则:逐步唤醒多模态潜能
TUNA 采用了严谨的三阶段训练策略,核心逻辑是“先对齐基础特征,再解锁复杂推理”。
- 阶段一:统一表示与生成头预热。 冻结庞大的 LLM,仅使用图像描述和文本到图像生成数据,专门更新特征编码器和流匹配头。这确立了视觉表示的基础对齐能力。
- 阶段二:全模型联合预训练。 解冻 LLM,开启端到端训练。随后引入难度更高的图像指令遵循、图像编辑以及视频描述数据,建立深度的跨模态关联。
- 阶段三:监督微调(SFT)。 使用 的低学习率,在高质量指令微调数据集上进行精雕细琢。(注:由于视频训练计算成本极其高昂,研究团队在 7B 变体中舍弃了视频数据的训练,以保证基础验证的推进。)
七、实验与对比:统一架构的性能突破
TUNA 的实验数据不仅验证了其性能,更凸显了统一表示路线的巨大潜力。
1. 图像与视频理解
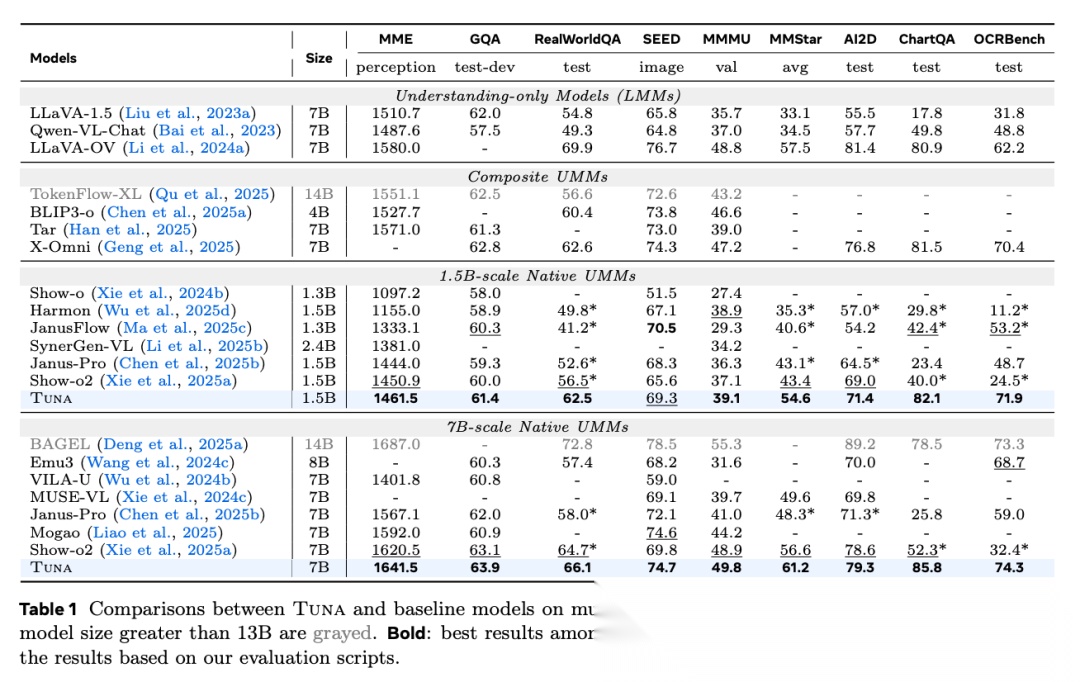
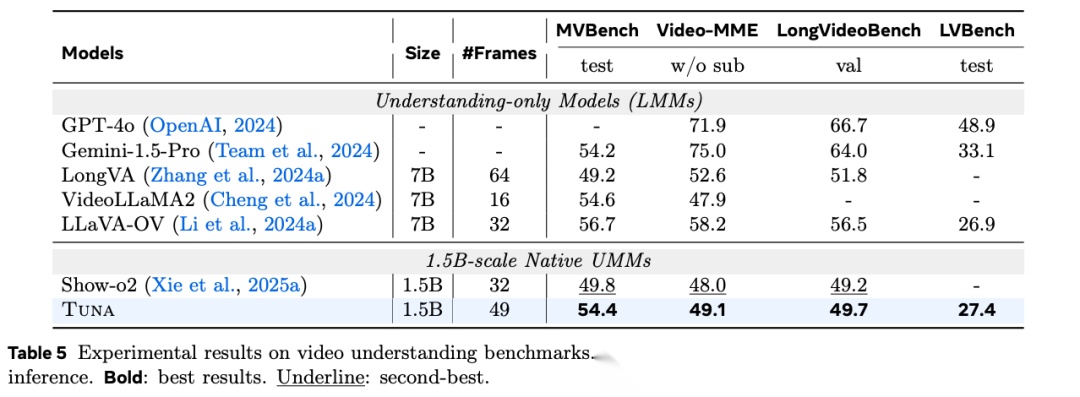
图表解析: 表 1 和表 5 分别展示了 TUNA 在核心图像理解基准(如 MME, MMMU, MMStar)和视频理解基准(如 MVBench, LVBench)上的得分。核心结论: 1.5B 和 7B 变体均在同规模模型中表现优异。特别是 TUNA 7B 取得了 61.2 的 MMStar 得分和 49.8 的 MMMU 得分;而 1.5B 变体凭借张量重塑机制,在 MVBench 上(54.4)超越了采用双分支设计的 Show-o2(49.8),证明其视觉表示空间保留了极高浓度的语义信息。
2. 图像与视频生成
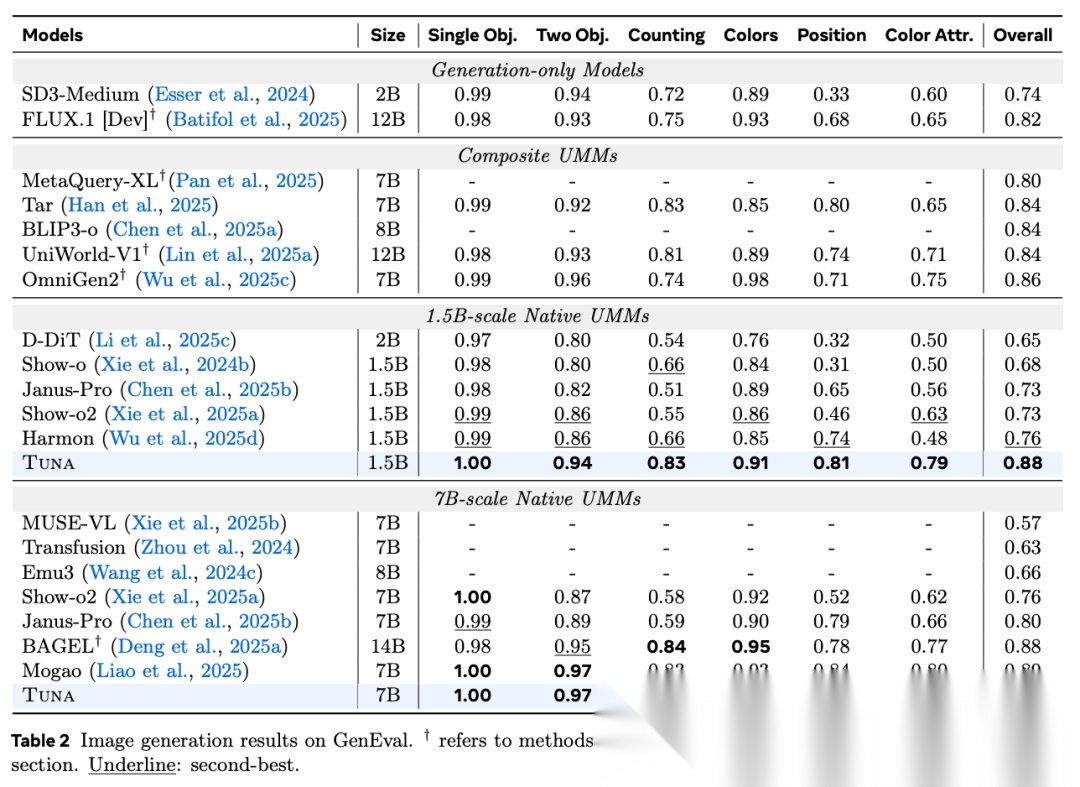
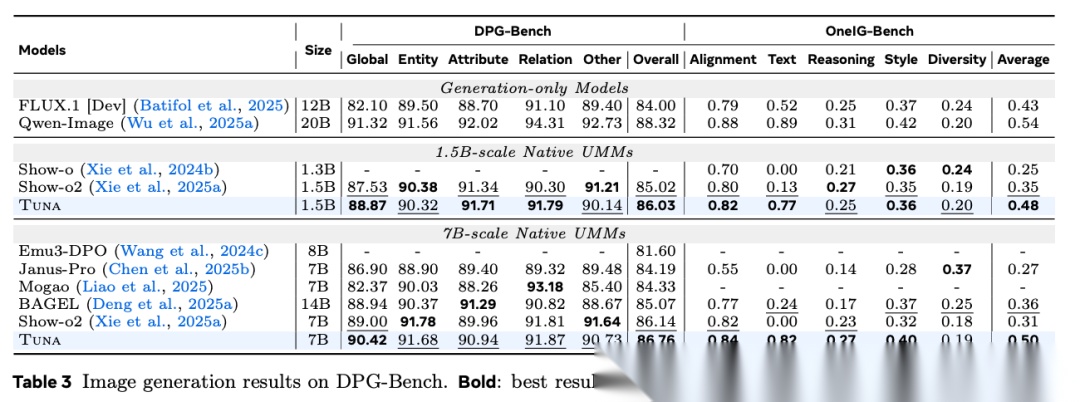
图表解析: 表 2、表 3 评估了图像生成质量(涵盖 GenEval, DPG-Bench, OneIG-Bench)。核心结论: TUNA 7B 在 GenEval 取得 0.90 分,在 DPG 取得 90.73 分。值得注意的是,在 OneIG-Bench 的“文本渲染(Text)”维度上,TUNA 7B 拿下了 0.82 的高分,这意味着模型能极其精准地将文本指令渲染为画面文字,这是其特征具备深度语义对齐能力的有力证据。
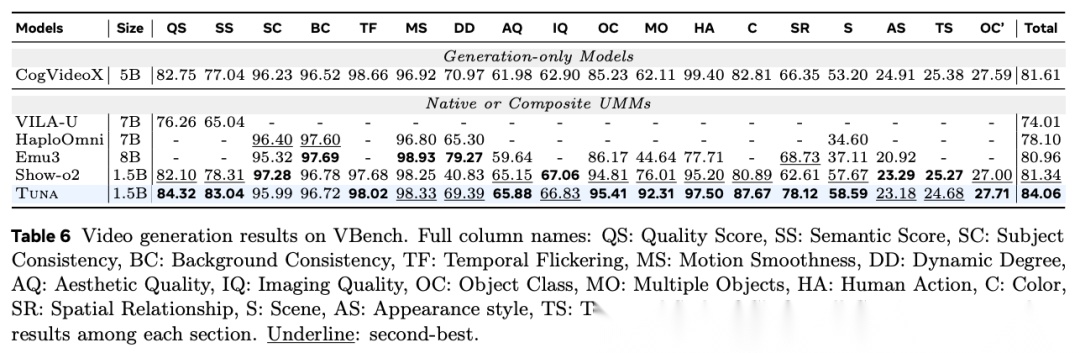
图表解析: 表 6 为 VBench 视频生成基准测试结果。核心结论: 1.5B 变体取得了 Total 84.06 的得分,大幅超越了包含视频生成能力的现有 UMM(如 Show-o2 的 81.34),证明了其连续潜在空间对视频生成的极高保真度。
3. 图像编辑能力
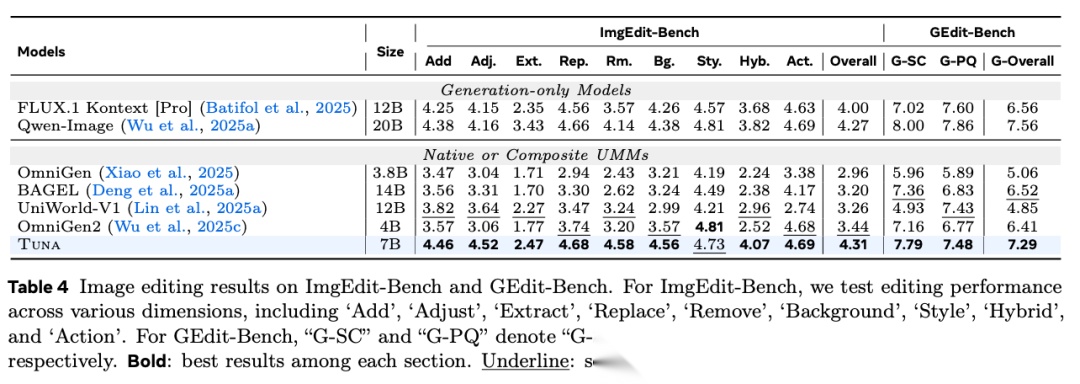
图表解析: 此表展示了 ImgEdit-Bench 和 GEdit-Bench 上的图像编辑任务评估。核心结论: TUNA 7B 分别取得了 4.31 和 7.48 的成绩,在所有原生和复合 UMM 中排名第一,综合编辑能力已逼近强大的纯生成模型 Qwen-Image。
八、消融分析:探寻机制背后的因果律
TUNA 为什么能在多个维度取得领先?我们在消融实验中寻找量化答案。
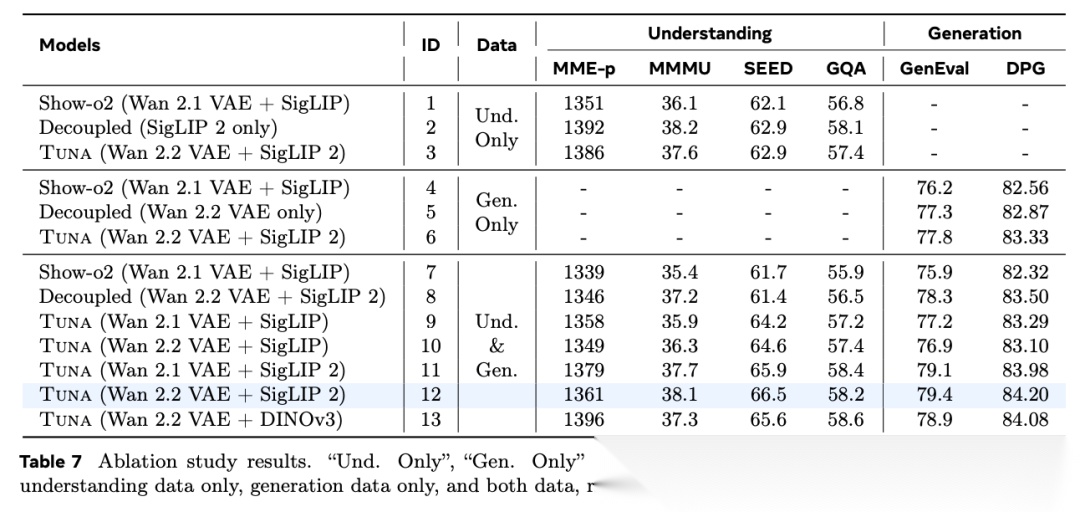
图表解析: 这是一组控制变量的消融数据表,详细对比了不同架构和训练数据组合对最终性能的影响。核心结论:
- 统一表示优于解耦表示: 对比 Model 12(统一表示)与 Model 8(解耦表示),Model 12 在 MMMU(38.1 vs 35.4)和 GenEval(79.4 vs 75.9)上全面占优,证实了解耦表示会引发特征冲突。
- 理解与生成的正向协同: 对比仅用理解数据训练(Model 3)、仅用生成数据训练(Model 6)以及联合训练(Model 12)。联合训练的 Model 12 在理解和生成指标上均实现了反超,证明在统一表示空间内,两大任务能产生正向协同增益。
- 预训练编码器的重要性: 对比 Model 10 (SigLIP)、13 (DINOv3) 和 12 (SigLIP 2)。数据表明更强的预训练编码器能拔高框架上限,而 SigLIP 2 在生成质量上明显优于参数量更大的 DINOv3。
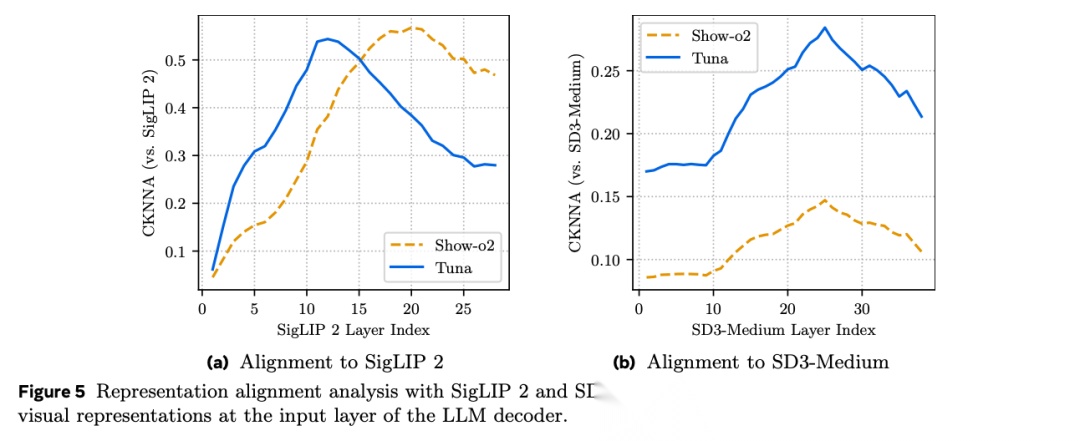
图表解析: 本图对比了 TUNA 和 Show-o2 提取的特征,与纯理解模型(SigLIP 2)和纯生成模型(SD3-Medium)中间层特征的 CKNNA 对齐分数。核心结论: 左图 (a) 显示两者对齐 SigLIP 2 的分数都很高。但右图 (b) 揭示了关键差异:TUNA 对齐 SD3-Medium 的分数远高于 Show-o2。这表明 Show-o2 的后期融合机制导致特征丢失了生成所需的结构信息,而 TUNA 的早期级联成功学习到了平衡理解与生成的无偏向“视觉母语”。
九、直观案例:复杂多模态任务的实际表现
为了将抽象的指标转化为直观的认知,我们来看看 TUNA 在复杂现实任务中的生成结果。

图表解析: 图像生成的定性对比。核心结论: 在生成“白板上的文字”时,TUNA 是唯一准确将底线画在“with everyone”下方的模型,并精准生成了指令要求的黑色架子及其物品。强大的文本渲染和空间成分理解能力,直接证明了其视觉-语言特征的深度耦合。
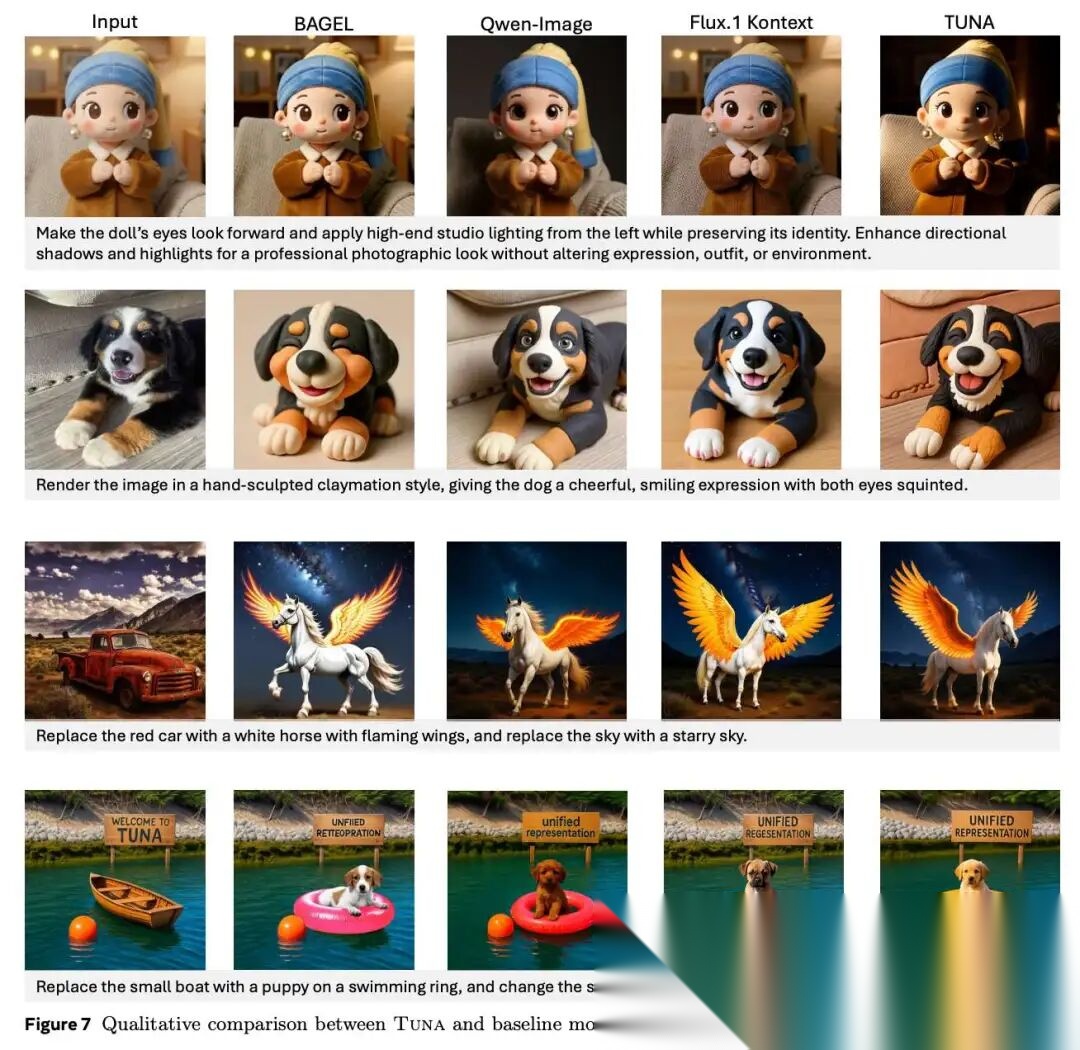
图表解析: 图像编辑的定性对比。核心结论: 在编辑“玩偶”的案例中,面对“打上来自左侧的高端影棚灯光”的指令,TUNA 在未破坏玩偶身份的前提下,正确渲染了左侧高光和右侧阴影。证明了模型不仅能执行显式的对象替换,还能深刻理解光影等物理规律。

图表解析: 文本到视频的生成效果展示。核心结论: 无论是红气球在街道飘浮的空间感,还是狮子平缓呼吸的微小动作,均保持了极高的帧间一致性。这验证了窗口注意力重塑机制能够在连续空间中平滑过渡时空信息。
十、结语
TUNA 的核心哲学十分明确:面对理解与生成的固有矛盾,无需强行调停,而是去寻找一个足够包容的基础表示空间。 通过冻结连续的 VAE 潜在空间,并将其与强大的 SigLIP 2 特征编码器进行早期级联,TUNA 优雅地避开了复杂的 MoE 路由和后期融合带来的语义偏见。它用严谨的实验证明了:理解与生成非但不是零和博弈,反而能在早期级联的架构下相互反哺。
尽管受限于算力成本(7B 版本未能一并整合视频数据),但 TUNA 在 1.5B 规模下所展现出的跨模态一致性,已经为下一代原生多模态大模型验证了一条极具潜力的技术演进路径。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献672条内容
已为社区贡献672条内容

所有评论(0)