推理引擎系列(五)《大模型服务系统》
本文系统阐述了大模型推理服务的架构设计与优化方法。首先介绍了基础功能模块,包括用户交互和会话管理,重点分析了KV Cache的内存管理策略。针对单用户多会话场景,对比了简单实现、KV Cache池和PagedAttention三种方案,其中vLLM的PagedAttention通过内存分页技术显著提升了并发能力。在多用户服务方面,详细解析了OpenAI风格API接口、服务层架构和核心调度策略,包括
目录
3.优化:Paged Attention(vLLM 核心创新)
本文聚焦大模型推理服务系统架构,讲解单用户推理服务与多用户推理服务区别。
大模型推理服务基本功能
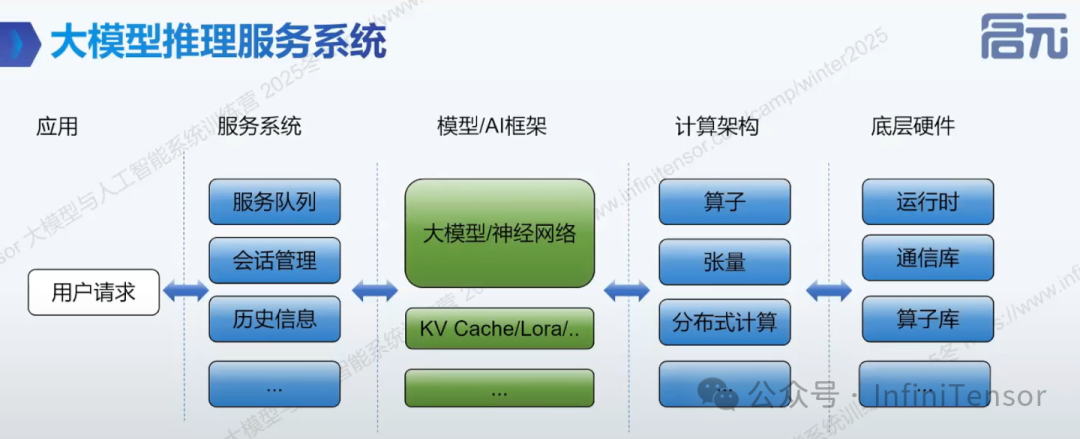
1.用户交互功能
-
• 用户输入与模型推理
-
• 流式输出与中断推理
-
• 多轮对话与历史问题修改
-
• 历史会话记录与管理
2.会话管理
-
• 会话管理的核心之一是 KV Cache 管理,但同时还包括对话历史、上下文裁剪策略及会话生命周期控制等内容
-
• KV Cache 的内存分配与最大上下文长度
-
• 对话总长度超过最大上下文长度的处理方法
-
• 保留最近 n 轮对话
-
• 对更早的对话进行总结
-
• 对用户所有历史对话进行归纳
-
单用户、多会话实现与优化
1.简单实现方法:
-
• 每个会话绑定一个 KV cache
-
• 切换会话时切换 KV cache
-
• 优点:会话 KV cache 命中率高
-
• 缺点:KV cache 不能无限分配
2.优化:KV cache 池
-
• 固定数量 KV cache
-
• 前缀匹配方式分配
-
• 缺点:总会话数受限,内存利用率低
3.优化:Paged Attention
(vLLM 核心创新)
-
• 使用“内存页”思想
-
• 动态分配内存块
-
• 内存共享与引用计数
-
• 在显存约束下支持大规模并发会话
-
• 复用与内存回收机制
多用户服务实现
1.多用户与单用户区别:
-
• 多用户服务中,多个用户通过网络接口同时向推理服务发送请求,服务端需要处理并发与调度问题
-
• 任意数量的请求随时可能出现,服务需要第一时间响应
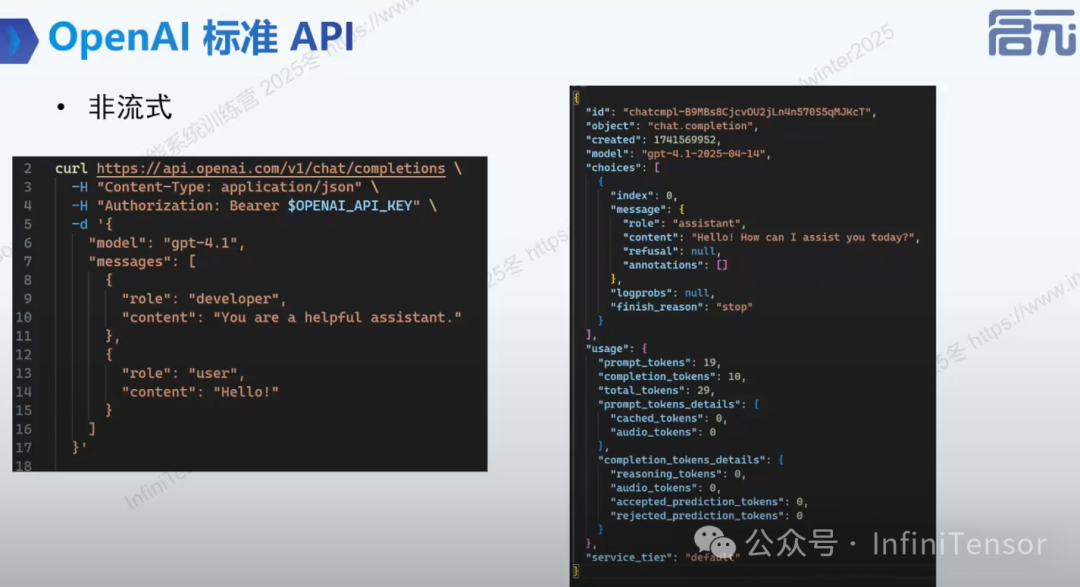
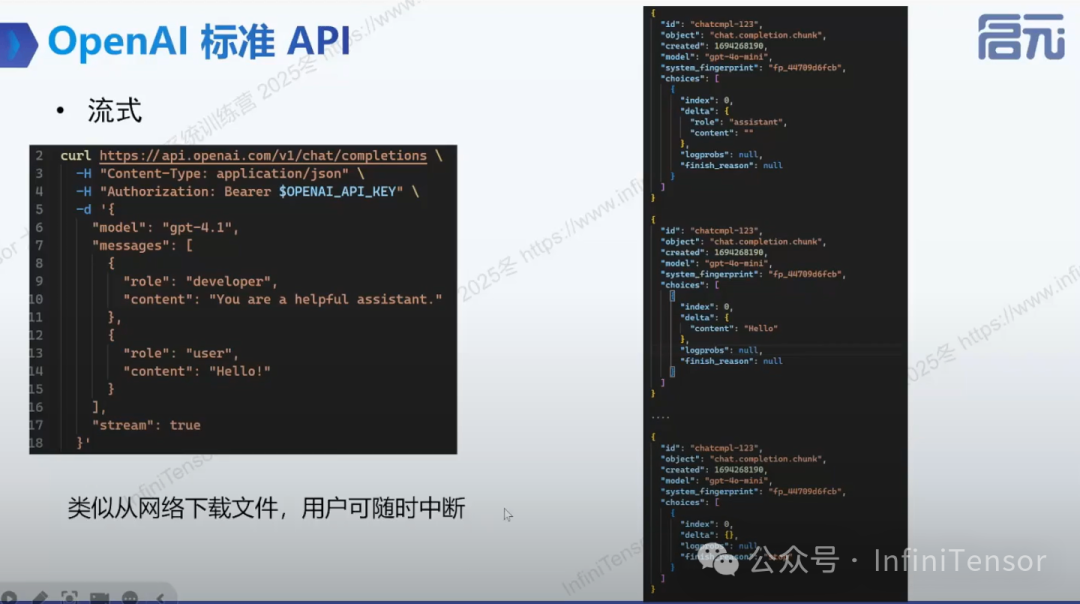
2.标准 API 介绍
-
• 业界广泛采用并兼容的 OpenAI 风格 API 接口
-
• JSON 格式数据传输
-
• 流式与非流式接口
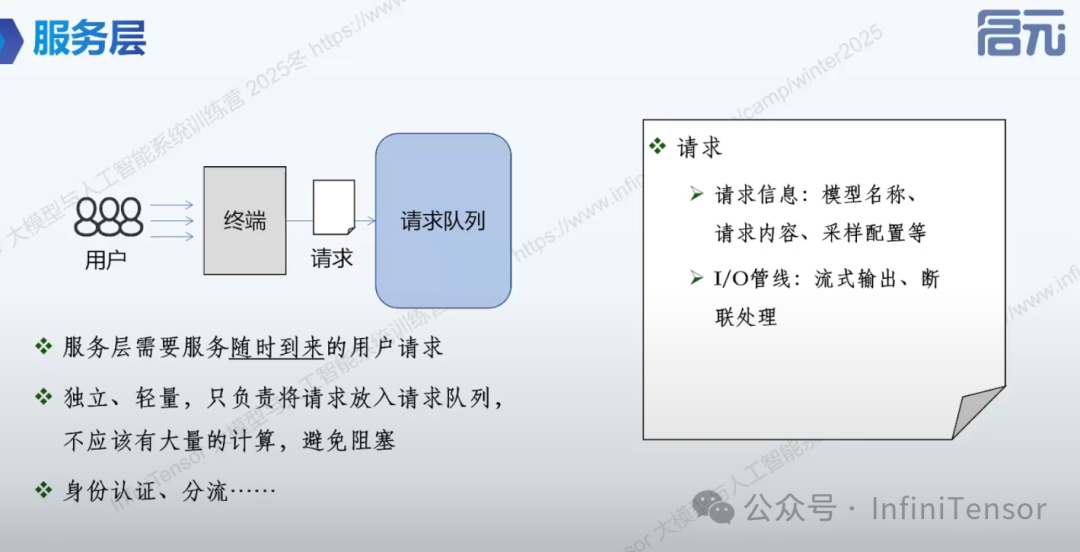
3.服务层功能
-
• 接收用户请求
-
• 请求队列管理
-
• 身份认证与网络分流
4.调度器功能
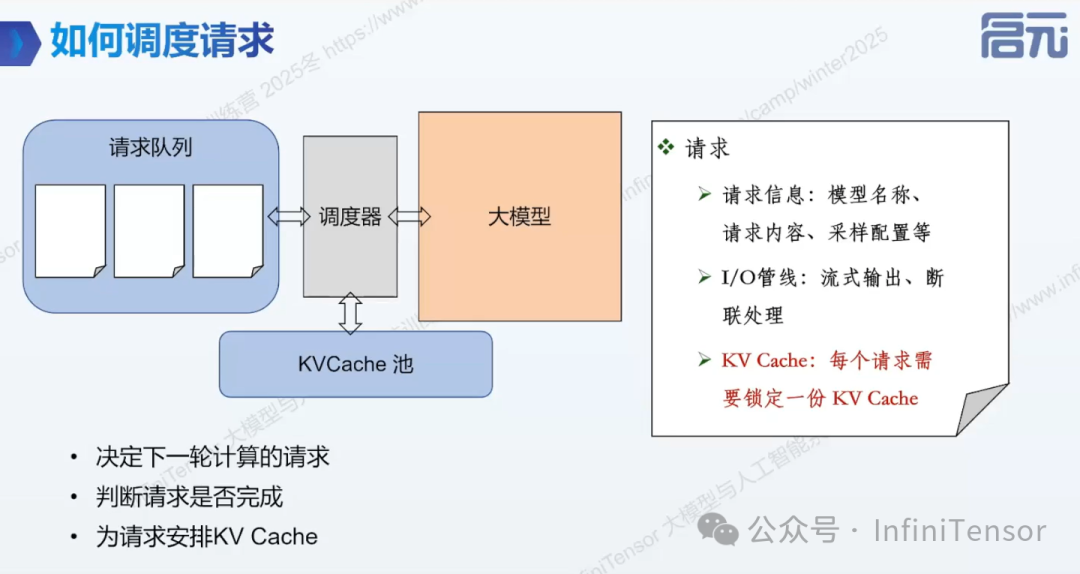
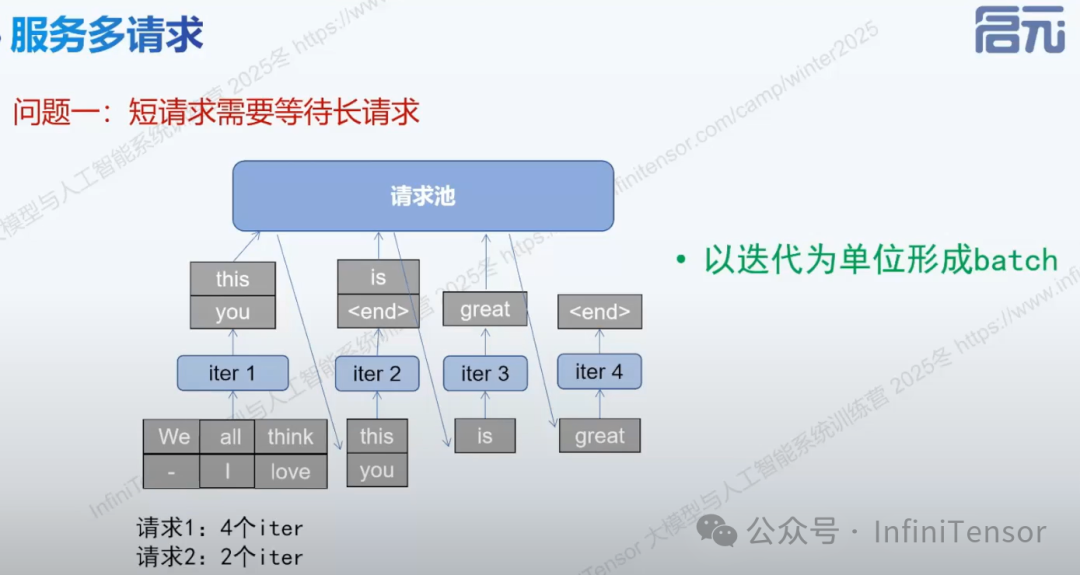
(1) 服务多请求
a. 以迭代为单位形成 batch
b. 跨请求批量化计算:
-
• 可批量化计算部分(MLP 层、RMS norm 等)
-
• 批量化难度较高的部分(Attention 相关的)

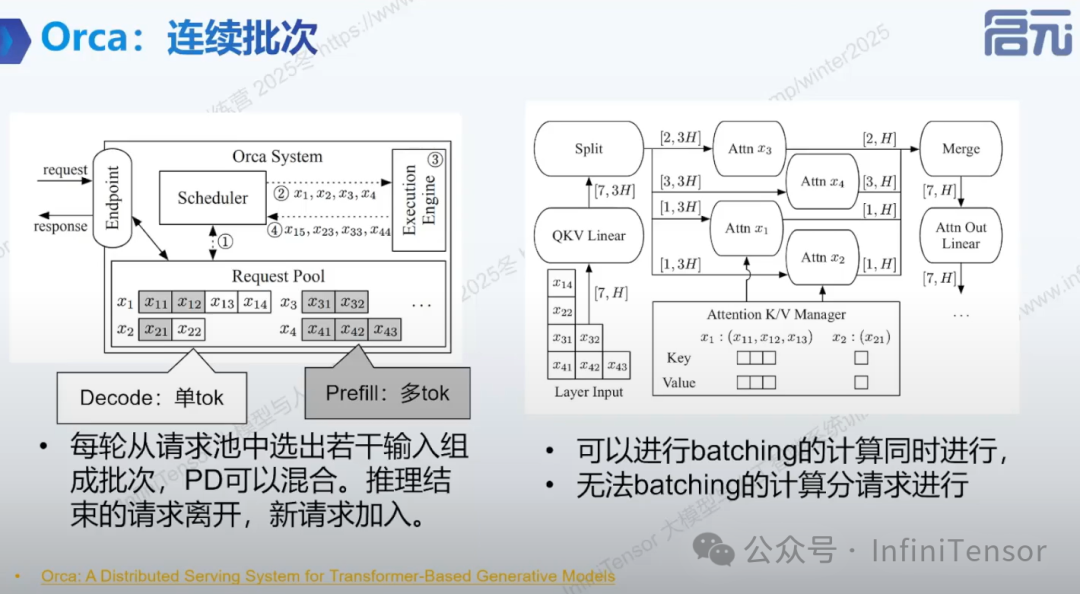
c. Orca 策略:连续批次
-
• 请求池管理
-
• 迭代级批次形成与计算
-
• 混合 PD 请求处理
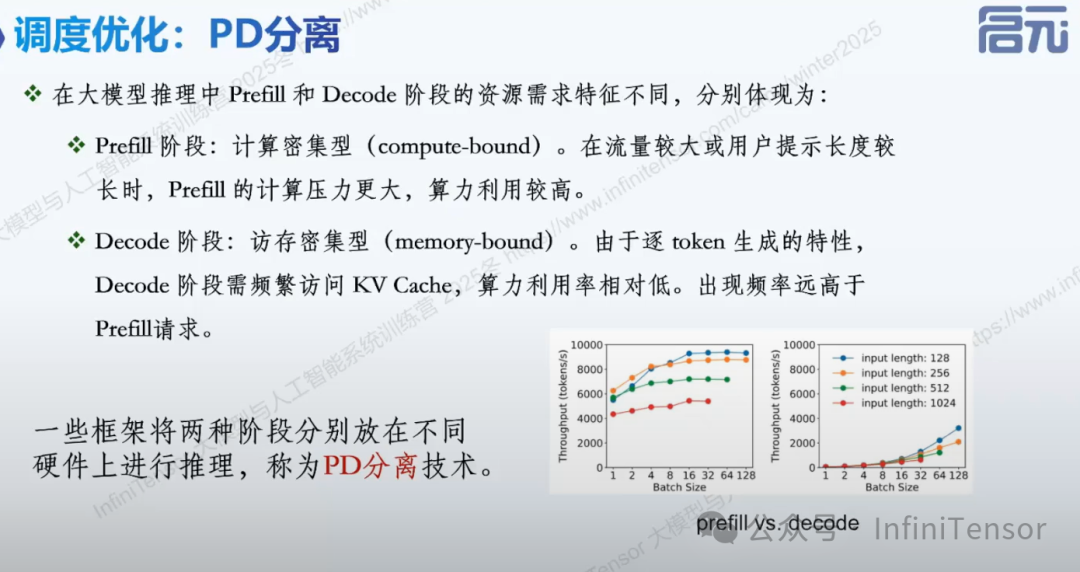
(2) PD 分离优化
-
• Prefill 与 Decode 阶段分离
-
• 不同硬件资源分配
(3) Chunk Prefill 与 Decode-Only Batch

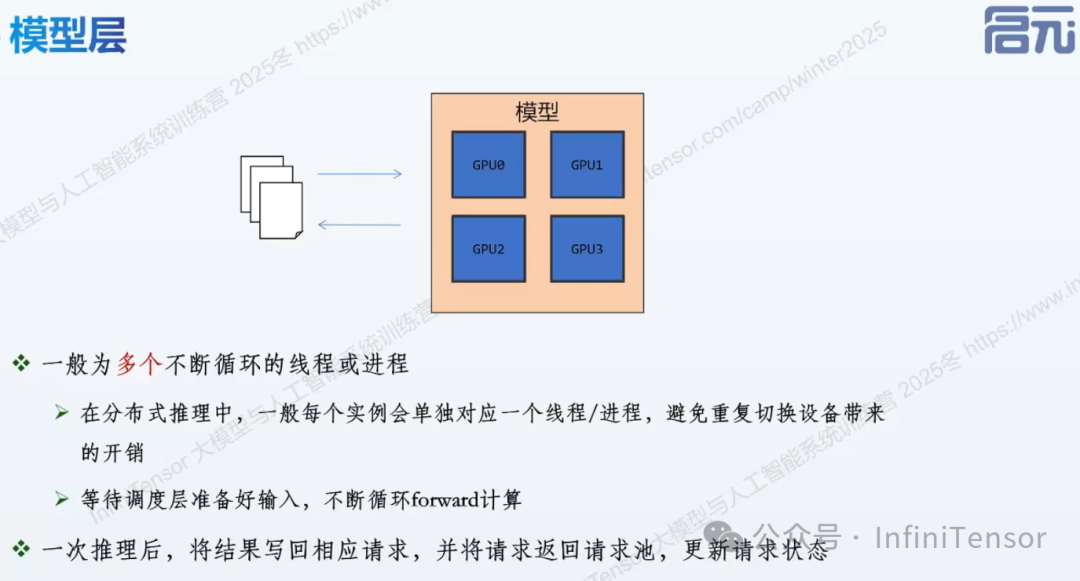
模型层
服务系统架构设计示例
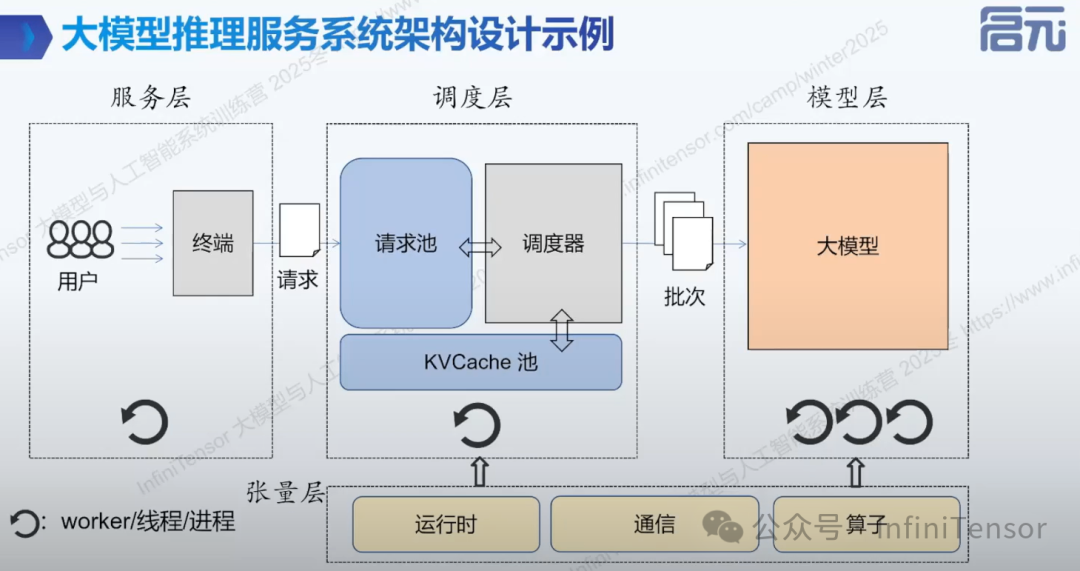
总结
本文系统阐述了大模型推理服务架构设计,重点分析了单用户与多用户服务的实现差异。在基础功能方面,详细介绍了用户交互与会话管理机制,特别是KVCache的内存优化策略。针对单用户多会话场景,探讨了从简单实现到PagedAttention(vLLM)的三级优化路径。在多用户服务部分,解析了标准API设计、服务层功能及调度器关键技术,包括请求批处理、PD分离优化等核心方法。通过架构设计示例,展示了如何构建高效的大模型推理服务系统。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 5
5 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)