【学习笔记1】AI 基础概念:机器学习、深度学习、大语言模型的区别

详细介绍 AI 基础概念:机器学习、深度学习、大语言模型的区别
先用一张图把三者的关系说清楚——它们是"包含关系",不是并列关系。

这张图说明了一件最重要的事:LLM 是 DL 的一种,DL 是 ML 的一种,ML 是 AI 的一种。它们不是平行的技术,而是一层套一层。
下面逐层解释每一个概念。
人工智能(AI)
这是一个"大帽子"。只要是让计算机模拟人类智能行为的技术,都叫 AI。包括最早的专家系统(用 if-else 写死规则)、搜索算法、甚至国际象棋程序。AI 不一定要"学习"——规则写死也算。
早期的专家系统(Expert Systems)不仅是 AI,而且曾是 AI 领域最显赫的“正统”代表。
在 AI 的发展史上,它被称为**符号主义(Symbolism)**或“逻辑驱动型 AI”。
为什么 if-else 也是 AI?
在 20 世纪 60 年代到 80 年代,AI 的主流定义是**“让机器模拟人类的推理逻辑”**。
当时的科学家认为,人类的智能体现在“知识”和“逻辑”上。如果能把领域专家的知识提取出来,写成成千上万条 if-then 规则,机器就能像专家一样做决策。
- 例子: 著名的医疗诊断系统 MYCIN。
-
if病人血液中存在某种细菌andif病人发烧超过 38.5°C...then结论:有 80% 的概率患有某种感染,建议使用某抗生素。
虽然它底层是硬编码的逻辑,但它表现出了解决复杂专业问题的能力,这符合当时对“智能”的定义。
普通的 if-else 语句本身只是“逻辑指令”,只有当这些指令规模化、系统化地用于模拟人类决策时,它才被视为 AI
- 简单的逻辑(不是 AI)
如果你写一段代码: if (temperature > 30) { open_fan(); } 这通常不被称为 AI。这只是一个简单的自动化脚本或条件控制。
- 原因: 它的逻辑过于简单,没有体现出“智能”所需的复杂推理或对不确定性的处理。它更像是一个“开关”。
- 复杂的规则系统(AI 的雏形:专家系统)
如果你写了 10,000 条 if-else,涵盖了某个医生诊断某种疾病的所有经验:
if (symptom == 'fever' && temperature > 39 && white_cell_count > high) { ... }- 再结合权重计算和逻辑推理机。 这就是 AI。 在计算机科学史上,这被称为**“硬编码 AI”**。它的智能不在于代码本身,而在于通过海量的逻辑组合,模拟出了专家的判断力。
- 现代 AI(不写死 if-else)
现代机器学习(如神经网络)与普通 if-else 的本质区别在于:谁来写逻辑?
- 普通程序: 程序员观察规律 -> 程序员写出
if-else-> 机器执行。 - 机器学习: 程序员设计框架 -> 机器观察海量数据 -> 机器自己生成内部的“逻辑”(参数)。
总结:界限在哪里?
我们可以用一个比喻来形容:
- 普通的
if-else就像是一个**“路牌”**:你告诉车,看到这个牌子就左转。这只是死指令。 - 专家系统(古典 AI) 就像是一个**“迷宫导航图”**:虽然都是指令,但它极其复杂,能应对各种岔路。
- 现代机器学习 就像是一个**“自动驾驶员”**:你没告诉它具体哪厘米该转弯,但它通过学习,自己掌握了开车的“感觉”。
所以,普通的 if-else 是构建 AI 的“砖块”。 一块砖头只是砖头(普通程序),但成千上万块砖头按照复杂的逻辑架构垒起来,就可以是一座“智慧宫殿”(AI 系统)。
机器学习(ML)
ML 是 AI 的一个子集,核心思想是:不手写规则,而是给机器大量数据,让它自己找规律。
用 Java 类比:传统编程是你写 if (price > 100) return "贵";机器学习是你给它 10 万条商品数据 + 标注,它自己学出来一个"判断贵不贵"的模型。
ML 里常见的算法有决策树、随机森林、SVM、线性回归等。这些算法需要人工提取特征(比如"价格"、"品牌"、"销量"这些字段要你自己想好再喂给它)。
深度学习(DL)
DL 是 ML 的子集,核心突破是:用多层神经网络自动提取特征,不再需要人工做特征工程。
还是类比:ML 时代你要告诉模型"看图片要看边缘、颜色、纹理";DL 时代你直接把原始像素扔进去,神经网络自己学会了"先找边缘,再组合成形状,再组合成物体"这个层次结构。这就是"深度"的含义——多层(深层)的网络。
DL 爆发的关键是 GPU 并行计算 + 海量数据,从 2012 年 AlexNet 开始。
大语言模型(LLM)
LLM 是 DL 的子集,专门用来处理语言。核心架构是 2017 年 Google 提出的 Transformer。
LLM 的训练方式是:给模型海量文本,让它学会"预测下一个词"。听起来很简单,但当参数量达到数百亿甚至数千亿,这个能力会涌现出推理、写代码、翻译等各种智能。GPT、Claude、Llama、通义千问都属于这一类。
核心概念
接下来是需要牢记的几个核心概念:
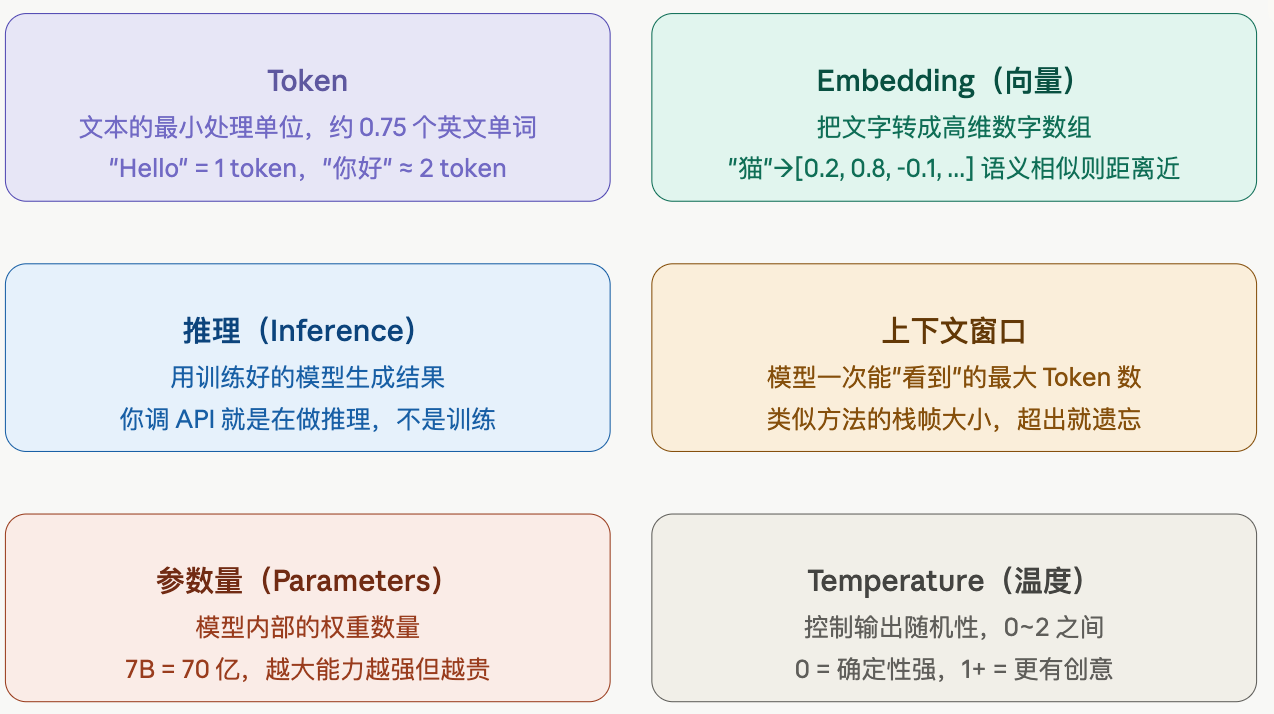
补充几个关键点:
Token 为什么重要? 因为所有 AI API 都按 Token 计费。"你好,请问今天天气怎么样?" 大约是 15 个 Token。调用 API 要时刻留意输入 + 输出的 Token 消耗,这直接决定成本。
Embedding 为什么重要? 这是 RAG(检索增强生成)的基础。把你的文档转成向量存进向量数据库,用户问问题时先搜索相似向量,再把相关文档片段塞给 LLM 回答。整个知识库问答系统都建立在 Embedding 上。
推理 vs 训练的区别 — 作为应用开发者,你 99% 的时间都在做"推理",也就是调用已经训练好的模型 API。训练模型需要大量 GPU 和数据,不是你的活儿。偶尔可能会做"微调(Fine-tuning)",但也不是从头训练。
上下文窗口 — 这是最容易踩的坑。每次 API 调用,你需要把所有对话历史都带上,因为模型没有记忆。历史越长,Token 消耗越多。上下文窗口满了之后,早期的内容会被截断,模型就"忘了"。设计多轮对话系统时要特别注意这一点。
用一句话总结三者区别:
机器学习是"让机器从数据中学规律"的方法论;深度学习是用神经网络实现机器学习、自动提取特征的技术;大语言模型是用超大规模 Transformer 神经网络专门处理语言的深度学习模型。
Token 是什么
文本 → Token 切分示例
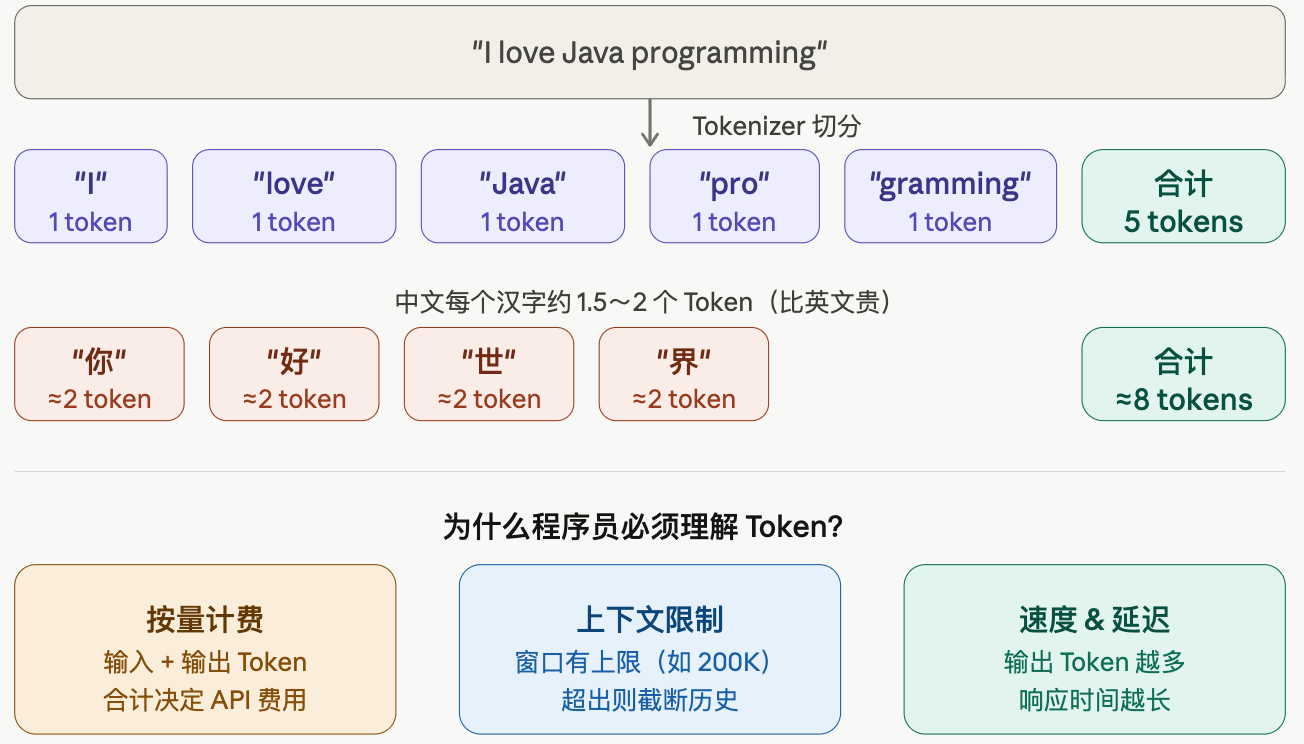
用 Java 最熟悉的概念来类比,Token 其实就是 词法分析器(Lexer)切出来的词素。
Java 编译器在编译源码时,第一步是词法分析:把 int x = 10 + 20; 切成 [int, x, =, 10, +, 20, ;] 这样一个个 token。AI 的 Tokenizer 做的事情完全一样——把原始文本切成模型能处理的最小单元。
区别只是:Java 编译器的 token 是关键字、运算符这种有语法意义的单位;AI 的 Token 是按"高频字符序列"切的,更像是字节对编码(BPE),不完全按词语边界切。所以 programming 会被切成 pro + gramming 两个 Token,因为模型认为把常见的子词分开学习更高效。
三个你必须记住的数字感
一般来说,1000 个英文单词约等于 750 个 Token;1000 个汉字约等于 1500 个 Token。所以写 System Prompt 时用中文比英文要多花将近一倍的 Token,这直接影响成本。
一个典型的 API 调用场景:你发一段 500 Token 的对话历史 + 100 Token 的问题,模型返回 200 Token 的回答,这次调用总共消耗 800 Token。每次多轮对话,你都要把完整历史带上,Token 会线性叠加。
跟 Java 开发直接相关的三个坑
第一,Token 是"输入 + 输出"合计计费的。很多人只算输入,忘了输出也要钱。如果你让模型生成一篇长文,输出可能比输入贵得多。
第二,max_tokens 参数控制的是输出上限,不是总量。你设 max_tokens=100,模型最多输出 100 Token 就截断。如果生成到一半被截断,你拿到的是不完整的 JSON,程序直接崩。
第三,多轮对话的 Token 累积是个隐形成本。第 1 轮 200 Token,第 10 轮你可能已经在输入 2000 Token 的历史了。生产系统要做对话摘要或滑动窗口来控制成本。
用一行代码感受一下 Token:如果你想实际数一段文本有多少 Token,可以用 Tiktoken 库(OpenAI 开源的)或者直接调各家 API 的计数接口。Claude 的 API 响应头里也会返回本次消耗的 Token 数,开发时可以打出来感受一下量级。
Embedding 向量
用 Java 来理解——Embedding 就是把"语义"存进一个数组,然后用距离来衡量相似度
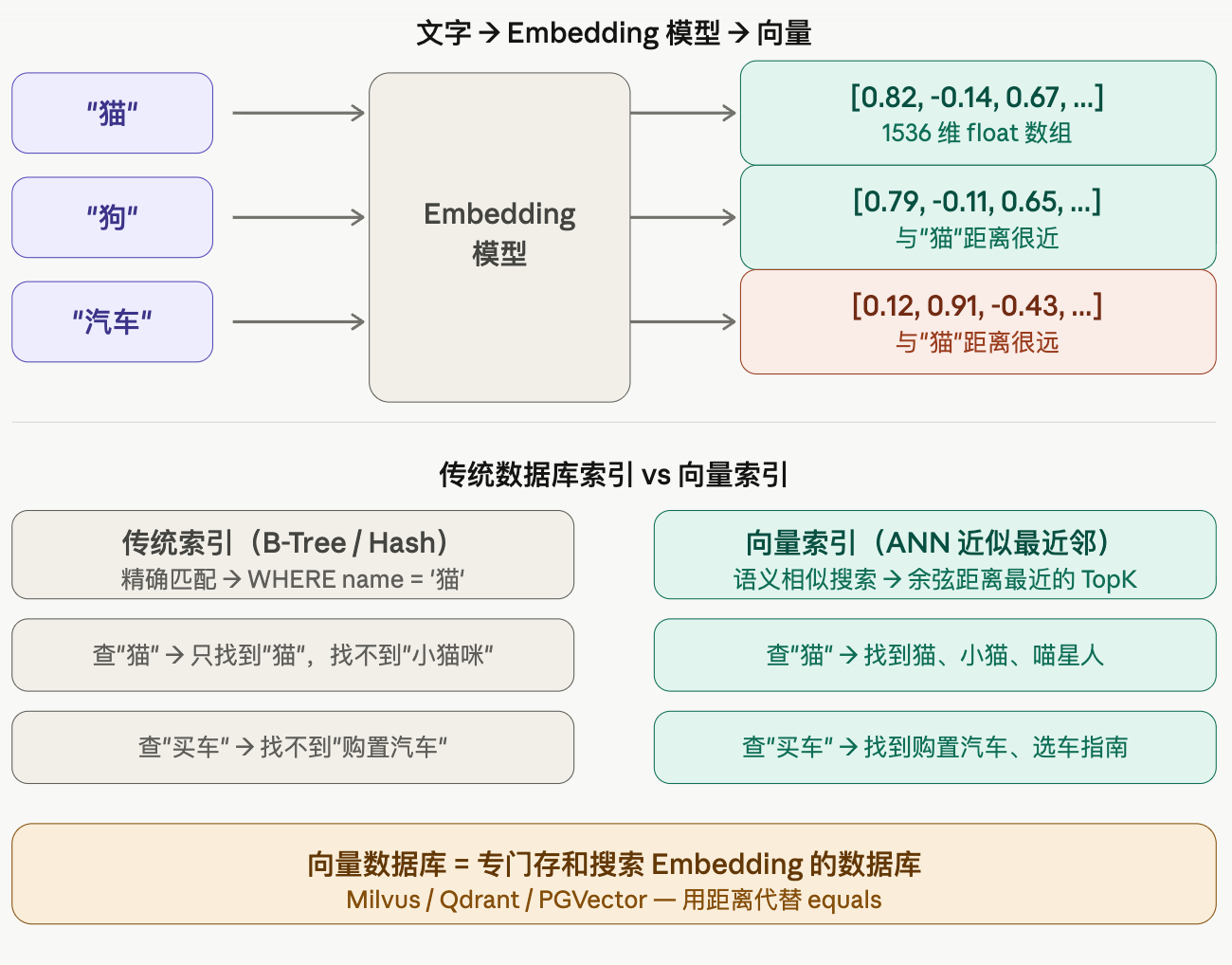
用 Java 代码感受一下 Embedding 是什么
想象你有一个方法,输入任意字符串,输出一个 float[]:
// 概念上,Embedding 就是这样一个函数
float[] embed(String text);
float[] cat = embed("猫"); // → [0.82, -0.14, 0.67, ...]
float[] kitty = embed("小猫咪"); // → [0.79, -0.11, 0.65, ...] 距离很近
float[] car = embed("汽车"); // → [0.12, 0.91, -0.43, ...] 距离很远这个数组有 1536 个维度(OpenAI ada-002 的维度),每个维度捕捉了文字的某种语义特征。你不需要知道每个维度具体代表什么,重要的是:语义相似的词,向量距离就近;语义不相关的词,距离就远。
和数据库索引的关系
传统 MySQL 的 B-Tree 索引解决的是"精确匹配"或"范围查询"——WHERE name = '猫' 或 WHERE price BETWEEN 100 AND 200。它完全不理解语义,你搜"买车"它找不到"购置汽车"。
向量索引解决的是"语义相似查询"——给定一个查询向量,找出向量空间里距离最近的 TopK 个结果。这个"距离"通常用余弦相似度来算,就像两个向量之间的夹角,夹角越小越相似。
// 传统索引的思维方式
SELECT * FROM docs WHERE content = '如何养猫'; // 精确匹配
// 向量索引的思维方式
float[] queryVec = embed("如何养猫");
List<Doc> results = vectorDb.search(queryVec, topK=5);
// 能找到:猫的饲养指南、宠物护理、小猫日常照料... 语义相近的都能搜到RAG 系统的完整流程
这是 Embedding 在实际工程中最重要的用途:
【建库阶段(离线)】
公司文档 → 切片(每段500字) → 调Embedding API转向量 → 存向量数据库
【查询阶段(在线)】
用户问题 → 转向量 → 向量数据库检索最相似的3-5段原文
→ 把原文塞进 Prompt → 让 LLM 根据原文回答这就是为什么 AI 能回答你公司内部知识库的问题——它实际上是先用向量搜索找到相关文档,再让 LLM 读文档来回答,而不是凭空"知道"的。
实际开发中需要关心的两件事
第一是选 Embedding 模型。text-embedding-ada-002(OpenAI)、text-embedding-3-small 是常用选择,国内可以用通义千问的 Embedding API。中文文档建议用对中文训练过的模型,效果差异很大。
第二是选向量数据库。如果你已经用 PostgreSQL,直接装 pgvector 插件最省事;如果是独立部署,Qdrant 用 Java 客户端很顺手;大规模场景用 Milvus。本质上它们都是把"找距离最近的向量"这件事做得又快又准。
可以使用 Hologres 作为向量数据库
但使用需要开启 Proxima 插件
在你需要的 Database 下执行,只需执行一次 CREATE EXTENSION IF NOT EXISTS proxima;
这一步就像是在 Java 项目里引入了一个 Dependency,没有它,数据库就不认识向量相关的函数和索引类型
在实际工程中,仅仅找出“最像的 Top 5”往往是不够的。如果用户问了一个完全无关的问题(比如你的库里全是“养猫知识”,用户问“怎么修火箭”),向量数据库依然会给你返回 5 条“相对最接近”的废话。
为了过滤掉这些无关结果,我们会设置一个相似度分值(比如 > 0.8)
SELECT
id,
content,
pm_cosine_similarity(feature, '{0.12, 0.88, ...}') as score -- 计算相似度得分
FROM my_knowledge_base
WHERE pm_cosine_similarity(feature, '{0.12, 0.88, ...}') > 0.8 -- 只取相似度大于 0.8 的结果
ORDER BY score DESC
LIMIT 5;AI 推理和训练
训练 = 编译,推理 = 运行时
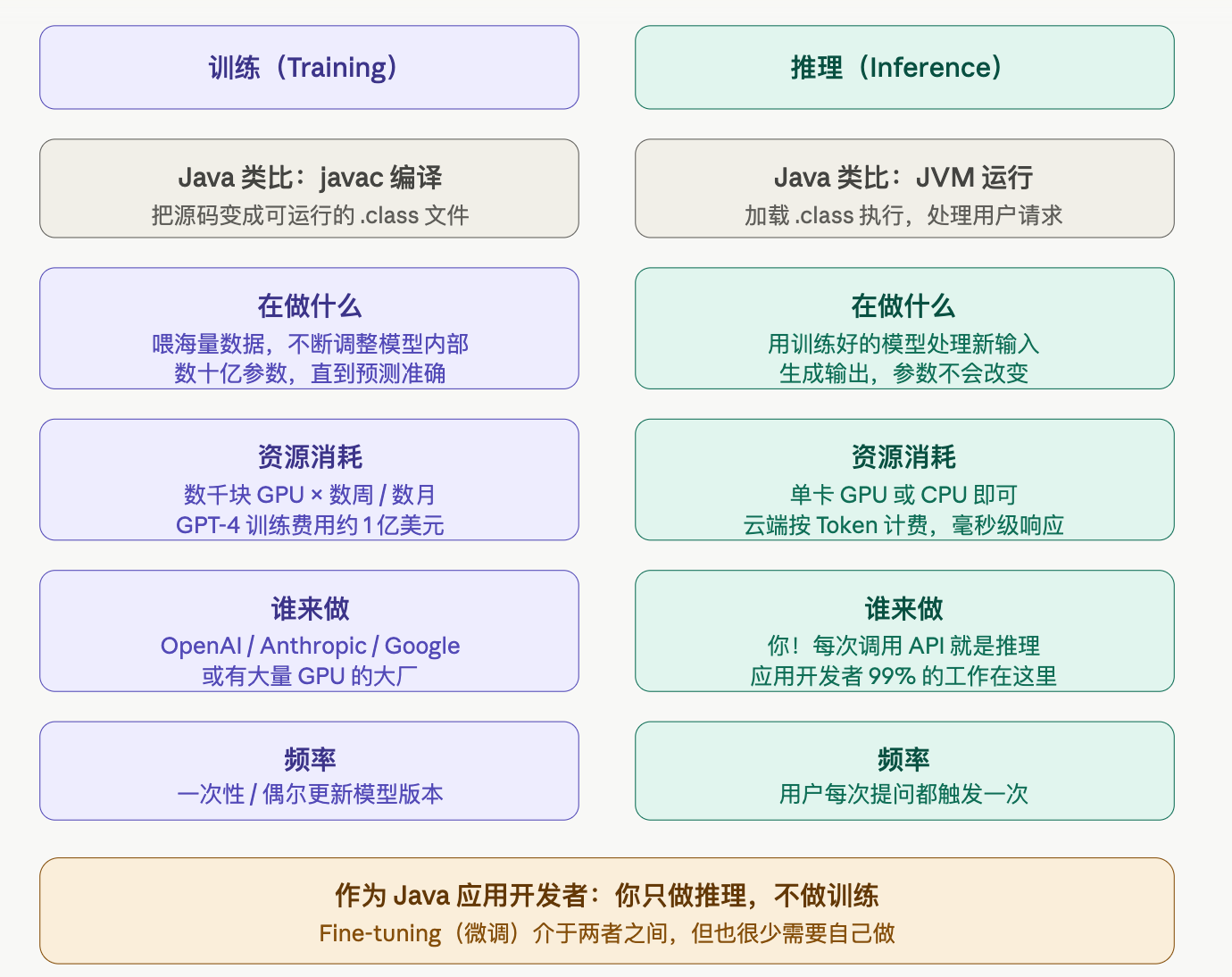
最核心的一句话
训练是"让模型学会某件事",推理是"用学会的模型做事"。你调用 POST /v1/messages 这个 API,就是在做推理——模型的参数在你调用的瞬间是完全固定的,不会因为你的输入而改变,就像运行中的 JVM 不会去修改 .class 文件一样。
训练过程到底在干什么(直觉版)
训练本质上是一个超大规模的"猜测-纠错"循环:
给模型看: "今天天气真___"
模型猜测: "棒"(概率 0.3)、"好"(概率 0.5)、"差"(概率 0.1)
正确答案: "好"
计算误差: Loss = 模型预测与正确答案的差距
反向传播: 沿误差梯度调整数十亿个参数(每个参数微调一点点)
重复: 这个过程在万亿级别的文本数据上跑数周这就是为什么训练要消耗天文数字的算力——不是做一次,是把这个循环重复万亿次,每次都要更新数百亿个参数。
还有一个中间地带:微调(Fine-tuning)
作为应用开发者,偶尔会听到"微调"这个词,它介于训练和推理之间:
用一个已经训练好的大模型(比如 Llama),在你自己的小数据集(比如公司的客服对话记录)上继续训练一小段时间,让它在特定领域表现更好。资源消耗比从头训练小几个数量级,但还是需要 GPU。
实际上,大多数业务场景用好 Prompt Engineering 和 RAG 就能解决,真正需要微调的场景比你想象的少得多。判断标准很简单:如果你需要的是"知识"(比如公司文档内容),用 RAG;如果你需要的是"风格或格式"(比如让模型始终用特定的语气回复),才考虑微调。
对写代码最直接的影响
推理有延迟,而且是流式的。模型不是算出完整答案再返回,而是一个 Token 一个 Token 往外吐,这就是你在 ChatGPT 上看到文字一个个蹦出来的原因。所以 Java 里调用 AI API 时,一定要处理流式响应(SSE / Server-Sent Events),否则用户要盯着空白等 5–10 秒才看到第一个字,体验很差。这是进入阶段二"调用 API"之后最先要搞定的工程问题。
上下文窗口
先用一个 Java 最熟悉的东西来类比——上下文窗口就是模型的"工作内存",类似线程栈,大小有限,超出就丢弃。
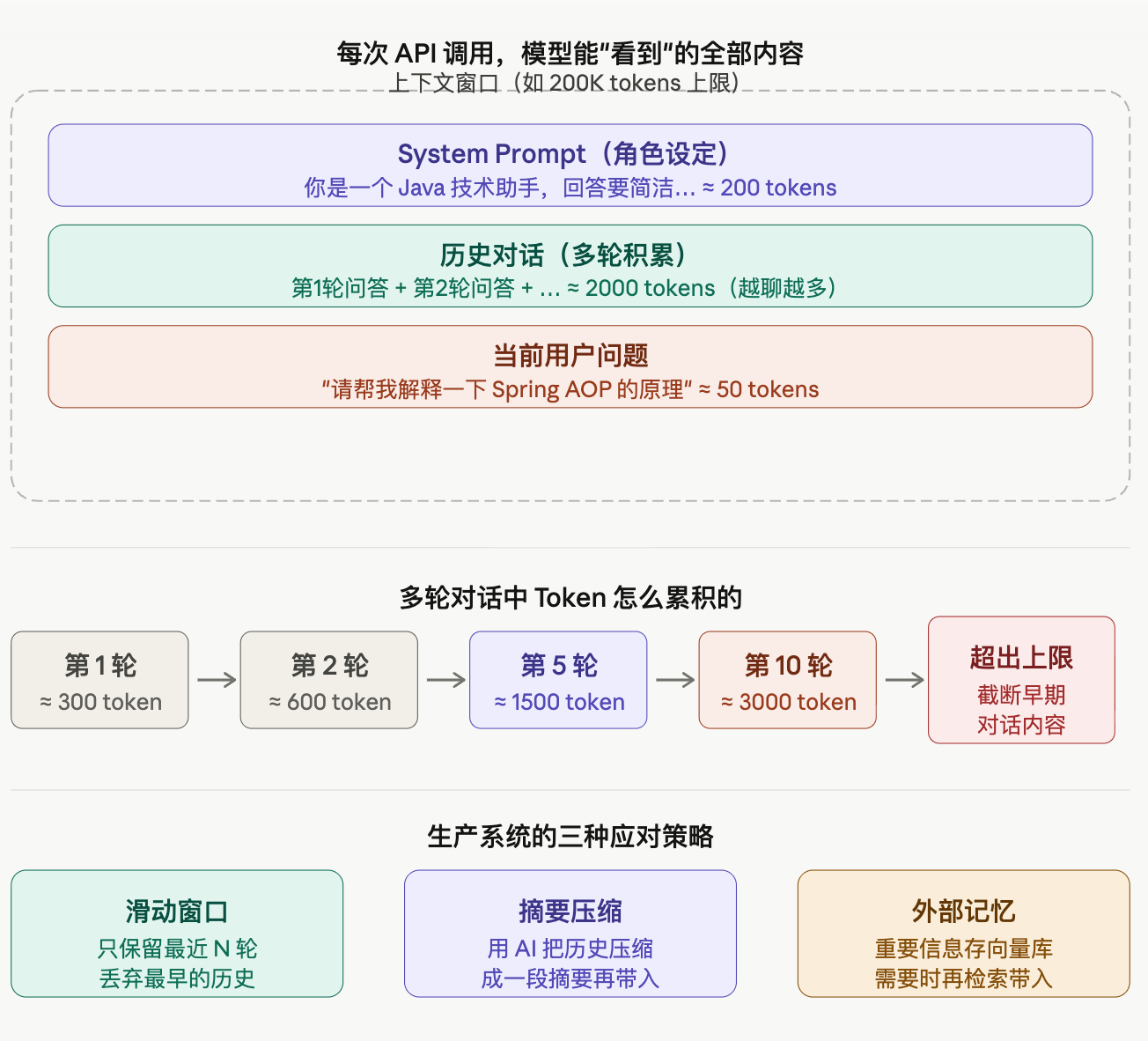
为什么有限制?从硬件说清楚
模型处理 Token 时,需要计算每个 Token 和其他所有 Token 之间的关系(这就是 Attention 机制)。计算量是 Token 数的平方级别——窗口翻倍,计算量翻四倍,显存也翻四倍。这是物理限制,不是厂商故意卡你。所以即便现在 Claude 支持 200K Token 的窗口,实际塞满了也会变慢、变贵。
用 Java 代码感受多轮对话的坑
模型没有服务器 Session,没有 ThreadLocal,没有任何"记忆"。每次 API 调用都是一个无状态请求。所以你必须在代码里自己维护对话历史,然后每次都完整带上:
List<Message> history = new ArrayList<>();
history.add(new Message("system", "你是一个 Java 技术助手"));
// 第1轮
history.add(new Message("user", "什么是 Spring AOP?"));
String reply1 = callApi(history);
history.add(new Message("assistant", reply1));
// 第2轮 —— 必须把完整 history 带上,模型才"记得"上一轮
history.add(new Message("user", "那它和 AspectJ 有什么区别?"));
String reply2 = callApi(history); // 带着第1轮的所有内容
history.add(new Message("assistant", reply2));
// 聊到第20轮... history 可能已经有几千 Token 了这就是为什么多轮对话的 API 费用会随轮数线性增长——每轮都要把所有历史重新发一遍。
三种工程策略的选择时机
滑动窗口最简单,适合客服类场景——用户一般只关心最近几轮,早期的"你好"、"请问有什么能帮您"根本不重要,直接扔掉没问题。
摘要压缩适合需要"记得整体脉络"的场景,比如长篇文档分析。每隔 N 轮,先让 AI 把历史总结成一段 200 Token 的摘要,替换掉原来的 2000 Token 历史,再继续对话。
外部记忆(结合向量数据库)适合需要跨会话记忆的场景,比如"记住用户的个人偏好"。把重要信息向量化存起来,下次对话开始时先检索相关记忆注入 Prompt,实现跨会话的"长期记忆"。
实际项目里,这三种往往组合使用:滑动窗口控制短期历史,摘要保留中期脉络,向量库存储长期偏好。这是做 AI 应用绕不开的工程问题,比调 API 本身要复杂得多。
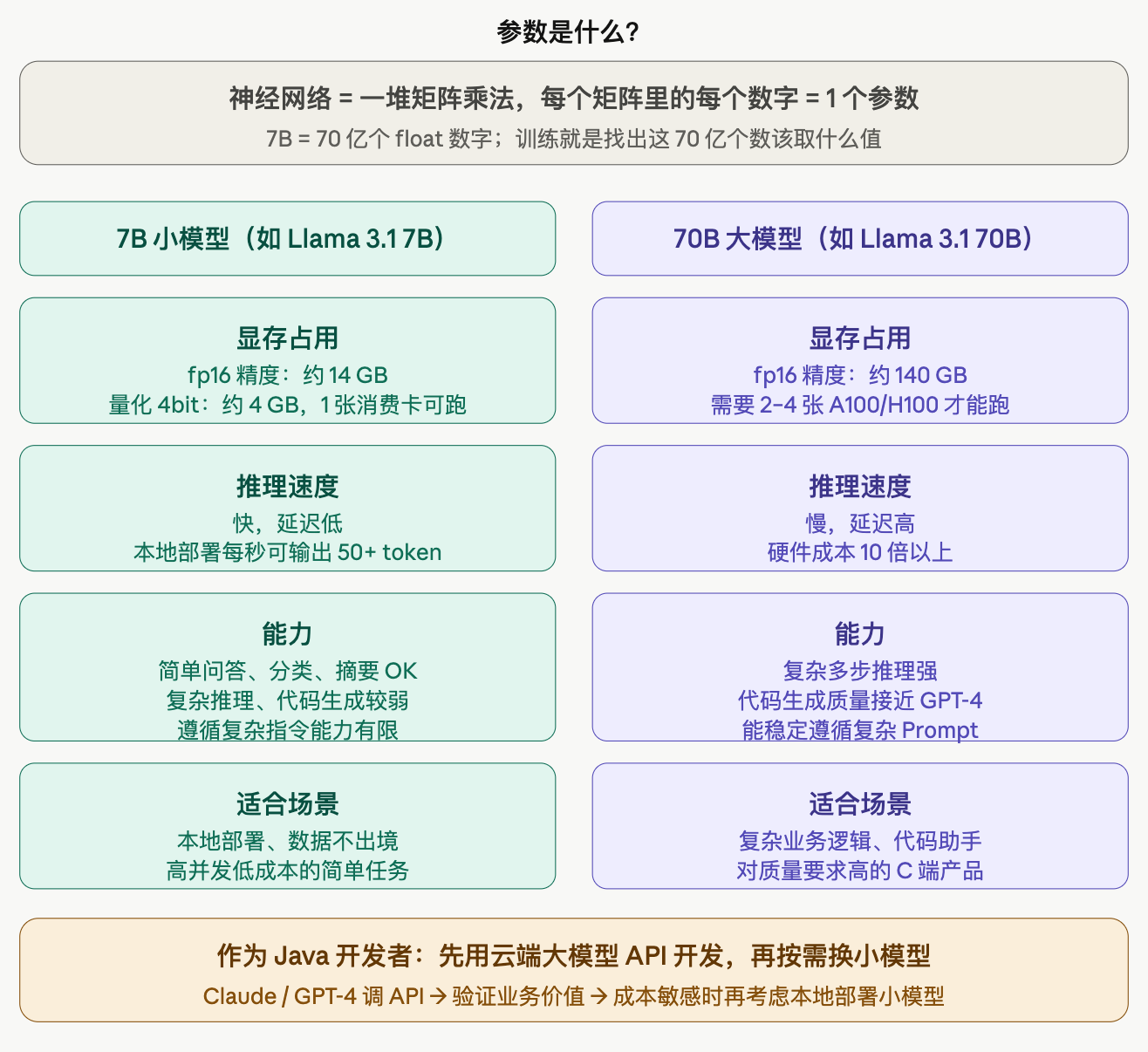
模型参数量
先用一个 Java 最熟悉的类比打底——参数就是模型里的"变量",训练就是找出让这些变量取什么值能让预测最准。
参数是什么——用 Java 代码打比方
想象一个极度简化的"预测下一个词"的函数:
// 超简化版神经网络的一层
float[] layer(float[] input, float[][] weights, float[] bias) {
// weights 里的每一个 float 就是一个"参数"
// 训练就是找出让预测最准的 weights 和 bias 的值
float[] output = new float[weights.length];
for (int i = 0; i < weights.length; i++) {
float sum = bias[i];
for (int j = 0; j < input.length; j++) {
sum += input[j] * weights[i][j]; // 矩阵乘法
}
output[i] = Math.tanh(sum); // 激活函数
}
return output;
}真实的 LLM 就是把这样的矩阵乘法叠了几十层到几百层。7B 的模型意味着所有 weights 和 bias 里的 float 加起来有 70 亿个。参数越多,模型能记住的"知识"和能表达的"规律"就越复杂。
内存怎么算?
每个参数存储为 fp16(2 字节),7B × 2 字节 ≈ 14GB 显存;70B × 2 字节 ≈ 140GB 显存。一张消费级 RTX 4090 只有 24GB 显存,跑 7B 的全精度都困难,跑 70B 完全不可能。
这就是"量化"存在的原因——把参数从 fp16 压缩到 4bit(INT4),内存降低 4 倍,精度略有损失但通常可以接受。量化后的 7B 大约只需 4GB 显存,一台 Mac M2 都能本地跑。
B 之外还要看什么?
参数量只是一个维度,实际能力还受训练数据质量、训练方式、对齐程度影响。所以不能光看 B 数:
Mistral 7B 发布时打败了很多 13B 模型,因为架构设计和训练数据更好。Claude Haiku 参数量比 Llama 70B 少得多,但在很多任务上表现更强,因为 Anthropic 在对齐和训练质量上投入了更多。所以选模型的正确姿势是:看 Benchmark 分数 + 自己跑业务场景测试,不要单纯比参数量。
Java 开发者的实用决策树
大多数情况下,你根本不需要关心参数量,直接调云端 API 就好。只有在这几个场景才需要考虑自己部署小模型:数据安全要求不能出境(金融、医疗)、调用量极大导致 API 费用不可接受、需要极低延迟的边缘场景。这时候才去研究 Ollama、vLLM 这类本地部署框架,把 7B 或 14B 的模型跑在自己服务器上。
Temperature 参数
Temperature 控制的是模型"选词时有多随机"——用 Java 来说,就是给 Random 的种子加了一个可调节的噪声放大器。

从代码层面理解 Temperature 做了什么
模型每次生成一个 Token,本质上是在做一次概率采样。模型先输出一个原始分数(logits),再经过 softmax 变成概率分布,最后从这个分布里抽一个词:
// 伪代码:Temperature 的作用
float[] logits = model.predict(context); // 原始分数,如 [3.2, 1.1, 0.4, ...]
// Temperature 就是在 softmax 之前除以 T
float temperature = 0.7f;
for (int i = 0; i < logits.length; i++) {
logits[i] /= temperature; // T<1 → 分数差距放大 → 高分词更占优
// T>1 → 分数差距缩小 → 各词概率趋于均匀
}
float[] probs = softmax(logits); // 转成概率
int nextToken = sample(probs); // 按概率随机抽一个T=0 时除以接近 0 的数,最高分词的概率趋近 100%,等于变成 argmax,每次都选概率最高的词,输出完全确定。T=2 时各词概率被"压平",低概率词也有机会被选中,输出就开始乱。
top_p 是 Temperature 的好搭档
实际 API 调用里你会看到两个参数一起出现。top_p(也叫 nucleus sampling)限制的是"只从累积概率达到 p 的候选词里选":
// top_p = 0.9 的意思:
// 把所有词按概率从高到低排,取前 N 个词,
// 直到它们的概率加起来超过 90%,只在这 N 个词里采样
// 相当于自动过滤掉所有"太离谱"的词实践中的常用组合:需要确定性的场景设 temperature=0, top_p=1;普通问答设 temperature=0.7, top_p=0.9;创意场景设 temperature=1.0, top_p=0.95。不要同时把两个值都调得很极端,容易得到奇怪结果。
Java 调用 API 时怎么传这两个参数
// 以 Claude API 为例
String requestBody = """
{
"model": "claude-sonnet-4-6",
"max_tokens": 1024,
"temperature": 0.0,
"messages": [
{
"role": "user",
"content": "从以下文本中提取 JSON 格式的姓名和年龄:张三,28岁"
}
]
}
""";
// temperature=0 → JSON 抽取场景,输出格式稳定,不会随机加字段记住一个原则就够了:让模型做"找答案"的事(抽取、分类、结构化)用低 Temperature;让模型做"创造内容"的事(写文案、头脑风暴)用高 Temperature。这条规则覆盖了 90% 的 Java 后端 AI 开发场景。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 9
9 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)