从“为人治”到“为机治”:数智化时代的企业数据治理范式革命
从“为人治”到“为机治”:数智化时代的企业数据治理范式革命
基于“发现问题→归因→建议→执行”闭环,论本体语义如何让AI真正驱动运营
引言:从一次“无人干预”的运营事件说起
凌晨2点17分,某零售企业华东区A品类销售额连续两日环比下降超过8%。系统自动触发预警,随即启动归因分析,定位到该区域近期无促销活动且遭遇连续暴雨,导致线下门店客流锐减。3秒后,系统生成了两套应对方案:一是对该品类启动限时8折促销,预计提升销量15%;二是调整线上搜索推荐权重,预计提升曝光20%。运营总监在手机端审阅后,点击确认第一方案。系统自动调用营销中台API,创建促销活动、推送优惠券、调整价格策略。整个过程,人只在关键节点做了一次审批确认。
这不是未来的想象,而是正在发生的数智化运营场景。
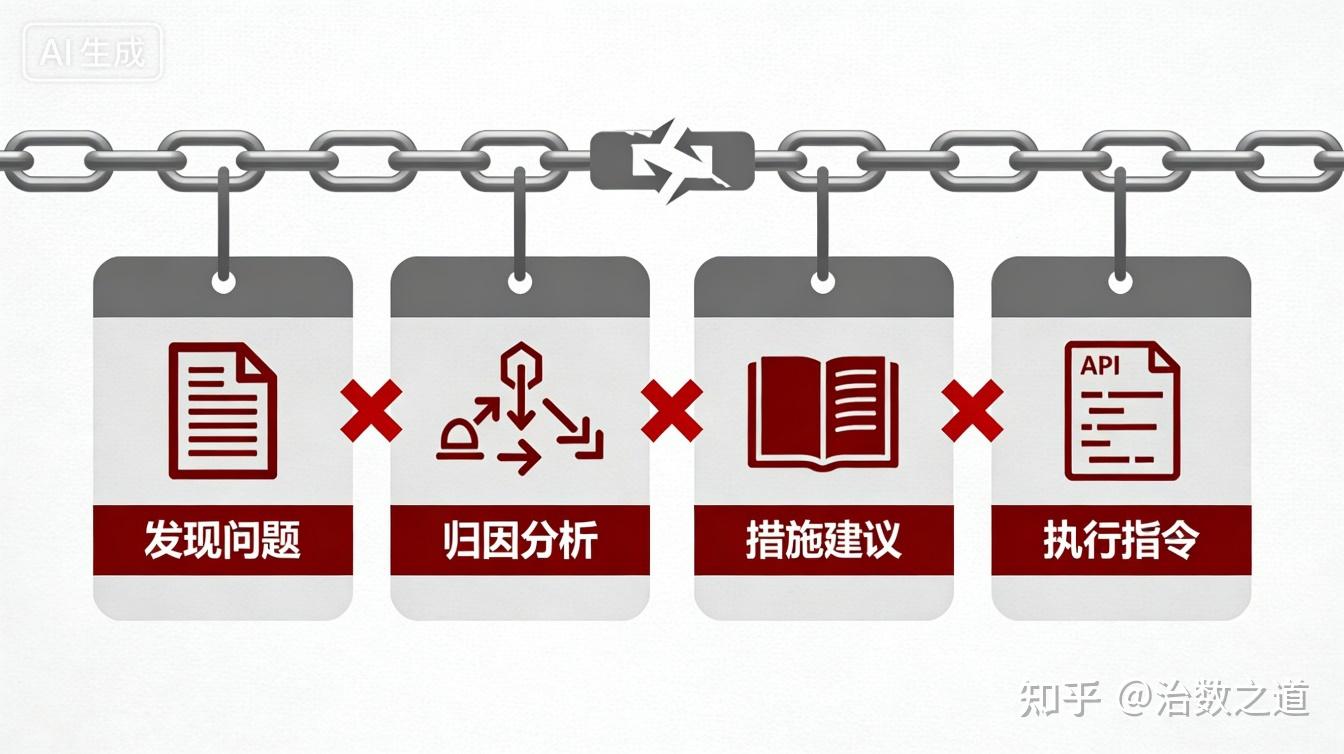
在这个闭环中,数据完整经历了 “发现问题→归因分析→措施建议→执行指令” 四个环节。而驱动这个闭环的“驾驶者”,不再是盯着报表的业务人员,而是沉默运行的程序、算法和AI。
这就引出了一个根本性的问题:要让机器可靠地走完这个运营闭环,我们需要为它提供什么样的“燃料”?我们延续了几十年的、默认以“人”为最终读者的数据治理体系,能支撑这样的自动化运营吗?
本文将围绕这个四步运营闭环展开论述,探讨数智化时代企业数据治理面临的范式革命——从“为人治”到“为机治”。

第一部分:时代之问——当AI成为运营闭环的“驾驶者”
1.1 运营链路的根本演变
让我们对比两组场景:
传统运营链路:业务人员登录BI系统查看报表 → 发现销售额异常 → 手动编写SQL或下钻分析 → 召集会议讨论原因 → 凭经验拟定对策 → 登录各业务系统手动执行。整个链路以“天”为单位,且高度依赖个人经验。
AI驱动运营链路:系统实时监控指标 → 自动感知异常 → 沿语义血缘溯源 → 基于规则生成方案 → 调用API自动执行。整个链路以“秒”为单位,且过程可复现、可审计。
两者的本质区别在于:执行主体从“人”变成了“机器”。AI从“副驾驶”变成了“主驾驶”,从“辅助决策”的角色升级为“直接执行”的角色。
1.2 新角色带来的新要求
当AI成为驾驶者,它对数据的“阅读能力”提出了完全不同的要求。
人开车可以看路标——路标上的文字“前方学校”是模糊的语义,但人可以结合上下文(时间、路况)做出合理判断。机器开车需要的是高精地图——每条车道的精确坐标、每个路口的红绿灯相位、每个限速标志的精确数值。任何歧义都可能导致事故。
这就是数智化运营的核心矛盾:概率性的AI,需要确定性的数据输入,才能可靠地走完运营闭环。大模型的本质是统计预测,它会基于概率“猜”出下一个词。但如果喂给它的数据本身就存在歧义,就会产生“概率的平方”效应,导致输出不可控。
1.3 本文的讨论边界
需要特别说明的是,本文讨论的数据治理,特指基于数据中台(数据仓库) 的治理。数据中台的核心使命正是支撑运营分析——从发现问题到辅助决策。当决策和执行的主体变成AI,数据中台的角色也必须随之进化:从“给人看的报表工厂”进化为“给机器读的语义中枢”。
这个进化,需要我们重新思考数据治理的底层逻辑。
第二部分:范式之困——传统治理在运营闭环的每个环节“掉链子”
传统数据治理默认的读者是“人”。它产出的元数据、标准、血缘、规则,都是写给“人”看的说明书。在AI驱动的四步运营闭环中,这种“为人设计”的范式在每个环节都面临着“语义断裂”。
2.1 发现问题环节:指标定义是“给人看的”,机器无法“感知”
传统做法:在数据标准文档中定义“月活跃用户是指一个月内有过登录或交易行为的用户”。分析师理解后,在BI工具中手动配置报表。
为什么AI会卡住:这个定义是自然语言。当AI要“感知”月活跃用户是否异常时,它不知道“活跃”的确切判定规则——是登录算活跃,还是交易算活跃?两者是“或”关系还是“且”关系?时间窗口是自然月还是滚动30天?AI只能靠概率猜测,导致预警要么漏报、要么误报。
2.2 归因分析环节:血缘是“流向图”,机器无法“理解语义”
传统做法:数据血缘工具记录“表A → 表B → 表C”的流向关系,画出一张数据流转图。分析师可以顺着这张图手动排查问题。
为什么AI会卡住:血缘只告诉我们“数据从哪里来、到哪里去”,但没有说明“过程中发生了什么变化”。是从源表直接复制?还是经过过滤、聚合、计算?AI想下钻分析“为什么销售额下降”,它需要知道“销售额”这个指标是从“订单金额”聚合而来,而“订单金额”又经过了“剔除退货”的过滤。没有语义标签的血缘,只是一张静态的地图,而不是一本可推理的说明书。
2.3 措施建议环节:业务规则在“文档里”,机器无法“调用”
传统做法:业务部门将“库存周转率低于2时应启动促销”这样的规则写成文档,或者在系统中硬编码。分析师凭经验参考这些规则提出建议。
为什么AI会卡住:规则是给人看的,或者写死在代码里。AI无法动态调用这些规则——它不知道存在这样的规则,即使知道,也无法理解“库存周转率”这个概念的精确含义(是平均库存除以销售成本?是期末库存除以日均销售?),更无法判断当前是否满足触发条件。
2.4 执行指令环节:API是“接口文档”,机器无法“可靠执行”
传统做法:开发人员编写API文档,描述输入参数、输出格式、调用示例。运营人员手动调用或由开发人员协助调用。
为什么AI会卡住:API文档是给人读的。AI不知道createPromotion这个API的discount参数是百分比还是小数、取值范围是多少、与price参数是否互斥。让它自动执行,就像让一个不懂本地语言的游客在异国他乡按照路牌开车——能走,但随时可能出错。
2.5 小结:根本局限在于“为人设计”的默认假设
传统治理在“人机交互”的旧范式下是够用的,因为人可以用常识和沟通来弥补模糊性。但在“机机交互”的新范式下,每个环节都出现了“语义断层”。
这不是技术问题,而是认知设计的根本局限。我们需要一套新的治理范式——其默认读者不再是“人”,而是“机器”。
第三部分:破局之道——构建“可计算”的数据治理新范式
要支撑AI走通“发现问题→归因分析→措施建议→执行指令”这个四步闭环,必须用一套新的方法论,为每个环节的数据赋予机器可读、可推理、可执行的语义。
这套方法论,就是基于本体论的数据治理。
3.1 发现问题环节的对策:语义化指标
什么是语义化指标:将指标定义为“原子指标 + 维度 + 业务约束”的可执行单元,而不是自然语言的文字描述。
示例:“月活跃用户”这个指标,在传统治理中是一个文本定义。在语义化指标中,它被形式化为:
- 原子指标:用户ID(去重计数)
- 维度:时间维度(最近30天)、行为维度(登录 OR 交易)
- 业务约束:活跃定义 = 登录行为 OR 交易行为;时间窗口 = 滚动30天
为什么这能让AI“感知”:AI可以精确理解这个指标的计算逻辑,并按照预设的规则(如“连续两日环比下降超过5%”)对指标流进行实时计算。一旦触发,AI立即生成一个结构化的预警事件,其中不仅包含“什么指标异常”,还携带业务上下文(如涉及的区域、产品线)。
3.2 归因分析环节的对策:语义化血缘
什么是语义化血缘:为数据血缘的每条边赋予语义标签,描述数据在流动过程中发生了什么变化。
示例:传统血缘记录“订单明细表 → 销售汇总表”。语义化血缘则进一步说明:订单明细表 → [is_aggregated_by(region, product)] → 销售汇总表。同时,订单明细表本身是由订单表和订单商品表通过[is_joined_by(order_id)]连接而成。
为什么这能让AI“溯源”:当AI发现“销售额下降”时,它可以沿着语义化血缘回溯:
- 是聚合过程中的某个维度成员出问题(如华东区订单量下降)?
- 是源头的过滤条件发生变化(如剔除了某类退货订单)?
- 是连接关系出现问题(如订单与商品匹配失败)?
每一步的语义标签,都为AI提供了可追溯、可推理的路径。
3.3 措施建议环节的对策:业务规则本体化
什么是业务规则本体化:将业务规则从文档或代码中抽离,定义为“如果[指标][维度][满足条件],则[建议策略]”的可执行规则,并将规则本身作为治理资产进行管理。
示例:规则“库存周转率低于2时应启动促销”被形式化为:
- 条件:库存周转率 < 2 AND 当前无进行中促销
- 建议:启动促销,参数:折扣率 = min(0.1 + (2 - 库存周转率)*0.05, 0.3),渠道 = 全渠道
- 预期效果:预计库存下降20%,预计毛利影响 = 计算模型预估
为什么这能让AI“建议”:AI可以动态查询这些规则,自动匹配当前状态,生成具体的建议方案,并评估预期效果。规则不再是静态的文档,而是可被AI调用的动态知识。
3.4 执行指令环节的对策:API语义化
什么是API语义化:将业务系统的API纳入治理范畴,用本体描述每个API的功能语义、输入参数的业务含义、输出结果的格式约束。
示例:营销系统createPromotion API被描述为:
- 功能:创建一场促销活动(语义类型:CreatePromotion)
- 输入参数:productList(产品列表,语义:Product实例列表)、discountRate(折扣率,语义:百分比,取值范围0-100)、region(区域,语义:Region实例)、startTime/endTime(时间范围,语义:DateTime)
- 输出:promotionId(促销活动ID)、status(创建状态)
为什么这能让AI“执行”:当AI生成“对华东区A品类启动8折促销”的决策后,它可以自动将其“翻译”为对createPromotion API的正确调用,填入符合语义约束的参数。执行完成后,AI将结果反馈给监控闭环,形成新的数据起点。
3.5 小结:运营语义层的诞生
这套新范式的核心产出,是一套 “运营语义层”——它像一层“翻译器”,架在数据中台和AI应用之间:
- 向上,它为AI应用提供机器可读的指标、血缘、规则、API语义
- 向下,它继承并重构了传统治理沉淀的数据资产
有了这层语义基础设施,AI才能真正可靠地走完运营闭环。
第四部分:进化的本质——认知升维,架构重构
在深入了解了新范式之后,一个关键问题自然浮现:这套基于本体论的数据治理,与传统治理是什么关系?是推倒重来,还是在原有基础上添砖加瓦?
4.1 资产继承:不是推倒重来
我们绝不抛弃传统治理沉淀下来的宝贵资产:
- 元数据:记录了数据的技术属性,是新范式中构建本体的原材料
- 数据标准:定义了业务术语的核心内涵,是语义化指标的基础
- 数据血缘:记录了数据流向的骨架,是语义化血缘的起点
- 业务规则:沉淀了企业的管理经验,是规则本体化的来源
- API文档:描述了系统接口的规范,是API语义化的素材
例如,传统治理梳理出的“客户信息标准”,在新范式中会被转化为“客户本体”的核心属性定义;传统血缘记录的数据流向,会成为“语义化血缘”的基础骨架。
4.2 范式跃迁:不是添砖加瓦
但新范式远不止于“在传统治理上加一个新工具”。因为这是认知层和架构层的根本跃迁:
- 认知升维:从“给人看的说明书”升维为“给机器读的源代码”。传统治理默认读者是人,所以产出的元数据、标准、血缘都是自然语言的、静态的、需要人解读的。新范式默认读者是机器,所以一切治理产出都必须形式化、机器可读、可执行。
- 架构重构:从“静态文档”重构为“动态可计算模型”。传统治理的产物是文档、图表、记录,它们是“被查阅”的。新范式的产物是本体模型、语义标签、可执行规则,它们是“被执行”的。
4.3 一个核心比喻:从“纸质地图”到“GPS导航系统”
这个关系可以用一个比喻来理解:
传统治理的成果,就像前人绘制的一张张精细的纸质地图。它们标注了哪里有山(数据源)、哪里有河(数据流向)、地名是什么(数据定义)。这是宝贵的知识资产。
但是,当我们要运营一支“自动驾驶车队”(AI应用)时,纸质地图无法被汽车直接读取。我们需要的是GPS导航系统——它继承了纸质地图的精确地理信息,但通过数字化、语义化、动态化,重构为机器可读、可计算、可导航的全新体系。
在这个比喻中:
- 纸质地图 = 传统治理资产
- GPS导航系统 = 基于本体论的新治理体系
- 地图没有消失,它换了一种更强大的方式存在,支撑自动驾驶(AI运营)跑通每个路口(运营环节)。
4.4 本章小结
基于本体论的数据治理,不是推倒重来,也不是简单的添砖加瓦。它是对传统治理资产的认知升维与架构重构——让治理成果从“被查阅”变为“被执行”,从“给人看的说明书”变为“给机器读的源代码”。
这才是数智化时代数据治理进化的正确方向。

第五部分:智治融合——基于“可计算”治理的AI运营闭环
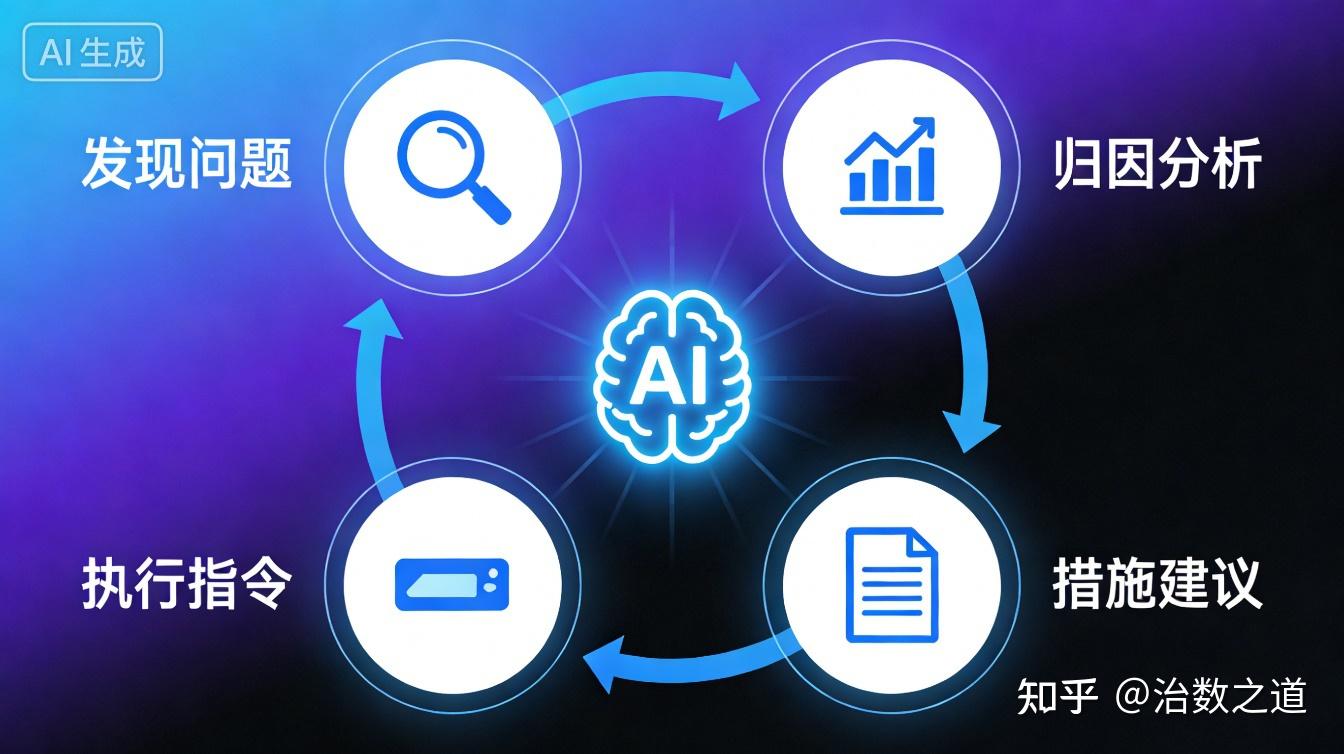
有了以上四章的理论铺垫,现在我们可以完整地展示:当新范式落地后,AI是如何基于数据中台,自动、可靠地执行完整的“发现问题→归因分析→措施建议→执行指令”运营闭环的。
5.1 发现问题:从“被动报表”到“主动感知”
AI应用:运营监控Agent订阅“语义化指标”,按“预警规则本体”实时计算。
治理基础:
- 语义化指标:如“销售额”被精确定义为SUM(订单金额),并关联“区域”“产品线”“时间”等维度
- 预警规则本体:如“连续两日环比下降超5%”被形式化为[指标]连续2日环比下降率>5%→触发预警
实际运作:
AI Agent实时扫描各指标流。一旦“华东区A品类销售额”触发规则,立即生成一个结构化的预警事件:
json
{ “event_type”: “metric_anomaly”, “metric”: “销售额”, “dimensions”: {“region”: “华东”, “product_category”: “A”}, “value”: 850000, “baseline”: 923913, “change_rate”: -0.08, “trigger_rule”: “连续两日环比下降超5%”, “timestamp”: “2026-03-25 02:17:00”}
应用层体现:
业务人员无需盯着屏幕,而是通过移动端或工作台收到AI推送的“智能预警工单”:
【自动预警】华东区A品类销售额连续2日环比下降8%,已触发预警阈值。
5.2 归因分析:从“人工下钻”到“智能溯源”
AI应用:归因Agent收到预警事件后,自动启动分析流程。
治理基础:
- 语义化血缘:记录了“销售额”指标从源头到聚合的每一步语义(如订单明细表→is_aggregated_by(region, product)→销售汇总表)
- 维度层次本体:定义了地域维度的“国家-省份-城市”层级、产品维度的“大类-中类-SKU”层级
- 外部本体:营销活动日历、天气数据等
实际运作:
归因Agent自动执行:
- 沿语义化血缘回溯:从“销售额”指标向下追溯,定位到其来源的订单明细表,计算发现“订单量下降20%”是主因,客单价基本稳定
- 沿维度层次下钻:自动按“区域”维度下钻,发现华东区订单量下降占整体下降的85%;再按“城市”下钻,锁定上海、杭州下降最严重
- 关联外部本体:查询营销活动日历(华东区近期无促销),查询天气数据(连续暴雨)
应用层体现:预警工单自动附上归因分析报告:
【归因分析】销售额下降主要源于华东区A品类订单量下降20%。进一步分析发现:①华东区近期无促销活动;②上海、杭州遭遇连续暴雨,线下门店客流锐减;③线上渠道订单量稳定,无异常。
5.3 措施建议:从“经验决策”到“策略生成”
AI应用:建议Agent根据归因结果,结合业务规则,生成应对方案。
治理基础:
- 业务规则本体:如“当库存周转率低于X且无促销时,建议启动促销”
- 历史策略知识库:将过去营销活动及其效果作为实例纳入本体
- 成本约束规则:促销预算、毛利底线等
实际运作:
建议Agent生成若干可行方案,并评估预期效果:
| 方案 | 内容 | 预期效果 | 成本/风险 |
|---|---|---|---|
| 方案一 | 华东区A品类限时8折促销 | 销量提升15% | 毛利下降约8万元 |
| 方案二 | 调整线上搜索推荐权重,优先展示A品类 | 线上曝光提升20% | 无直接成本 |
| 方案三 | 组合方案:线上推荐+线下门店引导线上下单 | 综合提升12% | 需协调门店资源 |
应用层体现:AI将建议方案推送给相关负责人,以结构化卡片呈现:
【措施建议】
- 方案一:对华东区A品类启动限时8折促销,预计提升销量15%,毛利影响约8万元
- 方案二:调整线上搜索推荐权重,预计提升曝光20%,无直接成本
- 方案三:组合方案,预计综合提升12%,需协调门店资源
[确认执行方案一] [修改] [驳回]
5.4 执行指令:从“人工操作”到“系统执行”
AI应用:执行Agent接收到审批通过的决策方案,自动执行。
治理基础:
- API语义化:用本体描述每个API的功能、输入参数的语义、输出结果的格式
- 语义化指令:将决策方案形式化为可执行的指令序列
实际运作:
执行Agent将“对华东区A品类启动8折促销”这一决策,自动“翻译”为对营销系统API的调用:
- 查询API语义库,找到createPromotion API
- 根据输入参数语义,填充参数:
- productList: [A品类所有SKU]
- discountRate: 20 (语义:百分比,取值0-100)
- region: “华东”
- startTime: 当前时间
- endTime: 当前时间+7天
- 调用API,获取返回结果promotionId
- 将执行结果反馈给监控闭环
应用层体现:业务人员收到确认通知:
【执行完成】促销活动已创建,活动ID:PROMO-20260325-001。预计明日生效,您可在营销后台查看详情。
5.5 本章小结
至此,我们完整展示了AI如何基于新治理体系,从“看数据”到“做动作”的全过程:
- 发现问题:语义化指标 + 预警规则 → 主动感知异常
- 归因分析:语义化血缘 + 维度本体 + 外部本体 → 智能溯源
- 措施建议:业务规则本体 + 知识库 → 策略生成
- 执行指令:API语义化 → 自动调用执行
数据中台完成了从“分析型系统”到“运营型中枢”的跃迁。而这一切的核心支撑,正是我们前四章所论述的——基于本体论构建的“可计算”数据治理体系。
第六部分:未来之路——迈向“人机互信”的智能企业
当AI能可靠地执行“发现问题→归因分析→措施建议→执行指令”这个运营闭环,人与机器的关系就从“工具”进化为“伙伴”。数据治理的终局,是构建一个“人机互信”的协同运营环境。
6.1 愿景描绘:人定义规则,机器执行运营
在这样的体系中:
- 人负责定义“业务的本体”:设定指标的口径、规则的阈值、策略的边界,审批例外情况,监督整体效果
- 机器基于这个精确的认知框架,自动执行“数据的运营”:感知异常、溯源根因、生成方案、调用API
企业运营从“人盯人”变为“机盯机,人管机”。人不再是重复劳动的“操作工”,而是定义规则的“架构师”。
6.2 行动路线图:如何迈出第一步
对于大多数企业而言,向这个新范式的演进不需要一步到位。建议采取“小步快跑”的策略:
第一步:试点选择
选择一个高频、闭环的运营场景作为试点,如:
- 营销自动化:监控销售指标 → 触发促销规则 → 自动创建活动
- 库存预警与补货:监控库存周转率 → 归因分析 → 自动生成采购单
- 客户流失预警:监控活跃度指标 → 识别高风险客户 → 自动推送挽回优惠
第二步:资产盘点
梳理试点场景所需的基础治理资产:
- 数据标准:哪些指标、实体需要语义化?
- 数据血缘:能否补充语义标签?
- 业务规则:哪些规则需要本体化?
- API清单:哪些系统接口需要语义化?
第三步:工具选型
引入支持新范式的基础设施:
- 语义建模工具:支持构建业务本体、指标本体
- 知识图谱平台:支持存储和查询语义化血缘
- 规则引擎:支持业务规则的本体化与动态调用
- API语义化平台:支持API的语义描述与自动调用
6.3 结语:从“知数”到“善用”
回到我们的初心——“知数善用”。
在数智化时代,这四个字有了新的内涵:
- 知数:不仅是让人知道数据,更是让机器也能精确地“知道”数据——知道每个指标的口径、每条血缘的语义、每个规则的边界
- 善用:不仅是让人善于使用数据做决策,更是让机器在人的监督下,善于使用数据自动执行运营
这就是我们从“为人治”到“为机治”的范式革命。它不是在传统治理上修修补补,而是基于本体论,对数据治理进行一场“认知升维”与“架构重构”。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 25
25 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)