[LLM量化] 深入理解大模型量化:GPTQ 原理解析
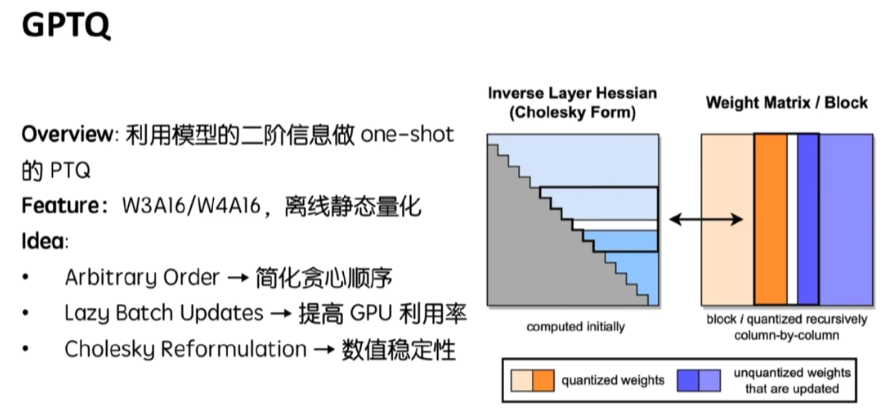
GPTQ是一种经典的后训练量化算法,专为大规模预训练模型设计。它属于权重量化方法(weight-only),采用均匀量化方式,支持对称和非对称量化。GPTQ的创新点在于:1)通过统一量化顺序避免重复计算Hessian矩阵;2)采用分组量化策略减少显存带宽压力;3)使用Cholesky分解提高数值稳定性。相比OBQ算法,GPTQ显著提升了量化效率,能在不训练模型的情况下实现W3A16/W4A16的低
二、GPTQ算法
接下来看这个比较经典的GPTQ,它的量化算法。从名字上也可以看到,它在我们前面的分类里面属于post training quantization,也就是不需要对模型做训练的。然后它是对任意的已经训练好的模型可以做量化。然后它是weight-only,也只对模型权重去做量化,那就没有static和dynamic的区别,而至于mapping type的话,它是属于uniform的,就是我量化的时候只要除以这个scale,然后做四舍五入到对应的这个整数值就可以。反量化的时候就是乘以这个scale对吧?对称和不对称的话,这个都是可以的那它的量化力度的话,文章里面介绍的是pre channel。

就GBTQ他这篇提出的是他不算最早的,之前也有一些量化算法了,而这些量化算法它又有哪一些问题呢?就是当时的话也是处于一个模型权重,或者说模型参数量越来越大的情况下。他当时说的是对这么大的模型,如果你用training的方法去做量化的话,它成本太高了,对吧?在千亿级别的参数,也就是100B以上的模型是很难做到的,那如果用post training quantization 的方法已经存在的这些直接做四舍五入的,也就是说直接在uniform基础上做四舍五入的。他在这么大的模型里做8B的量化效果还不错。但在3到4B的时候,将在图中看到的它perplexity会有一些明显的增高,这个时候模型就处于一个不可用的状态。
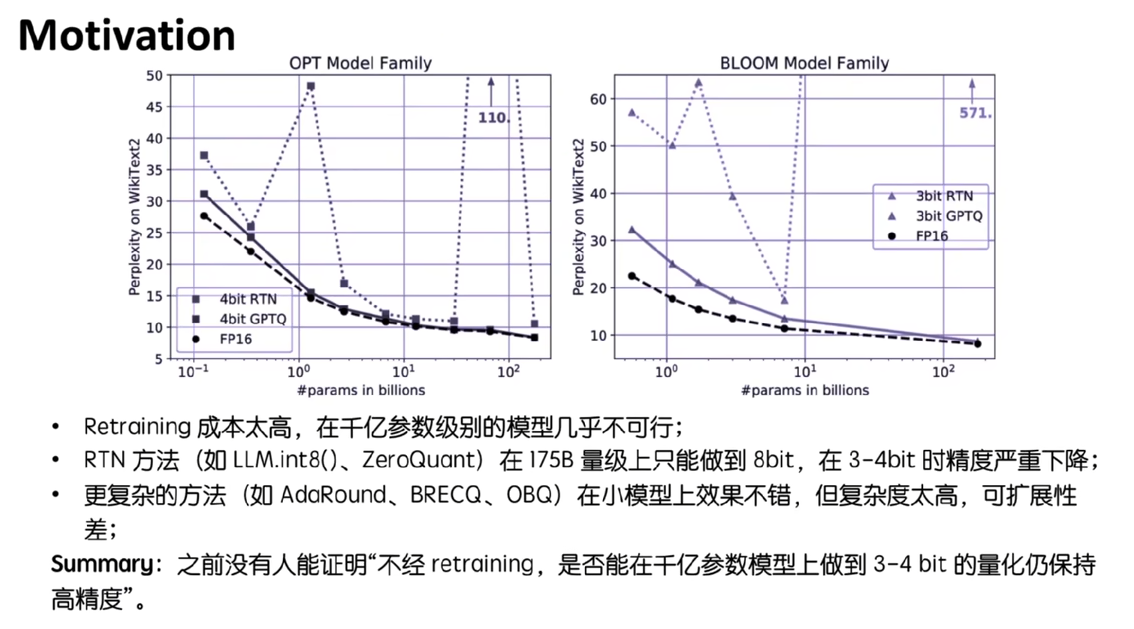
而除了这些四舍五入的办法,它还有一些比较更加复杂的算法。这些算法它虽然在小模型上效果不错,但这些算法在量化这个模型的时候本身复杂度就很高。像这里提到的Adaround,可能去量化这边175B的模型就需要几个小时,对吧?所以它的扩展性是很差的。那这篇文章想做的就是我有没有办法能够不用训练的方法,在这么大的模型上受到更低精度的量化,从而保持这个模型的效果呢?好,这就是GPTQ。它的总体思想是用模型的二阶的信息去做one shot的PTQ。
One shot是指我这个模型只要量化一遍就可以了,而不是说像有些方法我量化完以后要再倒回来调整权重来使得模型效果会更好,要量化好几遍的这种。他想做的是W3A16、W4A16,也就是我们前面说的we only这A16可能是BF16,也可能是FP16,但肯定就是16位的浮点数。它的总体思想分为这三点,都是在它的一个baseline的基础上去改进的。
那它的baseline是什么呢?我们首先来看一下他baseline的思想,就是叫optimal brain quantization。
2.1 optimal brain quantization
它的思想是这样,就是我们在做两个矩阵乘法的时候,假如我这里把W写在左边,activation写在右边,我们实际上的乘法。是可以看作W的每一行去乘以A去得到O的每一行,那我其实我们量化的误差也是可以按照W的每一行去看这个问题的。
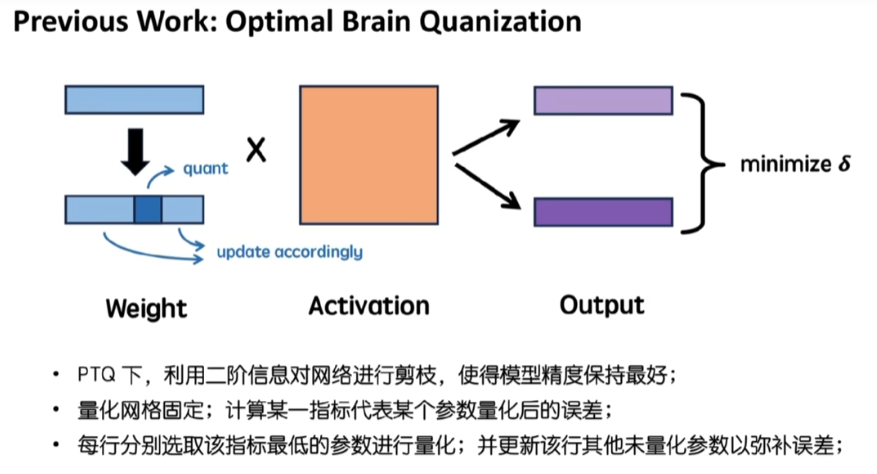
它是一个怎么样的思想呢?就是说我按照行去做量化,而每次我选择行中的某一个元素进行量化。量化完,然后在乘法的时候反量化,再做这个乘法的话,肯定和原来的这个不量化的情况相比会有一定的误差,那我可以对其他的元素,也就是除了我们现在选中的这个元素,其他的元素进行一些调整,来使得这个量化前后的乘法的它的误差达到最小。这就是optimal brain quantization它的思想。
也就是说我们需要确定两个事情。第一个是我要有一个函数来代表我。当我模型的权重做出调整以后,这个量化的误差是多少?比如说从W变成WC的情况下,这个误差它是一个关于这个变化的一个什么样的函数。第二个是有了这个函数的情况下,选取了某一个元素量化了以后,我要怎么样更新其他的权重,我要使得这个WC最小。这就是OBQ要解决两个问题对吧?第一个是说我要得出一个误差的函数。第二个是我要怎么使得这个误差的函数最小值。
我们具体来看,就假如这个乘法就是我们前面讲到的,我们这里activation用X去表示,它的乘法的话,我们就比如说W代表某一行,它经过某一种变化。比如说是量化了某一个权重元素,并且更新了其他权重元素,得到这个WC这样的变化以后,它的乘法误差的话,我们用所有元素的平方和去表示,可以得到这样的一个形式,然后我们对他做泰勒展开,最后得到这一项。

这一项是怎么得到的呢?首先小项可以丢掉,然后其次EW相当于就我没有做变化,所以它的误差肯定是0。一次项,WC相对于W有一点点的变化,它的误差肯定都是升高的,肯定是在W这个位置,它的误差是最小的对吧?你不可能比原始的状态的误差还要小。所以说这个一阶导数就是零,这一项也可以去掉了,那最后只剩下来这个东西。
而这个东西的话经过我们的一些计算,你可以发现中间的这个Hessain矩阵的话正好是两个activation,就activation乘以activation的转这样的一个形式。我们再带回去的话,你就可以得到这个EWC的表达式。这个EWC就是我们误差的函数。也就是说从权重W变成WC以后,我们乘以activation的误差实际上是EWC,这个函数就反映了我们做出某一种变化以后的误差。
那我现在想要最小化这个误差怎么做呢?也就是说假如我量化了某一个权重,比如说我量化了第Q个权重元素,那其他元素我想作为一些稍微的调整。比如说这里的delta w,这里的delta w当然是一个向量,它的Q位就代表量化前后元素本身的误差,而它的其他元素则代表我其他人没有量化的权重,我想做多少的更新能够弥补这个量化的权重所带来的误差,那我想做的就是使得这个东西最小化了,而且有一个约束,就是Q是个被量化的权重元素,也就是Q它的变化的值是确定的。而其他没有被量化的权重,我到底要更新多少来弥补它的误差,这个是不确定的。我们要求出这个delta w的在这个约束下使得这个值最小化,达到这样的一个解。那这个可以用拉格朗日的方法去解,我们最后一直解解可以得到,是这样的一个表达式,也就是最终权重的变化是这样的一个形式。

这个qq代表是第Q 行第Q列,同时它的误差也可以用Ewc这个式子去表示。OBQ的思想实际上是我对某一行,就是对于这一行权重而言,我对每个元素都尝试量化它,然后更新其他权重去选取误差最小的权重。每次选择误差最小的权重进行量化,然后更新其他权重。那被量化后的这个权重我就固定住了,就不去动它了。而其他的权重就这一行中其他的权中在进行相同的操作重复,直到所有权重都量化完毕。

当然你会发现,当我某一个权重它被量化完,然后我去不理他了以后,实际上我要对hessian矩阵进行更新的。为什么呢?因为这个hessian矩阵你想它是X乘以XT对吧?它是一个X乘以XT。这里的每一列实际上是代表每一个token,token这个维度是被reduce掉了。它外围的这个维度实际上就是代表的W的每一列。
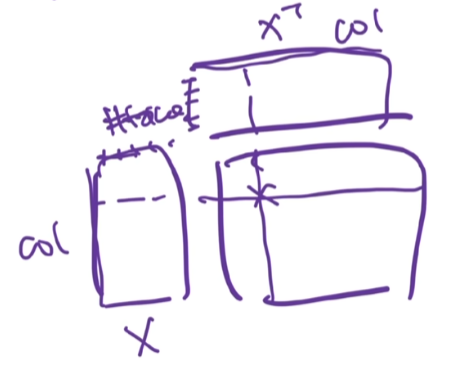
所以说当我某个元素我被量化完了以后,那它对应的这一列就要被删掉。比如说我要把海选矩阵中这一行这一列给它删掉,就得到圣体育元素的它的hessian矩阵。那这个hessian矩阵它的更新的话也会有一些对应的公式。
在OBQ里每一行的量化都是单独进行的,也就是说每一行选择第一个被量化的权重可能是不同的对吧?比如这个权重里面每一行单独的去选择它的误差最小的,第一行可能选中这个元素,第二行可能选中这个元素。那相当于我们每次都需要就对这个权重中每一个元素,这个tensor中每一个元素都算一遍,还是矩阵算一遍的开销是这么多,一共有这么多元素。所以它的时间复杂度是这样的,这个时间复杂度实际上是相当高的。

那GPTQ的话实际上就是想解决OBQ在这方面的问题。
2.2 GPTQ算法创新点
他所提出的第一个设计点就是,他发现你每一次选择这个误差最小的,其实没有必要,为什么呢?因为量化到后面的时候,比如量化到只有这两个元素了,那我选择一个去量化,然后他去补偿他的量化误差,或者选择他量化他去补偿他的量化误差,实际上都会引入较大的误差,就是你这样画到后面误差都会大的,所以说没有必要刚开始就选择最小的,其实按照任意顺序选都差不多。那最好的办法是什么?就我每一行按照相同的步骤去选,就是我我每一行现在不是单独做量化了,我每一次都是第一个量化,就选择所有行的第一个元素,然后更新其他的。第二次还是选择第二个,然后更新其他的元素。这样同步的顺序可以导致我hessain矩阵的更新也是同步的对吧?因为对于第一行来说,我hessain矩阵是删掉第一行第一列。对于第二行来说也是删掉第一行第一列。

就他们可以共用同一个hessain矩阵的更新。这样的话我们的时间复杂度就可以相当于减少了一个维度,这是GPTQ的第一个优化点,就是我所有行都按照相同节奏去做量化。、
而第二个设计点是我每量化一列都要更新一次hessain矩阵,这个对于显存带宽的压力是很大的。因为我的这个hessain矩阵实际上是存在这个HBM里的,那我每次更新的时候,我都要把它拿到sram里面,然后再更新完以后再拿回来,这整个传输量大,因为hessain矩阵是一个,两个维度跟你的模型大小是有关系,那我们也是没有办法说只跟一些hessain矩阵的一部分,就我只把要更新的那部分传输上去,然后不要的再传回来。
这里的解决办法就是我按组进行量化。比如说我每次只更新这几列的元素,那相同的节奏还是有的,也就是说每一行都是更新。比如说更新这一个元素,然后前面橙色的部分是已经量化完的,后面蓝色的部分是我要进行调整,来弥补白色的造成的量化误差。这样的话我就可以把对hessain的更新只限制在这几列里面。比如说这几列对应的海选矩阵是这几列的话,那就是选矩阵这个词。矩阵我每次只要更新这一部分就好了。当然我这一组列都量化完了以后,它会进行一个batch update。也就是说一次性更新剩余的所有微量化的权重,来弥补这一组所造成的量化误差。这一组的更新公式的话,其实也就是把前面的那个公式给它变成batch的形式,这是它的第二个设计点。
而第三个设计点是我们可以看到前面的这个hessain的它的更新实际上是有非常多的计算的,就非常多的数学计算。而计算多了,这个hessain矩阵会变得数值不稳定。因为理论上它是一个XXT的矩阵,它是一个半正定的矩阵。就是如果你经过了好几次更新,它会变成容易变成一个不定矩阵。不定矩阵带来的后果就是我们更新这些元素本身是为了弥补前面已经量化的权重所引起的误差。那有可能你hessain变得不定了以后,就会变成你更新了这些反而加重了它的误差。
常见的一个方法去保持它的方法叫做我把它的对角线加上一个元素。这里当lambda一般都是大于零的,也就是说我把hessain矩阵里面对角线的元素给它加重,让它对角占优,比其他元素都明显要大。那这样的话它就不容易变成不定矩阵。这样你可以想到就假如一个矩阵,比如说它对角元素的ABCD,它的逆矩阵基本上就约等于A分之1、B分之1、C分之1、D分之1,不会有什么问题的,但是他是说这个方法基本上只在小模型起效,也就是这个矩阵比较小的情况下会起效。

而这篇文章提出的方法是我就对他做这个classic分解。比如说H其实还可以做某一种分解,变成这种形式H = L * LT。其中L是一个下三角矩阵,这边画的是上三角,就是L的转置。这样的好处是我还选矩阵的更新,实际上我是想删掉某一行某一列,然后算出它的逆矩阵对吧?但在这里的话,这个下三角它的更新实际上就是删掉对应的某一行某一列,然后我再求它的逆矩阵,它的逆矩阵这个时候就变成了LT-1 * L-1。这个三角矩阵它本身算力是比较容易的,那我就不更新这个逆,而是我更新hessain矩阵分解以后的这个L矩阵,这样它的数据稳定性会更好。
我们来总结一下GPTQ,他在OBQ的基础上提出了三点的优化。第一个是与其让每一行每次都选择不同的权重,我不如让他们选择相同位置的权重。这样的话我就不需要计算这么多的hessain矩阵。第二个是我每次都只在一个组内去对权重做更新,这样子我更新的hessain矩阵的大小也会变小,对带宽的压力会更小。第三个是我对hessain矩阵进行这classes的分解,来提高它的数据稳定性。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 16
16 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)