拒绝 API 割韭菜!算家云+OpenClaw+本地模型,批量任务成本立降 90% !
本文介绍了一套低成本AI数据处理方案,通过算家云+OpenClaw+本地大模型(GLM-4.7-Flash)组合,可大幅降低电商评论处理等批量任务的成本。该方案支持一键部署、数据隐私保护、7×24小时稳定运行,实测最高可节省90%API费用。特别适合情感分类、关键词提取等简单但量大的任务,支持从单卡到八卡的弹性扩容,并提供预配置镜像实现10分钟快速部署。
还在为昂贵的 API 调用账单发愁吗?面对海量的数据清洗、评论分类和摘要生成,传统的云端 API 不仅成本随着数据量线性飙升,还容易受到限流的困扰。

今天,我们为大家分享一个降本增效的绝妙方案:在算家云上使用 OpenClaw 搭配本地大模型。实测表明,这套组合不仅能完美处理批量任务,更能将成本最高降低 90% !
💡真实痛点:电商数据的“吞金兽”
前不久,一位电商用户找到我们。他们的需求非常典型:每天需要处理海量的商品评论,包括:
· 情感分类(正面/负面/中性)
· 关键词提取
· 简单摘要生成
任务逻辑并不复杂,但数据量巨大。起初,他们使用外部 API 搭建了自动化流程(通过飞书接收数据,定时处理),但随着业务增长,API 费用迅速变得难以承受。
有没有一种既稳定、又便宜,还能保证数据隐私的方案?答案是肯定的。我们推荐使用:算家云+OpenClaw+Ollama+GLM-4.7-Flash。
🛠️核心方案:为什么选这套组合?
1. OpenClaw:批量任务的神器
OpenClaw 是一款开源的批量任务处理工具,原生支持本地模型。它特别适合逻辑相对简单但数据量大的场景(如分类、提取、简单生成)。
· 零 API 成本:本地推理,调用不计费。
· 数据不出云:保障隐私安全。
· 7×24 小时稳定:长时间运行不惧限流。
2. 算家云镜像社区:开箱即用 ⚡
还在为配置环境头疼?算家云镜像社区已经为你准备好了预配置环境! 我们提供了 OpenClaw-Ollama-glm-4.7-flash 镜像,预装了所有依赖环境,无需手动下载模型,几分钟即可上手。
3. GLM-4.7-Flash:性价比之王
为什么首选 GLM-4.7-Flash?
✅ 速度快:专为批量处理优化。
✅ 显存低:单张 RTX 3090/4090 即可流畅运行。
✅ 中文强:对中文语境支持极佳。
✅ 够精准:对于分类、摘要等简单任务,准确率完全满足需求。
💪实战演练:10分钟快速部署
第一步:一键创建实例
登录算家云控制台,进入「镜像社区」。
搜索「OpenClaw」,选择 OpenClaw-Ollama-glm-4.7-flash 镜像。
选择 GPU 配置(建议单卡起步,如 RTX 4090),点击创建。
等待几分钟,实例即自动启动。
第二步:验证环境
登录实例后,运行以下命令确保组件正常:
# 验证 Ollama 版本
ollama --version
# 查看已安装模型(预装了 GLM-4.7-Flash)
ollama list
# 验证 OpenClaw
openclaw --version
第三步:修改配置
编辑 ~/.openclaw/openclaw.json,将模型提供商指向本地 Ollama 服务:
{
"models": {
"providers": {
"ollama": {
"baseUrl": "http://localhost:11434/v1",
"api": "openai-completions",
"models": [
{
"id": "glm-4.7-flash",
"name": "GLM-4.7-Flash (本地)",
"cost": { "input": 0, "output": 0 }
}
]
}
}
},
"agents": {
"defaults": {
"model": "ollama:glm-4.7-flash"
}
}
}
关键点:将 cost 设为 0,意味着本地模型调用完全免费!
第四步:启动服务
# 启动 OpenClaw Gateway
bash run.sh -r
至此,一套低成本的自动化 AI 处理流水线就搭建完成了!
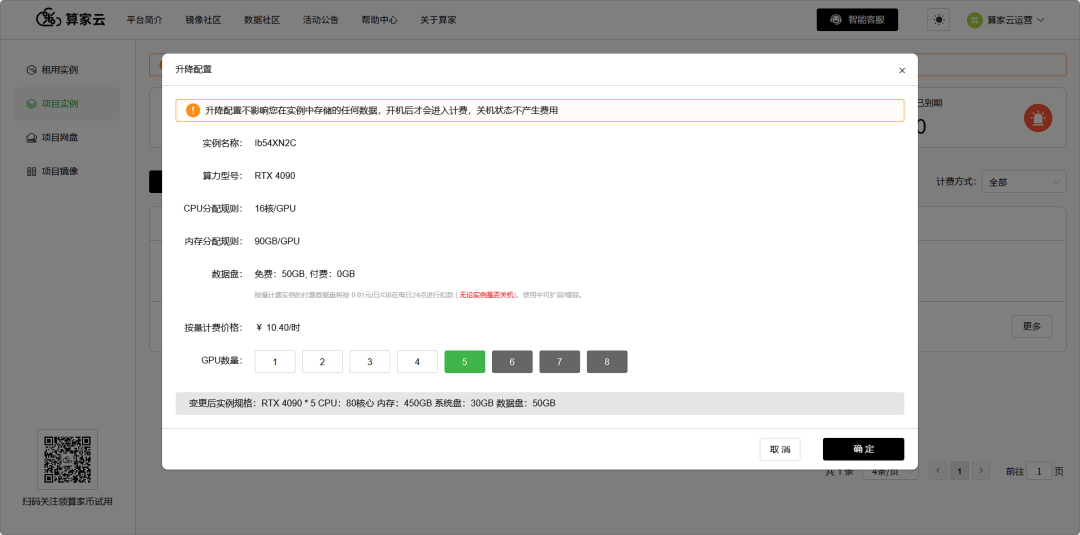
🔥灵活扩展:从单卡到八卡
算家云支持极其灵活的 GPU 配置,你可以根据任务量随时调整。
|
配置 |
适用场景 |
推荐模型 |
|---|---|---|
| 单卡 (1×GPU) |
日常批量任务 |
GLM-4.7-Flash / Qwen3.5-9B |
| 双卡 (2×GPU) |
中等规模任务 |
Qwen3.5-14B |
| 四卡 (4×GPU) |
大规模批量处理 |
Qwen3.5-32B |
| 八卡 (8×GPU) |
超大规模任务 |
Llama-3-70B |
升级操作:在容器中心的「项目实例」页面,实例处于关机状态时,点击「更多」-「升降配置」,选择更多卡数即可,数据自动保留。
🤖智能化玩法:多智能体与自动化
OpenClaw 不仅仅是模型调用器,更是一个智能协作系统。
· 多智能体分工:配置不同的 Agent(如 classification-agent、summary-agent),各司其职,效率倍增。
· Cron 定时任务:设置如 0 */2 * * *,每 2 小时自动处理一批积压数据,无需人工干预。
· 飞书集成:打通飞书通道,评论数据自动进入处理流程,分析结果自动回复,打造全自动闭环。
📊实战成本与场景分析
📈 什么时候用本地模型最划算?
公式:
API 成本 = 数据量 × Tokens × 单价 本地成本 = 运行时长(小时) × GPU 单价
结论: 日处理量在几千条以上时,本地模型优势显著。数据量越大,省得越多!
✅ 推荐场景
-
任务复杂度低(分类、提取、简单摘要)。
-
需要长时间连续运行(7×24 小时)。
-
数据量大,对 API 成本敏感。
-
对数据隐私有严格要求(数据不出内网/云端)。
❌ 不推荐场景
-
需要极高推理能力的复杂逻辑分析(建议升级更大模型)。
-
偶尔处理的小批量数据(API 更省事)。
-
需要秒级出结果的紧急任务。
🏆总结:算家云的核心优势
为什么选择在算家云上跑 OpenClaw?
- · 不买显卡:省去高昂硬件投入和维护烦恼。
- · 按需付费:用多少算多少,支持关机不计费,闲置不花钱。
- · 镜像即用:预配置环境,10 分钟部署,拒绝折腾。
- · 弹性扩容:从单卡到八卡,业务增长无需换机,一键升级。
OpenClaw + 算家云 + 本地模型,这不仅是成本的优化,更是数据处理效率的质变。
👇即刻访问算家云镜像社区,搜索 OpenClaw,开启你的低成本 AI 之旅!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 2
2 0
0- 0



 已为社区贡献63条内容
已为社区贡献63条内容

所有评论(0)