mRAG: Elucidating the Design Space of Multi-modal Retrieval-Augmented Generation
本文系统研究了多模态检索增强生成(mRAG)的设计空间,针对大型视觉语言模型(LVLMs)存在的静态数据局限、幻觉问题和位置注意力偏差,提出完整解决方案。研究首次拆解了mRAG的检索、重排序、生成三阶段,通过实验验证了EVA-CLIP分数融合检索器、LVLM列表重排序和Top-1文档生成的最优组合,并提出统一智能体框架实现动态证据筛选。在E-VQA和InfoSeek数据集上平均提升5%性能,为多模
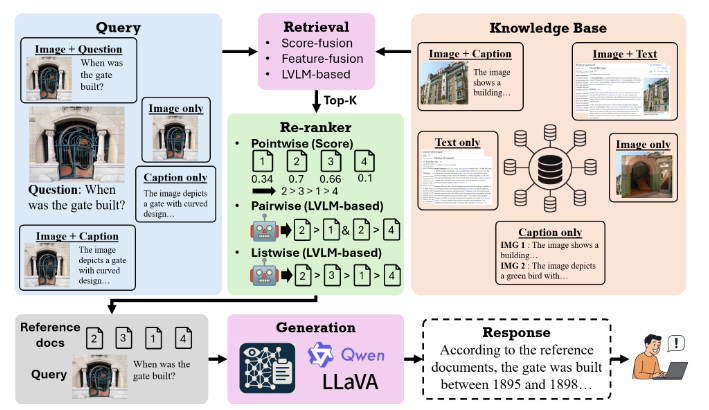
核心聚焦多模态检索增强生成(mRAG)的完整设计空间解析。论文首次系统性拆解了 mRAG 的检索、重排序、生成三大核心阶段,针对大视觉语言模型(LVLMs)的静态数据局限、幻觉问题与位置注意力偏差,提出最优实践方案与统一智能体框架,最终实现平均 5% 的性能提升,为 mRAG 的工程落地与学术研究提供了标准化指导。
一、研究背景与核心问题
1.1 研究动机
大型视觉语言模型(LVLMs)在视觉问答、视觉定位、复杂推理等多模态任务中取得显著进展,但受限于三大核心缺陷:
- 知识静态化:依赖冻结的训练数据,无法获取实时信息,面对时效性问题易输出过时内容;
- 幻觉频发:缺乏外部证据验证机制,生成内容看似合理却与事实不符;
- 模态对齐不足:跨模态语义关联能力有限,难以有效整合文本、图像等异质信息。
检索增强生成(RAG)为解决上述问题提供了可行路径,但现有 mRAG 研究存在明显局限:
- 研究碎片化:未系统探索模态配置、重排序策略、生成整合的协同优化;
- 策略单一化:重排序多依赖简单相关性评分,忽略 LVLMs 的位置注意力偏差(如 “中间信息遗忘” 效应);
- 流程孤立化:检索、重排序、生成阶段相互独立,未形成动态协同,无关信息易干扰生成结果。
1.2 核心目标
- 系统性剖析 mRAG 的完整设计空间,明确检索、重排序、生成各阶段的最优技术方案;
- 缓解 LVLMs 的位置注意力偏差,提升相关信息的利用率;
- 提出统一框架整合重排序与生成流程,动态筛选有效证据、抑制无关干扰,提升多模态任务的准确性与可靠性。
1.3 研究贡献
- 首次构建 mRAG 的完整设计空间,覆盖模态配置、检索策略、重排序方法、生成整合的全流程优化;
- 明确零样本场景下的最优实践:EVA-CLIP(分数融合)为最优检索器、LVLM 列表排序为最优重排序策略、仅输入 Top-1 相关文档为最优生成方案;
- 提出含自我反思机制的统一智能体框架,整合重排序与生成,实现动态证据筛选;
- 在 E-VQA 与 InfoSeek 数据集上验证有效性,平均性能提升 5%,且无需任何任务特定微调。
二、实验基础设置
2.1 数据集构建
论文采用两大知识密集型多模态问答数据集,为保证计算效率进行蒸馏处理:
表格
| 数据集 | 原始规模 | 蒸馏后规模 | 核心特征 | 测试样本量 |
|---|---|---|---|---|
| E-VQA(百科视觉问答) | 200 万篇文档、660 万张图像 | 5 万篇文档、17.1 万张图像 | 聚焦细粒度类别区分与实例识别,需视觉与结构化知识对齐 | 4750 个 |
| InfoSeek(信息检索视觉问答) | 10 万篇文档、37.1 万张图像 | 5 万篇文档、18.4 万张图像 | 需外部知识补充,无法仅通过视觉或常识回答 | 5000 个 |
蒸馏原则:保留原始类别分布,确保所有测试查询在精简知识库中仍可找到答案,同时控制实验计算成本。
2.2 评估指标
(1)检索阶段指标
- Recall@K:衡量 Top-K 检索结果中包含正确文档的比例,评估检索召回率;
- MRR(平均倒数排名):计算首个正确文档排名的倒数平均值,评估检索精准度。
(2)生成阶段指标
- ROUGE-L:衡量生成答案与参考答案的词汇相似度;
- 语义准确性:采用 InternVL3-14B 与 GPT-4.1 作为自动化裁判,评估生成内容的语义正确性(输出 “Correct/Incorrect” 标签)。
2.3 核心模型选型
- 检索器:6 种主流模型,涵盖分数融合(CLIP_SF、EVA-CLIP_SF、BGE-CLIP_SF)、特征融合(BLIP_FF)、LVLM-based(BGE-MLLM、GME)三类;
- 重排器:MM-Embed(零样本)、EchoSight(微调版)、Qwen2-VL-7B-Instruct(零样本);
- 生成模型:Qwen2-VL-7B-Instruct、LLaVA-OneVision(均为零样本设置)。
三、核心研究内容与实验结果
3.1 检索阶段:模态配置与策略优化
(1)模态配置设计
探索 5 种核心模态配置,分析查询与知识库的模态匹配效果:
表格
| 模态配置 | 定义 | 适用场景 |
|---|---|---|
| I(图像) | 仅使用图像作为查询 / 知识库模态 | 纯视觉检索任务 |
| IQ(图像 + 问题) | 查询侧为图像 + 自然语言问题,知识库为单一模态 | 视觉问答场景 |
| IT(图像 + 文本) | 知识库侧为图像 + 关联文本(如文章段落),查询为单一模态 | 多模态文档检索 |
| IC(图像 + 描述) | 图像搭配自动生成的描述文本,查询 / 知识库均可使用 | 需强化语义关联的检索 |
| C(描述) | 仅使用自动生成的文本描述作为模态 | 纯文本替代视觉的轻量化场景 |
(2)关键实验结果
- 最优检索组合:EVA-CLIP_SF(分数融合版)是性能最强的零样本检索器,
I↔IT(图像查询→图像 + 文本知识库)配置表现最优,E-VQA 与 InfoSeek 的 Recall@5 分别达 80.69%、81.58%; - 描述增强价值:图像查询搭配自动生成的描述(IC 配置)可使 Recall@1 提升 1%,但查询与知识库均采用 IC 配置(IC↔IC)会因描述差异放大偏差,导致性能显著下降;
- 纯文本局限:
C↔C等纯文本模态配置检索精度极低(Recall@5 仅 32%-52%),验证多模态融合对检索效果的关键作用。
3.2 重排序阶段:缓解位置注意力偏差
(1)重排序策略设计
测试三类重排序策略,适配 LVLMs 的注意力特性:
表格
| 策略类型 | 核心逻辑 | 实现方式 |
|---|---|---|
| 点态排序 | 对单个查询 - 候选对计算绝对相关性分数,按分数排序 | 提取 MM-Embed/EchoSight 的最后一层嵌入,计算点积相似度 |
| 成对排序 | 对比两个候选的相对相关性,让模型选择更优选项 | 提示 Qwen2-VL-7B-Instruct 二选一,输出 “Document A/Document B” |
| 列表排序 | 对全量候选列表进行整体评估与重排 | 提示 Qwen2-VL-7B-Instruct 按相关性降序排列所有候选 |
(2)关键实验结果
- 最优策略:LVLM 驱动的列表排序表现最佳,零样本场景下 E-VQA 与 InfoSeek 的 Recall@1 平均提升 2.6%,甚至超越专门在数据集上微调的 EchoSight 重排器;
- 位置偏差缓解:未重排序时,即使正确文档在检索结果中,也因 “中间信息遗忘” 效应被 LVLMs 忽略;重排序可将关键信息推至前端,适配模型注意力偏好;
- 负向策略:点态排序(如 MM-Embed)与成对排序性能均低于基线,前者因语义理解不足,后者因 pairwise 比较易丢失全局相关性。
3.3 生成阶段:证据整合优化
(1)实验设计
对比四种生成条件,分析检索结果数量对生成质量的影响:
- 无检索:仅依赖 LVLM 的预训练知识,作为性能下限;
- 初始检索结果:使用 Top-K 未重排序的检索文档;
- 重排序后结果:使用 Top-K 重排序后的检索文档;
- 黄金文档:直接输入包含标准答案的文档,作为性能上限。
(2)关键实验结果
- 冗余信息有害:检索精度随 K 值增大而提升(如 E-VQA 中 Top-1 到 Top-5 的 Retrieval Acc. 从 66.42% 升至 80.8%),但生成精度不升反降 ——ROUGE-L 从 0.416 降至 0.392,GPT-4.1 评估的语义准确性下降 2.11%,无关文档会干扰模型判断;
- 最优整合方案:仅提供重排序后最相关的 1 个文档,生成性能最优,重排序可使生成精度至少提升 1%;
- 性能上限验证:黄金文档的生成精度(E-VQA 的 GPT-4.1 准确率 53.73%)显著高于其他配置,证明检索质量对生成效果的核心驱动作用。
3.4 统一智能体框架:重排序与生成的动态融合
(1)框架设计
针对检索与生成的孤立问题,提出含自我反思机制的统一智能体框架,核心流程如下:
- 相关性评估:输入查询与检索文档,模型判断文档是否包含回答所需证据(输出 “Yes/No”);
- 答案生成:对相关文档,生成 tentative 答案;
- 自我反思:验证生成答案是否基于文档内容且准确回应查询(输出 “Yes/No”);
- 迭代优化:若答案无效或文档无关,切换至下一个检索文档;所有文档均无效时,输出 “Model fails to answer the question”。
(2)关键实验结果
- 框架优势:统一框架在 E-VQA 与 InfoSeek 数据集上分别提升生成精度 5%、2%,Qwen2-VL-7B 的 GPT-4.1 评估准确率从 41.77%/37.6% 提升至 45.66%/39.5%;
- 核心价值:无需任务特定微调,通过自我反思实现动态证据筛选,有效避免位置偏差与无关信息干扰,提升生成结果的可靠性。
四、最优实践方案与核心结论
4.1 mRAG 全流程最优实践
论文通过系统性实验,提炼出零样本场景下的 mRAG 最优配置:
- 检索阶段:采用 EVA-CLIP_SF 作为检索器,优先选择
I↔IT(图像查询→图像 + 文本知识库)或IC↔IT(图像 + 描述查询→图像 + 文本知识库)模态配置; - 重排序阶段:使用 Qwen2-VL 等 LVLM 执行列表排序,将最相关文档推至前端;
- 生成阶段:仅输入重排序后的 Top-1 相关文档,避免冗余信息干扰;
- 进阶优化:采用统一智能体框架,通过自我反思动态整合重排序与生成,进一步提升性能。
4.2 核心结论
- 多模态检索的关键在于模态匹配:图像查询与 “图像 + 文本” 知识库的组合能最大化利用跨模态语义关联,优于单一模态配置;
- LVLMs 的位置偏差不可忽视:重排序是提升生成性能的必要步骤,列表排序策略在零样本场景下效果最优;
- 生成质量与检索数量负相关:过量检索文档会引入噪声,仅保留最相关证据是平衡精度与效率的关键;
- 动态协同优于静态流程:统一智能体框架通过自我反思实现重排序与生成的深度融合,是 mRAG 的重要优化方向。
五、局限性与未来方向
5.1 局限性
- 场景局限:仅评估零样本场景,未探索任务特定微调对 mRAG 性能的提升;
- 数据局限:依赖蒸馏后的精简知识库,可能存在分布偏差,未完全反映真实世界中大规模异质数据的检索挑战;
- 评估局限:自动化裁判(InternVL3、GPT-4.1)的判断可能与人类评估存在偏差,尤其在模糊或开放式问题中;
- 模态局限:未覆盖视频、音频等动态多模态数据,聚焦于图像 - 文本组合。
5.2 未来方向
- 扩展场景:探索微调场景下的 mRAG 优化,结合领域数据提升特定任务性能;
- 数据扩展:构建大规模、多样化的多模态知识库,验证框架在真实场景中的泛化能力;
- 评估优化:开发人类参与的多维度评估体系,提升评估结果的可靠性;
- 模态扩展:支持视频、音频等动态模态,适配更复杂的多模态检索生成需求;
- 效率优化:探索轻量化检索与重排序策略,降低 mRAG 的计算与 latency 开销。
六、相关工作对比
表格
| 研究方向 | 代表工作 | 核心差异 |
|---|---|---|
| 传统单模态 RAG | Lewis et al. (2020) | 仅支持文本模态,未涉及多模态整合 |
| 早期多模态 RAG | Wei et al. (2024) | 聚焦模态融合技术,未系统探索全流程设计空间 |
| 重排序研究 | Liu et al. (2025) | 以文本检索为重,未针对 LVLMs 的位置偏差优化 |
| 本研究(mRAG) | - | 首次系统性拆解 mRAG 设计空间,提出跨阶段最优实践与统一框架,适配 LVLMs 特性 |
论文通过全流程的系统探索,为 mRAG 的学术研究与工程落地提供了清晰的技术路线,其核心发现与最优实践对多模态问答、智能文档分析等场景具有重要的指导价值

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 4
4 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)