【Generative AI For Autonomous Driving】6 生成式AI在具身智能领域的拓展:从自动驾驶到通用机器人的技术迁移
从自动驾驶到通用具身智能,生成式AI正在打通感知、决策与执行的任督二脉。图像与传感器生成模型丰富了智能体的感知能力,生成式规划器和轨迹模型提供了适应新情境的灵活动作生成,基于大语言模型的架构赋予智能体强大的推理引擎,而生成式数据增强与仿真则为训练鲁棒、可泛化的智能体提供了燃料,并确保其在关键罕见场景中得到充分测试。这种技术的双向流动正在加速:自动驾驶中的世界模型技术正在赋能家用机器人和工业自动化,
文献来源: Wang Y, Xing S, Can C, et al. Generative ai for autonomous driving: Frontiers and opportunities[J]. arXiv preprint arXiv:2505.08854, 2025.
自动驾驶技术作为具身智能(Embodied AI)的重要子集,其发展与技术突破往往与更广泛的机器人学、智能体研究相互促进。当我们将目光从单一的车辆场景扩展到涵盖人形机器人、机械臂、无人机乃至更多形态的智能体时,生成式AI展现出的潜力远远超出了数据合成的范畴。本章将探讨生成式AI如何在更广阔的具身智能领域发挥作用,涵盖多模态感知、动作决策、虚实迁移以及安全验证等关键议题,揭示自动驾驶技术与通用人工智能之间的深层技术共鸣。
一、具身智能与基础模型:技术范式的交汇
具身智能强调智能体通过物理身体与环境的交互来学习和进化,这与自动驾驶系统通过传感器感知世界、通过执行器改变状态的本质高度一致。近年来,基础模型(Foundation Models)的兴起为具身智能带来了新的可能性——这些在海量数据上预训练的大规模模型展现出强大的泛化能力和少样本学习特性,正在重塑机器人学的技术栈。
在自动驾驶领域,我们已经见证了生成式AI在场景理解、轨迹预测和决策制定中的威力。而在更广泛的具身智能场景中,这些能力同样适用:无论是机械臂抓取物体、人形机器人导航,还是无人机群协同作业,生成式模型都在提供统一的技术底座。值得注意的是,许多在自动驾驶中验证有效的技术路径——如基于扩散模型的轨迹生成、基于神经辐射场(NeRF)的环境重建、以及多模态大语言模型(MLLM)的推理能力——正在快速向通用机器人领域迁移,形成跨域的技术红利。
二、生成式模态在具身智能中的多元融合
生成式AI在具身智能中的应用首先体现在对多样化感知模态的处理与增强能力上。不同于自动驾驶主要依赖视觉(相机、激光雷达)和定位数据,通用具身智能体往往需要处理包括视觉、触觉、力觉、听觉在内的多模态信息。
2.1 视觉模态的深度生成与预测
视觉感知为具身智能体提供了对环境的全局理解。生成式图像模型(如GAN、扩散模型)和视频预测网络不仅增强了智能体的感知能力,更赋予其"想象"未来状态的能力。扩散模型被用于生成目标图像或预测中间物体状态,为策略学习提供"常识性"的几何推理指导。在机器人操作中,基于视频生成的世界模型允许智能体基于候选动作模拟未来的感官体验,这种生成式预见能力已被广泛应用于多步操作规划和导航任务。
在三维感知层面,神经辐射场(NeRF)及其衍生技术使机器人能够生成逼真的3D和4D场景,重建未观察到的视角或创建与真实环境高度匹配的合成深度信号。基于NeRF的模型被用于预判障碍物、规划无碰撞路径以及模拟环境动态变化。CLIP-Fields进一步将3D结构嵌入到视觉-语言空间中,支持语义导航任务,使智能体能够根据自然语言描述的对象进行推理和定位。
此外,纯合成的激光雷达数据生成技术(如基于扩散模型的LidarDM)能够生成物理上合理的连续4D激光雷达点云,这些生成式传感器模型可直接集成到仿真流程或智能体感知系统中,提供多样化且逼真的训练数据,显著提升鲁棒性而无需大量的真实世界数据采集。
2.2 触觉模态的生成式建模
虽然自动驾驶较少涉及触觉交互,但在通用具身智能中,触觉感知对于接触密集型任务(如抓取、插入、物体识别)至关重要。视觉-触觉传感器(如DIGIT、GelSight)的普及推动了触觉驱动生成模型的发展。
生成式模型在触觉领域的应用包括:从触觉输入重建接触几何形状(如NCF-v2利用变分自编码器和Transformer预测物体表面与环境的接触分布)、通过掩码自编码重建缺失的触觉区域(TacMAE)、以及将触觉信号与视觉和语言进行语义对齐(Sparsh、UniTouch)。这些技术使智能体能够基于触觉反馈生成反应式动作计划,甚至在物理上不可访问的表面上预测触觉反馈,实现跨模态的感知补全。
三、从感知到动作:VLA模型的端到端决策
在具身智能中,将感知信息转换为物理动作(Perception-to-Action Translation)是核心挑战。大语言模型(LLM)和多模态大模型(MLLM)的引入,使得"视觉-语言-动作"(Vision-Language-Action, VLA)模型成为当前研究的前沿范式。
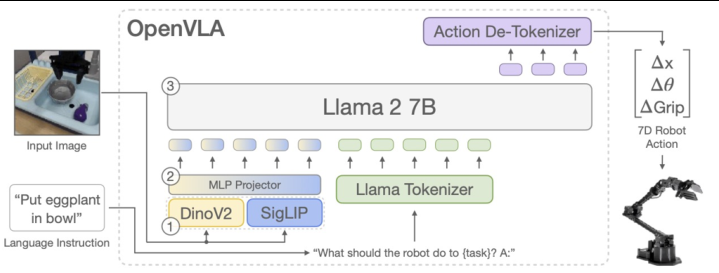
VLA模型通过统一的架构处理视觉输入、语言指令,并直接输出动作策略。与自动驾驶中的端到端驾驶模型类似,这些系统能够基于视觉观察和高层次的自然语言指令(如"将茄子放入碗中")生成具体的机械臂运动轨迹。代表性工作如RT-2、OpenVLA等,利用预训练的视觉-语言模型(VLM)作为骨干,通过添加动作Tokenizer和De-Tokenizer,将连续的动作空间离散化为可预测的Token序列。
这种架构的优势在于:首先,它继承了LLM的常识推理能力,能够理解复杂的语义指令;其次,通过在大规模互联网数据上预训练,模型具备了开放世界的知识,能够处理训练时未见过的新物体或新场景;最后,统一的生成式框架支持端到端的梯度优化,使得视觉、语言和动作表示能够在同一语义空间中对齐。
在自动驾驶与机器人学的交叉领域,这种技术迁移尤为明显。自动驾驶中的BEV(鸟瞰图)表示方法与机器人学中的占据地图(Occupancy Map)具有数学同构性;而用于驾驶轨迹生成的扩散模型,同样适用于机械臂的路径规划。这种技术同源预示着未来通用具身智能平台的诞生。
四、破解虚实鸿沟:Sim2Real迁移的生成式方案
仿真到现实的迁移(Sim2Real)是具身智能面临的经典难题。仿真器往往简化物理属性(质量、摩擦、形变),而真实世界交互充满变数。生成式AI为缩小这一"现实差距"提供了多维度的解决方案。
4.1 域随机化与视觉对齐
生成模型通过创建具有足够变异性的合成数据,使策略学习对视觉域差异具有不变性。扩散模型和NeRF被用于生成在不同光照、纹理和天气条件下的场景变体,通过域随机化(Domain Randomization)增强策略的泛化能力。例如,在自动驾驶中用于模拟不同天气的视觉生成技术,同样被用于机器人学中模拟不同材质的表面反光、阴影变化等视觉干扰。
4.2 动态物理匹配
针对仿真与真实世界在物理动态上的不匹配(如质量、摩擦系数的差异),生成式模型被用于合成多样化的物理参数或模拟合理的动态扰动。基于学习的表征和自动建模方法,如Dynamics-Augmented Neural Objects(DANOs),通过深度网络参数化的连续密度场捕捉视觉外观和动态属性,使仿真环境更好地反映真实交互行为。Real2Sim流程则通过从机器人交互数据中直接估计视觉几何、碰撞模型和惯性参数,自动生成仿真就绪的资产,最小化手动调参工作。
4.3 罕见任务与长尾场景生成
仿真环境往往难以捕捉真实世界的长尾分布(Long-tail Distribution)。生成式AI通过有针对性地创建具有挑战性的边缘案例(如罕见的杂物配置、动态障碍物或环境干扰)来解决这一问题。扩散增强智能体(Diffusion Augmented Agents)利用扩散模型从先前失败的轨迹中合成成功的结果;Gen2Sim结合图像扩散模型和大语言模型,自动生成纹理化的3D资产、任务分解和奖励结构,构建具有多样化物理动力学的复杂操作环境。
这些技术不仅适用于自动驾驶中的罕见交通事故模拟,也为机器人学中的异常处理(如滑倒、碰撞恢复)提供了数据基础。
五、生成式工具链:训练增强、推理能力与安全保障
生成式AI不仅改进了具身智能体内部的模型架构,更革命性地改变了训练数据的合成方式、推理过程的实现以及安全验证的手段。
5.1 可扩展的数据集增强
在机器人学习中,生成式管道能够合成新的训练样本,同时增强多样性和真实感。代表性方法如ROSIE(Robot Learning with Semantically Imagined Experience),利用扩散模型和大语言模型通过在新物体或干扰物上绘制(Inpainting)来语义化地扩展机器人数据集,生成逼真且物理一致的增强图像。UniSim提出了通用的动作条件模拟器,基于智能体动作预测未来观察,支持跨操作和导航任务的完全仿真长时程训练。
在布局层面生成以多样化训练场景方面,Context-Aware Layout Generation等方法通过推理语义和文化上下文来生成3D物体排布;LayoutVLM和LayoutReasoning利用视觉-语言模型通过基于优化或推理的管道合成物理合理且语义一致的场景布局。
5.2 多模态推理与认知架构
生成式模型为具身智能的多模态推理提供了支持。近期的研究提出了闭环架构,其中大语言模型用于生成关于目标和策略的高层次推理,而生成式模型则模拟提议动作的结果以验证其可行性。在抓取与操作中,推理调优(Reasoning-Tuning)方法将语义可供性感知与底层控制适应相结合;多模态抓取(Multimodality Grasping)通过解释隐式语言指令来指导基于部件的抓取行为。
在人机协作和多智能体协调方面,基于视觉-语言模型的架构能够动态解释和响应人类组装指令;时间子图推理(Temporal Subgraph Reasoning)解决了多人类-多机器人协作中的任务图动态构建问题。这些技术展现了生成式AI如何使具身智能体从底层控制扩展到复杂环境中的高层次灵活规划。
5.3 环境合成与安全验证
生成式工具在环境合成和安全验证方面展现出独特价值。语言驱动的生成模型能够合成多样化的布局、修改物体放置并引入环境变化,为评估具身智能体的鲁棒性提供了可扩展的手段。ChatScene等方法利用大语言模型从自然语言提示生成安全关键的驾驶场景,并将其转化为可执行的测试用例。类似地,在机器人学中,LLM可以生成假设条件(如"假设地面湿滑"或"物体易碎"),生成式仿真模型则将这些场景具象化,无需对硬件造成物理风险。
对于安全验证,生成式模型能够创建罕见事件进行边界条件测试。LidarDM等系统通过合成包含意外障碍物或动态智能体的真实激光雷达序列,评估自主系统对罕见或危险情况的响应。这些技术允许进行"假设"分析、对抗性训练和边界条件的系统探索,而无需等待真实部署中的罕见事件发生。
结语:技术融合与未来展望
从自动驾驶到通用具身智能,生成式AI正在打通感知、决策与执行的任督二脉。图像与传感器生成模型丰富了智能体的感知能力,生成式规划器和轨迹模型提供了适应新情境的灵活动作生成,基于大语言模型的架构赋予智能体强大的推理引擎,而生成式数据增强与仿真则为训练鲁棒、可泛化的智能体提供了燃料,并确保其在关键罕见场景中得到充分测试。
这种技术的双向流动正在加速:自动驾驶中的世界模型技术正在赋能家用机器人和工业自动化,而机器人学中的触觉生成和精细操作技术也在反哺自动驾驶的传感器仿真和车辆控制。可以预见,随着生成式AI的持续演进,我们将迈向能够跨域学习、推理和行动的真正通用具身智能体。
在下一篇(也是本系列的最后一篇)中,我们将整合原论文的第八章与第九章内容,深入探讨生成式AI在自动驾驶领域的未来机遇、开放挑战以及社会影响,包括理论基础的深化、伦理安全的保障、以及从城市交通规划到低空经济的宏观展望。敬请期待这场关于智能出行终极形态的深度思辨。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献49条内容
已为社区贡献49条内容

所有评论(0)